基于極限學習機模型的空氣質量二次預報
2022-08-05 02:41:16朱盛愷陳勁杰
軟件工程 2022年8期
關鍵詞:模型
朱盛愷,陳勁杰
(上海理工大學,上海 200093)
kaisss163@163.com;2502526194@qq.com
1 引言(Introduction)
大氣污染系指由于人類活動或自然過程引起某些物質進入大氣中,呈現足夠的濃度,達到了足夠的時間,并因此危害了人體的舒適、健康和福利或危害了生態環境。污染防治實踐表明,建立空氣質量預報模型,提前獲知可能發生的大氣污染過程并采取相應的控制措施,是減少大氣污染對人體健康和環境等造成的危害,提高環境空氣質量的有效方法之一。
但受制于模擬的氣象場和排放清單的不確定性,以及對包括臭氧在內的污染物生成機理的不完全明晰,現有的WRF-CMAQ一次預報模型的預測結果并不理想。由于污染物濃度實測數據的變化情況對空氣質量預報影響很大,故參考空氣質量監測點獲得的污染物實測數據對一次預報數據進行修正。通過對一次預報數據和實測數據的二次建模可以優化預測結果,能夠提高對空氣質量預測的準確率。
2 樣本數據處理(Sample data processing)
數據來源為某監測點的樣本數據庫數據,數據包括污染物濃度一次預報數據和污染物濃度實測數據,其中主要為用于衡量空氣質量的六種常規大氣污染物,分別為二氧化硫(SO)、二氧化氮(NO)、粒徑小于10 μm的顆粒物(PM)、粒徑小于2.5 μm的顆粒物(PM)、臭氧(O)、一氧化碳(CO)。對初始數據進行處理(以SO的處理為例),在對數據的分析過程中發現氣候與污染物濃度的數據表格中存在大量的缺失,此外,有許多異常值存在于測量數據中,圖1中選取了部分數據示例。
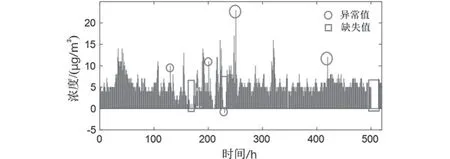
圖1 SO2監測濃度部分數據Fig.1 Partial data of SO2 monitoring concentration
由于提供的數據并非完整天數的檢測數據,根據每日預報的時間固定為早晨7 點,此時可以獲得當日7 點及之前時刻的實測數據,按天對數據進行整理,剔除頭部0 點到7 點的不完整數據,然后以整天為單位處理其余數據。
首先是對缺失值的處理,選擇以小時為單位在MATLAB中調用interp1進行一維線性插值。插值后的數據如圖2所示。
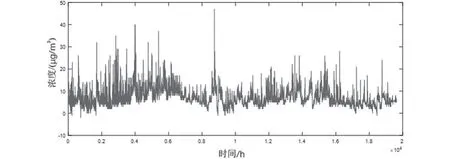
圖2 SO2監測濃度缺失值插值結果Fig.2 Interpolation results of SO2 monitoring concentration with missing values
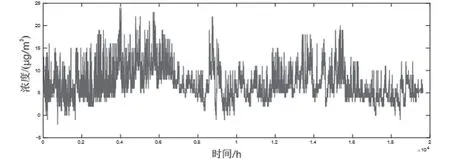
圖3 SO2監測濃度去除異常值插值結果Fig.3 Interpolation results of SO2 monitoring concentration with removal outliers
根據《環境空氣質量指數(AQI)技術規定(試行)》(HJ 633—2012),空氣質量指數(AQI)可用于判別空氣質量等級。空氣質量等級范圍根據AQI數值劃分,等級對應的AQI范圍如表1所示。
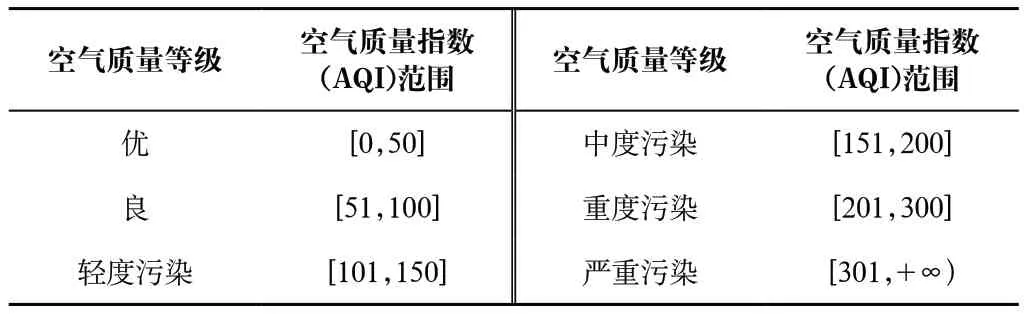
表1 空氣質量等級及對應空氣質量指數(AQI)范圍Tab.1 Air quality level and corresponding air quality index (AQI) range
當AQI小于或等于50(即空氣質量評價為“優”)時,稱當天無首要污染物。當AQI大于50時,空氣質量分指數(IAQI)計算值最大的稱為首要污染物。若IAQI最大值相同時,并列為首要污染物。IAQI大于100的污染物稱為超標污染物。
綜合考慮以AQI和首要污染物的誤差這兩個指標的加權組合作為遺傳算法的適應度。
首先得到各項污染物的IAQI,其計算公式如下:
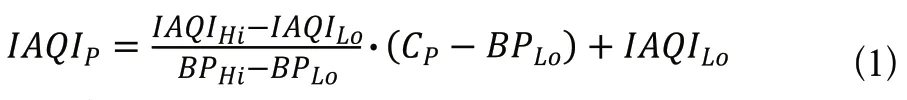
AQI取各分指數中的最大值,即
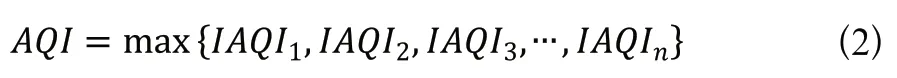
在本次研究中,對AQI的計算僅涉及六種污染物,因此計算公式如下:
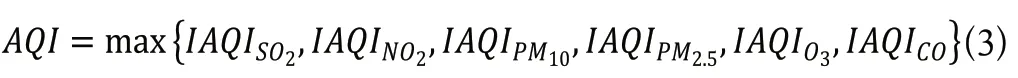
將數據庫數據經過插值處理后再轉換成AQI值,并記下對應的首要污染物,為后續分析做好準備。
3 極限學習機模型(Extreme learning machine model)
3.1 模型選擇
傳統的學習算法(如BP算法等)存在四方面的不足:訓練時間長;所得到的網絡性能差;因為某些特殊函數可能有局部極小點;網絡學習率波動大,成為阻止其進化的主要障礙。而前饋神經網絡往往采用梯度下降方法,也存在三個方面的不足:訓練時間長;容易陷入局部極小點,無法達到全局最小;學習率的選擇敏感。
極限學習機(ELM)模型網絡結構算法不再是基于梯度的算法,而是隨機產生輸入層與隱藏層間的連接權值和隱藏層神經元的閾值,在訓練中無須特殊操作,唯一值就是隱藏層神經元數量,訓練完成后就可以得到全局最優解。與以往的訓練方式比較,ELM模型具有訓練速度快、泛用性廣、誤差非常小等優點,故選擇ELM模型網絡結構完成模型預測。
3.2 模型建立
ELM模型的網絡結構與單隱藏層前饋神經網絡(SLFN)一樣,只不過在訓練階段不再是傳統的神經網絡中屢試不爽的基于梯度的算法(后向傳播),而采用隨機的輸入層權值和偏差,輸出層權重則通過廣義逆矩陣理論計算得到。得到所有網絡節點上的權值和偏差后,ELM的訓練就完成了,這時通過測試數據,利用剛剛求得的輸出層權重便可計算出網絡輸出,完成對數據的預測。
ELM訓練基本上分為隨機特征映射和線性參數求解。第一階段,隱藏層參數隨機進行初始化,然后采用一些非線性映射作為激活函數,將輸入數據映射到一個新的特征空間(稱為ELM特征空間)。簡單來說,就是ELM隱藏層節點上的權值和偏差是隨機產生的。隨機特征映射階段與許多現有的學習算法不同,ELM中的非線性映射函數可以是任何非線性分段連續函數。在ELM中,隱藏層節點參數(和)根據任意連續的概率分布隨機生成(與訓練數據無關),而不是經過訓練確定的,從而使與傳統BP神經網絡相比在效率方面占很大優勢。經過第一階段、已隨機產生而確定下來,可根據公式計算出隱藏層輸出。在ELM學習的第二階段,只需要求解輸出層的權值()。為了得到在訓練樣本集上具有良好效果的,需要保證其訓練誤差最小,將(網絡的輸出)與(樣本標簽)進行計算,求得最小平方差作為評價訓練誤差,使得該目標函數最小的解就是最優解。即通過最小化近似平方差的方法對連接隱藏層和輸出層的權重()進行求解,目標函數如下:
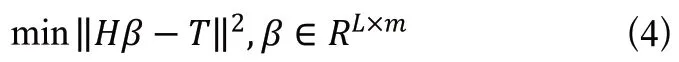
其中,是隱藏層的輸出矩陣,是訓練數據的目標矩陣。
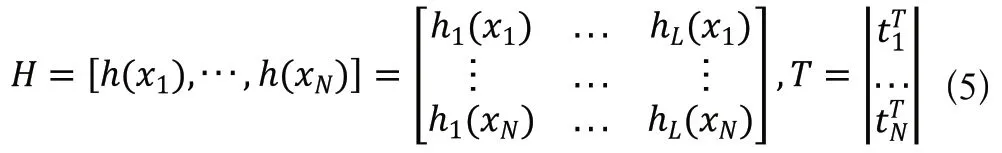
通過線代和矩陣論的知識可推導得到最優解為:

這時問題就轉化為求計算矩陣的Moore Penrose廣義逆矩陣。當HH(的轉置與相乘)為非奇異(可逆)時可使用正交投影法,得到的計算結果是:

4 優化模型的建立(Optimization model building)
4.1 遺傳算法優化的ELM模型
在模型建立上,發現ELM模型預測AQI的相對誤差最大值最小,首要污染物誤差最小,接著再選擇用遺傳算法優化現有預測模型,具體流程如圖4所示。
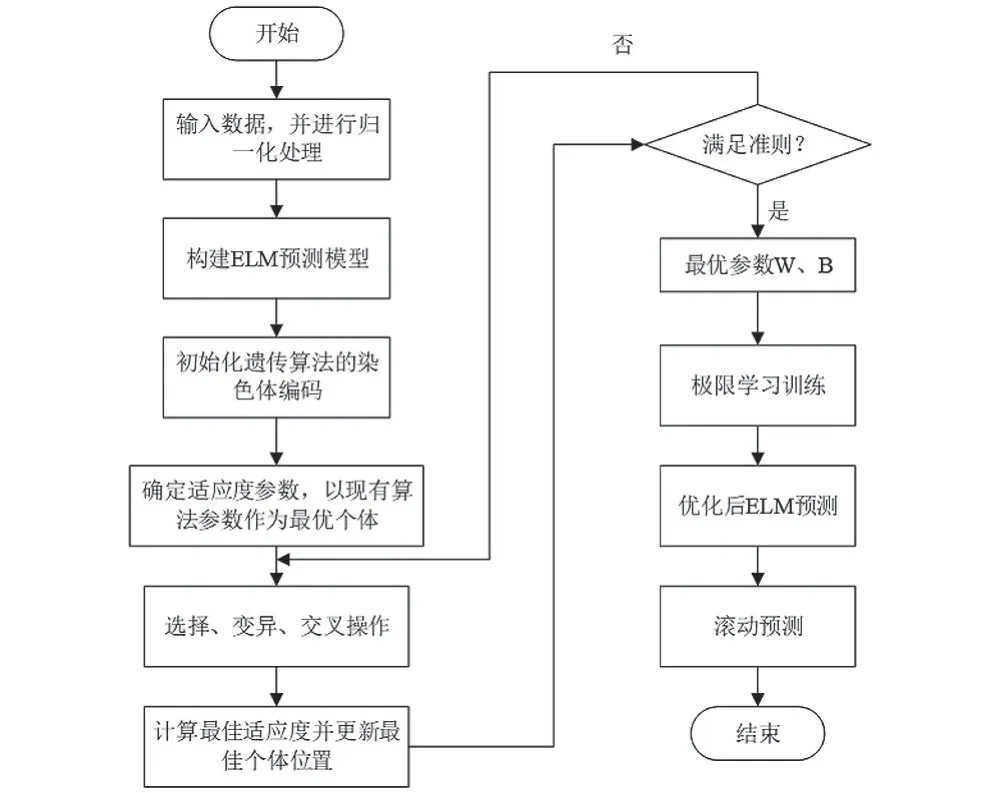
圖4 遺傳算法優化的ELM模型建立流程圖Fig.4 Flow chart of ELM model building for genetic algorithm optimization
確認好神經網絡的輸入輸出對應關系,以AQI和首要污染物的誤差這兩個指標的加權組合作為適應度,隨機設置一組要優化的懲罰因子和核參數。把數據分為80%訓練集和20%測試集,以設置的參數和訓練樣本去訓練模型,然后測試樣本的輸入與預測獲得預測結果以計算預測的AQI值,并計算得出適應度函數,再按照流程圖所示過程完成建模預測。
4.2 結果預測
預測將來某小時+1的一次預測結果時,采用滾動預測,結合該時間之前的真實時刻歷史數據,可以獲得該時間的二次預測結果。然后再預測+2 小時,+2之前+1這一時刻的歷史數據就可以采用二次預測結果去預測,預測結果如圖5—圖10所示。通過真實值-預測值得到了對應點的預測誤差數據,經過計算發現誤差值均不超過10%。可以發現,該模型方法預測還是比較準確的。
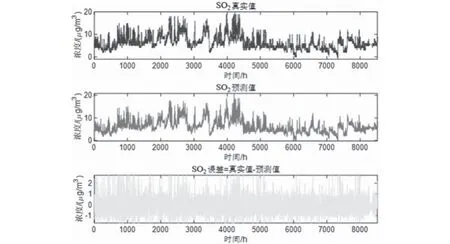
圖5 SO2真實-預測-誤差Fig.5 SO2 reality-prediction-error
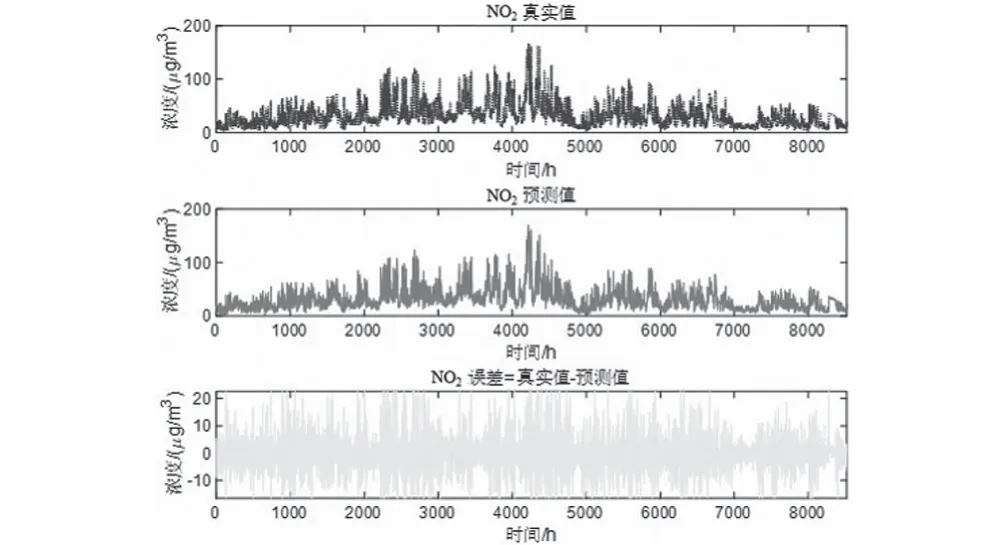
圖6 NO2真實-預測-誤差Fig.6 NO2 reality-prediction-error
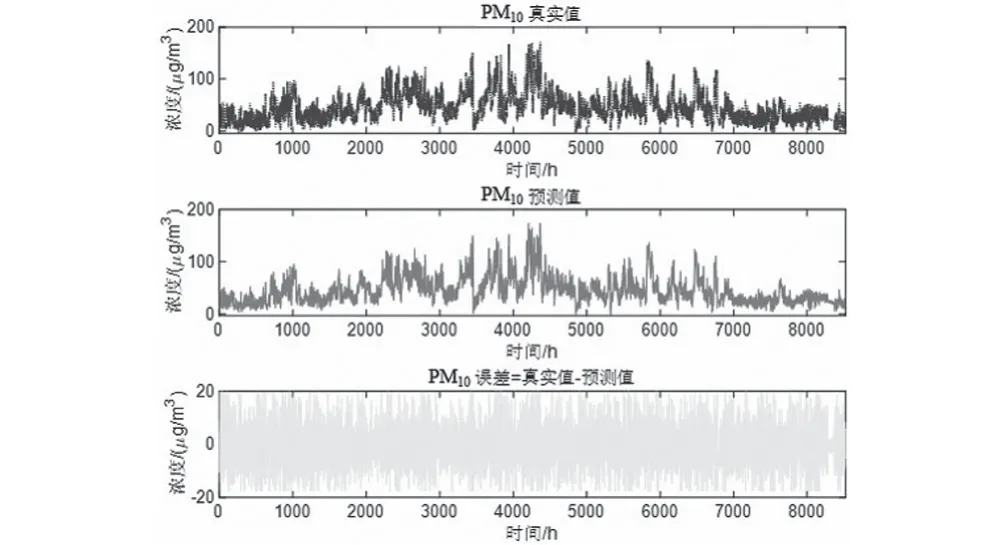
圖7 PM10真實-預測-誤差Fig.7 PM10 reality-prediction-error
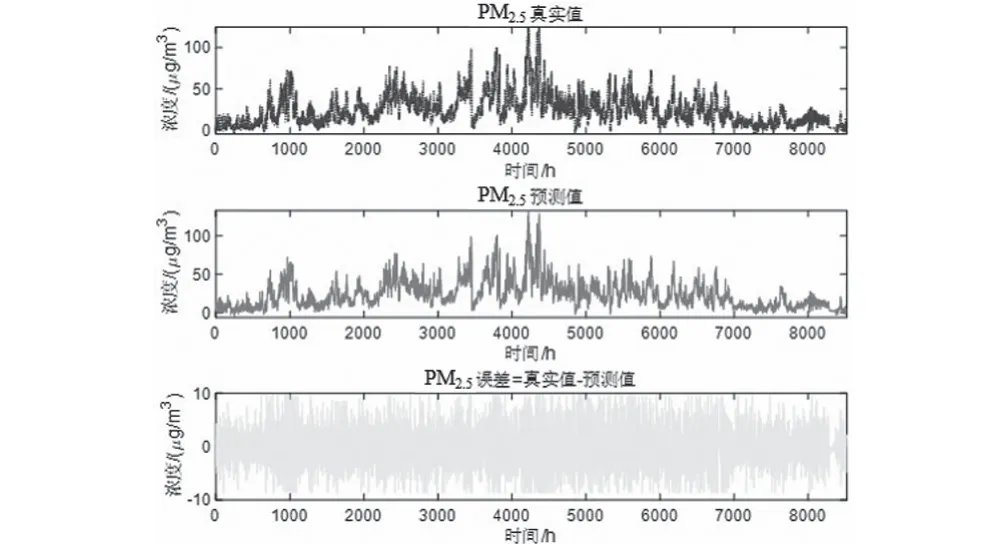
圖8 PM2.5真實-預測-誤差Fig.8 PM2.5 reality-prediction-error
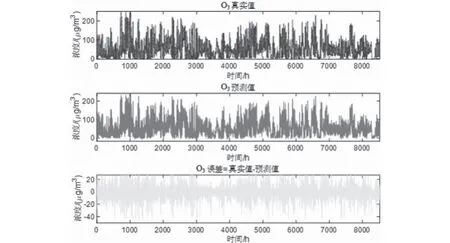
圖9 O3真實-預測-誤差Fig.9 O3 reality-prediction-error
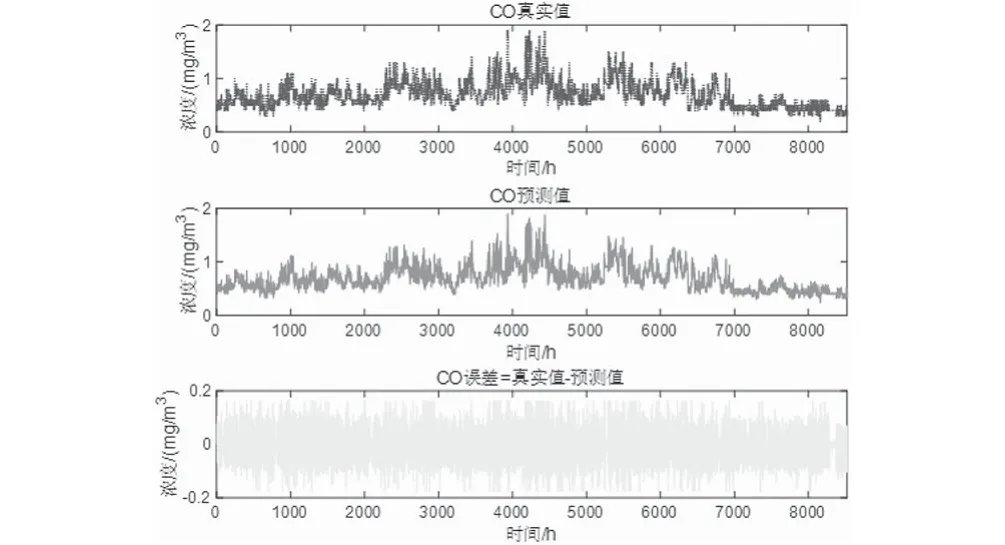
圖10 CO真實-預測-誤差Fig.10 CO reality-prediction-error
5 結論(Conclusion)
基于建立的ELM模型,結合遺傳算法,得到優化后的六種污染物真實值與預測值最大誤差均低于10%,而一次預報誤差普遍在15%以上。利用該模型在WRF-CMAQ等一次預報模型模擬結果的基礎上,結合監測點污染物實測數據進行再建模,提高了預報的準確性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
