結合棧式監督AE 與可變加權ELM 的回歸預測模型
2022-08-12 02:29:26張雪英李鳳蓮陳桂軍黃麗霞
計算機工程 2022年8期
關鍵詞:模型
閆 靜,張雪英,李鳳蓮,陳桂軍,黃麗霞
(太原理工大學信息與計算機學院,太原 030024)
0 概述
回歸分析是一種確定兩種或兩種以上變量間相互依賴的定量關系的統計分析方法,根據已知過程變量與目標變量間的相關性,建立基于歷史過程數據的回歸預測模型。由于目標變量總是受一個或多個過程變量的影響,且每個過程變量對目標變量的影響不同,因此根據過程變量對目標變量的精準預測可以為過程監控、優化和控制提供重要的實時信息。回歸預測模型多數采用不同的非線性結構來提取數據中包含的信息,常用模型包括主成分回歸(Principal Component Regression,PCR)[1]、偏最小二乘回歸(Partial Least Squares Regression,PLSR)[2]、人工神經網絡(Artificial Neural Network,ANN)[3]和支持向量回歸(Support Vector Regression,SVR)[4]。但對于大量高維、強相關性及高冗余的數據,這些模型的魯棒性差、預測性能低,而提取輸入數據的有效特征表示是建立回歸預測模型的關鍵步驟。多層深度網絡能夠提取復雜數據的特征,但由于梯度消失和爆炸問題,深度網絡并沒有比淺層模型表現得更好,直到文獻[5]提出通過無監督的逐層預訓練和有監督的微調來學習深度網絡模型,使得棧式自編碼器(Stacked Auto-Encoder,SAE)成為廣泛應用于數據分析[6]、圖像處理[7]、語音識別[8]、模式識別[9]等領域的深度學習[10]模型。
深度學習可以通過學習深層非線性網絡結構,實現復雜函數逼近,表征輸入數據,并利用特征的逐層變換完成最終的預測和識別[11]。文獻[12]將卷積神經網絡(Convolutional Neural Network,CNN)與極限學習機(Extreme Learning Machine,ELM)相結合,提出CNN2ELM 模型,用于人臉圖像的年齡預測,提高了預測魯棒性。文獻[13]將棧式降噪稀疏自編碼器(sDSAE)與ELM 相結合,提出sDSAE-ELM 算法,利用sDSAE 產生ELM 的輸入權重和隱含層偏置,降低噪聲干擾,優化網絡結構。文獻[14]將SAE 與以小波函數為激活函數的ELM 結合,提出SAEWELM 模型并將其用于工業鋁生產過程中的過度熱預測,具有良好的魯棒性和泛化能力。
針對回歸預測問題,對SAE 和ELM 兩部分進行改進再級聯是改善回歸預測效果的有效方法。文獻[13-15]采用SAE 進行特征降維或特征提取,取得了較好的效果,但它們未考慮到數據間的相關性,不能反映出目標變量與其他過程變量之間的關系。目前,關于結合改進的SAE 和ELM 進行回歸預測的研究也取得了一定成果,隨機確定輸入權值和隱含層偏置雖然能夠提升網絡速度[16],但不能根據輸入數據與輸出數據間的相關性大小進行合理賦值。本文構建一種基于棧式監督自編碼器(Stack Supervised Auto-Encoder,SSupAE)與可變加權極限學習機(variable weighted Extreme Learning Machine,vwELM)的回歸預測模型。利用棧式監督自編碼器使SAE 以有監督的方式進行逐層預訓練,提取與目標輸出變量相關的高級特征,挖掘數據間的深層關聯信息。采用可變權值的方式確定ELM 的輸入權值和隱含層偏置,以提升算法的魯棒性和泛化能力。在多個公共數據集及實際工業生產的多晶硅鑄錠數據集上進行實驗以驗證SSupAE-vwELM模型性能。
1 棧式監督自編碼器設計
1.1 棧式自編碼器
自編碼器(Auto-Encoder,AE)包括編碼和解碼兩個過程,編碼過程將輸入x通過非線性激活函數映射到隱含層,解碼過程將隱含層數據h轉化為輸出值z,再重構輸入[17]。AE 網絡結構如圖1 所示。編碼過程、解碼過程、損失函數的表達式如式(1)~式(3)所示:

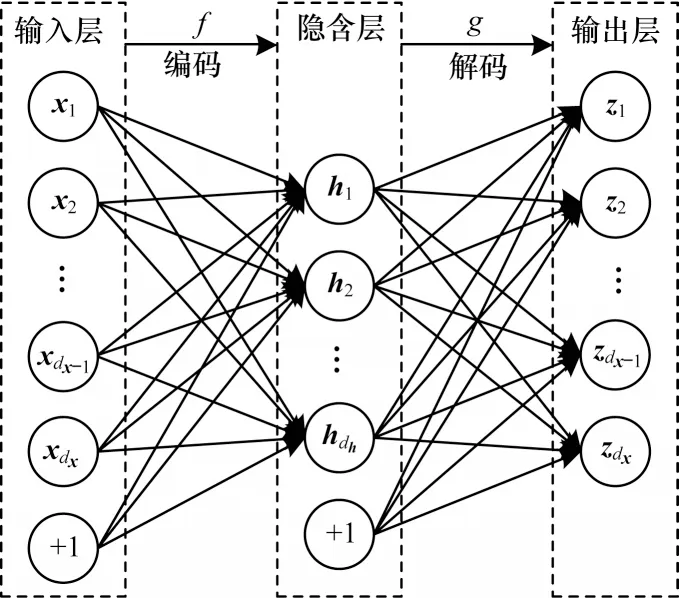
圖1 AE 網絡結構Fig.1 AE network structure
SAE 是通過多層無監督訓練的AE 逐層堆疊而構造的一種深度網絡結構,訓練過程分為無監督預訓練和有監督微調兩個階段[18],如圖2 所示。SAE采用無監督的方式逐層預訓練來初始化網絡參數,在最后一層隱含層后加入BP 回歸網絡進行回歸預測,使用目標變量數據y對權重和偏置進行整體微調,優化網絡結構。

圖2 SAE 訓練過程Fig.2 SAE training process
1.2 棧式監督自編碼器
棧式自編碼器的預訓練可以逐層學習到輸入數據的高級抽象特征,但在實際應用中,SAE 的無監督預處理方式未考慮過程變量與目標輸出間的相關性,所學習到的特征可能包含與目標輸出無關的信息。針對這一問題,提出一種以有監督方式訓練的監督自編碼器(Supervised Auto-Encoder,SupAE),即在AE 編碼與解碼的基礎上添加一層回歸網絡,AE在解碼的同時通過回歸網絡進行回歸預測,使得構成棧式監督自編碼器(SSupAE)的每層SupAE 都以有監督的方式完成預訓練,并使該深層網絡在學習重構特征的同時將與目標輸出變量相關的信息編碼到該網絡中,挖掘數據的深層特征。
SupAE 由編碼器、解碼器和預測目標輸出的回歸網絡三部分組成,網絡結構如圖3 所示。SupAE的編解碼過程與AE 相同,其中回歸網絡預測目標輸出值的計算公式如式(4)所示:
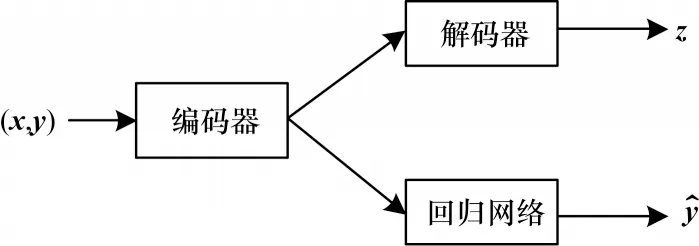
圖3 SupAE 結構Fig.3 SupAE structure

其中:本文使用的回歸網絡為BP 回歸網絡;Wr和br分別為BP 網絡的權值矩陣和偏置向量為對目標變量真實值y的預測值。
在訓練過程中,為了能夠對解碼重構輸入與回歸預測輸出同時優化,使SupAE 獲得更好的表示,SupAE的損失函數由重構誤差、目標變量的真實值與預測值間的誤差兩部分組成,通過最小化這兩部分的線性組合函數實現對數據的深層挖掘。假設訓練集有N個樣本{x,y}={(xi,yi)|xi?,yi?R,i=1,2,…,N},其中dx表示輸入數據的維數,則SupAE 的整體代價函數如下:

其中:L(x,z)為重構損失函數為目標變量的真實值和預測值間的誤差損失函數,本文均使用交叉熵損失函數;C為0~1的常數,用來平衡L(x,z)與間的比例。通過平衡重構損失與回歸預測值和真實值間的損失來提取輸入數據的潛在特征,在一定程度上相當于一種隱式的數據增強,在代價函數中引入可以將目標變量值編碼到隱含層中,同時將無監督學習的AE 轉化為有監督學習的AE,使隱含層中包含更多數據的信息,提高模型的泛化能力。
利用反向傳播算法結合梯度下降法,更新連接權值W和偏差b,求出使得式(5)達到最小值時的Wij和bi。更新公式具體如下:

其中:α為學習率。通過這種更新權值的方式,獲得最優的W和b,使得SupAE 隱層學習比較好的隱層表達。
SSupAE 是由SupAE 通過逐層堆疊構造的一種深度網絡結構,如圖4 所示,其輸入是由每個樣本對應的過程變量與目標變量值組成,在SupAE 進行逐層有監督預訓練后,舍棄每層的回歸網絡和解碼器(見圖4 中點線矩形框部分),以前一個隱含層的輸出作為后一個隱含層的輸入,通過最小化聯合損失函數(見圖4 中點劃線部分),并逐層堆疊以提取包含目標變量信息的高級特征。在最后一個隱含層后添加ELM 回歸網絡,使整個網絡再次以有監督的方式進行微調,更新各層的權值和偏置,使該網絡達到全局最優。

圖4 SSupAE 結構Fig.4 SSupAE structure
2 棧式監督自編碼器與可變加權極限學習機
2.1 極限學習機
ELM 是一種單隱含層前饋神經網絡[19],ELM 的網絡結構如圖5 所示。假設訓練集有N個樣本則ELM網絡模型可以表示如下:
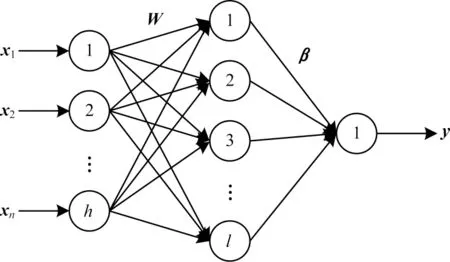
圖5 ELM 網絡結構Fig.5 ELM network structure

其中:W是輸入層到隱含層的權值向量;b為偏置向量;g(·)是激活函數;β是隱含層到輸出層的輸出權值。ELM 的矩陣表達式如式(11)所示。ELM 網絡的訓練過程就是求解式(11)的最小二乘解β,如式(12)所示。輸出權值矩陣β可由Moore-Penrose 廣義逆公式求解得到,如式(13)所示。

其中:H表示隱含層的輸出矩陣;Y表示樣本目標輸出的真實值矩陣;H?是H的廣義逆,H?=(HTH)-1HT[20]。
2.2 可變加權極限學習機
ELM 網絡隨機確定初始輸入權值和偏置,能夠提高網絡的學習速度,但是在隱含層節點個數一定的情況下,預測精度會受隨機性影響[21],因此對權值和偏置進行合理賦值能夠提升網絡的預測性能。本文將輸入變量與目標輸出間的相關性融入ELM 網絡,提出一種根據相關性確定權值與偏置的可變權值極限學習機。
針對回歸預測問題,不同的輸入變量對目標輸出變量的影響不同,對不同變量賦予不同的權值,不僅可以提高ELM 訓練的精度,而且可以有效提高模型的魯棒性。對于有N個樣本的訓練數據集{x,y}={(xi,yi)|xi?,yi?R,i=1,2,…,N},樣本中第j(j?dh)個變量與目標變量值的相關系數計算公式如下:
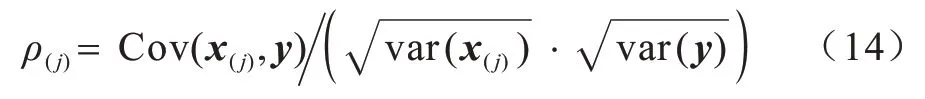
其中:x(j)為訓練集第j個變量的集合集,即x(j)={x1(j),x2(j),…,xN(j)}。協方差和方差的計算公式如下:


其中:λ(j)表示第j維變量的可變權值。
在對ELM 的輸入權值和偏置進行初始化時,用可變權值λ(j)分別對相應的輸入變量進行加權,則vwELM 網絡模型表示如下:

綜上,vwELM 算法的訓練過程如下:
1)計算輸入層輸入變量與目標輸出變量的相關系數,根據相關系數求得每個變量的可變權值。
2)確定隱含層神經元個數,對輸入層和隱含層之間的連接權重W和偏置b進行加權初始化。
3)選擇一個無限可微的函數作為隱含層神經元的激活函數,計算隱含層的輸出矩陣H。
4)根據式(11)計算輸出層權值β。
2.3 基于SSupAE-vwELM 的回歸預測模型
理論上,SSupAE-vwELM 算法能比ELM 算法實現更精準的預測。一方面,利用SSupAE 網絡對原始輸入數據進行特征提取,所提取的特征包含了目標輸出的相關信息。另一方面,vwELM 算法通過相關性分析對ELM 的權值和偏置加權,既克服了ELM因參數隨機賦值產生冗余節點[22],又使其包含了目標輸出的相關信息,有利于實現更加精準的預測。
SSupAE-vwELM 網絡結構如圖6 所示,將訓練好的n層SupAE 進行堆疊形成SSupAE,以SSupAE的頂層作為vwELM 網絡的輸入進行回歸預測。

圖6 SSupAE-vwELM 網絡結構Fig.6 SSupAE-vwELM network structure
1)特征提取。首先針對不同特征維數的數據集{xi,yi},將原始數據xi輸入到SSupAE網絡中,對SSupAE 網絡的每個隱含層節點數設置合適的值,并對每層的SupAE 權重和偏置初始化,分別設置學習率、正則化參數和學習率、丟棄率。在訓練中引入目標變量值yi使SSupAE 以有監督的方式完成訓練,提取輸入數據的深層相關特征。
2)回歸預測。以SSupAE 所提取的特征作為vwELM 的輸入,根據輸入變量與目標變量yi值間的相關性計算對應的可變權值,對vwELM 的輸入權值進行加權,訓練vwELM 網絡,得到輸出權值。
SSupAE-vwELM網絡訓練與測試過程如圖7所示。

圖7 SSupAE-vwELM 網絡訓練與測試過程Fig.7 Training and testing process of SSupAE-vwELM
3 實驗與結果分析
3.1 實驗環境與評價指標
應用MATLAB R2014b 進行實驗仿真,操作系統為Windows10,處理器為Intel Xeon E3-1535M,內存為32 GB。采用均方根誤差(Root Mean Square Error,RMSE)、決定系數(R2)和程序運行時間3 個指標對模型回歸性能進行評價,RMSE 和R2的計算公式如式(20)和式(21)所示:

其中:Nt為測試結果個數;yn和分別為真實值和預測值為測試集真實值的平均數。在回歸預測中,RMSE 值越小,R2值越接近于1,預測越精確,本文通過RMSE 和R2對模型預測結果進行綜合對比,驗證模型的預測準確性。
3.2 公共數據集上的實驗結果
3.2.1 數據集介紹
為驗證本文所提SSupAE-vwELM 模型的有效性,選用10 個樣本大小和屬性維度不同的公共數據集,具體信息如表1 所示,其中,Abalone 數據集通過物理測量變量預測鮑魚年齡,Air Quality 數據集是對意大利某嚴重污染區域的空氣質量進行預測,Boston Housing 數據集通過影響房價的變量預測房價,Concrete 數據集通過混凝土成分預測混凝土的抗壓強度,Stocks 數據集是預測10 家航天公司的股票價格,Bank 數據集是預測客戶選擇銀行的概率,Computer Activity 數據集是預測電腦CPU 的運行時間,Kinematics 數據集是預測人體的運動數據,Wine Quality 數據集是預測葡萄牙北部葡萄酒的質量,Yacht Hydrodynamics 數據集是對帆船水力性能的預測。為了解決數據特征屬性間數值量綱差異導致的計算問題,本文將所有數據歸一化為[0,1],并將每個數據集按8∶2 的比例劃分訓練集和測試集。

表1 公共數據集信息設置Table 1 Setting of public dataset information
3.2.2 參數設置
為分析SSupAE-vwELM 模型中不同網絡參數對整體回歸預測性能的影響,以Concrete 數據集為例,對比不同網絡層數的SSupAE 以及不同隱含層節點數的vwELM 對整體回歸預測準確性的影響。SSupAE 的輸入層節點數與歸一化處理后的輸入數據特征數保持一致,設置為8,預訓練的batchsize 設置為80,epoch 設置為100;微調的batchsize 設置為8,epoch 設置為1 000。通過SSupAE 網絡層數對比實驗來確定網絡結構,選取RMSE 及R2作為評價指標,將網絡層數從3 變化到8,如圖8 所示,可以看出5 層網絡結構的RMSE 最小,真實值與預測值的擬合度最好,其中每層的隱含層節點數通過試錯法確定,分別為40、30、20、10、5。

圖8 不同網絡層數的SSupAE 回歸預測性能Fig.8 Regression prediction performance of SSupAE at different number of network layers
通過vwELM 網絡隱含層節點數的對比實驗確定隱含層節點數,同樣選取RMSE 及R2作為評價指標,如圖9 所示,將隱含層節點數從1 變化到50,可以看出隱含層節點數設置為35 時RMSE 最小,真實值與預測值的擬合度最好。

圖9 不同隱含層節點數的vwELM 回歸預測性能Fig.9 Regression prediction performance of vwELM at different number of hidden layer nodes
3.2.3 結果分析
為驗證SSupAE-vwELM 模型的回歸預測性能,將ELM、SAE-ELM、SAE-vwELM、SSupAE-ELM 及SSupAE-vwELM 模型的實驗結果在10 個公共數據集上進行對比,其中,ELM 為未進行特征提取的回歸預測模型,SAE-ELM 為使用SAE 進行特征提取后使用ELM進行回歸預測的基礎模型,SAE-vwELM為在SAEELM 模型基礎上改進ELM 后的模型,SSupAE-ELM 為在SAE-ELM 基礎上改進SAE 后的模型。采用五折交叉方式驗證模型的預測效果,最終對5 次預測結果取平均值。實驗結果如表2所示,其中最優結果加粗表示。

表2 公共數據集上的回歸預測結果對比Table 2 Comparison of regression prediction results on public dataset
從表2 可知,在10 個公共數據集上SSupAEvwELM 模型相比其他模型的回歸預測性能都有所提升。SSupAE-vwELM 模型的運行時間長于ELM及SAE-ELM 模型的主要原因在于SSupAE 的深層網絡不僅能夠重構原始數據,而且還將目標輸出變量的信息編碼到網絡中,隨著網絡層數的增加,其深層非線性網絡將原始數據一層一層抽象,所提取的特征更能描述對象本質且提高預測精度,并且通過結合vwELM 回歸網絡進一步優化了網絡結構,提高了網絡的魯棒性和回歸預測能力。由此可見,SSupAE-vwELM 模型運行時間長說明其相比于ELM 及SAE-ELM 模型提取的特征更加符合樣本本質,魯棒性更好。以Concrete 數據集為例,測試集上部分樣本的預測值與真實值的對比結果如圖10 所示,可以看出除第3 個和第9 個測試樣本外,其余樣本的真實值與預測值間的誤差很小,可見本文模型的回歸預測性能較好。

圖10 測試集上的預測值與真實值的對比Fig.10 Comparison between predicted values and actual values on the test set
3.3 多晶硅鑄錠數據集上的實驗結果
為驗證SSupAE-vwELM 模型的實用性,將其在工業多晶硅鑄錠數據集上進行實驗。多晶硅作為最主要的光伏產業材料之一,配料數據對多晶硅鑄錠的電學性能和生產成本有著重要的影響,但由于每次生產所用配料的批次或重量的差異,會對質量產生影響,因此準確的配料分析和預測模型的建立至關重要[23]。少子壽命值即硅錠中少數載流子存活時間,通常被用作評價多晶硅鑄錠的質量,根據配料對少子壽命值的準確預測可以有效地指導實際生產。工業上通常用工藝試驗來預測產品質量,實現的成本高且難度大。因此,采用深度學習方法對多晶硅鑄錠過程中的少子壽命值進行精準預測對提高產品質量具有重要意義。
本文使用的多晶硅鑄錠數據集來源于山西某新能源技術有限公司的實際生產數據,該數據集包括G6 和G7 兩種產品,每種產品包含非免洗原生多晶塊料、碎多晶鋪底、碎片、中料、提純錠芯自產、提純錠芯外購、循環料等7 個配料類別,通過屬性值評價各種配料的質量,最終所需預測的目標變量為多晶硅的少子壽命值。本文所用到的數據集中G6 產品有500 個樣本,G7 產品有391 個樣本。表3 為部分G6 數據的示例。
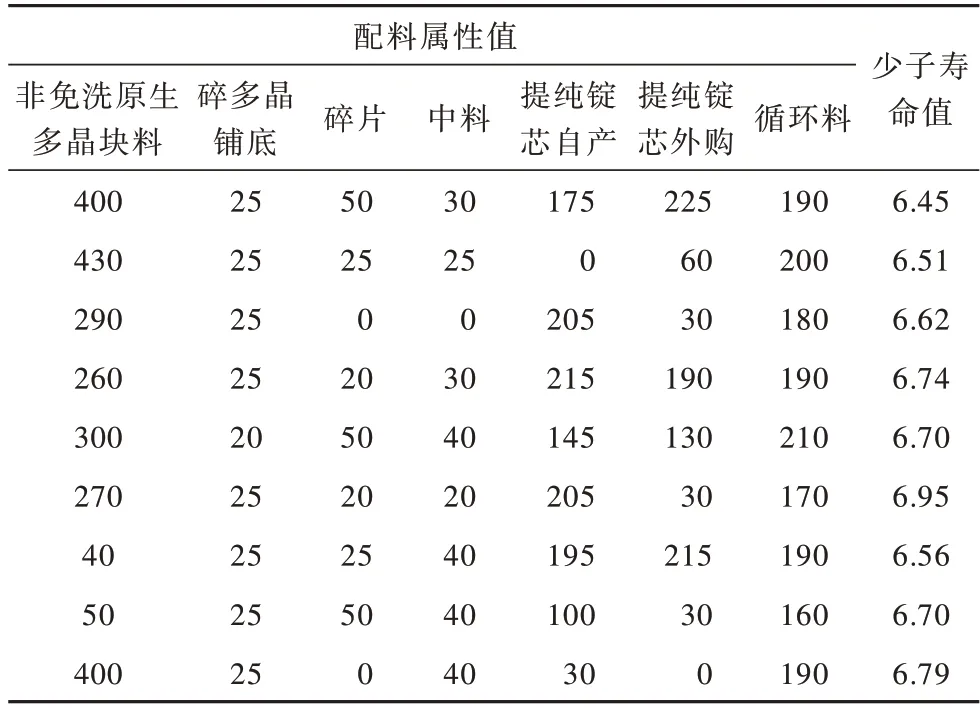
表3 部分G6 數據示例Table 3 Partial G6 data examples
將多晶硅配料數據按8∶2 分為訓練集與測試集,同樣將ELM、SAE-ELM、SAE-vwELM、SSupAE-ELM及SSupAE-vwELM 模型的實驗結果在G6 和G7 產品數據集上進行對比,實驗結果如表4 所示。

表4 多晶硅鑄錠數據集上的回歸預測結果對比Table 4 Comparison of regression prediction results on polycrystalline silicon ingot dataset
從表4 可以看出,與ELM、SAE-ELM 模型相比,SSupAE-vwELM 模型雖然運行時間增加,但回歸性能在多晶硅鑄錠的G6 產品數據集中RMSE 降低了0.056 7、0.011 2,R2提升了0.489 3、0.290 3;在G7 產品數據集中RMSE 降低了0.010 8、0.006 3,R2提升了0.297 2、0.190 6。比較表2 和表4 中5 種模型的預測結果,在多晶硅鑄錠數據集上的回歸預測結果整體比公共數據集差,主要原因為在實際鑄錠生產過程中,記錄的不規范和缺失,導致數據中出現異常數據和缺失數據,且每次生產所用的配料的批次或成分的差異,使用同樣質量的配料會出現不同少子壽命值的情況,導致最終的預測值與真實值的決定系數較低,但是表2 和表4 中SSupAE-vwELM 模型的預測結果優于其他模型結果的趨勢是一致的。
4 結束語
為了學習輸入數據的顯著表征,實現對輸出變量的精準預測,本文提出基于SSupAE-vwELM 的回歸預測模型。利用SSupAE 提取與目標輸出變量相關的高級特征,將所提取的特征作為vwELM 的輸入數據,并根據原始數據的特征表示與輸出數據間的相關性大小對ELM 的權值和偏置進行加權,解決了回歸預測任務中目標特征提取不準確、預測精度低等問題。在多個公共數據集及實際工業生產的多晶硅鑄錠數據集上的實驗結果表明,與ELM及SAE-ELM模型相比,SSupAEvwELM 模型具有較強的魯棒性和泛化性能。由于在實驗過程中發現SSupAE 網絡隱含層層數、節點數以及vwELM 網絡隱含層節點數的設置對實驗結果影響較大,因此后續將繼續研究如何合理準確地設置網絡參數,進一步提升SSupAE-vwELM 模型的回歸性能,使其適用于實際工業生產。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
