基于位置和注意力聯合表示的知識圖譜問答
2022-08-12 02:29:36吳天波程軍軍何小海
計算機工程 2022年8期
關鍵詞:模型
吳天波,周 欣,,程軍軍,朱 晗,何小海
(1.四川大學 電子信息學院,成都 610065;2.中國信息安全測評中心,北京 100085)
0 概述
知識圖譜問答的目標是針對輸入的自然語言問題,系統自動地從知識圖譜中找到答案,該答案是與問題最為匹配的實體或實體集合。若一個問題從主語實體出發,經過n條三元組到達答案所在的實體,就稱該問題為n跳問題,對該問題進行回答的過程稱為n跳問答。自動問答在發展初期主要針對較為簡單的單跳問題,隨著自然語言處理技術的不斷發展,研究人員開始關注更加復雜的多跳問答。多跳問答中涉及的實體和關系數量較多,隨著跳數的增加,搜索出正確關系路徑的復雜程度呈幾何倍數增長,如何匹配出多跳問題的正確答案是當前研究的熱點與難點。
隨著深度學習技術的不斷成熟,基于表示學習的知識圖譜問答方法越來越多。表示學習將三元組中的實體和關系表示為不同的向量,在向量空間中計算不同對象之間的相似度,進而完成知識圖譜問答任務。許多學者對知識表示學習展開研究,構建出一系列具有代表性的翻譯模型:BORDES 等[1]提出的TransE 將尾實體表示為頭實體向量和關系向量之和;WANG 等[2]提出的TransH 把頭實體和尾實體映射到關系所在的向量空間;LIN 等[3]提出的TransR將實體和關系映射到不同的向量空間進行處理。許多神經網絡模型也被用于知識表示學習:ConvE[4]把頭實體和關系拼接在一起,并用卷積層和隱藏層網絡挖掘它們的特征;CapsE[5]采用膠囊網絡,通過卷積層提取特征信息;K-BERT[6]基于BERT 模型,通過引入軟位置和可見矩陣來限制知識噪聲的影響。
基于表示學習進行知識圖譜問答的主要思想是學習問題和知識庫在低維空間的向量表示,并通過答案選擇策略來與候選答案進行匹配,從而得出正確答案。DONG 等[7]利用多層卷積網絡對問題和三元組學習低維空間的表示;YIH 等[8]定義一種查詢圖的方法,用深度卷積神經網絡處理分階段搜索問題,從而匹配問題和謂詞;陳文杰等[9]構建一種基于TransE 的TransGraph模型,該模型同時學習三元組和知識圖譜網絡結構特征,以增強知識圖譜的表示效果;DAI 等[10]基于條件聚焦的神經網絡CFO,對大規模的實體信息表示進行泛化;SUN 等[11]提出“Pull”操作智能化擴充查詢子圖,進而分類判斷正確答案;LAN 等[12]提出改進的分段查詢圖生成方法,利用該方法修改候選查詢圖,執行排名最高的查詢圖以獲取答案實體;SAXENA 等[13]將問題嵌入到與三元組相同的表示空間中,通過相同的打分函數計算候選答案得分;金婧等[14]設計一種融合實體類別信息的類別增強知識圖譜表示學習模型,其結合不同實體類別對于某種特定關系的重要程度及實體類別信息進行知識表示學習。
本文提出一種基于位置和注意力聯合表示的知識圖譜問答方法。結合復數域編碼思路表示三元組的特征,通過基于向量融合表示的答案預測方法構建端到端的知識圖譜問答模型,并在三元組分類和多跳問答的公開數據集上進行實驗以驗證該方法的分類性能。
1 相關工作
1.1 位置編碼
自Google 提出Word2vec[15]模型 以來,出現了許多詞嵌入模型,其中一個重要的上下文信息就是位置信息。復數域編碼是一種能夠讓模型精準挖掘更復雜位置關系的相對位置編碼方法,其通過在復數域計算位置編碼以表征輸入特征的上下文關系。TROUILLON 等[16]通過復數域的嵌入處理多種二元關系,SUN 等[17]在復數域構建旋轉模型以對各種關系模式進行建模和推斷,WANG 等[18]定義復數域的連續函數,將復數表示中的虛數與具體的物理意義聯系起來。復數域編碼使用關于位置的連續函數來表征一個詞在某個位置的向量表示,例如在一段文本中,一個位置嵌入向量為Ppos的詞ωj可以表示為實數域的函數f(j,Ppos),若將實數域看作復數域的子集,為不失一般性,定義此函數的值域在復數域中,則有:

其中:g為復數域的連續函數。當g滿足一定條件時,可將其改寫為指數形式:

其中:振幅rj只和詞在詞表中的索引有關,表示詞的含義,和普通的詞向量對應;相位ωj Ppos+θj既和詞本身有關,也和詞在文本中的位置有關,對應一個詞的位置信息。
1.2 關系循環神經網絡
關系循環神經網絡[19]是SANTORO 等在2018 年提出的一種用于NLP 中特征提取的網絡結構,其在提取特征的過程中引入記憶的交互,能夠對序列進行關系推理,在處理實體與關系中涉及記憶間聯系的任務時效果顯著。網絡通過引入多頭注意力機制,構建與RNN 神經元類似的關系記憶核(Relational Memory Core),使模型能較好地運用于具有記憶交互的任務中。關系記憶核結構如圖1 所示。

圖1 關系記憶核結構Fig.1 Structure of relational memory core
關系記憶核的內部結構與LSTM、GRU 等類似,循環利用上一時間步的輸出并作為記憶信息輸入到網絡中,通過門控單元控制當前時刻的輸出狀態,并利用注意力機制引入記憶間的交互。該結構維護一個記憶矩陣M,其行數為N,每一行代表一個記憶槽位。首先將當前時刻的輸入和記憶信息共同送入多頭點積注意力[20]模塊中,將其與記憶矩陣M通過殘差連接[21]得到的殘差和送入多層感知機中,再次計算殘差和,當前時刻的輸出由MLP 的輸出和記憶矩陣M共同決定。設當前時刻為t,用Mt表示當前時刻的記憶矩陣,其計算公式如下:


2 知識圖譜問答模型
2.1 三元組表示
三元組的表示學習大致可以分為編碼器網絡和解碼器網絡2 個部分,編碼器網絡將三元組映射到表示學習空間中,解碼器網絡則從三元組編碼中挖掘相關特征用于后續操作。本文參考復數域編碼中振幅和相位的物理含義,提出一種基于位置-注意力聯合編碼的三元組表示模型Pos-Att-complex,其結構如圖2 所示。編碼器在復數域求解三元組注意力和位置特征的聯合編碼,得到三元組表示并送入解碼器網絡;解碼器網絡如圖2 中上半部分虛線框中所示,用于提取來自編碼器輸出的三元組編碼向量的相關特征。

圖2 三元組表示總體模型結構Fig.2 Overall model structure of triple representation
解碼器網絡在得到三元組編碼向量后,將向量分別經過關系循環神經網絡層和卷積池化層,最后通過全連接層和Sigmoid 函數輸出,得到范圍為0~1的三元組得分。
Pos-Att-complex 編碼器結構如圖3 所示。在Batch Loader中,對正樣本的補集隨機生成與Batch大小相同、互不重復的頭實體id 和尾實體id,以50%的概率隨機替換正樣本中的頭實體或尾實體,得到和正樣本與負樣本等量的混合樣本,同時輸送到實數域鏈路和復數域鏈路,供三元組分類任務訓練使用。
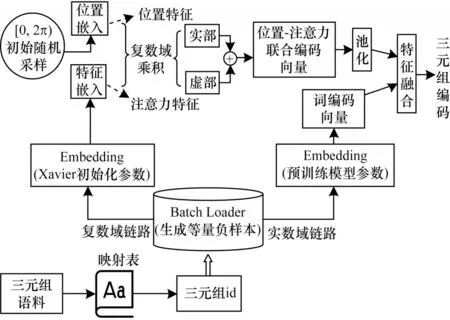
圖3 Pos-Att-complex 編碼器結構Fig.3 Stucture of Pos-Att-complex encoder
在實數域鏈路,三元組通過預訓練模型得到詞編碼向量m1。在復數域鏈路,三元組id 通過Xavier[22]隨機初始化參數做詞嵌入,得到特征嵌入向量m2,其表征三元組的注意力特征。同時,對[0,2π)的區間進行初始均勻隨機采樣,得到位置嵌入向量Ppos,其表征三元組的位置特征。對特征嵌入向量與位置嵌入向量進行復數域乘積,分別得到復數域表示的實部Re和虛部Im:

將實部和虛部相加,得到位置-注意力聯合編碼向量m3:

在對實數域鏈路的詞編碼向量和復數域鏈路的位置-注意力編碼向量進行特征融合之前,為緩解訓練過程中由過擬合帶來的泛化性能瓶頸問題,對位置-注意力編碼向量采用池化策略。具體地,對一個Batch 上的向量做池化運算,然后與詞編碼向量進行特征融合,如下:

其中:pool 為池化函數,通常有最大池化(Max Pooling)和均值池化(Mean Pooling)2 種方式,分別取整個維度上的最大值和平均值作為輸出為池化后的位置-注意力聯合編碼向量。
對復數域鏈路和實數域鏈路的三元組表示向量進行特征融合,通過加權和的方式得出最合適的三元組編碼向量m:

其中:α為待訓練的參數,其初始值設置為1。
2.2 知識圖譜問答
圖4 所示為多跳問答的總體流程,通過主語實體將問題與知識圖譜進行匹配,定位出與問題相關的三元組路徑。
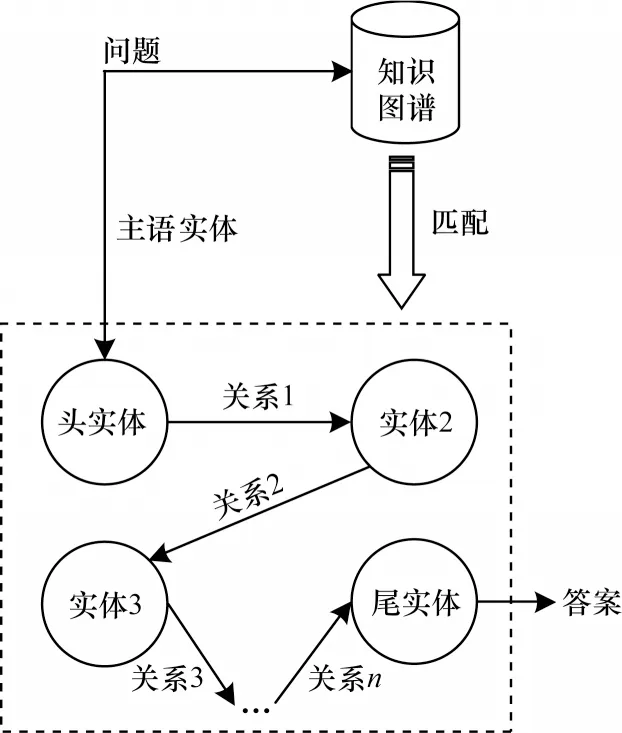
圖4 多跳問答總體流程Fig.4 Overall procedure of multi-hop question-answering
結合三元組表示方法,本文構建一種基于向量融合表示的端到端知識圖譜問答模型,如圖5 所示。

圖5 知識圖譜問答模型結構Fig.5 Stucture of knowledge graph question-answering model
知識圖譜問答模型分為問題嵌入、關系篩選、向量融合、答案預測4 個模塊,通過各模塊協同來完成知識圖譜問答任務:
1)在問題嵌入模塊中,問題q通過RoBERTa[23]做詞嵌入,然后輸入到N層的線性層中,進一步學習問題的表示,最后通過一層工廠層,將特征向量的維度轉換為三元組嵌入的維度,得到問題嵌入向量vq。
2)關系篩選模塊篩選出與輸入的問題可能相關的所有關系,得到關系集合R,將其作為三元組編碼器的輸入之一,同時為向量融合模塊提供支撐。關系篩選模塊具體流程如圖6所示,首先將問題q中的主語實體h送入查詢圖生成器中,查詢圖生成器對知識圖譜中的所有關系進行初步篩選,生成關系候選集R0,生成步驟為:以h為中心節點,不限制跳數地遍歷所有與h有關聯的關系鏈,直到沒有節點可以擴展出新的關系鏈,從而得到這些關系的集合R0。在得到R0后,對其做進一步篩選,使輸出到后續模塊的信息盡可能精確。一方面,針對R0中的每個關系r,計算問題q和r的語義相似度,將相似度分數s大于0.5 的關系構成一個集合,記為R1。在計算語義相似度時,將q通過RoBERTa 后得到q0,將其與r計算點積,然后通過Sigmoid 函數得出它們的相似度分數s,計算公式如下:
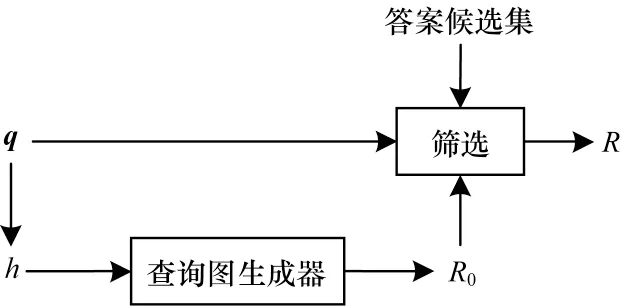
圖6 關系篩選模塊流程Fig.6 Procedure of relational filtering module

另一方面,針對知識圖譜所有三元組答案實體ta,篩選主語實體h到ta之間的最短關系路徑,將所有最短路徑中包含的關系構成另一個集合,記為R2。綜上,R1包含了與問題q可能有關的所有關系,R2包含了主語實體h到所有可能答案實體的最短路徑中的關系。本輪問答最有可能涉及的關系應該處于上述兩者的交集中,因此,對R1和R2進行交集運算,得到所需的關系集合R:

3)在向量融合模塊中,首先對R中的每個關系進行編碼,通過Pos-Att-complex 編碼器得到關系向量的集合VR。為了表示關系集合中的向量并與問題向量較好地融合,對VR中的所有關系向量計算均值,然后將其與vq相加,實現關系和問題向量的融合表示。設R中關系的數量為nR,模塊輸出的融合表示向量為vr′,其計算公式如下:

4)答案預測模塊通過計算答案預測的分數,輸出得分最高的答案,得到候選答案向量集合VA,其中的每一個向量代表一條三元組中的尾實體向量。將VA中的每個向量與vh、vr′組合構成三元組編碼,送入Pos-Att-complex 解碼器,對三元組進行打分,得到的分數就代表問題與所輸入答案的匹配程度。在解碼器的輸出中,記錄vh、vr′與每個候選答案之間構成的三元組得分,即答案預測分數,取分數最高的三元組對應的尾實體,該尾實體即為預測的答案。
3 實驗結果與分析
3.1 數據集與實驗環境
WN11 和FB13[24]是用于評估基于知識圖譜的三元組分類準確率的權威基準數據集,通過模型分類真假三元組的能力來衡量模型對三元組進行表示學習的效果。三元組分類數據集規模如表1 所示,2 個數據集分別擁有11 和13 類關系、萬級的實體數量和十萬級的三元組數量,其中,訓練集中只有真實三元組,在訓練時從Batch Loader 中生成錯誤三元組,驗證集和測試集中同時擁有真實三元組和錯誤三元組,用于計算模型的分類準確率。

表1 三元組表示數據集規模Table 1 The size of triple representation datasets
MetaQA[25]是目前公開的一個大規模多跳知識圖譜問答數據集,在通用語料的電影領域有超過40 萬個問題,分為1 跳、2 跳和3 跳的問答對,同時提供一個包含約13.5 萬條三元組、4.3 萬個實體的知識圖譜。MetaQA 問答數據集規模如表2 所示,在該數據集上,每個問題的主語實體都已經被標注出,模型可直接從中提取主語實體。

表2 MetaQA 數據集規模Table 2 The size of MetaQA dataset
本文模型訓練所在的計算機環境為Ubuntu 16.04 操作系統,所用顯卡為Nvidia GTX 1080Ti,深度學習框架為CUDA 10.0 和Pytorch 1.6.0,編程語言及版本為Python 3.6.10,使用的梯度下降優化器為Adam 優化器[26]。
3.2 三元組分類
在使用WN11 和FB13 數據集訓練模型之前,需要選取模型的超參數和預訓練的詞嵌入模型。針對WN11 和FB13 數據集,本文分 別選取GloVe[27]和TransE[1]作為Pos-Att-complex 編碼器中實數域鏈路的預訓練詞嵌入模型。WN11 和FB13 這2 個數據集的詞嵌入維度都設置為50,學習率分別設置為1e?4和1e?6,總迭代輪次分別設置為50 和30。
模型每訓練完一個輪次便計算一次當前參數下的驗證集準確率,當且僅當驗證集準確率比之前的輪次都要高時才保存并覆蓋模型,最終得到驗證集上效果最好的輪次下的參數,計算該參數下的模型在測試集上的準確率并作為測試結果,從而更加客觀真實地反映模型的泛化性能。模型在編碼器上進行池化時采用最大池化和均值池化2 種方式,WN11和FB13 上的測試結果如表3 所示。

表3 不同池化方式下的三元組分類結果Table 3 Triad classification results under different pooling methods %
從表3 可以看出,采用均值池化的模型測試準確率更高,分類效果更佳。本文模型Pos-Att-complex 采用均值池化的方法,表4 所示為該模型與近幾年公開的主流模型之間的測試結果對比。

表4 5 種模型的測試結果對比Table 4 Comparison of test results of five models %
在表4 中,TransD[28]、TranSparse[29]和TransAt[30]為近年來效果較好的改進翻譯模型,R-MeN[31]使用較新的關系循環神經網絡來提取特征,本文Pos-Attcomplex 模型參考了其應用關系循環神經網絡的方式,提出的位置-注意力聯合表示方法使模型在WN11 上取得了更高的準確率,并且在2 個數據集上的測試結果平均值高于R-MeN 模型,但在FB13 上的結果還有一定提升空間。同時值得注意的是,本文在對復數域編碼經典模型ComplEx[32]進行三元組分類的代碼復現中發現,相對于WN11 數據集,學習率的設置對FB13 數據集的影響更大,不同的損失函數設置、歸一化方法以及硬件算力都可能對實驗結果產生影響。
3.3 知識圖譜問答分析
知識圖譜問答模型的問題嵌入模塊通過4 層線性層挖掘問題特征。模型在每個數據集上至多訓練200 個輪次,并設置早停等待輪次為12,當模型超過12 個迭代輪次后在驗證集上仍未出現更高的準確率時就停止訓練,同時保存在驗證集上準確率最高的模型。在3 個數據集上完成訓練后保存3 個模型,依次在各個測試集上計算問答的準確率,將本文模型的測試結果與近幾年公開的模型進行對比,如表5所示。
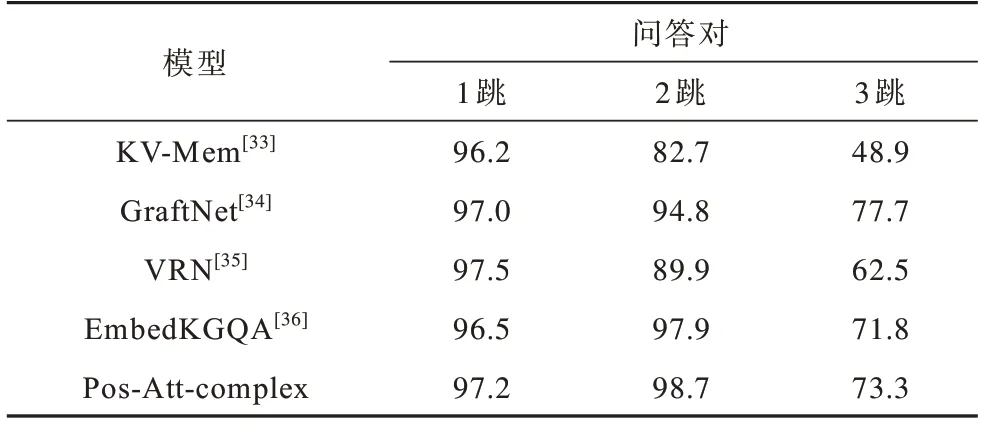
表5 5 種模型的問答結果對比Table 5 Comparison of question-answering results of five models %
KV-Mem[33]是EMNLP 2016上提出的模型,其通過維護一個鍵值對形式的內存表進行問答對檢索;GraftNet[34]是EMNLP 2018 上提出的模型,其使用啟發式方法從文本語料庫中創建特定的問題子圖進行問答推理;VRN[35]是AAAI 2018 上提出的使用變分學習算法來處理多跳問答的模型;EmbedKGQA[36]是ACL 2020上提出的在表示學習空間求解知識圖譜問答的模型,其將問題嵌入到與知識圖譜相同的表示空間中,用復數域編碼經典模型ComplEx[32]處理三元組的嵌入,并用相同的打分函數選取最優答案,為了對比改進效果,表中該行數據記錄了本文在相同的實驗環境下對該模型的復現結果。本文基于向量融合表示的答案預測方法結合三元組表示學習模型,通過關系篩選、向量融合等策略,對問題與三元組的匹配做出進一步約束,從表5可以看出,相對其余4 種模型,本文模型的準確率都有一定程度的提高,綜合能力表現較優。
3.4 消融實驗分析
為了驗證本文所提三元組表示和知識圖譜問答方法的有效性,對其分別進行消融實驗。在三元組分類實驗中,在不進行池化和不采用復數域鏈路編碼的情況下訓練模型,相同實驗條件下模型的測試結果如表6 所示。
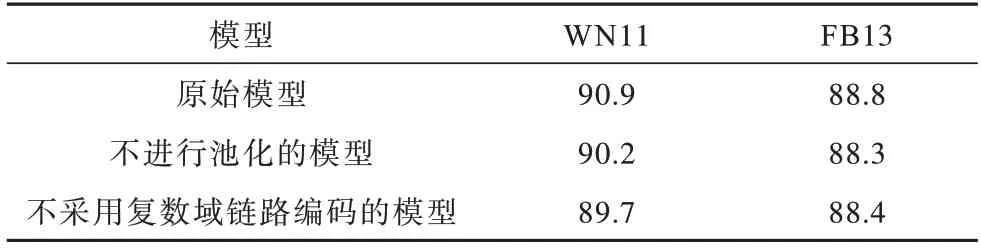
表6 三元組分類消融實驗結果Table 6 Triple classification ablation experimental results %
從表6 可以看出,采用復數域編碼和均值池化的原始模型測試準確率最高,不進行池化的模型的準確率在WN11 和FB13 上分別下降0.7 和0.5 個百分點,不采用復數域鏈路編碼的模型的準確率分別下降1.2 和0.4 個百分點,因此,復數域編碼對模型性能的影響較大。
在知識圖譜問答的消融實驗中,在其他條件不變的情況下取消向量融合,直接將問題嵌入向量vq當作vr′輸入Pos-Att-complex 解碼器,在相同實驗環境下訓練模型,測試結果如表7 所示。

表7 知識圖譜問答消融實驗結果Table 7 Knowledge graph question-answering ablation experimental results %
從表7 可以看出,當取消向量融合時,模型在1 跳~3 跳數據集上的準確率均出現了不同程度的下降,從而驗證了向量融合策略的有效性。
4 結束語
本文構建一種基于位置和注意力聯合表示的知識圖譜問答模型。通過Pos-Att-complex 三元組表示模型將知識圖譜中的三元組映射到表示學習的向量空間中,通過三元組分類任務對模型參數進行訓練。在知識圖譜問答模型中,基于已有知識表示學習模型提出基于向量融合表示的答案預測方法,以問題嵌入、關系篩選模塊作為基礎,向量融合模塊作為核心,通過答案預測模塊輸出結果,從而實現端到端的知識圖譜問答。該模型在三元組分類的權威基準數據集和多跳問答基準數據集上均取得了較好的測試結果,準確率相比近幾年提出的公開模型均有一定提升,同時,對復數域編碼和向量融合策略的消融實驗結果驗證了本文方法的有效性。但是,本文模型引入了較多的訓練參數,使得三元組編解碼器和知識圖譜問答的模型訓練耗時較長,間接導致三元組分類和知識圖譜問答的周期延長,下一步將針對模型訓練效率進行優化以解決上述問題。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
