深度學習中的安全帽檢測算法應用研究綜述
2022-08-19 08:19:36張立藝武文紅牛恒茂段凱博蘇晨陽
計算機工程與應用 2022年16期
張立藝,武文紅,牛恒茂,石 寶,段凱博,蘇晨陽
1.內蒙古工業大學 信息工程學院,呼和浩特 010080
2.內蒙古建筑職業技術學院 建筑工程與測繪學院,呼和浩特 010020
建筑施工現場中因高空墜落、物體打擊導致作業人員死亡的事故占比達50%以上,安全帽是保證作業人員免受致命傷害的一種重要防護工具。因此在施工現場安全管理中,對施工人員進行安全帽佩戴檢測是重要工作,同時也是未來智能建造平臺或智慧工地應用的重要內容。
目標檢測作為計算機視覺領域的一個重要研究方向,是很多復雜計算機視覺任務的基礎,其基本任務是找出圖像中感興趣的目標并給出目標的類別和位置信息。安全帽檢測作為目標檢測的具體應用領域,在施工現場智能化監控系統中起關鍵作用。截至目前,安全帽檢測算法的研究主要分為兩類:一是基于傳感器的安全帽檢測算法;二是基于計算機視覺的安全帽檢測算法。其中,基于計算機視覺的安全帽檢測算法又分為傳統安全帽檢測算法和基于深度學習的安全帽檢測算法。
基于傳感器的安全帽檢測算法主要依靠定位技術來檢測工人和安全帽,現有的基于傳感器的檢測和跟蹤技術需要每個施工人員佩戴物理標簽或傳感器,這就會對工人的正常作業造成干擾,跟蹤設備通常都會有距離限制,并且投資成本很高。因此,該方法具有一定的局限性。傳統安全帽檢測算法大致可以分為三個階段:首先通過活動窗口提取出候選區域。其次對這些候選區域進行手工的特征提取,特征提取的方法包括Haar-like特征[1]、方向梯度直方圖(histogram of oriented gradient,HOG)[2]和局部二值模式(local binary pattern,LBP)[3]。最后使用AdaBoost[4]、支持向量機(support vector machine,SVM)[5]等方法進行分類識別,進而判斷作業人員是否佩戴安全帽。傳統安全帽檢測算法主要有三種:背景差法[6]、圓霍夫變換法[7]和DPM(deformable part model)算法[8]。目前,安全帽檢測大多應用于監控視頻中,由于攝像機放置位置不同,會產生近場、遠場以及光照強度、背景復雜多變的安全帽特征。傳統安全帽檢測算法提取的特征基本都是低層次、人工選定的特征,不能夠很好地表達大量、多類目標。算法基于滑動窗口的區域選擇沒有針對性,使得大量窗口冗余,造成算法的時間復雜度高。以上缺陷導致傳統安全帽檢測算法的準確性差且無法滿足實時性要求。
隨著深度學習的發展,利用卷積神經網絡能夠提取更高層、表達能力更好的安全帽特征,相比于用人工選定的特征,極大地提高了安全帽實時檢測的準確性。基于深度學習的目標檢測算法已經廣泛應用于安全帽檢測任務當中,具有很大的應用價值。本文首先簡述了傳統安全帽檢測算法并分析其局限性,提出安全帽檢測面臨的問題;之后簡介了當前常用的基于深度學習的安全帽檢測算法的應用情況,說明了各類算法的優缺點,重點闡述了基于深度學習的安全帽檢測算法的改進、優勢以及存在的問題;最后對安全帽檢測未來的研究方向進行了分析和討論。
1 基于深度學習的兩階段安全帽檢測算法
基于深度學習的兩階段安全帽檢測算法按照兩階段目標檢測算法的原則進行檢測,其最大的優點是可以充分提取圖像的特征,對安全帽實現精確的分類和定位,針對小目標安全帽的檢測效果很好,但由于需要分兩步進行檢測,檢測效率偏低。目前,在安全帽檢測任務中用到的兩階段目標檢測算法有Faster R-CNN 和Cascade R-CNN。
2015年Ren等[9]提出的Faster R-CNN算法是由生成候選框的區域建議網絡(region proposal network,RPN)和Fast R-CNN目標檢測算法兩個模塊組成。Faster RCNN 采用RPN 來代替Fast R-CNN 中使用分割算法生成候選框的方式,節約計算成本,真正地實現了端到端訓練,對安全帽的檢測準確度和檢測速度比傳統的目標檢測算法提高很多,但由于兩階段的算法特性,其檢測效率較低。Fang等[10]提出了一種基于Faster R-CNN的自動非硬帽使用(non-hardhat-use,NHU)檢測方法,研究分析了建筑工人的各種視覺條件,并根據視覺條件對圖像幀進行分類,根據不同的視覺類別,將圖像幀輸入到Faster R-CNN 模型中進行訓練,得到了比傳統安全帽檢測算法精度更高、速度更快、能有效檢測不同施工現場條件下施工人員NHU 的安全帽檢測算法,但由于采用最原始的FasterR-CNN算法,只能運用于對實時性要求不高的安全帽檢測任務中。僅僅依靠Faster R-CNN算法不能很好地實現安全帽佩戴的圖像和視頻檢測。針對該問題,2020 年鄧開發等[11]通過將Faster R-CNN目標檢測模型和深度特征流算法(deep feature flow)[12]相結合,實現了對施工現場攝像頭監控的視頻中安全帽的檢測,該方法可以較好地實現安全帽佩戴的圖像和視頻檢測。但是對圖像和視頻中目標被遮擋和光線變化多樣的目標檢測效果不好,需要進一步通過改進Faster R-CNN網絡來提高檢測的準確度。
針對兩階段目標檢測算法中單個的IOU 閾值設定使得正負樣本不均衡導致檢測準確度低的問題,2018年Cai等[13]提出了Cascade R-CNN算法。該算法將對樣本的單閾值采樣改為多閾值采樣,它的重采樣機制保證了算法的每一個R-CNN 階段的檢測器都不會過擬合,提高了檢測效果。Cascade R-CNN與Faster R-CNN網絡結構對比圖如圖1所示,其中“I”表示輸入圖片,“Conv”表示骨干卷積神經網絡,“Pool”表示按區域提取特征,“H”表示檢測頭,“B”表示邊界框,“C”表示分類類別。相比于Faster R-CNN,Cascade R-CNN 很大程度上提高了檢測準確度,但僅能應用于對檢測速度要求較低的安全帽檢測任務中。

圖1 Cascade R-CNN與Faster R-CNN網絡結構對比圖Fig.1 Comparison of network structures between Cascade R-CNN and Faster R-CNN
隨著基于深度學習的目標檢測算法的發展,施工現場安全帽檢測領域中所用到的算法也不斷地更新。由于兩階段安全帽檢測算法需要預先生成候選框,再對候選框進行分類和回歸,邊界框經過兩次微調,檢測準確度比單階段安全帽檢測算法要高,但損失了檢測速度。這就導致兩階段安全帽檢測算法不能夠適用于對速度要求極高的安全帽檢測任務。基于深度學習的兩階段安全帽檢測算法可以精準地識別遠處小目標安全帽、遮擋的安全帽目標以及處理光線變化等因素導致的檢測效果差的安全帽檢測問題。然而面對復雜場景的施工現場中的安全帽檢測任務,單階段安全帽檢測算法則體現了更高的應用研究價值。
2 基于深度學習的單階段安全帽檢測算法
基于深度學習的單階段安全帽檢測算法模型結構簡單且檢測速度快,能夠很好地應用于安全帽檢測任務中,與兩階段安全帽檢測算法相比,單階段安全帽檢測算法的檢測準確度有所下降。目前,在安全帽檢測任務中常用的單階段目標檢測算法包括YOLO 系列算法、SSD算法、RetinaNet和EfficientDet等。
2.1 YOLO系列安全帽檢測算法
用于安全帽檢測任務中的YOLO 系列算法包括YOLO、YOLOv2、YOLOv3、YOLOv4和YOLOv5算法。
2015 年Redmon 等[14]提出了YOLO(you only look once),該算法將對目標的分類和定位問題轉化為回歸問題,YOLO網絡結構由24個卷積層和2個全連接層構成,通過整張圖訓練網絡模型,能夠很好地區分檢測目標和背景,通過劃分單元格的方式來檢測目標,大大提高了檢測速度。雖然YOLO 的檢測速度獲得了極大的提升,但是由于邊界框定位不準確導致小目標安全帽檢測效果差,存在小目標安全帽漏檢的問題。YOLOv2[15]采用YOLO劃分單元格的思想,使用由22個卷積層和5個池化層構成的完全卷積網絡提取特征,與原始YOLO相比,去掉了dropout層,引入BN操作和錨機制,無全連接層,采用K-means聚類方法獲得錨框尺寸,在保持速度的同時提高了檢測準確度。YOLOv2 較YOLO 對小目標的檢測效果有所提升,但仍沒有解決小目標安全帽漏檢、錯檢的問題。將YOLOv3 應用于安全帽檢測任務,極大地提高了對小目標安全帽的檢測準確度,同時檢測速度也有所提升。YOLOv3[16]相比于YOLOv2,采用基于殘差網絡的DarkNet-53來提取特征,無全連接層和池化層,對特征圖進行8、16、32倍下采樣實現多尺度檢測,使得網絡的檢測準確度更高,同時加快了檢測速度。為了實現復雜場景下對工作人員是否佩戴安全帽的實時檢測,2019年林俊等[17]提出將YOLOv3應用于安全帽檢測,針對未佩戴安全帽單類檢測問題,修改分類器,將輸出修改為18維度的張量,將YOLOv3在ImageNet上進行預訓練得到預訓練模型,然后再在自制數據集上進行訓練并優化調參,最終得到的安全帽檢測模型檢測準確率可達98.7%,平均檢測速度達到了35 frame/s,滿足實時性的檢測要求。總體來說采用YOLOv3 算法作為安全帽檢測的基礎,通過在自制數據集上進行訓練,獲得一個最優的模型,并對作業人員安全帽佩戴情況進行有效的檢測,該方法的檢測準確率大多超過了90%,滿足實際需求。雖然YOLOv3 提升了對小目標安全帽的檢測效果,但對一些人員密集環境下重疊安全帽檢測仍然存在漏檢、錯檢的問題。2020 年Bochkovskiy 等[18]提出YOLOv4,該算法提高了對重疊安全帽檢測性能,并且在檢測速度和檢測準確率平衡方面優于之前的YOLO系列算法,更適用于安全帽檢測任務。與YOLOv3 相比,雖然平衡了模型的檢測精度和速度,但YOLOv4 的模型尺寸大,檢測速度要慢,且無法將其應用于小型設備中。2021 年朱夏晗瀟[19]提出一種基于YOLOv4 的安全帽應用檢測方法。先通過機器人進行視頻數據采集,再經過訓練好的YOLOv4模型判斷頭部和安全帽位置,之后判斷出行為人是否佩戴安全帽。通過在自制的數據集上進行訓練測試,網絡模型的平均精度均值可達91.7%,分別比Faster R-CNN和YOLOv3提高了7.2%和4.1%。YOLOv5沿用了YOLOv4的網絡結構,同樣采用了Mosaic數據增強方法,采用自適應錨框,檢測速度很快,集成了YOLOv3 和YOLOv4 的部分特性,檢測速度遠超YOLOv4,有多種網絡結構,具有更高的靈活性。為了實時監控相關人員是否佩戴安全帽,2021年Yi等[20]采用YOLOv5 目標檢測算法檢測復雜場景中作業人員安全帽佩戴情況,可以準確檢測處于運動狀態中的作業人員,對于遮擋的安全帽也有很好的檢測效果,檢測準確度達到了92.4%。但將YOLOv5 模型應用于小型的嵌入式安全帽檢測設備中,還需對YOLOv5模型的網絡結構做進一步改進。目前,YOLO系列安全帽檢測算法的應用比較廣泛,由于YOLO算法的更新,其中YOLOv3及YOLOv4在安全帽檢測領域最為常見。
由于單階段安全帽檢測算法不需要預先生成候選區域,直接對圖像的各個位置進行分類和回歸,檢測速度較兩階段安全帽檢測算法有所提升,但同時也損失了檢測精度。雖然YOLO系列算法經過一步步的更新,對小目標安全帽檢測效果有所提升,尤其是在檢測速度方面有顯著的進步,但是針對遮擋、光線變化環境中的小目標安全帽的檢測準確度還是不高。SSD 安全帽檢測算法則平衡了兩階段檢測算法檢測精度高但檢測速度慢,和YOLO系列算法檢測速度快但對小目標安全帽檢測效果不佳的問題。
2.2 SSD安全帽檢測算法
2016 年Liu 等[21]提出SSD(single-shot multibox detector)算法,該算法結合了Faster R-CNN和YOLO的思想,采用修改的VGG作為骨干網絡,有效地運用多尺度特征圖預測的思想,可以有效地檢測到相對較小的目標,檢測速度方面可以和YOLO 相媲美,檢測準確度方面可以和Faster R-CNN相媲美。SSD算法可以很好地解決安全帽檢測中背景復雜且干擾性強和待檢測目標較小的問題。但隨著SSD算法復雜度增加,檢測速度也會大幅度下降,難以應用于檢測速度要求較高的安全帽檢測任務,并且算法模型難以應用到儲存和計算能力有限的嵌入式設備中。在現有的SSD安全帽檢測算法中,研究人員大多是將改進的SSD 算法應用在安全帽檢測任務中。
2.3 新型的單階段安全帽檢測算法
除了上述單階段目標檢測算法之外,一些新型的單階段目標檢測算法也逐漸運用到了安全帽檢測任務當中。2017 年Lin 等[22]提出的RetinaNet 指出了正負樣本不平衡的問題是導致單階段目標檢測算法的檢測準確度普遍低于兩階段目標檢測算法的原因,采用加權的交叉熵損失函數,稱為焦點損失(focal loss,FL),可以減少正確檢測框的損失。該算法基于ResNet和特征金字塔網絡(feature pyramid networks,FPN)[23]構建特征提取網絡,實現了多尺度檢測,達到了與兩階段目標檢測算法相當的檢測準確度,同時保持了檢測速度。2021年王雨生等[24]提出一種基于姿態估計的安全帽佩戴檢測方法。使用RetinaNet 檢測頭部區域安全帽的佩戴情況,解決了安全帽與復雜施工場景類極不平衡的問題,網絡模型的平均精度均值可達97.1%,分別比Faster RCNN 和YOLOv3 提高了9.53%和2.8%,但檢測速度要遜于YOLOv3。2019年Duan等[25]提出的CenterNet針對CornerNet[26]不能很好地參考被檢測對象全局信息而產生部分誤檢的問題,在CornerNet 的基礎上增加了感知視覺模式,通過中心點池化來預測對象的中心點,通過判斷檢測框的中心區域是否有預測的中心點來消除錯誤的檢測框,提高了檢測準確度,但難以解決兩個不同的重合中心點的問題,對重合安全帽檢測效果差。2020年Tan 等[27]提出了EfficientDet,該算法由特征提取網絡EfficientNet 和面向多目標檢測的加權雙向特征金字塔網絡構成,解決了網絡的深度、寬度和分辨率值檢測不平衡問題,提高了生成模型的泛化能力。該算法的網絡結構可以實現多尺度的特征融合,對小目標安全帽的檢測起到了顯著作用,但由于網絡模型的復雜度增大,使得檢測速度有所降低。2020 年梅國新等[28]提出了基于EfficientDet 的用于檢測邊緣環境下面向復雜監控視頻背景的安全帽檢測算法。通過在SHWD公開數據集上進行訓練測試,網絡模型檢測平均精度均值最高可達92%,比YOLOv3提高了20%,檢測速度達到15 frame/s,但檢測速度比YOLOv3 要低。EfficientDet 模型克服了檢測目標存在明顯遮擋、重疊度高和圖像分辨率低的問題,取得了比較好的檢測效果,同時模型所占空間較小,為模型部署在邊緣計算環境上提供了可能,但在檢測速度方面還有較大的提升空間。其他未改進的單階段安全帽檢測算法的具體應用見表1。
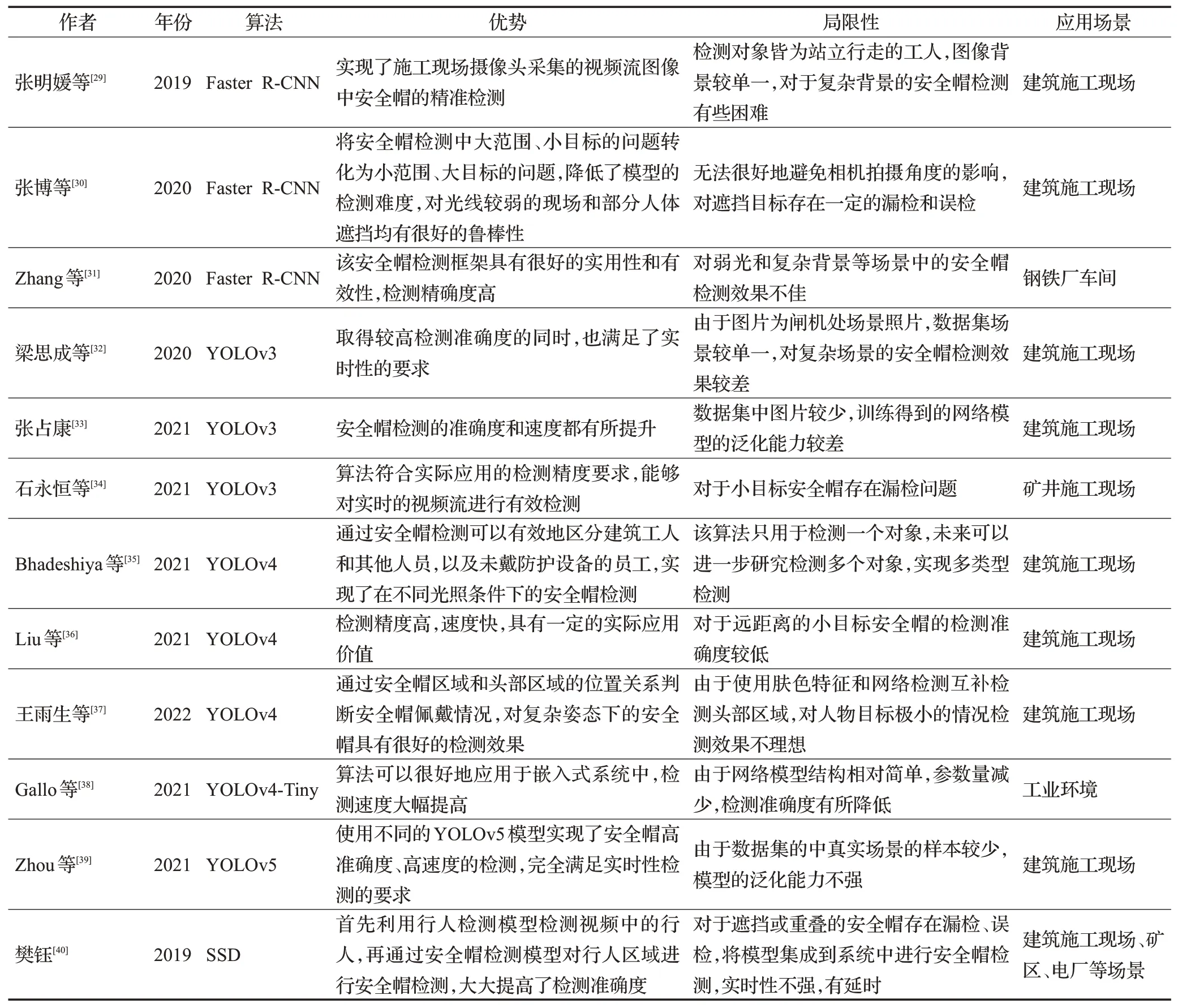
表1 無改進的基于深度學習的安全帽檢測算法Table 1 No improved helmet detection algorithm based on deep learning
3 基于深度學習的安全帽檢測算法的改進及應用
僅僅將原始的基于深度學習的目標檢測算法應用于安全帽檢測任務中具有一定的局限性,研究人員提出了一系列的改進方法。具體方法包括:優化Anchor Box、優化骨干網絡、特征融合、引入注意力機制、優化非極大值抑制算法、引入在線困難樣本挖掘策略和優化損失函數等。
3.1 優化Anchor Box
優化Anchor Box[41]也就是對錨點數量或錨點尺寸的調整,在基于深度學習的兩階段安全帽檢測算法和單階段安全帽檢測算法中都使用了優化Anchor Box的改進方法。兩階段安全帽檢測算法中RPN的錨點數量是網絡中的一個超參數,直接影響后續候選區域的生成。由于在安全帽檢測任務中,需要檢測安全帽、人員等多個目標,尤其是向安全帽這種局部的目標檢測,小目標是無法避免的,網絡默認的錨點參數較大,無法對小目標安全帽進行很好的識別,因此需要對網絡默認的參數進行修改或增加。通過優化Anchor Box的改進方式可以有效地解決安全帽檢測算法對部分遮擋、尺寸不一和小目標存在檢測難度大的問題。2020 年徐守坤等[42]提出了一種改進的Faster R-CNN安全帽檢測算法。針對施工現場安全帽檢測任務中的小目標,在網絡默認錨點數量的基礎上,加入了一組64×64 錨點,使得網絡可以檢測到更多的小目標安全帽。原始的Faster R-CNN使用9 個錨點,而改進之后錨點數量增加到了12 個,分別對應64×64、128×128、256×256 和512×512 這四個尺度大小。通過在自制的數據集上進行訓練測試,檢測精確度提升了0.79%。該改進方法增強了網絡檢測不同尺寸目標的魯棒性,通過增加錨點數量和修改錨框的尺寸,使RPN 得到可以覆蓋安全帽佩戴檢測所有尺寸的目標框,提高了安全帽的佩戴檢測精度,對多尺寸目標和小目標均有較好的檢測效果,但由于人員的姿態有所不同,此模型只能粗略地選取安全帽的相對位置,泛化性不高。在單階段安全帽檢測算法中采用的是K-means聚類算法[43]對安全帽數據集進行聚類分析,對目標框的大小進行分類,輸出先驗框的尺寸,從而達到優化網絡內部初始錨框的目的。由于在安全帽檢測任務中收集的安全帽數據集有所不同,原網絡結構中的錨框尺寸參數不能滿足安全帽數據集的檢測要求,這就需要對安全帽數據集重新進行聚類,選擇合適的先驗框。針對施工現場遠景視野下安全帽目標較小的特點,常增加特征圖尺度個數,再進行聚類得到先驗框的尺寸。2021 年鄭曉等[44]設計實現了一種基于深度學習的安全帽檢測智能監管系統,系統采用YOLOv4 目標檢測模型,在數據集上使用K-means算法聚類分析生成新的先驗框,并使用新的先驗框進行訓練。該模型的檢測精度可達92%,大大提高了工程現場的生產安全系數和監管效率,但在實際應用當中,對數據集進行聚類分析得到的先驗框尺寸不滿足待檢測的安全帽的大小,導致對小目標安全帽的檢測效果較差。
由于使用的安全帽檢測數據集有較大差異,除了采用原模型中K-means聚類算法在新數據集上重新聚類得到先驗框的尺寸之外,還可以對聚類算法進行優化改進,應用到安全帽檢測算法中,得到更加精確的先驗框的尺寸大小,進而達到優化Anchor Box的目的,提高模型的檢測效果,優化聚類算法是優化Anchor Box 的一種有效方式。然而對于密度不均勻的安全帽檢測數據集,聚類效果不是很好。原始的K-means聚類算法,是隨機選取數據集中K個點作為聚類中心,這種隨機選取的方式導致聚類得到的先驗框的尺寸不夠準確。2021年孫世丹等[45]對網絡模型中的聚類算法進行優化,使用加權核K-means聚類算法對訓練數據集聚類分析,選取更適合小目標檢測的Anchor Box,提高了檢測的平均精度和速度。改進之后的網絡模型檢測的平均準確率可達到93.5%,比原YOLOv3 提高了7.6%,檢測速度達到45 frame/s,但該算法的改進同樣是針對安全帽檢測數據集的聚類分析,對于現實中的安全帽并不完全適用,對極端大小的安全帽存在漏檢、誤檢問題。
優化Anchor Box的改進方式僅僅是通過對安全帽圖像中的目標框進行尺寸判斷,進而細化特征圖中的錨框,從而提高了對安全帽的檢測效果,但對小目標的檢測效果有限,要想真正地提高檢測性能,需對骨干網絡進行改進或替換,提高模型的特征提取能力,使小目標在特征圖上更好地表達出來,從而提升模型的檢測準確率。
3.2 優化骨干網絡
骨干網絡(backbone)作為目標檢測模型中的特征提取器,特征提取的效果往往直接影響目標檢測的性能。兩階段目標檢測中常見的骨干網絡有SPPNet[46]、VGG-Net[47]和ResNet[48]等。原始Faster R-CNN 算法的骨干網絡為VGG,它采用頂層特征做預測會導致底層的位置信息丟失,對深層次的特征信息學習能力不足,降低模型對小目標安全帽的檢測準確度,提高特征提取能力需要更多的網絡層數,但增加網絡層數會加大模型損耗。RestNet網絡可以很好地解決由于卷積層加深而導致的模型退化的問題。在安全帽檢測任務當中,研究人員通過優化骨干網絡,采用ResNet代替原來的VGG-Net,從而達到很好的檢測效果。為了解決Faster R-CNN算法在對小物體檢測性能方面魯棒性差的問題,2019年周展博[49]摒棄了原始的VGG-16 基礎網絡,提出將101 層堆疊的殘差學習模塊組成的ResNet-101 網絡作為新的基礎網絡。該改進方法提升了安全帽佩戴的檢測精度,但由于采用更深網絡結構的ResNet以達到更好的檢測準確度,網絡模型的復雜性更高,在檢測速度上未達到實時性級別。
除了兩階段目標檢測算法中常用的VGG、ResNet和SPPNet 骨干網絡之外,單階段目標檢測算法還用到了MobileNet[50]、DenseNet[51]等。YOLO系列算法采用層數結構不同的DarkNet 來提取特征,網絡結構變得復雜,參數量也會隨之增加,導致檢測速度慢,內存消耗大且對硬件性能要求很高的問題,不利于安全帽的實時性檢測。深度可分離卷積網絡將區域和通道分開計算,并且對不同的通道進行獨立卷積操作,可以大大減小模型的參數量和運算量,得到一個輕量化的模型。2020年朱曉春等[52]提出了改進的基于YOLOv3 的安全帽檢測算法,通過深度可分離卷積對DarkNet 網絡結構進行改進,優化了骨干網絡,減少了模型的參數量,相對于標準卷積運算,降低了模型的計算量,網絡結構如圖2 所示。該改進算法的檢測準確率可達89.67%,檢測速度為105 frame/s,檢測速度提高了兩倍,但由于模型參數量的減少,網絡結構相對簡單,并沒有提高模型的檢測準確率。
圖2 網絡結構Fig.2 Network structure
實際安全帽檢測環境下需要把網絡模型部署在算力有限的移動端或嵌入式設備中,但將體積偏大的原YOLOv5模型嵌入到設備中,會導致設備無法支持復雜的計算量的問題。2021 年蔣潤熙等[53]提出了一種適合部署在移動設備上的輕量級目標檢測網絡HourGlass-YOLO(HG-YOLO)。該算法以YOLOv5 為基礎模型,重構了新的骨干網絡來替換原骨干網絡,并使用了通道剪枝技術,在保證精度的情況下,減少了模型的參數。通過在公開數據集SHWD 上進行訓練測試,網絡模型的平均精度均值可達94.4%,雖然檢測準確度不如原YOLOv5模型,但檢測速度達到9.5 frame/s,參數量達到了最少,可以更好地將算法部署在低端設備,然而由于融合卷積層與批量歸一化層,減少了網絡層數和參數量,使得模型對小目標安全帽的檢測會出現漏檢情況。VGG作為SSD的基礎網絡對SSD算法的檢測性能有重要影響,MobileNet網絡在參數量、計算量和訪存量上都要比VGG 小得多,因此在一些特別的安全帽檢測任務中,MobileNet 更加適合。針對在安全帽檢測任務中SSD 模型在不使用GPU 加速時檢測速度緩慢、內存消耗大以及計算復雜度高的問題,2020年張麗[54]引入輕量型MobileNet來替換SSD中的VGG網絡,網絡模型檢測速度比原SSD 提高了兩倍。改進的SSD 安全帽檢測算法大幅度提高了檢測速度,但其精度卻有所損失,因此,在檢測速度加快的同時保持檢測精度還需要進一步的研究。
雖然優化骨干網絡后的檢測精度得到了大幅提升,但目前骨干網絡仍存在模型復雜等問題,施工現場安全帽檢測大多面臨復雜背景環境,僅僅替換骨干網絡對安全帽小目標的特征提取能力還是不足。如果說優化骨干網絡屬于從大結構上來改進網絡模型,從而提高特征提取效果,那么特征融合則屬于從細節上進一步提高模型的特征提取性能。
3.3 特征融合
基于深度學習的目標檢測算法一般關注的是中、大目標,利用卷積神經網絡提取深層次的特征,具有很好的檢測性能。但對于安全帽檢測任務中的小目標,深層卷積神經網絡的尺寸小且感受野較大,使得小目標會被漏檢,淺層卷積神經網絡雖然感受野小,但目標特征不強,置信度較低,在檢測過程中也會被舍棄。特征融合就是將深層和淺層的卷積特征進行融合,使得產生的候選區域特征同時具有高分辨率特征圖的位置信息和低分辨率特征圖的語義信息,再由RPN 網絡分別預測達到多尺度檢測的目的,從而提高網絡對小目標的檢測能力。但是僅僅采用特征融合的方法都會損失一定的檢測速度,研究人員有時會將特征融合方法與其他改進方法配合使用以達到最好的檢測效果。2020年吳冬梅等[55]提出了一種基于改進的Faster R-CNN的安全帽佩戴檢測及身份識別方法,通過將骨干網絡中的5個網絡階段的特征圖進行融合,如圖3 所示,并將多尺寸的特征圖分別輸入到RPN網絡中,完成特征融合和多尺度檢測,改進之后的網絡的平均精度均值比原模型提高了16.8%。該改進方法在安全帽特征提取時能充分利用所有特征層信息,大大提升了安全帽檢測效果,但由于進行了5個階段的特征融合,增加了模型的復雜度,使得模型的檢測速度有所降低。針對施工現場作業場景的復雜環境,由于工人所佩戴的安全帽在圖像中所占的像素較少,導致使用卷積神經網絡提取的特征質量不高,極大地影響了檢測模型的檢測精度。2021年Jin等[56]采用基于特征融合的Faster R-CNN 算法實現了工人安全帽佩戴檢測,利用特征映射融合方法獲得特征信息更豐富的特征映射,然后利用特征映射對檢測模型進行訓練,檢測準確率可達96%,能有效地檢測出工人安全帽佩戴情況。

圖3 特征融合金字塔Fig.3 Feature fusion pyramid
在單階段安全帽檢測算法中,采用特征融合使得網絡可以得到包含豐富位置信息和語義信息的特征,獲得不同尺度的特征圖,從而提高網絡模型對小目標的檢測準確度,增強網絡的魯棒性。針對安全帽檢測場景中環境復雜、光照不均勻等各類環境問題,2019 年何超[57]通過對YOLOv3算法進行改進,提出了一種新的特征融合算法,其主要網絡結構是深度殘差網絡,在YOLOv3 的主網絡之后又增加了1個卷積層,并同淺層的殘差網絡做特征融合,從而將網絡從3 個尺度擴展為4 個尺度卷積層的特征金字塔,然后對特征金字塔進行2 倍上采樣,與前面的深度殘差網絡進行融合,形成深度融合的快速安全帽檢測模型。該網絡模型的平均精度均值可達93.61%,比原網絡提升了4.51%。但由于有些安全帽檢測中的背景較復雜,多尺度檢測利用高分辨率特征會引入過多的背景噪聲,容易造成模型收斂速度緩慢的結果。2021年肖體剛等[58]提出一種基于改進SSD的安全帽佩戴快速檢測算法。通過將SSD中的骨干網絡VGG-16替換為輕量型卷積神經網絡MobileNetV3-small,減少了模型的參數,同時使用特征金字塔結構將深層特征與淺層特征進行融合,提升了檢測精度,網絡模型的平均精確率可達91.1%,基于GPU的檢測速度為108 frame/s,該改進方法不論是檢測速度還是精度都優于原SSD算法。
采用特征融合的方式進行安全帽檢測能夠將安全帽特征圖中的深層特征和淺層特征結合起來,得到多尺度的特征,但特征融合使得特征之間的信息交互不完全,提取特征的相關性不強。而注意力機制通過分配不同的權重來獲得安全帽特征信息,具有很好的特征表達效果,使得提取的特征的相關性更強,更大程度地提高安全帽檢測性能。
3.4 引入注意力機制
安全帽檢測算法的特征提取環節尤為重要,在神經網絡中,注意力機制[59]是根據關注對象的重要程度進行不同的資源分配,注意力分配的資源也就是權重。在卷積神經網絡當中,卷積核是局部的,為了增大感受野,采用堆疊卷積層的方式將卷積核和原始特征進行線性組合得到輸出特征,但是這種方式的效率很低。引入注意力機制可以獲得全局信息并選擇出對當前任務目標更關鍵的信息,具有很好的特征表達效果,這就使得提取的特征的相關性更強,捕獲到更豐富的高級語義信息,進而提高檢測性能,但引入注意力機制后模型的參數量也會隨之增加,加大網絡的計算量,進而降低模型的收斂速度。2022 年孫國棟等[60]提出了一種基于Faster RCNN的融合注意力機制的安全帽檢測算法。該算法通過自注意力層來捕獲多個尺度上的全局信息,得到更豐富的高層特征并將更大的感受野范圍引入模型,采用ResNet-101 代替原來的VGG-16 骨干網絡,同時采用錨點補選增強的方法,強化了網絡對小尺度目標的表達能力。改進之后的網絡模型的平均精度均值可達94.3%,比傳統的Faster R-CNN提高了6.4%。引入注意力機制的改進方法對不同施工現場的安全帽檢測任務有著較好的檢測效果,但采用注意力機制需要矩陣來存儲注意力權重,增大模型的參數量,檢測速度有所降低。引入注意力機制的改進方法同樣適用于單階段目標檢測算法,自注意力模塊通過計算輸出特征圖每個像素點之間的相互影響,改變每個網絡層之間的感受野,從而讓網絡在向前傳播的過程中感受野不斷增加,使得檢測算法具有全局性和可靠性。施工現場的復雜環境中存在的弱小目標與遮擋目標大多難以得到有效檢測,針對該問題,2021年李天宇等[61]在YOLOv3的基礎上建立了一種基于注意力機制的雙向特征金字塔的安全帽檢測卷積神經網絡。為了準確檢測戴安全帽的工人,減少網絡特征損失,引入了雙向特征融合的特征金字塔網絡PANet,提高了對弱小目標的定位準確性;為了減少遮擋目標被誤檢,在特征金字塔網絡的輸出部分引入了注意力模塊,網絡模型的平均精度均值可達91.96%,比原YOLOv3 提升了0.82%,檢測速度可達21 frame/s,能夠實現復雜環境下的安全帽精確檢測且滿足實時性要求,但由于模型的復雜度提高,影響了檢測速度。2020年黃勇[62]提出了融入自注意力的SSD 改進算法。通過Self-Attention模塊擴大了SSD算法的感受野,增強了算法的識別能力。通過在自制的數據集上進行訓練測試,網絡模型的檢測準確率可達71.7%,比原SSD提升了2.37%。該方法對安全帽的目標小、易形變以及堆疊的情況有很好的檢測效果。
通過優化Anchor Box、優化骨干網絡、特征融合和引入注意力機制的改進方法,一定程度上可以提升對安全帽小目標的檢測能力,但還是解決不了候選框被錯誤剔除的問題,對一些密集目標還是存在漏檢、錯檢。
3.5 優化非極大值抑制算法
非極大值抑制算法(non-maximum suppression,NMS)[63]的作用是在目標框篩選階段剔除部分冗余框,解決一個目標被多次檢測的問題。但NMS算法始終存在兩個問題:一是對于一些目標比較密集的檢測任務,在剔除部分冗余框的同時去掉了部分正樣本的檢測框,如圖4所示。二是NMS算法是將大于閾值的目標框直接剔除,但是一個合適的閾值是很難找到的。

圖4 NMS的缺陷Fig.4 Defects of NMS
因此,在一些安全帽檢測任務中,研究人員通過優化非極大值抑制算法來解決上述問題,進而提高安全帽檢測算法的檢測效果。具體優化算法包括Soft-NMS和DIOU-NMS等,該方法皆適合于解決較密集的安全帽檢測場景下因NMS過程中刪除高度重疊目標而造成安全帽漏檢的問題。2019 年金肖瑩[64]針對分布比較密集的安全帽目標,使用Soft-NMS[65]來替換后處理過程中的NMS,在不重新訓練模型的情況下提高了檢測的準確性。改進之后的網絡的精確度可達88.1%,比傳統的Faster R-CNN模型提高了9.5%。通過優化非極大值抑制算法之后的安全帽檢測算法在準確率和泛化能力上表現出了很好的性能,但由于本身是兩階段的算法,即使提高了檢測準確度,其檢測速度還是較低,仍無法解決檢測速度要求較高的安全帽檢測問題。針對YOLOv5算法檢測小目標時存在的漏檢和模型收斂速度慢的問題,2021 年Tan 等[66]增加檢測規模,并使用DIOU-NMS代替NMS,利用DIOU-NMS 在對候選框進行剔除的同時考慮了重疊區域和兩個目標框的中心距離的優點,提高了模型對小目標的檢測準確度,模型的檢測準確度可達95.68%,檢測速度達到98 frame/s,但由于YOLO系列算法網絡檢測目標的局限性,對嚴重遮擋安全帽仍存在一定程度的漏檢、錯檢。2020 年邱浩然[67]針對安全帽位置中存在的遮擋和重疊情況,使用Soft-NMS 代替YOLOv3中的NMS算法,提高了模型的檢測效果。
以上五種改進方法在兩階段安全帽檢測算法和單階段安全帽檢測算法中都比較常見,為了達到最好的檢測效果,研究人員常常把多種改進方法結合起來使用,從而在最大程度上提高對安全帽佩戴的檢測效果。除了上述改進方法,兩種基于深度學習的安全帽檢測算法還有各自的改進方法,進一步提升了安全帽檢測算法的檢測性能。更多相關改進的安全帽檢測算法見表2。

表2 (續)
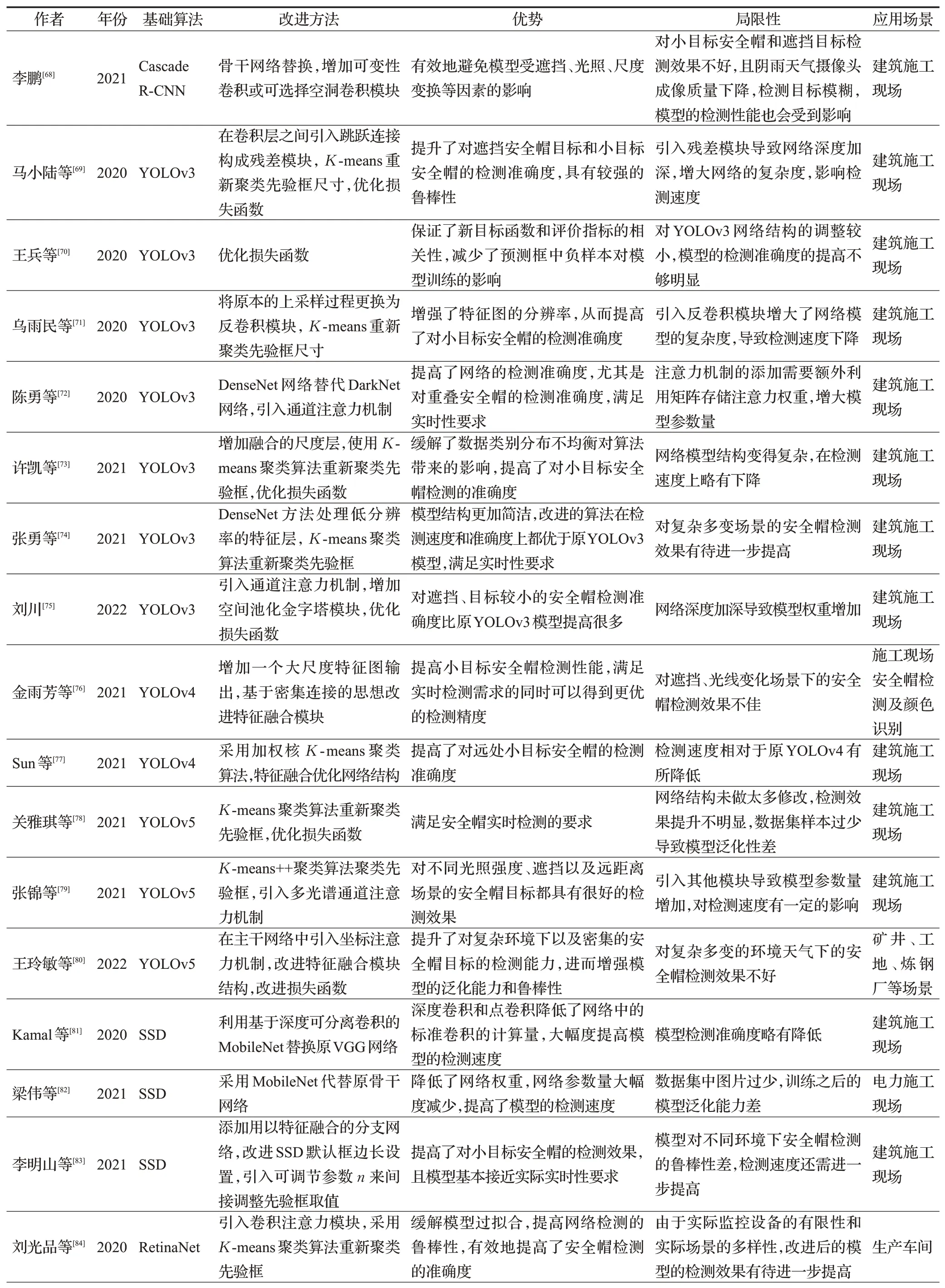
表2 改進的基于深度學習的安全帽檢測算法Table 2 Improved helmet detection algorithm based on deep learning
3.6 引入在線困難樣本挖掘策略、優化損失函數
在兩階段安全帽檢測算法中,通過引入在線困難樣本挖掘策略,解決了兩階段安全帽檢測算法隨機挑選正負樣本并設置比例導致樣本存在大量無效樣本,以及模型參數更新緩慢導致檢測效率低的問題。在線困難樣本挖掘策略[88]通過自動挖掘損失較高的樣本而不需要人為設定正負樣本比例,這樣有針對性地學習訓練,提高了模型的訓練速度和檢測準確度,但在安全帽檢測中由于安全帽檢測數據集本身的問題,無法覆蓋各種場景的安全帽樣本。2020 年王慧[89]針對安全帽數據集中難易樣本、正負樣本不均衡使得網絡后期損失較高的問題,將在線困難樣本挖掘機制引入到特征融合后的FasterR-CNN。改進之后的網絡模型的平均精度均值可達93.3%,比原模型提高了1.8%,在線困難樣本挖掘策略能夠挖掘損失較大的困難樣本,進行針對性的訓練,增強模型背景分辨能力的同時降低了漏檢率,但只是基本滿足實際應用中的精度要求,對小目標安全帽和遮擋安全帽的檢測準確度還有待提高。2020 年徐守坤等[90]在原始Faster R-CNN的基礎上使用多層特征融合技術優化區域建議網絡產生首選區域特征圖,使用在線困難樣本挖掘技術訓練ROI網絡,自動挑選出困難樣本使訓練更加有效,提高了對部分遮擋和小尺寸目標的檢測效果,對環境變化也有很強的適應性。引入在線困難樣本挖掘策略提高了檢測效率,但采用多特征融合技術增加了模型的復雜程度和參數量,最終導致檢測速度有所降低。
在單階段安全帽檢測算法中,YOLOv3利用均方誤差(mean squared error,MSE)作為損失函數來進行目標框的回歸,利用均方誤差評價指標有時候并不能把不同質量的預測結果區分開來。比如說,在YOLOv3中采用交并比(intersection over union,IOU)來判斷模型是否檢測到目標,模型設定一個IOU 閾值,如果檢測目標的IOU 大于設定閾值,則會判斷為檢測到目標,反之則反。YOLOv3中回歸質量的評價采用IOU指標,但是對于IOU 值不同的檢測目標可能得到相同的MSE 損失值,如圖5所示。

圖5 相同MSE下的IOU值Fig.5 IOU value under same MSE
因此,以均方誤差作為衡量預測邊界框的回歸效果的損失值,不能與IOU 很好地聯系起來,從而影響了模型的檢測性能。2021 年韓錕等[91]針對損失函數與模型檢測效果不匹配的問題,使用基于GIOU的損失函數代替均方誤差損失函數,更好地匹配了算法損失函數與目標檢測評價之間的關系,網絡模型檢測的平均精度均值可達93.84%,比未改進損失函數的模型提高了2.57%。改進的模型對多樣化場景、多尺度目標具有很好的魯棒性,但沒有考慮到天氣對圖像成像質量的影響,雨雪、霧霾天氣會造成攝像頭成像質量下降,檢測目標模糊,模型的檢測性能也會受到影響。在安全帽檢測的實際應用場景中,輕量級算法YOLOv3-Tiny 由于參數數量較少,易于在嵌入式設備中部署,但其檢測精度較低,不適合檢測小目標安全帽。2021 年Cheng 等[92]構造了一種基于深度可卷積和通道注意機制的輕量級模塊來代替原有的卷積層,在減少參數和計算量的同時,獲得了更多的特征信息,采用CIOU 損失函數代替原損失函數,提高了對小目標的檢測效果,與原模型相比,提高了檢測精度,檢測準確率可達81.6%,但損失了檢測速度。為了解決基于深度學習的安全帽檢測方法因結構復雜和計算量大而難以應用到嵌入式設備中的問題,2022年農元君等[93]以YOLOv3-Tiny檢測網絡為基礎,通過優化網絡結構,引入空間金字塔池化模塊豐富特征圖的多尺度信息,采用K-means聚類算法重新優化錨框,最后引入了CIOU 邊界框回歸損失函數提高了檢測精度。該改進方法在光線不佳、小目標、密集目標等復雜施工環境下具有良好的適應性和泛化能力,但該改進方法為了滿足嵌入式平臺的需要,降低了網絡參數,減少了運算量,使得檢測準確度比YOLOv3要低。
優化損失函數的改進方法彌補了IOU 損失函數的不足,解決了當檢測框與真實框沒有重合部分時,梯度不存在而無法進行梯度下降優化的問題。但優化損失函數并不是每次都能達到最好的訓練結果,損失函數的選擇還得依安全帽檢測的實際情況而定。
3.7 改進算法模型適應能力的其他方法
在對基于深度學習的安全帽檢測算法研究中,除了上述的改進方法之外,研究人員還通過引入其他網絡、模型壓縮、遷移學習、數據增強以及選擇合適的優化器的方法,進一步提高模型的適應能力。
3.7.1 引入其他網絡——提高安全帽檢測準確度
在將單階段目標檢測算法運用到具體應用中時,通常也采用與其他網絡相結合來改進網絡模型的方法。這種改進方式使得原網絡融合了其他網絡結構的優勢,提高模型的泛化能力。2021 年鐘鑫豪等[94]提出了一種基于改進Tiny-YOLOv3 算法的安全帽佩戴檢測模型,在該算法的原網絡中加入殘差網絡模塊,避免了小目標的特征隨著網絡的加深而導致梯度消失的問題,提高了小目標的檢測準確率。網絡模型檢測的平均精度均值比原模型提高了4.1%,檢測速度基本與原模型相當。雖然檢測精度和速度得到了均衡,但與YOLOv3等大型檢測網絡相比,小目標安全帽的檢測準確度還有待提高,且增加殘差網絡模塊影響檢測的實時性。在安全帽檢測中,有些檢測對象較小,由于其在圖片中所占的像素較小,使得在特征提取時會造成特征信息的丟失。針對該問題,2021 年曹燕等[95]將Conv-LSTM 引入到SSD 模型中,改進后的模型可以將高特征信息層與低特征信息層分開,使得小目標信息特征可以充分利用,提高了對小目標檢測的檢測效果,但由于在SSD網絡的基礎上增加了Conv-LSTM模塊,網絡的復雜度提升,降低了檢測速度。
3.7.2 模型壓縮——提升安全帽檢測速度
模型壓縮主要是在保持網絡精度的前提下,減少模型參數,從而實現模型的壓縮,提高模型的檢測速度。模型壓縮最常用的三種方法是參數量化[96]、模型蒸餾[97]、模型裁剪[98]。為了增加模型的可用性,2019年方明等[99]以YOLOv2 目標檢測方法為基礎,借鑒了密集連接網絡思想,在原網絡中加入密集快實現特征融合,利用MobileNet 中的輕量化網絡結構對網絡進行壓縮,縮減了網絡,大大提高了檢測速度,改進之后的網絡模型的檢測速度可達148 frame/s,檢測精度達到87.42%。該改進方法減少了模型的參數量,增加了模型的可用性,但由于縮減了網絡結構,模型對安全帽檢測的準確度有待提高。2021年趙紅成等[100]提出了一種新型輕量的安全帽佩戴檢測模型,通過優化骨干網絡,將原始YOLOv5s主干網絡更改為MobileNetV2,通過對模型進行壓縮,在BN層引入縮放因子進行稀疏化訓練,采取模型裁剪方法進一步減少模型推理計算量,最后通過模型蒸餾進行微調得到了YOLO-S。改進的網絡模型的檢測平均精度可達92.1%,比原模型提高了1.4%,浮點數為YOLOv5s 的1/3,推理速度比其他模型快,可移植性高。模型壓縮降低了模型的參數量,顯著提升了檢測速度,為將安全帽檢測算法模型應用于嵌入設備提供了可能,但是損失了一定的檢測準確度。該方法需要和其他方法結合使用,從而平衡檢測速度和檢測準確度。
3.7.3 遷移學習和數據增強——解決安全帽數據集規模小的問題
在安全帽檢測任務中,往往在自制的數據集上進行模型訓練,為了克服數據不足造成的缺陷,通常也采用遷移學習和數據增強。遷移學習[101]是將網絡中每個節點的權重從一個訓練好的網絡遷移到另一個全新的網絡。在安全帽檢測任務中,安全帽數據集的樣本數量是訓練網絡性能的限制因素,神經網絡訓練的數據集數量往往需要達到如ImageNet[102]的量級才能有效地避免網絡過擬合。針對安全帽數據集規模小的問題,使用遷移學習策略能夠加快安全帽檢測模型的訓練速度,增強模型的泛化能力。為了解決安全帽數據集規模小導致網絡難以充分擬合特征的問題,文獻[103-104]采用遷移學習策略克服模型訓練困難問題,加快了安全帽檢測模型的訓練速度。在網絡的訓練階段,改進數據增強的方法在擴充數據集的同時還可以增加樣本中小目標的數量。2021年趙春暉等[105]提出基于改進YOLOv3的安全帽檢測算法,在訓練階段利用目標可占比數據增強方法,增加了小目標的數量,同時在網絡中引入了多尺度特征池化模塊,使得網絡對不同尺度的目標更加敏感。該改進方法的平均精度可達88.63%,比原YOLOv3 提升了1.54%,但改進方法僅提高了對小目標安全帽的檢測精度,對于遮擋的安全帽目標檢測有待進一步研究,并且模型引入多尺度模塊,使得網絡參數量增加,影響了模型的檢測速度。針對不平衡數據集導致模型檢測精度下降的問題,2021 年Geng 等[106]在YOLOv3 目標檢測算法的基礎上,采用基于加權的高斯模糊數據增強方法對不平衡數據集進行預處理,對YOLOv3 算法進行改進,檢測準確度可達98.2%。但由于通過高斯模糊數據增強方法對圖像進行處理時,圖像離被處理對象越近,其對該像素的影響就越大,然而使用加權平均之后,每個像素使用周圍像素的平均值,這就導致了圖像中點丟失特征細節,影響了之后模型的檢測準確度。
3.7.4 選擇合適的優化器——優化檢測效果
神經網絡中的優化器是用來更新和計算影響模型訓練和模型輸出的網絡參數,使其達到最優值。一個合適的優化器可以加快網絡模型的收斂速度,減少訓練時間。2020年張業寶等[107]提出基于改進SSD的安全帽檢測方法。采用Adam 優化器實現訓練過程中神經網絡的快速收斂,同時對網絡進行遷移學習,加快了訓練過程并減少了對數據量的需求,提高了網絡模型的檢測準確度,但檢測速度較原SSD 算法提升不夠明顯,有待進一步研究。在基于深度學習的目標檢測算法中,都會有符合算法的優化器,但是在安全帽檢測任務中,有時候通過更換優化器會有意想不到的效果。
以上對提升安全帽檢測模型適應能力的有關方法進行了總結,更多采用提高模型適應能力方法的安全帽檢測算法見表3。
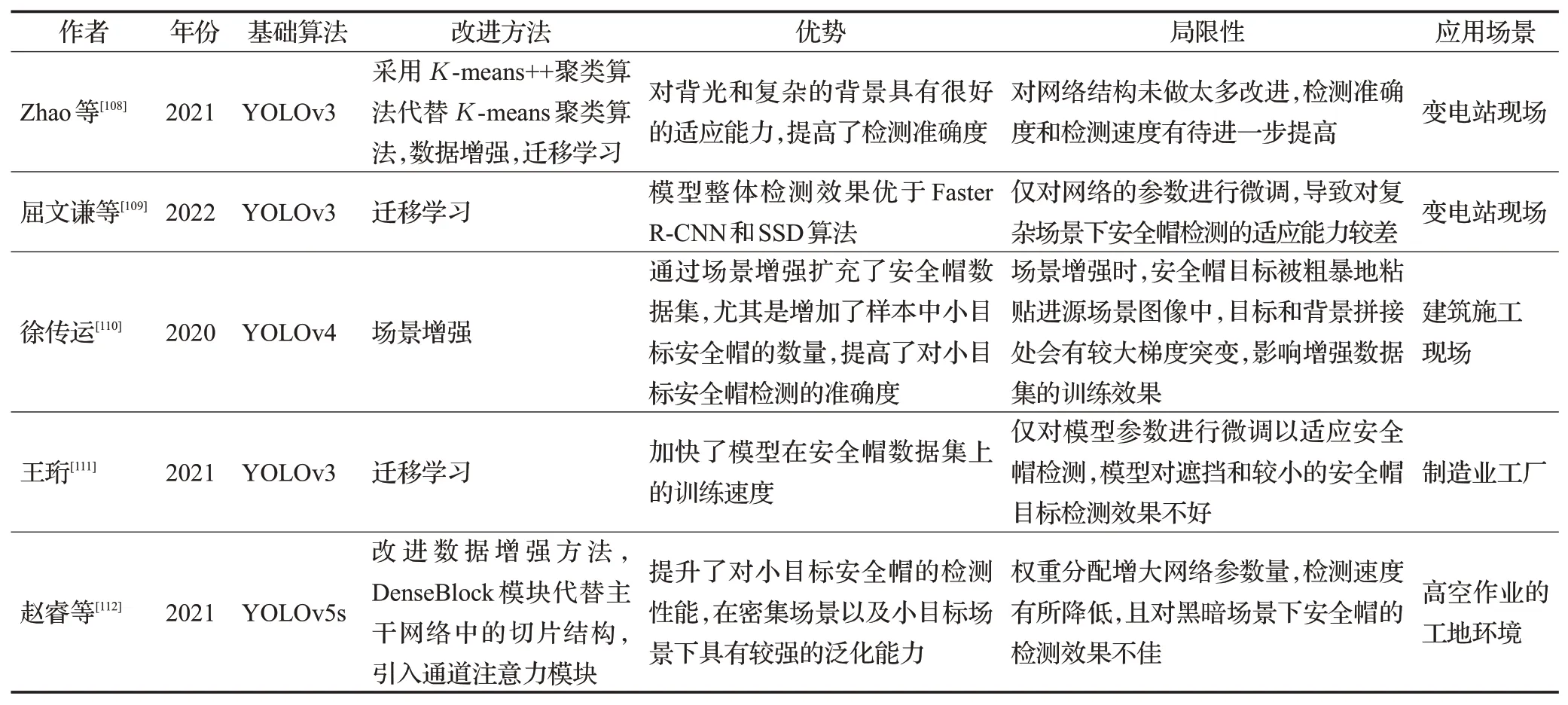
表3 改進的增強模型適應能力的安全帽檢測算法Table 3 Improved helmet detection algorithm to enhance adaptability of model
4 總結與展望
本文深入分析了近年來基于深度學習的目標檢測算法在安全帽檢測領域的研究,總結了安全帽檢測方法的種類,詳細闡述了兩階段安全帽檢測算法和單階段安全帽檢測算法及其具體改進方法,為智能建造技術領域相關科研人員提供借鑒與思路。當前安全帽檢測算法雖然已取得了一定的成果,但將其使用在未來智能建造平臺或智慧工地的應用維度上還需繼續努力研究。以下提出當前研究過程中的一些問題或建議,同時給出未來發展方向,供大家借鑒。
(1)目前安全帽檢測數據集還是太少,難以適應各種復雜場景下網絡模型的訓練要求。目前,大多數研究人員都是根據安全帽檢測的具體應用場景自行構建數據集。綜合分析施工現場安全帽數據集的圖片來源主要包括以下三個途徑:利用搜索引擎從互聯網上爬取圖片;從施工現場的監控視頻中截取視頻幀;通過攝像機在施工現場進行手工拍攝。未來,還需要研究人員針對安全帽檢測任務構建一套完備的數據集。
(2)安全帽檢測數據集中的小目標還是存在一定的誤檢、漏檢,這是安全帽檢測領域普遍存在的問題。針對該問題,除了本文提到的改進方法,還需在對安全帽的檢測當中充分利用小目標的區域特征,結合上下文信息增強對小目標的檢測。Transformer 已經在計算機視覺領域表現出很好的性能,主要運用了自注意力機制,Transformer應用于安全帽檢測任務可能會有很好的效果。
(3)安全帽檢測算法應用于嵌入式設備中還是有些困難。針對該問題,未來可以對輕量級網絡展開研究,采用模型壓縮、參數量化等方法減少模型參數量,使其可以應用于嵌入式設備中。
(4)由于攝像機位置角度不同使得數據集中存在遮擋目標,對這種情況同樣存在誤檢、漏檢。未來,隨著5G 網絡時代的發展和硬件技術的更新,智慧工地也會針對性地設計多樣化的視頻設備來降低誤檢、漏檢概率。
(5)人與安全帽的位置關系不好判斷的問題,模型不能很好判斷出作業人員是否正確佩戴安全帽。目前,智能建造技術領域已經將基于姿勢估計算法的工人關鍵點提取和基于多目標跟蹤算法的工人關鍵點跟蹤應用于工人施工狀態識別當中,盡管還不成熟,但是可以預計未來人與安全帽位置關系不好判斷的問題,可以通過關鍵點檢測算法和目標檢測算法相結合的方式來解決。
利用智能的方法實現施工現場實時監控,既節省人力成本,又提高施工現場安全性,更為我國智能建造平臺或智慧工地的發展奠定了良好的基礎。在安全帽檢測任務中,由于考慮角度不同,有的針對遮擋和小目標安全帽的問題,有的需要應用于嵌入式設備中,有的針對數據集中檢測目標不足的問題,有的則更注重模型的收斂速度,因此改進方法有所不同,將基于深度學習的目標檢測算法應用于安全帽檢測任務中,還需具體問題具體分析。未來,隨著深度學習的發展,將會有更多的研究成果應用于安全帽檢測領域中。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
