基于多重注意力引導的人群計數算法*
2022-08-23 06:49:16楊倩倩彭思凡殷保群
網絡安全與數據管理 2022年7期
楊倩倩,何 晴,彭思凡,殷保群
(中國科學技術大學 信息科學技術學院,安徽 合肥 230026)
0 引言
由于人群所在的位置和行動軌跡具有主觀性強、自由度高的特點,監控視頻采集的圖像包含大量雜亂分布的人群,不同局部區域的人群密度差異巨大,增大了人群計數算法的估計難度。如圖1所示,在同一人群場景中,多個局部區域表現為人口極度聚集,而部分區域人口稀疏甚至是孤立的個體,難以預測的行人位置將導致密度圖中不同位置的密度值之間存在巨大差異,對算法感知不同密度分布模式的能力提出了更高的要求。為解決上述問題,本文提出基于多重注意力引導的人群計數算法,將特征金字塔機制和注意力機制相結合,促進語義信息和空間細節的融合,并通過注意力圖引導模型生成對應不同分布狀態的密度圖。

圖1 人群非均勻分布圖像示例
1 概述
為解決計數問題中的非均勻分布問題,研究者主要設計了基于分類或檢測等輔助任務和注意力機制的計數方法,讓模型提取到各種分布模式下的全局和局部語義信息來識別分布在不同密集程度下的行人。CP-CNN[1]在多列密度估計框架的基礎上搭建了兩個額外的人群密度分類網絡,分別學習將輸入圖像或局部圖像塊按照密度差異分類為5個類別,以此來學習全局和局部區域的上下文信息,并將提取的上下文語義信息融合到密度圖估計任務中,從而生成高質量的人群密度圖。然而,該算法對全局或局部區域人數分類只能提取到粗糙的語義特征,復雜場景下需要細粒度的密度語義信息。Liu等人[2]認為在不知道每個行人具體位置的情況下,計數模型在低密度區域容易產生過估計現象。為了解決此問題,作者提出的Decidenet將檢測和回歸方法結合來處理不同密度區域的人群,能夠自適應地根據實際密度情況決定合適的計數方法,在低密度區域采用檢測方法估計人數,在擁擠區域則采用回歸方法捕捉人群信息。然而,采用的Faster-RCNN[3]等檢測網絡往往十分復雜,難以將其和密度圖回歸網絡以端到端的方式訓練,且訓練過程繁瑣。Jiang等人[4]指出在不同的密度模式的圖像區域中,數據驅動的計數算法容易出現過估計或欠估計。作者提出了一種基于注意力機制的人群計數算法,該網絡包括密度注意力網絡和注意力尺度網絡,后者給前者提供與不同密度區域相關的注意力信息,并采用尺度因子幫助縮小不同區域的估計誤差。然而,該模型由2個VGG-16[5]組成,網絡參數量過大并且結構較為復雜,同時需要對子網絡分別訓練,這些弊端導致該模型訓練困難且不利于計數性能的提升。
針對以上問題,本文提出一種基于多重注意力引導的人群密度估計算法(Multi-Attention Convolutional Network for Crowd Counting,MACN)來完成密度圖回歸任務,采用多重注意力機制指導網絡提取多種分布模式下的人群特征,改善不同密集程度下的密度圖質量,從而提升人群計數算法的整體性能,主要包括特征提取模塊(Feature Extraction Module,FEM)、特征融合模塊(Feature Fusion Module,FFM)、上下文注意力模塊(Context Attention Module,CAM)和密度圖生成模塊(Density Map Generation Module,DGM)。
2 密度估計網絡結構設計
針對復雜場景中存在的人群非均勻分布問題,設計了一個端到端的計數網絡來實現密度圖估計,采用注意力機制獲取像素級別的語義信息來指導密度圖回歸任務,感知不同分布模式下的行人,具體結構如圖2所示。

圖2 MACN結構
2.1 特征提取模塊
VGG-16具有強大的特征提取能力和優秀的遷移學習能力,采用小卷積核代替大卷積核,能夠在保證特征表達能力的同時不消耗過多計算資源,所以采用VGG-16的前13個卷積層作為特征提取模塊,根據池化層位置進一步分5個子模塊,其具體配置如表1所示。

表1 FEM網絡結構
2.2 特征融合模塊
Lin等人[6]在目標檢測系統Faster R-CNN中引入了特征金字塔結構(Feature Pyramid Network,FPN),它是一種包含自下而上路徑、橫向連接和自上而下路徑的特征融合機制,能夠充分融合來自網絡中間不同層次的特征。Zhang等人[7]提出一種輕量化金字塔切分注意力模塊(Pyramid Split Attention,PSA),將其嵌入到ResNet[8]中來提取更細粒度的空間信息并建立通道之間的長距離依賴,有效提升了分類網絡的性能。受到上述工作啟發,本文將金字塔切分注意力模塊引入特征金字塔機制,搭建了自上而下的特征融合路徑。
PSA的網絡結構如圖3所示,共包含四個主要步驟。假設輸入特征X的尺寸為C×H×W,首先在通道維度上將輸入向量均分為S組,采用分組卷積的方法讓S個不同尺寸的卷積核并行處理每組向量,并采用級聯的方式對結果進行融合得到F。然后采用通道注意力模塊為每組特征學習注意力權重向量,權重的計算方式將在后面詳細介紹。第三步是采用Softmax函數注意力向量進行調整得到Z′,從而自適應地選擇不同的空間尺寸。最后,將調整后的注意力向量Z′和F做逐像素乘積得到輸出特征。

圖3 PSA結構


其中f(·)表示PSA模塊的映射關系,conv(·)表示1×1卷積運算,up(·)表示雙線性插值函數。
2.3 上下文注意力模塊
注意力機制是一種讓模型關注重點目標區域的信息篩選機制,能夠幫助網絡提取到與人群目標更相關的有利信息。上下文注意力模塊首先提取全局和局部上下文信息并進行融合,基于該融合語義信息生成能感知不同密度分布模式的注意力圖,給不同密度級別的密度圖分配對應的權重,讓模型關注到不同分布狀態的行人,從而克服圖像中人群雜亂分布導致的密度差異,其具體結構如圖4所示。

圖4 CAM結構
Dai等人[9]指出只利用全局上下文信息將使得模型更關注于分布于全局的目標,并弱化小尺寸目標的圖像信號,局部上下文信息的使用將有助于模型關注更多的空間細節信息,從而生成更高質量的特征圖。所以CAM模塊分別設計了全局和局部上下文提取模塊,并對提取的多尺寸上下文語義進行融合。考慮到平均池化和最大池化具有不同的特性,平均池化對特征圖上的每個像素點都產生反饋信號,而最大池化更加關注于區域內相應最大的位置,所以采用全局平均池化(Global Average Pooling,GAP)和最大池化(Global Max Pooling,GMP)兩種池化機制來提取全局上下文信息。輸入特征首先分別經過GAP和GMP來聚合全局空間信息,然后采用兩個1×1卷積捕獲各通道間全局信息的依賴關系。同時設計了局部上下文信息提取模塊,不采用全局池化操作,通過小尺寸的卷積操作建立局部連接來捕捉局部上下文特征。最后對提取的上下文信息進行融合得到多尺寸上下文語義特征,并經過兩個1×1卷積進一步增大特征的感受野并調整通道數量,生成最終的注意力權重。
2.4 密度圖生成模塊
SE Block[10]能夠對輸入特征通道之間的相關性進行建模,通過網絡學習的方式自動獲得每個特征通道的重要程度。本節采用SE Block來對特征融合模塊得到的多級語義融合特征進行通道維度的權重調整,其具體結構如圖5所示。

圖5 SE Block結構
SE Block首先通過全局平均池化聚合空間信息,為每個通道分別生成一個全局描述符。假設輸入特征f的尺寸為C×W×H,于是第c個通道的描述符的計算過程如式(2)所示:
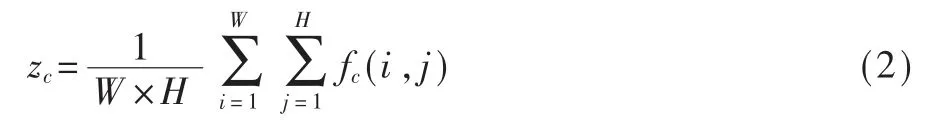
其中fc表示第c個通道的輸入特征。然后將全部描述符輸入到兩個全連接層進行非線性變換,并采用Sigmoid激活函數實現特征的重新標定,于是得到所有通道的注意力權重:

其中W1和W2分別表示兩全連接層的權重,z表示C個通道描述符組成的整體描述符。于是調整后的特征如式(4)所示:

通道注意力模塊對多級語義融合特征進行了通道權重的調整,加強了對密度估計更重要的通道,生成了更具辨別力的特征。為了提取更深層的語義信息,首先采用1×1卷積層將通道維數降為512通道,再采用2個3×3卷積層進一步擴大特征的感受野,最后采用1×1卷積層生成3個對應不同密度級別的密度圖。最后,將CAM生成的感知不同密度模式的注意力圖和DGM生成的不同區域的密度圖進行逐像素相乘,相加融合生成最終的高質量密度圖,具體計算過程如式(5)所示:

其中,Ai和Di分別表示CAM和DGM生成的第i個通道的特征,⊙表示逐像素相乘。
2.5 損失函數
本文采用歐式距離衡量估計密度圖和真值密度圖之間的差距,定義如式(6)所示:

其中,θ是MACN中待優化網絡參數的集合,N是訓練樣本數量,Xi表示第i張輸入圖像,Fi和F(Xi;θ)分別表示真值密度圖和估計密度圖。此外,采用交叉熵損失監督CAM模塊生成的注意力圖,計算方式如式(7)所示:

其中,yj和Aj(Xi;θ)分別表示第j個密度等級注意力權重的真值標簽和估計值。yj的獲得方式將在3.1節詳細介紹。因此,總體損失函數如式(8)所示:

其中α表示超參數,在實驗中被設置為1。
3 算法實現
3.1 地面真值生成
假設xi位置存在一個人頭標記,可將其表示為一個單位沖擊函數δ(x-xi),可將包含M個人頭標記的輸入圖像表示為:

然后采用歸一化的高斯核對每個人頭標記做平滑處理,即將H(x)與高斯核做卷積來生成真值密度圖,計算方式如式(10)所示:

其中μ和σ分別表示高斯核的均值和方差,Gμ,σ(x)表示歸一化的二維高斯核。本文采用15×15的固定尺寸高斯核生成真值密度圖。
此外,為了監督CAM模塊生成的注意力圖,本文依據上述生成的真值密度圖得到注意力真值標簽,計算過程如式(11)所示:

其中yi(x)表示第i個密度級別的注意力標簽,avg表示整張真值密度圖所有像素的平均值,β是超參數,被設置為0.2。
3.2 數據增強處理
本節采用多種方法對數據進行增強,防止訓練過程出現過擬合現象。首先,從原始圖片中裁剪出9張1/4原圖尺寸的圖像塊,并將每個圖像塊隨機裁剪到256×256的固定尺寸。然后,以0.5的概率對所有圖像塊做水平翻轉,以0.3的概率在[0.5,1.5]范圍內對圖像塊做伽馬變換,以0.1的概率將彩色圖片轉換成灰度圖像,以0.25的概率將彩色圖像的RGB通道切換。最后,以0.25的概率像圖像加入均值為0、標準差為5的高斯噪聲。
3.3 訓練過程
本文以端到端的方式訓練MACN。特征提取模塊采用在ImagNet上預訓練的VGG-16的參數進行初始化,剩余其他所有卷積層的權重都采用均值為0,標準差為0.01的高斯分布初始化。采用Adam優化器來優化模型參數,初始學習率和衰減率分別被設置為1×10-5和0.995,批尺寸設置為8。跟隨Gao等人[11]的做法,訓練時將密度圖乘以一個較大的放大倍數(100)來實現更快的收斂速度和更準確的結果,更好地平衡損失權重。本文所有工作皆是基于PyTorch深度學習框架,采用11 GB顯存的Nvidia-2080Ti GPU顯卡實現訓練和測試的加速。
4 實驗分析
參考其他優秀人群計數方法[12-13],本文采用平均絕對誤差(Mean Absolute Error,MAE)和均方誤差(Mean Squared Error,MSE)來評估算法性能,計算公式如式(12)、式(13)所示:
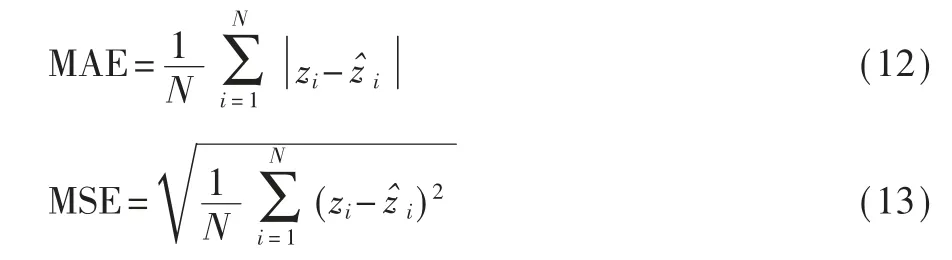
其中,N代表測試圖片數目,zi與z^i分別代表真值與算法的預測值。
4.1 ShanghaiTech數據集實驗
ShanghaiTech數據集[13]共包括1 198張人群圖片,根據密度差異被分為Part_A和Part_B兩個部分。Part_A由互聯網上獲取的482張人群圖片組成,人群分布較為密集,訓練集和測試集分別包含300張和182張圖片;Part_B中的716張圖片均拍攝于上海街頭,人群分布較為稀疏,訓練集和測試集分別包含400和316張圖片。
表2給出了在本數據集上MACN算法與其他代表性算法的實驗結果。由分析可知,MACN在兩個子數據集上同時實現了最好的MAE和MSE指標,相比于第二名分別將MAE指標優化了4.6%和9.2%,在人群密集的Part_A和人群較為稀疏的Part_B上都能實現較明顯的性能提升,說明MACN算法對人群密度變化具有較好適應性。圖6展示了測試集的部分估計密度圖和真實密度圖的可視化樣例,第一行、第二行表示Part_A上的估計結果,第三、四行表示Part_B上的估計結果;從左到右每一列分別表示人群圖片、真值密度圖和估計密度圖。

表2 ShanghaiTech數據集結果

圖6 ShanghaiTech上MACN算法生成密度圖可視化樣例
4.2 UCF_QNRF數據集實驗
Ideers等人[20]提出了UCF_QNRF數據集,圖片主要來源于朝圣素材和網頁搜索,共包含1 535張圖片,比ShanghaiTech數據集具有更大的規模,且圖像中人群總數浮動較大,人群場景更為復雜。
表3列出了MACN算法與其他優秀算法在UCFQNRF上的實驗結果。和MAE排名第二的PaDNet相比,MACN將MAE指標在數值上減小了2.7%,這表明該算法在極度密集的場景中仍能對人群數量進行準確估計。圖7展示了測試集的部分估計密度圖和真實密度圖的可視化樣例,可以看到MACN算法能夠有效應對圖像中存在的人群非均勻分布問題,生成接近真實人群分布的估計結果。

表3 UCF_QNRF數據集結果
4.3 JHU-CROWD++數據集實驗
Sindagi等人[27]提出的JHU-CROWD++數據集是一個新型的大規模無約束數據集,由不同場景與環境下的4 372張人群圖像組成,由訓練集(2 272張)、驗證集(500張)、測試集(1 600張)三個部分組成,人頭標注數量高達151萬。為了進一步研究人群計數算法在各種密度情況下的性能,測試集與驗證集的人群圖像被細分為高密度、中密度和低密度三個類別。同時考慮到惡劣天氣的影響,此數據集還包含單獨由復雜天氣人群圖像組成的子集。下面將在總體、低密度、中密度、高密度以及天氣環境這5種情況下分析人群計數算法的準確率和魯棒性,如表4所示。

表4 JHU-CROWD++數據集結果
對比MACN算法和其他先進算法在JHU-CROWD++測試集上的性能。在整體性能上,MACN算法的MAE指標比第二名優化了6.8%;在低密度、中密度、高密度、惡劣天氣等子類上MACN分別將MAE指標比第二名在數值上優化了0.2、1.9、16.6和7.9。JHU-CROWD++測試集的部分估計密度圖和真實密度圖的可視化樣例如圖8所示。分析表明,MACN算法在總體與所有子類上都實現了最準確的計數結果并能夠保持較高的魯棒性,驗證了MACN算法的泛化性和準確性。

圖8 JHU-CROWD++上MACN算法生成密度圖可視化樣例
4.4 消融實驗
為驗證各子模塊的有效性,本小節在Shanghai-Tech Part_A上對不同結構進行實驗。表5展示了五種不同結構的實驗結果,其中W/O FFM+CAM+SE表示將FFM模塊、CAM模塊和DGM中的SE Block移除;W/O FFM表示移除FFM模塊;W/O CAM表示移除CAM模塊;W/O SE表示移除SE Block;MACN表示完整結構。由實驗結果可知,同時采用FFM、CAM、SE Block能夠獲得最優的MAE和MSE指標,大幅提升模型性能。

表5 參數選擇實驗
5 結論
本文提出了一種基于多重注意力引導的密度估計網絡MACN,來解決人群計數任務中的人群雜分布問題。首先,該算法基于輕量化的切分注意力模塊,構建了一條自上而下的特征融合路徑以促進不同語義級別特征之間的流動,旨在增強特征的表達能力。然后,建立上下文注意力模塊來提取并融合多尺度上下文信息,以生成對應不同密度級別的注意力圖,從而引導密度估計網絡識別不同分布模式下的行人目標。最后,憑借大量實驗結果充分說明MACN有助于提升各種場景下的計數性能。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
無線電工程(2020年11期)2020-10-29 01:25:46
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
現代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
