基于多尺度卷積和注意力機制的LSTM 時間序列分類
2022-08-24 06:29:48玄英律萬源陳嘉慧
計算機應用 2022年8期
玄英律,萬源,陳嘉慧
(武漢理工大學理學院,武漢 430070)
0 引言
時間序列是按時間順序排列的一組數據,廣泛存在于商業、醫學和社會科學等領域中。時間序列分類在數據挖掘領域具有重要的研究價值,其目標是根據時間序列的特征信息為其分配正確的類標簽[1]。具有不同長度的子序列包含不同時間跨度的特征信息,稱為時間序列的多尺度特征。在分類任務中,這些特征的重要程度不同[2-3]。除此之外,時間序列之間或內部存在復雜的相關關系,這種相關關系被稱為時間序列相關性。因此,在時間序列分類任務中,如何有效地提取多尺度特征、評估特征重要程度并處理時間序列相關性問題是一個巨大的挑戰。
時間序列分類模型可大致分為兩大類:基于傳統機器學習的模型和基于深度學習的模型。傳統的時間序列分類模型中,基于距離的模型使用距離函數計算時間序列間的相似性,并結合最近鄰法(1-Nearest Neighbor,1NN)預測類標簽[4-5];基于特征的模型利用特征對時間序列進行分類,如Sch?fer 等[6]提出的 BOSS(Bag of Symbolic Fourier Approximation Symbols),根據詞分布形成詞直方圖,并通過詞直方圖的距離得到分類結果。
然而,大多數傳統的時間序列分類模型都需要進行繁雜的特征工程或數據預處理工作,深度神經網絡在時間序列分類中的應用有效地解決了這一問題,并進一步提高了分類準確率[7]。Wang 等[8]在實驗中驗證了多層感知機(MultiLayer Perceptron,MLP)處理時間序列分類問題的效果,MLP 通過全連接神經元的形式對整體時間序列數組的每一個元素逐層賦予權重,計算各類別概率,并輸出最終的類標簽;但MLP直接學習所有元素之間的相關關系,不能有效地提取特征[8-9]。Shelhamer 等[10]提出了全卷積神經網絡(Fully Convolutional Network,FCN),使用卷積層替換多層感知機最后的全連接層,加入批標準化層和全局池化層,防止網絡過擬合,增強了網絡的特征提取能力;但FCN 以固定大小的卷積核進行卷積,無法提取不同尺度的子序列特征,存在特征丟失問題。Franceschi 等[11]提出的USRL-Combined(1NN)模型,通過堆疊casual 卷積層獲取更豐富的序列特征表示,其分類效果普遍優于傳統的時間序列分類模型。Cui 等[12]提出一種新的基于卷積神經網絡(Convolutional Neural Network,CNN)的深度架構——多尺度卷積神經網絡(Multiscale Convolutional Neural Network,MCNN),該網絡包含三個網絡支路,分別進行恒等映射、滑動平均以及下采樣處理用以提取時間序列數據的多尺度特征,在一定程度上解決了特征丟失問題,然而其分類性能在很大程度上取決于超參數的選擇和數據的預處理質量[13-14],模型仍有較大的改進空間。Chen 等[15]為了提高深度學習模型的魯棒性,提出了一種結合多尺度特征提取和注意力機制的端到端網絡MACNN(Multi-scale Attention Convolutional Neural Network),該網絡設計了基于CNN 的多尺度卷積模塊(Multi-scale Convolutional Module,MCM),CNN 具有較為魯棒的特征提取能力[8],網絡堆疊多個模塊,能產生不同范圍的感受域,從而獲取不同尺度上的時間序列特征信息。
注意力機制借鑒了人類視覺所特有的信息處理機制。人類視覺通過快速掃描全局信息,獲得需要重點關注的目標區域信息之后,對重要的信息投入更多注意力資源,從而提取關鍵的細節信息,同時抑制其他無用信息,注意力機制能夠顯著地提高信息處理的效率與準確性。近年來,在已有的多尺度特征提取的工作基礎上,Huang 等[16]將注意力機制應用于時間序列分類任務中,使模型能夠自動學習并關注重要的特征,高效地分配計算資源以聚焦對分類結果有重要貢獻的特征表示,抑制貢獻較小的特征。
但時間序列數據常常存在復雜的相關性,上述深度神經網絡只能獨立地處理輸入的時間序列信息,無法在時間域中獲取隱含的序列依賴關系。循環神經網絡(Recurrent Neural Network,RNN)[17]是一類專門處理序列數據的網絡,其特點是前一時刻的輸出將對之后的輸出產生影響。然而,在處理長序列時,RNN 容易發生記憶丟失和梯度消失問題,導致網絡難以繼續訓練[18]。針對此問題,Hochreiter 等[19]基于RNN提出長短時記憶(Long Short-Term Memory,LSTM)網絡,引入記憶細胞(memory cell)保存序列的長期信息,并通過門機制(gate mechanism)增加或舍棄即將進入細胞狀態中的信息,在一定程度上解決了傳統RNN 存在的梯度消失的問題,可以學習長期相關信息[20]。為了提高網絡的特征提取能力,同時考慮時間序列相關性的問題,Karim 等[14]提出一種并行深度架構LSTM-FCN,使用LSTM 提取時間序列數據的相關性信息,并利用FCN 作為特征提取模塊提取時間序列高維特征,相較于LSTM,該模型顯著地增強了分類性能,但仍存在不能提取多尺度特征的問題。2020 年,Xiao 等[21]基于LSTMFCN 作出改進,提出了RTFN(Robust Temporal Feature Network for time series classification),該網絡使用LSTM 結合CNN、跳躍連接結構和自注意力機制提取多尺度時間序列特征。
上述模型仍存在兩個問題:1)在提取序列特征時,網絡以固定大小的卷積核提取序列特征,導致無法有效提取多尺度特征,而對于時間序列分類任務而言,充分地利用多尺度特征能夠有效增強網絡的分類能力。2)大多數基于深度學習的分類模型未考慮序列特征的重要性差異,在計算資源有限的條件下,如果網絡對所有特征視為同等重要可能造成資源的浪費,而且當對分類有較大貢獻的特征被忽視時,將會嚴重影響網絡的分類性能。
針對上述的問題,本文提出一種新的基于多尺度卷積和注意力機制的LSTM(Multi-scale Convolution and Attention mechanism based LSTM,MCA-LSTM)模型以提高時間序列分類的準確率。該網絡為兩個支路組成的并行架構,結合LSTM 和多尺度卷積注意力模塊(Multi-scale Convolutional and Attention Module,MCAM)。其中LSTM 使用門機制和記憶細胞控制序列信息的傳遞,有利于網絡學習時間序列的相關性信息。多尺度卷積注意力模塊由多尺度卷積模塊(MCM)和注意力模塊(Attention Module,AM)組成,在多尺度卷積模塊中,為CNN 設置了三種不同大小的卷積核,能產生多個感受域提取時間序列數據在不同尺度上的特征,進而將融合提取的特征傳入注意力模塊。該模塊沿用SE Net(Squeeze and Excite Network)[22],通過降低通道數融合通道間的特征信息并學習特征的重要性程度,在輸出特征圖前恢復原通道數計算特征圖的注意力權重,最后融合帶有注意力權重的多尺度特征和時間序列相關性信息,輸出分類結果。
本文的主要工作如下:
1)基于多個并行的CNN 構造網絡的特征提取模塊,充分提取時間序列的多尺度抽象特征。
2)在多尺度特征的提取過程中,結合通道注意力機制,自動學習特征的重要程度,并利用重要的多尺度特征進行分類,有效提高分類準確率并降低模型的時間復雜度。
1 相關工作
1.1 LSTM網絡
LSTM 網絡是基于循環神經網絡的一種改進模型,使用門機制和記憶細胞控制序列信息的傳遞,在處理長序列信息時,可以有效解決記憶丟失和梯度消失問題[19]。LSTM 主要由記憶細胞和多個控制序列信息流動的“門”組成,相關函數的公式如下所示:
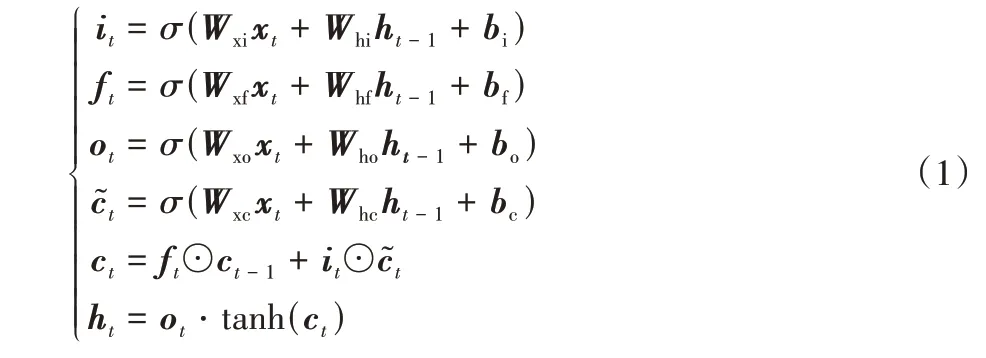
其中:xt表示t時刻的信息輸入;c表示細胞狀態,用于保存網絡提取到的序列信息;i表示輸入門,控制xt輸入至記憶細胞中的信息量;f表示遺忘門,控制t-1 時刻的細胞狀態ct-1輸入t時刻細胞狀態ct的信息量;o表示輸出門,控制ct傳遞至t時刻隱藏層狀態ht的信息量;Wxi、Wxf、Wxo、Wxc分別表示輸入層到輸入門、遺忘門、輸出門與細胞狀態的權重矩陣;Whi、Whf、Who、Whc分別表示隱藏層到輸入門、遺忘門、輸出門與細胞狀態的權重矩陣;bi、bf、bo、bc分別表示輸入門、遺忘門、輸出門與細胞狀態的偏置向量;σ(·)表示Sigmoid 激活函數;tanh(·)表示雙曲正切激活函數;⊙表示兩個同階矩陣中對應元素相乘的運算,稱為Hadamard 乘積。
1.2 注意力機制
根據人類的視覺機制,Vaswani 等[23]提出的注意力機制近年來已廣泛應用于語音識別、自然語言處理等領域,使用注意力機制的模型能夠自動學習并關注重要的特征,高效地分配計算資源以獲取最重要的特征表示[24-25]。最近的研究表明,通道注意力機制已被廣泛應用于時間序列分類領域。Hu 等[22]提出SE Net,在通道維度上融合信息,學習各通道間的相關關系,并計算衡量特征圖重要性的注意力權重。Huang 等[16]基于ResNet[26]提出殘差注意力網絡(Residual Attention Net),針對跨領域的序列數據,將Universal-Transformer 架構[27]和殘差網絡相結合,從而識別更高層次的序列模式。
1.3 多尺度特征提取
時間序列數據內部往往存在復雜的特征信息,充分地提取特征,并利用重要的特征進行分類,能夠有效提高時間序列分類模型的性能。Cui 等[12]提出的MCNN 在頻域將時間序列自動平滑去除噪聲,在時域通過不同程度的下采樣處理獲取多尺度特征。在端到端的深度學習模型中,Shuang 等[28]提出卷積-反卷積詞嵌入(Convolution-Deconvolution Word Embedding,CDWE)網絡,結合LSTM 與卷積-反卷積詞嵌入模型,融合特定的上下文信息和特定任務信息。Fawaz 等[29]在GoogLeNet[30]的基礎上,改進并應用于時間序列分類領域,提出Inception-Time 架構,其核心是基于并行CNN 的Inception 模塊,通過堆疊該模塊產生多個尺度的感受域,并且使用不同長度的卷積核,提取多個時間跨度的潛在層次特征。Tang 等[31]提出OS-CNN(Omni Scale-CNN)架構,利用根據數據集序列長度自適應網絡參數的全尺度模塊(Omni Scale block,OS block)捕捉序列的多尺度局部特征,挖掘數據的層次表示和層次結構中的相關關系。本文在深度網絡中結合通道注意力機制和多尺度卷積,以充分提取多尺度特征,聚焦重要的序列多尺度特征,從而提高模型的分類性能。
2 多尺度注意力長短時記憶網絡
2.1 整體架構
MCA-LSTM 的結構如圖1 所示,該網絡由LSTM 支路和基于多尺度卷積注意力模塊(Multi-scale Convolutional and Attention Module,MCAM)的支路組成。網絡中多次使用兩個MCAM 和一個池化層(Pooling)的結構,下文稱這樣的結構為Section。
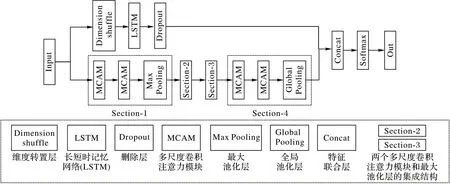
圖1 MCA-LSTM的整體結構Fig.1 Overall structure of MCA-LSTM
多尺度卷積注意力支路堆疊4 個Section 用于獲取重要的特征,池化層用于減少網絡的參數量、防止網絡過擬合。其中,Section-1 與Section-2、Section-3 均使用最大池化層且具有完全相同的結構;Section-4 則使用全局池化代替傳統的全連接層[32],以降低網絡參數量。
在LSTM 支路上,時間序列數據首先輸入維度轉置層(Dimension shuffle),使網絡將長度為N的單變量時間序列樣本視為長度為1、具有N個變量的多變量時間序列,維度轉置操作可以顯著提高LSTM 的訓練速度[14]。LSTM 控制序列信息的傳遞,提取序列相關性信息。隨后將提取的特征輸入丟棄層(Dropout)[33],在網絡訓練過程中按一定的概率p移除神經元,防止模型產生過擬合,增加模型魯棒性。加入Dropout操作后,網絡計算公式如下:
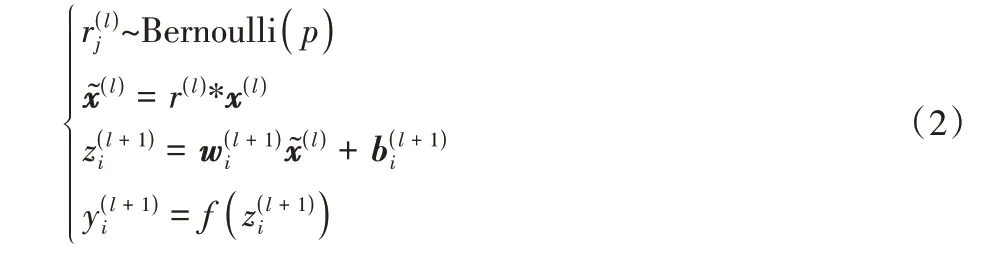
其中:Bernoulli 表示伯努利分布;參數p表示移除神經元的概率分別以概率p和1 -p取1 和0 為值,用于調整神經網絡的輸入分別表示第l+1 層上第i個神經元的權重向量和偏置向量;f(·)為線性整流單元(Rectified Linear Unit,ReLU)激活函數。最后使用特征聯合層連接兩個支路提取的多尺度注意力特征和相關性信息,輸入Softmax 計算類別概率,輸出分類結果,并在網絡的輸出層提供監督,根據交叉熵損失函數學習網絡參數。
2.2 多尺度卷積模塊
時間序列數據的子序列包含復雜的信息,在時間序列分類中,網絡中存在的子序列特征丟失問題往往會導致數據被錯誤分類。在基于深度學習的時間序列分類模型中,可以利用不同范圍的感受域獲取更豐富的時間序列特征信息。為了提取多尺度特征,進一步解決局部特征丟失問題,本文使用多尺度卷積模塊(MCM),同時提取時間序列的多尺度特征,融合更豐富的局部信息,更加充分地利用序列內部隱含信息。
由于時間序列是一維的,在CNN 上使用一維卷積核對時間序列數據進行卷積操作。第l 層CNN 上第i個濾波器t時刻激活值的計算公式如下:
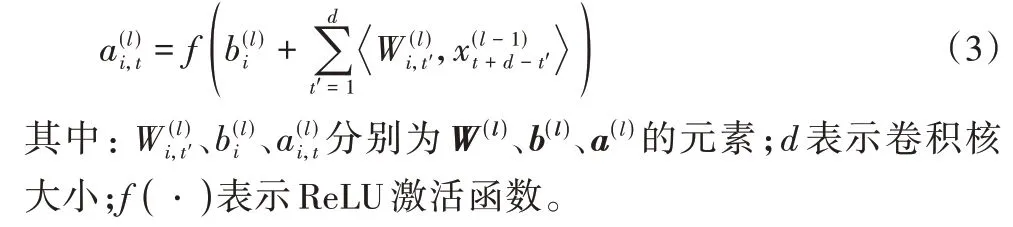
在MCA-LSTM 中,3 個并行CNN 的卷積核大小分別設置為d1、d2、d3,且滿足d1<d2<d3,對應提取時間序列的短、中、長期特征。進而將多尺度特征輸入特征聯合層(Concatenate Layer)進行特征融合,傳入批標準化(Batch Normalization,BN)層對樣本進行標準化操作:

最后一層為激活層,使用ReLU 作為激活函數,其優點是能夠增強網絡的非線性表示關系,產生較為稀疏的學習參數矩陣,從而在一定程度上降低網絡的計算復雜度;為了提高模型的收斂速度和魯棒性,本文結合使用BN 操作和ReLU 激活函數[35]。模塊的輸出由式(6)計算得到:
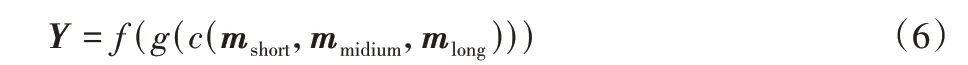
其中:mshort、mmidium、mlong表示卷積核大小等于d1、d2、d3的卷積核提取到的特征圖,對應時間序列的短、中、長期特征;c(·)表示特征連接操作;g(·)表示批量標準化操作;f(·)表示使用ReLU 激活函數計算激活值。
2.3 注意力模塊
時間序列的子序列所包含的特征信息通常具有不同的重要程度,為了進一步提高模型性能,本文創新地使用基于空間注意力機制的注意力模塊(AM)建模時間序列卷積特征的通道之間的相互依賴關系,網絡根據前向誤差自動學習特征權重,聚焦重要的特征信息,以提高網絡產生的特征表示的質量。
注意力模塊的結構如圖2 所示。首先,多尺度模塊輸出的特征圖作為注意力模塊的輸入進行全局池化操作:
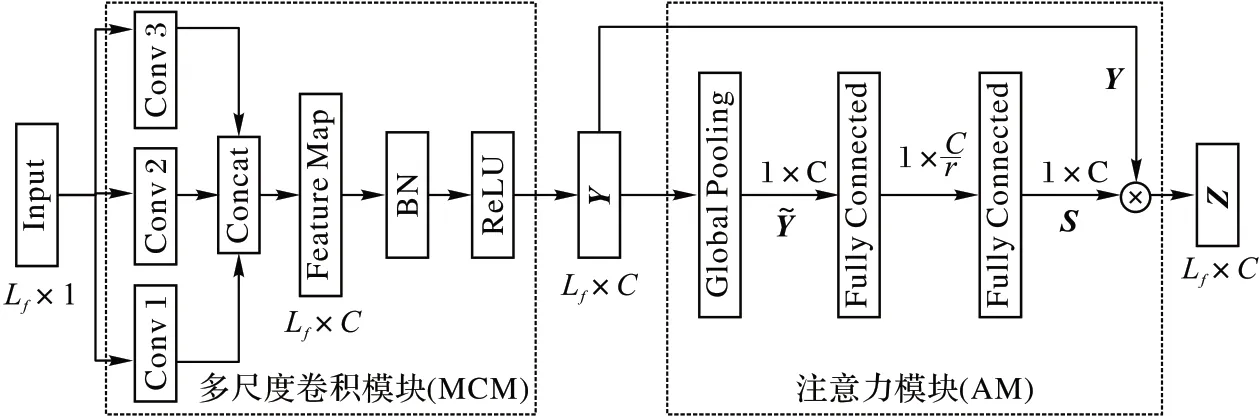
圖2 多尺度卷積注意力模塊的結構Fig.2 Structure of multi-scale convolutional and attention modules

最后兩層分別使用激活函數為ReLU 函數和Sigmoid 函數的兩個全連接層,r表示降維因子。在第1 個全連接層中壓縮特征圖的通道數為輸入時的1/r,融合通道的全局特征信息,利用全局信息獲取各通道之間的非線性相關關系;第2 個全連接層中進行升維操作,將特征圖通道數恢復至輸入時的通道個數,計算特征圖的注意力權重向量,融合多尺度特征,根據式(8)計算得到注意力權重S:

其中:δ表示ReLU 激活函數;σ表示Sigmoid 激活函數;W1、W2分別表示第1、2 個全連接層中神經元的權重參數。
多尺度卷積模塊的輸出特征向量Y與對應的注意力模塊輸出的權重矩陣S逐元素相乘,得到注意力模塊的輸出矩陣Z,并輸入后續的網絡層,對特征賦注意力權重的計算公式如下:

對應元素的計算公式如下:

如果特征越重要,其對應注意力權重si越接近1;反之,注意力權重si越接近0。網絡可根據權重的大小判斷特征yi的重要程度,為重要的特征分配更多計算資源,抑制不重要的特征,從而提高網絡產生的特征表示的質量。
3 實驗與結果分析
3.1 實驗數據集與評價指標
3.1.1 數據集
本文模型使用Xiao 等[21]在對比實驗部分使用的UCR 檔案[36]中的65 個單變量時間序列數據集,共涉及心電圖、圖像、運動、傳感器、模擬、和圖譜分析6 個領域。序列長度為24~2 709,數據集的樣本數為20~4 500。這些數據集對現實時間序列數據具有較強的代表性,得到的實驗結果能夠驗證模型的性能和泛化能力。
3.1.2 評價指標
本文選擇三種常用的時間序列分類評價指標對各個模型進行綜合評價,并使用Wilcoxon 符號秩檢驗和Nemenyi 后續檢驗對比本文模型和其他模型的性能差異。具體定義如下:
1)算術平均排名(Arithmetic Mean Rank,AMR)表示目標模型在所有數據集上準確率排名的算術平均值,該值越低說明模型的綜合性能越好,計算公式如下:

其中:ri表示目標模型在第i個數據集上的準確率排名;N表示數據集的總個數。
2)幾何平均排名(Geometric Mean Rank,GMR)表示目標模型在所有數據集上準確率排名的幾何平均值,與AMR 共同度量模型在數據集上的綜合性能。如果某模型具有較大的GMR 值,說明該模型在多個數據集上的準確率排名靠后。計算公式如下:

3)平均錯誤率(Mean Error,ME)表示目標模型在所有數據集上取得的準確率,該值越低說明模型性能越好,計算公式為:

其中:ai表示目標模型在第i個數據集上的Top-1 準確率。
4)Wilcoxon 符號秩檢驗(Wilcoxon Signed rank Test,WST)是一種非參數統計檢驗,對比其他模型在各數據集上準確率排名,檢驗本文模型的性能是否顯著優于其他對比模型,其原假設和備擇假設如下:

其中:m表示模型在所有數據集上準確率排名的中位數。
5)Nemenyi 后續檢驗(Nemenyi Test),當存在兩個模型在WST 中拒絕原假設后,說明模型間的性能表現有顯著差異,此時進行Nemenyi 后續檢驗進一步區分模型的優劣程度。根據相應的置信度計算臨界差(Critical Difference,CD),比較模型的算術平均排名是否超出該臨界值以判斷性能差異,臨界差C的計算公式如下:

其中:qα在自由度為α下的置信度;k表示模型個數;N表示數據集的總個數。在本文的實驗條件下,置信度α=0.05,qα=2.85。
3.2 實驗設置
本文在UCR 檔案中挑選了8 個涉及多個領域、具有不同序列長度的單變量時間序列數據集,用于選擇最優的模型架構與網絡參數設置,具體情況見表1。
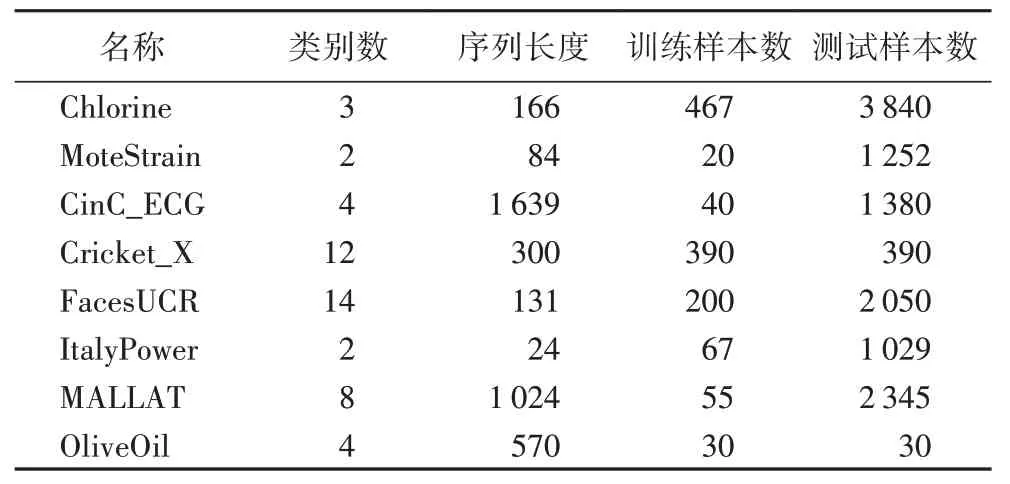
表1 8個時間序列數據集細節Tab.1 Details of 8 time series datasets
3.2.1 網絡架構搜索
MCA-LSTM 的多尺度卷積注意力支路,可以通過堆疊多個Section 產生不同大小的感受域以提取重要的多尺度時間序列特征。但由于本文所使用數據集的樣本序列長度不等,在提取短、中、長期特征時,需要產生大小合適的感受域以適應大多數數據集。此外,如果堆疊的層數過多,可能會在某些數據集上發生過擬合問題。因此,本文對包含不同數量Section 的網絡架構進行性能對比實驗。實驗的網絡參數設置沿用文獻[14-15]和文獻[22]中的設置,其中批處理大小設置為128,學習率設置為0.001,降維因子設置為16,訓練輪數設置為2 000。在8 個數據集上分別運行包含1~6 個Section 的網絡架構,架構搜索的實驗結果如圖3 所示。
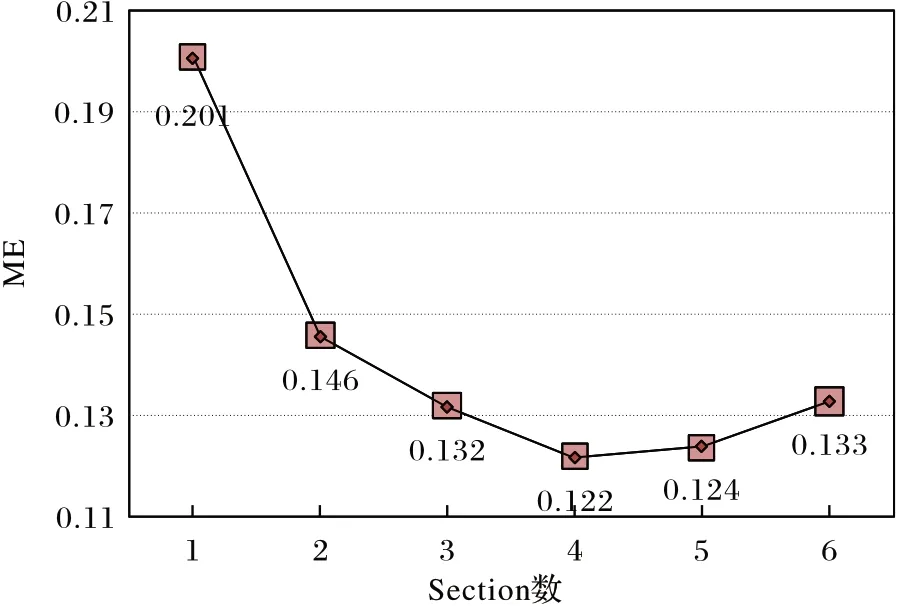
圖3 不同架構的平均錯誤率Fig.3 Mean errors of different architectures
根據架構搜索結果發現,當網絡堆疊的Section 數小于等于3 時,增加網絡的深度能夠提高分類的準確率;當Section數大于5 時,模型的性能開始下降。這可能由于網絡層數過少時,未能充分提取時間序列特征,而當Section 數大于等于5 時,網絡中發生了過擬合問題。包含4 個Section 的網絡架構達到最低的平均測試錯誤率為0.122,因此本文選擇在多尺度卷積注意力支路中堆疊4 個Section 作為MCA-LSTM 的網絡架構。
3.2.2 網絡參數選擇與設置
確定網絡架構之后,為了選擇適合MCA-LSTM 的參數組合,本文沿用文獻[15]的超參數搜索方法和初始超參數組合:首先,依次設置批處理大小、訓練輪數、降維因子和丟棄率的初始值為32、2 000、16、0.8。然后采用基于該超參數組合的貪婪策略搜索最優參數取值。具體來說,先固定后3 個參數,對第1 個參數的不同取值進行實驗,選取使得模型達到最低錯誤率的取值作為該參數的最優值;然后固定第1、3、4 個參數,選取第2 個參數的最優值,以此類推。應注意的是,已選取最優值的參數將在接下來的參數搜索實驗中恒被固定為最優值。
本文根據文獻[14-15]設置網絡參數搜索空間,分別在{32,64,128,256}、{1 500,2 000,2 500,3 000}、{8,16,32}和{0.5,0.6,0.7,0.8,0.9}中依次搜索批處理大小、訓練輪數、降維因子和丟棄率。表2 為各個網絡參數組合的平均錯誤率,粗體超參數取值和平均錯誤率分別表示超參數在貪婪策略下的局部最優取值和局部最低的平均錯誤率。
從表2 可看出:在給定的網絡參數空間中,模型取得最小的平均錯誤率為0.130 9,其中,訓練輪數為2 500 和3 000時取得的模型表現相同,在節省計算資源的原則下,選擇2 500 作為訓練輪數的最優值。因此模型最終的參數選擇情況如下:批處理大小設置為128,初始學習率設置為1E-3,訓練輪數設置為2 500,并使用Adam 優化器[37]。在訓練過程中,如果模型在測試集上的準確率連續100 輪未獲得提高,學習率將降低為原來的,直至降低為1E-4。在MCALSTM 的多尺度卷積模塊中,3 個CNN 的卷積核大小分別設置為3、6、12,卷積的滑動步長設置為1,卷積核個數均設置為32,最大池化層的滑動步長設置為2。注意力模塊中降維因子設置為16。LSTM 的記憶細胞數在8、64、128 中選擇,丟棄層的丟棄率設置為0.8。
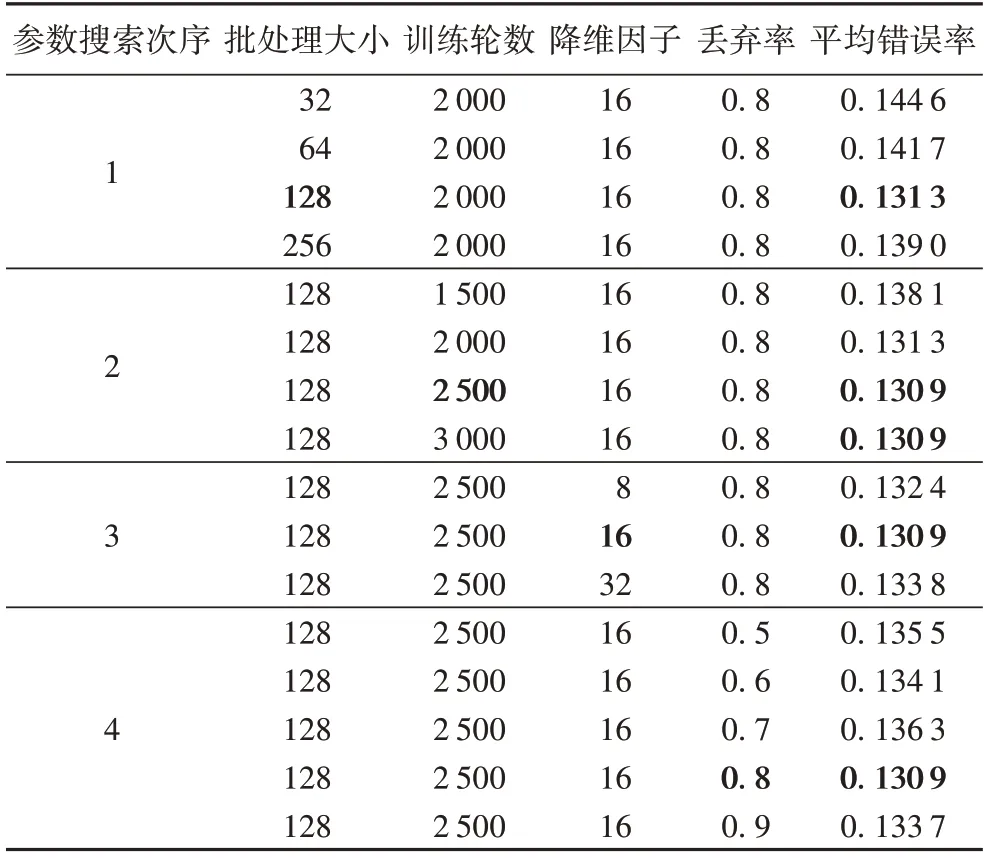
表2 各參數組合的平均錯誤率Tab.2 Mean error of each parameter combination
3.3 實驗結果與分析
MCA-LSTM模型的代碼使用深度學習框架Keras[38]編寫,并在NVIDIA GeForce RTX 2080 GPU 上進行訓練。由于神經網絡使用隨機初始權重,進行了10 次實驗以平均由初始權重引起的誤差。此外,在本文的設置中,數據集序列長度小于200 稱為短序列數據集,序列長度介于200 到500 之間稱為中序列數據集,長度大于500 的稱為長序列數據集。
3.3.1 Top-1準確率對比
本文選擇5 種基于深度學習的時間序列分類模型作為對比模型,包括:USRL-FordA(Unsupervised Scalable Representation Learning-FordA)[11]、USRL-Combined(1-NN)[11]、OS-CNN[31]、Inception-Time[29]和RTFN(Robust Temporal Feature Network for time series classification)[21]。本節將展示MCALSTM 和5 種對比模型在65 個單變量時間序列數據集上取得的Top-1 準確率,實驗結果如表3 所示,粗體表示所有對比模型在某數據集取得的最高分類準確率。
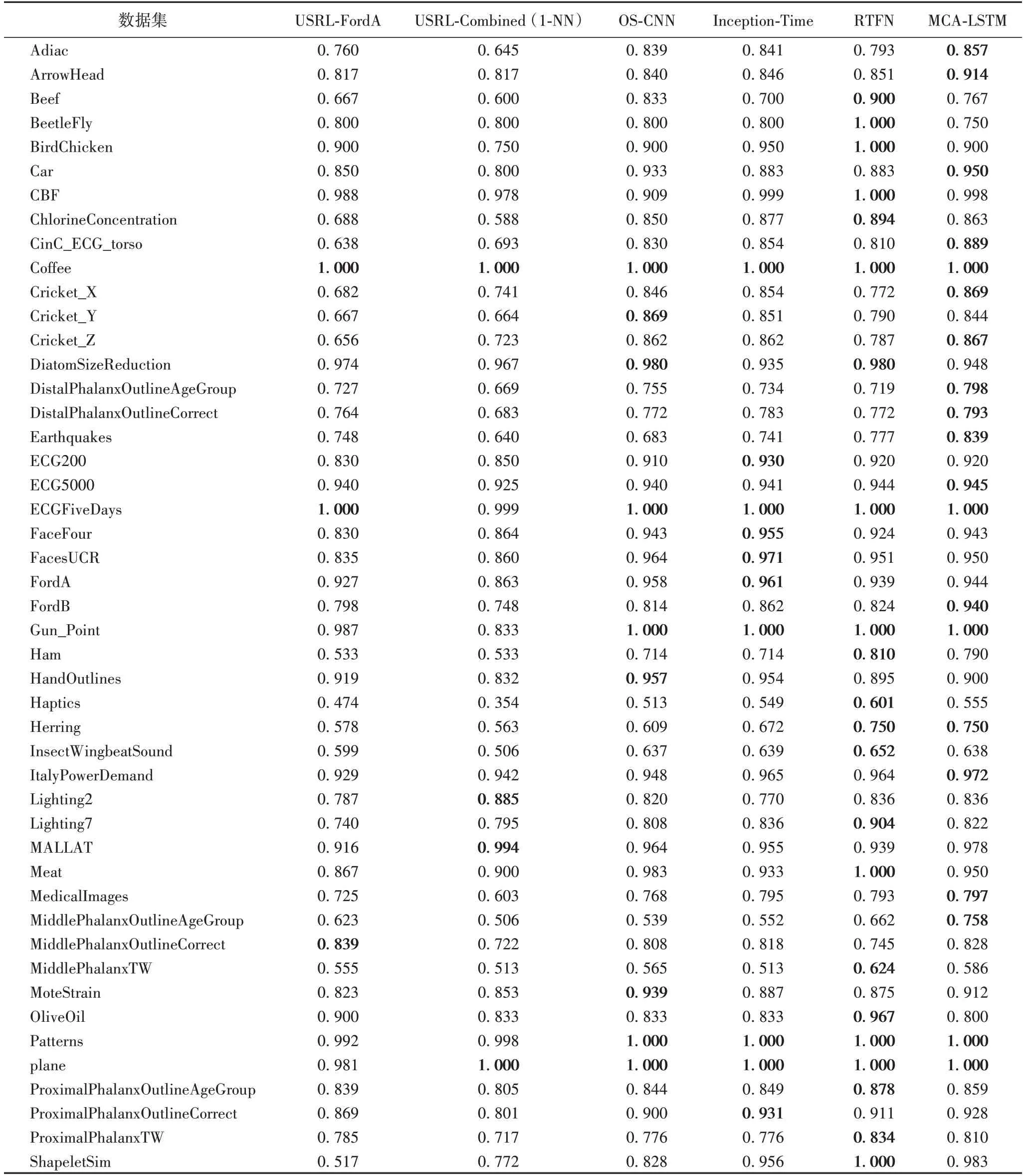
表3 65個數據集上的Top-1準確率對比Tab.3 Comparison of Top-1 accuracy on 65 datasets
相較于5 種基于深度學習的時間序列分類模型,本文模型共在28 個數據集上取得最高的Top-1 準確率。具體來說,相較于沒有使用多尺度卷積和注意力機制的深度模型,如USRL-FordA 和USRL-Combined(1-NN),本文模型分別在54個和57 個數據集上取得更高的準確率。對比同樣使用了多尺度卷積的OS-CNN 和Inception-Time,本文模型分別在37 個和38 個數據集上取得了更優秀的表現,分別在10 個和7 個數據集上與上述兩種多尺度模型的準確率持平。相較于最新的RTFN,該模型在編碼器-解碼器結構中使用多尺度卷積和自注意力模塊,本文模型仍在30 個數據集上取得了更好的結果,并在另外11 個數據集上的準確率與之持平。對實驗結果分析發現,在個別數據集上,如BeetleFly 和OliveOil,MCA-LSTM 的分類準確率普遍低于其他對比模型。其中的原因是,這兩個數據集的序列長度均在500 以上。當序列長度較大時,MCA-LSTM 只能在相對較短的尺度上提取特征,導致對長序列數據集的分類準確率提升有限。而MCA-LSTM 在短、中序列的數據集上的分類準確率均取得了較為明顯的提升,說明本文模型更有利于處理短、中序列的數據集。不同序列長度的數據集上的平均Top-1 準確率對比如表4 所示,粗體表示不同序列長度下對比模型得到的最高平均Top-1 準確率。從表4 可以看出:相較于最新的RTFN 模型,MCA-LSTM 在短、中、長序列數據集上的平均錯誤率分別降低了2.1、0.02、-0.02 個百分點。總的來說,兩種模型在中、長序列數據集上的分類能力相近,而在短序列數據集的處理上MCA-LSTM 具有更明顯的優勢。
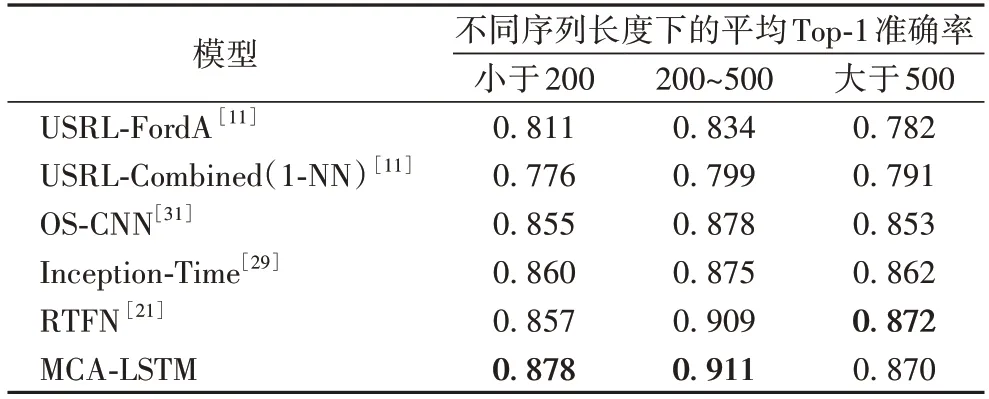
表4 按序列長度分組的不同模型的平均Top-1準確率Tab.4 Average Top-1 accuracies of different models grouped by sequence length
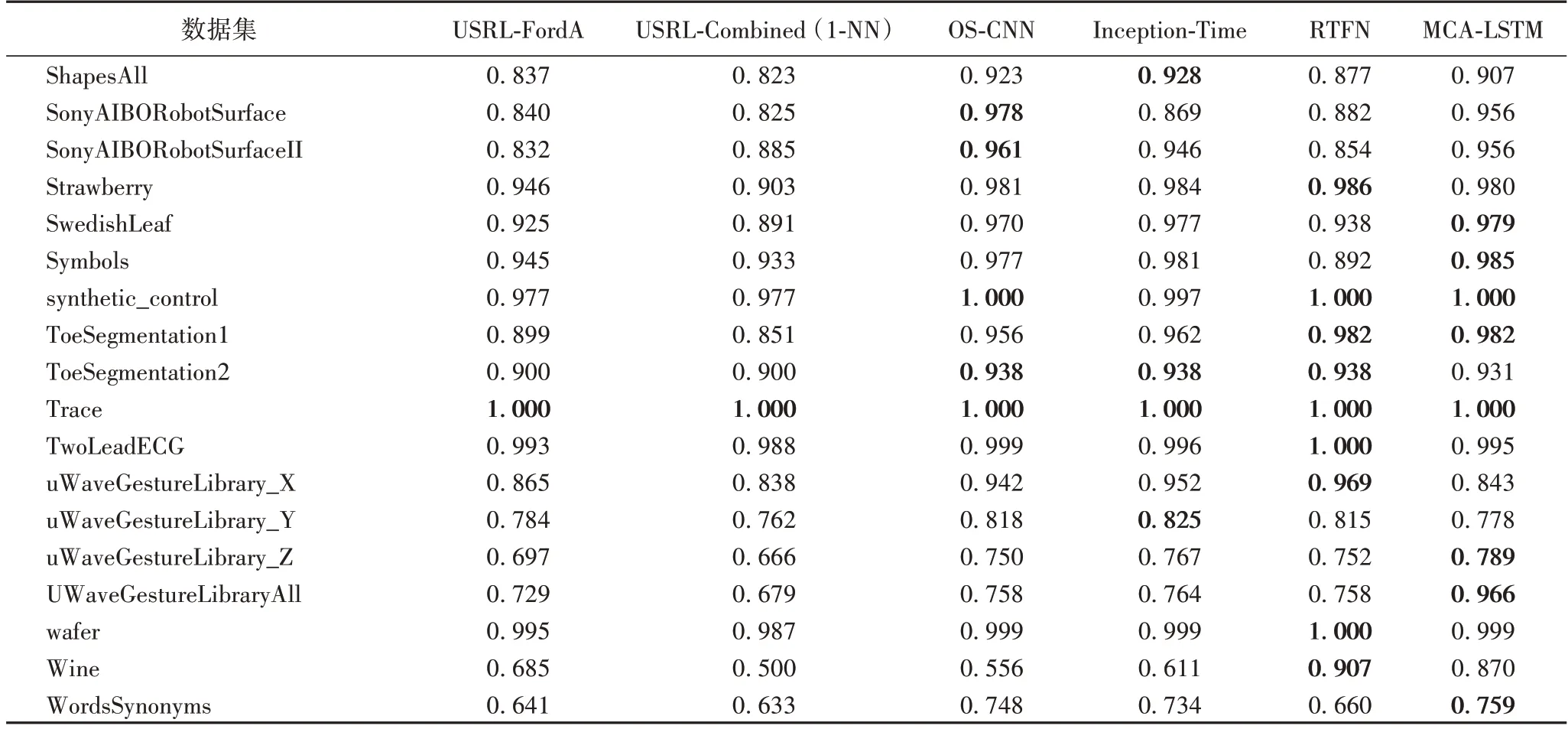
續表
3.3.2 評價指標對比
為了評價MCA-LSTM 和其他模型在所有數據集上的整體性能表現,根據式(11)~(13)分別計算評價指標平均錯誤率(ME)、算術平均排名(AMR)和幾何平均排名(GMR),分析表5 可以得出以下結論。
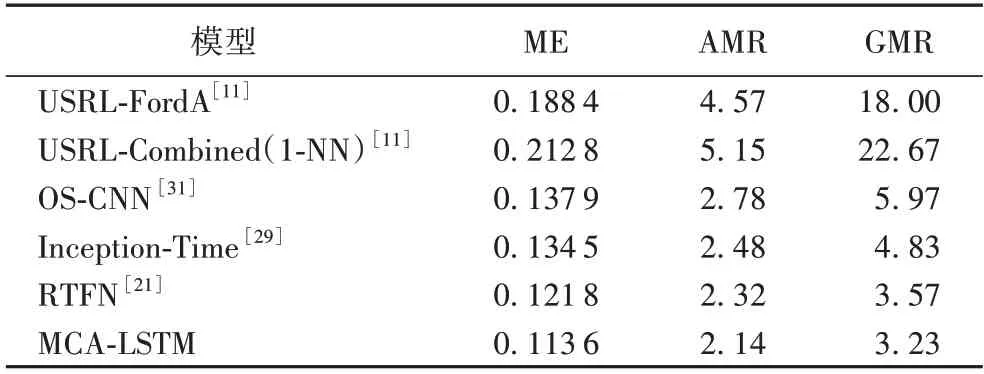
表5 評價指標對比Tab.5 Comparison of evaluation indicators
相較于其他5 種基于深度學習的時間序列分類模型,本文模型在UCR 檔案中的65 個單變量時間序列數據集上取得的ME、AMR 和GMR 三種評價指標均優于其他5 種對比模型。三種評價指標的具體數值分別為11.36%、2.14 名、3.23名 。具體來說,相較于USRL-FordA 和 USRLCombined(1-NN),MCA-LSTM 的ME 分別降低了7.48 個百分點和9.92 個百分點;對比其他提取多尺度特征進行分類的模型架構,如OS-CNN 根據序列長度自適應分配卷積核大小提取多尺度特征,Inception-Time 通過堆疊基于CNN 的特征提取模塊產生不同感受域提取多尺度特征,MCA-LSTM 相較于OS-CNN,ME 指標降低了2.43 個百分點,AMR、GMR 分別提升0.64 名和2.74 名。相較于Inception-Time 模型,ME 降由于MCA-LSTM 和RTFN 之間以及其他部分模型之間的性能差異未通過顯著性檢驗,進行Nemenyi 后續檢驗,由式(15)計算CD,進一步判斷各個模型性能的優劣程度。根據各模型間的臨界差圖(如圖4 所示)可以得出結論:本文模型的總體分類性能顯著優于未使用多尺度卷積的USRLCombined(1-NN)和USRL-FordA,在一定程度上優于使用多低2.09 個百分點,AMR、GMR 分別提升0.34 名和1.60 名。這歸功于MCA-LSTM 在多尺度卷積的基礎上結合了注意力機制,使模型能夠更有效地融合多尺度信息,并關注重要的特征。對比結合多尺度卷積和自注意力機制的RTFN,本文模型在平均錯誤率上降低0.82 個百分點,算術平均排名、幾何平均排名上分別提升0.18 名和0.34 名,這是由于MCALSTM 堆疊了較多基于CNN 和注意力機制的MCAM 協助網絡進行特征提取,較深的網絡結構使得MCA-LSTM 能夠更充分地學習數據間的非線性關系,并提取到更多有利于分類的潛在時間序列特征。
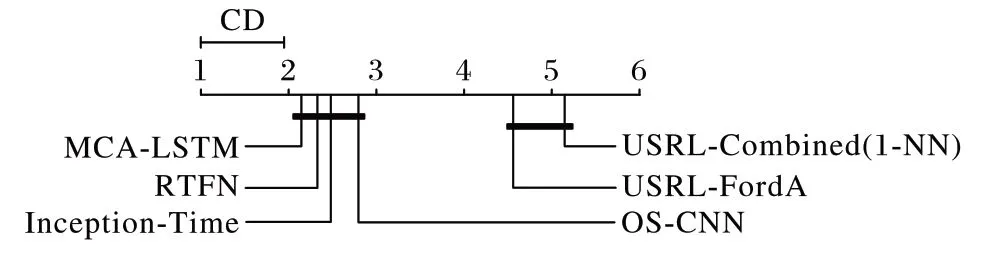
圖4 基于算術平均排名的臨界差圖Fig.4 Critical difference diagram based on arithmetic mean ranks
為了探究各模型之間分類準確率的顯著性差異程度,將MCA-LSTM 與其他模型進行Wilcoxon 符號秩檢驗,若檢驗的p值小于0.05,則拒絕原假設,說明兩個模型的分類性能具有顯著差異;反之接受原假設,說明兩個模型的性能相近。表6 中的加粗p值表示接受原假設,即對應模型之間的分類性能無顯著差異,本文模型與USRL-FordA、Inception-Time、USRL-Combined(1-NN)、OS-CNN 的性能具有顯著差異,但和RTFN 的性能差異不顯著。尺度卷積的RTFN、Inception-Time 和OS-CNN。
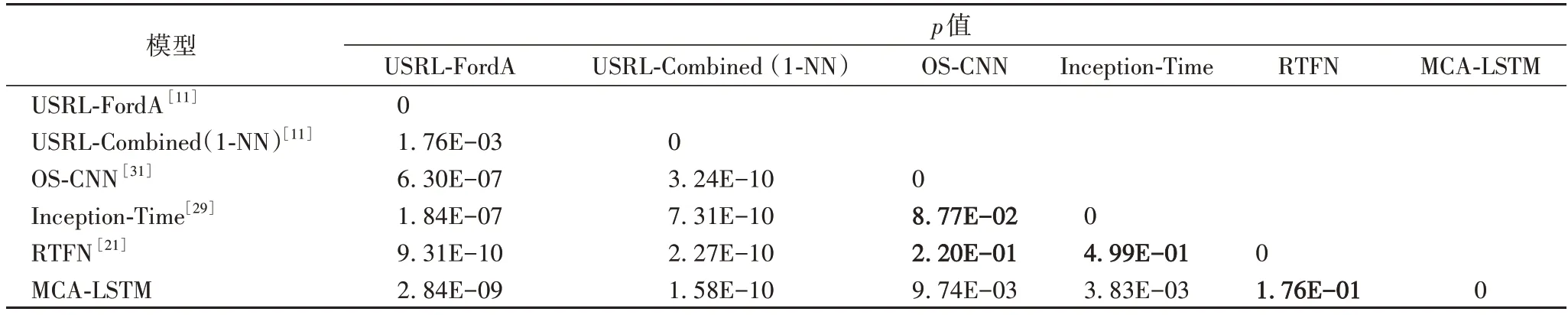
表6 各模型間Wilcoxon符號秩檢驗結果Tab.6 Wilcoxon signed-rank test results between different models
綜合上述實驗結果可知,本文模型在65 個實驗數據集上取得了優于所有對比模型的綜合表現,這表明結合多尺度卷積和注意力機制,能讓網絡取得更良好的分類表現。因此,相較于其他基于深度學習的模型,MCA-LSTM 在解決單變量時間序列分類任務方面更有優勢。
4 結語
為了提高單變量時間序列的分類準確率,本文提出一種基于多尺度卷積和注意力機制的LSTM 模型——MCALSTM。該網絡為兩個支路組成的并行架構,結合LSTM、多尺度卷積模塊和注意力模塊:LSTM 控制序列信息的傳遞,使網絡能夠有效地學習序列的相關性信息;多尺度卷積模塊通過產生多個感受域提取時間序列數據在不同尺度上的特征,獲取更豐富的特征表示;注意力模塊融合通道特征信息,使網絡聚焦于重要的特征。在UCR 檔案中的65 個單變量數據集上進行的實驗和評價結果表明,相較于其他5 種基于深度學習的時間序列分類模型,MCA-LSTM 的分類性能更為優秀,從整體上提高了分類準確率。然而,本文模型對長時間序列的分類效果提升不夠明顯,除此之外,尚未將模型應用至多變量時間序列分類數據集中,在未來的工作中將在此模型的基礎上深入研究解決多變量、長序列分類問題的模型架構。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
