融入時空顯著性的高精度視頻穩像算法
2022-08-24 06:30:42尹麗華康亮朱文華
計算機應用 2022年8期
尹麗華,康亮,朱文華
(上海第二工業大學工程訓練中心,上海 201209)
0 引言
手機、數碼相機等手持設備憑借便攜性已成為人們日常拍攝的首選,然而,拍攝的視頻不可避免地存在畫面抖動的問題,不僅影響視覺效果,而且容易導致誤判或漏判。因此,將這些視頻信號轉化為高質量的穩定視頻具有重要的意義。電子穩像技術具有體積小、質量輕、精度高、靈活性強等優勢,已經成為當前的研究熱點[1-2]。
電子穩像技術的基本思想是通過運動估計獲取幀間運動,并通過各種濾波方法(如高斯濾波、卡爾曼濾波、粒子濾波等)平滑相機路徑,最后通過反向補償得到穩定圖像[3]。然而,在實際的拍攝場景中,不可避免地會存在各種類型的運動前景(比如行人、車輛等),而運動前景的存在容易混入局部運動分量,降低運動估計的精度,進而影響穩像的精度。因此,剔除運動前景的干擾對進一步提高穩像精度至關重要。目前,主要通過隨機抽樣一致性(RANdom SAmple Consensus,RANSAC)算法進行多次迭代[4];采用最小二乘法迭代或者采用背景/前景分割技術。例如,邱家濤[5]在穩像算法中結合RANSAC 算法剔除錯誤匹配點,但是僅能排除部分前景區域對抖動估計的影響,效果不理想。朱娟娟等[6]提出采用基于塊的三幀間差分,利用時空一致性快速剔除運動前景區域,但是該算法只利用了時域內的運動特征,不適用大范圍場景情況;Liu 等[7]利用子空間約束平滑運動路徑,但是單個子空間無法處理包含較大前景運動的視頻;謝亞晉等[8]采用基于最小生成樹的特征點迭代篩選算法,一定程度上避免了局部運動分量的影響,但是該算法僅利用特征點的距離,剔除效果有限。
后來,楊佳麗等[9]提出結合陀螺儀進行參數估計,并利用李群流形上的卡爾曼濾波進行平滑,但該算法的穩像精度容易受設備精度的限制。Zhao 等[10]提出RTVSM(Robust Traffic Video Stabilization Method assisted by foreground feature trajectories),該算法綜合利用了前景和背景的特征軌跡實現視頻的穩定,但僅適用于交通場景,對復雜場景的適用性較差。隨著深度學習在計算機視覺方面的迅速發展,Wang等[11]提出基于StabNet 神經網絡結構的穩像模型,但是該方法需要依賴大量的數據集,而穩像數據的獲取仍比較困難。
綜上可知,傳統穩像算法對簡單場景的適用性較好,處理有大范圍和多個運動前景的情況時,仍有一定的局限性。目前,視覺顯著性技術[12-14]已在計算機視覺任務方面得到了應用,基本思想是利用計算機模擬人眼的視覺注意選擇機制,檢測圖像中密度、顏色、形狀等與周圍有顯著差異的區域,相較于背景區域,運動前景更容易被篩選出來。2006 年Zhai 等[15]提出了LC(Luminance Contrast)模型,在空域和時域內分別求解空間顯著圖和時間顯著圖,最后通過融合得到時空顯著圖,該模型能充分利用空間特征信息和時域運動信息,適合解決在動態場景下的運動目標檢測問題。
結合時空顯著性在運動目標檢測方面的獨特優勢,本文提出了一種融入時空顯著性的高精度視頻穩像算法,本文的主要工作體現在:一方面通過時空顯著性檢測技術識別運動目標;另一方面結合多網格的運動路徑進行運動補償。
1 基本原理
1.1 算法流程
本文算法的主要步驟如下:
步驟1 SURF(Speeded Up Robust Features)特征點提取與匹配。輸入不穩定視頻后,先對相鄰幀提取SURF 特征點;然后,采用BBF(Best Bin First)搜索策略和RANSAC 算法實現特征點由粗到精的匹配[5],得到初始的特征點匹配對集合。
步驟2 顯著性目標檢測。首先,利用上一步中檢測出的SURF 特征點集,生成時間顯著圖;然后,利用各像素點在圖像上的顏色對比度,生成空間顯著圖;接著,通過融合生成時空顯著圖;最后,對時空顯著圖進行二值化和閾值處理,從而識別出運動目標。
步驟3 剔除顯著性目標對應的特征點匹配對。根據視覺顯著性的檢測結果,剔除顯著性運動目標所對應的特征點匹配對。
步驟4 網格劃分與運動矢量計算。將視頻幀劃分成M×N的網格,然后計算每個網格所對應的運動矢量。
步驟5 運動軌跡生成。對所有時間點的運動矢量進行累乘,得到每個網格所對應的運動軌跡。
步驟6 多路徑平滑。采用多路徑平滑策略,實現運動路徑的平滑。
步驟7 反向補償。利用平滑后的路徑,對圖像進行反向補償,從而輸出穩定視頻。
1.2 顯著性目標檢測
時空顯著性目標檢測是該穩像算法[15]的核心環節,綜合利用特征點的時間和空間對比度信息,提高了運動目標識別的準確率,而剔除運動目標干擾后能提高穩像環節中運動估計的精度,進而影響后續的穩像精度,因此,該算法比傳統的穩像算法更有優勢。
1.2.1 利用特征點之間的運動對比度,生成時間顯著圖
鑒于一幅圖像中通常包含前景和背景目標,而它們的特征點運動對比度不同。因此,利用基于特征點之間的運動對比度信息的時間顯著圖,能初步實現前景和背景目標的有效分割,過程如下:
1)采用RANSAC 算法將特征將匹配集合G1劃分為不同的內點集,并利用內點集(要求內點集數目≥4)估算出對應的矩陣H。
假設相鄰兩幀圖像中的特征點對為{p,p′},其坐標分別為p(x,y)和p′(x′,y′)。如果特征點對{p,p′}屬于內點集,則應滿足如下關系:

否則,如果不屬于內點集,則特征點p與其他特征點間的運動對比度ε(p,H)定義為:

其中:H=,單應性矩陣H中共包含8 個待求的未知參數a1~a8。
2)計算所有特征點所對應的時間顯著值。將特征點p與其他特征點間的運動對比度疊加,得到該特征點的時間顯著值SalT(p),公式如下:
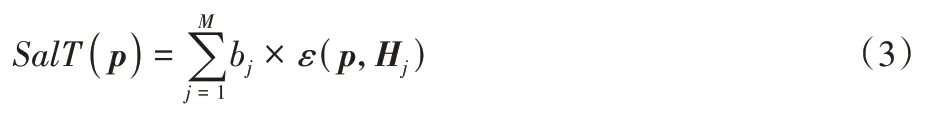
其中:M表示該場景中單應矩陣H的數量;Hj代表第j個單應性矩陣。bj表示由第j個單應性矩陣H包含的內點集所圍成的矩形區域占總圖像的比例,即:
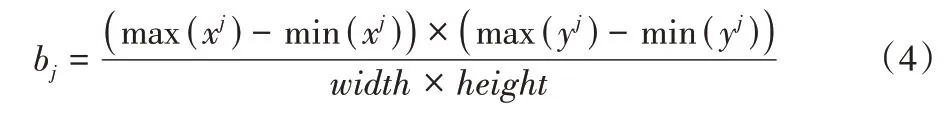
其中:bj∈[0,1];(xj,yj)表示第j個單應性矩陣H所對應的內點集中的坐標位置;width、height分別表示圖像寬度和高度。
3)計算圖像中非特征點的時間顯著值。鑒于同一矩形區域內所有的圖像像素應該具有相同的時間顯著值,所以將矩形區域內所有特征點的時間顯著值的平均作為該矩形區域內像素點的時間顯著值,即

其中:SalT(I)表示整個圖像I所對應的時間顯著值;num表示該矩形區域內包含的特征點總數;k表示特征點的編號;SalT(pk)表示第k個特征點所對應的時間顯著值。如果該像素被多個矩形區域覆蓋,則為它分配多個時間顯著值中的最大值;否則,將它的時間顯著值設置為0。
圖1 為時間顯著圖的示例。從圖1(b)可以看出:利用時間顯著圖能較好地識別出運動目標,但是識別的目標不完整,主要因為時間顯著圖僅利用了相鄰幀的運動特征信息。

圖1 時間顯著圖示例Fig.1 Example of temporal saliency map
1.2.2 利用像素點在圖像上的顏色對比度,生成空間顯著圖
圖像I中某像素Ik對所應的空間顯著值SalS(Ik),等于該像素與所有像素在顏色上的距離之和,將具有相同顏色值an的像素歸到一起,則該像素對應的空間顯著值為:

其中:fn表示顏色值an在圖像中出現的概率;n∈[0,255]。
對于圖像幀I,通過計算每個像素的空間顯著值即可得整個圖像對應的空間顯著圖SalS(I),即:

圖2 為空間顯著圖的示例。從圖2(b)、(c)中可以看出:通過空間顯著圖可以識別運動目標,但部分非運動目標也會被識別出來,識別準確率有限,主要因為空間顯著圖只利用了空間的顏色信息,而缺乏運動特征信息。
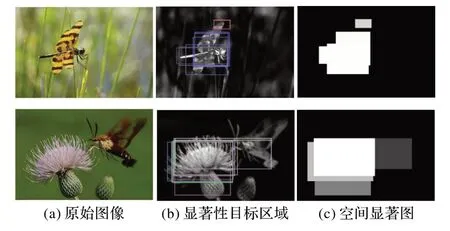
圖2 空間顯著圖示例Fig.2 Example of spatial saliency map
1.2.3 將空間顯著圖和時間顯著圖融合,生成時空顯著圖
將空間顯著圖和時間顯著圖進行融合后,得到最終的時空顯著圖Sal(I):

其中:Max、Median 分別為最大值和中值;Sal(I)為圖像幀I的時空顯著圖。
1.2.4 時空顯著圖二值化,識別出運動目標所對應的像素點
如果特征點位于運動目標上,則把該特征點對應的匹配對剔除,否則繼續保留,并將其用于后續的運動矢量求解。對于特定像素點Pm,判斷其時空顯著值Sal(Pm)與閾值T的關系,確定該像素點是否為運動目標,即
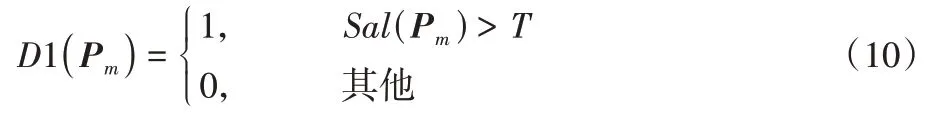
其中:T表示閾值。D1(Pm)表示二值化的結果,如果D1(Pm)為1,則說明該像素點位于運動目標上;否則,說明該像素點位于背景上。
1.3 剔除顯著性目標對應的特征點
根據1.2 節中獲得的二值化結果,如果特征點Pm位于運動目標上,則將該特征點對應的匹配對剔除;否則將繼續保留。最終生成新的匹配對集合G2,并將其用于后續運動矢量求解。
1.4 網格劃分與運動矢量的計算
1)利用1.3 節中獲得的匹配對集合G2,計算單應性矩陣并將它作為全局的運動矢量,t代表圖像的幀號。
2)將視頻幀劃分為M×N的網格,通常M=N=16,要求遍歷每個網格,如果某網格內的特征點匹配對數≥4,則利用該網格中的特征點匹配對,計算該網格對應的局部運動矢量Fi′(t),最終運動矢量Fi(t)即為全局和局部運動矢量的乘積:

其中:i表示網格的編號,i∈[1,M×N]。
3)如果某網格內的特征點匹配對數<4,則最終運動矢量Fi(t)即為全局的運動矢量。
1.5 軌跡生成與多路徑平滑
利用1.4 節中得到的每個網格在不同時刻的運動矢量Fi(t),對所有時間點的運動矢量進行累乘,得到每個網格對應的運動路徑Ci(t),計算公式如下:

其中:Fi(0),Fi()1,…,Fi(t-1)為第i網格在不同時刻運動矢量。
各網格的原始運動路徑C(t),通過最小化目標函數實現路徑的平滑,得到最優路徑P(t),即
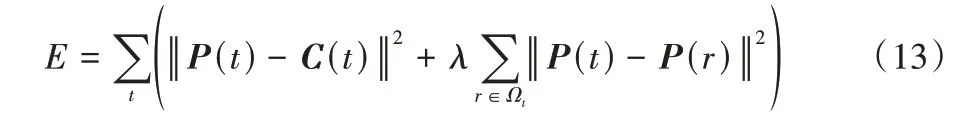
其中:E代表目標函數;λ為學習系數;r表示變量;Ωt表示第t幀的相鄰幀。
運動軌跡生成如圖3 所示。
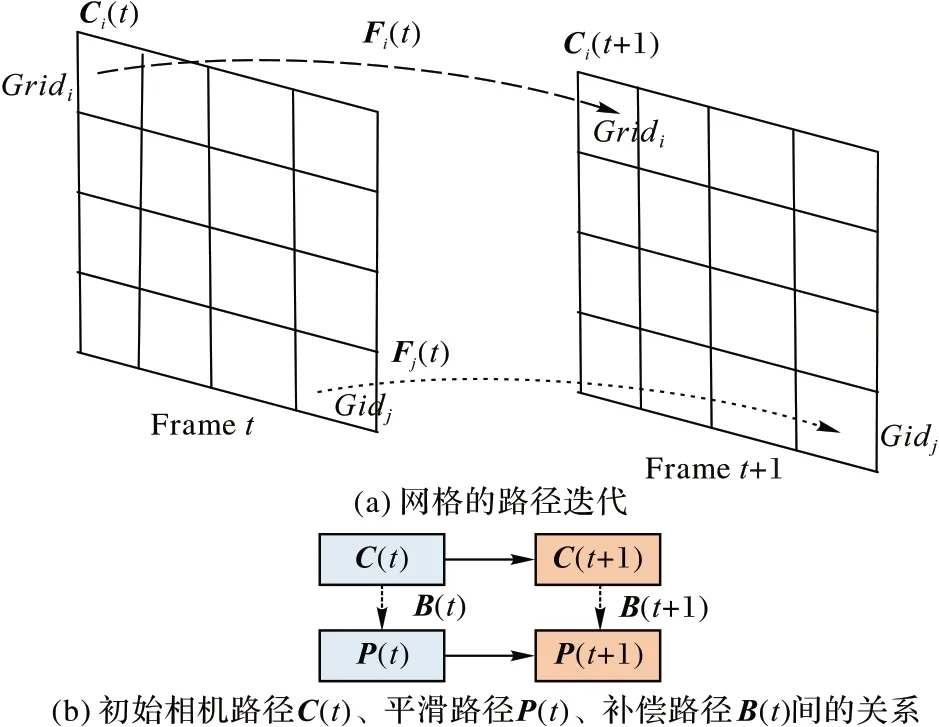
圖3 運動軌跡生成Fig.3 Motion trajectory generation
1.6 反向補償
利用每個網格的最優路徑Pi(t)和運動路徑Ci(t),計算圖像中每個網格單元的補償量Bi(t),公式如下:
然后,通過補償量Bi(t)對該網格單元的像素進行反向補償,得到穩定圖像,最終生成穩定的視頻。
2 實驗與結果分析
2.1 實驗環境與穩像評價指標
2.1.1 數據集與實驗平臺
實驗是在Intel Core i5-5200U CPU 2.20 GHz,8 GB 內存,64 位Windows 10 系統上進行,利用Matlab2016a 軟件實現算法程序,并結合“ffmpeg”多媒體處理工具對視頻/圖像數據進行轉化,本文的驗證實驗采用了如下的數據集:
1)數據集1。
Testing Set1 數據集,該自建數據集包含9 個視頻序列,其中每個視頻序列中都包含前景目標,比如包含移動的車輛或行人等。
2)數據集2。
Testing Set2 數據集[7],該數據集為公共穩像數據集,圖像分辨率為640×320,包含了7 種不同的拍攝情況:①Simple類,攝像機的運動比較簡單;②Rotation 類,攝像機存在大幅的旋轉運動;③Zooming 類,攝像機存在大幅的縮放運動;④Parallax 類,攝像機進行掃描拍攝;⑤Driving 類,利用基于車載攝像機拍攝;⑥Crowd 類,拍攝的場景存在運動前景;⑦Running 類,利用快速前進的攝像機拍攝。
2.1.2 穩像指標
目前常用的評價方法[16]分為:
1)主觀評價。主要評估視頻序列的展示性效果,視頻過渡越平滑,說明視頻的穩像效果越好。
2)客觀評價。能反映視頻穩定質量的度量標準。Battiato 等利用相鄰幀間的峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)衡量穩定后視頻的幀間保真度,PSNR 反映了參考圖像和當前圖像間的峰值信噪比。定義如下:

其中:Imax是最大亮度值;MSE(I1,I0)表示連續幀間的均方差。PSNR 值越大,說明幀間的灰度差越小,圖像穩定效果越好。
后來,佘建國等[4]又提出采用三個指標定量地評價和度量視頻穩像結果:
1)裁剪率(Cropping)指標。主要衡量穩定后圖像幀剩余的有效區域占原圖像幀的比例,值越大,說明視頻的穩像效果越好,整個視頻的裁剪率=average{所有視頻幀裁剪率}。
2)失真率(Distortion)指標。主要衡量穩定后視頻的失真程度,值越大,說明視頻的穩像效果越好,整個視頻的失真率=min{所有幀圖像的失真率}。
3)穩定度(Stability)指標。衡量穩定后視頻的穩定度,值越大,說明視頻的穩像效果越好。采用頻率分析法對視頻中的運動進行估算,基于假設:運動分量中低頻分量所占的越多,則說明視頻越穩定。
2.2 基于時空顯著性的運動目標識別結果
2.2.1 多組視頻下時空顯著性目標的識別結果
為了驗證基于時空顯著性的運動目標識別優勢,從Testing Set1 數據集中選出了兩組含有運動目標的視頻,并進行時空顯著性目標檢測實驗。
圖4 為基于時空顯著圖的運動目標檢測結果。從圖4(e)中可以看出:利用時空顯著圖能很好地將圖中的運動目標識別出來,因為時空顯著圖不僅利用了運動特征信息,而且充分結合了空間顏色對比度,因此,運動前景識別的準確率更高。
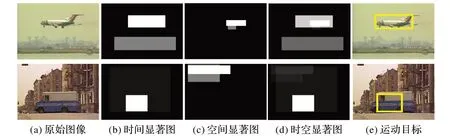
圖4 基于時空顯著圖的運動目標檢測結果Fig.4 Moving target detection results based on spatio-temporal saliency maps
2.2.2 時空顯著性目標的識別準確率評估
為了驗證時空顯著圖的優勢和算法的魯棒性,本文從數據集1 中選出了包含大范圍運動前景的視頻Video1 和包含多復雜運動前景的視頻Video2 開展實驗,并分別對比了采用時間顯著圖、空間顯著圖、時空顯著圖的運動目標識別準確率,表1 為三種顯著圖下的運動目標識別準確率結果。
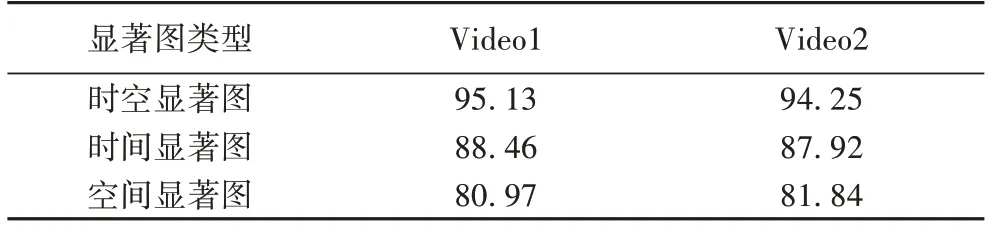
表1 三種顯著圖下的運動目標識別準確率對比 單位:%Tab.1 Comparison of moving target recognition accuracy with three saliency maps unit:%
由表1 中的數據可以看出,在兩組視頻下,利用時空顯著圖比其他兩種顯著圖的運動目標識別準確率更高,充分說明了本文算法具有較好的魯棒性優勢。
為了能進一步驗證利用時空顯著圖對運動目標的識別更具優勢,分別從數據集1(Testing Set1)和數據集2(Testing Set2)中選出兩組包含復雜運動前景的視頻,采用時空顯著圖進行實驗。根據主觀評價將運動目標的識別結果分為三類:滿意的、可接受的、失敗的,并統計每一類下結果占比,基于不同數據集的運動目標識別結果如表2 所示。通過表2 可以看出,本文算法在數據集1 和數據集2 上都獲得不錯的運動目標識別結果,也說明該算法具有較好的魯棒性。

表2 不同數據集上的運動目標識別結果Tab.2 Moving target recognition results on different datasets
2.3 各算法的穩像結果對比
為驗證本文算法在對于運動前景干擾視頻的穩像優勢,從數據集中2 選出了三組穩像測試視頻,如圖5 所示,其中:第一組為包含簡單運動前景的視頻;第二組為包含大范圍運動前景的視頻;第三組為包含多運動前景的視頻。同時,將本文算法與四種傳統的穩像算法即Subspace[17]、Epipolar[18]、Bundled-paths[7]、RTVSM[10]進行穩像精度比較。

圖5 穩像測試視頻Fig.5 Image stabilization test videos
由圖6 所示的三組視頻下各算法的穩像精度對比可以看出,在三組測試視頻中,相較于傳統算法,本文算法在Cropping、Distortion 指標上略占優勢,但在Stability 指標方面表現突出。如圖6(b)所示,在第二組測試視頻中,本文算法和RTVSM[10]的Stability 值分別為0.91 和0.83,Stability 指標提高了約9.6%;如圖6(c)所示在第三組測試視頻中,本文算法和Bundled-paths[7]的Stability 值分別為0.9 和0.85,Stability 指標提高了約5.8%。綜上可以得出結論,本文算法對于復雜運動前景干擾的情況,穩像性能表現更為突出,說明了本文算法能有效避免復雜運動目標的干擾,保證視頻的穩定度。

圖6 三組視頻下各算法的穩像精度對比Fig.6 Comparison of image stability accuracy of different algorithms in three videos
另外,為了能更加直觀地說明本文算法的穩像優勢,圖7 列出了三組視頻下本文算法與Bundled-paths 算法的穩像視覺結果對比,圖中標識出的交叉直線主要是為了便于比較、觀察。
由圖7(a)中可以看出,對于包含簡單運動前景的視頻,采用Bundled-paths 算法、本文算法后雖然結果比較接近,但是本文算法的邊緣區域更少。
由圖7(b)和(c)可以看出,相較于傳統的Bundled-paths算法,本文算法對包含大范圍和多運動前景視頻的穩像效果更好,穩像后視頻過渡更加平滑,圖像邊緣區域更少,說明了本文算法的有效性。

圖7 三組視頻下各算法的穩像視覺結果對比Fig.7 Comparison of visual image stabilization results of different algorithms in three videos
3 結語
為了解決運動前景干擾的視頻穩像問題,同時鑒于時空顯著性檢測算法在運動目標檢測方面的獨特優勢,本文提出了一種融入時空顯著性的高精度視頻穩像算法。該算法的創新點主要在于:通過時空顯著性檢測技術識別運動目標,同時結合多網格的運動路徑進行運動補償,剔除運動前景的干擾。實驗結果表明,相較于傳統的算法,本文算法在穩定度指標方面表現突出。對于大范圍運動前景干擾的視頻,本文算法相較于RTVSM 的Stability 指標提高了約9.6%;而對于多運動前景干擾的情況,本文算法比Bundled-paths 算法的Stability 指標提高了約5.8%,這充分說明了本文算法對復雜場景的穩像優勢。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
建材發展導向(2021年6期)2021-06-09 05:57:08
現代國際關系(2021年2期)2021-04-13 01:59:16
今日農業(2020年17期)2020-12-15 12:34:28
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中國外匯(2019年11期)2019-08-27 02:06:32
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
太空探索(2016年10期)2016-07-10 12:07:01
