融合多尺度多頭自注意力和在線難例挖掘的小樣本硅藻檢測
2022-08-24 06:30:50鄧杰航郭文權陳漢杰顧國生劉景建杜宇坤劉超康曉東趙建
計算機應用 2022年8期
鄧杰航,郭文權,陳漢杰,顧國生*,劉景建,杜宇坤,劉超,康曉東,趙建
(1.廣東工業大學計算機學院,廣州 510006;2.廣東工業大學自動化學院,廣州 510006;3.法醫病理學公安部重點實驗室(廣州市刑事科學技術研究所),廣州 510442)
0 引言
硅藻是一類很重要的浮游植物,硅藻檢測是溺水診斷中常用的一種重要診斷方法[1]。當法醫診斷從水中打撈起來的尸體是屬于溺水而亡還是死后拋尸時,法醫需要借助硅藻在尸體器官內的含量和種類進行輔助判斷。在人體溺水的過程中,硅藻會隨著水流被人體吸入肺中,并通過血液循環流到其他器官,如大腦和骨髓[2]。而當人體是死后被拋入水中時,人體停止了呼吸和血液循環,僅有少量的硅藻流入人體內。另外,硅藻的種類和數量會受到水質環境的影響,即不同的水質環境存在不同種類和數量的硅藻,法醫可以根據這個關系推斷出尸體的落水點。因此,硅藻檢測為診斷溺水案件提供可靠的診斷依據。
硅藻檢測一直以來都是一個具有挑戰性的任務。傳統的硅藻檢測方法是由人工透過顯微鏡觀察硅藻細胞并計數,不僅耗時耗力,還需要熟悉硅藻細胞的專家來執行,因為大部分的法醫不具備硅藻分類的專業知識。為了提高法醫對溺水診斷的速度,亟須一種使用計算機代替人工對硅藻進行識別與分類的方法。
隨著卷積神經網絡(Convolution Neural Network,CNN)的快速發展,圖像分類和目標檢測任務的性能得到了飛速提升。借助于CNN 強大的特征提取能力,Pedraza 等[3]把CNN應用到硅藻分類任務中并取得很好的分類效果。Zhou 等[4]為了充分利用人工智能和傳統硅藻檢測方法的優點,設計了一個結合傳統硅藻檢測方法的人工智能系統對硅藻進行識別,該系統的識別性能與5 位具有豐富硅藻檢測經驗的法醫學家的識別效果相媲美[5]。應用目標檢測模型Faster R-CNN(Faster Regional CNN)[6]對硅藻進行識別與定位,相較于傳統的識別方法大幅提高了識別準確率。為了設計一種用于硅藻統計的工具,Krause 等[7]應用全卷積神經網絡(Fully Convolutional Neural network,FCN)[8]對硅藻進行計數;Yu等[9]使用RetinaNet[10]對硅藻進行自動搜索。這些方法雖然從不同方面對硅藻檢測進行了研究,但它們都需要大量的訓練樣本。然而,由于溺水案件涉及倫理問題且實際上殘留在尸體器官內的硅藻數量不多,硅藻圖像的獲取相當困難。即使能夠獲得大量的硅藻圖像數據,圖像標注工作也需要專家花費大量的時間完成。因此,提出面向小樣本的硅藻檢測。
小樣本目標檢測方法可以分為四類,分別是元學習、度量學習、遷移學習和微調方法。基于元學習的方法[11-13]通過設計大量的相同視覺任務,使檢測模型學習如何學習檢測的能力。Kang 等[11]提出了一個元模型,該模型可以對從已標注的輸入圖像提取的特征進行重新加權。模型預測器可根據重新加權的特征有效地對只有少量樣本的類別進行分類和定位。基于度量學習的方法[14-15]利用待預測圖像與參考圖像之間的距離,判斷待預測圖像的種類。Karlinsky 等[15]提出了一個度量學習模塊,該模塊評估每個預測框里的特征與從少量標記圖像中提取的特征的相似度,并用這個度量學習模塊取代了Faster R-CNN 的分類分支。基于遷移學習的方法[16-17]將從源域中學習到的預訓練權重泛化到目標域,其中,源域具有大量的訓練樣本,目標域僅有少量可用的訓練樣本。Chen 等[17]提出了遷移知識正則化和背景抑制正則化以解決直接在少量標記圖像上訓練時的過擬合問題。基于微調的方法[18-19]主要關注模型對小樣本訓練集的微調過程。微調技術實現簡單,且通過對模型進行簡單微調即可在Pascal VOC(Visual Object Classes)2007 數據集[20]的小樣本設置上顯著提高檢測精度,并且優于基于元學習的方法。因此,本文選擇基于微調的方法作為小樣本硅藻檢測的基線模型。
TFA(Two-stage Fine-tuning Approach)[18]是一個基于微調方法的兩階段模型,只需微調模型的最后一層且模型的訓練策略簡單,在Pascal VOC[20]數據集和MS COCO(Common Objects in COntext)[21]數據集上的檢測性能都比基于元學習的方法[11-13]好。因此,本文基于TFA 提出一種融合多尺度多頭自注意力(Multi-scale Multi-head Self-attention,MMS)和在線難例挖掘策略(Online Hard Example Mining,OHEM)[22]的小樣本硅藻檢測(MMS and OHEM based Few-shot Diatom Detection,MMSOFDD)模型。該模型針對小樣本的硅藻識別問題,將基于CNN 的ResNet-101[23]的最后三個空間3 × 3 卷積替換為多頭自注意力,形成一個基于Transformer[24]的特征提取網絡 BoTNet-101(Bottleneck Transformer Network-101)[25]。通過改進其中的多頭自注意力為多尺度多頭自注意力,稱之為多尺度BoTNet-101。由多尺度BoTNet-101 生成的特征圖經過池化等處理后,在嵌入OHEM的模型預測器中進行預測。采用從高清電鏡下采集的復雜背景硅藻圖像進行實驗,驗證了本文模型對小樣本硅藻檢測的有效性。
1 MMSOFDD
在本文中,為了實現小樣本硅藻目標檢測,在少量硅藻訓練樣本的情況下,基于TFA 模型提出了融合多尺度多頭自注意力和OHEM 的小樣本硅藻檢測模型MMSOFDD。該模型的總體架構如圖1 所示。
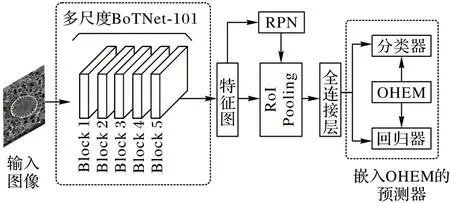
圖1 MMSOFDD的總體架構Fig.1 Overall architecture of MMSOFDD
從圖1 中可以看出,MMSOFDD 模型的總體架構采用Faster R-CNN[6]的架構,主要的組成部分包括特征提取器、區域生成網絡RPN(Region Proposal Network)、RoI(Region of Interest)池化、全連接層和預測器。在MMSOFDD 中,特征提取器是一個基于Transformer 的多尺度BoTNet-101,其內部結構如圖2 所示。區域生成網絡RPN 的作用主要是通過卷積運算對圖像錨框進行前景和背景的分類及對錨框位置的粗調整。預測器分為目標分類器和邊界框回歸器。在目標分類器中,使用余弦相似度計算預測值與目標值之間的距離,使用交叉熵損失函數計算分類損失。交叉熵損失函數的定義如下:

其中:C為類別數;gi為真實標簽,表示當前的真實類別為第i類;pi為模型輸出的預測值,表示預測為類別i的概率。
邊界框回歸器對錨框的位置進行細調整,使錨框更加準確地把圖像目標標記出來,使用SmoothL1損失函數計算回歸損失,定義如下:

其中:x表示預測邊界框的坐標向量與真實邊界框的坐標向量的差,坐標向量包含邊界框的中心坐標、寬度和高度。
圖1 中的圓角虛線框表示本文的主要改進工作,分別是多尺度BoTNet-101 和嵌入OHEM 的預測器。
1.1 多尺度BoTNet-101
BoTNet-101 是一個基于Transformer 的新型骨干網絡,通過把圖2(a)ResNet-101 結構的Block 5 的3 × 3 卷積替換成圖2(b)中Block 5 的多頭自注意力(Multi-Head Self-Attention,MHSA)而形成,該模型架構簡單但功能強大。將圖2(b)BoTNet-101 的多頭自注意力改進為多尺度多頭自注意力,即可得到多尺度BoTNet-101,如圖2(c)所示。在多尺度BoTNet-101 中,同時使用CNN 和多頭自注意力機制提取圖像特征,能夠有效地結合圖像的局部特征和全局特征。其中:Block 1、Block 2、Block 3 和Block 4 使用CNN 處理大尺度圖像并提取局部特征信息,生成低分辨率的特征圖;Block 5 則基于多頭自注意力對低分辨率特征圖的全局信息進行聚合。多尺度BoTNet-101 把CNN 和Transformer 的優勢結合起來,提升骨干網絡的特征提取能力。多頭自注意力的運算過程如圖3 所示,其中,⊕表示逐元素相加,?表示矩陣乘法。
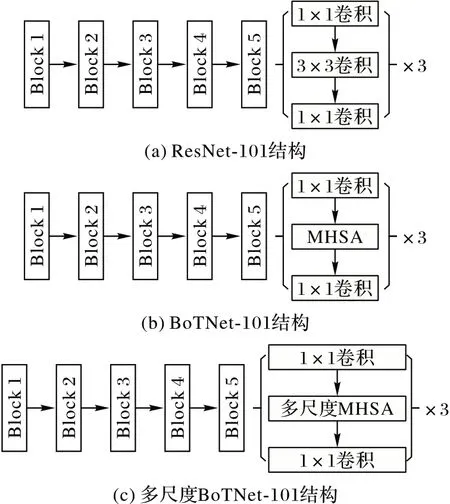
圖2 特征提取網絡的結構變化Fig.2 Structure change of feature extraction network
在圖3 中,輸入特征圖與1 × 1 卷積核WQ、WK、WV相乘分別得到特征圖q、k、v。Rh和Rw分別是使用二維相對位置自注意力[26-27]計算得到的垂直和水平方向上的相對位置信息,將Rh和Rw調整大小并相加融合得到位置編碼r。通過計算qkT+qrT得到空間敏感的相似性特征,讓多頭自注意力機制關注合適區域,其中T 表示矩陣的轉置運算。注意力得分由空間敏感的相似性特征經過Softmax 運算得到,并與v相乘作為多頭自注意力的輸出。
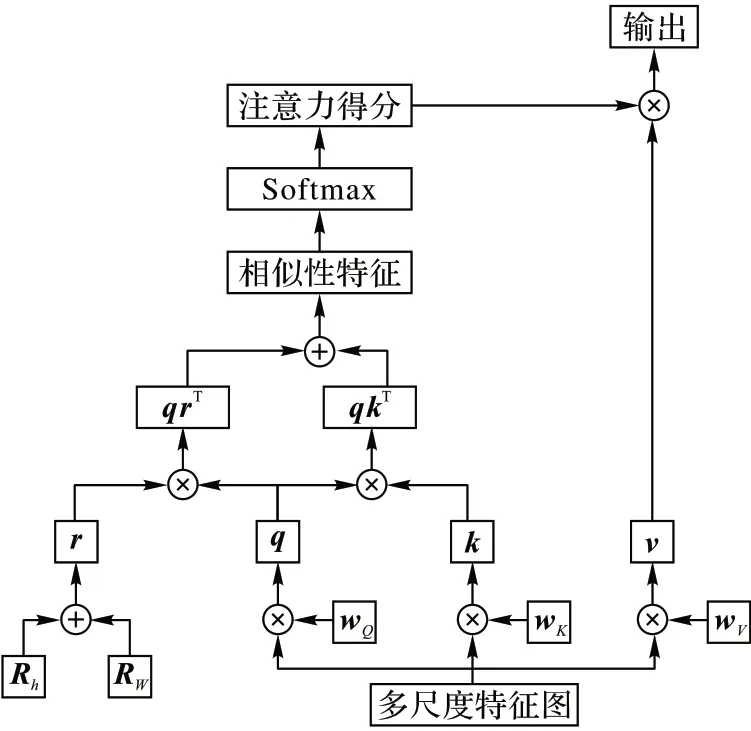
圖3 多尺度多頭自注意力的運算過程Fig.3 Multi-scale multi-head self-attention calculation process
在多頭自注意力機制中,要求輸入固定尺寸的特征圖。因此,訓練樣本在輸入后需要縮放到固定的尺寸。檢測模型基于該縮放尺度生成相應的預測框,當這些預測框在原始圖像上標定目標時,預測框的位置和大小會出現偏差。另外,由于骨干網絡對單尺度圖像提取到的特征信息不夠豐富,模型容易出現對圖像目標的誤檢和漏檢的情況,導致模型的檢測精度下降。因此,本文根據硅藻圖像的特性,設計并收集硅藻圖像采集的所有尺寸,在模型訓練的過程中,根據當前的圖像大小選擇對應的多頭自注意力層,即多尺度多頭自注意力。多尺度多頭自注意力可以兼容CNN 對不同尺寸的輸入圖像生成的特征圖,使特征提取網絡能夠提取更加豐富的圖像特征。
1.2 嵌入OHEM的預測器
在小樣本目標檢測中,可用的訓練資料有限,檢測模型不能利用大量的訓練樣本逐步更新模型參數,所以每一次的參數更新都至關重要。在小樣本硅藻檢測中,硅藻目標與背景存在類別不平衡,為了讓少量的硅藻訓練樣本得到高效利用,在模型預測器中嵌入OHEM。通過挖掘難以識別的目標區域并基于此更新參數,模型的檢測性能可以得到有效提升。
OHEM 是一種能夠自動選擇難以識別的樣本進行訓練的方法,可用于解決簡單樣本和難識別樣本之間的類別不平衡問題。OHEM 的基本結構如圖4 所示,由特征提取器和RPN 運算輸出的N個感興趣區域RoIs 作為輸入,分別經過分類損失計算和邊界框損失計算,得到每個RoI 的分類損失值和回歸損失值。將分類損失值與回歸損失值之和從大到小排序,損失值之和大的為難識別樣本。由于位置上相鄰的RoI 會輸出相近的損失值,其表示的實際上是同一個目標實例。因此,OHEM 使用非極大值抑制(Non-Maximum Suppression,NMS)算法[28]移除交并比(Intersection over Union,IoU)大于一定閾值的RoI。最后選擇B個損失值最大的RoI 作為難例樣本,剩下的RoI 則作為非難例樣本。難例樣本將用于反向傳播進行參數更新。
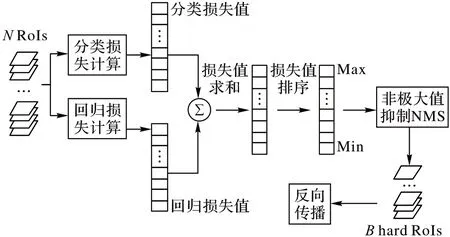
圖4 OHEM結構Fig.4 Structure of OHEM
2 模型訓練
2.1 數據集
2.1.1 Pascal VOC數據集
為了讓模型學習類不可知的特征,使用Pascal VOC 2007+2012 的train/val 數據集中的15 個類別作為基礎訓練階段的訓練集,其中包含aeroplane、bicycle、boat、bottle、car、cat、chair、diningtable、dog、horse、person、pottedplant、sheep、train、tvmonitor。每一個類別的圖像數量以及實例個數如表1所示。
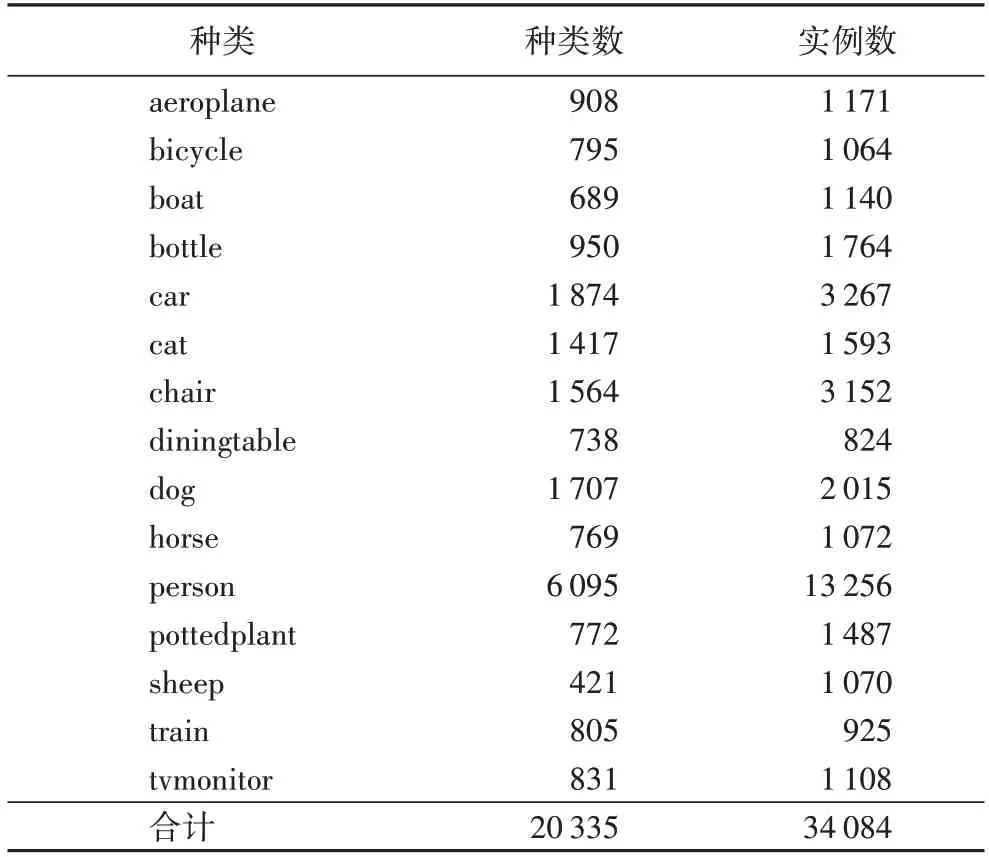
表1 Pascal VOC數據集的15類分類明細Tab.1 Classification details of 15 classes in Pascal VOC dataset
2.1.2 硅藻數據集
為了有效評估本文模型在僅用少量訓練樣本的條件下,對硅藻進行識別與定位的性能,通過高分辨率掃描電子顯微鏡對硅藻進行成像并構建了一個硅藻數據集。數據集包含的硅藻種類及其對應的數量如表2 所示。其中,硅藻圖像的種類分別有小環藻、舟形藻、菱形藻、針桿藻、異極藻、橋彎藻、卵形藻和直鏈藻,總量為2 606 張。小環藻、舟形藻、菱形藻和直鏈藻各有400 張,針桿藻有280 張,異極藻有220 張,橋彎藻有346 張,卵形藻有160 張。實例表示硅藻目標,一張硅藻圖像中可存在多個實例。在本文所構建的硅藻數據集中,硅藻實例的總量為2 652 個,其中小環藻有417 個,舟形藻有404 個,菱形藻有407 個,針桿藻有283 個,異極藻有222個,橋彎藻有347 個,卵形藻有161 個,直鏈藻有411 個。各類硅藻圖像如圖5 所示。

圖5 硅藻樣本圖像Fig.5 Diatom sample images
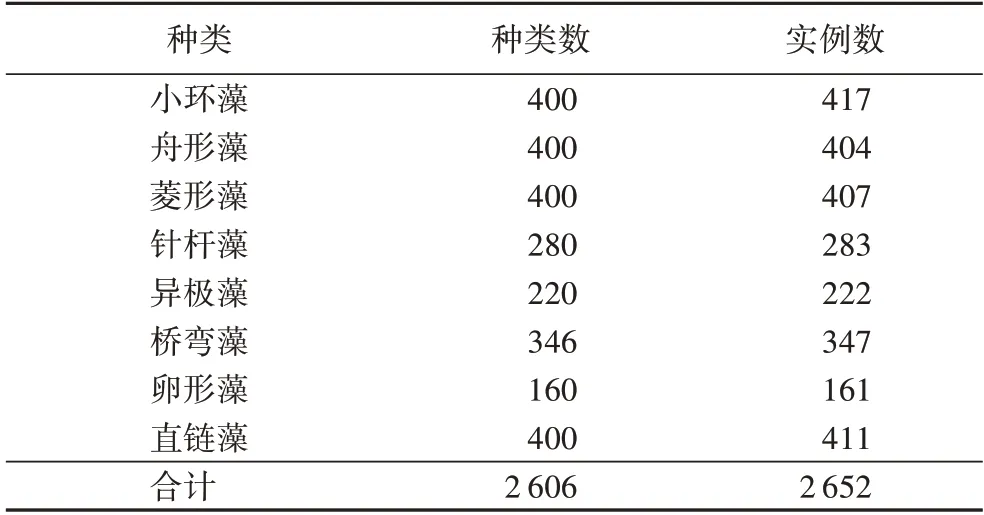
表2 硅藻數據集統計信息Tab.2 Diatom dataset statistics
本文研究的是10-shot 硅藻檢測,即從每一類硅藻圖像中選擇10 個硅藻實例作為訓練樣本。通過設置固定的隨機種子,在每一類硅藻圖像中隨機選擇10 個硅藻實例,共80個,小樣本硅藻訓練集數據分布如表3 所示。測試集是由除訓練集以外的所有硅藻實例組成,具體分布如表4 所示。
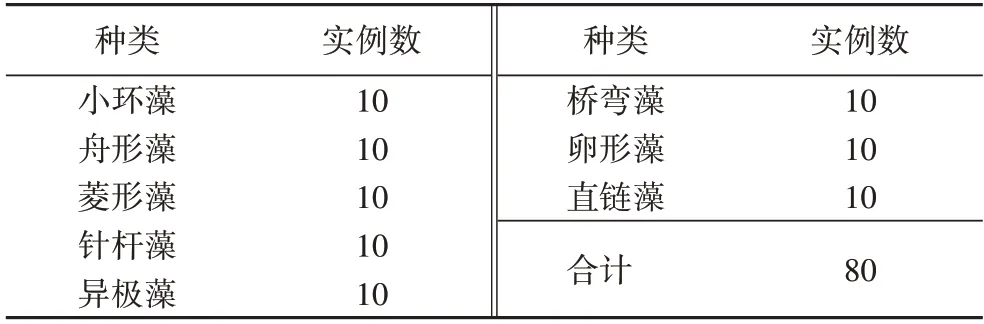
表3 小樣本硅藻訓練集Tab.3 Few-shot diatom training set
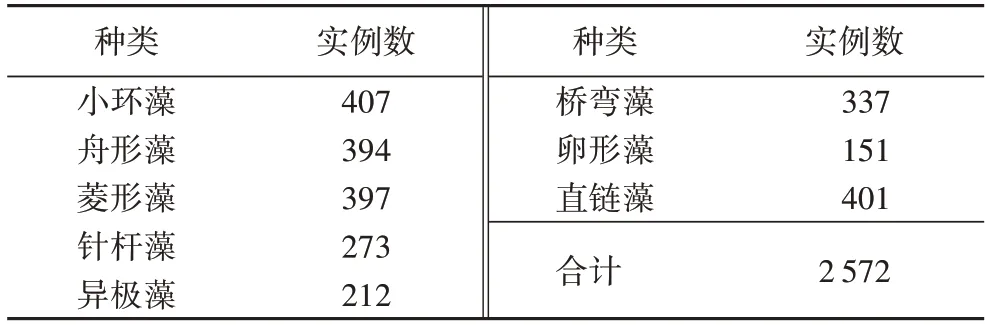
表4 硅藻測試集Tab.4 Diatom test set
2.2 小樣本目標檢測設置
在本文中,硅藻小樣本目標檢測的實驗設置遵循由Wang 等[18]所提TFA 的實驗設置。在小樣本目標檢測中,數據集可以分為基類Cb和新類Cn。基類是具有大量可用訓練樣本的類別,一般用于預訓練目標檢測模型。新類,也稱為未知類,指在基類預訓練中沒有參與訓練的類別,即Cb∩Cn=?,而且新類中每一類只有K(K一般小于等于10)個可用標注樣本。小樣本目標檢測的目標是把模型從大量的基類中學習到的知識泛化到新類,使新類在少量訓練樣本的條件下能夠獲得一個檢測性能良好的目標檢測模型。因此,本文的基類設置采用TFA 中使用的Pascal VOC 數據集的15 個類別,新類設置為8 類硅藻。
2.3 改進訓練策略
原始TFA 的訓練策略分為兩個階段:1)基礎訓練階段,使用大量的訓練數據訓練整個模型并輸出預訓練權重用于小樣本微調階段的初始化;2)小樣本微調階段,固定特征提取器,使其不進行參數更新,只微調模型的最后一層。在基類為Pascal VOC 數據集的15 個類別、新類為8 類常見硅藻的設置下,將原始TFA 的訓練策略應用到小樣本硅藻檢測中,得到的平均精度均值(mean Average Precision,mAP)約為27.60%。導致硅藻類別的檢測精度低的原因是硅藻圖像與Pascal VOC 數據集的圖像存在較大的差異,在特征提取器固定的情況下,檢測模型無法學習硅藻目標的特征表示,從而出現使用舊的知識難以預測新的類別的情況。因此,本文模型對原始TFA 模型的訓練策略進行改進。通過開啟骨干網絡和RPN 的參數更新,特征提取網絡能夠在模型訓練的過程中學習硅藻的特征表示,從而使檢測模型在預測的過程中能夠準確地識別硅藻,提高檢測模型對硅藻的檢測精度。
2.4 模型訓練過程
模型的訓練過程分為兩個階段:1)模型基礎訓練階段,該階段涉及的網絡模塊如圖6 灰色模塊所示;2)模型微調訓練階段,該階段涉及的網絡模塊為圖6 中的所有模塊。在圖6 中,灰色模塊參與了模型基礎訓練。整個網絡參與了模型的微調訓練。
1)為了使模型學習類不可知的特征,即與類別不相關的特征,在模型基礎訓練階段,使用大型圖像數據集Pascal VOC 的15 個類別共20 335 張圖像,34 084 個目標實例作為訓練集。該階段使用的檢測模型是Faster R-CNN,其組成部分有骨干網ResNet-101、區域提議網絡RPN、RoI 池化、全連接層以及由分類器和邊界框回歸器構成的預測器。其中ResNet-101 由5 個Block 組成,每個Block 各有1、9、12、69、9層卷積層,共100 層。在模型預測器中,分類器網絡由全連接層和分類函數組成,邊界框回歸網絡由全連接層和回歸函數組成。通過大型圖像數據集Pascal VOC 對整個模型進行訓練,圖6 中灰色模塊的參數基本固定,即圖像的類不可知特征。對于預測器學習到的參數,在模型微調階段將會被隨機初始化。
2)為了充分利用硅藻圖像的局部和全局信息以及解決簡單樣本和難識別樣本之間的類別不平衡問題,在模型微調訓練階段,把圖6 骨干網的Block5 的3 × 3 卷積層替換為多尺度多頭自注意力機制,以及在模型預測器中引入OHEM 策略,形成MMSOFDD 模型。在此階段,訓練集更改為8 類硅藻圖像數據集,其中每一類硅藻只有10 個實例用于訓練,共80個。在微調模型進行訓練之前,為了保留基礎訓練得到的與目標類別不相關的特征,將基礎訓練階段的結果對MMSOFDD 模型進行初始化,即保持圖6 灰色模塊的卷積層參數不變。為了避免基礎訓練的Pascal VOC 的15 個類別分類特征對微調訓練8 類硅藻類別特征造成負面影響,隨機初始化分類器與回歸器的參數權值,同時調整學習率、迭代次數等超參數。由于硅藻圖像的目標與背景的概貌和細節與Pascal VOC 數據集的圖像之間相差巨大,因此,在微調階段,網絡所有的參數都需要更新。模型微調階段開始訓練,硅藻圖像經過放縮后,多尺度BotNet-101 對其進行特征提取。首先,通過多尺度BotNet-101 的Block1、Block2、Block3 和Block4 的卷積層獲取硅藻目標的局部特征信息并生成低分辨率的特征圖;其次,通過Block5 的多尺度多頭自注意力提取該低分辨率的特征圖的全局特征信息得到特征圖;然后,通過RPN 和RoI 池化處理后,得到包含硅藻目標信息的RoI;分別計算這些RoI 的分類損失值與邊界框回歸損失值的和,采用OHEM 策略,選擇損失值和最大的若干個RoI 進行參數更新;最后,確定MMSOFDD 模型的參數。
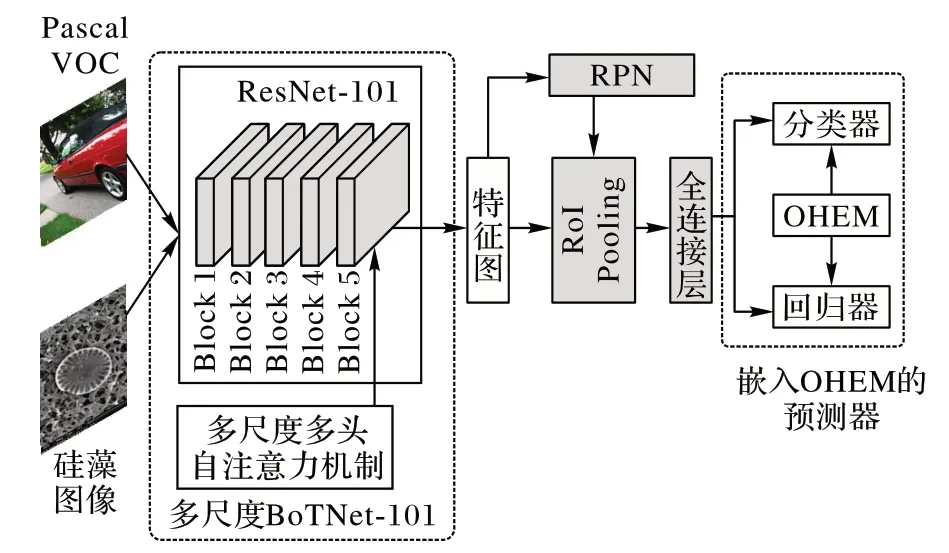
圖6 網絡訓練結構Fig.6 Structure of network training
3 實驗與結果分析
3.1 實驗設置與評價指標
本文實驗基于64 位操作系統Ubuntu 18.04 和PyTorch 框架完成,處理器型號為Intel Core i9-10900X,16 GB 內存。顯卡型號為Nvidia GeForce GTX 3090,24 GB 內存,采用Nvidia CUDA 11.0 加速工具箱。
在訓練過程中,輸入數據的批大小設置為8,使用隨機梯度下降優化器(Stochastic Gradient Descent,SGD)進行訓練,其中,權重衰減為0.000 1,動量參數為0.9;學習率策略為step,其中基礎學習率是0.000 5,學習率調整倍數γ 是0.1,學習率變化步長為18 000,最大迭代次數為20 000,當訓練迭代次數小于18 000 時,學習率為0.000 5,訓練迭代次數大于等于18 000 時,學習率為0.000 05。
為了驗證本文實驗的有效性,本文采用Pascal VOC 標準的平均精度(Average Precision,AP)、平均精度均值(mAP)和8 類常見硅藻的檢測精度的標準差作為小樣本硅藻檢測實驗的評價指標。
3.2 消融實驗結果分析
為了驗證新增模塊在MMSOFDD 模型中具有提升模型檢測性能的作用,分別獨立引入多尺度多頭自注意力和嵌入OHEM 進行實驗,并結合兩個模塊進行實驗以探索兩者之間的相互作用。實驗定性結果如圖7 所示,其中:改進方法1 表示只引入多尺度多頭自注意力而沒有嵌入OHEM;改進方法2 表示只嵌入OHEM 而不引入多尺度多頭自注意力;MMSOFDD 表示同時引入多尺度多頭自注意力和嵌入OHEM,紅色矩形框表示識別錯誤,綠色矩形框表示識別正確。以下實驗均在調整訓練策略后進行。
在圖7 的例圖1 中,圖像背景非常粗糙,存在很多大小不一且不同形狀的干擾,這些干擾的分布隨機,亮度變化沒有規律。其中有一個小環藻在中央,小環藻的部分邊緣被遮擋導致部分紋理缺失。從圖7 可以看出:改進方法1 能夠充分提取圖像的特征提高TFA 的識別能力,從而正確識別硅藻。雖然改進方法2 漏檢了圖7 中例圖1 的硅藻,但當改進方法1和改進方法2 結合在一起時,MMSOFDD 既能夠正確檢測也能夠提高識別準確率。在圖7 的例圖2 中,菱形藻的形狀比較扁,內部紋理非常模糊且圖像背景復雜。TFA 算法和改進方法1 把菱形藻誤識別為舟形藻,改進方法2 和MMSOFDD則檢測正確且MMSOFDD 的識別準確率更高,說明嵌入OHEM 既能夠正確識別TFA 中難識別的硅藻目標,也能夠與多尺度多頭自注意力相互作用,提高識別準確率。圖7 中的例圖3 的硅藻目標清晰度低且紋理丟失,與背景十分相似且圖像左上角有大面積的白色干擾,圖7 中的例圖4 硅藻目標雖然形狀完整,但背景十分復雜,亮度分布不均勻。TFA 方法對圖7 中的例圖3 和例圖4 中的硅藻都識別錯誤,改進方法1 和改進方法2 對其都識別正確,而MMSOFDD 對硅藻識別正確且準確率比改進方法1 和改進方法2 都高。因此,改進方法1 和改進方法2 都能夠有效提高TFA 的檢測精度,結合兩者能夠起到相互增益的作用,互補雙方的檢測能力,MMSOFDD 可以獲得更高的檢測性能。

圖7 不同模塊在消融實驗中定性結果Fig.7 Qualitative results of different modules in ablation experiment
實驗定量結果如表5 所示。

表5 不同模塊的mAP比較Tab.5 Comparison of mAP of different modules
為了進一步定量地檢驗模型的性能,統計了不同模塊的mAP 值,如表5 所示。從表5 中可以看出,引入多尺度多頭自注意力后,圖像的局部信息和全局信息得到有效利用,改進方法1 的mAP 比TFA 提升了1.47 個百分點,精度達到65.18%。改進方法2 基于ResNet-101 提取圖像特征,在預測器中嵌入OHEM 解決前景目標和背景之間的不平衡問題,檢測精度達到66.83%,比TFA 提升了3.12 個百分點。從改進方法1 和改進方法2 中可以看出,多尺度多頭自注意力和OHEM 都對模型的檢測精度有所提升,因此,MMSOFDD 把多尺度多頭自注意力和OHEM 結合起來進行實驗,得到檢測精度69.60%。與TFA、改進方法1 和改進方法2 相比,MMSOFDD 分別提升了5.89、4.42 和2.77 個百分點,證明結合多尺度多頭自注意力與OHEM 對模型的檢測效果的提升有相互增益的作用。上述實驗結果表明,本文提出的MMSOFDD 能夠在少量訓練樣本的條件下有效提升硅藻的檢測精度。
3.3 對比實驗結果分析
為了進一步驗證MMSOFDD 能夠在訓練樣本量少的條件下獲得較高檢測精度,將其與FSRW(Few-Shot Re-Weighting)[11]、Meta R-CNN[13]、FSIW(Few-Shot In Wild)[12]、Context-Transformer[16]、MPSR(Multi-scale Positive Sample Refinement)[29]、DeFRCN(Decoupled Faster R-CNN)[30]、FSCE(Few-Shot object detection via Contrastive proposals Encoding)[19]小樣本目標檢測模型在10-shot 的訓練集設置下進行比較分析。實驗結果如表6 所示。
從表6 可以看出:
1)在8 類硅藻中,小環藻、針桿藻、卵形藻和直鏈藻在所有模型上的精度都比較高,而舟形藻、菱形藻、異極藻和橋彎藻的精度都比較低。因此,保證小環藻、針桿藻、卵形藻和直鏈藻的檢測精度的同時提升舟形藻、菱形藻、異極藻和橋彎藻的檢測精度是關鍵。MMSOFDD 對舟形藻、菱形藻和異極藻的檢測精度分別是55.37%、59.1%和62.60%,是所有模型中最高的,對比其他模型都有大幅度的提升。橋彎藻的檢測精度相較于Meta R-CNN、FSIW、Context-Transformer 和MPSR 也有較大的提升。從評價指標平均精度均值mAP 來看,MMSOFDD 達到69.60%,相較于FSRW、Meta R-CNN、FSIW、Context-Transformer、MPSR、DeFRCN 和FSCE,分別提高了2.71、8.00、8.70、56.02、8.69、4.96 和8.34 個百分點,說明MMSOFDD 對硅藻檢測的綜合性能更高。
2)從算法的魯棒性上看,魯棒性越好的模型,對不同硅藻的識別率AP 的標準差越接近零。表6 中統計了不同模型對不同硅藻的識別率AP 的標準差。雖然Context-Transformer模型獲得AP 的標準差達到4.42,但其各類硅藻的檢測精度較低,mAP 只有13.58%,不宜用于硅藻檢測。MMSOFDD 的標準差為14.67,低于除Context-Transformer 以外的所有對比模型,說明MMSOFDD 模型對8 類硅藻的檢測精度更為平衡,模型的魯棒性更好,在實際應用中的應用范圍更加廣泛。
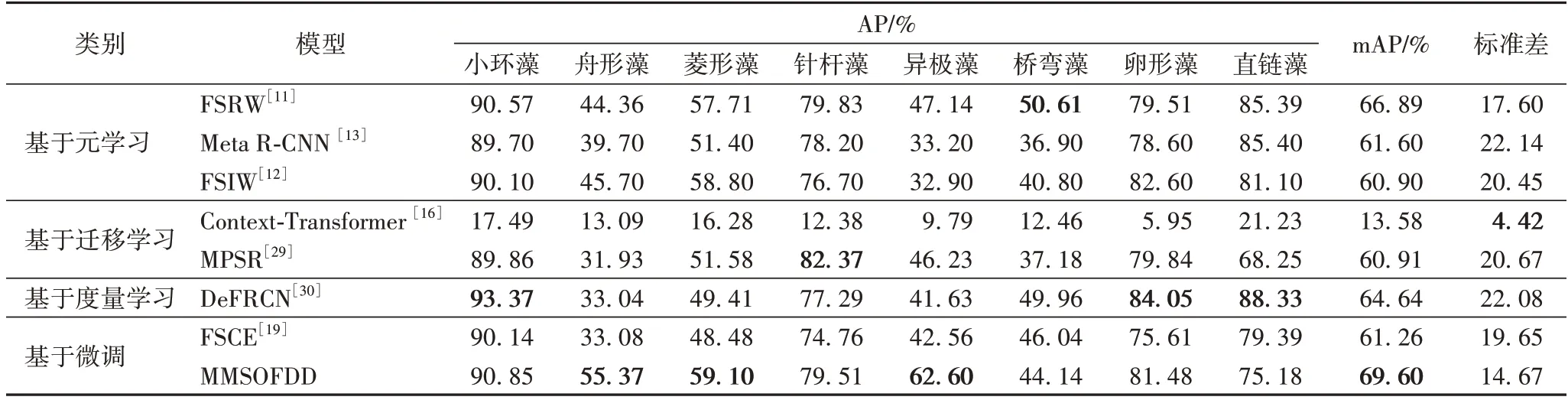
表6 不同模型對8類硅藻的AP、mAP和AP標準差的比較Tab.6 Comparison of AP,mAP and standard deviation of AP among different models for 8 species of diatoms
因此,在法醫診斷溺水案件中,即使硅藻圖像的獲取和標注困難,MMSOFDD 能夠利用少量的硅藻樣本訓練得到一個精度較高的硅藻檢測器,有助于提高法醫的診斷速度。
4 結語
把小樣本目標檢測應用到硅藻檢測中,能夠有效解決硅藻樣本獲取困難的問題,有助于提高法醫診斷溺水案件的速度,但目前小樣本目標檢測仍然是一個挑戰。本文基于兩階段微調方法TFA 進行改進,引入基于Transformer 的特征提取網絡BoTNet 并將其改進為多尺度BoTNet-101,在預測器中嵌入OHEM 提出一個融合多尺度多頭自注意力和OHEM 的小樣本硅藻檢測模型MMSOFDD。實驗結果表明,多尺度BoTNet-101 結合了CNN 和Transformer 的優勢,同時使用圖像的局部特征和全局特征,在訓練樣本量少的條件下能夠充分地利用訓練樣本。同時,多尺度BoTNet-101 中的多尺度多頭自注意力能夠處理CNN 輸出的不同尺寸的特征圖,從而提取更加豐富的信息。在預測器中加入OHEM 可以自動選擇出難識別的樣本并針對其進行訓練,有效解決前景目標與背景之間的類別不平衡問題。通過與其他小樣本目標檢測模型進行對比實驗驗證了MMSOFDD 有效地提高對硅藻的檢測能力,在10-shot 的條件下能夠達到較好的檢測效果,未來可以基于MMSOFDD 繼續提高對其他硅藻的檢測精度。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
