指標預警系統設計與分析
2022-08-29 02:20:46劉利朋
現代信息科技 2022年12期
關鍵詞:定義
劉利朋
(太平金融科技服務(上海)有限公司,上海 201201)
0 引 言
隨著大數據技術的興起和發展,越來越多的企業開始擁抱大數據,大數據技術在跟企業現有技術的融合也越來越深入。從2017年開始保險行業發展減緩,業績的不理想亟須新的發展動力,而大數據分析正好為其提供了有力的理論支持。大數據技術逐步融入現有的技術體系中,既對客戶的行為分析、特征分析、產品需求分析等提供了有力支撐,也對公司整體業績發展中出現的問題及時預警,并提供發現問題、分析問題、解決問題一攬子解決方案。筆者僅以一個約十五年數據分析經驗的從業者角度,分享一下這些年積累的數據分析設計經驗。
1 指標預警系統特點
指標預警系統既不同于傳統的數據分析系統多以制式報表等方式展示,也不同于互聯網領域的數據分析多以hadoop等為基礎的分布式計算。而是基于現有資源和數據,同時采用大數據技術的“混搭”模式,以指標數據為分析對象,以指標變化為分析內容,以影響指標變化數據為溯源途徑,采用因果分析法進行問題原因逐層遞進,從而逐步發現問題根源,進而達到解決問題的目標。具體內容為:
(1)分析模型源于整體數據。傳統數據分析均來自經營分析會議,而經營分析會議的數據來自相關部門對關注數據的提取和分析,因限于系統計算能力,只能提取部分數據進行分析,現在采用新系統,我們對全系統數據做整體統計分析,把全部加工后的分析數據導入分析模型,從而基于比較完整的數據,得出更準確地預警結果。
(2)發現問題源于整體數據。原來發現問題主要靠業績達成率和排名,而業績的統計往往比較滯后,以月度或季度為統計周期,很難及時發現問題。現在采用新系統,數據既有橫向同級機構比較,也有歷史數據縱向比較,還可以下鉆到其他維度。相對以前,可以更容易更迅速地發現問題。
(3)分析問題源于整體數據。由于大數據技術支撐,分析指標數據異常的時候不僅可以從多個維度分析問題,還可以同時查看對應機構對應時間區間的關聯指標,找出影響指標的指標,進而更準確地分析和定位問題。
(4)解決問題源于整體數據。發現和分析問題的過程既可以發現問題機構,也可以同時找到對應的優秀機構,若干個關聯指標對應比較,可確定問題根源及應對措施,同時結合問題機構的反饋,從而得出合理的解決方案。
筆者有幸主持實施的2021年某壽險公司指標預警系統的建設項目,本項目完成后得到了客戶的廣泛好評,形成了業務活動產生數據—數據分析反饋業務經營活動情況—業務根據經營情況改善經營決策的良性循環。本文以此為實例,進行一些探討研究,希望借此能提供一些有用的經驗。
2 指標預警系統概述
2.1 功能概要說明
指標預警系統分為指標定義、指標計算、指標展示、指標推送四個模塊,指標定義和指標計算即是本文所說的數據分析模型。
指標定義模塊包括指標定義、維度定義、時間定義、維度組合定義等。主要用于管理指標計算模塊的計算范圍、計算時間等。此模塊未來會擴展為指標管理平臺,作為我們數據分析系統的統一指標管理系統。
指標計算模塊,根據指標定義的指標,對沒有計算而又需要計算的指標,按照時間定義確定時間范圍,按照維度定義確定數據范圍,進行數據計算。
數據展示模塊,把數據計算結果展示到頁面,供用戶使用。
數據推送模塊,根據訂閱關系和預警閾值,推送不同的預警消息給不同的用戶。整體來說指標預警系統根據指標定義進行指標計算,計算完之后進行指標展示,對于異常指標進行消息推送。指標預警系統主流程如圖1所示。
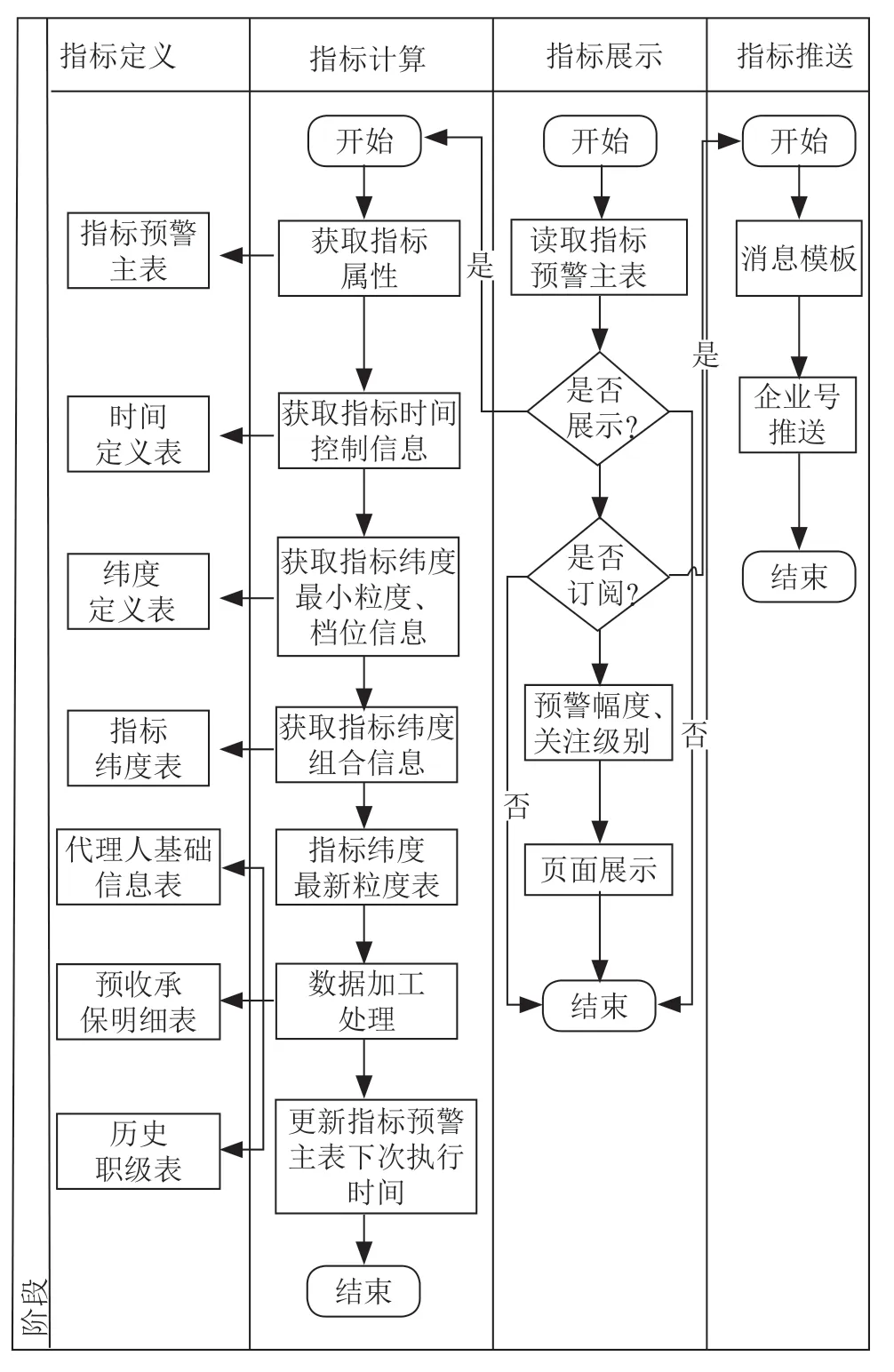
圖1 指標預警系統主流程圖
2.2 指標預警系統整體方案
2.2.1 架構設計
指標預警系統采用傳統數據庫和大數據相結合的模式。人力、產能等數據量較小的指標,因現有數據庫可以支持,直接集成現有程序和數據。出勤率等考勤指標涉及刷臉等數據量較大數據則充分利用大數據的數據計算能力來計算。大數據計算能力的引入也為未來指標擴展儲備算力。
指標預警定位為獲取各個業務系統數據進行指標計算,通過跟歷史數據進行比較縱向,與同級機構進行橫向比較,以便及時發現異常,并對異常信息進行溯源分析。同時進行推送預警消息給對應的訂閱人和責任人,功能架構如圖2所示。
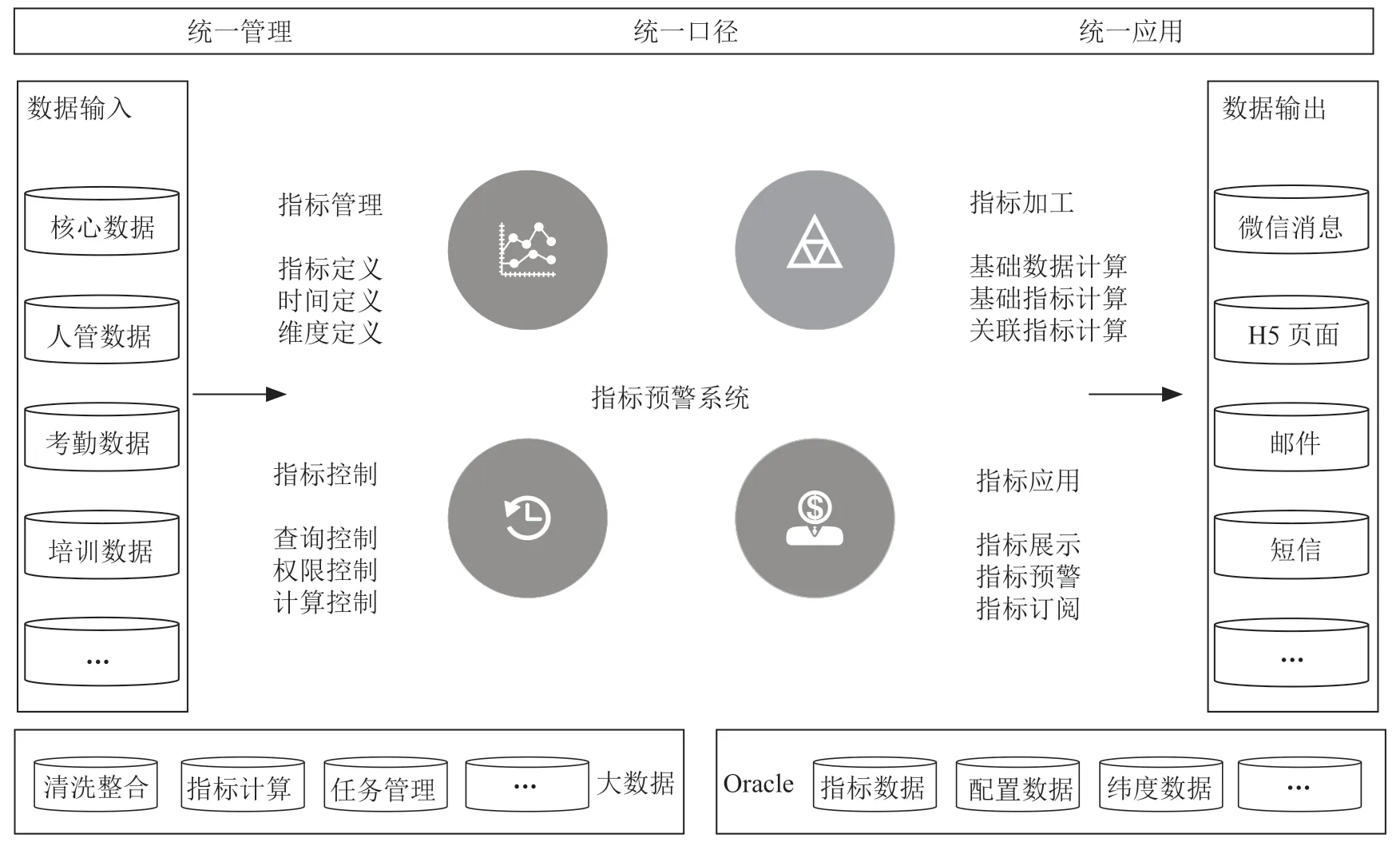
圖2 功能架構
指標預警系統通過大數據平臺進行指標計算,并把計算結果推送至Oracle,通過java-job 調用Oracle 結果數據通過緩存數據庫返回給前端H5,技術架構概述如圖3所示。
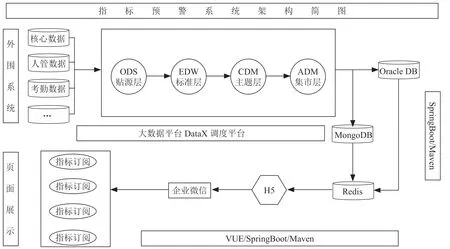
圖3 技術架構
2.2.2 指標定義
指標定義模塊包括指標定義、維度定義、時間定義、維度組合定義。這些維度表主要用于管控指標計算模塊的計算范圍、計算時間等。指標定義包括指標代碼、指標預警幅度、指標是否有效、指標是否展示、指標計算范圍、指標計算頻率等;維度定義包括:機構維度、險種維度、職級維度等多個維度表,每個維度表具有不同的維度組合;時間定義包括時間控制、時間大類、時間小類;維度組合定義指標對應的第一維度、第二維度、第三維度等信息。
(1)指標定義。指標定義模塊不僅包括常規的指標代碼、指標名稱、指標類型,還包括指標預警(廢棄及開發中指標不需要預警)、預警幅度、是否展示、時間大類、時間小類、當前數據計算完成時間、下次數據計算時間、數據計算頻率、數據計算范圍、需求來源、指標責任人。
(2)時間定義。時間大類分日、周、月、季、半年、年等,時間小類根據時間大類進行細分。比如日分工作日和非工作日,月分傭金月或自然月等。不同類型的指標,有不同的時間分類。
(3)維度定義。維度除了常規的維度代碼和名稱外,還有維度最小粒度和最小檔位,比如代理人職級最小粒度包括試用、降級、正式、業務員、業務經理一級、業務經理二級、高級經理一級、高級經理二級、區域總監、區域總經理,最小檔位可分為業務員和主管,或者試用、正式、業經、高經、區域總等。
(4)指標維度組合表。不同的指標對應不同的維度,維度可能有多個,不同的組合匯總出不同的結果數據,比如職級跟產品的組合、司齡跟產品的組合等。
2.2.3 指標計算
指標計算模塊主要是根據指標的定義,按照指標的屬性,比如指標類型、計算范圍、計算頻率、時間控制屬性及維度信息進行數據的清洗、加工和計算。
2.2.4 指標展示
指標展示模塊用于展示指標定義為可以展示且計算完成的指標,指標展示頁面根據用戶的關注度進行展示。用戶進入指標預警系統可以看到指標列表,點擊指標訂閱,可以選擇高中低不同的指標關注度,每個用戶最多可以關注16 個指標,按照關注度的高中低依次展示。用戶進入指標預警系統后可以查看不同的指標,每個指標展示不同的維度,不同的指標不同的維度有不同的展示風格,相關性指標會有關聯展示。指標展示示例頁面如圖4所示,維度展示示例頁面如圖5所示。

圖4 活動率展示

圖5 職級維度變化
2.2.5 指標推送
指標推送模塊用于訂閱用戶的消息推送,不同的指標根據不同的預警幅度和關注度推送不同的用戶。用戶訂閱指標后,根據關注度進行相應的閾值配置,比如高關注度的用戶,預警幅度達到5%即進行預警消息推送,中關注度的用戶預警幅度達到7%就進行預警消息推送,低關注度用戶,預警幅度達到10%才進行預警消息推送。當數據趨勢異常,達到閾值時,觸發微信推送消息,不同級別的消息,按照不同的消息模板進行推送。消息模板有指標異常數據說明,如指標歷史數據、目前數據、偏差量、偏差原因、建議解決方案等。指標預警消息推送頁面如圖6所示。

圖6 消息推送
2.3 計算模塊設計
如前所述,用于計算的業務數據來源于不同系統,從核心業務系統通過實時同步工具OGG 同步保單業績明細數據,從人管系統通過ETL 工具Informatica 同步傭金、職級,組織架構數據,從營銷系統通過ETL 工具Informatica 同步增員數據,從培訓系統通過ETL工具Informatica同步培訓數據,從考勤系統通過大數據同步工具sqoop 同步考勤數據等,批處理按照模塊區分,考勤、培訓、會議、請假等數據在hive中處理,業績費用明細、人力、職級、傭金數據在Oracle 中處理。匯總數據在Oracle 輕度聚合后,存入redis/mongodb供前端應用調用獲取。
2.3.1 批處理功能設計
指標計算模塊的核心是批處理的流程設計,批處理要運行的指標,指標計算的范圍都是通過指標定義模塊控制的。具體流程為:
(1)系統輪詢指標主表,指標主表是當前系統所有指標的屬性,包括時間屬性、預警屬性、展示屬性、運維屬性、數據屬性、優先級屬性等,一般來說預警的指標優先級高,則預警頁面優先展示,其次是展示優先級一般的指標,非展示的指標(一般是剛上線處于試運行的指標)優先級最低。
(2)通過指標主表的優先級,優先處理優先級高的指標數據,根據其時間屬性關聯時間控制表,時間控制表用于定義每個指標的計算范圍,數據存儲范圍,統計開始和結束時間等。
(3)通過指標代碼關聯指標維度表,獲取指標對應的計算維度,指標維度決定計算結果數據的最細粒度。
根據指標的時間屬性和維度定義劃定對應數據的內容和范圍,比如業績月度產能指標會先讀取指標主表的月度產能指標,根據產能指標的時間屬性,讀取時間控制表的產能指標的統計范圍,再根據指標維度表讀取產能指標的維度,比如跟產能指標有關的維度有機構、職級、司齡、險種,批處理會從核心費用數據關聯代理人的機構、入司時間、職級計算出當月1日0 點截止到目前的明細數據,按照2 到5 級機構,每個機構每個代理人機構id 和名稱,產品id 和產品名稱,代理人編碼、姓名、職級、渠道、入司時間、預收保費、承保保費、預收價值、承保價值、FYC、收入、預收件數、承保件數、預收壽險長險件數、承保壽險長險件數、年度產能等。
(4)更新完指標基礎數據后,更新匯總數據,按照機構、職級、司齡、險種等維度進行分類匯總,比如新人分為入司3 個月新人、入司4 ~6 個月新人、入司7 ~12月新人、入司1 ~2年內新人、入司3 ~5年新人等,險種分類有人壽險、健康險、年金險、意外險等,匯總數據直接供頁面查詢展示。
指標數據運行完畢后更新指標主表的數據更新時間、數據更新完成標識、歷史數據更新范圍等數據。
批處理運行流程如圖7所示。
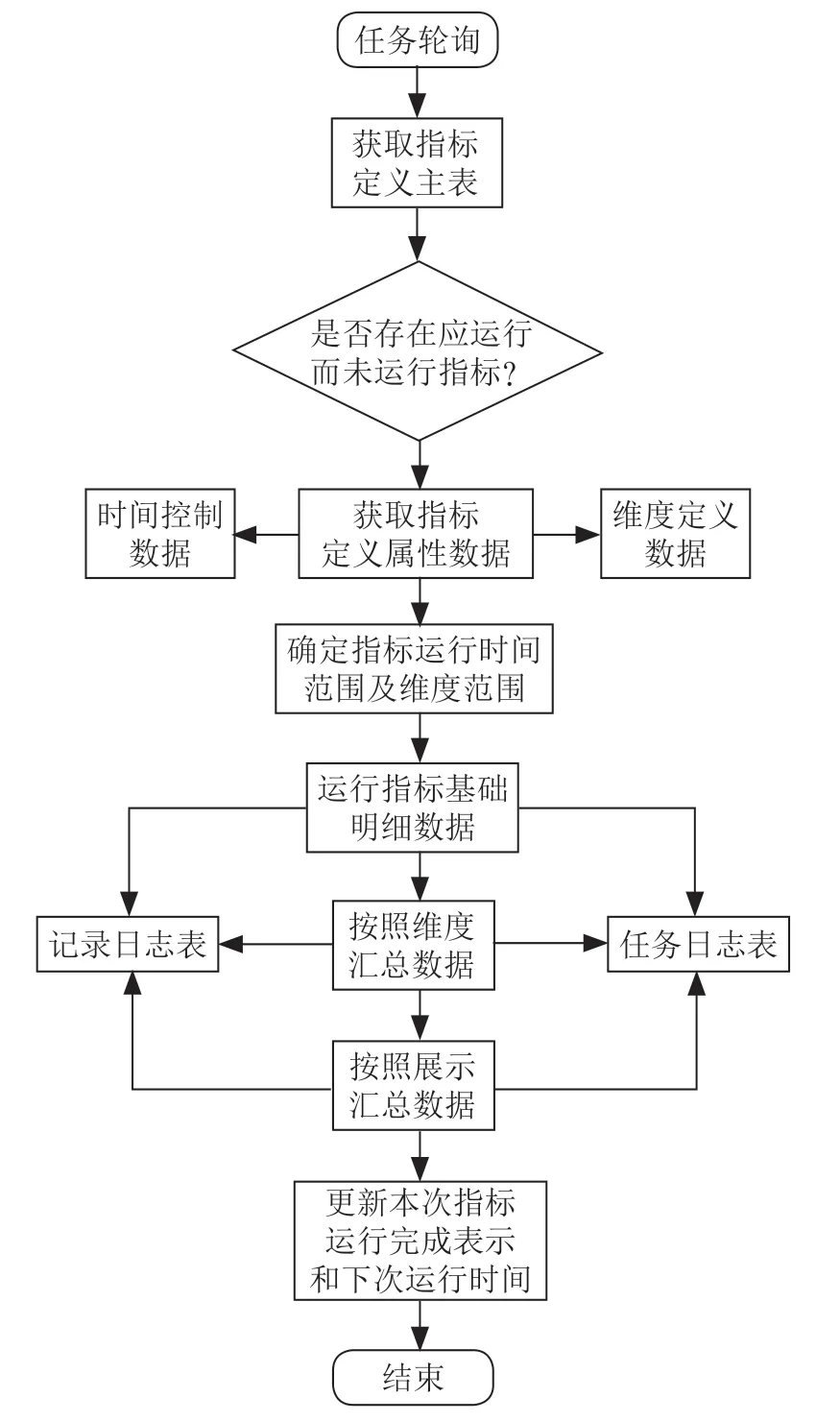
圖7 批處理
2.3.2 批處理性能設計
由于數據量比較大,所以數據計算性能是必須要考慮的因素。在指標預警系統中,不同的數據庫根據特點承擔不同的任務,Oracle 主要存放指標定義數據和計算結果數據,計算現有集成的數據,hive 數據庫主要計算大批量數據,Redis 和MongoDB 主要用于Oracle 和應用之間緩存數據。批處理性能設計為:
(1)sqoop 同步過來的數據在hive 數據庫進行計算,主要是考勤數據;OGG 和ETL 同步過來的數據在Oracle 數據庫計算,主要計算核心業務的費用明細數據。
(2)基礎費用數據批量更新頻率為15 分鐘,常用的維度如機構、職級、險種、司齡等,職級、人力數據更新頻率為1 天,機構、部門、人員異動等數據更新頻率為4 小時。考勤、培訓、請假數據更新頻率為1 小時。
(3)Oracle 的計算任務,為了防止實時同步數據大概率短時間數據同步延遲,在考慮減少系統性能壓力和批處理運行時長等情況下,高頻數據每次更新最近時點往前推30分鐘以來的數據,為了防止源系統數據更新歷史數據,每天凌晨2 點更新最近15 天數據。
(4)大數據hive 的計算任務,在早晚班時間每小時計算一次當天刷臉數據,每天12:30 和22:30 計算當月數據,每月15日及15日之前計算上月數據,15日之后計算當月數據。增員數據每2 個小時計算一次當月數據,為了減少數據計算壓力,每個并發處理一個二級機構。
(5)維度指標數據批處理依賴于基礎數據批處理,屬于串行關系,維度數據批處理之間是并行關系。批處理經過數據優化,索引、分區分片、并行等技術優化,已實現均衡運行。
(6)計算結果同步到redis 和MongoDB 是通過Java 的定時job 實現的。業績指標匹配數據頻率,一般15 分鐘,其他指標根據數據生成頻率,30 分鐘到2 個小時不等。
2.3.3 指標計算模型設計
指標預警數據計算模型分為四層:ODS 貼源層、EDW標準層、CDM 模型層、ADM 集市層。
ODS 貼源層,直接存放從業務系統抽取過來的數據,這些數據從結構上和數據上與業務系統保持一致,基本都是按照源頭業務系統結構進行存儲。
EDW 標準層,從ODS 層同步數據,并完成數據清洗,按照統一數據模型標準化。定位永久保留,全量數據。指標預警按照指標類型進行標準化,比如產能指標、業績指標、傭金指標、出勤指標、增員指標等。
CDM 模型層,為了降低數據應用復雜度建立的通用層,包括匯總和明細。按業務主題進行劃分。存放明細事實數據、維表數據及公共指標匯總數據。通用的保險業模型是按照客戶、保單、理賠、財務、服務、渠道、產品、機構、再保、合作方這種主題分類的。由于指標預警系統的特殊性,模型主題按照指標分類,分為業績、傭金、產能、增員等,比如增員模型對應的指標包括增員率、活動率、三轉率、脫落率等。
ADM 集市層,基于CDM 層數據的高度匯總數據,根據業務場景生成對應的結果數據。數據生成后用于導入Oracle 供應用調用。
指標預警系統通過大數據平臺進行指標計算,并把計算結果推送至Oracle,通過java-job 調用Oracle 結果數據通過緩存數據庫返回給前端H5,計算模塊在整體系統架構起到了核心作用,其整體架構流程圖如圖8所示。
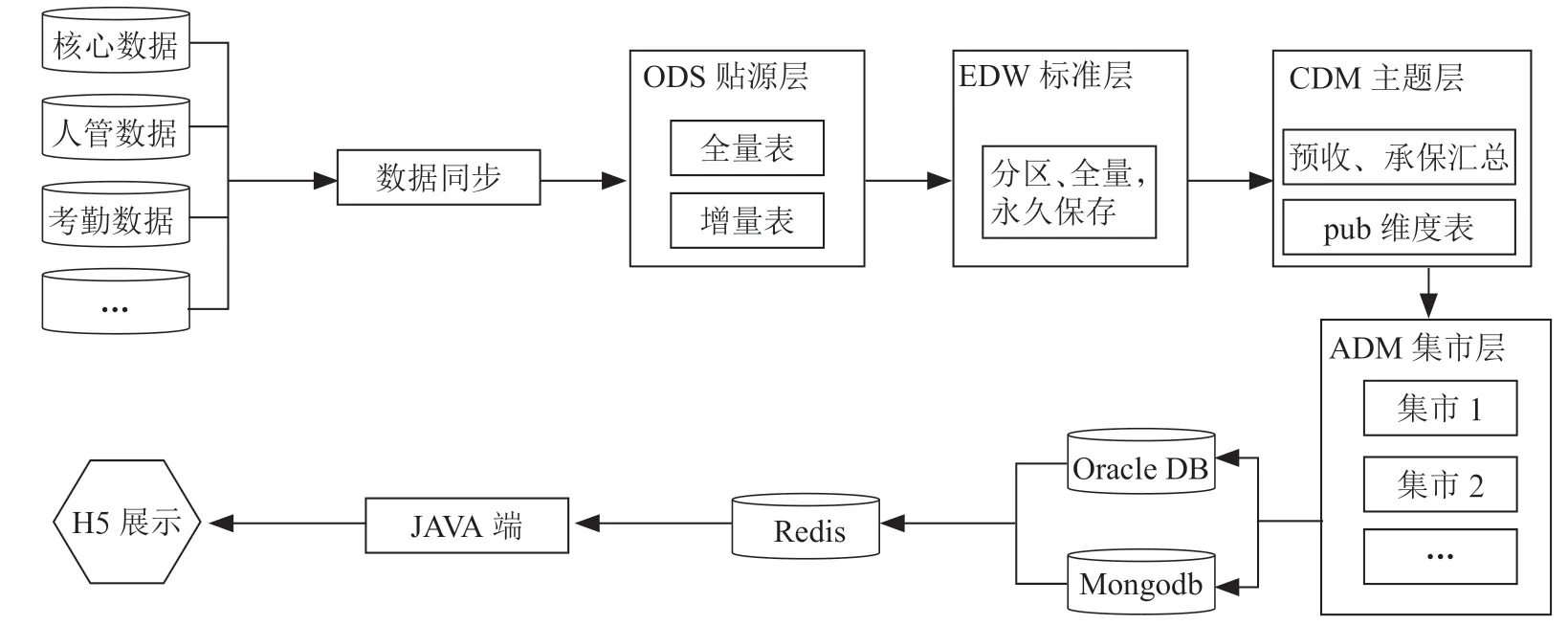
圖8 計算模塊
3 結 論
綜上所述,我們可以看出,雖然指標預警系統和數據分析系統有一定關聯性。但總的來說還是有其獨特的特點。目前國內公司信息化技術水平都在迅速發展,而對于傳統公司,大數據技術使用程度還有很大提升空間。也希望指標預警系統的應用能夠給其他公司提供一些經驗,既不需要完全遷入大數據系統,又能在現有系統的基礎上充分利用大數據技術的優勢。與現有技術相互補充,相得益彰。在公司可承受成本的基礎上進一步發揮大數據優秀的計算能力和擴展能力優勢,把數據分析真正作為企業經營分析甚至決策的重要參考依據。
猜你喜歡
幼兒教育·父母孩子版(2022年4期)2022-05-08 21:35:35
中學生數理化(高中版.高考數學)(2021年3期)2021-06-09 06:09:14
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:38
中學生數理化(高中版.高二數學)(2021年2期)2021-03-19 08:54:04
海峽姐妹(2020年9期)2021-01-04 01:35:44
華人時刊(2020年13期)2020-09-25 08:21:32
VOGUE服飾與美容(2020年9期)2020-09-02 14:47:26
山東青年(2016年1期)2016-02-28 14:25:25
汽車維護與修理(2015年6期)2015-02-28 12:16:55
當代修辭學(2014年3期)2014-01-21 02:30:44
