基于改進深度學習的電力營銷數據異常識別研究
2022-09-01 11:33:40康徑竟黃河滔
通信電源技術 2022年9期
萬 龍,康徑竟,黃河滔
(云南電網有限責任公司 昭通供電局,云南 昭通 657100)
0 引 言
能源與電力發展事關國計民生,與經濟社會存在廣泛緊密的聯系。推動深度學習和實體經濟深度融合,挖掘改進深度學習的價值,對于助力新時代能源電力事業更好地服務經濟社會發展具有重大意義。在我國經濟發展水平日益向好、國民生活質量日益改善的背景下,我國電力用戶的數量也在持續增加,與此同時用電量也出現明顯提升,在電力系統中電力業務所具有的重要意義和作用也逐漸突出,因此針對電力營銷管理工作中所涉及到的電量管理工作的要求也愈發嚴格[1]。對電量管理工作而言,電費以及電價的統計分析工作極為關鍵,在進行電量管理工作時經常會遇到電量異常等問題,借助優化后的改進深度學習方法,對于電力營銷工作中所涉及到的異常數據加以識別判斷,可改善電力營銷數據的準確性和可靠度。
1 深度學習簡介
深度學習理論描述了學習樣本數據的表示層次及其內在作用規律,在學習過程中所獲得的一切文字、聲音、圖像等信息參量,都具備較強的應用處理能力。該項理論算法的最終實踐目標是使機器人具備像人一樣的學習與分析能力,在準確識別文字、聲音、圖像等數據信息的同時,為各項理論參量賦予較強的計算與處理能力。總體而言,深度學習是一種極為復雜的機器學習類應用算法,在圖像及語音識別方面具有較為廣闊的應用前景,遠超數據挖掘、機器翻譯等其他類型的信息處理技術[2]。
深度學習在異常檢測方面展現出良好的性能,遞歸神經網絡(Recurrent Neural Network,RNN)常用于分析序列信息,長短期記憶(Long Short-Term Memory,LSTM)網絡是RNN的一個分支,在自然語言處理等序列信息分析應用中表現良好。
2 深度學習主要網絡模型
卷積神經網絡(Convolutional Neural Network,CNN)為當前應用較多的深度學習理論中的研究模型之一,其標準結構包括輸出層、全連接層、輸入層以及交替的卷積層、池化層等部分。為了保障民生,提高電網可靠性,有些學者已將深度學習引入電力行業進行研究、探索[3]。
自動編碼器(Auto Encoder,AE)在創建之初實際上是用于壓縮數據,主要具有下述特點:(1)與數據間具有密切聯系,即代表自動編碼器,僅能夠對和訓練數據較為類似的數據進行壓縮處理;(2)通過該方法對數據進行壓縮處理以后,會在一定程度上對數據產生損傷,這主要是由于在進行降維處理時必然會丟失部分信息。
通過自動編碼器能夠對輸入原始數據所具有的一些隱蔽性特征進行學習,也就是編碼(Coding)。在對新特征進行學習后,即可重新獲得原始輸入信息,這一過程也被稱之為解碼(Decoding)[4]。對自動編碼器的工作情況進行分析,其實際上和主成分分析(Principal Component Analysis,PCA)具有相似之處,但是性能卻得到顯著優化,這主要是由于神經網絡能夠自動的對一些新的數據和能力進行學習,因此能夠使得企業數據處理效率和質量均得到顯著提高。在對自動編碼器的工作原理和整體情況進行深入分析后,能夠發現其實際上屬于無監督式的深度學習模型,通過其能夠獲得多種多樣的訓練樣本的新數據信息,所以從這一層面而言,其實際上也可以被劃分到生成算法模型的范疇中[5]。
對于RNN結構進行分析,該算法能夠對此前所輸入的各項信息加以記憶,并在現有輸出信息中進行應用,所以對于數據序列類型的數據信息進行計算時極為適用,而且將CNN算法和RNN算法聯合應用可以很好地解決數據間的相關性問題。
3 基于改進深度學習的電力營銷數據識別設計
基于改進深度學習的電力營銷異常數據檢測包含Caffe 深度學習框架構建、電力營銷數據清洗、異常檢測標簽編碼3個處理步驟,具體執行方法如下[6]。
3.1 Caffe深度學習框架
Caffe深度學習框架是電力系統硬件執行環境的搭建基礎,由學習網絡本體、電網監測主機、學習節點、異常數據集合等多個結構共同組成。其中,學習網絡本體可提供電力系統運行所需的電子量信息,并可借助數據傳輸通道反饋至下級應用結構之中。電網監測主機起到承上啟下的物理連接作用,可在電量數據傳輸流的作用下,將異常數據平均分配至各級學習節點之中,從而較好地滿足電信息捕獲需求。異常數據集合位于Caffe深度學習框架底部,可有效整合各學習節點中的電力系統異常數據,并將其轉換為既定格式的存儲應用參量。Caffe深度學習框架結構如圖1所示。

圖1 Caffe深度學習框架結構
3.2 電力數據清洗
數據清洗轉換實際上就是對數據中存在的異常問題進行處理解決,并對對象識別工作中所涉及到的不足之處進行解決應對的過程,通過傳統的人工數據處理方法僅能夠對少量的數據信息進行處理,而且還存在費時費力、效率較低等問題,同時對專業水平要求高,本身還會出錯,不能滿足海量調度管理類及實時類數據清洗要求[7]。基于此,開發出一種便捷高效快速的數據清理轉換方法,并且借助一定的設備或者儀器實現自動化或者半自動化的數據清洗工作具有重要意義,對于控制數據質量也具有顯著積極影響。
一般情況下,在Caffe深度學習框架中,電力數據清洗結果受到常性化捕獲指標χ的直接影響,若不考慮其他干預條件對最終計算結果的影響,常性化捕獲指標數值越大,電力數據的清洗能力也就越強,反之則越弱。圖2為電力數據清洗的過程。
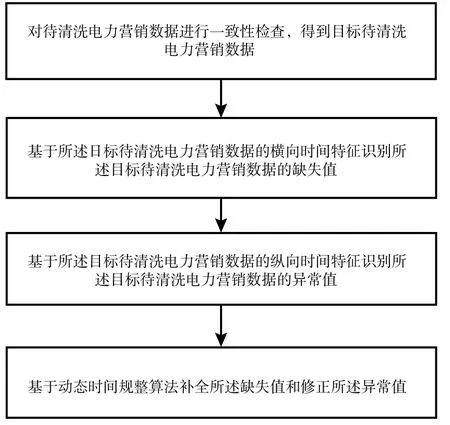
圖2 電力數據清洗過程
3.3 異常檢測標簽編碼
異常檢測主要分為以下兩類。
(1)數據有標簽。對于這樣的數據,期望訓練一個分類器,這個分類器除了要能告知正常數據的類別外,還要對于異常數據輸出其屬于“unknown”類,這個任務叫做Open-set Recognition[8]。
(2)數據無標簽。這類數據分為兩種,一種是數據是干凈的(clean),也就是說數據集中不包含異常數據;另一種是數據是受污染的(polluted),數據集中包含少量的異常數據。其中,受污染的數據是更常見的情況。
通常情況下,電力系統異常數據中始終包含大量的類別特征參量,這些特征同時具備較強的標簽編碼能力,然而仍有一部分捕獲節點需要對電力系統異常數據設置必要的判別條件,也就是異常檢測標簽的編碼處理行為[7,8]。異常檢測標簽編碼所能接收的電力系統數據必須保持有序存在狀態,并要求其輸出行為必須為連續且規范的。按照既定表示形式,待編碼的數值并不能持續保持為有序狀態,也就是Caffe 深度學習框架為其分配了一個數量值而已[9]。
4 異常識別研究
自動化協議棧能夠提供電力營銷異常數據自動捕獲所需的一切連接協議信息,應用層、傳輸層、網絡層、鏈路層以及物理層結構體同時位于電力系統以太網絡外端,能夠為Caffe深度學習框架提供良好的捕獲節點條件。一方面可提防異常數據對于電力營銷主機的打擊與干擾行為;另一方面也可將異常數據信息整合成獨立的傳輸主體,大幅節省改進深度學習網絡中的數據存儲空間。
異常數據拷貝可耗費大量的CPU存儲空間,在自動化協議棧多層架構體系的作用下,該項處理行為可將電力系統異常數據的自動捕獲時間縮短近50%。在電力系統異常數據傳輸速率水平保持為l0 Mb/s 的情況下,檢測標簽編碼執行速率可達到原有捕獲速率的一倍或幾倍。在此情況下,異常數據的拷貝與封裝行為都會對最終信息捕獲結果造成直接影響,數據傳輸量過大或過小,都會導致捕獲結果出現偏頗,從而影響改進深度學習網絡的實際作用能力。
電力營銷的內核訪問用戶空間一般不會直接對深度學習網絡開放,且在實際操作時也極易受捕獲節點所處位置的影響。因此,應以電力營銷異常數據的原始存在節點作為捕獲映射條件的初級建立依據,以自動化捕獲節點的終止存在位置作為捕獲映射條件的終極建立依據,兩相結合在深度學習網絡中實現電力系統異常數據捕獲映射條件的順利應用。
5 改進深度學習的電力營銷數據異常識別研究難點
營銷數據審核過程中,核算員需要依據電力營銷應用系統中電量電費審核條件篩選出來的異常用戶進行審核過濾。作為電量電費審核的輔助工具,審核條件的完善及準確性對審核工作質量起著十分重要的作用。改進深度學習模型需要進行實際的訓練,通過大量數據來提高它的準確性和智能性。深度學習實際上就是借助建立涉及到多個隱藏層的機器學習模型,通過大量的訓練數據進行反復的學習,從中提取到數據的有用特征,進而使得預測或者分類工作準確性得到有效提升的一種方法。深度模型實際上是一種方式、一種手段,而特征學習才是其目的。在深度學習算法中,對于模型結構的深度極為重視,同時對于特征學習所具有的重要意義進行了著重表現,借助逐層的特征變化使得樣本在原本空間中所具有的特征進行處理,以一個新的空間特征加以表示,進而降低預測或者分類工作的難度[10]。相較于人工規則構造特征算法而言,借助大數據進行課程學習,可以對數據所蘊含的大量內在信息進行更加準確可靠的體現。
在僅能夠提供有限的數據的情況下,深度學習算法無法實現對數據中所包含規律的無偏差估計,所以為顯著提高算法的精度,必須給予充足的數據支持。因為深度學習中圖模型的復雜化,所以使得算法的時間和復雜程度大大提高,想要切實保證算法的實時性,還需要進一步優化改善硬件設備和編程技能。
6 結 論
在改進深度學習網絡的作用下,電力營銷異常數據自動捕獲方法可聯合Caffe框架,在清洗電力數據信息的同時,對異常檢測標簽節點進行編碼處理,且由于自動化協議棧多層架構體系的存在,待拷貝異常數據能夠與最終信息捕獲結果建立一一對應的捕獲映射條件,不僅能夠較好穩定已連接的電網應用環境,也可實現對異常傳輸電子量的精確化處理,具備較強的應用可行性。
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年6期)2019-01-08 02:43:04
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
中華手工(2017年2期)2017-06-06 23:00:31
新聞傳播(2015年10期)2015-07-18 11:05:40
中外會展(2014年4期)2014-11-27 07:46:46
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
