基于鐵路調度指揮作業指令的關鍵詞識別技術應用研究
2022-09-06 09:14:18何振華馮立恒毛疆華
鐵路計算機應用 2022年8期
楊 博,何振華,馮立恒,郭 星,毛疆華
(1. 中國鐵路北京局集團有限公司 調度所,北京 100036;2. 鄭州信大先進技術研究院,鄭州 450000;3. 河南信大煜坤智能科技有限公司,鄭州 450000)
調度所是鐵路日常運輸組織的指揮中樞,調度員口頭指示非常嚴肅,直接關系到運輸生產效率與調度指揮安全,因此調度用語的標準化執行與檢查工作尤為重要。日常調度錄音數據量龐大,對調度員的語音檢查只能通過錄音回放、人耳分辨形式進行抽樣檢查,關鍵信息不能高效定位,無法滿足對全量調度語音進行快捷有效檢查分析的需求。
針對上述情況,通過關鍵詞識別可實現對調度語音結果自動分析,智能快速查找關鍵信息,自動定位不規范用語、非正常情況的關鍵詞,并將結果直接反饋給相關人員,提升語音檢查效率,提高非正常情況處置速度,輔助調度語音標準化和應急處置管理工作。
1 關鍵詞識別技術概述
1.1 關鍵詞識別技術原理
關鍵詞識別是一種從連續的音頻流中檢測出特定關鍵詞的語音技術[1]。過去40多年中,出現過許多技術用來解決關鍵詞識別任務,主要可以劃分為3類:基于模板的關鍵詞識別技術、基于關鍵詞-廢料模型(Keyword-Filler Model)的關鍵詞識別技術[2]和基于大詞匯量連續語音識別的關鍵詞識別技術[3]。
(1)基于模板的關鍵詞識別是利用特定關鍵詞的已知語音片段,去匹配待檢測語音中的語音片段,是最早被用到關鍵詞識別任務的技術之一。如果待檢測語音片段中存在與模板相似的片段,則認為此語音片段中包含關鍵詞。其主要分為2步,分別是模板生成和模板匹配。模板生成是將關鍵詞語音片段轉換成代表關鍵詞特征的模板的過程,常見的模板有原始語音片段、從原始語音片段提取出的梅爾頻率倒譜系數(MFCC,Mel-Frequency Cepstral Coefficient)和原始語音片段經過神經網絡得到的后驗概率等。模板匹配則是利用第1步生成的模板到待檢測音頻中進行匹配,找到關鍵詞的過程,主要使用基于動態時間規整的方法。
(2)基于關鍵詞-廢料模型的關鍵詞識別是對關鍵詞和廢料進行建模,廢料是指不包含關鍵詞的其他語音片段,將待檢測語音片段輸入系統進行識別,對齊到關鍵詞或廢料模型上判斷是否包含關鍵詞。關鍵詞和廢料模型通常使用隱馬爾可夫模型(HMM,Hidden Markov Models)建模。這種方法模型簡單、參數量少、計算資源耗費低,多用于對實時性要求比較高的智能終端設備中。這種方法由于需要事先對關鍵詞進行建模,用于檢測預定義的關鍵詞,如需增加額外關鍵詞,則需要對新增關鍵詞及系統識別模型重新進行建模訓練。
(3)基于大詞匯量連續語音識別的關鍵詞識別技術是先通過語音識別系統將待檢測語音數據轉寫為文本數據,利用文本數據生成用來搜索關鍵詞的倒排索引,并直接從倒排索引中搜索文本關鍵詞。在實踐中,經常會利用語音識別系統產生的詞格,將語音識別備選詞也列入到搜索范圍中以提高準確率。由于大量詞匯連續語音識別只能將語音數據轉換成詞匯表中事先定義好的詞匯,所以在搜索集外詞、關鍵詞時也會應用一些特殊的技巧,如模糊搜索、子詞系統等。這種方法常用于檢測非預定義的關鍵詞,其檢測的目標通常為數據量較大的音頻,部署在計算資源和存儲空間都比較充足的設備上面,如PC、服務器或云計算平臺等。
1.2 關鍵詞識別技術應用
目前,關鍵詞識別技術有2類主流的應用,語音檢索和語音喚醒。
(1)語音檢索的主要任務是從海量的語音數據庫中找到感興趣的關鍵詞,并返回相應的位置。語音檢索可被應用到音視頻內容的搜索上。
(2)語音喚醒的主要任務是實時地從音頻數據流中檢測出事先定義好的關鍵詞,被廣泛地應用于語音助手中,如各個品牌手機的語音助手及智能音箱設備都使用了語音喚醒技術,檢測各自設備的喚醒詞。由于語音喚醒技術運行在設備端上,并需能實時地從語音數據流中檢測出關鍵詞,因此對算法的計算復雜度和實時率都有較高的要求。
2 應用場景及任務目標
本文討論的應用場景不限于鐵路調度語音監督應用場景,同時希望將關鍵詞識別技術應用于特定環境下的專業詞匯檢測,以此規范工作流程。
目前,大量詞匯連續語音識別針對方言的識別效果一般,如果重新訓練針對方言的連續語音識別模型,則需大量語音數據,這就需要長時間且大量的數據標注工作,在短時間內完成的可能性比較小。且此種特定專業方向的識別內容中包含大量專業詞匯,這些專業詞匯不會存在于一般場景所訓練的連續語音識別系統的詞匯表中,這也給基于連續語音識別的關鍵詞識別帶來了難度。此外,基于連續語音識別的關鍵詞檢測在實際部署過程中會需要較高的計算成本,對實時率要求也很難滿足。
由于在需求場景的工作流程中,所需要檢測的關鍵詞相對比較固定,因此,我們擬采用基于關鍵詞-廢料模型的關鍵詞識別技術,利用一種端到端[4]的訓練方法完成這種場景下的關鍵詞識別任務。在語料標注過程中只需標注出關鍵詞,節省了標注所需的人力成本和時間成本。這套方法可識別的關鍵詞比較固定,如果想后期添加關鍵詞則需要重新建模,不過對于需求場景產生的影響較小。另外,這種方法也易于在移動終端平臺部署且能滿足實時率要求。
3 關鍵詞識別系統
3.1 系統框架
本文所使用的基于關鍵詞-廢料模型的識別系統由特征提取、聲學模型、語言模型及解碼器模塊組成,如圖1所示。
(1)特征提取模塊是針對輸入的音頻信號序列進行聲學特征提取,所提取的聲學特征為MFCC。提取過程包括預處理、快速傅里葉變換、梅爾濾波器組、對數運算、離散余弦變換和動態特征提取等步驟。
(2)聲學模型部分表示單詞音素狀態對應到語音序列聲學特征的概率,即描述了“什么詞發什么音”的問題。聲學模型是語音識別系統的重要組成部分,它占據著語音識別大部分的計算開銷,決定著語音識別系統的性能。
(3)語言模型是針對識別語言進行建模,描述單詞序列出現的概率。對于關鍵詞識別任務,它的語言模型相對比較簡單,一般可分為2個部分,關鍵詞模型,對應的也就是指定的關鍵詞在解碼圖中的路徑;廢料模型,對應的也就是其他非喚醒詞,包括靜音、噪音和其他非喚醒詞語音的路徑。
(4)解碼器的主要任務是對輸入的語音信號進行解碼,即依據聲學得分、語言得分和詞典,尋找該輸入信號最有可能對應的文字序列。
在本文中,我們使用的關鍵詞識別框架參照文獻[5]進行搭建。其中,識別模型采用了非詞格依賴的最大互信息(LF-MMI,Lattice Free Maximum Mutual Information )的訓練準則,LF-MMI訓練準則最初是針對連續語音識別任務提出的。在訓練過程中,不再單獨訓練獨立的聲學模型和語言模型,而是將它們作為識別模型的部件進行整體優化。模型訓練不再依賴高斯混合模型 (GMM,Gaussian Mixture Model)-HMM模型生成對齊信息,無需對訓練語料進行解碼生成詞網格,直接進行識別模型訓練,簡化了訓練流程。為了使其適用于我們的任務,出于效率和性能的原因,對隱馬爾可夫拓撲、聲學模型網絡結構進行了一些必要的調整和更改,還使用了快速在線解碼器。這些將在后續小節中進行詳細介紹。
3.2 關鍵詞模型的構建
基于關鍵詞-廢料模型的關鍵詞識別利用HMM為關鍵詞進行建模。為了實現關鍵詞識別,需要為每個關鍵詞創建HMM,并且額外創建一個HMM表示廢料模型。通常情況下,表示關鍵詞的HMM來自組成關鍵詞的有效音素序列,即關鍵詞的每個音素對應一個HMM的轉移狀態。
本文所采用的HMM模型是使用單個HMM針對整個關鍵詞進行建模,即詞級別的HMM,該HMM 中不同狀態的數量是一個預定義的值,其狀態數量小于實際音素的數量。對于關鍵詞識別任務,使用固定數量的HMM狀態已具備足夠的建模能力。類似的,針對廢料模型也采用了相同的HMM拓撲結構。
此外,使用一個額外的HMM專用于非語音聲音,即表示為SIL的非人聲片段,對于性能的改善也起到了至關重要的作用。SIL作為可選的靜音狀態添加到每個關鍵詞或廢料模型的開頭和結尾,以便能夠正確的對實際的靜音片段建模。HMM轉移狀態拓撲圖,如圖2所示。
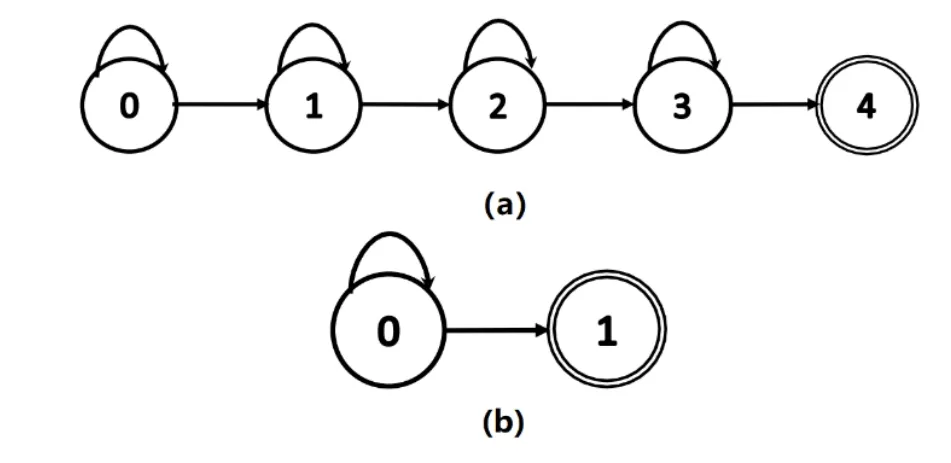
圖2 HMM狀態拓撲
圖2(a)表示了關鍵詞和廢料模型的HMM狀態拓撲結構,圖2(b)則用來表示靜音段的拓撲結構。2種結構中分別具有4個和1個HMM發射狀態,最后的狀態將不再進行轉移。這樣的結構可以減少HMM狀態的數量,可以有效提升解碼速率。
3.3 聲學模型
聲學模型采用了帶有跳躍連接機制的因子分解時延神經網絡[6](TDNN-F,Factorized TDNN)進行建模。在TDNN-F網絡中,將TDNN的參數矩陣M通過奇異值分解(SVD)分解為2個小矩陣相乘的形式M=A×B,從而有效減少了層參數量,以便在整體參數量相近的情況下,更好的利用網絡深度的優勢。此外,為了避免因為隨機初始化參數導致的訓練發散,在TDNN-F更新層參數的時候,使得其中一個因子矩陣B保持為半正定矩陣,控制層參數變化速度,使訓練穩定。
TDNN-F網絡引入的跳躍連接機制是指每個TDNN-F層會接收神經網絡之前層的參數輸出,將輸出結果按一定比例縮小后再加到當前層的輸入中,在本文中將其縮小至原來的0.66。跳躍連接的引入能夠保證信息向深層流入,有助于緩解梯度消失的問題。
本文使用的深度神經網絡結構中,網路層數為20層,隱藏層參數維度為80,每個輸出幀覆蓋大小范圍為 80。每3幀會評估一次輸出的 LF-MMI 損失,以減少訓練中的計算成本和測試時間。
3.4 解碼圖的構造
針對關鍵詞識別任務的解碼方法是使用在線維特比解碼[7],它以令牌傳遞的方法表示推測過程。具體的解碼過程是先用一個詞級別的有限狀態轉錄機(FST,Finite-State Transducer)構建解碼圖,指定所有可能出現詞路徑的先驗概率,解碼圖中開始狀態和最終狀態會合并形成一個環,可針對關鍵詞和其他可能的語音相交叉的音頻進行解碼識別。
在線解碼期間,每次處理完一段錄音中的固定長度塊之后,可沿著由2個最近的初始令牌分割的幀檢測是否在該部分中存在關鍵詞,如果找到則向系統報告,否則就繼續解碼過程。簡單來說,如果所有當前推測都來自于前面步驟中相同的令牌,則該令牌之前的所有推測都可以通過修剪和標記重組折疊為一個,從中可逐段檢查它是否包含關鍵詞。
4 實驗設置與結果分析
本文將以目標任務場景下采集到的語音數據訓練此關鍵詞識別模型,并測試該模型的識別效果。
4.1 數據集和數據處理
本文所使用的數據集為應用環境下采集的真實語音,其與常見的開源數據集不同。采集到的錄音則摻雜有大量的背景噪音,且噪音的類型各不相同。所以在初期數據量沒有積累到一定程度的時候,識別效果不如實驗室開源數據集結果。當然,這也是本文的任務之一,就是探究真實應用場景需要至少積累到多少數據量,才會獲得一個可作為工業應用的關鍵詞識別模型。
目前,采集并標注完成的數據量十分有限,標注關鍵詞總數量有35個,針對同一關鍵詞出現的頻次最多的也只有3000余條,人聲時長總計逾40 h,因此,實驗會對采集到的數據集作數據增強處理。由于數據集中已包含了各類噪聲,主要有機車運行時加速或者剎車產生的噪音,檢測時鋼鐵碰撞聲以及戶外的風噪,所以數據擴增的主要方式為音量調整和音速調整。
4.2 實驗平臺和工具
實驗中用于模型訓練和測試的設備是由一臺工作站來完成的。
實驗基于當前較為流行的開源語音識別工具箱Kaldi[8],Kaldi的底層應用程序由C++實現,上層調用則主要是由shell腳本來實現的。本文采用nnet3作為訓練工具,它是基于計算圖的神經網絡,通過定義相關的配置文件,可方便地實現各種深度神經網絡,也可進行基于LF-MMI準則的訓練。
4.3 實驗整體流程
(1)數據準備
利用 Kaldi 做語音識別,數據準備一般包括數據集相關文件制作、詞典準備和語言模型的構建等。語音數據集的相關文件準備,包括wav.scp、text、utt2spk和spk2utt等,這些都是和音頻文件存放位置、標注及語音和說話人信息對應的相關文件,一般按照Kaldi要求的格式來做即可。對于關鍵詞性能參數的測試,需構建前文所介紹的解碼網絡,這當中所包含的語言模型實際上是一個關鍵詞構成的1-gram語言模型。
(2)特征提取
本文按第2節中介紹的特征提取方法對語音數據進行處理,為后續的鏈式模型訓練提供數據特征。對與神經網絡相關的聲學模型訓練,本文采用 13 維的MFCC特征。
(3)數據擴增
針對原始數據做數據擴增。實驗中會對原始數據做音量和音速調整處理,分別將數據的音量調整到原始音量的0.125~2倍之間,音速調整到0.9、1、1.1倍速,以此擴充數據量。
(4)聲學模型訓練
實驗核心的部分是關于神經網絡的訓練,基于LF-MMI準則,在訓練開始前,仍需做一些準備工作,主要包括:HMM拓撲修改,決策樹重建及分子詞圖和分母詞圖的構建等。需要注意的是,實驗中為了盡量減少參數量,在決策樹重建時,限定其最終的葉子節點數不超過1000,這樣可顯著降低神經網絡最后一層的參數數目。完成這些工作后,可配置神經網絡,并在LF-MMI準則下進行訓練。
(5)解碼測試
完成聲學模型的訓練后,結合(1)中建立的語言模型生成對應的解碼圖,對測試集進行解碼測試及實時因子的測量。其中,實時因子是在服務器集群中的同一個計算節點上進行測量的,對上述測試集的隨機抽樣數據進行多次解碼并計算平均的實時因子作為最終的測試結果。
4.4 評價指標
在對關鍵詞識別進行評測時,不同的使用場景有不同的評價指標,本文使用較為常見的召回率(Recall Rate)和誤識率(False Alarm Rate)作為性能評價指標, 召回率Precall和 誤識率PFA公式為

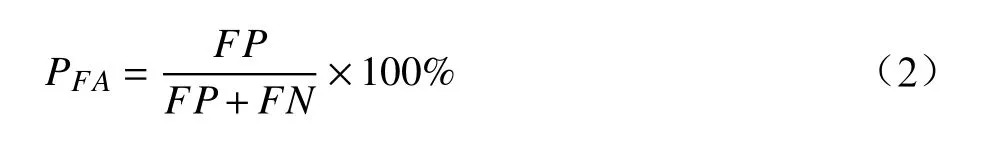
其中,TP為關鍵詞樣本被正確檢測為關鍵詞的個數;
FP為非關鍵詞樣本被錯誤檢測為關鍵詞的個數;
TN為關鍵詞樣本被錯誤檢測為非關鍵詞的個數;
FN為非關鍵詞樣本被正確檢測為非關鍵詞的個數。
4.5 結果與分析
不同閾值下不同關鍵詞的識別測試結果,如表1、表2所示。

表1 關鍵詞1的測試結果
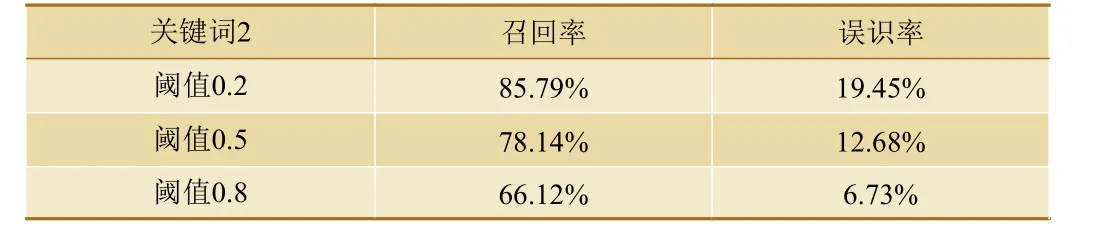
表2 關鍵詞2的測試結果
根據測試結果,目前在訓練集正樣本數,即關鍵詞數量有限的情況下,測試結果均能達到預期。通過調整關鍵詞識別閾值,將誤識率控制在較低的情況下,可達到一定的關鍵詞識別率。在本文實驗中,僅使用了3000條樣本數量就能達到如表1、表2所示的結果,說明此關鍵詞識別模型在語料充足的情況下能夠滿足識別要求。
5 結束語
本文對鐵路調度指揮調度作業指令關鍵詞識別系統進行了研究,驗證了針對真實應用環境下采集到的訓練數據應用到此關鍵詞識別系統的可行性。本文所述的關鍵詞識別系統模型結構簡單,參數量小,且對計算平臺要求不高,適合在鐵路調度作業環境下部署。在后續工作中,將進一步采集和標注相應環境下的關鍵詞 ,在積累到一定樣本數量后,對此關鍵詞系統進行優化,提高系統的召回率并降低誤識率。另外,在增加不同關鍵詞之后,語言模型也會進行相應的調整。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
