結(jié)合領(lǐng)域先驗詞匯的遠(yuǎn)程監(jiān)督關(guān)系抽取模型
2022-09-07 03:20:08王會勇張曉明
計算機應(yīng)用與軟件 2022年8期
王會勇 安 康 張曉明
(河北科技大學(xué)信息科學(xué)與工程學(xué)院 河北 石家莊 050000)
0 引 言
在領(lǐng)域知識圖譜構(gòu)建過程中,概念或?qū)嶓w間的關(guān)聯(lián)關(guān)系發(fā)現(xiàn)是構(gòu)建領(lǐng)域知識圖譜的重要基礎(chǔ)。但是,由于特定領(lǐng)域知識適用范圍小、知識結(jié)構(gòu)較復(fù)雜、專業(yè)性較強等領(lǐng)域因素,使得領(lǐng)域知識圖譜構(gòu)建難度較高,存在很多挑戰(zhàn),例如通用領(lǐng)域的關(guān)系抽取方法并不能完全適用于特定領(lǐng)域,數(shù)據(jù)標(biāo)注過程人工參與程度較高。因此,針對特定領(lǐng)域的關(guān)系抽取研究具有重要的現(xiàn)實意義。
目前隨著關(guān)系抽取任務(wù)的研究,常采用深度學(xué)習(xí)方法通過對文本特征的判斷來進行關(guān)系分類,文本特征是關(guān)系抽取模型進行關(guān)系分類的重要特征。在關(guān)系抽取任務(wù)中,常通過改進模型來提取更多的特征信息,進而提高關(guān)系抽取效率,而且外部知識特征也逐漸被引入到關(guān)系抽取模型中輔助關(guān)系分類。例如Li等[1]提出了一種基于因果關(guān)系詞匯的因果關(guān)系抽取模型,模型會將表達因果關(guān)系的詞匯特征引入到卷積神經(jīng)網(wǎng)絡(luò)模型來輔助關(guān)系抽取任務(wù),有效地利用先驗詞匯判別實體間的因果關(guān)系類別。因此,在特定領(lǐng)域中,基于外部知識的關(guān)系抽取模型可以充分利用領(lǐng)域知識和專家經(jīng)驗,為關(guān)系抽取提供豐富的先驗特征,提高特定領(lǐng)域關(guān)系抽取的效率。而且在關(guān)系抽取研究中,常采用Mintz等[2]提出的遠(yuǎn)程監(jiān)督方法,遠(yuǎn)程監(jiān)督方法的自動標(biāo)注數(shù)據(jù)能力可以減少大量人工標(biāo)注的代價,為特定領(lǐng)域缺少標(biāo)注數(shù)據(jù)的困難提供了解決方案。
因此,本文基于Li等[1]的方法提出了基于先驗詞匯的分段池化卷積神經(jīng)網(wǎng)絡(luò)模型K-PCNN,利用領(lǐng)域的關(guān)系先驗詞匯輔助關(guān)系分類任務(wù),并在Li等提出的因果關(guān)系抽取模型的基礎(chǔ)上拓展為多關(guān)系抽取。針對缺少標(biāo)注數(shù)據(jù)的問題,采用了遠(yuǎn)程監(jiān)督的方法進行關(guān)系數(shù)據(jù)自動標(biāo)注。本文的主要貢獻如下:
(1) 提出一種基于先驗詞匯的分段池化卷積神經(jīng)網(wǎng)絡(luò)模型K-PCNN。該模型在卷積神經(jīng)網(wǎng)絡(luò)中引入各類關(guān)系的先驗詞匯知識特征,利用先驗詞匯特征幫助模型判別關(guān)系類型,加強關(guān)系分類能力,以提高關(guān)系抽取性能。
(2) 提出一種基于遠(yuǎn)程監(jiān)督的領(lǐng)域數(shù)據(jù)標(biāo)注方法,利用領(lǐng)域三元組知識以及領(lǐng)域文本語料,基于遠(yuǎn)程監(jiān)督的自動標(biāo)注方法進行領(lǐng)域數(shù)據(jù)集構(gòu)建,并且以金屬材料領(lǐng)域為例,構(gòu)建了金屬材料領(lǐng)域關(guān)系抽取數(shù)據(jù)集MMRE。所提出的構(gòu)建數(shù)據(jù)集的方案也可以應(yīng)用到其他缺乏關(guān)系標(biāo)注數(shù)據(jù)的特定領(lǐng)域中,用于關(guān)系抽取模型的訓(xùn)練和評估。
1 相關(guān)工作
1.1 關(guān)系抽取方法
關(guān)系抽取任務(wù)是構(gòu)建知識圖譜的重要環(huán)節(jié),通過發(fā)現(xiàn)文本中實體對間的語義關(guān)系,為知識圖譜提供關(guān)系特征。目前常用的關(guān)系抽取方法有監(jiān)督學(xué)習(xí)方法、無監(jiān)督學(xué)習(xí)方法和半監(jiān)督學(xué)習(xí)方法。
監(jiān)督學(xué)習(xí)方法采用了深度學(xué)習(xí)模型,將關(guān)系抽取任務(wù)作為關(guān)系分類任務(wù),常用的模型如卷積神經(jīng)網(wǎng)絡(luò)模型[3-5]和循環(huán)神經(jīng)網(wǎng)絡(luò)模型[6-8]。無監(jiān)督學(xué)習(xí)關(guān)系抽取方法是一種聚類方法,主要依據(jù)相同語義關(guān)系具有相同的上下文信息這一特征,通過上下文信息對實體關(guān)系進行聚類,例如Ma[9]采用了K-means聚類算法。半監(jiān)督學(xué)習(xí)方法包含基于BootStrapping的方法和Mintz等[2]提出的遠(yuǎn)程監(jiān)督方法。其中基于BootStrapping的方法是依賴人工標(biāo)注好的種子實例和模板,然后迭代抽取關(guān)系模板和更多實例,例如Gupta等[10]提出了基于高置信度評估的BootStrapping方法;遠(yuǎn)程監(jiān)督方法假設(shè)一個句子中若包含一類關(guān)系涉及的實體對,則該句可以作為此類關(guān)系的訓(xùn)練正例,這種自動標(biāo)注方法大大減少了標(biāo)注數(shù)據(jù)的人工成本,增加了大量的訓(xùn)練樣本。
由于深度學(xué)習(xí)模型對于訓(xùn)練數(shù)據(jù)的依賴,關(guān)系抽取任務(wù)需要大量的關(guān)系標(biāo)注數(shù)據(jù)。以上方法中,監(jiān)督學(xué)習(xí)方法和基于BootStrapping的半監(jiān)督方法均需要標(biāo)注大量的數(shù)據(jù);人工標(biāo)注的方法會耗費大量人力,不能適用于專業(yè)性較強的特定領(lǐng)域;遠(yuǎn)程監(jiān)督方法可以適用于特定領(lǐng)域,快速標(biāo)注大量的領(lǐng)域數(shù)據(jù),為領(lǐng)域關(guān)系抽取模型提供訓(xùn)練數(shù)據(jù)。
1.2 關(guān)系抽取模型
在關(guān)系抽取任務(wù)中,常通過對深度學(xué)習(xí)模型的改進來獲取更多的文本特征,例如,Zeng等[11]在卷積神經(jīng)網(wǎng)絡(luò)模型的基礎(chǔ)上,提出了一種根據(jù)實體對位置進行分段式最大池化的方法,可以獲得更多的文本特征,而且Zeng等[12]通過增加實體的位置信息和其他相關(guān)詞匯特征來提高關(guān)系預(yù)測準(zhǔn)確率。Yan等[13]將句子的詞性特征、依存關(guān)系特征和短語語法樹特征進行融合,得到句子的特征表示,充分利用句子的語義信息,提高Text-CNN模型的抽取效率。Jia等[14]通過注意力機制發(fā)現(xiàn)表達關(guān)系類別的關(guān)系模式,利用發(fā)現(xiàn)的關(guān)系模式來實現(xiàn)關(guān)系抽取任務(wù)。Jat等[15]利用多種詞級注意力模型的互補特性來增強較長文本的句子表示能力,從而提升關(guān)系抽取性能。
以上的研究大多在文本特征的基礎(chǔ)上,繼續(xù)挖掘文本中所包含的重要特征,進而提高模型的關(guān)系抽取效率。但隨著自然語言處理的研究,外部知識賦能的模型逐漸被應(yīng)用于關(guān)系抽取任務(wù)。基于外部知識的關(guān)系抽取模型可以把額外的知識特征作為輔助特征來判斷文本中的關(guān)系類別。例如Li等[1]利用因果關(guān)系的同義詞、近義詞作為關(guān)系先驗詞匯,利用先驗詞匯特征實現(xiàn)關(guān)系類別判斷,增加關(guān)系抽取能力。Zhang等[16]提出了一種基于知識庫的知識感知模型,并將傳統(tǒng)的關(guān)系抽取任務(wù)建模為關(guān)系檢索任務(wù)進行關(guān)系抽取。Zeng等[17]提出了基于關(guān)系路徑的關(guān)系抽取模型,借助中間實體和關(guān)系路徑來進行關(guān)系抽取。Nathani等[18]提出基于圖注意力模型的特征嵌入方法,通過獲取實體對在知識庫中相鄰實體和關(guān)系特征來增強特征表示。Vashishth等[19]利用了知識庫中實體類型和關(guān)系別名作為模型的附加信息,將附加信息作為關(guān)系抽取的軟約束,從而提升關(guān)系抽取性能。在特定領(lǐng)域中,采用基于外部知識特征的關(guān)系抽取方法能夠充分利用領(lǐng)域知識和專家經(jīng)驗,為關(guān)系抽取提供豐富的經(jīng)驗知識,從而提高關(guān)系抽取效率。
基于以上研究思路,本文采用了基于先驗知識的關(guān)系抽取方法,充分利用能夠表達關(guān)系類別的外部詞匯知識輔助領(lǐng)域關(guān)系抽取任務(wù),并選擇具有良好學(xué)習(xí)能力的卷積神經(jīng)網(wǎng)絡(luò)模型作為特征提取模型。同時,利用遠(yuǎn)程監(jiān)督方法的自動標(biāo)注數(shù)據(jù)能力解決特定領(lǐng)域缺少標(biāo)注數(shù)據(jù)的問題。
2 問題描述和概念定義
2.1 問題描述
領(lǐng)域關(guān)系抽取任務(wù)可以為知識圖譜的構(gòu)建擴充三元組的數(shù)量,是發(fā)現(xiàn)實體對之間關(guān)系類別的重要過程。領(lǐng)域關(guān)系抽取任務(wù)的進行離不開領(lǐng)域關(guān)系抽取模型以及領(lǐng)域標(biāo)注數(shù)據(jù)。因此,本文要解決的核心問題是領(lǐng)域先驗詞匯的獲取,以及將先驗詞匯特征應(yīng)用于領(lǐng)域關(guān)系抽取模型,并為模型的訓(xùn)練評估標(biāo)注領(lǐng)域數(shù)據(jù)。本文通過獲取并利用已有的關(guān)系先驗詞匯為抽取模型提供外部特征信息,從而提高領(lǐng)域關(guān)系抽取效率;而且,有效利用領(lǐng)域文本語料及三元組為模型創(chuàng)建領(lǐng)域數(shù)據(jù)集,進行模型訓(xùn)練評估。
2.2 概念定義
在定義相關(guān)概念之前,首先介紹本文中所使用的符號:三元組集合表示為T={T1,T2,…,Tn},Ti=
定義1關(guān)系先驗詞匯知識。本文采用了能夠描述關(guān)系類別的詞匯作為關(guān)系先驗詞匯。關(guān)系先驗詞匯知識是判斷文本所含關(guān)系類別的重要特征。先驗詞匯知識主要是從已有的詞匯知識庫、包含關(guān)系類別的文本語料、三元組中獲取,例如表1所示的Founder關(guān)系的先驗詞匯知識來源。

表1 Founder關(guān)系的先驗詞匯知識獲取來源
定義2領(lǐng)域關(guān)系抽取數(shù)據(jù)集RE。領(lǐng)域關(guān)系抽取數(shù)據(jù)集可表示為RE={(S1,r1),(S2,r2),…,(Sn,rn)},其中(Si,ri)為一組標(biāo)注數(shù)據(jù)。Si=(si,hi,ti),其中:Si為一條標(biāo)注實體對hi和ti的文本;si為未標(biāo)注實體對的純文本;hi為頭實體;ti為尾實體;ri為標(biāo)注的關(guān)系類別。
3 基于先驗詞匯的分段池化卷積神經(jīng)網(wǎng)絡(luò)模型
針對特定領(lǐng)域關(guān)系抽取任務(wù),本文提出基于先驗詞匯的分段池化卷積神經(jīng)網(wǎng)絡(luò)模型K-PCNN。K-PCNN的模型結(jié)構(gòu)如圖1所示,該模型主要包含兩個核心部分:基于先驗詞匯的卷積層(Convolution Layer with Priori Words)和分段池化層(Piecewise Max Pooling)。其中:模型的輸入為文本語句;Embedding Layer為模型嵌入層。最后是實現(xiàn)關(guān)系抽取的分類器。
基于先驗詞匯的卷積層是將關(guān)系先驗詞匯特征作為卷積神經(jīng)網(wǎng)絡(luò)的卷積核權(quán)重,利用關(guān)系先驗知識特征來識別文本中包含的關(guān)系類別。先驗詞匯知識特征是該模型進行關(guān)系分類的重要依據(jù),且先驗詞匯特征是用預(yù)訓(xùn)練的詞向量進行向量表示,不需要在模型訓(xùn)練時重新訓(xùn)練。本文的模型中池化層采用了Zeng等[11]提出的分段池化,可以獲取更多的文本特征,減少降維過程的特征損失。
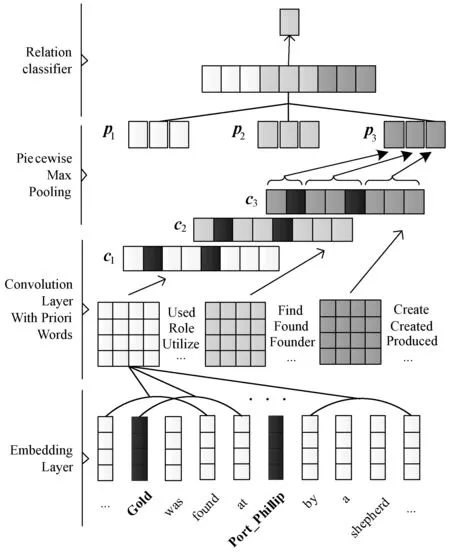
圖1 基于先驗詞匯的分段池化卷積神經(jīng)網(wǎng)絡(luò)模型
3.1 詞嵌入層
本文K-PCNN模型的輸入為一條帶有實體對的文本,例如圖1所示的輸入語句為:“Gold is found at Port_Phillip by a shepherd.”,其中:實體對是“Gold”和“Port_Phillip”;關(guān)系標(biāo)簽為“FOUND”。K-PCNN模型的嵌入層是為了將模型的輸入文本嵌入到低維向量空間。本文采用了Word2vec模型,并利用領(lǐng)域數(shù)據(jù)集的文本進行預(yù)訓(xùn)練,從而得到詞嵌入矩陣。根據(jù)詞嵌入矩陣,得到輸入文本的詞向量矩陣。例如,給定一個文本序列{w1,w2,…,wn},其中n為文本中單詞數(shù)量,根據(jù)詞嵌入矩陣,將文本序列轉(zhuǎn)換為詞向量序列{q1,q2,…,qn},qi∈Rd,d為詞向量維度,如式(1)所示。
qi=fWord2vec(wi)
(1)
式中:wi為文本序列中的單詞;qi為第i個單詞的詞向量表示;fWord2vec表示W(wǎng)ord2vec模型函數(shù)。
3.2 基于先驗詞匯的卷積層
基于先驗詞匯的卷積層將關(guān)系先驗詞匯特征作為卷積核參數(shù),即先驗詞匯的詞向量作為卷積核的權(quán)重參數(shù),進行卷積運算。利用先驗詞匯特征來辨別文本中包含的關(guān)系類別。因此,本節(jié)主要介紹關(guān)系類別先驗詞匯知識的獲取與應(yīng)用。
先驗詞匯特征是關(guān)系分類的重要特征,關(guān)系先驗知識的豐富性有助于關(guān)系類別的判斷。WordNet[20]和FrameNet[21]兩個詞匯知識庫包含了大量的詞匯知識,可以為關(guān)系抽取提供重要的詞匯知識。除此之外,在領(lǐng)域數(shù)據(jù)集的語料文本中已經(jīng)包含了各個類別的文本信息,也是判斷關(guān)系類別的重要先驗知識。因此,本文利用詞匯知識庫和領(lǐng)域數(shù)據(jù)集來獲取相關(guān)詞匯知識,并通過專家對獲取的詞匯進行篩選,最終得到應(yīng)用于模型的關(guān)系先驗詞匯。專家篩選是為了將表達關(guān)系類別的重要先驗詞匯篩選出來,領(lǐng)域?qū)<艺莆沼写罅款I(lǐng)域知識及經(jīng)驗,能夠快速判斷關(guān)系類別的相關(guān)先驗詞匯,用于關(guān)系類別的判別。關(guān)系先驗詞匯的獲取及篩選流程如圖2所示。
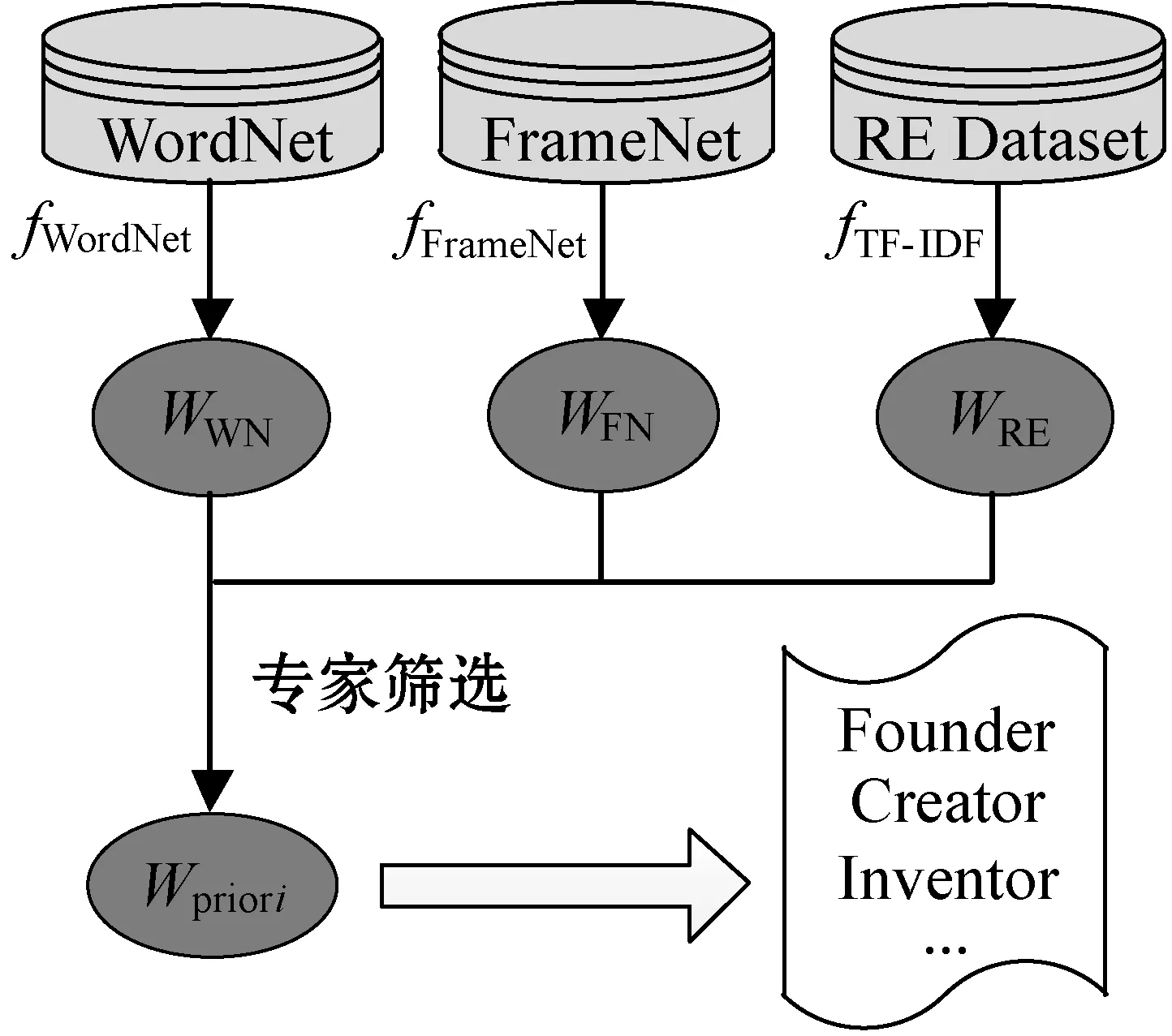
圖2 關(guān)系先驗詞匯的獲取流程
先驗詞匯知識的獲取過程如下:
Step1從WordNet和FrameNet中獲取關(guān)系先驗詞匯。WordNet和FrameNet作為兩個詞匯知識庫,其中包含了較為完整的詞匯知識,并分別利用同義詞集和詞匯框架將詞匯之間鏈接起來。給定要進行抽取的關(guān)系類別標(biāo)簽r,將關(guān)系類別標(biāo)簽作為查詢關(guān)鍵詞,在WordNet和FrameNet中進行同義詞和近義詞的提取,獲得詞匯集合WWN和WFN,分別表示為:
WWN=fWordNet(r)
(2)
WFN=fFrameNet(r)
(3)
式中:fWordNet和fFrameNet分別為WordNet、FrameNet同義詞、近義詞提取函數(shù);WWN和WFN分別是從WordNet和FrameNet提取的關(guān)系類別r的相關(guān)詞匯集合。
Step2從領(lǐng)域數(shù)據(jù)集獲取關(guān)系先驗詞匯。領(lǐng)域數(shù)據(jù)集在本文中不僅作為關(guān)系抽取訓(xùn)練集,也將用于抽取關(guān)系先驗詞匯。本文利用TF-IDF算法來提取數(shù)據(jù)集文本中的重要詞匯信息。給定數(shù)據(jù)集中該類關(guān)系的文本語句集合{s1,s2,…,sm},利用TF-IDF算法得到根據(jù)詞頻排序的語料詞匯集合WRE,表示為:
WRE=fTF-IDF({s1,s2,…,sm})
(4)
式中:fTF-IDF表示為TF-IDF算法函數(shù);WRE為利用TF-IDF算法得到的語料詞匯集合。
Step3專家篩選關(guān)系先驗詞匯。關(guān)系類別的相關(guān)詞匯詞集WWN、WFN和WRE包含了關(guān)系類別的一些相關(guān)詞匯,但是詞集的詞匯數(shù)量繁多需要進行篩選,得到能夠充分描述關(guān)系類別的先驗詞匯。篩選過程采用了專家人工篩選的方法,可以更為準(zhǔn)確地保留關(guān)系類別的重要先驗詞匯知識,有助于模型對關(guān)系類別的分類能力,公式表示為:
Wpriori=fExpert(WWN,WFN,WRE)
(5)
式中:fExpert表示為專家篩選先驗詞匯過程;Wpriori為得到的關(guān)系類別的先驗詞匯集集合。
經(jīng)過以上方法得到先驗詞匯集Wpriori后,在進行模型分類前需要根據(jù)詞嵌入矩陣將先驗詞匯轉(zhuǎn)換為詞向量,得到先驗詞匯特征矩陣F,如式(6)所示。特征矩陣F將作為卷積層的卷積核權(quán)重進行模型訓(xùn)練和分類。
F=fWord2vec(Wpriori)
(6)
式中:fWord2vec表示為Word2vec模型函數(shù);F為先驗詞匯特征矩陣。
卷積層可以包含有多個卷積核,因此不同關(guān)系類別的先驗詞匯特征矩陣將作為不同的卷積核權(quán)重進行卷積,多卷積核的應(yīng)用能夠獲取不同的特征。若模型輸入一條語句{w1,w2,…,wn},其中n為單詞個數(shù);經(jīng)過嵌入層后得到詞向量序列{q1,q2,…,qn},qi∈Rd,其中d為詞向量維度;卷積核長度為k,卷積核權(quán)重矩陣為F,F(xiàn)∈Rk×d,則嵌入層的第i行到第j行矩陣qi:j與F卷積計算過程如下:
cj=Fqj-k+1:j
(7)
式中:cj為卷積計算得到的特征值,j∈[1,n+k-1]。卷積完成后得到特征圖為c∈Rn+k-1。
3.3 分段池化層
在卷積神經(jīng)網(wǎng)絡(luò)模型中,經(jīng)過卷積后得到的特征圖會通過池化層來降低維度大小,防止過擬合,并且可以保留重要的特征信息。池化層常用的設(shè)置為最大池化,即取特征值中的最大值。為了獲取更多的文本特征,Zeng等[11]提出了分段池化設(shè)置。分段池化是把卷積后的特征圖矩陣根據(jù)實體對的位置切割為三段,再進行最大池化的方法,如圖1中Piecewise Max Pooling部分。相比于普通的最大池化只獲得了一個特征值,分段池化將三段分別求最大池化,可以保留更多的特征信息。
在關(guān)系抽取模型中,模型輸入為一個文本序列,轉(zhuǎn)換為詞向量序列后進入卷積層,經(jīng)過卷積得到若干個特征圖{c1,c2,…,cm},ci∈Rn+k-1。若對其中一個個特征圖ci進行最大池化,得到池化后的結(jié)果僅為一個特征值pi,如式(8)所示。若把特征圖ci根據(jù)實體對位置進行分段處理,將ci分為三段{ci1,ci2,ci3},再分別對三段進行最大池化,便可得到三維向量pi=(pi1;pi2;pi3),如式(9)所示。
pi=max(ci)
(8)
pij=max(cij) 1≤i≤m,1≤j≤3
(9)
模型經(jīng)過卷積層和池化層后,得到的特征矩陣?yán)^續(xù)在分類器中實現(xiàn)關(guān)系的分類。經(jīng)過卷積層和池化層后的特征矩陣包含了文本的重要特征以及關(guān)系類別特征,最終這些特征矩陣進入關(guān)系分類器利用Sigmoid函數(shù)實現(xiàn)關(guān)系分類。
4 基于遠(yuǎn)程監(jiān)督的領(lǐng)域數(shù)據(jù)標(biāo)注方法
特定領(lǐng)域關(guān)系抽取模型的訓(xùn)練和評估離不開大量的標(biāo)注數(shù)據(jù)。在特定領(lǐng)域中,傳統(tǒng)的人工標(biāo)注方法需要大量的人工參與。因此,本文根據(jù)關(guān)系抽取模型的訓(xùn)練數(shù)據(jù)需求,提出基于遠(yuǎn)程監(jiān)督的數(shù)據(jù)標(biāo)注方法,如圖3所示。該方法主要應(yīng)用了遠(yuǎn)程監(jiān)督的自動標(biāo)注能力,利用特定領(lǐng)域的三元組知識和語料文本進行數(shù)據(jù)集構(gòu)建。
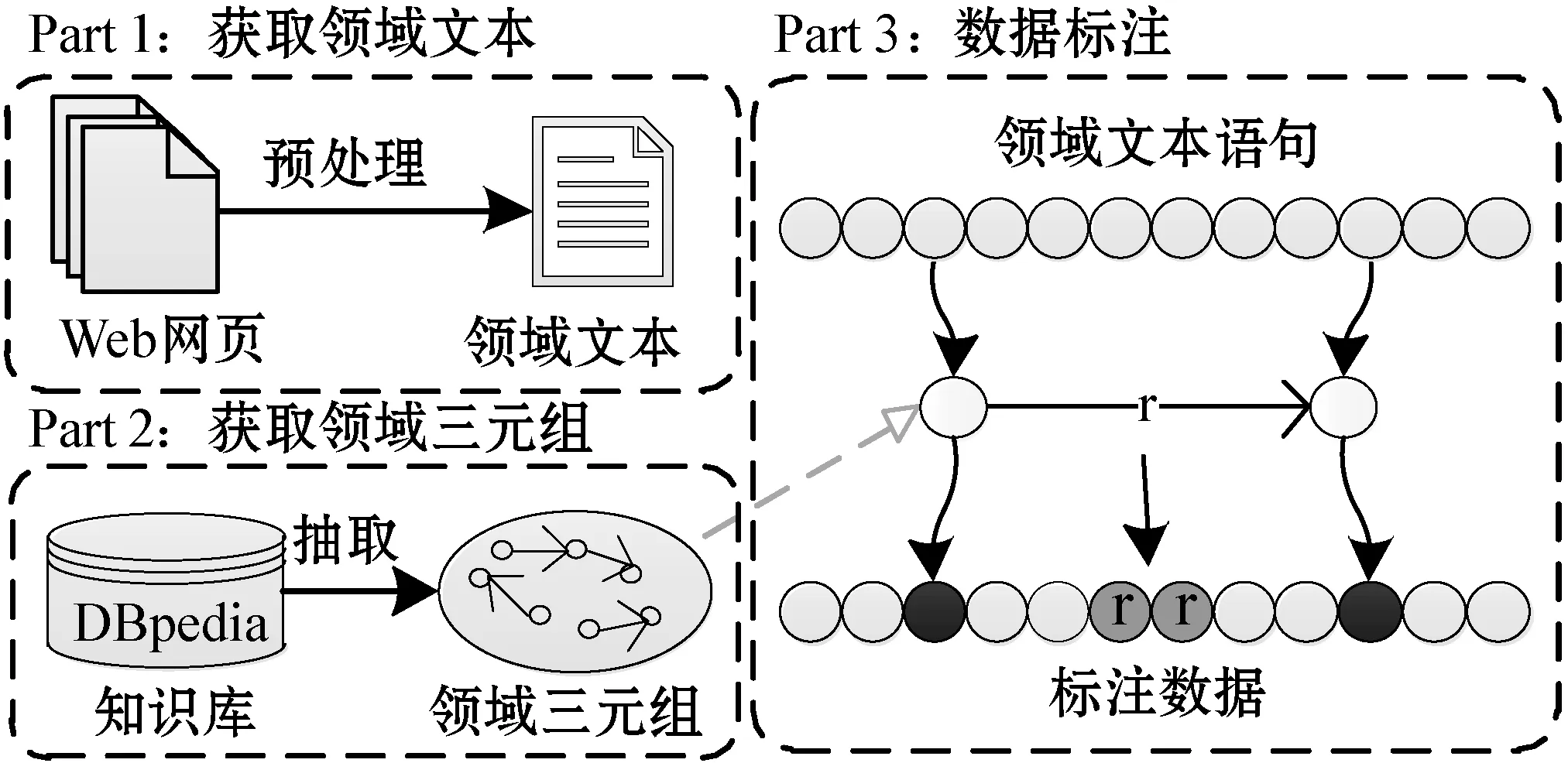
圖3 領(lǐng)域數(shù)據(jù)標(biāo)注流程
遠(yuǎn)程監(jiān)督數(shù)據(jù)標(biāo)注方法的具體實現(xiàn)是根據(jù)文本中是否存在實體對而進行關(guān)系標(biāo)注的。因此,根據(jù)遠(yuǎn)程監(jiān)督方法進行數(shù)據(jù)標(biāo)注需要獲取領(lǐng)域三元組及領(lǐng)域語料文本。本文將數(shù)據(jù)標(biāo)注過程設(shè)置為三部分:獲取領(lǐng)域語料文本,獲取領(lǐng)域三元組知識和領(lǐng)域數(shù)據(jù)標(biāo)注。其中:Part1為從Web網(wǎng)頁中爬取領(lǐng)域文本;Part2為從DBpedia等知識庫獲取領(lǐng)域三元組知識;Part3為數(shù)據(jù)標(biāo)注過程。
4.1 基于DBpedia與Wikipedia的領(lǐng)域語料與三元組抽取方法
Wikipedia是一個跨學(xué)科跨領(lǐng)域的百科全書,其中包含了大量的語料文本,而DBpedia是一個開放知識圖譜,包含了大量來自Wikipedia的三元組知識,并且與Wikipedia的資源相關(guān)聯(lián)。因此,本文依據(jù)DBpedia知識圖譜結(jié)構(gòu),在Wikipedia和DBpedia中抽取領(lǐng)域文本與領(lǐng)域三元組知識。
本節(jié)以金屬材料領(lǐng)域為例,介紹基于DBpedia與Wikipedia的領(lǐng)域語料與三元組抽取方法,并采用了Zhang等[22]提出的逐步提取策略(Stepwise Extraction Strategy,SES)。領(lǐng)域文本與三元組的抽取過程主要包含創(chuàng)建候選類別實體集合、抽取DBpedia中的領(lǐng)域三元組、抽取Wikipedia中的語料文本、迭代擴充四個步驟,抽取流程如圖4所示。領(lǐng)域語料文本及三元組抽取的具體步驟如下:
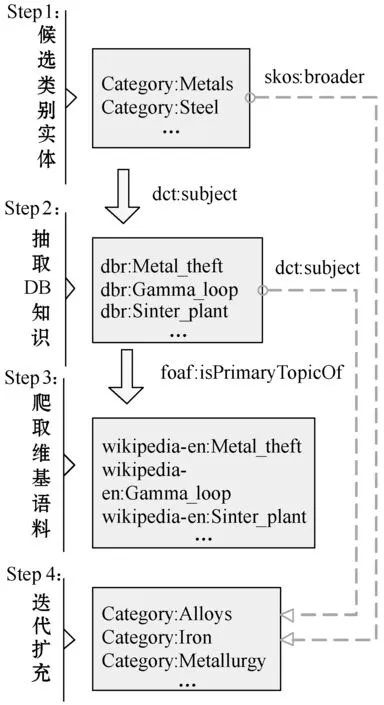
圖4 領(lǐng)域語料及三元組抽取流程
Step1創(chuàng)建候選類別實體集合Edbc。DBpedia中實體可以分為兩類:一類為表示類別的類別實體edbc,例如“dbc:Metals”;另一類為表示資源的資源實體edbr,例如“dbr:Iron”。候選類別實體集合Edbc是由人工初始化的一些金屬材料類別實體組成。
Step2抽取DBpedia中的領(lǐng)域三元組。根據(jù)DBpedia中類別實體和資源實體之間的關(guān)系類別“dct:subject”,可以從DBpedia API中獲取類別實體對應(yīng)的資源實體,例如圖4中類別實體“dbc:Metals”根據(jù)三元組
Step3抽取Wikipedia中的領(lǐng)域語料文本。已知DBpedia的三元組知識均源于Wikipedia,并且每一個資源實體都通過“foaf:isPrimaryTopicOf”關(guān)系鏈接到相應(yīng)的Wikipedia網(wǎng)頁資源,例如
Step4迭代擴充實體集合與語料文本。在DBpedia中資源實體與類別實體存在關(guān)系“dct:subject”,而類別實體之間存在包含關(guān)系“skos:broader”。因此,根據(jù)這兩類關(guān)系可以對初步得到的類別實體集合進行擴充,從而得到更多的領(lǐng)域語料文本和三元組。
領(lǐng)域語料文本及三元組抽取方法的具體實現(xiàn)算法如算法1所示。算法的輸入是候選類別實體集合Edbc,迭代次數(shù)k,算法結(jié)束后,將返回領(lǐng)域文本集合D與領(lǐng)域三元組集合T。
算法1領(lǐng)域語料文本及三元組抽取算法
輸入:Edbc,k。
輸出:D,T。
1.Edbr=?,D=?,T=?,j=0
2.ForeachedbcinEdbc
3.Ifj>kdo
4.break
9.j=j+1
10.ForeachedbrinEdbr
11.doc=fisprimarytopicof(edbr)
12.D=D∪{doc}
13.{trii|i∈Z+}=fDBpedia(edbr)
14.T=T∪{trii|i∈Z+}
17.j=j+1
18.EndFor
19.EndFor
20.ReturnD,T
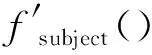
圖5所示為根據(jù)算法1實現(xiàn)的實體擴充實例。以“dbc:Metals”為候選類別實體,可以通過“dct:subject”和“is skos:broader of”兩種關(guān)系,經(jīng)過兩次迭代即可獲得“dbc:Iron”等五種類別實體及其資源實體。
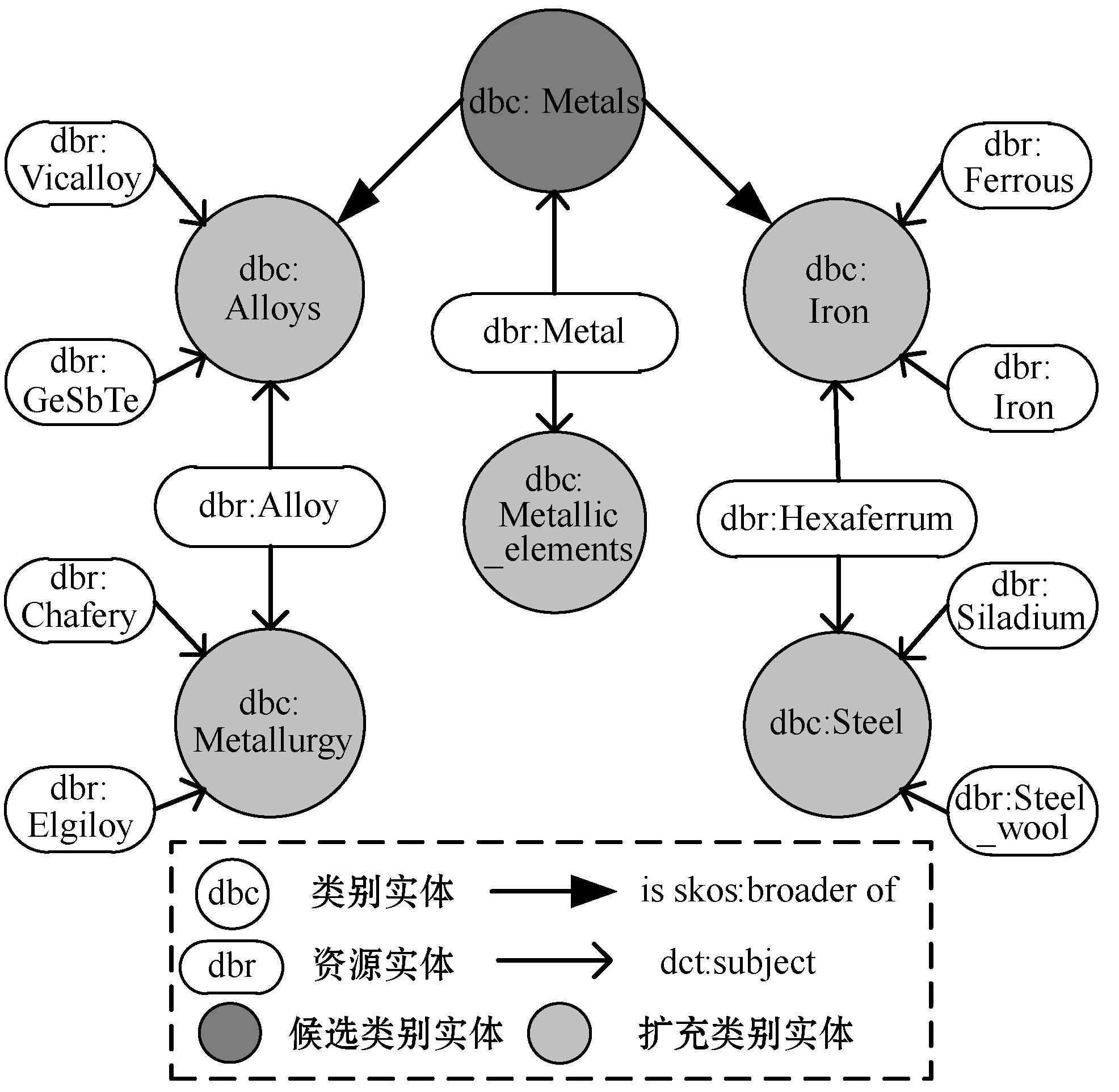
圖5 DBpedia領(lǐng)域?qū)嶓w迭代擴充示例
4.2 基于OpenIE與ReVerb的領(lǐng)域三元組擴充方法
經(jīng)過對Wikipedia和DBpedia中領(lǐng)域文本和三元組的抽取,可以得到領(lǐng)域文本集合與領(lǐng)域三元組集合。但是,在抽取的語料文本中仍然存在著許多DBpedia未包含的三元組知識。因此,為了獲取更多的三元組知識,本文提出基于OpenIE與ReVerb的領(lǐng)域三元組擴充方法,利用開放信息抽取工具OpenIE[23]與ReVerb[24],繼續(xù)抽取領(lǐng)域文本中所包含的三元組知識,擴充領(lǐng)域三元組集合。OpenIE與ReVerb是兩個重要的開放信息抽取模型,使用之前不需要提前指定關(guān)系,即可從句子中抽取三元組。領(lǐng)域三元組擴充方法的步驟主要分為兩步,過程如下:
(1) 三元組抽取。該步驟主要利用OpenIE和ReVerb兩種工具對從Wikipedia獲取的領(lǐng)域文本進行三元組抽取。
(2) 三元組篩選。篩選過程主要利用置信度來篩選出高置信度的三元組。置信度篩選利用了OpenIE與ReVerb的置信度評分進行篩選三元組,選取置信度高于0.8的三元組。如表2所示,兩種抽取工具對同一文本的抽取結(jié)果及三元組置信度評分。最后將篩選的三元組擴充到領(lǐng)域三元組集合,用于數(shù)據(jù)標(biāo)注過程。
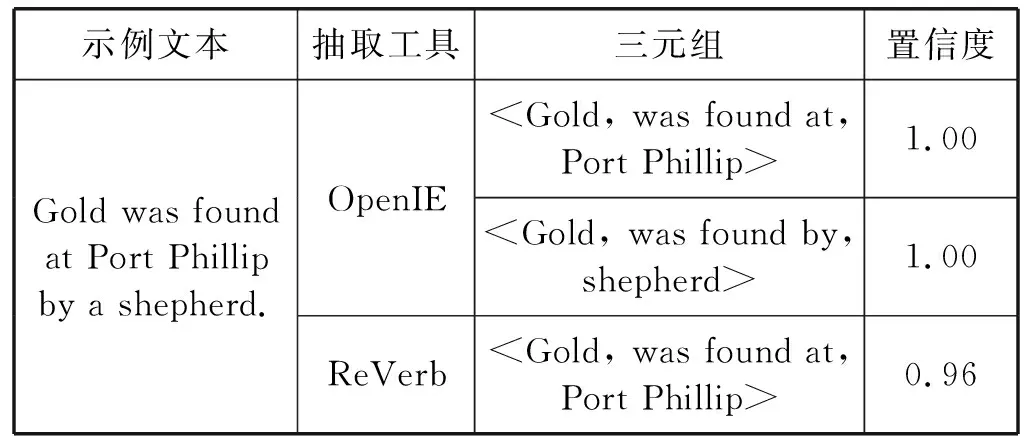
表2 OpenIE與ReVerb抽取三元組示例
4.3 基于遠(yuǎn)程監(jiān)督的領(lǐng)域數(shù)據(jù)標(biāo)注
基于上述方法,可以得到領(lǐng)域語料文本集合及三元組集合。利用得到的文本和三元組,就可以基于遠(yuǎn)程監(jiān)督方法進行數(shù)據(jù)標(biāo)注,標(biāo)注示例如圖6所示。在數(shù)據(jù)標(biāo)注前,首先將文本語料進行數(shù)據(jù)清洗,指代消解、分句等預(yù)處理,最終得到一系列文本語句;然后將得到的文本語句及三元組根據(jù)遠(yuǎn)程監(jiān)督方法進行數(shù)據(jù)標(biāo)注。遠(yuǎn)程監(jiān)督方法對文本的標(biāo)注依據(jù)是文本序列中是否存在三元組的實體對,若文本中存在實體對,則進行關(guān)系標(biāo)注,表示為:
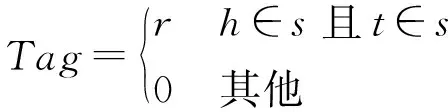
(10)
式中:s={w1,w2,…,wn},s表示待標(biāo)注的文本序列,wi表示s中的單詞;h、r、t分別是三元組
圖6所示是以金屬材料領(lǐng)域為例的領(lǐng)域數(shù)據(jù)標(biāo)注示例。圖6中實例1文本中包含了三元組
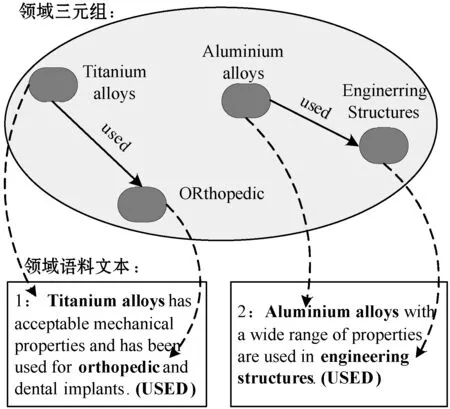
圖6 金屬材料領(lǐng)域數(shù)據(jù)標(biāo)注示例
5 實 驗
5.1 實驗數(shù)據(jù)
由于領(lǐng)域缺少專有的關(guān)系抽取數(shù)據(jù)集,因此本文的實驗數(shù)據(jù)利用所提出的基于遠(yuǎn)程監(jiān)督的領(lǐng)域數(shù)據(jù)標(biāo)注方法進行自動標(biāo)注,構(gòu)建了金屬材料領(lǐng)域關(guān)系抽取數(shù)據(jù)集MMRE。并且,通過對三元組關(guān)系的篩選,選擇了其中四類主要實體關(guān)系,共包含了7 000多條標(biāo)注文本,具體關(guān)系類別如表3所示。
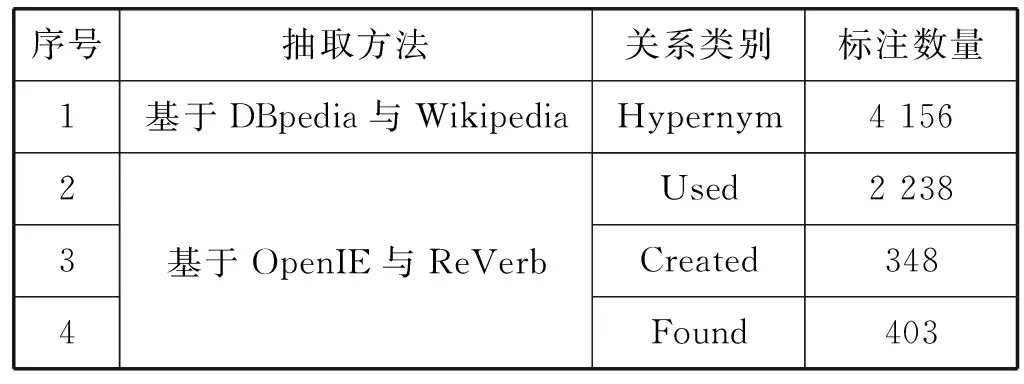
表3 MMRE數(shù)據(jù)集包含的關(guān)系類別
除了領(lǐng)域數(shù)據(jù)集,本文還采用了關(guān)系抽取任務(wù)中廣泛應(yīng)用的NYT[25]數(shù)據(jù)集進行模型的評估。NYT數(shù)據(jù)集共包含53種關(guān)系類別,本文從中選擇了4類關(guān)系進行評估實驗,具體的關(guān)系類別如表4所示。
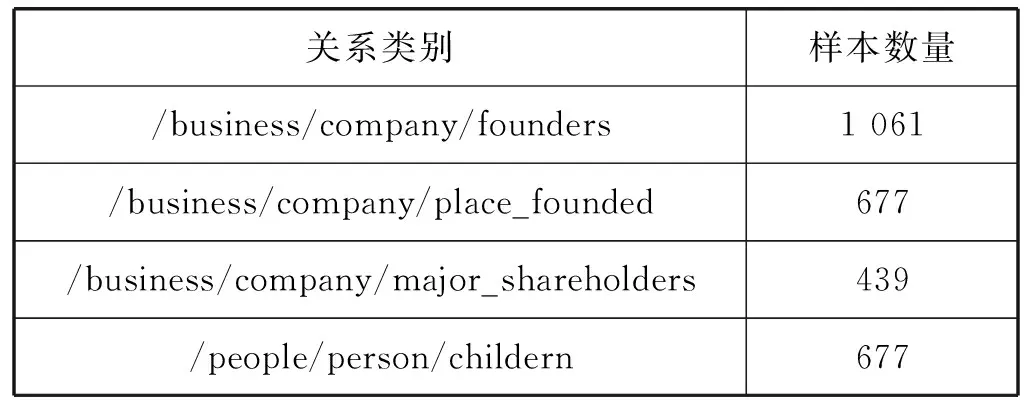
表4 NYT數(shù)據(jù)集中的4種關(guān)系類別
5.2 評價指標(biāo)
本文的關(guān)系抽取實驗采用了內(nèi)部自動評測方法來評價關(guān)系抽取模型的性能,以F1值為評價標(biāo)準(zhǔn)對關(guān)系抽取效果進行綜合評估。除此之外,為了能清楚地了解模型對每一類關(guān)系的抽取效果,采用ROC評估曲線的AUC值對各類關(guān)系的抽取效果進行詳細(xì)評估。
ROC評估曲線主要表現(xiàn)為一種真正率與假正率之間的權(quán)衡。AUC值即ROC曲線與橫軸之間的面積,AUC值的計算表示為:
(11)
式中:M為某類關(guān)系的正例樣本數(shù)量;N為非此類關(guān)系的負(fù)例樣本數(shù)量;PT為正例樣本的預(yù)測概率;PF為負(fù)例樣本的預(yù)測概率;(PT,PF)為樣本對,即一個正例樣本與一個負(fù)例樣本的組合;I(PT,PF)為所有樣本對中,正例樣本的預(yù)測概率大于負(fù)例樣本的預(yù)測概率的個數(shù)。
5.3 實驗方法
在對關(guān)系抽取任務(wù)的研究中,本文選用了卷積神經(jīng)網(wǎng)絡(luò)作為關(guān)系抽取基礎(chǔ)模型。因此,為了提升模型泛化能力,防止過擬合現(xiàn)象,本文采用了模型正則化方法和數(shù)據(jù)擴增的方法,并且實驗過程中采用了K折交叉驗證的訓(xùn)練方法。
在數(shù)據(jù)量有限、樣本不均衡等情況下,模型訓(xùn)練會受到數(shù)據(jù)集的限制而不能達到最優(yōu)。Wei等[26]提出了一種數(shù)據(jù)增強技術(shù)(Easy Data Augmentation,EDA),該技術(shù)為小數(shù)據(jù)集的訓(xùn)練提供了數(shù)據(jù)優(yōu)化方法,可以顯著提高模型性能并減少過擬合。同時,考慮到實驗標(biāo)注數(shù)據(jù)中實體對位置不能隨意變換,不能隨機刪除或增加詞匯,因此,采用了EDA的同義詞替換和變換詞序的方法來增強MMRE數(shù)據(jù)集。
在MMRE數(shù)據(jù)集的基礎(chǔ)上,本文分別采用了EDA技術(shù)的同義詞替換和變換詞序方法,生成了兩個新的數(shù)據(jù)集:同義詞替換后的數(shù)據(jù)集MMRE_eda和原文本逆轉(zhuǎn)詞序后的數(shù)據(jù)集MMRE_rev。表5展示了增強后數(shù)據(jù)集樣本數(shù)量情況,其中:MMRE_ori是原始MMRE數(shù)據(jù)集;MMRE_all是MMRE_eda和MMRE_rev兩個數(shù)據(jù)集的集合。
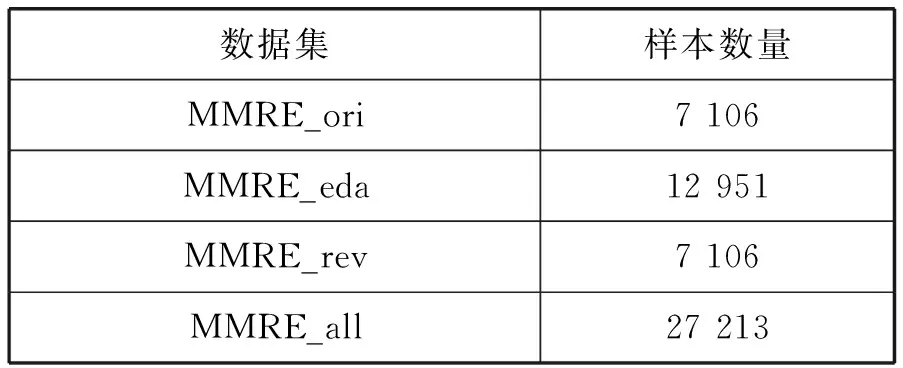
表5 數(shù)據(jù)增強后的各個數(shù)據(jù)集情況
5.4 超參數(shù)設(shè)置
實驗過程中,為了提高模型的性能,本文以F1值為評價指標(biāo),從詞向量維度、文本序列長度方面判斷了兩種參數(shù)對實驗訓(xùn)練過程F1值的影響。詞向量維度是模型將文本嵌入到向量空間時向量維度的大小,文本序列長度是指輸入文本轉(zhuǎn)換為詞向量序列時進行擴充或切割而得到的序列長度。
本文將詞向量維度范圍設(shè)置為100到400,數(shù)值間隔為50,文本序列長度范圍為200到500,數(shù)值間隔為50,利用網(wǎng)格搜索方法選取兩組參數(shù)中的最優(yōu)組合。實驗如圖7所示。
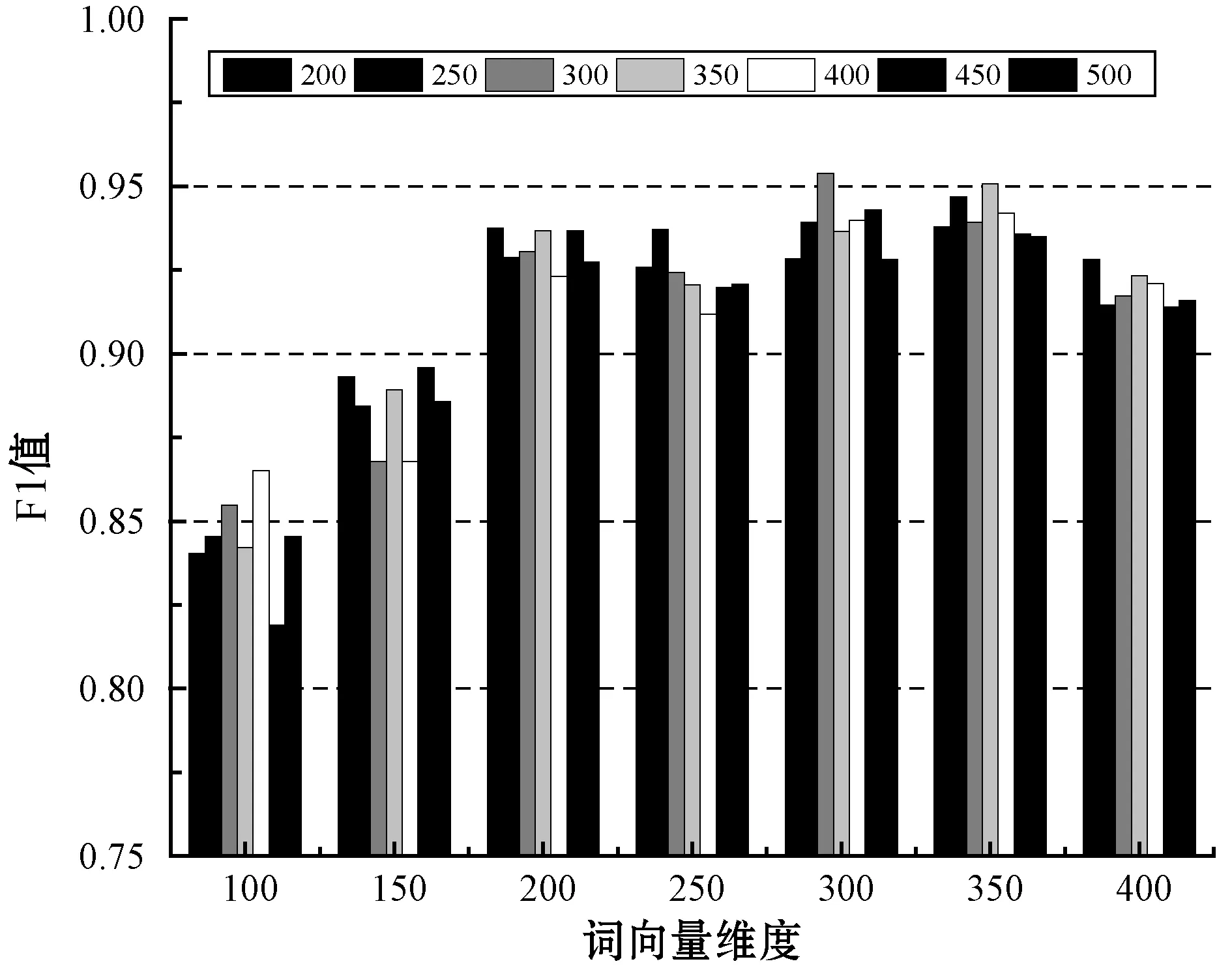
圖7 不同詞向量維度與不同詞序列長度參數(shù)組合實驗
圖7中橫軸為不同的詞向量維度,每個詞向量維度對應(yīng)7個不同的詞序列長度。根據(jù)圖7中縱軸F1值可知,當(dāng)詞向量維度為300且詞序列長度為300時,F(xiàn)1值最大,為最佳參數(shù)組合。其中,不同詞向量維度和不同詞序列長度分別對模型F1值的影響如圖8、圖9所示。
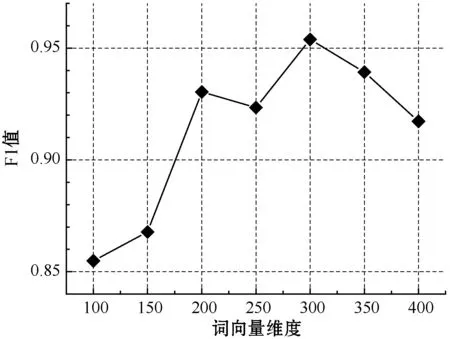
圖8 不同詞向量維度對模型F1值的影響
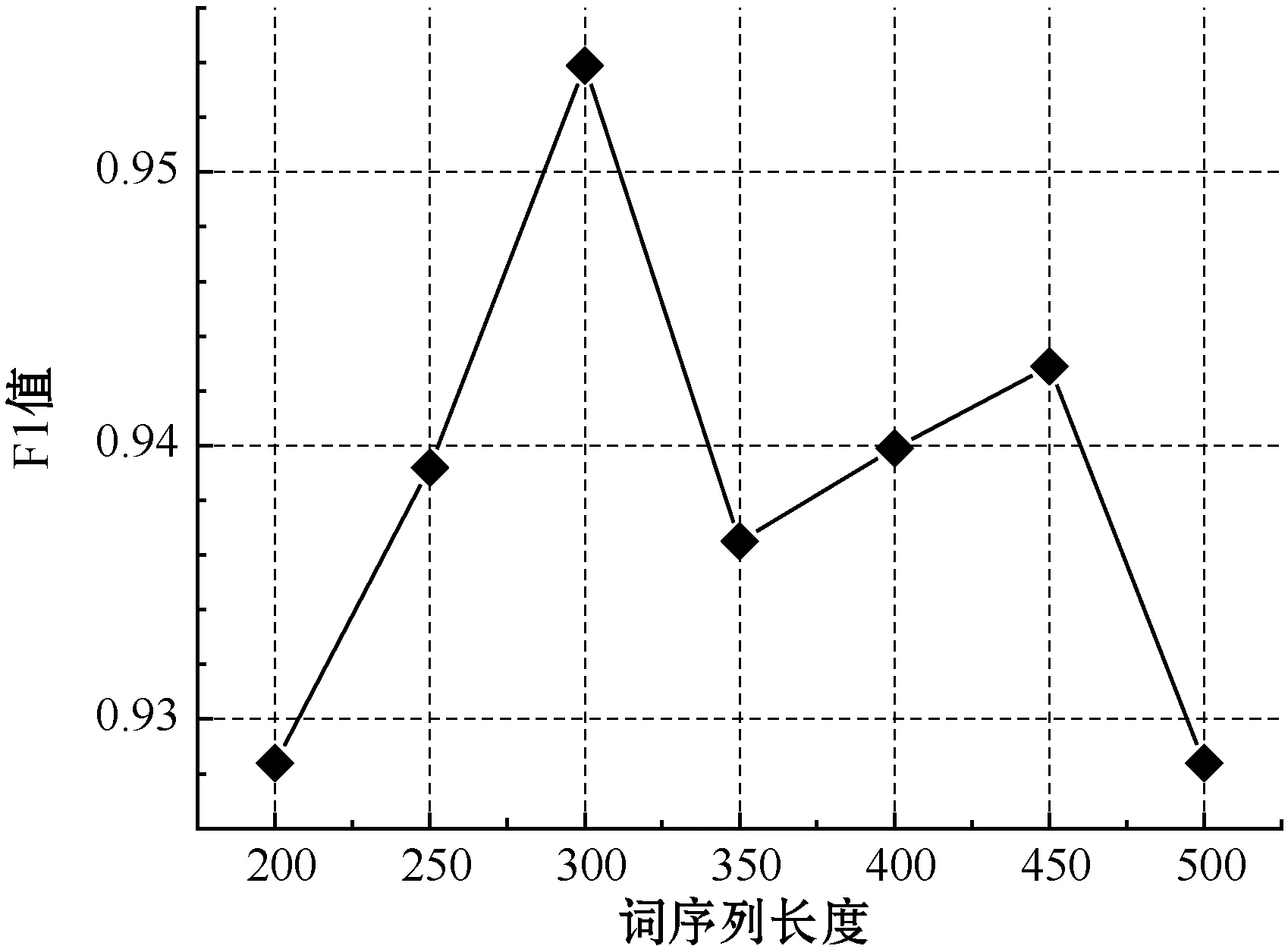
圖9 不同詞序列長度對模型F1值的影響
如圖8所示,當(dāng)詞序列長度為300時,經(jīng)過7種不同詞向量維度的F1值對比可知,隨著詞向量維度增加,在300維時,F(xiàn)1值達到最高;并且在300維之后,隨著維度遞增,F(xiàn)1值逐漸減小。因此,最優(yōu)詞向量維度為300維。
如圖9所示,當(dāng)詞向量維度為300時,隨著詞序列長度的不斷增加,F(xiàn)1值不斷上升,并在數(shù)值為300時,F(xiàn)1值達到最高點,因此實驗中文本在輸入層是統(tǒng)一采用的序列長度為300。
本文的超參數(shù)設(shè)置如表6所示。
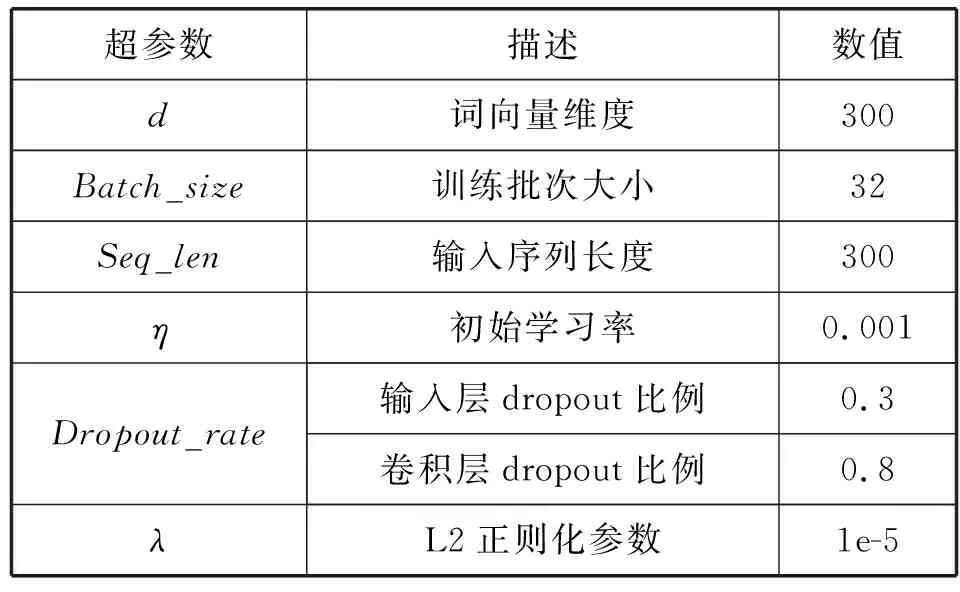
表6 實驗超參數(shù)設(shè)置
5.5 關(guān)系分類實驗
(1) 綜合性能F1值評估。為了評價本文提出的K-PCNN模型在關(guān)系抽取任務(wù)的性能效果,本文選擇Zeng等[11]提出的PCNN模型的改進模型PCNNwWLA進行對比實驗。對比實驗分別在領(lǐng)域數(shù)據(jù)集和公共數(shù)據(jù)集上進行。表7為K-PCNN模型與PCNNwWLA模型的測試集F1值對比。
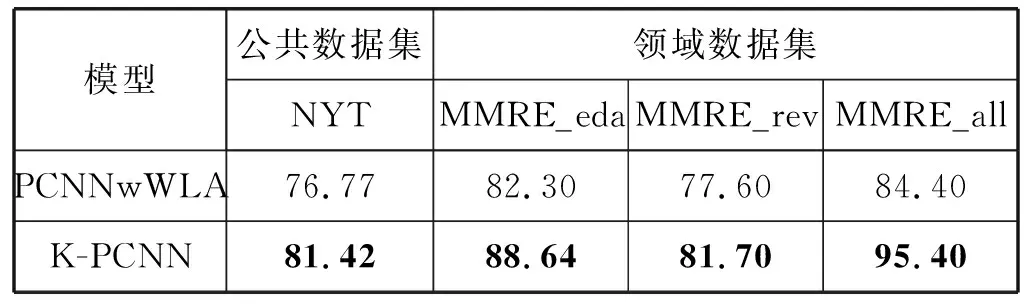
表7 測試集F1值對比
表7所示實驗結(jié)果顯示,在領(lǐng)域數(shù)據(jù)集和公共數(shù)據(jù)集的對比實驗中,K-PCNN的F1值均達到80以上,且均略高于PCNNwWLA模型。實驗結(jié)果分析可知,領(lǐng)域先驗詞匯特征的應(yīng)用有助于提高模型關(guān)系分類能力,且數(shù)據(jù)增強后的數(shù)據(jù)集也提高了模型的分類效果,使得K-PCNN模型關(guān)系抽取性能略高于PCNNwWLA模型。表8為本文模型對金屬材料領(lǐng)域語料的關(guān)系預(yù)測實例。
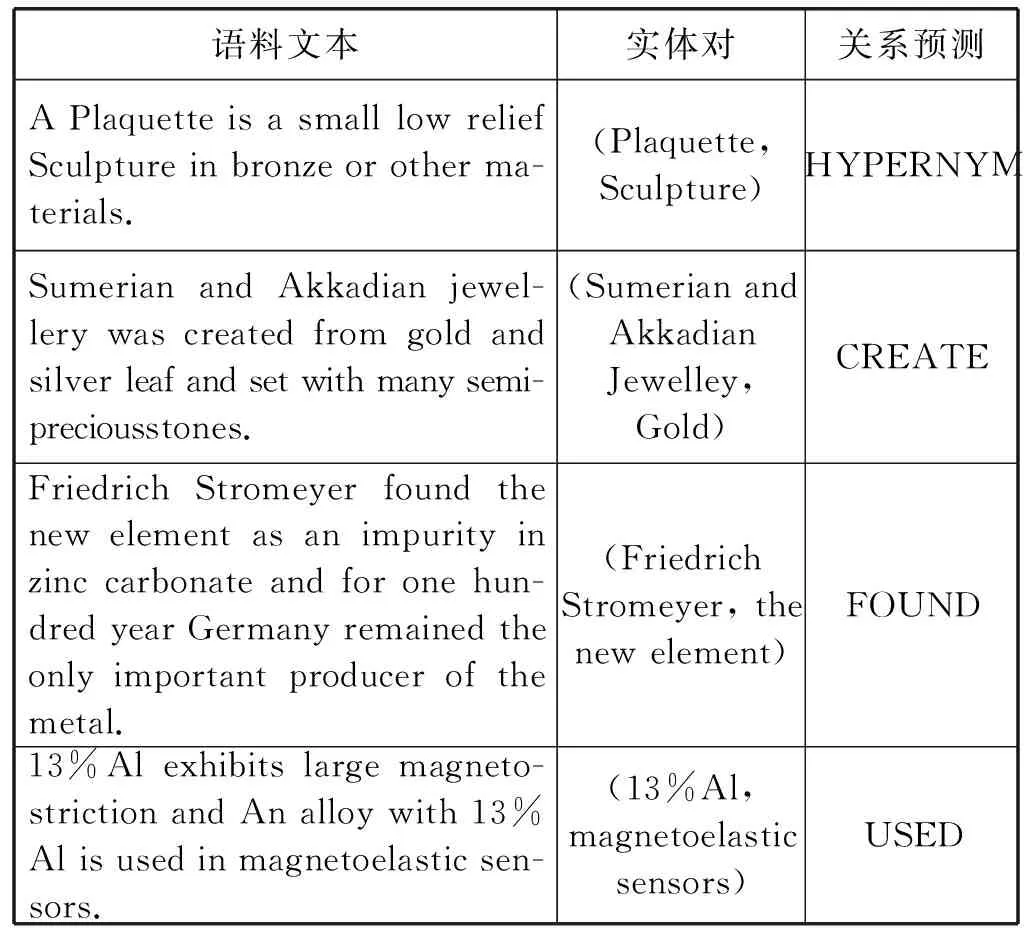
表8 K-PCNN模型關(guān)系預(yù)測實例
(2) 關(guān)系類別的AUC值評估。在經(jīng)過數(shù)據(jù)增強方法得到的領(lǐng)域數(shù)據(jù)集上,K-PCNN模型對四類關(guān)系的預(yù)測能力以及四類關(guān)系的AUC平均值變化如圖10所示。
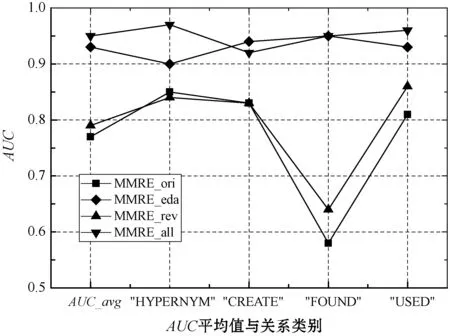
圖10 關(guān)系類別AUC的對比
可以看出,在MMRE_all數(shù)據(jù)集中四類關(guān)系的AUC均高于0.9,說明模型K-PCNN對各類關(guān)系都有較強的分類能力。并且,K-PCNN模型在增強后的數(shù)據(jù)集上對每類關(guān)系的分類性能均優(yōu)于原數(shù)據(jù)集,實驗說明了數(shù)據(jù)增強技術(shù)有助于提高模型的性能。
6 結(jié) 語
本文在特定領(lǐng)域關(guān)系抽取任務(wù)中,針對領(lǐng)域關(guān)系抽取任務(wù)缺少適用模型及缺少領(lǐng)域標(biāo)注數(shù)據(jù)的兩個挑戰(zhàn),分別提出基于先驗詞匯的分段池化卷積神經(jīng)網(wǎng)絡(luò)模型K-PCNN和基于遠(yuǎn)程監(jiān)督的領(lǐng)域數(shù)據(jù)標(biāo)注方法。K-PCNN模型充分利用了關(guān)系先驗詞匯進行關(guān)系分類,將獲取的關(guān)系詞匯知識嵌入詞向量后,輸入到卷積神經(jīng)網(wǎng)絡(luò)模型作為外部知識特征輔助關(guān)系分類。并且,本文以金屬材料領(lǐng)域為例,創(chuàng)建了金屬材料領(lǐng)域關(guān)系抽取數(shù)據(jù)集,對模型的性能進行了評估。實驗數(shù)據(jù)表明,該模型具有較高的關(guān)系抽取能力,說明本文提出的關(guān)系抽取模型以及數(shù)據(jù)標(biāo)注方法能夠在一定程度上解決特定領(lǐng)域關(guān)系抽取任務(wù)的問題,具有一定的現(xiàn)實意義。
雖然本文提出的基于先驗詞匯的關(guān)系抽取模型達到了較高的關(guān)系抽取性能,但是模型僅僅引入了能夠表達關(guān)系類別的先驗詞匯知識,不能充分利用其他的外部知識或特征來輔助關(guān)系分類;而且,由于對先驗詞匯的依賴性,該模型只能抽取一些具有明顯關(guān)系特征的關(guān)系類別,可抽取的關(guān)系類別有一定限制。因此,未來的工作將嘗試把先驗知識的范圍進行拓展,例如實體類別等外部知識;并通過擴展更多的先驗知識來增加可以抽取的關(guān)系類別。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中華胰腺病雜志(2021年1期)2021-02-26 11:28:36
山東醫(yī)藥(2020年34期)2020-12-09 01:22:24
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
制造技術(shù)與機床(2019年10期)2019-10-26 02:48:08
中華胰腺病雜志(2019年4期)2019-08-29 08:52:20
電子制作(2018年18期)2018-11-14 01:48:06
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
