核主成分與隨機森林相融合的配電網線損計算方法研究
2022-09-13 02:14:48趙成斌
能源與環保 2022年8期
張 華,陳 淼,孫 博,趙成斌
(國網上海浦東供電公司,上海 200122)
線損是電網經濟運行水平的關鍵指標,同時也是反映供電公司管理水平的重要考核指標[1]。尤其是對于一些偏遠地區,存在著諸如供電設備老化、電網結構不合理、竊電等問題,會使得該地區出現很高的電能損耗[2],而通過配電網線損計算可為該地區電網結構及運行方式的優化提供很好的技術指導[3]。因此,對配電網線損計算進行研究對于降損節能和電網公司的綜合管理水平及經濟效益的提高具有重要的意義。
配電網線損傳統計算方法主要有均方根電流法、回路電流法和等值電阻法等[4],這些方法雖然具有理論成熟和準確度高等優勢,但其需要眾多的電氣運行信息及參數,且對數據的精確度要求很高[5]。目前我國各地的配電網自動化程度差異很大,傳統線損計算方法的計算實施難于有效開展[6]。近年來,人工智能方法被廣泛應用于配電網線損計算,取得了較好的效果,不僅能保證較高的精度,而且還能極大地簡化線損計算過程[7]。文獻[8]將支持向量機法應用配電網線損計算,但其對特征量的要求較高。文獻[9]采用BP神經網絡法進行線損計算,但其收斂速度較慢,且易陷入局部最優的問題。以上線損計算方法均未進行特征量處理,且存在著線損計算結果精確度不高的問題。
本文提出了一種融合核主成分與隨機森林的配電網線損計算方法,通過線損計算實例的分析,對本文方法的實用性和優越性進行了驗證。
1 核主成分和隨機森林算法基本理論
核主成分分析主要指抽取主成分時使用非線性映射的方法,原始向量由映射函數映射到高維空間,然后再進行線性主成分分析[10]。核主成分分析通過核技巧能夠有效避免傳統主成分分析中非線性變換的未確知性,所提取的主成分貢獻率更加集中,核主成分分析法的優越性已在工程實踐中獲得廣泛的認證[11]。在配電網運行信息不全的條件下,能夠獲取的特征量較少,而通過核主成分分析后,可進一步挖掘特征量之間的相關性,提供更多且更高質量的特征量,從而為特征量與線損非線性映射關系的建立提供更好的基礎。
隨機森林算法是一種集成學習的強分類預測器,其對單棵決策樹的分類能力要求并不高,魯棒性和抗干擾能力很強[12]。隨機森林算法核心原理是bootstrap重抽樣法,生成的決策樹是互不相關的,并獨立地訓練樣本和投票,避免了決策樹算法識別中過擬合問題的影響[13]。隨機森林算法無需獨立的測試樣本便可實現分類誤差的無偏估計,從而有效提高了對待評估樣本的預測正確率,隨機森林算法在數據挖掘和故障診斷方面,其高效性和實用性的優勢獲得了廣泛的認證[14]。
隨機森林算法的各決策樹的獨立性能有效減少特征量與線損之間出現過擬合的問題,隨機森林算法更不易陷入局部最優,能有效提高線損計算的速度[15]。隨機森林算法的高干擾性能有效應對配電網運行信息采集時存在干擾的問題,降低對特征量的要求,且隨機森林算法具有更強的非線性映射能力,能使線損計算取得更高的精度。
隨機森林算法構建如圖1所示。過程如下:①導入所有原始樣本數據,生成訓練集X;②對訓練集采用bootstrap重抽樣法進行抽樣,獲得K個訓練集,并使每個子集合與訓練集X的抽樣數一致;③對K個訓練集做分類回歸樹建模處理,尋找各訓練集袋外數據的最優分類精度,獲得相應數量的決策結果;④對K個決策結果再進行投票表決處理,獲得最終結果。

圖1 隨機森林構建示意Fig.1 Random forest construction schematic diagram
自變量X訓練后獲得的決策樹群為{J1(X),J2(X),…,Jh(X)},則最終輸出結果J(X)為:
(1)
式中,h為訓練輪數;N(·)為示性函數;Y為輸出變量。
當隨機森林算法中的決策樹的數量達到一定程度時,其泛化誤差將趨于一上界值PE*:

(2)

袋外數據為抽取訓練集時未被抽中的原始訓練集樣本,它能夠對隨機森林算法的性能進行評估[16]。決策樹Ji的OOB準確率OOBCorr(i)為
(3)
式中,OOB(i)為決策樹Ji對應的袋外數據樣本;OOBSize(i)為袋外數據樣本的規模;OOBCorrectiNum(i)為診斷后診斷正確的分類結果的數量。
2 融合核主成分與隨機森林的線損計算
配電網線損的傳統計算方法主要有等值電阻法等,該方法雖然準確性高,應用廣泛,但等值電阻法需要眾多的電氣參數,且計算過程復雜[17]。由于配電網線損的特征量較少,尤其在配電網運行信息不全的條件下,配電網線損的特征量會更少,較少的特征量會使得算法訓練后得到的分類器差異不大,造成線損計算結果精度較差。因此,本文引入核主成分分析,將線損特征量從低維的狀態空間映射到高維的核空間,更好地挖掘特征量互相之間存在的聯系。在核空間用隨機森林方法訓練得到差異性符合要求的分類器群,從而提高線損計算的精度,而經核主成分法處理后的特征量相關性更弱,可減少隨機森林算法訓練時的復雜度,從而提高訓練的速度。隨機森林算法在構建分類體系時,每棵決策樹均是隨機生成的,且投票也是獨立的,因此能夠完全避免過擬合的問題,有效避免算法陷入局部最優的問題。隨機森林算法對樣本數據適應力強、抗干擾性能強,在進行全局搜索時準確性更為優異,能以更快的速度獲得全局最優解[18]。
本文以等值電阻法的線損計算結果以及影響配電網線損的電氣特征量作為隨機森林訓練和測試的樣本數據,選取的線損相關特征量有:線路總長度、主干線路長度、分支線路長度、導線單位長度電阻、月有功供電量、月無功供電量、配電變壓器容量、配電網三相不平衡度和配電網負載系數[19]。本文以這9個配電網線損相關電氣特征量來估計配電網的線損,首先采用核主成分進行分析,然后再用隨機森林算法實現特征參量與配電網線損之間的非線性映射。本文配電網線損主要計算流程如圖2所示。
主要過程為:①對配電網的供電信息進行分析,提取需要的相應電氣特征量,并對獲得的特征量樣本進行歸一化處理,然后對歸一后的樣本矩陣Xi進行核主成分,獲得變換矩陣Ti及其變換后的矩陣Yi。②對Yi做重采樣處理,為對隨機森林進行訓練,對特征量進行隨機抽取后得到樣本矩陣Zi,選取核主元后得到測試樣本矩陣Di。③選取合適的隨機森林模型參數,模型的輸出為配電網線損,采用訓練樣本矩陣Zi對隨機森林進行訓練,并對隨機森林的參數做改進處理。④采用測試樣本矩陣Di測試本文的配電網線損計算模型的準確性和穩定性。
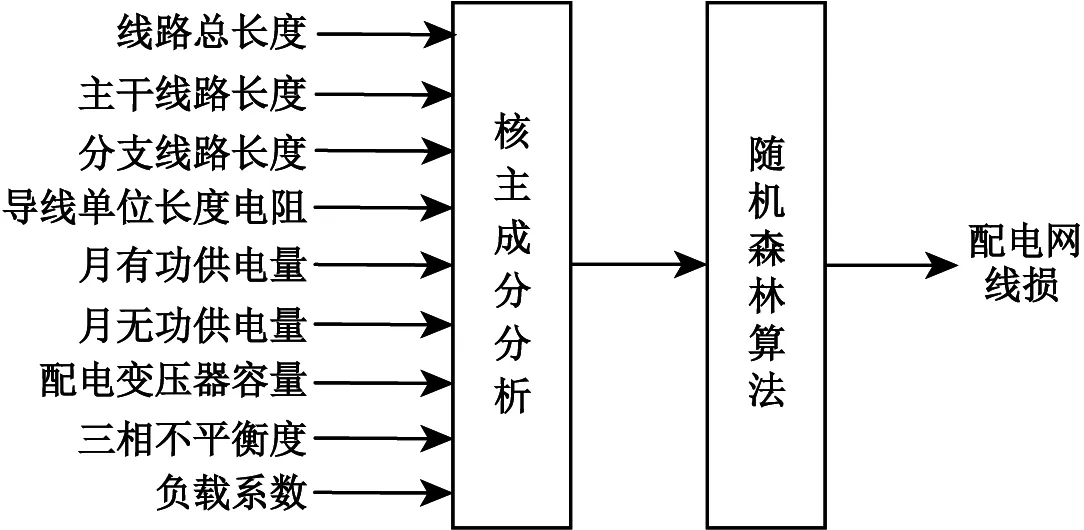
圖2 配電網線損計算模型Fig.2 Distribution network line loss calculation model
3 配電網線損計算實例分析
3.1 線損計算實例
以某城市的10 kV配電網為例進行線損計算分析,挑選具有代表性的20條線路的歷史數據作為建立本文融合核主成分和隨機森林算法的配電網線損計算模型的樣本,其中一條線路的拓撲結構如圖3所示。

圖3 10 kV線路網絡結構Fig.3 10 kV line network structure diagram
本文核主成分的核函數選擇為高斯核函數,隨機森林算法的最佳分裂的變量數mtry和最小節點尺寸取值均為3,OOB誤差估計已被證明可無偏估計隨機森林算法的性能,本文隨機森林OOB錯誤率與隨機森林中樹的數量變化情況如圖4所示。

圖4 隨機森林的OOB錯誤率變化Fig.4 Variation of OOB error rate in random forest
由圖4可知,隨著決策樹數量的增加,隨機森林的OOB錯誤率呈現逐漸下降的趨勢,當決策樹的數量大于33時,OOB錯誤率已穩定為0。為保證算法具有一定的裕度,本文取隨機森林決策樹的數目為40。
3.2 線損計算結果對比分析
為體現本文所提融合核主成分和隨機森林方法的實用性,采用本文方法進行多次線損計算,結果如圖5所示,具體情況見表1。
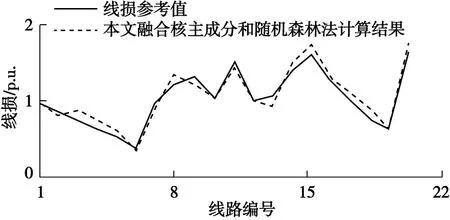
圖5 線損計算結果對比Fig.5 Comparison diagram of line loss calculation results

表1 計算結果誤差情況Tab.1 Error of calculation results
其中等值電阻法的線損計算結果作為參考,計算結果的比較采用均方根誤差(RMSE)和平均絕對誤差百分比(MAPE),RMSE和MAPE值越小[20],表明結果與預參考值越接近,RMSE和MAPE的計算公式為:

(4)

(5)

根據圖5可知,本文融合核主成分與隨機森林的配電網線損計算方法的計算結果與線損參考值非常接近。表1的計算誤差也表明,采用核主成分進行特征量優化處理能提升配電網的線損計算效果,本文線損計算結果的MAPE和RMSE分別為2.53和1.65,線損計算結果誤差很小,本文方法能在配電網線損計算中獲得很好的精度。
4 結論
本文提出了融合核主成分和隨機森林的配電網線損計算方法,利用核主成分對線損特征量處理后再由隨機森林進行線損的非線性映射計算,通過配電網線損計算實例的分析,結果表明隨機森林算法具有更加強大的非線性擬合能力,而本文采用核主成分進行特征量優化處理后能進一步提升配電網的線損計算效果,計算后的誤差MAPE和RMSE非常小,準確度很高。本文融合計算方法能獲得優良的計算效果,可為配電網的線損管理及節能降損提供有效的理論參考和技術指導,從而更好地提高配電網的經濟性和管理水平。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
經濟技術協作信息(2018年32期)2018-11-30 01:43:16
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
電子制作(2016年23期)2016-05-17 03:54:05
電測與儀表(2016年5期)2016-04-22 01:14:14
河南電力(2016年5期)2016-02-06 02:11:24
電測與儀表(2015年13期)2015-04-09 11:57:38
