機器人智能化背后的“靈魂科技”
2022-09-14 06:12:29
電腦報 2022年35期
計算機科學和密碼學的先驅艾倫·麥席森·圖靈在1950年撰寫了《計算機器與智能》一文,提出了一項經典的測試:如果一臺機器與人類展開對話,超過30%的測試人類誤以為在和人類說話而非機器,那么就可以說這臺機器具有智能。這就是人工智能行業知名的“圖靈測試”,圖靈預言在20世紀末一定會有電腦通過這項測試,但事實上直到2014年,人工智能軟件“尤金·古斯特曼”才第一個通過了圖靈測試。這也從側面反映出一個事實:雖然早在70多年前就已經有科學家進行了猜想,但賦予機器人“靈魂”,卻仍然任重道遠。那么問題來了,目前的人工智能處于相對高速的發展階段,我們有哪些能讓機器人與我們交互呢?
第一步:讓機器人“看見”世界
作為地球上最有智慧的生物,人類獲取信息的渠道83%來自視覺、11%來自聽覺、3.5%來自嗅覺,而1.5%來自觸覺、1%來自味覺,而既然要模擬人類的思維方式,其核心就是讓機器通過深度學習,根據所收集的數據信息做出相應的反饋,考慮到我們大部分信息的來源都是視覺,所以,讓機器人“看到”物體和場景,進而對圖像內容給予解釋就成了機器人靈魂的核心。
目前隨著人工智能視覺技術的不斷進化,包括物體識別、目標追蹤、導航、避障已成為各類智能設備的前端通用技術,我們在工業生產自動化、流水線控制、汽車自動駕駛、安防監控、遙感圖像分析、無人機、農業生產以及機器人等各個方面都能找到很多案例。
而對于移動機器人來說,就需要使用多種不同傳感器來實現環境感知,比如大家在飯店餐館可能會看到自動傳菜機器人,抑或是在工廠里很常見的運輸機器人,它們會通過搭載激光雷達、立體視覺攝像頭、紅外以及超寬頻傳感器來“分辨”環境并構建地圖,從而擁有識別、感知、理解、判斷及行動能力。
環境感知能力是機器人最基本的功能,這意味著這類機器人更適用于服務型工作,目前來看這類機器人還可以通過模塊化裝備,完成人員異常行為監測、人員檢測及記錄、異常高溫或火災報警、環境數據異常報警等功能,甚至通過遠程監控模塊,可以代替人員進入危險場所,完成勘察任務。

人形雙臂機器人通過攝像頭識別和算法精準定位匹配,可實現擰瓶蓋等操作
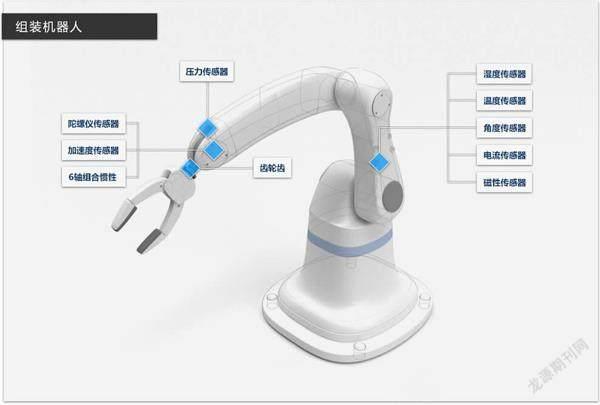
工廠里最常見的機器人也同樣有著豐富的感知傳感器
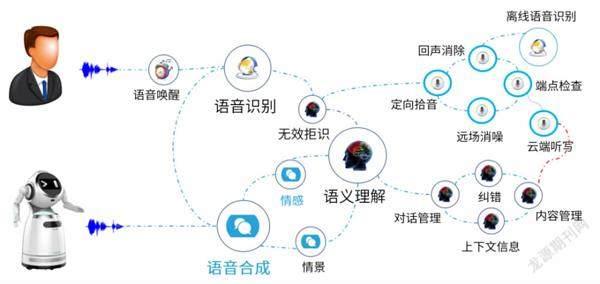
看似簡單的對話,卻蘊含了多個解析步驟
第二步:讓機器人“開口說話”
如果只是通過環境感知來完成工作,這樣的機器人算得上“聰明”么?站在人類的角度來看不過也都是自動化的工具而已,離咱們想象中電影里那樣的智能化機器人有著非常明顯的差距,其實很大程度上產生這種感覺的原因在于,服務型機器人大多都不會與人進行交互,而我們人類交互的核心方式就是說話聊天。70多年前提出的圖靈測試還是通過文字形式來驗證,而現在如果要重新定義的話,語音交互應該是必考項目,比爾·蓋茨就曾說“人類自然形成的與自然界溝通的認知習慣和形式必定是人機交互的發展方向”。
人機交互技術主要包含語音識別、語義理解、人臉識別、圖像識別、體感/手勢交互等技術,其中語音人機交互過程中包含信息輸入和輸出、語音處理、語義分析、智能邏輯處理以及知識和內容的整合。
就目前來看,人工智能語音技術可以分為近場語音和遠場語音兩個分類,近場語音基本上是為了滿足一些輔助使用需求,比如蘋果Siri和微軟小冰就是近場語音產品,而很多智能音箱則可以實現遠場語音,用戶能在5米外的距離語音指示它控制智能家居設備。這些看起來似乎很簡單的工作,事實上對準確性的要求非常高,從處理過程來看先要通過聲學處理我們的聲音和周圍環境,再通過語音識別技術將聽到的聲音翻譯成文字,語義理解技術則會分析這些文字的意義,最后機器去執行用戶的指令或者通過語音合成技術把要表達的內容合成語音。
但在真實環境下,受噪聲等環境因素影響,機器仍然無法完全準確識別自然語言,機器將聽到的語音翻譯成文字時,重音、口音模糊、語法模糊等又很影響成功率,而且人類語言太復雜,受到單詞邊界模糊、多義詞、句法模糊、上下文理解等影響,再加上中文存在大量的方言,語義理解是一個巨大的障礙。
所以,現階段的人工智能語音系統更多用在垂直使用場景,比如汽車的車載智能語音系統、兒童娛樂和教育軟件、人工智能客服等等。尤其是人工智能客服,很多人應該都接到過銀行或金融機構的智能客服電話,大多數情況下它的表現都跟真人沒有太大差別,但嚴重缺乏變通能力,只能在相對狹窄的范圍內進行溝通,準確率也并不高,但它一則可以實現客戶需求的快速響應,二來在一定程度上能夠節約時間和人工成本,所以在未來也一定會隨著滲透率的不斷加深而繼續進化。
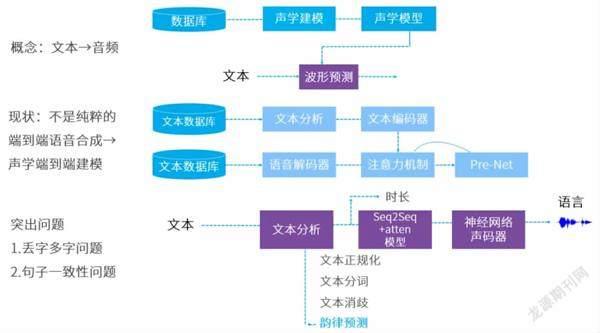
機器人的語義理解能力目前仍處于較低水平

機器人抓取姿態判別深度學習方案

姿態識別也是機器人視覺學習的關鍵點之一
第三步:讓機器人更“聰明”
既然我們說到了機器人的智能進化,可能有讀者朋友會問:那它是怎樣進化的呢?最知名的方法就是深度學習,早在2011年,谷歌一家實驗室的研究人員就從視頻網站中抽取了1000萬張靜態圖片,把它“喂”給谷歌大腦,目標是從中尋找重復出現的圖片,而在足足3天后,谷歌大腦才完成了這一挑戰,而谷歌大腦就是一個由1000臺電腦、16000顆處理器組成的10億神經單元深度學習模型。
深度學習的概念源于人工神經網絡的研究,本質上是構建含有多隱層的機器學習架構模型,通過大規模數據進行訓練,得到大量更具代表性的特征信息,從而對樣本進行分類和預測,提高分類和預測的精度。比如抓取姿態判別,對于人類來說,想要拿起一個東西只需要看幾眼就知道該用怎樣的手勢去拿,而對機器人來說這卻是一個不小的挑戰,涉及到的研究包括智能學習、抓取位姿判別、機器人運動規劃與控制等,而且還需要根據抓取物體的材料性質來隨機應變,調整抓取姿勢和力度。
不過,創造一個強大的神經網絡需要更多處理層,這就需要很強的數據處理能力,所以深度學習的背后往往都有上游硬件大佬的“撐腰”,這些年圖形處理器、超級計算機和云計算的迅猛發展,讓深度學習脫穎而出,NVIDIA、英特爾、AMD等芯片巨頭都站到了人工智能學習的舞臺中央。
深度學習技術建立在大量實例基礎上,給它學習的數據越多,它就越聰明。因為大數據的不可或缺,所以目前深度學習做得最好的基本是擁有大量數據的IT巨頭,如谷歌、微軟、百度等。與此同時,深度學習技術在語音識別、計算機視覺、語言翻譯等領域,均戰勝傳統的機器學習方法,甚至在人臉驗證、圖像分類上還超過人類的識別能力,比如短視頻時代很熱門的人工智能“換臉”,就是將原視頻里的人臉逐幀導出,再通過大量想要替換的人臉照片來進行模型訓練,訓練的過程你會直觀看到替換的人臉從模糊逐漸變得清晰,根據電腦配置的不同,在訓練數小時甚至數十小時后就能得到一個相當不錯的替換結果,這就是深度學習的典型過程。
對于機器人來說,深度學習的應用面除了圖像識別之外還有很多,比如工業或安防機器人需要用到的復雜環境路線規劃和室內導航,教育機器人識別學生坐姿、舉手、摔倒的人體姿態判斷等。在未來,計算方法可能更趨向于與大數據、云計算相結合,使機器人利用云平臺更好地存儲資源和自主學習,同時在大數據環境下,數量龐大的機器人共同分享學習內容,疊加學習模型,更有效地分析和處理海量數據,從而提高學習和工作效率,發展智能機器人的潛力。
當然,這些發展還存在很多隱藏的問題,比如在機器人與云平臺相結合時,因為技術還不夠成熟,在資源分配、系統安全、可靠有效的通信協議,以及如何打通各大上游廠商之間的技術壁壘等都是下一步研究中需要關注的問題。
猜你喜歡
大科技·百科新說(2021年6期)2021-09-12 02:37:27
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
好孩子畫報(2020年5期)2020-06-27 14:08:05
意林·全彩Color(2019年6期)2019-07-24 08:13:50
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
商界(2019年12期)2019-01-03 06:59:05
IT經理世界(2018年20期)2018-10-24 02:38:24
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
小康(2017年16期)2017-06-07 09:00:59
