基于ARM架構國產化私有云的大數據平臺適配性研究
2022-09-15 11:36:18嚴愛民楊乘勝
無線互聯科技 2022年14期
嚴愛民,黨 龍,楊乘勝
(1.華電陜西能源有限公司,陜西 西安 710016;2.南京華盾電力信息安全測評有限公司,江蘇 南京 210000)
0 引言
自2018年“華為、中興”等安全事件發生以來,信創產業進入快速開展階段。經過多年發展,已實現芯片、基礎硬件、操作系統、中間件、數據服務器等國產化替代產品研發,并從實驗階段逐步轉入產業化發展階段[1]。云平臺作為基礎技術底座,具備高可用性、穩定安全、彈性伸縮等優勢,可以靈活應對復雜環境中的業務,有效降低基礎資源的建設和運維成本,使企業提升內部效率,實現信息共享、協同辦公、互聯互通。而ARM架構由于其先天的低功耗優勢,基于ARM架構的服務器已經越來越多地出現在云平臺應用中。與此同時,隨著數據持續以指數級別增長,為保證數據時效性、充分挖掘數據價值,企業紛紛基于云平臺搭建自己的大數據平臺,提升大數據處理能力,滿足各類數據應用需求[2]。
1 企業IT建設特點
(1)國產化程度不足。企業應用的IT底層標準、架構、生態等大多都由國外大型互聯網企業制定,存在諸多安全風險隱患,需在核心芯片、基礎硬件、操作系統、中間件、數據庫等領域實現國產替代。
(2)IT資源異構程度較大。經過多年信息化發展,各企業擁有了大量信息系統,每個信息系統是在不同時期由不同的項目組完成建設,所采購的軟硬件來自不同廠商的不同產品,導致大量異構IT資源并存,資源利用效率不高,系統彈性擴展能力不足。
(3)數據價值有待挖掘。企業經過多年發展,積累了大量歷史數據,并且數據規模持續不斷以指數級增長,亟需構建自主可控、高可靠、高性能、可擴展的大數據處理平臺,加強企業數據分析挖掘能力,充分發揮數據資產價值。
2 國產化云平臺建設
與x86架構相比,ARM使用精簡指令集(RISC),RISC支持的指令比較簡單、功耗較小、價格便宜,擁有高并發處理效率、升級速度快等特點。經過多年發展,各ARM架構版本可以衍生出多種處理器內核,支持針對不同應用場景推出不同產品。同時,通過架構/指令集層級授權、內核層級授權、使用層級授權3種層級授權,實現與全球多個半導體廠商合作。
目前,ARM架構國產化CPU芯片廠商主要有飛騰、鯤鵬等,國產操作系統發展出深度、中標麒麟、銀河麒麟、UOS等優勢產品,形成華為等國產化云平臺解決方案。為了滿足企業快速上云、實現國產化替代應用需求,選擇知名云廠商成熟產品搭建企業私有云平臺,開展大數據平臺適配性研究,滿足大數據應用需求。平臺架構,如圖1所示。

圖1 ARM架構國產化私有云平臺架構
基礎設施層主要提供服務器、存儲、網絡等基礎硬件。平臺層提供計算服務、鏡像服務、存儲服務、災備服務、網絡服務、安全服務、數據庫服務、管理服務等云服務,向上支持搭建大數據平臺,實現對外提供數據分析、實時計算、數據挖掘等數據服務。
3 大數據平臺建設
隨著Hadoop,Spark,Flink,Kafka,Hive,HBase等大數據相關開源技術的發展[3],很多企業都搭建了自己的大數據平臺。本文數據平臺架構主要分為數據采集、數據存儲、數據計算、數據應用4層。平臺架構,如圖2所示。

圖2 大數據平臺架構
3.1 數據采集
數據采集層可以分為日志采集和數據源同步。日志采集主要由日志埋點、爬蟲采集、業務日志等,Flume是Cloudera提供的一個高可用的、高可靠的、分布式的海量日志采集、聚合和傳輸的系統。Flume支持在日志系統中定制各類數據發送方,用于收集數據。同時,Flume提供對數據進行簡單處理,并將處理后的數據發送到各數據接受方的功能。目前,使用Flume+Kafka是最主流的解決方案。
數據庫同步主要是將存儲在業務數據庫(Mysql,Oracle,SQL Server)中的數據同步復制到大數據平臺中存儲。
3.2 數據存儲
數據主要分為結構化數據和非結構化數據兩種。數據存儲層主要可以通過關系型數據庫、非關系型數據庫以及分布式數據庫進行存儲。存儲可以通過Redis集群、Mysql集群、MongoDB集群以及HDFS和HBase。
HDFS是Hadoop項目的核心子項目,是分布式計算中數據存儲管理的基礎,具備高容錯性、高可靠、高吞吐等特點。
HDFS采用Master/Slave架構。一個HDFS集群是由一個NameNode和一定數目的DataNodes組成。NameNode是一個中心服務器,負責管理文件系統的名字空間以及客戶端對文件的訪問。集群中的DataNode一般是一個節點一個,負責管理它所在節點上的存儲。HDFS暴露了文件系統的名字空間,用戶能夠以文件的形式在上面存儲數據。從內部看,一個文件其實被分成一個或多個數據塊,這些塊存儲在一組DataNode上。DataNode負責處理文件系統客戶端的讀寫請求。在NameNode的統一調度下進行數據塊的創建、刪除和復制。
HBase是一個分布式的、面向列的開源數據庫,它不同于一般的關系數據庫,更適合于非結構化數據存儲的數據庫,是一個高可靠性、高性能、面向列、可伸縮的分布式存儲系統。
3.3 數據計算
數據計算是數據處理的關鍵環節,通過計算才能對外輸出相應的結果。目前,常用的計算有批量計算以及流式計算,主要通過開源MapReduce,Hive,Spark,Storm以及Flink實現。
MapReduce是開源分布式計算的第一個流行的計算框架,它將所有計算抽象成Map和Reduce兩個階段。在計算時,MapReduce將大型作業分解為可以跨服務器集群執行的單個任務,并行地對各個子任務進行Map或Reduce操作,并將結果寫到文件中。如此反復得到最終的結果。Hive是基于MapReduce的架構,具有穩定可靠特點,但是計算速度較慢;Spark則是基于內存型的計算,一般認為比MapReduce的速度快很多,但是其對內存性能的要求較高,且存在內存溢出的風險。Storm,Spark Streaming,Flink則是目前常用的流計算框架。
3.4 數據應用
數據應用層基于數據計算結果對外提供數據分析、實時計算、數據挖掘等數據服務,開展人工智能等分析,深入分析行業數據特點,梳理行業數據產品需求,建立適用于不同行業的數據應用產品,實現數據為業務賦能。
3.5 國產化適配
目前,商用計算平臺上部署Hadoop架構已較普及,但在國產化全自主可控的軟硬件環境下平臺的適配工作才剛起步。本文通過與中標麒麟操作系統的調優適配,實現了Hadoop架構大數據平臺的國產化遷移。為確保分布式運算環境效率,選用5臺性能相同的國產化計算機,適配步驟如下:
(1)準備國產化機器安裝國產化操作系統。
(2)準備私有云依賴,國產化環境下編譯安裝。
(3)準備Hadoop相關依賴,國產化環境下編譯安裝。
(4)配置Hadoop。
(5)啟動Hadoop。
國產化分布式集群平臺軟硬件運行環境如表1所示。

表1 軟硬件運行環境
4 性能測試
4.1 軟硬件環境
為了測試適配的基于ARM架構私有云的大數據平臺性能,本研究搭建2個大數據平臺,一個使用國產華為鯤鵬服務器,一個使用Intel x86架構服務器。
使用TPC-DS測試工具分別對Hive在信創環境和x86環境進行了查詢性能的測試,服務器配置,如表2所示。
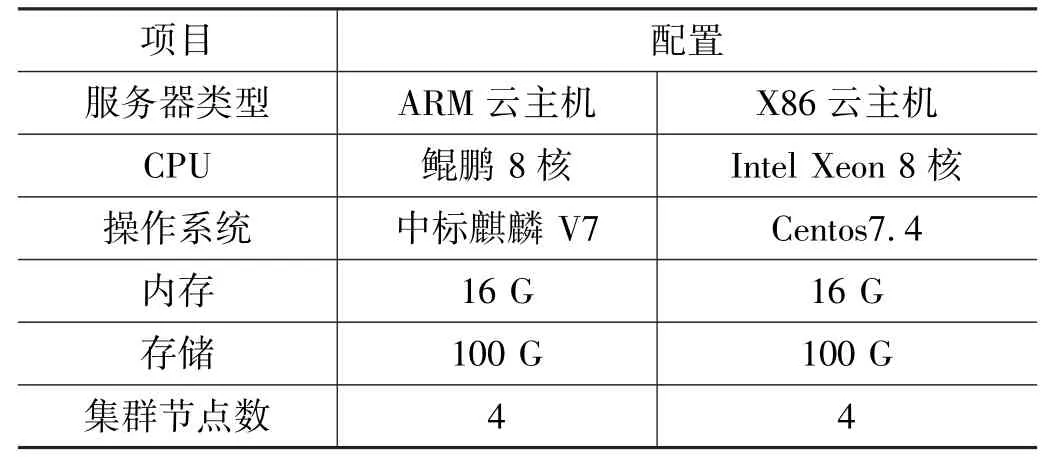
表2 大數據平臺軟硬件配置
4.2 測試結果
通過TPC-DS工具分別向信創和X86環境下的HDFS生成10 G測試數據,然后將10 G數據傳輸到Hive中存儲。查詢時間的結果,如表3所示。

表3 Hive執行sql時間 (單位:s)
測試結果顯示,在10 G量級的數據下,基于ARM架構國產化私有云的大數據平臺的查詢性能和穩定性,性能已經接近同等配置的x86服務器,能夠滿足實際應用中對海量數據的存取要求。
5 結語
本文提出了ARM架構國產化私有云及其上大數據平臺解決方案,并適配性研究。實驗驗證了大數據平臺國產化遷移的可行性,基于ARM架構國產化私有云的大數據平臺性能與同等配置下x86服務器性能相似,能夠滿足實際應用中對海量數據的處理需求。
猜你喜歡
中老年保健(2021年12期)2021-08-24 03:30:40
中國傳媒大學學報(自然科學版)(2021年1期)2021-06-09 08:43:00
中國生殖健康(2020年6期)2020-02-01 06:28:50
新世紀智能(英語備考)(2019年12期)2020-01-13 06:07:18
中國生殖健康(2019年11期)2019-01-07 01:28:02
中國生殖健康(2018年6期)2018-11-06 07:09:28
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
