基于EMD-LSTM的冷軋煤氣消耗量預測模型仿真
2022-09-16 07:26:12翟慧熊偉李福進楊杰
機床與液壓 2022年14期
翟慧,熊偉,李福進,楊杰
(1.華北理工大學電氣工程學院,河北唐山 063210;2.唐山鋼鐵集團高強汽車板有限公司,河北唐山 063026)
0 前言
在我國,鋼鐵行業作為一個重要且依賴能源的行業,如何合理利用和配置資源一直是制約它發展的重要因素。煤氣是一種重要的二次能源,其回收率影響企業生產成本和環境,對企業具有重要的經濟和環境意義。其中,冷軋生產過程消耗大量煤氣,并且生產過程中發生大量的化學反應。煤氣消耗的影響因素復雜,夾雜著周期性波動、隨機擾動,這對煤氣消耗量的預測帶來了一定難度。在實際生產過程中,煤氣的分配僅憑人工經驗操作,導致煤氣不能充分利用;而且煤氣的突然過剩,容易導致設備熄火,并將多余煤氣釋放到大氣中污染環境;而煤氣的短缺則會導致用戶停產。因此,有必要為冷軋過程設計一個有效的煤氣消耗量預測模型。
隨人工智能、人工神經網絡的迅速崛起,支持向量機、神經網絡等方法被大量用于預測。LYU等提出了一種基于灰色徑向基函數(RBF)神經網絡的高爐煤氣量預測模型。利用灰色理論對歷史數據進行預處理,獲取豐富的信息,結合 RBF 神經網絡,實現了30 min內有效的趨勢預測。李志剛等以高爐煤氣為主要研究對象,提出了一種基于LSTM與自回歸差分滑動平均(ARIMA)組合的預測模型,提高了煤氣預測精度。隨后,又通過調試和改進建立了PSO-BP 神經網絡高爐煤氣受入量預測模型,實現了對煤氣的合理調度和平衡調整。SUN等提出了一種基于事件驅動、機制驅動和數據驅動的混合預測方法,在預測高爐煤氣量的同時考慮了高爐操作事件,使預測更加準確。徐化巖和馬家琳針對鋼鐵企業高爐煤氣系統設備工況復雜、煤氣量波動頻繁、難以準確預測的問題,依據小波分析方法、BP 神經網絡、最小二乘支持向量機的性質建立了基于數據驅動的高爐煤氣的復合預測模型。以上智能算法在一定程度上實現了預測,但在準確性和穩定性方面仍存在一些問題,并且在基于數據預測的過程中忽略了數據本身特性對預測精度的影響。
隨著深度學習的快速發展,基于深度神經網絡的新一代人工智能已廣泛應用于各種領域。其中,LSTM是一種特殊的時間遞歸神經網絡(RNN),能有效地保存長期記憶信息,具有良好的預測能力。NEERAJ等利用LSTM建立了電力負荷預測模型,具有較高的預測精度。ZHOU、王強等人使用LSTM預測了刀具在可變條件下的剩余使用壽命。
經驗模態分解(Empirical Mode Decomposition,EMD)是一種分析非線性數據的方法,可以提取數據本質特征。HUANG等將經驗模態分解用于電流信號分析。GRASSO等使用EMD技術分離了不同的頻率波形。SHRIVASTAVA 和SINGH使用經驗模態分解對刀具顫振信號進行了預處理。LI等將經驗模態分解應用于齒輪箱局部故障診斷中的振動信號分析,發現利用經驗模態分解能夠更有效地檢測振動信號。EMD方法解決了使用傳統方法會導致有價值的信息被拋棄、復雜現象無法準確呈現的問題。
煤氣消耗數據的非線性、非平穩,導致煤氣消耗量難以準確預測。并且預測時需要大量的先驗信息,非常耗時,時間跨度大。因此,可以利用EMD對煤氣消耗數據進行預處理,提取復雜序列中的本質特征,為后續預測提供參考。憑借其獨特的記憶優勢和解決長時間序列相關問題的優勢,LSTM可以很好地預測冷軋過程中的煤氣消耗量。因此,為滿足調度員的需求,本文作者建立一種基于EMD-LSTM的煤氣消耗量預測模型。
1 方法及原理
1.1 EMD基本原理
經驗模態分解可基于數據本身,將復雜信號分解為一系列IMF和一個(),分解信號時,不需要預先設置任何基函數。因為這一特點,理論上EMD方法可預處理任何一種信號的數據,因此被廣泛應用。
()=∑IMF,+()
(1)
每個IMF分量都應滿足以下2個特點:
(1)在整個時間范圍內,局部極值點和過零點的數量必須相等或最多相差一個;
(2)在任何時間點,局部最大包絡和局部最小包絡的平均值必須為0。
IMF代表數據的固有振動模式。根據IMF的定義,IMF每個振動周期只有一個振動模式,不存在其他復雜波。作為混合序列的煤氣消耗數據也可以分解為如式(1)所示的形式。分解后的IMF分量包含不同的局部特征信號。因此,利用EMD分解煤氣消耗數據是可行的。
1.2 長短時記憶神經網絡
LSTM在解決長時間序列相關性問題上具有獨特優勢,是深度學習中比較流行的方法。LSTM的內部結構由遺忘門、輸入門、輸出門和存儲單元組成。由于其獨特的“記憶”優勢,LSTM網絡得到了越來越廣泛的應用。圖1所示為LSTM的網絡結構。

圖1 LSTM結構
遺忘門決定了前一時刻的單元狀態需要保留到當前時刻的程度。
()=[(-1)+()+]
(2)
輸入門分為兩部分:Sigmoid層決定哪些信息需要更新,并輸出為();Tanh層創建候選向量′()。最后,組合這2個向量來創建更新值。數學表達式為
()=[(-1)+()+]
(3)
′()=tanh[(-1)+()+]
(4)
單元狀態()是遺忘門()與上一時刻單元狀態(-1)乘積和()與()乘積的和。
=(-1)?()+()?()
(5)
輸出門是輸出到LSTM控制單元狀態的當前輸出值,由Sigmoid層和Tanh層兩部分組成。
()=[(-1)+()+]
(6)
()=()?tanh[()]
(7)
其中:為激活函數;、、、、、、、為權重;(-1)為前一個神經元的輸出結果;、、、為偏置;?為元素乘法符號。
由于Tanh的導數大于Sigmoid函數的導數,Tanh激活函數通常用于解決RNN梯度消失問題。Sigmoid函數估計輸入數據與先前隱藏狀態的權重和激活,值在0~1之間,指示允許流入多少相關信息。各個門之間以特定的關系相互作用、過濾和保存信息。這種結構可以有效解決梯度消失問題。
2 基于EMD-LSTM的煤氣消耗預測模型
EMD-LSTM適用于同類型的時間序列預測。首先,通過EMD從煤氣消耗序列中提取煤氣消耗特征,捕捉可變操作條件下的復雜時間序列關系;然后,使用LSTM研究鋼板規格、軋制條件和煤氣消耗的關系。如圖2所示,EMD-LSTM煤氣消耗預測模型主要由兩部分組成。

圖2 基于EMD-LSTM的煤氣預測流程
2.1 基于EMD的信號預處理
使用EMD對煤氣消耗數據進行預處理。具體步驟如下所示:
(1)識別煤氣消耗序列()的所有極值點,用三次樣條插值函數繪制()的上下包絡線;
(2)求上下包絡線的均值,畫出平均包絡();
(3)從原始信號()中減去平均包絡(),得到第1個分量();
(4)確定()是否滿足IMF的2個條件,如果滿足,則信號為IMF分量;如果不滿足,以信號為基礎,重復步驟(1)—(4),IMF分量通常通過幾次迭代獲得;
(5)獲得第1個IMF分量后,從原始信號中減去IMF1,作為新的原始信號,然后重復步驟(1)—(4),以獲得IMF2分量,以此類推,直到最終殘差變為單調函數,EMD分解完成。
2.2 LSTM煤氣消耗量預測
文中選取某鋼廠一個月的煤氣消耗量,前90%的數據樣本用于模型訓練,后10%數據用于監測預測模型的準確性。煤氣消耗的影響因素非常復雜,因此應選擇主要影響因素來確定合適的輸入參數。選擇合適的輸入可以提高煤氣預測模型的有效性。
確定輸入參數后,應確定LSTM的結構。考慮到模型的計算速度和預測的準確性等相關因素,進行大量測試以確定隱含層數、批次、迭代次數等參數。
在LSTM模型的構造中,使用自適應矩估計算法優化預測模型的參數。它可以更新網絡的權重,動態調整各個參數的學習速率,使各個參數的更新更加獨立。
各個分量預測完成后,累加每個模型的預測值,作為冷軋煤氣消耗量的最終預測結果。
3 實驗分析
3.1 工作條件
冷軋工藝一般包括原材料、酸洗、軋制、退火、精整等,以熱軋產品作為冷軋帶鋼的原材料。原料冷軋前先進行酸洗,去除熱軋帶鋼表面的氧化皮,確保產品表面清潔。冷軋是材料變形的主要過程。經過多道次軋制后可以獲得所需尺寸、形狀的帶材。退火的目的是消除再結晶之后的硬化。精加工包括檢驗、剪切、矯治、分揀和包裝,以獲得最終產品。圖3所示為冷軋工藝的整體布局。

圖3 冷軋工藝布局
以唐山某鋼鐵企業四鍍鋅冷軋生產線為研究對象,采集了2020年10月的實際生產數據,數據樣本4 544個。采用EMD-LSTM模型預測冷軋煤氣消耗量。樣本數據分為兩個子集:訓練集和測試集。前4 090個數據點作為歷史數據訓練模型,剩余的454個數據點用于評估預測性能。
3.2 煤氣消耗數據特征提取
圖4所示為實際生產過程中煤氣的消耗情況。EMD分解可以降低變量的非線性和不穩定的影響,提取數據中包含的主要信息。信號分解EMD結果如圖5所示。

圖4 煤氣消耗實際值

圖5 基于EMD分解的煤氣消耗序列
3.3 LSTM模型與訓練
經分析,煤氣消耗量的主要影響因素有:鋼板寬度、鋼板厚度、碳含量、硅含量、硫含量、磷含量、加熱爐酸洗速度、加熱爐酸洗溫度、退火爐速度、退火爐加熱段1溫度、退火爐加熱段2溫度、退火爐均熱溫度。建立LSTM網絡,使用12個變量作為預測模型的輸入,預測各個煤氣消耗量分量,模型參數采用自適應矩估計算法調整。每個分量迭代次數設置為5,批次設置為15,隱含層設置為32。
3.4 結果和討論
為驗證EMD-LSTM模型的預測能力,與BP、EMD-BP、LSTM和EMD-LSTM的煤氣預測結果進行比較。
如圖6和圖7所示:BP模型的預測值與煤氣消耗實際值差距較為明顯,它只能預測煤氣消耗的大體趨勢;經過EMD分解提取本質特征后,煤氣消耗量的預測精度大大提高,但在極值點處仍存在較為明顯的誤差,需要進一步改進。兩種模型預測結果表明,對數據進行預處理可以在一定程度上提高模型的預測能力。

圖6 BP模型煤氣預測值
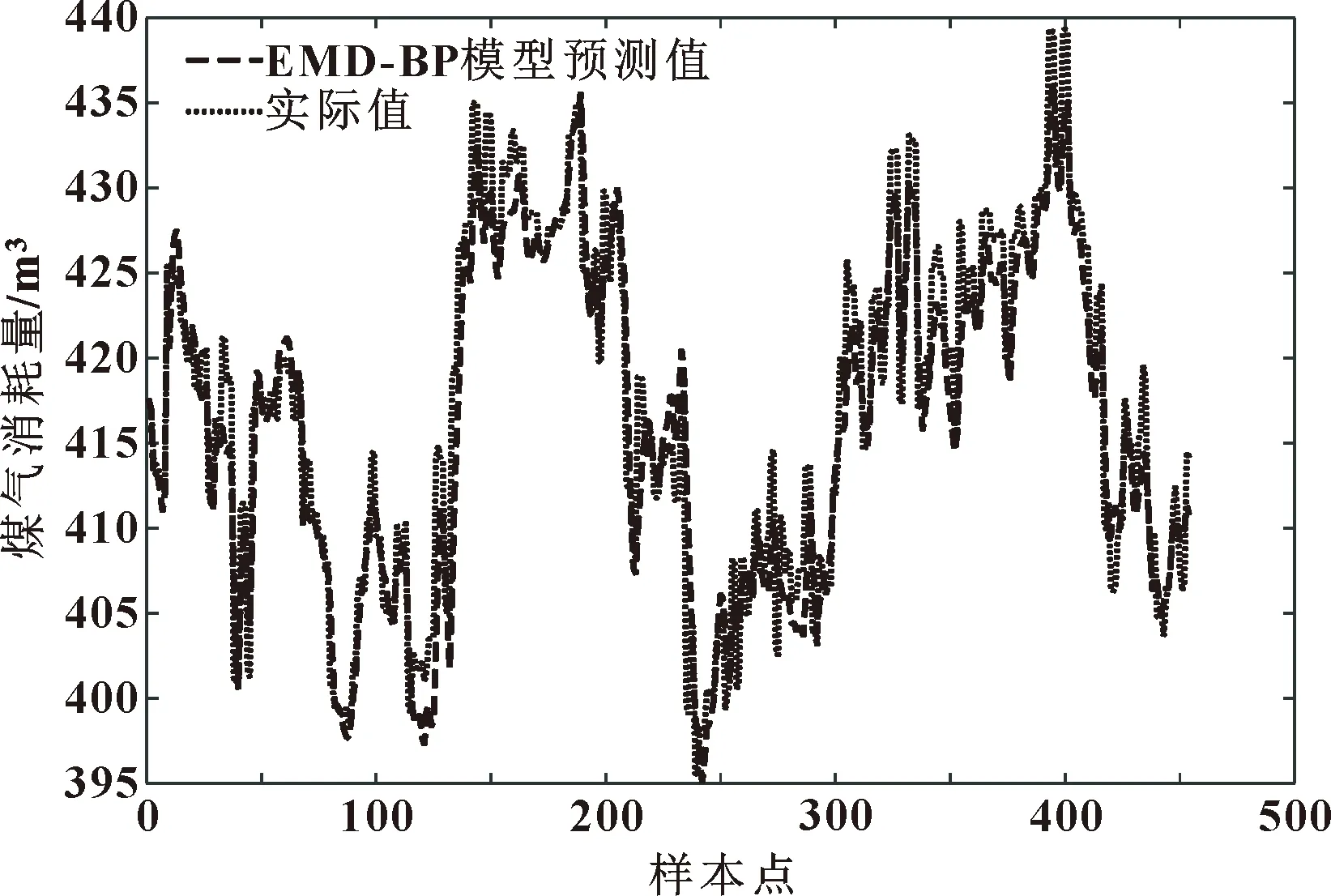
圖7 EMD-BP模型預測值
在閱讀了大量文獻后,本文作者發現理論上LSTM對時間序列有更強的預測能力,可以充分利用數據中的有效信息。因此,驗證LSTM的預測能力。
由圖8可以看出:LSTM預測曲線與實際煤氣消耗曲線趨于一致,預測精度明顯高于BP模型;然而,在部分極值點處,預測值略低于實際值。
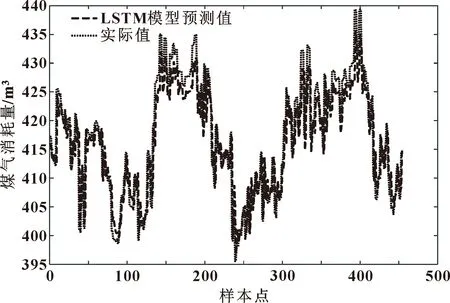
圖8 LSTM模型煤氣預測值
通過以上分析,將EMD分解與LSTM相結合,利用EMD提取煤氣消耗數據的本質特征,對副產品煤氣消耗量進行LSTM預測。
如圖9所示:與BP、EMD-BP和LSTM相比,EMD-LSTM的預測結果與實際值基本相近,表明它完美結合了兩個算法的優勢,可用于預測冷軋過程中的煤氣消耗量。

圖9 EMD-LSTM模型煤氣預測值
對于煤氣消耗預測,使用平均絕對誤差(MAE)、均方根誤差(RMSE)、平均絕對百分比誤差(MAPE)和均方根誤差()來評估預測模型的性能。
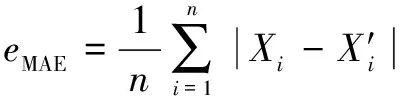
(8)

(9)

(10)
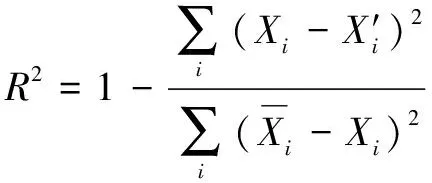
(11)
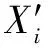
表1所示為4種模型預測性能的比較結果。可知:EMD-LSTM相較于其他算法具有較低的MAE(1.634)、RMSE(2.121)、MAPE(0.39%)和較高的(0.957),這表明預測值與實際值的擬合程度較高,預測能力良好。從上述4種模型的預測結果看,EMD-LSTM模型充分利用了EMD分解在非線性數據特征提取和時間序列長期記憶中的LSTM效應,克服了單一模型的缺點,提高了煤氣消耗量的預測效果。

表1 不同方法的預測性能比較
4 結論
針對工業過程中數據存在非線性、非平穩的現象,提出了一種EMD-LSTM方法,并用某鋼鐵企業實際冷軋生產數據進行了驗證。首先,利用EMD將煤氣消耗量序列分解成若干頻率分量,從中提取煤氣消耗量本質特征。然后,建立了一個煤氣消耗量預測模型,對各分量進行預測。最后,將各個預測值相加,得到最終的預測結果。從仿真結果可以得出以下結論:
(1)EMD-BP方法與BP 方法進行對比,得到采用 EMD對數據進行預處理可以有效提高模型的預測能力;
(2)LSTM方法與BP方法相比,得到LSTM方法能夠利用大量先驗信息,有效解決長期依賴的問題,具有更高預測精度;
(3)預測結果表明:EMD-LSTM方法結合了兩個方法的優勢,大大提升了煤氣預測精度,MAPE低至0.39%,達到0.957。該方法可以用于冷軋煤氣消耗量的預測,為鋼鐵企業節約生產成本、降低環境污染及煤氣調度提供參考。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
鴨綠江(2021年35期)2021-04-19 12:24:18
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
數學物理學報(2020年2期)2020-06-02 11:29:24
中國生殖健康(2019年3期)2019-02-01 06:12:26
光學精密工程(2016年6期)2016-11-07 09:07:19
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
海軍航空大學學報(2015年3期)2015-11-11 17:20:00
核科學與工程(2015年4期)2015-09-26 11:59:03
