基于注意力機制的短道速滑運動軌跡預測模型
2022-09-20 02:54:32張子涵周斌李文豪
現代計算機 2022年14期
張子涵,周斌,李文豪
(中南民族大學計算機科學學院,武漢 430074)
0 引言
近年來,隨著計算機視覺和人工智能的進步,軌跡處理技術廣泛應用于機器人導航、自動駕駛、視頻的智能監控等領域。人類軌跡的預測最近已經成為計算機視覺界一個充滿活力的研究課題。軌跡預測是根據過去的運動軌跡進行建模,從而預測未來一段時間的軌跡,其中行人的軌跡預測是軌跡預測領域研究的基礎與重點。現有的行人軌跡預測研究工作可以分為基于傳統模型和基于深度學習的方法。
Kalman提出卡爾曼濾波,將統計學應用于軌跡預測,利用前一時刻的狀態(和可能的測量值)來得到當前時刻下狀態的最優估計。Chen等提出了光流卡爾曼濾波,此模型較傳統的卡爾曼濾波更精準,但只能局限于速度不變,運動較慢的行人。Williams提出用高斯過程分布來對行人的速度和方向等運動參數進行建模。Helbing和Molnar的Social Forces模型是經典論文之一,他們提出了兩種力,第一種力是引導人們相互走近的吸引力,第二種力是使行人避免碰撞的排斥力。Trautman和Krause提出進一步的改進,在Social Forces模型基礎上利用高斯IGP得出行人軌跡的概率性預測。這些傳統模型局限于手動設置的行人屬性和函數,僅適用于行人基本沒有互動的情況,逐漸被數據所驅動的深度學習模型所超越。
行人的軌跡可以看做一個典型的序列到序列(sequence-to-sequence,seq2seq)問題,因此善于處理時間序列的循環神經網絡(recurrent neural network,RNN)逐漸走進研究者們的視野。然而,由于梯度消失或梯度爆炸的問題,簡單的RNN很難記住長期的輸入信息,所以研究者設計出擅長處理長期依賴關系數據的長短期記憶網絡(LSTM),尤其是LSTM在時間序列數據處理的成功應用如語音識別、語言翻譯、圖像字幕等,為行人的軌跡預測提供了嶄新的思路。最經典的是Alahi等提出的Social-LSTM模型,此模型中提出了一個新的概念“Social Pooling”,即根據行人的空間距離判斷處于鄰域內行人的隱藏狀態進行共享,得到行人周圍的信息,以代表其他行人對目標行人軌跡的影響。其結果表明,Social-LSTM模型平均比Social Forces模型和其他基線方法更接近真實結果。然而,Social-LSTM模型對于重要場景的上下文信息具有一定的局限性。Lee等提出了深度隨機逆最優控制RNN編碼器-解碼器(desire)框架,將場景上下文進行排序和細化而不是直接對場景信 息 納 入 軌 跡 預 測。Bartoli等用contentpooling層進一步拓展了Social-LSTM模型,這也使神經網絡能夠研究障礙如何影響行人運動。Xue等創新性地提出了三種分工不同的LSTM來分別捕獲行人過去的信息、行人彼此的互動信息和場景布局的信息,并用圓形鄰域代替矩形鄰域,使得預測精準度進一步提高。
如今,各種軌跡預測模型算法也被應用于運動員的軌跡預測。預測運動員的運動軌跡相比于預測行人軌跡更加困難,因為每一個運動員對于下一時刻運動行為的選擇,不僅取決于自身的意圖,還取決于其他運動員的位置、運動方向以及運動速度。這些因素并不能直接觀察得到,只能從過去的信息推測出來。特別是在足球、籃球或者短道速滑等具有激烈對抗性的運動比賽中,預測運動軌跡具有極其關鍵的地位,能否提高預測精度,對于充分了解己方和對方運動員的位置信息與運動方式對在比賽中獲得戰術優勢,或者賽后的比賽數據精準分析來說都至關重要。Cohan使用LSTM來預測籃球運動員最佳的運動位置。Zheng等也研究了NBA球員的軌跡預測,提出了一個基于VAE和LSTM的深度生成模型,并經過弱監督訓練的深度生成模型來預測整個球隊的軌跡。
在本文工作中,將軌跡預測應用于短道速滑中,旨在預測分析運動員的運動軌跡。短道速滑的軌跡分析屬于運動員軌跡預測領域,可以借鑒現代的行人軌跡預測理論方法進行研究。短道速滑運動員運動特點與行人的特點相比主要有以下不同:
(1)短道速滑運動員的運動方向都是同向的,而行人的運動方向并不固定,受到場景和其他行人的影響。
(2)短道速滑運動員的運動速度與行人行走速度相比更快且變化更頻繁。因此,本文將運動員的速度信息作為重要條件。
(3)短道速滑運動員的運動軌跡相比行人而言,更具有規律性。
雖然,短道速滑運動軌跡具有規律性,大致分為直道軌跡和彎道軌跡。但是,在短道速滑訓練或者比賽中,運動員之間出現頻繁的遮擋及位置交錯的情況下難以避免地會出現運動員的軌跡紊亂現象,是否能準確地預測短道速滑運動員軌跡成為了一種挑戰。
綜上所述,本文提出了一個基于LSTM編碼器-解碼器(encoder-decoder)框架的位置速度信息LSTM(position-velocity-LSTM,PV-LSTM)的軌跡預測模型,將軌跡預測應用于短道速滑中,專注于運動員在真實訓練或者比賽中的運動軌跡,從而準確預測運動員未來的軌跡。
1 PV-LSTM模型
PV-LSTM在Encoder模塊采用速度和位置LSTM分別處理位置和速度信息,并在Encoder和Decoder中間引入注意力機制,添加速度注意力機制模塊,計算速度權重對軌跡影響較大的運動員軌跡信息,旨在提升軌跡預測的精度,最后在Decoder模塊對軌跡進行預測。
1.1 問題定義
在運動比賽或訓練中,假設場上的運動員數量為,所以在時刻,場景中的每個運動員都由2D坐標(x,y)表示。我們從=1到=T觀察每個運動員的位置,目的是預測運動員從=T到=T的位置,其中T與T分別表示結束觀察的時刻和結束預測的時刻。給定觀察軌跡P=[(,),…,(x,y)],其中和分別代表橫向位置和縱向位置。對于速度信息來說,短道速滑運動員在做行為決策的時候,相對速度比絕對速度更為重要,因此對于周圍的速滑運動員,本文選擇與目標運動員的相對速度作為輸入U=[(,),…,(u,v)],其中和分別代表橫向速度和縱向速度。輸入到編碼器中的歷史位置和速度信息是:

其中,表示運動員中的一員,在時刻的歷史位置信息和速度信息。
1.2 PV-LSTM模型結構
整個網絡結構如圖1所示,模型框架包括如下幾個模塊:LSTM編碼器模塊、注意力模塊和LSTM解碼器模塊。LSTM編碼器模塊首先將觀察到的位置信息和速度信息分別輸入到位置LSTM模塊和速度LSTM模塊,以獲得相應模塊的隱藏狀態。接著將速度隱藏狀態輸入到對應的注意力模塊中進行加權求和,再與位置隱藏狀態連接形成最終上下文向量,最后LSTM解碼器模塊生成預測的軌跡。
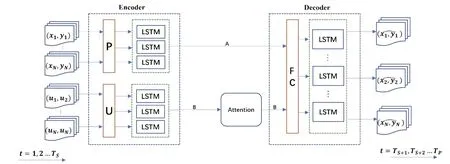
圖1 網絡結構圖
1.3 LSTM編碼器模塊
編碼器模塊是由多層感知機(multi-layer perception,MLP)、位 置LSTM和 速 度LSTM組成。對于輸入進編碼器的每個運動員的位置和速度信息,本模型通過MLP把信息分別嵌入到向量中,即:
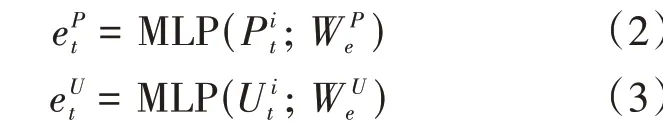



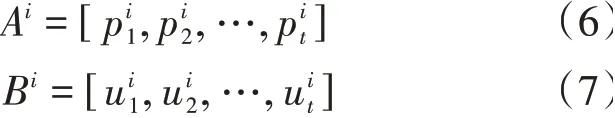
其中,A和B是運動員在各個時刻的位置和速度隱藏狀態總和。
1.4 注意力模塊
傳統編碼器輸出的B不能完全代表T之內所有的速度狀態信息,因為編碼器-解碼器模型具有一定的局限性,第一個輸入序列信息會被隨后輸入序列數據稀釋或覆蓋,而且隨著輸入序列長度的增加,這種現象會更加嚴重。
為了解決這一問題,本模型采用注意力機制,其核心思想是在解碼過程的每一個時刻,都會選擇更合適的上下文向量。在本實驗中,不同時間的速度信息對未來軌跡有不同的影響,注意力機制可以使影響預測結果的信息分配更大的權重,聚焦有用的信息,使預測更加精準。上下文向量本質上就是將所有隱藏狀態進行加權求和得到的,B可以改寫為:

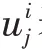
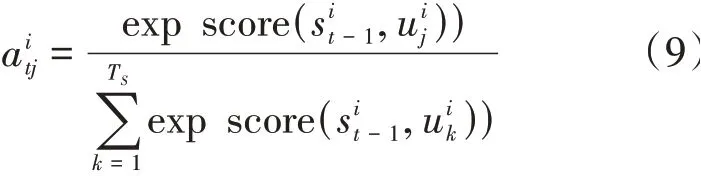
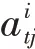
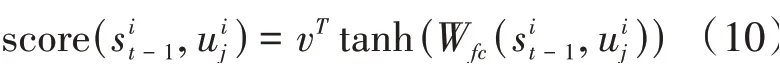

最終,得到速度的上下文向量并與所有位置信息的隱藏狀態進行連接,即:

其中是具非線性的全連接層,使得輸出的是最終的上下文向量,并輸入到LSTM解碼模塊。
1.5 LSTM解碼器模塊
通過注意力模塊輸入到本模塊的是最終上下文向量C,本模塊的結構是標準的LSTM模型,輸出的預測軌跡計算公式如下:
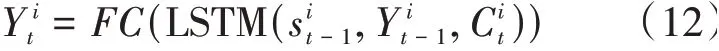
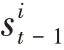
上一個時間步LSTM解碼器的輸出作為輸入傳遞給下一個時間步LSTM解碼器,也就是說解碼器在時間步時攜帶著時間步-1的位置與信息,在輸入到下一個時間步之前對位置與速度信息進行加權并更新。
2 實驗
2.1 實驗方案
本文將嵌入層的維度設置為16,每個LSTM層的維度設置為32。該模型使用Adam優化器進行訓練,初始學習率為0.001。在訓練過程中,本預測模型將Droput率設置為0.2,以避免過度擬合。本文使用的數據集有速滑運動員日常訓練的數據集(DET),由多名速滑運動員日常訓練數據組成,ETH由750名行人數據組成,UCY由786名行人數據組成。ETH包含ETH和Hotel場景,UCY包含UNIV,ZARA1和ZARA2場景,數據集包含了豐富的現實世界場景。本文使用平均位移誤差(ADE)和最終位移誤差(FDE)兩個指標,其值越小表示誤差越小,精確度越高。
(1)ADE是預測軌跡與地面真值軌跡中所有點之間的平均歐氏距離。
(2)FDE定義為預測軌跡的最終點(目標點)與地面真值目標點之間的歐氏距離。
為了檢測PV-LSTM模型相較于其他模型的精度提升,將所有模型進行實驗并與基準模型進行對比:
(1)Vanilla-LSTM:僅將位置信息作為輸入,并且沒有任何交互模塊的LSTM,本文將此設為基準模型,作為參考標準。
(2)Social-LSTM:采用一個社會池化層對人與人之間的相互作用進行建模的LSTM。
(3)PV-LSTM-NA(沒有注意力模塊):取消注意力模塊之后的PV-LSTM。
實驗運行在Ubuntu20.04 LTS的操作系統上,GPU為NVIDIA GTX 2060,采用的是Pytorch 1.7.1的深度學習框架,CUDA 11.0的運行環境。
2.2 實驗結果與分析
第一組實驗是各個實驗模型在短道速滑運動員日常訓練的數據集(DET)上訓練并測試,旨在判斷本文模型對速滑運動員軌跡的有效提升性。具體的實驗結果如表1所示。
綜合表1可以得出,各種網絡模型在DET數據集下實驗結果均較為理想,但是,PVLSTM在兩個指標下的性能結果均優于Vanilla-LSTM、Social-LSTM和PV-LSTM-NA。結合具體場景情況而言,短道速滑運動的場地分為兩段直道和兩段彎道。對于直道,軌跡多成線性狀態,各個網絡模型均能預測較為精準,差距并不大。因此,圖2分別表示的是各個網絡模型下場地左側和場地右側對于同一名運動員運動預測軌跡對比可視化。可以清晰地看出本文模型在彎道比Vanilla-LSTM和Social-LSTM的精準性更高,對于短道速滑軌跡分析具有關鍵性的作用。綜上表明,PV-LSTM相對于基準模型,其ADE和FDE精度分別提升22.86%和21.95%,均優于其他模型,在短道速滑軌跡預測,尤其是彎道的軌跡預測更精準,更具有實際的應用價值。

圖2 賽道左右兩側彎道預測軌跡可視化

表1 各種模型在DET數據集下ADE和FDE結果對比
第二組實驗是各個實驗模型在ETH和UCY上訓練,即分別在4個場景上訓練,在剩下的一個場景上測試,依次循環5次,旨在判斷本文模型對軌跡預測的不同場景的泛化性。具體實驗結果如表2所示。
綜合表2可以看出,Vanilla-LSTM、Social-LSTM和PV-LSTM-NA在ETH和UCY的各 個數據集的表現各有千秋。本文提出的PV-LSTM在各個數據集上雖具有良好的效果,但是性能結果 相 比Vanilla-LSTM、Social-LSTM和PVLSTM-NA并不具備明顯的優勢,這是因為行人的速度比運動員的速度慢太多,速度變化也不是很明顯。結合實際場景分析,ETH場景下的行人進出建筑物的運動軌跡大多都是非線性的,因此各個模型的預測效果均不理想。在HOTEL,ZARA1和ZARA2場景中的行人密度穩定,行人軌跡大多呈直線性狀態,各模型的預測結果較為理想。本文提出的PV-LSTM在各個數據集訓練和測試的結果與基準模型相比,ADE和FDE平均精度分別提升了6.67%和6.52%,均優于其他模型。進一步表明PV-LSTM精度更高的同時具有一定的泛化性。

表2 各種模型在各數據集下的ADE和FDE結果對比
3 結語
針對短道速滑運動員在場地上運動時,因速度快、較擁擠等情況容易導致軌跡紊亂的痛點,本文設計了一種基于注意力機制的編碼器-解碼器軌跡預測模型,構造一個包含LSTM編碼器模塊,一個注意力模塊,一個LSTM解碼器模塊的網絡模型。實驗結果表明,在與文獻中現有的模型相比,在真實的運動員訓練數據集上,尤其是在關鍵的彎道軌跡預測中具有更高的精準性,PV-LSTM模型在ETH/UCY上具有一定的泛化性,證明了本文PV-LSTM模型的可行性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
中外會展(2014年4期)2014-11-27 07:46:46
中學數學雜志(初中版)(2006年1期)2006-12-29 00:00:00
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
