基于鏈接器的RISC-V字加載指令優(yōu)化①
2022-09-20 04:10:32烏鑫龍廖春玉
計(jì)算機(jī)系統(tǒng)應(yīng)用 2022年9期
烏鑫龍, 廖春玉
1(中國(guó)科學(xué)院 軟件研究所, 北京 100190)
2(北京師范大學(xué)珠海分校 計(jì)算機(jī)學(xué)院, 珠海 519087)
1 引言
由于RISC-V指令集架構(gòu)具有開源、芯片設(shè)計(jì)友好、開發(fā)成本低等特點(diǎn)[1,2], 近年來被越來越多地運(yùn)用于嵌入式設(shè)備中. 同時(shí)RISC-V指令集作為RISC的一員, 也會(huì)不可避免的存在一些精簡(jiǎn)指令集的弊端,RISC二進(jìn)制程序體積偏大的問題就是其中之一. 因?yàn)镽ISC指令集只要求實(shí)現(xiàn)計(jì)算機(jī)硬件中最常用且數(shù)量有限的基礎(chǔ)指令, 所以其中較復(fù)雜的操作只能通過基礎(chǔ)指令的組合來實(shí)現(xiàn). 因此在完成相同操作的情況下,相較于直接包含復(fù)雜操作指令的CISC來說, RISC程序往往需要執(zhí)行更多條指令. 尤其是在內(nèi)存大小受限的嵌入式設(shè)備中[3], 二進(jìn)制程序體積偏大的問題更加突出[1].
本文第2節(jié)簡(jiǎn)要介紹了相關(guān)減小程序體積的部分方法以及研究, 并且簡(jiǎn)要介紹Zce子擴(kuò)展對(duì)于指令優(yōu)化的效果. 第3節(jié)介紹RISC-V架構(gòu)以Zce子擴(kuò)展的優(yōu)化思路. 第4節(jié)詳細(xì)解釋了LSGP指令優(yōu)化程序體積的方法. 最后基于LLD鏈接器實(shí)現(xiàn)了LSGP指令的優(yōu)化并對(duì)優(yōu)化效率進(jìn)行分析.
2 相關(guān)研究
針對(duì)RISC程序體積偏大的問題, 目前主流方法之一就是在基礎(chǔ)指令集以外額外支持一個(gè)“短指令集”.該指令集用更短的指令寬度編碼基礎(chǔ)指令集中最常用的指令從而二進(jìn)制程序體積. 在ARM架構(gòu)中就使用Thumb指令集縮減程序體積, MIPS架構(gòu)則有MISP16指令集承擔(dān)縮小程序體積的任務(wù)[3]. 得益于RISC-V指令集可擴(kuò)展性高的特點(diǎn), RISC-V當(dāng)前也有C指令集子擴(kuò)展被用于同樣的目的.
除此之外, Halambi等人[3]還通過對(duì)MIPS指令建模, 使用啟發(fā)式的方法來估算因?yàn)榧拇嫫鲾?shù)量有限導(dǎo)致被分配的堆棧, 計(jì)算分析從而更細(xì)粒度地選擇壓縮指令. 在MISP 16壓縮指令集的基礎(chǔ)上更進(jìn)一步的壓縮了MIPS二進(jìn)制程序的體積.
在嵌入式領(lǐng)域的基準(zhǔn)測(cè)試中, RISC-V架構(gòu)的二進(jìn)制體積相較ARM架構(gòu)增大了約11%, 即使在使用了C子擴(kuò)展的情況下仍有較大差距[4]. 本文研究的RISC-V的Zce子擴(kuò)展[4]與C子擴(kuò)展同樣被用來解決二進(jìn)制程序體積偏大的問題. 但與C子擴(kuò)展不相同的是, 該擴(kuò)展除了通過縮減常用指令的長(zhǎng)度以外, 還嘗試替換頻繁使用的固定指令組合從而縮減程序體積, 進(jìn)一步增加了代碼密度. 具體而言, 在C子擴(kuò)展的基礎(chǔ)上, Zce子擴(kuò)展使得二進(jìn)制體積比ARM架構(gòu)小約1.75%. 本文對(duì)于Zce擴(kuò)展中以LWGP為代表的指令進(jìn)行研究, 基于LLD鏈接器實(shí)現(xiàn)該優(yōu)化并且評(píng)估其優(yōu)化效率.
3 RISC-V指令集擴(kuò)展
RISC-V指令集由基礎(chǔ)指令集和眾多擴(kuò)展指令集組成. 其中基礎(chǔ)指令集包含了如整數(shù)加減和位運(yùn)算以及分支跳轉(zhuǎn)指令等, 如表1所示. 這些指令足以支撐一個(gè)簡(jiǎn)單的裸機(jī)程序或者操作系統(tǒng)的運(yùn)行.

表1 基礎(chǔ)指令集中常用的主要指令
除此之外, 基礎(chǔ)指令集還為RISC-V指令集定義了x0-x31共32個(gè)通用寄存器. 每個(gè)寄存器都有其對(duì)應(yīng)的用途. 如表2所示.
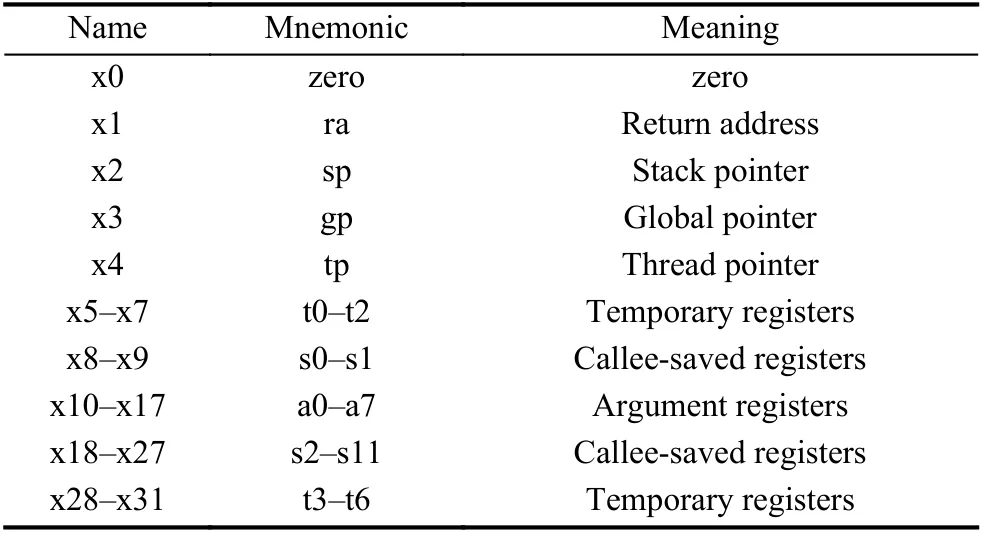
表2 通用寄存器使用規(guī)范
表2中, gp和tp寄存器則較為特殊, 它在程序執(zhí)行的過程中被當(dāng)作常量值使用.
3.1 Zce指令集擴(kuò)展
與基礎(chǔ)指令集不同, Zce擴(kuò)展更多的是針對(duì)當(dāng)前已有指令的壓縮和優(yōu)化問題. 它通過減少指令中某些情況下冗余操作數(shù)或者替換常用的固定指令組合來縮減單個(gè)指令的長(zhǎng)度和指令條數(shù).
以基礎(chǔ)指令集中邏輯運(yùn)算指令為例, 邏輯運(yùn)算中只有與, 或和異或, 非運(yùn)算則通過將源寄存器異或-1實(shí)現(xiàn). 圖1是XORI的指令格式
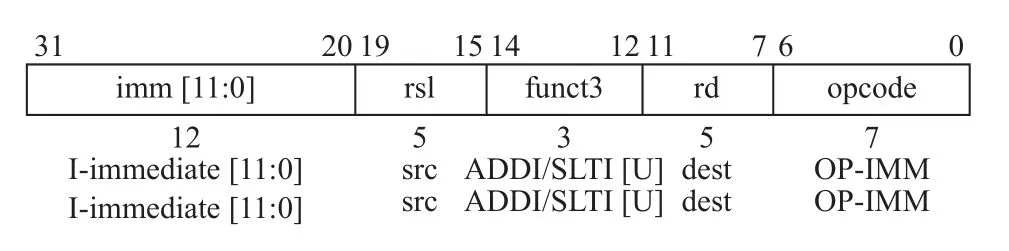
圖1 XORI 指令格式
XORI指令將rs1寄存器中的數(shù)和立即數(shù)imm按位異或運(yùn)算, 結(jié)果寫入rd寄存器. 在非運(yùn)算過程中較頻繁的會(huì)出現(xiàn)rs1和rd使用同一個(gè)寄存器的情況, 因此Zce擴(kuò)展嘗試將這種情況下rs1和rd寄存器合并以節(jié)約編碼點(diǎn). Zce中將非運(yùn)算(c.not)定義為如圖2格式.

圖2 c.not指令格式
c.not 指令合并rs1和rd寄存器為rsd, 同時(shí)因?yàn)榧s定立即數(shù)為-1所以刪除了立即數(shù). 將基礎(chǔ)指令集實(shí)現(xiàn)的32位非運(yùn)算指令XORI rd, rs1, -1縮減為16位的c.not指令.
Zce擴(kuò)展中還有一部分指令用于壓縮固定的指令組合. 例如push/pop指令. 在RISC-V匯編中, 函數(shù)的開始和末尾都需要保存和恢復(fù)堆棧指針和參數(shù)或返回值. Zce以使用push/pop指令一次性代替多條SW/LW指令的方式縮減指令條數(shù).
LSGP指令縮減程序體積的方式也與之類似,LSGP指令仍為32 bit指令, 它通過提高硬件的復(fù)雜度,將兩條指令合并為一條指令從而減小程序二進(jìn)制體積.Zce中使用GP寄存器進(jìn)行優(yōu)化的指令共4條, 分別是LWGP、SWGP、LDGP、SDGP (下用LSGP指代全部4條指令). 其與基礎(chǔ)指令集的Load/Store指令對(duì)應(yīng).其中, LDGP和SDGP僅被用于RISC-V 64位機(jī)器中加載雙字長(zhǎng)的數(shù)據(jù).
4 LWGP指令優(yōu)化原理
4.1 LW指令介紹
前面提到的RISC-V基礎(chǔ)指令中還定義了字加載/存儲(chǔ)指令, 分別是LW、SW、LD、SD (下多以LW指令為例), 它們被用來從給定地址加載字節(jié)數(shù)據(jù). 其指令格式如圖3所示. LW指令使用rs1的值為基地址,將rs1+offset處4個(gè)字節(jié)的數(shù)據(jù)加載到rd寄存器中.這就意味著在程序執(zhí)行LW指令之前仍需使用額外指令將基地址加載到rs1寄存器中. 適用于這種情況的有兩條指令, 分別是ADDI和LUI. 本文主要研究使用LUI指令加載基地址的情況.

圖3 Load/Store指令格式
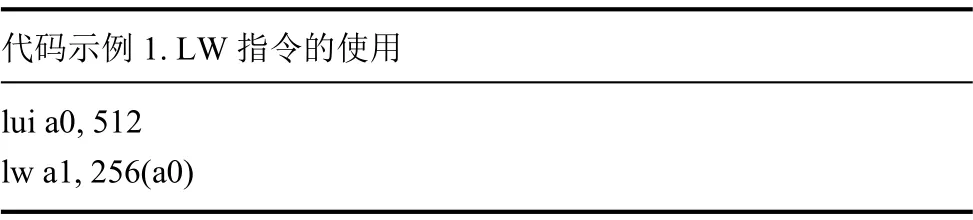
代碼示例 1. LW指令的使用lui a0, 512 lw a1, 256(a0)
在代碼示例1中, 兩條指令一起被用來加載位于0x200100的數(shù)據(jù). 由LUI現(xiàn)將該數(shù)據(jù)的高二十位地址加載進(jìn)a0寄存器, 再由LW指令將位于此處的數(shù)據(jù)加載到a1中.
為了對(duì)這種情況進(jìn)行優(yōu)化, RISC-V引入了一個(gè)全局指針寄存器GP. 這個(gè)寄存器的值在鏈接過程中被確定并且在程序執(zhí)行過程中保持不變. GP寄存器主要被用來優(yōu)化程序中全局變量的訪問, 所以在一般情況下,鏈接器會(huì)將GP指針指向ELF文件中.sdata小數(shù)據(jù)段+0X800的位置. 當(dāng)某一個(gè)全局變量可以被以GP為基地址訪問時(shí). 鏈接器就會(huì)刪除LW指令之前的LUI指令以縮減代碼體積. 示意如圖4.

圖4 GP指針位置示意
但是由于LW指令中的偏移量的長(zhǎng)度僅有12 bit,因此僅能訪問到GP±2 KB范圍內(nèi)的全局變量. 對(duì)于超出該范圍的全局變量, 就仍需要LUI指令通過其他寄存器傳遞基地址.
4.2 通過LWGP提高LW指令的訪存能力
LW指令的主要問題是偏移量位寬不足以當(dāng)前情況. 它只能訪問基地址±2 KB范圍內(nèi)的變量. 所以需要較為頻繁的使用LUI指令以重新加載新的基地址. 而LWGP正是通過增加長(zhǎng)偏移量的位寬提高了其訪存能力. LWGP指令格式如圖5.

圖5 LWGP指令格式
LWGP指令事先約定了使用GP寄存器作為基址寄存器, 如此可以將LW中基地址寄存器rs1對(duì)應(yīng)的編碼點(diǎn)分享給偏移量offset使用. 這樣就可以使得偏移量的寬度從LW的12 bit擴(kuò)展到了LWGP的16 bit, 從而使LWGP指令可以訪問GP±32 KB范圍內(nèi)的全局變量. 基于同樣的原理, LDGP和SDGP的訪存能力更是擴(kuò)大到了GP±64 KB的范圍.
5 基于LLD的LSGP指令優(yōu)化
正如上文所提到的, GP指針被用來優(yōu)化全局變量的訪問. 然而在程序鏈接之前, 全局變量的地址還尚未被確定. 因此當(dāng)前生成的一些匯編指令需要使用標(biāo)志符預(yù)先占位, 如 %hi (symbol) 代表符號(hào)symbol的高20位地址, 這些標(biāo)志并不能被直接編碼到二進(jìn)制指令中, 所以編譯器會(huì)使用重定位類型(如R_RISCV_LO12_I)標(biāo)記這條指令, 表示這條指令還需要鏈接器做后續(xù)處理. 而具體的相應(yīng)數(shù)據(jù)會(huì)在鏈接過程中被寫入.
5.1 鏈接器松弛
在鏈接器松弛過程中, 鏈接器會(huì)從整個(gè)可執(zhí)行程序的視角對(duì)于代碼進(jìn)行優(yōu)化. 鏈接器會(huì)讀取并解析文件中所有的重定位信息, 針對(duì)每一條重定位信息進(jìn)行相應(yīng)的優(yōu)化處理, 鏈接器松弛的簡(jiǎn)要流程如圖6所示.每條重定位信息的優(yōu)化方式取決于該條信息的重定位類型, 不同的重定位類型對(duì)應(yīng)著不同的函數(shù)方法. 本文的優(yōu)化主要設(shè)涉及3種重定位類型, 分別是R_RISCV_HI20、R_RISCV_LO12_I和R_RISCV_LO12_S.

圖6 鏈接器松弛簡(jiǎn)要流程
當(dāng)LUI指令被用來加載一個(gè)全局變量的高20位地址時(shí), 編譯器會(huì)將該指令用R_RISCV_HI20標(biāo)記. 同時(shí), 該指令通常會(huì)和使用全局變量低12位的LW指令一起使用. 以本文研究涉及到的LW和LUI的指令為例, 編譯器會(huì)給LW指令標(biāo)記重定位類型R_RISCV_LO12_I.
在鏈接器的松弛階段中, 鏈接器會(huì)不斷重復(fù)掃描并嘗試優(yōu)化程序中每一條重定位信息, 直到全部的重定位信息都不能夠再次被優(yōu)化. 其中被用來加載全局變量的LUI和LW兩條指令會(huì)被嘗試優(yōu)化成以GP寄存器為基地址寄存器的LW指令. 基于同樣的邏輯, 本文主要討論的LSGP也需要做相似的處理.

代碼示例 2. LW指令使用的重定位類型lui a0, %hi (symbol) # R_RISCV_HI20 (symbol)lw a0, %lo (symbol) (a0) # R_RISCV_LO12_I (symbol)
由于LSGP指令格式與其他指令都不相同, 因此并不能被目前已經(jīng)存在的重定位標(biāo)記正確處理. 于是在這一階段我們定義了新的重定位類型來指定LSGP指令的優(yōu)化操作. 同時(shí), 鏈接器中所有被用到的重定位類型都需要由psABI來定義. 但是由于Zce擴(kuò)展仍處在實(shí)驗(yàn)階段, psABI中沒有定義相關(guān)的重定位類型, 因此出于實(shí)驗(yàn)測(cè)試目的, 作者針對(duì)LSGP臨時(shí)定義了重定位標(biāo)記用于指令的優(yōu)化.
鏈接器松弛結(jié)束后, 每一條被重定位類型標(biāo)記的指令會(huì)被按照這個(gè)重定位類型的要求計(jì)算地址, 并且填充到對(duì)應(yīng)占位標(biāo)志的地方.
5.2 鏈接器上LSGP優(yōu)化的實(shí)現(xiàn)
本節(jié)中使用LLD鏈接器為例子進(jìn)行討論. 由于LLD主線針對(duì)于RISC-V鏈接器松弛的實(shí)現(xiàn)尚不完善,因此我們使用了一個(gè)上游正在review的補(bǔ)丁來完善相關(guān)功能. 在此基礎(chǔ)上進(jìn)行LSGP等指令的生成、優(yōu)化以及評(píng)估工作. 同時(shí), 為了能夠單獨(dú)評(píng)估LSGP的優(yōu)化效率, 我們定義了一個(gè)-mzce-lsgp開關(guān), 用來更直觀地評(píng)估LSGP四條指令的優(yōu)化效率.
編譯器會(huì)為L(zhǎng)UI和LW指令分別標(biāo)記重定位類型R_RISCV_HI20和R_RISCV_LO12_I. 在初始階段,鏈接器就會(huì)統(tǒng)一提取所有的重定位信息. 因此我們通過遍歷重定位標(biāo)記就可以找到需要被優(yōu)化的指令. 但值得注意的是, LUI指令并不僅會(huì)和LW被一起使用.也會(huì)和例如ADDI等其他指令一同被用來加載絕對(duì)地址. 因此我們?cè)谂袛郘UI指令是否可以被優(yōu)化的時(shí)候還需要提前讀取并判斷下一條指令是否屬于字加載指令.
在此之后還需針對(duì)R_RISCV_LO12_*進(jìn)行優(yōu)化.為了避免造成額外的影響, 首先需要判斷當(dāng)前指令是否為L(zhǎng)W/SW/LD/SD的其中之一, 之后計(jì)算當(dāng)前指令使用的全局變量是否位于LSGP指令要求的地址范圍內(nèi). 過程中要注意保存rd寄存器的值來確保優(yōu)化前后的功能不會(huì)改變. 整體實(shí)現(xiàn)邏輯偽代碼如示例代碼3所示. 鏈接器在將LW修改成LWGP的過程中并不會(huì)對(duì)偏移量offset參數(shù)進(jìn)行賦值, 它的值將會(huì)在鏈接器優(yōu)化階段結(jié)束后被統(tǒng)一調(diào)整.

代碼示例 3. 優(yōu)化LUI和LSGP指令1. for each rel in relocations 2. if rel.type is R_RISCV_HI20 and rel.inst is LUI 3. if rel.nextInst is one of (LW ro LD or SW or SD)4. if rel.inst.offset is in range of Uint16 and aligned by 4 b 5. Call removeInst(rel)6. else if rel.type is R_RISCV_LO12_I or R_RISCV_LO12_S 7. if rel.inst is LW 8. if rel.inst.offset is in range of Uint16 and aligned by 4 b 9. Call repleaseInstByLWGP(rel)10. rel.type = R_RISCV_LWGP 11. else if rel.inst is SW 12. if rel.inst.offset is in range of Uint16 and aligned by 4 b 13. Call repleaseInstBySWGP(rel)14. rel.type = R_RISCV_SWGP 15. else if rel.inst is LD 16. if rel.inst.offset is in range of Uint17 and aligned by 8 b 17. Call repleaseInstByLDGP(rel)18. rel.type = R_RISCV_LDGP 19. else if rel.inst is SD 20. if rel.inst.offset is in range of Uint17 and aligned by 8 b 21. Call repleaseInstBySDGP(rel)22. rel.type = R_RISCV_SDGP 23. end
鏈接器優(yōu)化結(jié)束后, 意味著各個(gè)段的地址已經(jīng)被最終確定. 編譯器會(huì)分別為不同的重定位標(biāo)記計(jì)算地址, 并按照相應(yīng)的指令格式將偏移量寫入指令. 同樣因?yàn)長(zhǎng)SGP四條指令的格式各不相同, 所以需要分別處理.
6 LSGP優(yōu)化效率分析
為了分析LSGP指令對(duì)于程序的優(yōu)化效果, 我們嘗試使用上文中修改的LLD和Clang對(duì)RISC-V測(cè)試(riscv-test)代碼的部分程序進(jìn)行編譯鏈接. 并對(duì)比分析使用LSGP指令前后反匯編代碼數(shù)目.
6.1 LSGP縮減代碼體積的比例
由于LSGP指令針對(duì)于全局變量進(jìn)行訪問, 我們從RISC-V test測(cè)試集合中選取了兩個(gè)使用全局變量較為頻繁的測(cè)試程序, 分別是用來測(cè)試整數(shù)加法的Dhrystone測(cè)試以及測(cè)試遞歸調(diào)用的towers測(cè)試, 此外還編譯了Linux常用軟件bash和vim進(jìn)行測(cè)試. 測(cè)試過程中均以riscv32imac作為基準(zhǔn), 結(jié)果如圖7所示.
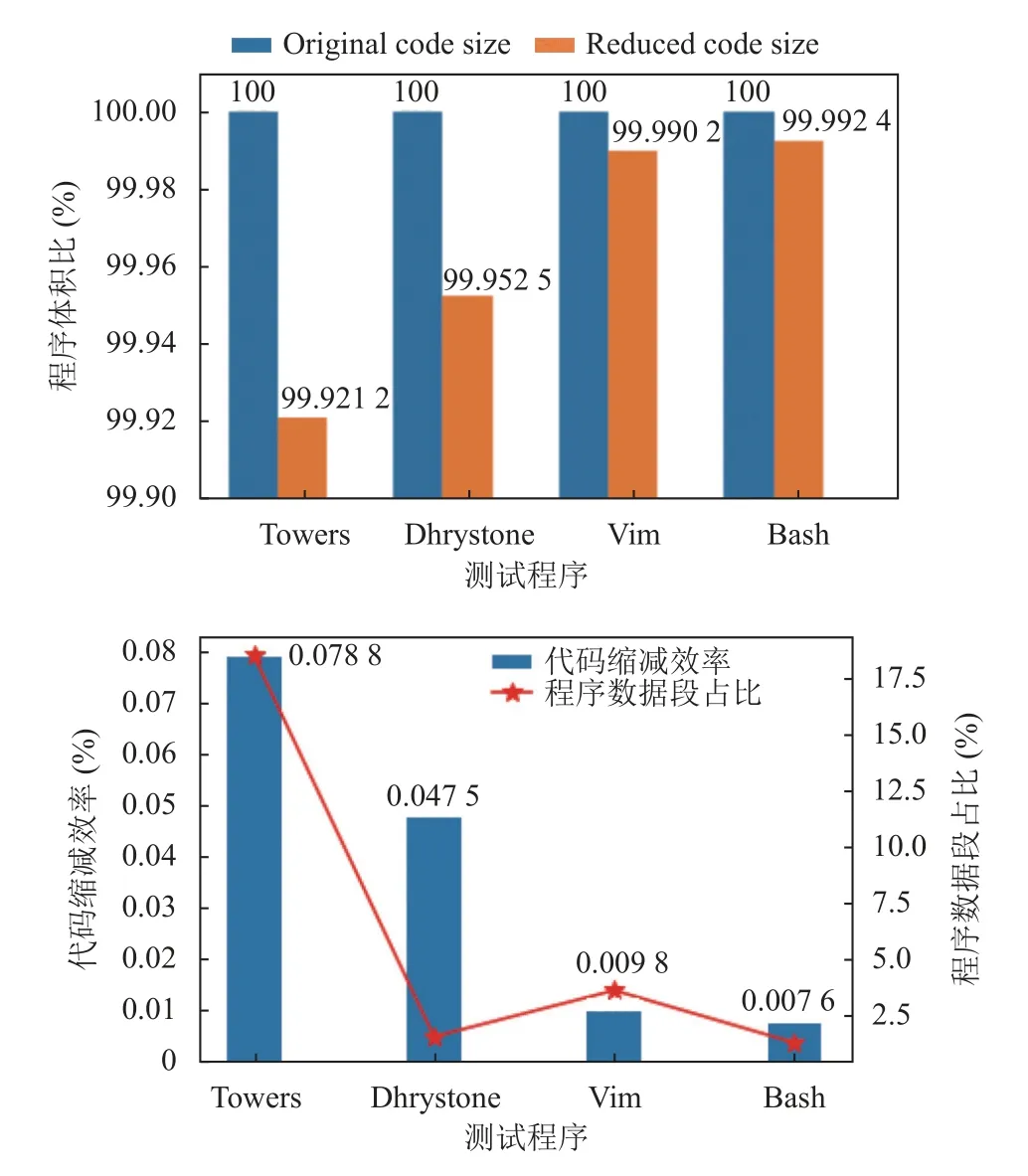
圖7 LSGP 縮減程序體積與數(shù)據(jù)段大小的關(guān)系
在Dhrystone測(cè)試程序中, 使用LSGP指令前后反匯編得出的指令條數(shù)分別為18 447和18 413條. .data和.sdata共計(jì)4 384字節(jié). 有22個(gè)全局變量被訪問, 共計(jì)184字節(jié)的全局?jǐn)?shù)據(jù)通過LDGP/SDGP被訪問. 優(yōu)化前二進(jìn)制大小286 216字節(jié), 優(yōu)化后二進(jìn)制大小286 080字節(jié). 二進(jìn)制體積減少約0.047%. 對(duì)于towers測(cè)試程序, 由于相對(duì)使用全局變量較少且程序整體代碼量較少. .data與.sdata總計(jì)1 880字節(jié), 共計(jì)36字節(jié)全局?jǐn)?shù)據(jù)通過LSGP被訪問, 優(yōu)化前二進(jìn)制大小為10 152字節(jié), 優(yōu)化后為10 144字節(jié). 二進(jìn)制程序體積減少了0.07%.我們還嘗試編譯了目前常用的GNU軟件vim和bash作為日常軟件的代表. 與測(cè)試集合中刻意的測(cè)試代碼不同, bash和vim程序體積減小的幅度小于Dhrystone和towers. Bash中.data與.sdata總計(jì)35 548字節(jié)中的148字節(jié)數(shù)據(jù)被通過LSGP指令訪問. Vim中則共有782字節(jié)的數(shù)據(jù)被LSGP訪問. 相較于使用LSGP加載數(shù)據(jù)之前, bash和vim二進(jìn)制程序體積的縮減效率分別是0.007 6%和0.009 8%. 總體而言, 程序體積的縮減效率與程序數(shù)據(jù)段占比呈正相關(guān).
表3中展示的優(yōu)化效率看似較為低下, 其主要由于Zce擴(kuò)展的優(yōu)化空間所導(dǎo)致. Zce指令集的目的是在C壓縮指令擴(kuò)展的基礎(chǔ)上進(jìn)一步縮減程序體積.C擴(kuò)展指令已經(jīng)將RISC-V程序體積大幅度縮小. 盡管如此, 相較于ARM Cortex M4架構(gòu)下的二進(jìn)制程序,仍然有不到10%的體積差距[5]. 于是Zce子擴(kuò)展則致力于進(jìn)一步縮小這不到10%的差距. 這也就導(dǎo)致了Zce擴(kuò)展的優(yōu)化空間普遍較小, 從而優(yōu)化效率相較于C指令集較低. 同時(shí)考慮到Zce擴(kuò)展中其他單條指令的優(yōu)化效率也都在0.02%-0.24%之間, 所以從這個(gè)角度來分析LSGP作為單條指令的優(yōu)化效率也算合格.
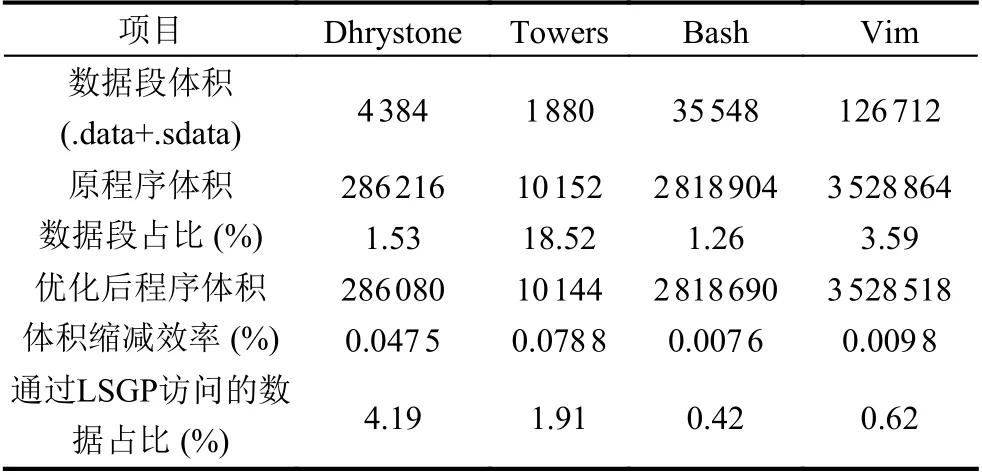
表3 LSGP縮減程序體積的效率
對(duì)于代碼體積的優(yōu)化問題, 本研究中主要針對(duì)于對(duì)全局變量的優(yōu)化, 因此正如表3和圖7所體現(xiàn)的, 一個(gè)程序中全局變量的數(shù)量或占比決定了LSGP優(yōu)化的效率. 而程序中全局變量使用的數(shù)量一定程度上取決于程序的規(guī)模[6]和功能. 因此, 對(duì)于底層軟件, 例如操作系統(tǒng), 單片機(jī)程序等也會(huì)使用到較多全局變量的程序來說, LSGP縮減代碼體積的效果同樣是樂觀的.
7 結(jié)論和展望
綜上所述, 與LW等常規(guī)字加載指令相比, LSGP指令能夠針對(duì)LW指令的部分使用場(chǎng)景進(jìn)行優(yōu)化, 通過約定基址寄存器的方式將寄存器的位寬分配給偏移量使用, 從而擴(kuò)大指令的尋址范圍. 本文在LLD鏈接器上實(shí)現(xiàn)這部分的優(yōu)化并進(jìn)行了評(píng)估. 對(duì)于RISC-V的部分標(biāo)準(zhǔn)測(cè)試程序來說, LSGP達(dá)到了較高的優(yōu)化效率. 同時(shí)在日常通用軟件中, LSGP對(duì)于程序體積的縮減也起到了一定的作用.
雖然前文描述了LWGP確實(shí)在一定程度上優(yōu)化了代碼體積. 但是優(yōu)化效率相較于標(biāo)準(zhǔn)測(cè)試程序中的理想條件仍有一定差距. 可以通過改進(jìn)以下問題進(jìn)一步減小這個(gè)差距.
(1) LSGP指針的編碼不合理.
(2) 部分LSGP的尋址能力被浪費(fèi).
(3) 局限于優(yōu)化.sdata段而忽略了其他可以被優(yōu)化的數(shù)據(jù)段.
psABI只考慮到LW指令的4K尋址能力. 因此將GP指針的值設(shè)置為.sdata+2K (0X800)的位置來確保盡可能大覆蓋到.sdata節(jié)的數(shù)據(jù). 但是對(duì)于LSGP指令達(dá)到64 KB的尋址能力來說, GP指令仍位于.sdata+2K (0X800)位置的話就意味著LSGP指令的尋址范圍并不是從.sdata段開始. 所以最簡(jiǎn)單的辦法本應(yīng)是改變GP指針的位置, 但由于LSGP指令無法完全代替LW指令, 無法改變GP指針的位置. 基于此, 當(dāng)前最好的解決辦法就是嘗試更改LSGP指令的格式, offset偏移量從帶符號(hào)數(shù)改為無符號(hào)數(shù), 從GP±32 KB變成GP±64 KB, 這樣LW和LWGP搭配使用, 可以通過GP指針訪問更大范圍的全局變量.
又因?yàn)長(zhǎng)SGP大部分的尋址范圍覆蓋到了除.sdata段以外的地址. 因此每個(gè)數(shù)據(jù)段之間的相對(duì)位置就變得相對(duì)重要. 如果相關(guān)的數(shù)據(jù)段排列在一起, 可以更大程度上避免LSGP尋址能力被浪費(fèi). 同時(shí), .sdata段是小數(shù)據(jù)段, 其存儲(chǔ)了數(shù)據(jù)長(zhǎng)度小于某一閾值(通常小于8字節(jié))的變量, 其余的全局變量會(huì)被存儲(chǔ)到.data段. 這就導(dǎo)致程序中的.sdata段普遍較小, 甚至一部分程序根本不存在.sdata段. 目前鏈接器的實(shí)現(xiàn)(以LLD為例)僅基于.sdata段設(shè)置GP指針. 如果.sdata段不存在, 則GP指針就會(huì)被LLD忽略, 不只LSGP, 甚至對(duì)于LW的優(yōu)化也會(huì)被無效化. 如果鏈接器在.sdata段不存在的情況下將GP指向.data段, 程序體積可以被進(jìn)一步縮減.
8 結(jié)束語
本文通過介紹和分析LW指令的作用以及存在的問題, 闡述了LSGP指令的優(yōu)勢(shì)和特點(diǎn). 將之實(shí)現(xiàn)到LLD鏈接器上并粗略評(píng)估了LSGP指令優(yōu)化效率. 相較于現(xiàn)有的字加載指令, LSGP通過擴(kuò)大偏移量立即數(shù)的位寬增大尋址范圍的方式避免使用LUI指令加載高位地址, 從而縮減代碼條數(shù)和程序體積的方式, 針對(duì)于使用GP寄存器作為基址的情況進(jìn)行優(yōu)化. 證明了LSGP指令存在一定的優(yōu)化價(jià)值. 同時(shí)在整個(gè)過程中作者也發(fā)現(xiàn)了目前LSGP作為實(shí)驗(yàn)性指令存在的一些問題. 針對(duì)于這些問題提出了相應(yīng)的解決方案. 我們已經(jīng)將這些問題和建議反饋到RISC-V社區(qū).
猜你喜歡
科普童話·神秘大偵探(2023年1期)2023-05-30 12:48:10
房地產(chǎn)導(dǎo)刊(2022年5期)2022-06-01 06:20:14
建材發(fā)展導(dǎo)向(2021年12期)2021-07-22 08:06:48
建材發(fā)展導(dǎo)向(2021年7期)2021-07-16 07:07:52
中學(xué)生數(shù)理化(高中版.高二數(shù)學(xué))(2021年12期)2021-04-26 07:43:48
人大建設(shè)(2019年12期)2019-05-21 02:55:44
測(cè)控技術(shù)(2018年5期)2018-12-09 09:04:26
電子測(cè)試(2018年18期)2018-11-14 02:30:34
瞭望東方周刊(2017年42期)2017-12-05 18:49:38
環(huán)球時(shí)報(bào)(2017-03-30)2017-03-30 06:44:45
