基于機器學習的日志異常檢測綜述①
2022-09-20 04:10:38閆力,夏偉
計算機系統應用 2022年9期
閆 力, 夏 偉
(江南計算技術研究所, 無錫 214084)
1 引言
日志是各類軟硬件記錄系統運行狀態的一類重要數據, 它描述了系統的歷史運行狀態和詳情. 運維工程師在進行故障排除、安全性檢查等工作場景下, 經常需要對日志數據進行檢查和分析. 而大數據技術的迅猛發展使得現代數據中心規模日益擴大, 復雜的系統每天都會產生數以千萬計的日志記錄, 一個運行在中等規模網絡中的系統每天的日志量也能輕松超過TB級[1]. 體量巨大且種類繁多的日志數據使得運維工程師難以再依賴簡單的關鍵詞搜索或者正則匹配等方式來進行手工分析. 這不僅會帶來繁重而枯燥工作量,同時也是對運維人員領域專業知識的極大考驗——只有對某類日志特征具有豐富的處理經驗才能設定出合理的過濾規則. 因此, 應用機器學習技術為機器自身賦能, 實時或準實時捕獲系統運行狀態異常以實現日志分析自動化, 是未來數據中心實現智能自主運維的重要途徑之一.
日志、指標、鏈路追蹤數據是運維工作中最為核心的監控和分析對象[2], 相較于指標和鏈路追蹤數據,日志是內容最為豐富且來源充足的一類數據, 系統的異常或者性能下降一般會在日志中優先體現出來. 文章闡述了實現在線自動日志異常檢測的主要步驟、關鍵技術、方法分類等內容, 分析了日志分析的技術難點, 并介紹了近期領域內的最新研究成果. 最后, 提出今后的一些研究重點和思路.
2 日志異常檢測任務簡介
2.1 日志異常檢測流程
日志異常檢測任務一般分為日志采集、日志解析、特征表示、異常判別4個步驟.
日志采集: 日志作為一種信息系統中廣泛存在的數據, 往往散落于系統各處, 特別是對于分布式軟件、大型軟件等, 不同節點、不同組件都在持續生成和積累日志, 所以日志采集是日志異常檢測任務的第一步.較為常見的日志采集工具包括Logstash、Flume、Fluentd、Kafka等, 通過持續、實時的數據采集, 可以將數據集中入庫或者通過“發布-訂閱”的模式推送給消費端進行后續處理.
日志解析: 日志屬于半結構化數據, 需要分析其一般構成, 并利用解析技術將其中的常量和變量分離出來, 為后續特征表示提供良好基礎. 一條日志數據可以分解為正則消息部分和特征消息部分[3]. 正則消息包括時間戳、日志等級、產生日志的類名稱等日志基本組成, 這部分是可以用正則表達式進行提取和分解的, 屬于日志數據的基礎信息. 特征消息部分則是描述了日志內容的核心部分, 由文本、數字及特殊符號等組成.一條日志數據是由程序開發者在代碼中預先埋點編寫的各種輸出語句在滿足特定條件下產生的, 例如printf、log.info、log.warn等. 它包括了字符串常量和參數變量, 其中字符串常量被稱為日志模板(或事件、鍵值),表明了該條日志數據的類屬, 是日志消息的語義描述;參數變量則表明了系統狀態關鍵變量的取值, 例如對象ID、內存消耗、執行時間等. 其中日志模板由于是開發者對系統狀態的語義描述, 蘊含豐富的信息, 往往作為重要的分析對象輸入后續檢測模型進行異常判別.表1展示了截取自多個系統的日志片段, 并標識了各個組成部分, 需要注意的是由于應用軟件開發規范和開發者的編程習慣各異, 日志格式上也存在千差萬別.
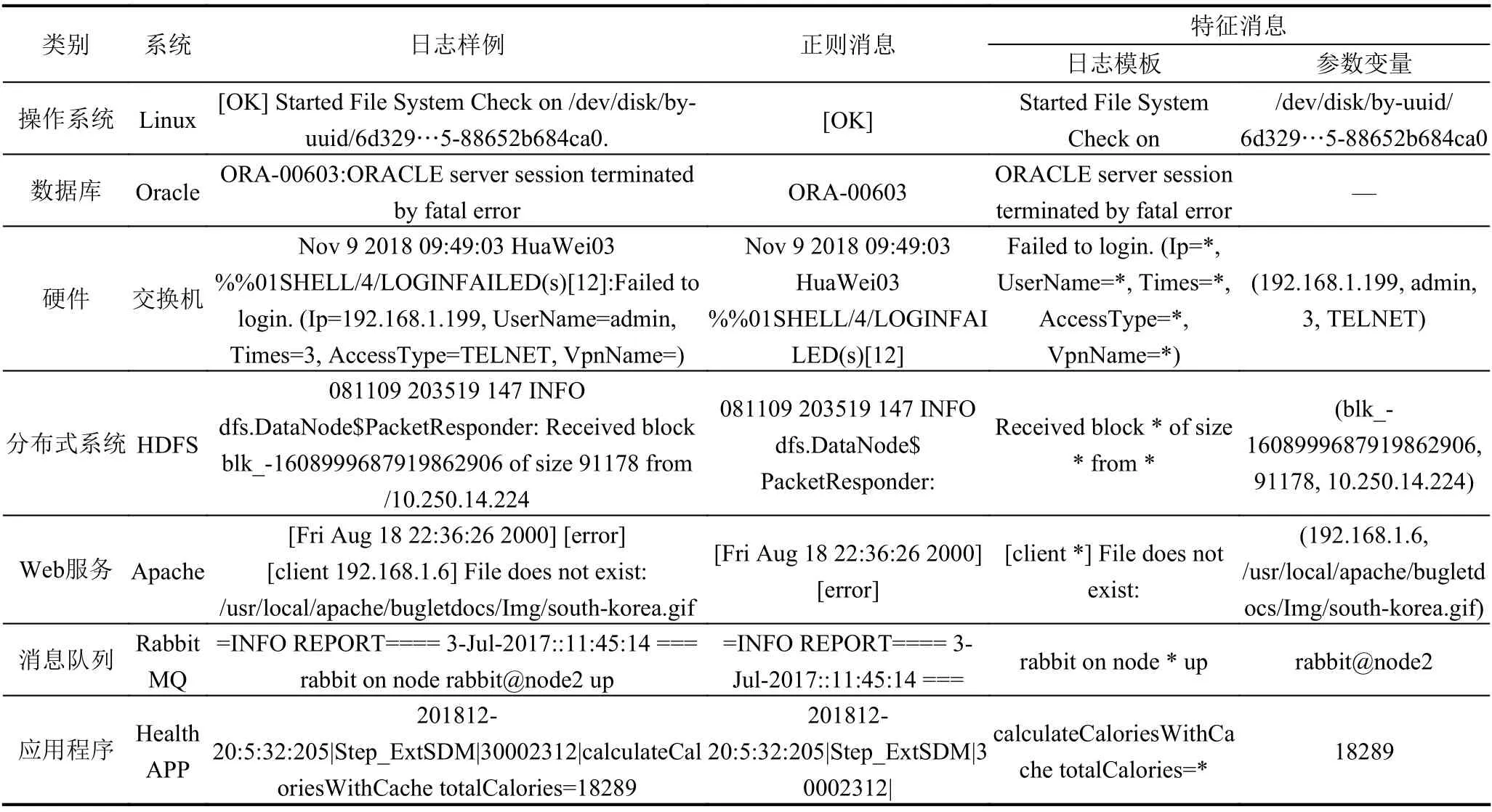
表1 典型日志樣例解析
數據解析的精度將顯著影響檢測模型的性能表現,有研究試驗表明數據解析階段4%的錯誤可能會在異常檢測階段導致性能下降擴大一個數量級[4]. 日志解析從分析對象來源上區分, 可分為基于源代碼的模板抽取和基于日志文本的模板抽取. 有研究工作使用了基于源代碼中類似printf等語句來抽取模板[5,6], 但這種方式在多數情況下并不可行——因為源代碼分析難度大且難以獲得. 目前, 就基于日志文本來抽取模板的方式, 領域內已經提出了大量算法, 典型的有SLCT[7]、IPLoM[8]、LKE[9]、Spell[10]、Drain[11]、LPV[12]等.SLCT是最早提出的日志解析算法, 通過2次遍歷日志消息分別構造日志詞匯表和候選簇, 再從簇中進行模板抽取; IPLoM在模板生成前采用3步式分層劃分方法對日志消息進行處理; LKE是由微軟提出的一種離線日志解析算法, 主要利用了分層聚類和啟發式規則;Spell基于最長公共序列來以在線方式解析日志模板;Drain使用一棵固定深度解析樹, 通過持續更新解析樹來在線獲得日志模板; LPV是最近提出的一種日志解析算法, 它使用Word2Vec詞嵌入技術[13]對日志消息向量化, 基于向量相似度來聚類, 日志模板從所聚類的簇中提取出來.
特征表示: 這部分工作的主要目的在于構造機器學習模型可以處理的特征數據, 借此來學習日志的正常或者異常模式. 所提取特征的質量決定了后續模型檢測效果所能達到的精度. 日志分析領域, 前一階段提取的日志模板一般被稱為事件或者鍵值. 在進行特征提取前, 需要對連續的日志進行切分, 通常有時間窗口、會話ID等方式: (1) 日志是一種具有時間屬性的連續文本, 一條日志數據是否提示異常不僅取決于自身所蘊含的信息, 還受到其上下文的影響, 因此可采用固定或者滑動時間窗口將日志切分成數據片段, 便于輸入模型進行處理. 最優時間窗口的大小可根據數據的特點進行多次嘗試得到, 過小或過大的窗口都會對檢測精度帶來不利影響——過小的窗口會使得上下文信息不足, 而過大的窗口又會帶來冗余信息; (2) 某些日志的變量參數標記了某一特定會話的執行路徑, 例如HDFS日志中的block_id, OpenStack日志中的instance_id等, 可以根據會話ID將并行進程產生的日志進行剝離, 但這種方法僅限于具有此類變量參數的日志.
日志異常檢測通過采用的主要特征包括: 事件計數、事件序列、文本語義、時間間隔、變量取值、變量分布等[14], 這些特征的變化往往反映出系統狀態的異常. 事件計數表示日志中某一類別的事件數量大幅增加或者減少, 如Web應用日志中某一時間段內突然出現大量“Login failed”事件, 可能是系統出現安全事件的標志; 由于具有時序屬性, 正常日志事件出現的順序也會遵循一定的規律, 如OpenStack管理日志中, 一臺虛擬機的生命周期是從“VM Created”開始, 中間可能經過若干次“Pause/Unpause”和“Suspend/Resume”的事件組合, 最終以“VM deleted”結束; 文本語義是通過自然語言處理技術解析日志文本自身攜帶的語義來判別日志是否出現異常; 時間間隔則是兩條日志消息相繼出現所經過的時長, 由于絕大多數日志都帶有時間戳,時間間隔很容易計算, 如果特定兩條日志消息的時間間隔過大, 可能預示著服務性能的下降; 變量取值指的是模板抽取后分離出的參數變量如果取值超過正常閾值范圍, 則提示了系統的狀態異常, 例如某進程消耗的內存過大, 可能是出現了內存泄漏. 變量分布則是對于某些參數變量的取值進行分布統計, 典型的如Web服務器日志中某一時間段同一源IP地址分布密度遠大于其他地址, 則提示潛在威脅的出現. 現有的研究成果提出的算法往往用到其中一種或者多種的組合, 這些特征表示從不同維度反映出系統的當前狀態.
異常判別: 經過特征提取, 原始日志數據已經轉換為模型可以處理的特征數據, 可以輸入判別模型進行異常檢測. 在檢測模型的設計上, 包括傳統機器學習方法和深度學習方法. 傳統機器學習方法具有硬件依賴性低、可解釋性好等特點, 典型的有基于主成分分析的算法[5]、基于支持向量機的算法[15]、基于隱馬爾科夫模型的算法[16]、基于K最近鄰算法[17,18]、各種聚類算法[3,19]等. 傳統機器學習算法提取高級特征或者全局特征的能力相對有限, 特別是日志文本的語義識別、長距離依賴等問題上表現不如深度學習, 所以有大量研究將深度學習引入日志異常檢測任務. 基于深度模型的日志分析算法中包括基于長短期記憶網絡的算法[20-24]、基于雙向長短期記憶網絡的算法[25]、基于變分自編碼器的算法[6,26]、基于生成對抗網絡的算法[27]、基于Transformer網絡的算法[28,29]等. 但深度學習方法也并非“完美”: 首先, 深度學習作為一種端到端的解決方案, 屬于黑盒模型, 可解釋性較差; 其次, 為了獲得滿意的模型容量, 深度模型包含數層神經網絡, 參數量往往十分龐大, 訓練時間長且消耗資源多. 本質上, 異常判別模型是一個二分類器, 通過對新到達的日志消息進行分析, 來推斷其屬于正常或異常.
2.2 評價標準
關于日志異常檢測的研究普遍采用分類任務中的常用評價準則, 即精確率(precision)、召回率(recall)和F1-score. 精確率表示在所有判別為異常的結果中正確判別結果所占比例, 精確率過低表示算法的誤檢率較高, 會帶來大量的系統誤警; 召回率表示在所有實際為異常的結果中正確判別結果所占比例, 召回率過低表示算法的漏檢率較高, 系統將不能識別大部分的日志異常; F1-score為精確率和召回率的調和平均數, 兼顧了精確率和召回率對算法整體檢測效果的影響, 過低的精確率或召回率都會導致F1-score性能下降. 準確率(Accuracy)表示所有判別正確的結果占總結果數的比例, 少部分文獻采用了準確率作為評價指標, 但在正常和異常樣本數據比例嚴重失衡的日志異常檢測任務中, 占比大的樣本(正常日志)對準確率的影響更大,一般不能很好反映算法的性能. 正式地, 有:

其中, TP (true positive)代表實際為真(異常日志)且判別也為正的結果數; FP (false positive)代表實際為假(正常日志)但判別為正的結果數; TN (true negative)代表實際為假且判別也為負的結果數; FN (false negative)代表實際為真但判別為負的結果數.
3 日志分析技術難點分析
3.1 技術分類及其特點
根據是否需要對特征數據打標簽來進行模型訓練,可分為有監督方法、半監督方法和無監督方法. 有監督方法利用預先打過標簽的特征數據對模型進行訓練,同時學習正常數據與異常數據的特征, 訓練完成的模型即可對測試數據進行判別(分類). 然而, 有監督方法在日志分析中的熱度不如半監督方法和無監督方法,原因有以下幾點: (1) 日志中的異常數據是相較稀少的,導致訓練數據集失衡現象嚴重, 影響模型訓練效果;(2) 為每條日志打上標簽是非常耗時耗力的, 且需要對該類日志有較深的領域認知, 才能做出正確判斷;(3) 有監督方法得到的模型只能識別已知的異常日志,對于未見過的異常無法判斷. 相比于有監督方法, 無監督方法避免了上述問題, 主要通過聚類、降維等方法尋找具有相同或相近特征的數據, 進而識別出數據異常點, 但也面臨著準確率較低、容易受噪聲影響等問題. 半監督方法介于二者之間, 通常只需要系統正常樣本即可完成訓練過程, 實現前兩者的優勢互補.
3.2 日志分析難點
指標類數據屬于單變量或者多變量的時序數據,鏈路追蹤數據屬于結構化數據, 輸出格式也相對固定且有限, 依據采用的收集工具(如谷歌的Dapper、推特的Zipkin等)即可確定. 但是, 因日志具有非結構化特點, 且沒有統一標準, 使得日志輸出格式上自由度非常大, 這就使日志分析難度更大.
3.2.1 日志的不穩定性
由于系統升級、應用更新等原因, 源代碼的日志輸出語句會持續變化, 包括添加、刪除和修改等操作,致使前期模型訓練數據當中未發生變化的內容越來越少, 進而使異常檢測模型性能急劇下降甚至失效. 舉例來說, 一款來自微軟的軟件經過數次版本迭代, 生成的日志中未發生變化的日志事件只占總數的30%左右[25].
3.2.2 易受噪聲干擾
噪聲并非日志消息自身攜帶, 而是在輸入模型處理前的各個環節引入的. 例如, 采集日志消息時由傳輸網絡不穩定、系統斷電、軟件bug等引起的日志消息整體缺失或部分缺失; 又如, 解析過程中出現的日志模板抽取不準確, 導致特征數據質量降低. 日志解析錯誤主要來自于兩種: (1) 語義理解偏差, 將參數變量解析為模板組成, 或反之. 如圖1所示, 在日志解析時將“hadoop”誤判為模板組成. (2) 詞表外詞匯(out of vocabulary)引入的解析錯誤, 由于日志不穩定性或者訓練數據劃分等問題, 測試數據中出現訓練過程中從未出現的詞匯, 致使日志解析出未知模板(事件), 影響模型性能. 文獻[28]就日志解析對模型性能的影響做了詳細的量化分析.
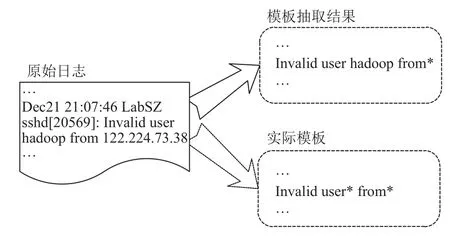
圖1 日志模板解析錯誤示例
3.2.3 計算和存儲要求高
如前文所述, 日志種類多樣且規模日益增大, 涵蓋了從底層硬件、服務中間件、數據庫和上層應用等多種來源. 海量的日志需要足夠大的存儲資源來承載數據, 和快速實時處理能力來滿足時效性要求, 并且基于深度學習的算法還需昂貴的GPU資源來訓練模型. 因此, 在做相關研究設計時, 應當考慮盡量降低算法的存儲要求, 同時可利用大數據分布式處理工具(如Spark Streaming, Storm等)來實現并行處理, 這樣有利于算法更好地應用于實際生產中. 文獻[1]提出的ADA算法通過在線訓練的方式解決了深度模型需要大量數據來訓練的問題, 進而極大減少了對于存儲空間的需求.文獻[3]提出分布式日志處理框架, 通過Spark Streaming完成日志解析、特征提取、數據歸一化等步驟, 增強了算法面對海量實時日志的分析能力. 文獻[30]針對經典日志解析算法面對海量日志解析能力不足的問題,基于Spark分布式計算框架提出了POP算法. 文獻[31]則基于GPU的并行能力改進了LKE算法.
3.2.4 算法和模型可移植性差
由于日志格式自由度大, 因此不同的系統日志呈現出的特征模式不同, 同時根據應用目的的不同, 即使同一類型日志關注的特征也可能有所差異. 現有研究多數基于有限的公開日志數據集[32]來開展算法和模型設計, 所以其可移植性差, 難以實現成果復用. 文獻[14]詳細分析了日志異常模式的復雜性, 并提出一種組合式算法LogAD來針對不同異常模式來選擇合適的算法來處理.
4 相關研究
該領域已經有大量研究工作就如何實現自動化的日志異常檢測提出了諸多算法和框架模型. 根據前述分類, 將現有成果進行簡要說明, 并在附錄中以表格形式(表A1)對比了各個算法特點.
4.1 基于傳統機器學習的方法
文獻[5]使用PCA的方法來實現對日志的離線異常檢測. 其主要步驟是在完成對整個日志文件的解析后, 構建狀態變量比率向量和消息計數向量2種特征,再應用PCA來識別出異常數據. 文獻[15]同樣構造了以會話ID為行、以日志模板為列的特征矩陣, 只是通過專家知識對語義相近的模板進行了合并, 減少了噪聲干擾. 最后, 應用SVM對日志數據是否異常進行判別. 文獻[16]針對Web日志提出二級機器學習算法實現異常檢測. 首先, 利用帶有標簽的訓練數據訓練一顆決策樹, 用來對測試數據分類, 生成正常數據集和異常數據集, 最后將正常數據分解參數后用于隱馬爾科夫模型的訓練, 提取出所有訓練數據中的正常狀態用以識別異常. 文獻[17]利用TF-IDF技術對日志模板向量化, 并使用meanshift聚類等方法為樣本打上標簽, 最后利用標簽化后的數據訓練KNN模型來進行新樣本的異常判別. 文獻[18]提出由K-prototype聚類和KNN分類組合的日志異常檢測算法, 先利用K-prototype來篩選出疑似異常對象, 再基于KNN給出最終判別結果. 文獻[19]基于字符串度量和數值度量設計了一種對日志消息進行實時在線聚類的算法, 用于檢測信息與通信網絡中的攻擊. 文獻[3]構建并基于Spark Streaming持續更新日志消息計數向量(message count vector),利用K-means聚類算法將這些向量分為正常和異常兩類.
上述算法在相應的各類數據集上取得了最高約0.99的F1-score性能表現.
4.2 基于深度學習的方法
日志數據的內在復雜模式和長距離依賴等特點,使得不少研究工作將深度學習引入日志異常檢測領域.
長短期記憶網絡 (long short-term memory, LSTM)[33]作為一種特殊的循環神經網絡, 最早應用于機器翻譯領域, 由于LSTM擅于保存序列中的長距離依賴關系,使其也適合應用于日志分析當中——捕捉日志消息中的遠距離依賴關系. DeepLog[20]作為最經典的基于深度學習的日志分析算法之一, 利用2層疊加的LSTM網絡實現了日志模板序列和參數變量的異常檢測.nLSALOG[21]同樣使用2層LSTM網絡, 并在其中引入自注意力機制, 使得模型能更好地捕獲序列內部的依賴關系, 提高異常檢測性能. LogAnomaly[22]在日志模板語義表達上做了改進, 利用dLCE自然語言處理模型通過詞嵌入技術生成模板向量, 再輸入LSTM進行模型訓練, 最終用于預測推斷. 這種方法可通過計算模板向量間的近似度將系統新產生的陌生日志模板匹配到模型已經學習到的模板向量. LogNL[23]借鑒了DeepLog和LogAnomaly的優勢, 通過2層LSTM完成日志模板和參數變量的異常判斷, 改善了有模型性能. LogMerge[24]對提取的日志模板基于詞向量加權求和后得到模板向量, 通過對2種類型日志的模板向量進行聚類操作獲取簇中心向量, 實現了跨日志類型的異常檢測. 模型方面采用了CNN+LSTM的組合. LogRobust[25]利用一個雙向LSTM捕獲來自日志模板序列前向和后向兩個方向的依賴關系, 并應用注意力機制識別出那些對判別結果更重要的日志模板. 同時, 由于也使用了日志模板的語義表達, 對于噪聲干擾有一定的魯棒性. NoTIL[34]是一種用于檢測日志消息時間間隔異常的算法, 通過滑動時間窗口對日志序列進行切分,并計數時間窗口內的每類事件生成該窗口的表示向量,輸入LSTM來預測未來的時間窗口, 并基于實際結果與預測值間的誤差判別異常. ADA[1]引入在線深度學習技術[35], 基于LSTM提出了一種自適應式的異常檢測算法, 具備在線學習能力的同時, 還能夠根據當前異常檢測結果自動調整模型層數.
門控循環單元 (gated recurrent unit, GRU)[36]是另一種重要的循環神經網絡, 基本原理和LSTM十分相似. PLELog[37]結合了有監督方法和無監督方法的優勢, 通過對日志模板向量化后進行聚類, 然后基于概率標簽估計的方法為訓練集中沒有標簽的數據打上概率化的標簽. 再以此輸入帶有注意力機制的GRU網絡中訓練.
采用LSTM或者GRU搭建日志異常檢測模型是一個較普遍的做法, 但RNN類的模型需要順序輸入數據, 致使其無法實現數據的并行化處理, 也就限制了其在大流量日志數據條件下的性能表現. 近年來, 谷歌的Transformer模型[38]因其強大的快速并行能力在自然語言處理領域獲得了廣泛應用, Transformer在處理大流量輸入數據方面的優勢使有些學者將其引入日志分析任務中. HitAnomaly 算法[29]基于分層式的Transformer結構分別將日志序列中的模板(事件)序列和參數(變量)序列轉化為兩個向量表示, 再利用注意力機制對二者加權求和, 最后通過Softmax層得到異常概率分布. NeuralLog算法[28]采用了BERT模型[39]對日志消息所有單詞進行詞嵌入, 并對日志消息中所有的詞向量求均值得到日志消息的特征向量, 最后輸入基于Transformer的模型進行訓練及預測. 值得注意的是,NeuralLog并未使用日志解析技術, 避免了日志解析錯誤給異常檢測模型結果帶來的影響.
變分自編碼器 (variational auto-encoder, VAE)[40]是深度學習領域重要的生成模型之一, 廣泛用于圖像生成任務. VAE通過編碼器將訓練數據映射為隱空間內的低維變量, 再由解碼器從隱空間中隨機采樣來生成訓練數據的重構. 基于VAE的日志異常檢測算法一般是以重構誤差來判斷異常或者直接給出異常概率.VeLog[6]以會話ID切分日志數據, 并構造日志執行計數矩陣和日志執行順序矩陣, 輸入VAE進行訓練, 以此來識別日志模板在數量和執行路徑上的異常. 該方法對于訓練集中未出現的日志模板會判斷為異常, 需將新出現的模板加入訓練集對模型重新訓練. 文獻[26]提出的hybrid CAE and VAE framework將日志模板序列進行獨熱編碼(one-hot encoding)后, 使用卷積自編碼器 (convolutional auto-encoder, CAE)將其壓縮以提取序列高層特征, 再輸入VAE進行訓練, 學習日志模板序列的正常模式.
生成對抗網絡 (generative adversarial network,GAN)[41]作為另一種重要的深度生成模型, 也有研究人員將其用于日志分析任務. 文獻[27]為解決日志數據不平衡的問題基于生成對抗機制設計了生成器和判別器, 通過二者博弈來相互提高性能, 直至收斂. 最后, 利用生成器可產生出逼近真實異常樣本的模擬數據, 進而在檢測時輸出當前日志模板序列模式下后續可能事件正常或異常的概率分布.
上述算法在相應的各類數據集上取得了最高約0.99的F1-score性能表現.
5 研究重點及方向
5.1 日志消息的語義表征
日志屬于軟件開發者對系統實時狀態的描述文本,這種特點令自然語言處理中的諸多詞嵌入技術可以應用于日志分析當中并變得越來越重要. 獨熱編碼屬于最簡單的編碼方式, DeepLog、ADA、hybrid CAE and VAE framework等都采用了這種方式, 但獨熱編碼存在維度災難和語義鴻溝(即編碼向量由于詞匯表龐大而變得非常稀疏, 且所有向量均正交, 不能體現語義相似性), 使其應用受限. 相比之下, Word2Vec、FastText[42]、Glove[43]等詞向量相關技術能更好地表現日志語義關系, 也被大量研究工作所采用, 如LogRobust、PLELog、LogMerge等, 但這幾種技術并不能很好地解決一詞多義的現象. 詞表外詞匯的出現在日志中十分普遍, 據文獻[28]研究, 某些數據集(如BGL)中即使訓練集達到80%時, 仍有超過80%的詞匯在訓練集中從未出現. 能否處理好詞表外詞匯是日志語義表征能力的重要體現. 有研究專門為日志分析提出了一種語義表征框架Log2Vec[44], 通過MIMICK算法[45]解決詞表外詞匯的向量表示, 但其字符級推算的方式難以獲得有實際意義的詞向量. NeuralLog算法采用BERT模型來表征日志語義, 不僅能夠解決一詞多義問題, 也可以在子詞級別推算詞表外詞匯的含義, 獲得相對更有意義的詞向量. 總之, 語義表征是日志分析中的重要一環, 能夠提高算法的魯棒性, 在一定程度上抵抗日志不穩定性帶來的影響.
5.2 模型在線更新機制
如前文所述, 現代軟件產品多采用Dev Ops敏捷開發模式, 產品的持續集成、持續部署加速了其迭代更新, 從而也使得日志模式持續演進, 產生不穩定性. 而日志不穩定性會導致持續出現新的日志模板和更多的詞表外詞匯. 所以在設計有關算法時, 不得不考慮模型的持續更新能力, 以適應新出現的日志模式. 過往研究中, 主要有3種方法來進行模型更新: 一是定期對模型重新訓練以適應新的日志模式; 二是基于運維人員對檢測結果的反饋, 對模型就行及時修正, 如DeepLog、VeLog等; 三是引入在線學習機制, 如ADA等. 模型定期重新訓練的方式不僅在實時性上滿足不了生產要求,也會帶來較大的計算和時間開銷(特別是深度學習模型). 應該說運維人員參與到日志異常檢測任務當中來是必要的, 特別是通過人工反饋的方式可以引入領域專家知識, 而這些是無法單純憑借算法獲得的. 但應考慮模型的在線更新機制的設計, 盡量減少重復訓練帶來的開銷. 文獻[46]提出了終身學習的日志異常檢測方法, 通過反饋結果來對模型進行更新(而不是重新訓練). 在線學習是一種重要的研究思路, 可以將數據以流的方式輸入模型進行逐步優化的動態訓練和預測,令模型更具擴展性.
5.3 算法的并行度和通用性
日志大體量和多類型的特點對檢測算法提出了并行度和通用性要求. 首先, 不論是基于傳統機器學習算法還是深度學習算法, 均需考慮算法部署于生產環境下的并行化能力, 以滿足海量日志處理的需求, 例如文獻[3]利用大數據相關技術實現日志的全流程并行處理, 使其具有實際應用能力. 同時, 在某些計算、存儲資源不充沛的條件下, 還應當盡量減少日志分析處理過程中的計算和存儲開銷, 如ADA算法通過在線深度學習減少了在空間存儲上的需求. 其次, 結合日志數據的異常模式和應用場景的多樣化, 算法設計應盡可能具有一定的通用性, 或者只需要根據數據特征或場景需求進行微調即可快速應用, 如LogAD即是一種典型的組合式方法, 其應對復雜場景下多種日志模式的異常檢測綜合能力明顯提高.
5.4 結果的可解釋性和輔助決策
為了在智能運維場景下更好地進行故障預警和輔助運維人員進行事件處理, 日志異常檢測任務不應停留在只檢測當前日志是否出現異常, 也應注重檢測結果的可解釋性. 例如, 當前異常由何種特征提示、如何以運維人員能夠看得懂的方式呈現、異常的相互關聯問題、異常可能的影響范圍如何等問題. 即在更高層次賦予檢測結果良好的可解釋性和輔助決策能力, 是該項技術的深化和延展. DeepLog、LogAD中都試圖構建任務執行的工作流, 很好地印證了填補機器算法輸出與人之間理解鴻溝的重要性. 特別地, 由于深度學習一般被認為是端到端的黑盒模型, 基于深度模型的算法可解釋性較差, 目前已經有相關研究致力于獲得檢測結果的可解釋性[47].
6 結束語
日志異常檢測任務是智能運維發展的重要落地場景, 是機器學習和運維管理結合的重要一環. 大量研究已經表明, 將機器學習應用于日志分析當中, 可以有效應對當下數據中心日志體量急速膨脹導致分析難、管理難的問題. 文章對日志異常檢測任務的典型流程、技術難點、相關研究工作和后續研究重點都做了詳細闡述和分析, 對于該領域研究具有一定的參考價值.
附錄
為了更清晰直觀地比較各個算法的技術路徑和優劣勢, 文章給出了算法對比表, 如表A1所示.

表A1 各算法對比詳情表
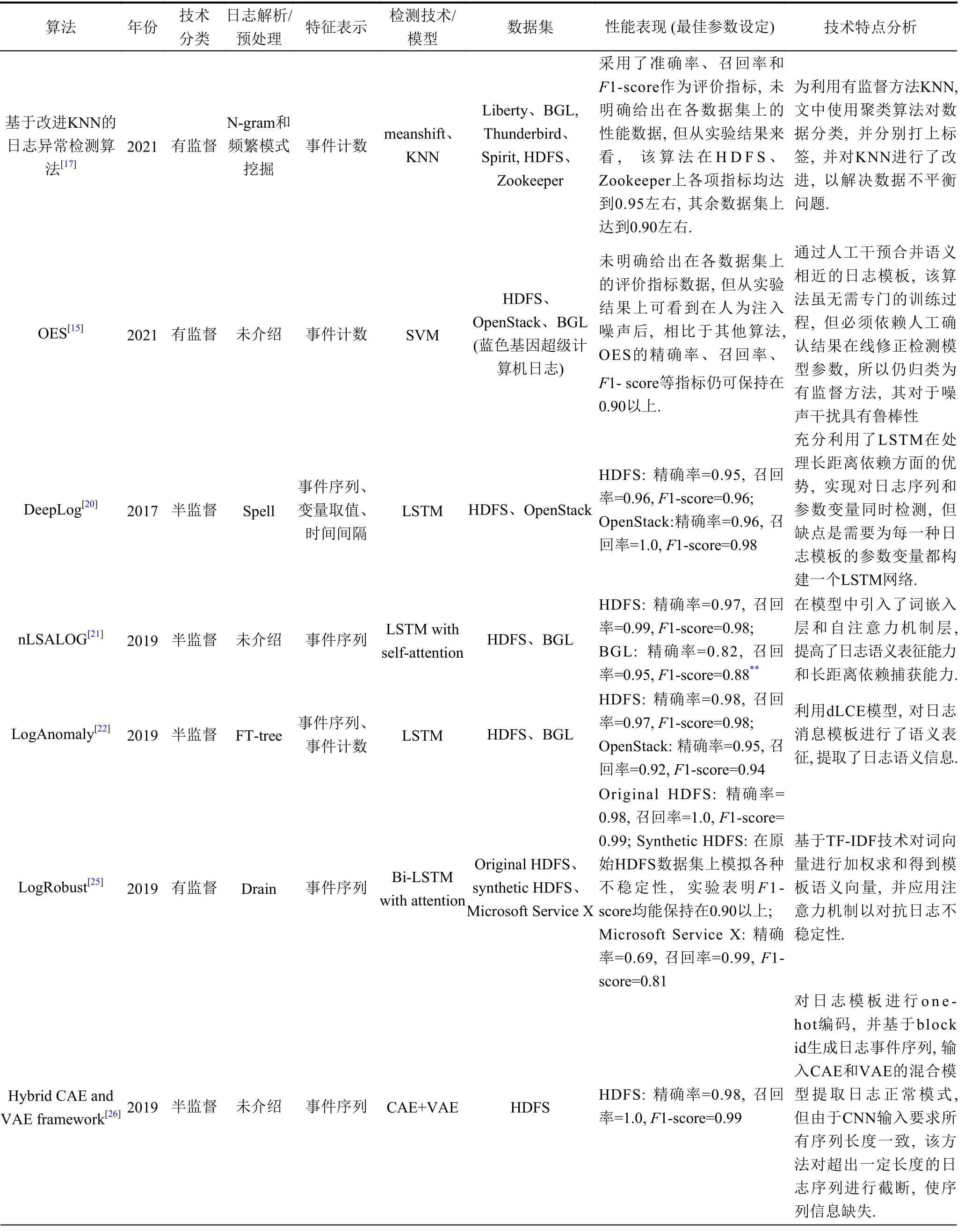
表 A1 (續) 各算法對比詳情表
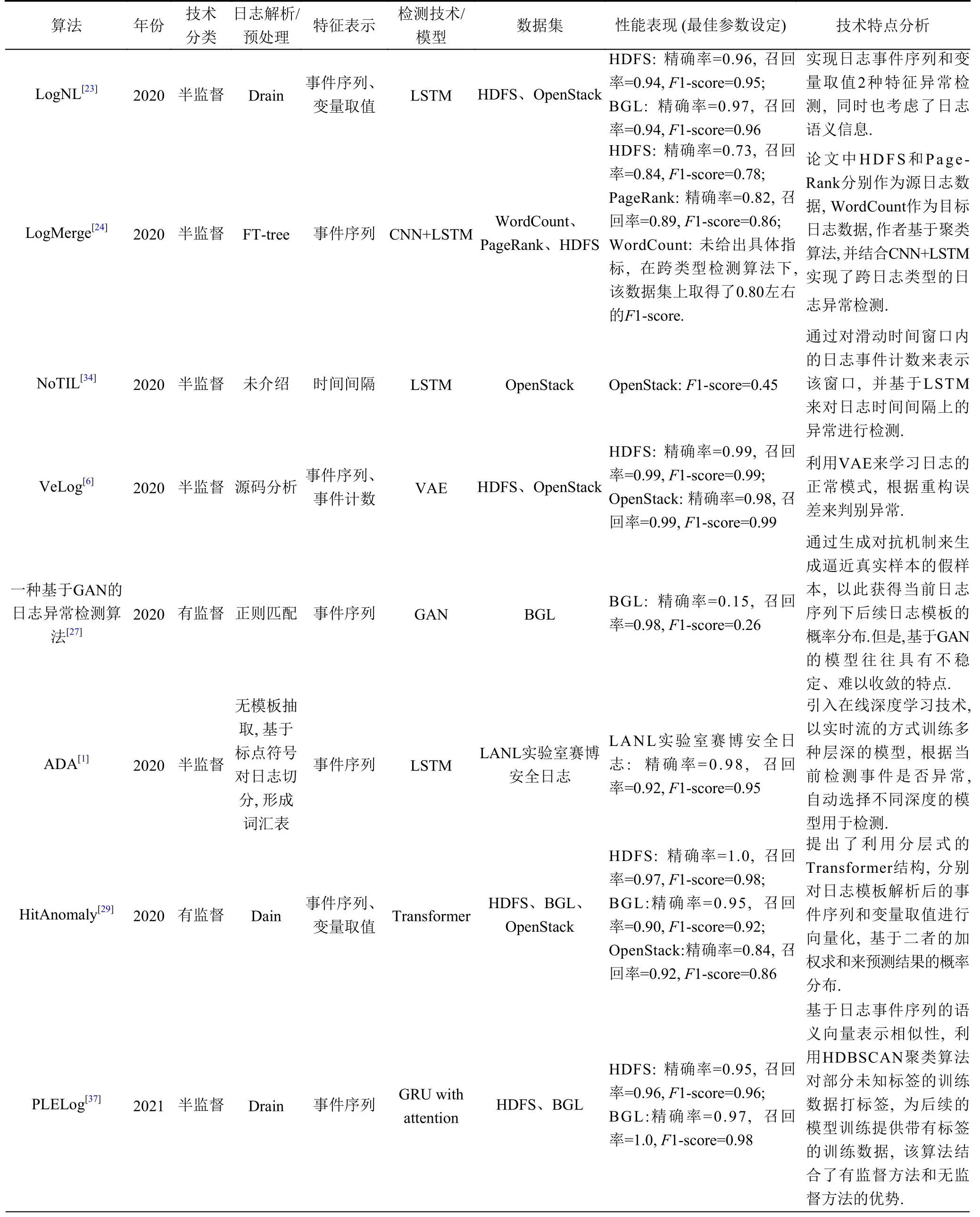
表 A1 (續) 各算法對比詳情表

表 A1 (續) 各算法對比詳情表
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
