基于拓撲結構約束和特征增強的醫學影像標志點定位算法①
2022-09-20 04:11:08張靈西
計算機系統應用 2022年9期
張靈西
(復旦大學 計算機科學技術學院, 上海 200438)
近年來, 人工智能技術的飛速發展在醫療領域受到廣泛關注. 與此同時, 隨著醫學數據集的不斷擴增、硬件計算能力的快速提升以及應用算法的突破性進展,人工智能在醫療場景中的技術積累日漸成熟, 應用范圍逐步拓寬. 2019年1月, 由上海交通大學人工智能研究院領銜發布的《人工智能醫療白皮書》[1]中指出,人工智能在醫療領域應用最廣的場景就是醫學影像分析, 該領域更是被業內人士認為是最有可能率先實現商業化的人工智能醫療領域.
醫學影像可以直觀地呈現人體內部的解剖結構與病灶信息, 通過醫學圖像便可觀察病人身體內部器官、組織的變化情況, 是醫生在臨床診斷和手術規劃時的重要輔助手段. 在臨床實踐中, 往往首先需要根據人體骨骼結構對醫學影像中的解剖標志點進行標記,再通過這些標志點和參考線計算相關的線段長度或測量角度, 進而完成疾病的診斷[2]. 由此可見, 解剖標志點定位的準確性對于臨床影像分析具有重要意義. 深度學習為利用人工智能技術進行醫學影像標志點定位開辟了新的視角: 深度神經網絡通過學習大規模的醫學影像數據, 對原始輸入圖片進行多層非線性變換, 進而實現從數據中歸納出從低級到高級的特征[3], 摒棄了傳統方法中根據領域知識手動提取特征的過程, 進而使計算機自動完成解剖標志點定位的影像分析任務.
由此可見, 標準規范的影像數據及數據標注是利用人工智能算法進行醫學影像分析發展的基礎. 然而,與自然圖像的獲取不同, 醫學影像的獲取十分艱難: 一方面, 訓練樣本的獲取需要成本高昂的專業影像采集設備; 另一方面, 影像數據的標注需要受過專門培訓的專業醫生參與, 而由于臨床、科研任務重, 醫療專家往往沒有時間進行大量的數據標注工作. 因此, 醫學影像領域本身面臨著高質量標注數據匱乏的現實. 在這種情況下, 如何利用醫學影像本身所固有的特點, 進一步提升網絡的特征提取能力, 更好地挖掘有限數據中更多的特征, 進而實現自動化提取、測量和分析影像學表型, 對于輔助醫生快速診斷疾病具有重要的理論價值和現實意義, 不僅可以有效提升醫學影像自動讀片效率、降低患者就醫成本, 還可以在一定程度上緩解地區醫療水平差距大、醫療資源分布不均等社會問題.
本文提出了一種基于拓撲結構約束和特征增強的醫學影像標志點定位算法, 使用多任務U-Net網絡[4]作為骨干網絡, 利用醫學影像上各個標志點之間形成的拓撲結構具有變換不變性這一特點, 為網絡添加額外的約束; 通過為網絡引入多分辨率注意力模塊[5], 為不同分辨率下的特征圖生成不同分辨率的注意力信息,使網絡加強對重要特征信息的關注, 以避免圖像中其他冗余特征的干擾; 此外, 受啟發于空洞空間金字塔池化結構(atrous spatial pyramid pooling, ASPP)[6], 本文通過使用多分支空洞卷積來實現增大感受野的目的, 多個分支并行操作可以同時捕獲不同尺度的上下文信息,且空洞卷積的使用也避免了參數量的增加.
本文的貢獻可總結為以下4個方面:
(1)考慮到各個解剖標志點之間的拓撲關系存在結構不變性的特點, 本文為深度神經網絡加入拓撲結構約束, 并提出結構不變性損失來增強網絡的特征提取能力.
(2)通過在網絡內部嵌入多分辨率注意力機制, 為不同分辨率的特征圖生成不同分辨率的注意力系數圖,幫助網絡提取與標志點更相關的特征.
(3)通過在低層特征和高層特征的融合階段引入多分支空洞卷積層, 在不增加網絡參數量的情況下實現增大卷積層感受野的作用范圍, 使網絡更好地感知上下文信息.
(4)本文在公開數據集上驗證了提出算法的有效性. 實驗表明, 本文算法在各個指標上超過了當前主流的解剖標志點定位算法.
1 相關工作
醫學影像解剖標志點定位是臨床診斷中非常重要的預處理步驟, 是制定醫學治療計劃的基礎環節. 在實踐中, 往往需要首先對重要的解剖標志點進行準確定位、測量, 進而才能完成如骨齡預測[7]、膝關節手術[8]、骨盆外傷手術[9]及頜面部手術[10]等醫學診療任務.
傳統的解剖標志點定位方法大致可分為兩類: 基于模型的方法和基于回歸的方法[11]. 基于模型的方法根據預定義的模板迭代地找到最佳的標志點位置, 并通過形狀模型調節全局空間形狀[12,13]; 基于回歸的方法則直接從圖像特征回歸標志點坐標[14]. 除此之外, 還有部分學者提出了基于先驗知識的邊緣檢測方法[15,16],然而此類方法只能成功檢測位于清晰邊緣的標志點,且先驗知識的引入使得算法對解剖結構變化較為敏感,降低了算法的泛化能力.
隨著人工智能技術的不斷發展, 學術界已經提出了一系列基于深度學習的醫學影像解剖標志點定位方法, 此類方法利用深度神經網絡自動地學習圖像特征并進行標志點定位, 避免了傳統方法依賴手工定義特征的弊端, 不僅提升了標志點定位的準確程度, 且減少了定義特征的人力和時間成本.
基于深度學習的解剖標志點定位算法的主要思路是輸入圖像和對應的標志點坐標, 深度神經網絡自動挖掘圖像特征并選出圖像上概率最大的像素點作為預測坐標, 通過不斷降低預測坐標和真實坐標之間的損失以不斷優化網絡參數, 進而實現標志點自動定位.Zhang等人[17]提出了一種兩階段的深度學習方法, 在第1階段利用基于回歸模型的卷積神經網絡學習局部圖像和目標解剖標志點之間的內在關聯, 在第2階段進一步建模各個局部圖像之間的關聯, 進而實現在有限的訓練數據上實時聯合檢測多個解剖標志點. Oh等人[18]提出了一個新的頭影測量標志點檢測框架, 該框架通過引入局部特征擾動器(local feature perturbator,LFP)和解剖上下文損失(anatomical context loss, AC loss), 使得卷積神經網絡在訓練期間可以學習更豐富的解剖上下文特征. Chen等人[10]提出了基于自注意力模塊的方法, 該方法可以提取語義增強的多層次融合特征, 以提升標志點定位的精度. Payer等人[19]將空間結構信息引入深度神經網絡來定位標志點, 從而利用標志點之間的結構關系預測標志點在圖片各個像素上出現的概率. 此外, 對于3D影像數據, Yang等人[8]提出可以將3D空間視為2D正交平面的組合, 使用常規卷積神經網絡處理3組獨立的2D磁共振圖像(magnetic resonance imaging, MRI)切片, 并將3D位置定義為3個2D切片的交點.
然而, 現有方法大多具有以下3個主要問題:
(1)標志點定位過程中未能挖掘醫學影像本身固有的特點. 醫學影像中的解剖結構往往相對固定, 而標志點位置通常與解剖結構密切相關. 以上方法大多利用深度神經網絡強大的非線性擬合能力, 未能針對醫學影像固有的結構特點進行優化.
(2)特征提取過程中缺乏對顯著特征的關注. 深度神經網絡提取的特征圖中不同位置的特征往往對于預測結果有著不同的重要程度, 有的特征對于預測標志點位置至關重要, 而有的特征對于預測結果作用較小,屬于冗余特征. 冗余特征的存在為實現精準的標志點定位帶來額外開銷.
(3)特征融合的過程中缺乏對上下文信息的利用.醫學影像中的器官位置及骨骼結構等信息通常有助于判斷解剖標志點的位置, 而這些信息則蘊含在更大的感受野之中. 但傳統的卷積操作只能對局部特征進行處理, 往往忽略了上下文特征所帶來的額外信息.
因此, 本文立足于醫學影像本身固有的結構特點,提出基于拓撲結構約束和特征增強的醫學影像標志點定位算法, 利用標志點之間拓撲關系的結構不變性構建額外約束, 通過多分辨率注意力機制和多分支空洞卷積結構提升網絡對精細特征的提取能力以及上下文信息的感知能力, 使得網絡可以更好地挖掘醫學影像的結構和語義, 并提取魯棒性更強的特征, 進而取得更好的標志點定位效果.
2 網絡結構與算法原理
考慮到醫學影像數據一般較少, 且圖像中的語義和結構都對預測標志點坐標具有重要意義, 所以網絡預測時不僅需要利用高層語義特征, 還需要同時考慮低層結構特征. 因此, 本文使用可以同時結合低層特征和高層特征的U-Net[20]作為主干網絡, 提出一種新的解剖標志點定位模型, 模型整體流程如圖1所示.
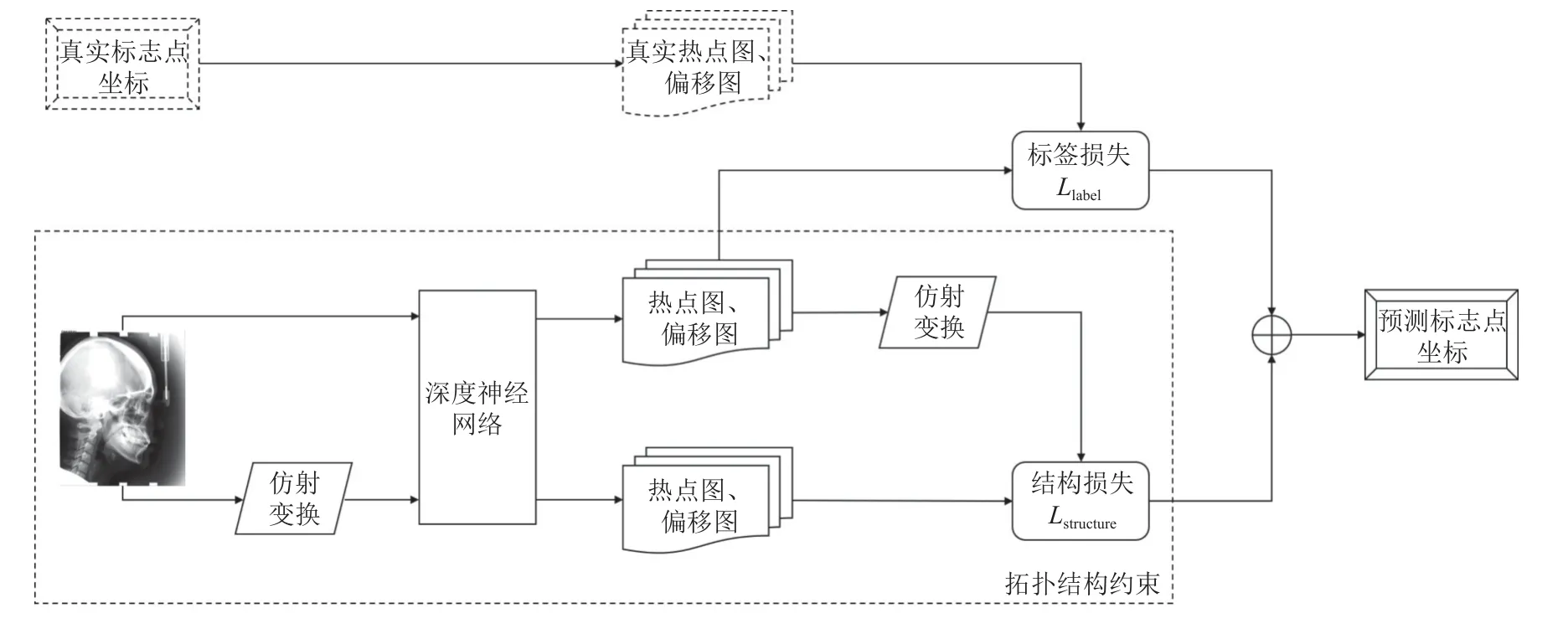
圖1 標志點定位整體流程
為避免網絡直接預測坐標具有較大的偏差, 本文使網絡同時預測熱點圖(heatmap)和偏移圖(offset map), 其中熱點圖表示標志點在圖中每個像素位置出現的概率, 偏移圖表示標志點與真實標志點之間的坐標偏移, 分為x軸和y軸兩個方向. 將輸入圖片和經仿射變換后的圖片輸入到深度神經網絡, 對于原圖使用根據真實坐標計算的熱點圖和偏移圖構建損失函數;對于仿射變換的圖片, 由于標志點之間形成的拓撲結構也將發生相同的仿射變換, 因此, 此時網絡預測的熱點圖和偏移圖, 與輸入原圖時預測的熱點圖和偏移圖之間, 可構成一種額外的結構約束, 使網絡更好地學習圖像結構, 并基于此構建結構不變性損失, 最后模型將結合兩部分損失得到標志點坐標的預測結果.
用于預測熱點圖和偏移圖的深度神經網絡結構如圖2所示. 對于輸入的醫學影像, 神經網絡提取不同分辨率的特征圖, 同時為不同分辨率的特征圖計算各個像素的重要程度, 以生成不同分辨率的注意力系數圖,實現加強對重要特征的關注, 削弱冗余特征的影響. 通過將U-Net網絡每一層級的普通的上采樣部分改為多分支空洞卷積結構, 使得網絡可以同時感知多尺度的上下文特征, 進而能夠更好地確定標志點位置. 網絡將經注意力加權后的低層特征與對應層級的高層特征進行拼接后得到新特征, 將該特征輸入解碼器經過上采樣再得到下一層級的高層特征, 通過上述方式, 網絡不僅可以加強對重要特征的關注, 還可以同時考慮不同尺度的上下文信息, 提升了網絡的特征提取能力.
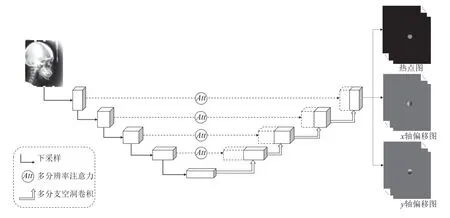
圖2 模型結構圖
2.1 多任務U-Net網絡
U-Net網絡采用編碼器-解碼器結構, 編碼器部分通過下采樣操作得到多個分辨率的低級特征圖, 解碼器部分通過上采樣操作將低級特征圖逐層上升為與編碼器相應層級相同的分辨率, 直至恢復為原圖分辨率.網絡在每一層級采用跳躍連接(skip connection)來結合同層級的高級特征圖和低級特征圖, 并使用拼接后的特征圖作為該層級的上采樣層輸入. 這種方式結合了低層特征所包含的信息, 避免直接使用最后一層特征進行損失計算, 通過利用多尺度特征有效提升網絡精度.
本文使用多任務U-Net網絡[4]同時預測熱點圖和偏移圖, 對于圖片X中坐標為( xi,yi) 的第i個標志點, 其熱點圖可由高斯函數計算, 如式(1)所示:
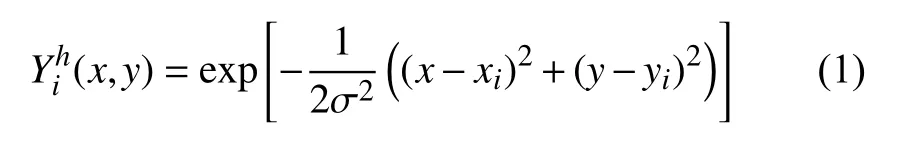
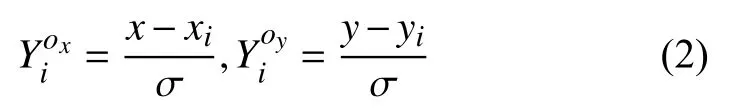
本文中使用二值交叉熵損失函數 Lh來懲罰預測熱點圖和真實熱點圖之間的差異, 使用L1損失函數 Lo來懲罰坐標偏移. 令 fh(X)表 示網絡預測的熱點圖,fo(X)表示網絡預測的坐標偏移圖, 為了使熱點圖和偏移圖所包含的信息進行有機的結合, 損失函數的構建將同時考慮熱點圖和偏移圖對預測結果的約束, 這部分的損失函數Llabel如 式(3)所示, 其中, α 為 權重系數,I(λ) 為 指示函數, 表示只考慮熱點圖值高于閾值λ 的像素.
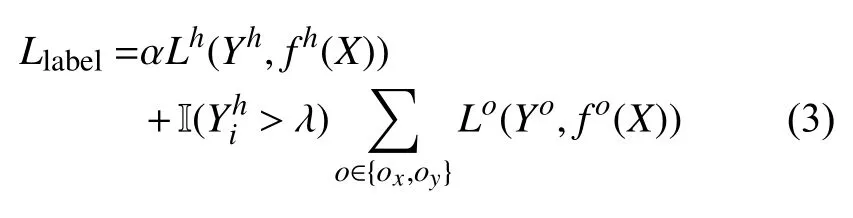
網絡輸出的熱點圖、x軸偏移圖和y軸偏移圖均為19個通道, 每個通道代表對一個標志點的預測信息.在檢測階段, 根據網絡預測的坐標偏移圖, 對所有熱點圖值高于λ 的像素點進行投票, 將第i個通道中的獲勝位置作為第i個標志點的最終預測結果.
2.2 拓撲結構約束
受啟發于等價標志點變換[21], 本文提出基于仿射變換的拓撲結構約束方法, 根據標志點之間拓撲結構的整體性質構建額外的約束, 使網絡可以學習到更魯棒的標志點特征.
給定圖像 X和仿射變換T , X′=T(X,θ)表示圖像X經仿射變換T 后的結果, θ為仿射變換參數, 此時圖像X′上的標志點坐標也將發生相同的仿射變換. 因此, 將圖像X′輸 入到深度神經網絡 f所得到的結果, 應當與原圖像X 輸入到神經網絡 f所得到的結果遵循同樣的仿射變換, 即存在 f(T(X,θ))=T(f(X,θ)), 圖3為拓撲結構約束的示意圖, 以旋轉變換為例.
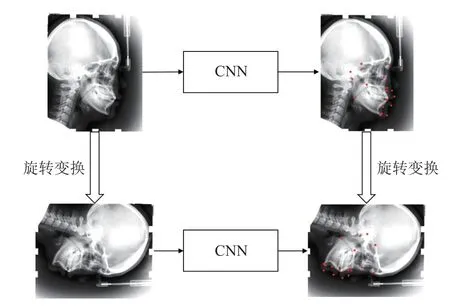
圖3 拓撲結構約束(以旋轉為例)
基于此, 利用圖像中標志點所形成的拓撲結構經過仿射變換后自相似的性質, 通過分別對比圖像變換前后網絡輸出的熱點圖以及偏移圖之間的相似程度,可以構成一種額外的約束, 使網絡能夠捕獲標志點之間所蘊含的結構信息, 進而提取魯棒性更強的特征, 本文中使用MSE損失函數來懲罰圖像變換前后網絡的預測差異來構建結構不變性損失, 如式(4)所示:
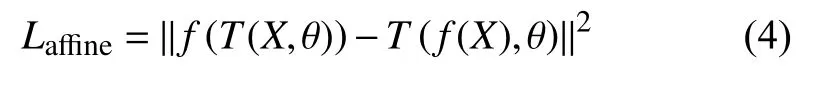
該部分也需同時考慮熱點圖和偏移圖的信息, 因此該部分的損失函數Lstructure如 式(5)所示, 其中α 為權重系數,為指示函數.
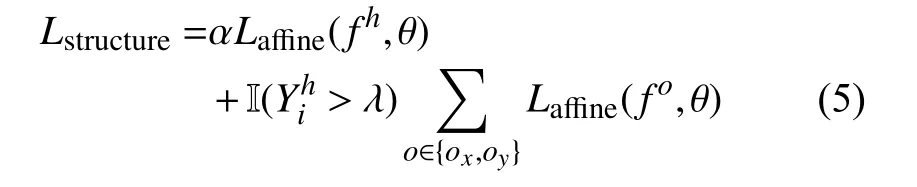
此時, 模型總的損失函數如式(6)所示:
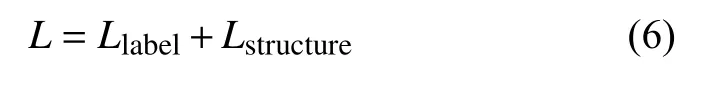
2.3 多分辨率注意力機制
U-Net網絡可以獲取不同分辨率的特征圖, 進而得到不同比例下的標志點信息, 然而原始的U-Net網絡只是簡單地把低層特征和高層特征進行拼接, 無法實現加強對圖像中重要區域的關注. 本文通過引入注意力門控(attention gate, AG)模塊[5], 使編碼器獲取的低層特征在經過注意力門控調整之后, 再與解碼器得到的高層特征進行拼接, 進而加強網絡對顯著特征的關注, 并抑制不相關的冗余特征的影響.
注意力門控模塊搭載于U-Net網絡的跳躍連接部分, 其結構如圖4所示. g為解碼器部分經上采樣得到的特征圖, x為編碼器部分經下采樣得到的特征圖. 首先分別將g 和 x 經 過1×1卷積Wg和Wx降低通道數, 再將得到的兩部分特征圖相加并通過ReLU函數進行非線性激活, 然后將激活后的特征圖經過1×1卷積ψ 轉化為單通道的特征圖, 最后對該特征圖施加Sigmoid函數得到注意力系數圖 A tt. 通過這種方式計算得到的注意力系數圖, 強調了在低層特征圖和高層特征圖中同時重要的區域. A tt的計算方式如式(7)所示.
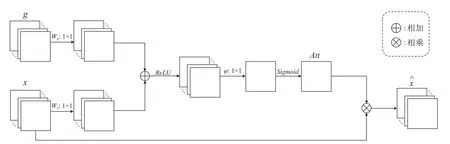
圖4 注意力門控模塊
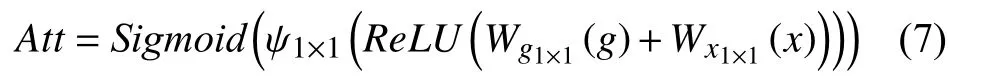
通過在不同層級的跳躍連接加入注意力模塊, 可以獲得不同分辨率下的注意力系數圖. 在訓練過程中,注意力系數圖將不斷進行更新, 從而使網絡可以逐漸修正重要特征的位置信息, 最終實現對不同分辨率特征圖中重要區域的關注, 提升模型的特征提取能力.
2.4 多分支空洞卷積結構
在對醫學影像進行解剖標志點定位時, 通常需要考慮器官位置及骨骼結構等額外信息, 故而需要增大網絡的感受野以使模型能夠捕獲更多的上下文特征.網絡的感受野大小由卷積核的大小所決定, 而更大的卷積核在帶來更大感受野的同時也引入了更多的參數.空洞卷積[6]通過在卷積核中插入權值為0的空洞實現在不增加模型參數量的情況下增大網絡感受野, 卷積核各值之間的間距稱為擴張率, 對于擴張率為r, 卷積核大小為 k ×k的空洞卷積, 其感受野的計算方式如式(8)所示. 圖5為擴張率為2, 卷積核大小為3×3的空洞卷積示意圖.
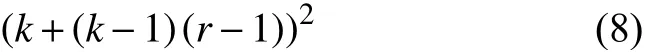
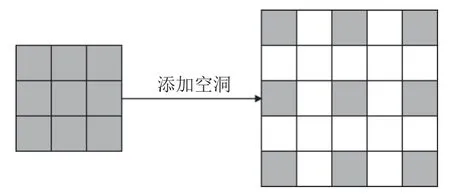
圖5 空洞卷積示例
本模塊旨在利用多尺度感受野以獲得更豐富的特征信息, 達到提升標志點定位精度的目的. 受啟發于語義分割任務中常用的ASPP結構[6], 本文提出一種適用于醫學影像標志點定位的多分支空洞卷積結構, 并將其應用于模型的解碼器部分. 每個分支使用不同擴張率的空洞卷積層, 不同的分支提取不同尺度的上下文信息, 使解碼器在融合低層特征與高層特征的過程中,可以在更大程度上捕獲像素特征之間的相關性, 進而更好地恢復圖像的空間位置等信息.
定義多分支空洞卷積結構的參數為( k,R), 其中k 表示卷積核大小, R表示各個分支擴張率的組合, 即R=(r1,r2,···,rn) , 其中, r1,r2,···,rn分別表示n 個分支上的n種不同的擴張率, 該部分結構如圖6所示.
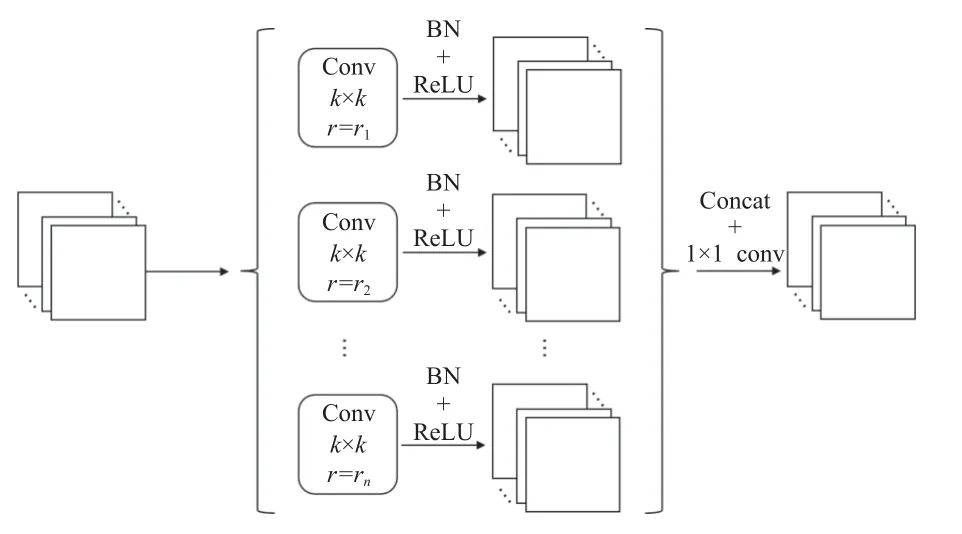
圖6 多分支空洞卷積
將不同擴張率的空洞卷積提取的不同尺度的特征圖分別經過批歸一化和ReLU激活層后進行通道拼接,再使用1×1卷積將拼接后的新特征降低通道數, 輸入接下來的上采樣層. 通過這種方式, 不僅解決了特征融合的過程中缺乏對上下文信息的利用這一問題, 并且在不增加參數量和計算量的基礎上使網絡可以更好地關注多尺度特征, 進而提升網絡預測標志點的準確性.
3 實驗及分析
本文基于公開數據集進行實驗, 首先探究損失函數中權重系數α 對模型性能的影響; 隨后探究多分支空洞卷積結構的不同擴張率組合對模型性能的影響; 接著將本文算法與目前公開發表的論文中先進的算法進行對比, 實驗結果表明本文提出的算法在各個指標上取得了更好的效果; 最后對網絡的不同模塊進行消融實驗, 以驗證拓撲結構約束、多分辨率注意力機制和多分支空洞卷積結構對于提升模型性能的有效性; 最后對本文算法的定位效果進行結果展示.
3.1 數據集介紹
X光頭影測量分析可用于正頜外科的輔助診斷,以弄清畸形的特征, 并進一步進行治療設計及療效預測. 本文使用IEEE ISBI 2015 Challenge提供的頭影測量標志點定位公開數據集[22]進行實驗, 該數據集收集了400位病人的400幅頭影測量X光圖片, 并分為150張訓練集和250張測試集. 數據集中每幅圖片的像素大小為1935×2400, 每個像素大小為0.1×0.1 mm2, 包含19個頭顱解剖標志點的標記信息, 每個標志點由兩名醫生進行手動標記和檢查. 數據集中的原始頭影測量X光片及其上標注的19個標志點如圖7所示,19個標志點的詳細信息如表1所示.
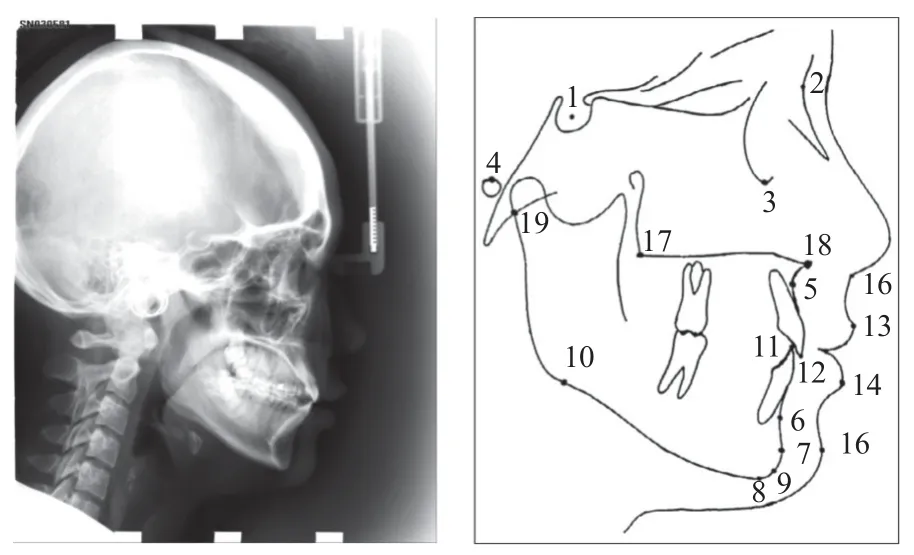
圖7 頭影測量X光片及19個標志點
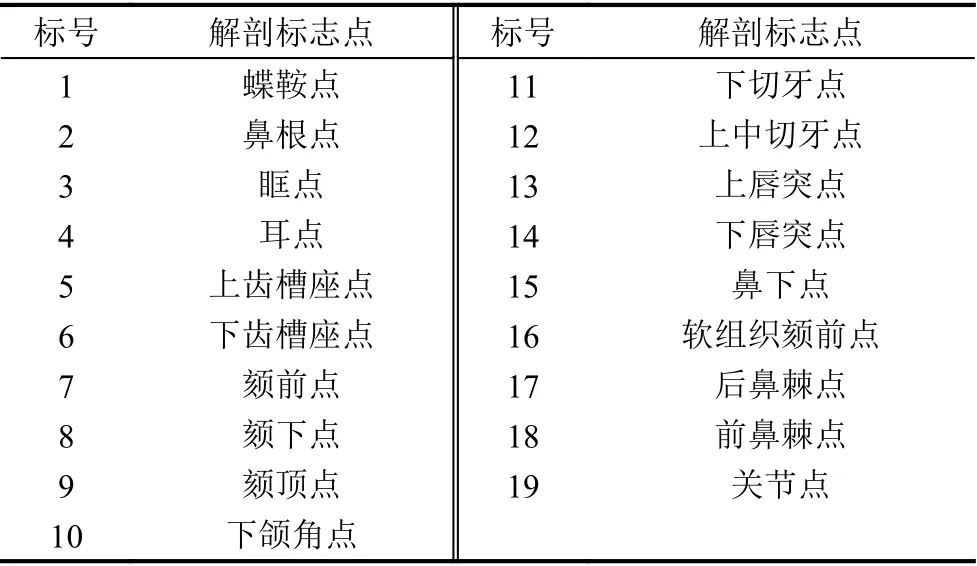
表1 19個解剖標志點詳細信息
3.2 實驗設置
本文實驗中網絡的編碼器部分使用ImageNet[23]上預訓練的VGG-19網絡[24]. 由于本文使用的數據集中圖片分辨率較高, 因此將圖片縮放至800×640大小,并歸一化至[-1, 1]區間. 模型在4個NVIDIA GeForce RTX 2080 Ti GPU上進行訓練, 批大小設置為4, 初始學習率設置為0.001, 每150次迭代乘以0.1減小學習率, 權值衰減系數設置為0.000 1, 共迭代300次, 閾值λ參考Yao等人[4]設置為0.6. 拓撲結構約束部分每張圖片僅發生一種仿射變換, 每種變換以均等概率發生,其具體參數如表2所示, 變換示例如圖8所示, 從左至右分別為旋轉變換、放縮變換、平移變換、翻轉變換.

表2 仿射變換參數
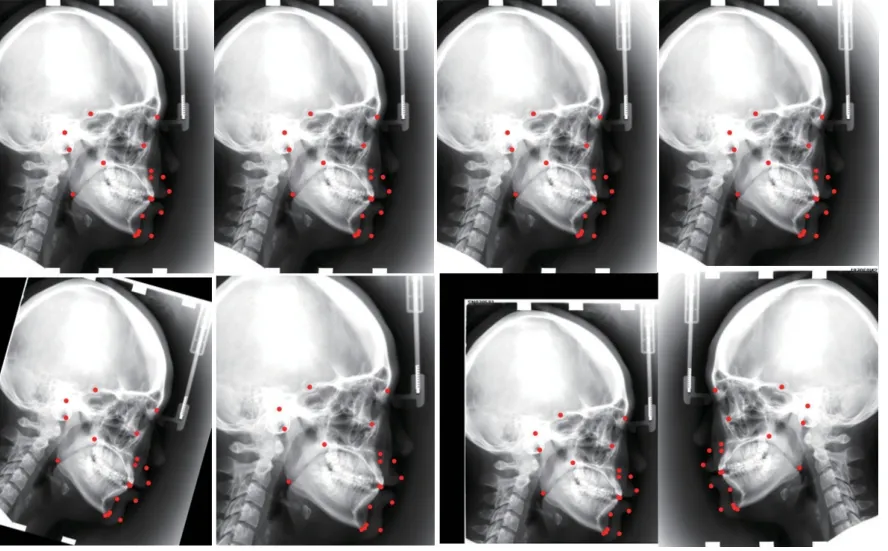
圖8 仿射變換示例
3.3 評價指標
本文中采用IEEE ISBI 2015 Challenge提供的平均徑向誤差和成功檢測率作為評價指標, 以評估算法效果.歐氏距離, 計算方式如式(9)所示, 其中表示第i 張圖上第l 個預測標志點和真實標志點在x軸上的絕對誤差,表示在y軸上的絕對誤差, n 為圖片張數. 該指標
(1)平均徑向誤差(mean radial error, MRE): 用于衡量算法所獲取的標志點位置與真實標志點位置之間的取值越低, 表明算法預測的標志點位置越準確.
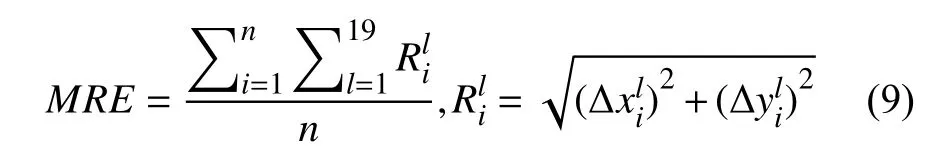
(2)成功檢測率(successful detection rate, SDR): 用于衡量算法檢測標志點的精確度, 計算方式如式(10)所示, 其含義為如果預測的標志點和真實標志點之間歐氏距離不大于z mm, 則此標志點的檢測將被視為精確檢測, 否則被視為錯誤檢測. 該指標越高表示算法的成功檢測率越高. 為方便同主流方法進行對比, 本實驗中使用與其他主流方法中相同的誤差范圍z, 即2 mm、2.5 mm、3.0 mm、4.0 mm.

3.4 損失函數權重系數實驗
本部分實驗用于探究損失監督學習與自監督學習的損失函數中權重系數α 的不同取值對實驗結果的影響. α代表了熱點圖損失和偏移圖損失之間的權重比例, 當α 取值越高時, 表明熱點圖損失所占權重越高. 實驗結果如表3所示, 表中加粗數字表示最優結果.
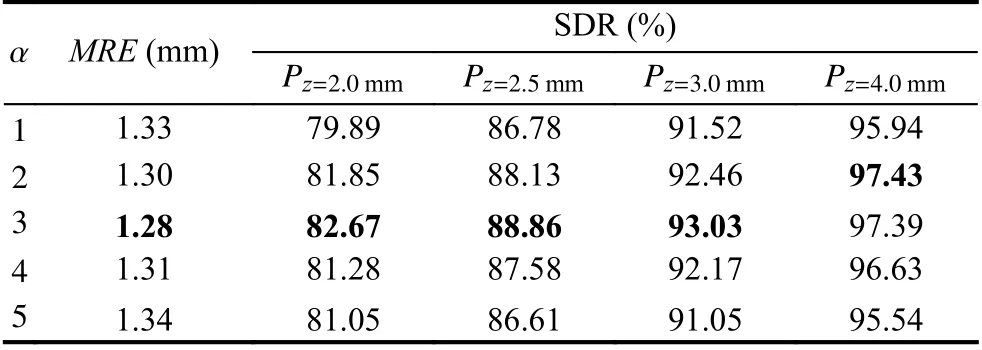
表3 損失函數權重系數實驗結果
實驗結果表明, α取值為3時模型效果最好. 當α<3時, 模型性能大體上隨著α 的增加而上升, 原因在于代表概率的熱點圖包含了比偏移圖更重要的信息, 因此提升其權重有助于模型性能的提高; 當α >3時, 模型性能反而隨著α 的增加而下降, 原因在于熱點圖權重過高時, 其所包含的誤差信息權重也隨之增加, 削弱了偏移圖所包含的正確信息的作用.
3.5 多分支空洞卷積參數實驗
本部分實驗用于探究多分支空洞卷積模塊的不同擴張率組合對實驗結果的影響, 其中空洞卷積的卷積核大小設置為3, 即參數 k =3, 參數R 選取不同的取值組合. 實驗結果如表4所示, 表中加粗數字表示最優結果.
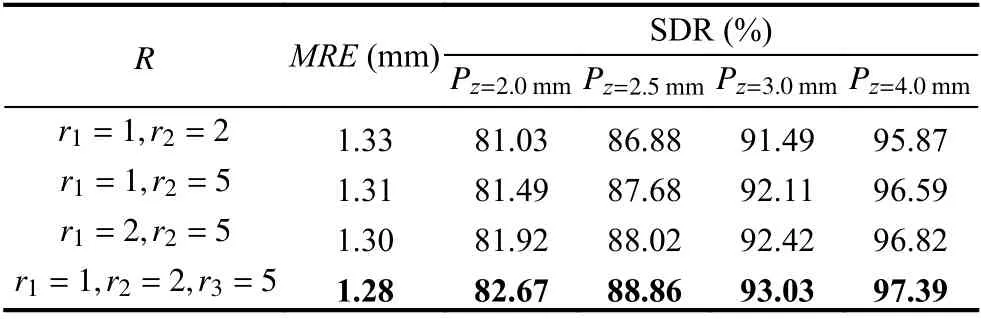
表4 多分支空洞卷積參數實驗結果
從實驗結果可以看出, 較大的擴張率對于模型性能有一定的提升作用, 其原因在于較大的擴張率可以更好地擴大模型的感受野, 使模型可以更多地感知上下文特征, 避免了普通卷積核僅使用局部特征帶來的局限性. 當參數 R 的取值為R =(r1=1,r2=2,r3=5)時,模型效果最優, 此時3個分支的感受野大小分別為3×3, 5×5, 11×11.
3.6 對比實驗
在頭影測量標志點定位的公開數據集上, 將本文所提出的算法與當前主流算法進行對比, 實驗結果如表5所示, 表中加粗數字表示最優結果.
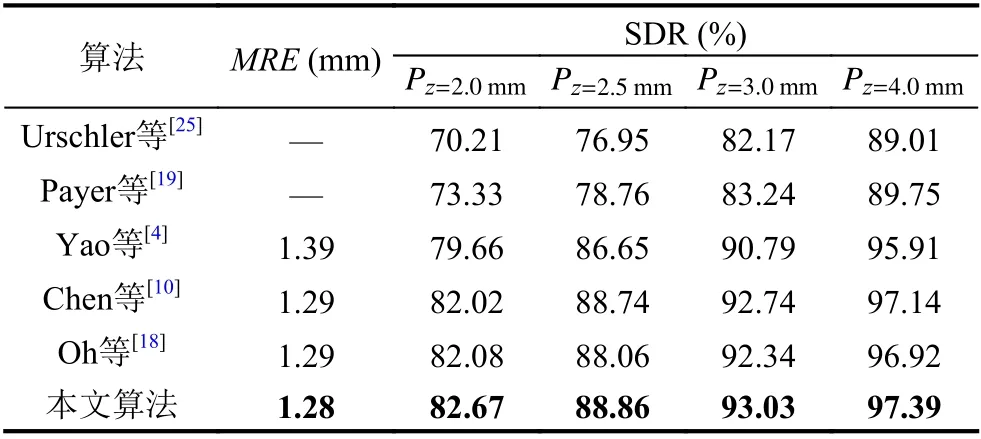
表5 不同算法對比實驗結果
從實驗結果可以看出, 本文提出的模型效果在各個指標上均超過了當前主流算法, 這得益于模型在加入拓撲結構約束后, 能夠更好地學習到醫學影像中蘊含的解剖結構信息, 且多分辨率注意力機制和多分支空洞卷積的使用也使得模型可以更有效地提取圖像特征, 從而提升標志點定位的準確程度.
3.7 消融實驗
本部分實驗用于探究模型中各個模塊對結果的作用, 以探究拓撲結構約束、多分辨率注意力機制和多分支空洞卷積對標志點自動定位效果的影響, 實驗結果如表6所示, 表中加粗數字表示最優結果.

表6 消融實驗結果
從實驗結果可以看出, 加入拓撲結構約束后, 模型效果優于未使用拓撲結構約束的效果, 這表明拓撲結構約束對于模型性能有提升作用, 且SDR指標的提高表明拓撲結構約束也提升了模型的魯棒性; 加入多分辨率注意力機制后, 模型在各個指標上的表現均有提高, 這表明該機制有效增強了對圖像中重要特征的關注, 并提升了模型預測的準確率; 引入多分支空洞卷積之后, 模型的性能進一步提高, 說明不同尺度的上下文信息有助于模型預測標志點位置. 消融實驗結果驗證了拓撲結構約束、多分辨率注意力機制和多分支空洞卷積對提升模型性能的有效性.
3.8 結果展示
19個解剖標志點各自的MRE如圖9所示, 從圖中可以看出, 所有點的MRE均在2.5 mm以內, 17個點的MRE達到2.0 mm以內, 且1、7、8、9、12、15號標志點的MRE可以達到1.0 mm以內, 由此可見本文算法具有較高的定位精度, 而如4、16號標志點的MRE較高, 這可能是由于不同人的個體差異導致這兩個標志點在不同人的影像上位置有一定偏差, 對這些標志點進行有針對性的優化也是未來的改進方向之一.
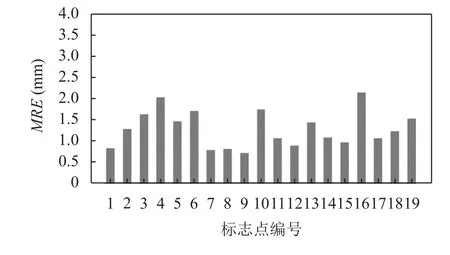
圖9 19個解剖標志點的MRE
圖10為部分測試集圖片的解剖標志點定位效果展示, 第1排為原始圖像, 第2排為真實標志點與預測標志點之間的誤差對比圖像, 其中藍色為真實標志點, 綠色為預測標志點.
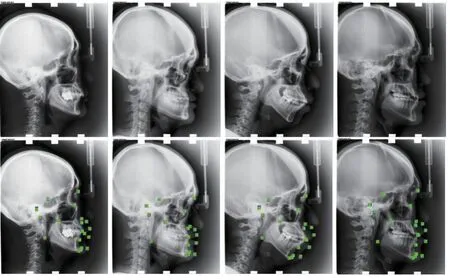
圖10 解剖標志點定位效果展示(真實標志點: 藍; 預測標志點: 綠)
由圖10可見, 雖然不同影像中顱骨的形態有所不同, 但本文算法依然可以在較低的誤差范圍內定位標志點位置, 由此可見本文算法在醫學影像解剖標志點定位任務上的優越性能.
4 總結
醫學影像標志點定位的準確性對于臨床診療具有重要意義. 本文針對醫學影像標志點定位任務當前所面臨的問題, 提出了一種基于拓撲結構約束和特征增強的標志點定位算法, 根據標志點所形成的拓撲結構具有結構不變性的特點, 為網絡添加額外約束, 使網絡提取更魯棒的特征, 以實現網絡對解剖結構信息的利用; 多分辨率注意力機制的引入使模型更加關注重要的圖像區域, 網絡自動學習注意力系數圖并為不同的空間特征分配不同的權重, 以提升模型的特征提取能力; 多分支空洞卷積結構在不增加模型參數量和計算量的情況下增大網絡的感受野, 實現對不同尺度上下文信息的融合利用, 進一步提升了模型性能. 基于公開數據集的實驗表明, 本文提出的算法獲得了較高的識別精度, 為目前公開發表的論文中性能較優的水平, 具有定位效果好、魯棒性強的特點. 未來在獲得更多類型的醫學影像數據后, 將在更廣泛的數據集上驗證本文算法的有效性.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
哲學評論(2021年2期)2021-08-22 01:53:34
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中華詩詞(2019年7期)2019-11-25 01:43:04
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
光學精密工程(2016年6期)2016-11-07 09:07:19
