基于Spark的配電網數據挖掘及處理研究
2022-09-21 10:51:18呂穎利李志強
通信電源技術 2022年10期
呂穎利,李志強
(濟源職業技術學院,河南 濟源 459000)
0 引 言
配電網的線路故障分析、設備靈敏性計算、無功補償、潮流計算、網絡架構升級以及負荷線損預測等課題的探究都離不開電網負荷和線路拓撲等數據。配電網儲存的線路拓撲數據大多為半結構和非結構化,具有波動頻率太高、數據容易丟失、無序等缺點,這些都將直接或間接地對配電網負荷預測、無功補償等技術的研究造成負面影響。同時,由于配電網數據需要消耗大量的計算時間和空間來完成格式轉化、清洗篩選以及數據異常辨別等操作,因此需要從長遠出發,考慮大數據技術的運用與計算效率的提升,幫助配電網大數據釋放能量。本文以配電網非標數據為切入點展開研究,通過結合Spark等大數據技術完成了非標準數據的公用信息模型(Common Information Model,CIM)/可擴展標記語言(Extensible Markup Language,XML)統一格式轉換。該方法依據彈性數據集的分布情況將彈性分布式數據集(Resilient Distributed Datasets,RDD)當成數據載體,同時和傳統的MapReduce數據挖掘處理方式進行對比,極大地縮短了數據并行處理的時間。
1 CIM/SVG數據格式
CIM是一種關于如何描述電力行業設備數據及應用數據信息的國際化行業標準。在CIM中,CIM/XML作為一種國際化標準語言,旨在構建規范化的電力拓撲模型。可縮放矢量圖形(Scalable Vector Graphics,SVG)是一種用于對圖形界面進行設計和優化的標準語言,由萬維網聯盟(World Wide Web Consortium,W3C)研制開發。
如今,CIM模型與SVG語言已經在電網的生產精益化管理系統等系統中得到運用,電網的運維人員可以根據實時電網拓撲圖監測設備的運行狀態,從而迅速開展故障消缺等工作。可是當需要進行配電網的線路故障分析、設備靈敏性計算、無功補償、潮流計算、網絡架構升級以及負荷線損預測等研究工作時,由于在系統數據庫下載的CIM、SVG等數據具有非標準化、非結構化的特征,因此不能采用[1]。傳統的CIM/XML和SVG大都用文件對象模式(Document Object Mode,DOM)和XML的簡單應用程序接口(Simple API for XML,SAX)等進行分析,得出電網拓撲數據的關聯,但同時具有效率低下、面對重大損失無法挽救線路拓撲和平臺相關應用、無法結構化拓撲數據等缺點。
針對以上缺點,本文采用Spark中的內存分布式計算引擎、分布式圖形計算以及分布式數據分析等庫,對來自于配電網系統的CIM、SVG等數據進行提煉聚合,從而獲取到線路拓撲與地理位置的有效信息。同時,結合提煉的信息建立基于有向線性序列的配電網數據表,并對拓撲圖中供電區域進行逐一劃分,給無功補償、潮流計算等研究奠定了基礎。
2 地理位置與線路拓撲信息的提取
實際上,電網中的CIM模型和SVG語言能夠實現數據規范化,主要歸功于它們是包含統一標準字符數組的數據文件。本文根據規則表達式的模式,分析和提煉出CIM/XML、SVG中有效拓撲數據信息。
2.1 規則表達式
1951年,美國科學家Stephen Kleene首次闡述了規則表達式的概念。規則表達式亦可稱為正則表達式,它是一種特殊工具,用于字符串數據的相關操作,實質上是一種關聯規則,用來對字符串進行匹配。規則表達式具有很多優點,如便捷性,可以用于提取、調換及搜索各類繁雜的字符串,同時還具有效率高、錯漏率低等優點,可以滿足Web的提取功能、辨別功能、抽取功能以及自動查看功能等要求[2]。
2.2 地理位置信息提取
SVG擁有相關幾何和地理數據用于配電線路拓撲存儲。本文通過提取SVG中各類型設備的地理位置坐標來完成配電網網絡架構的優化以及數據信息提取速度的提高。配電網中的設備由點型、線型以及復合直線型構成,點型設備的位置坐標由一個橫坐標值和一個縱坐標值確定,而線型和復合直線型設備的位置坐標分別由兩個橫坐標和縱坐標組成。
在進行規則匹配時,需要采用不同的規則表達式來匹配不同類型的設備位置坐標。對配電網中SVG數據通過規則表達式匹配后得到電網設備的具體地理位置坐標信息。
2.3 線路拓撲信息提取
通過CIM/XML語言中的端點對象來描述配電網線路拓撲數據間的聯系,電網設備可以依據端點的個數進行分類,主要包括單端點與雙端點兩種設備類型。匯流母線、營銷電表等設備僅有一個端點,因此屬于單端點設備,而隔離開關、電纜等設備有兩個端點,屬于雙端點設備。結合CIM/XML語言對配電網線路拓撲關聯度進行研究和分析,大致流程如圖1所示。
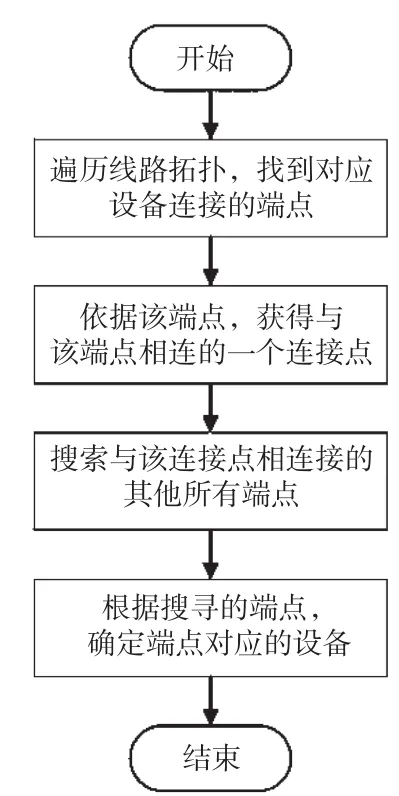
圖1 基于CIM/XML線路拓撲關聯度分析流程
配電網的線路故障分析、設備靈敏性計算、無功補償、潮流計算、網絡架構升級以及負荷線損預測等探究還要用到線路拓撲中設備的電壓級別和開關狀態等參數信息。由上述對設備具體參數的CIM/XML描述,可以通過設計規則表達式用于匹配與設備ID相關聯的電壓級別與開關狀態[3]。
3 拓撲中結構化數據構建
3.1 拓撲設備的規約轉換
通過建立規則表達式匹配獲取設備的聯絡端點號、關聯電壓級別以及關聯開關狀態等信息,并以設備ID號為關聯字段將這些數據信息篩選合并輸出,完成線路拓撲所需數據的初始化工作。但是線路拓撲中設備種類繁雜,若直接將初始化的數據拿來使用,則會消耗大量時間,效率不高,因此本文設計了如下規則用以拓撲設備的規約轉換操作。
(1)將雙端點設備(隔離刀閘、電力電纜、絕緣導線等)由初始化的點型規約轉換成線型設備,具體操作是在設備坐標同位置下復制生成一個新的坐標點。(2)將單端點設備(匯流母線、營銷電表等)由初始化的線型/復合直線型規約轉換成點型設備,具體操作是折中法,即拿設備線段中間位置的坐標替代。(3)將不影響拓撲構建和潮流計算的設備(電流互感器、避雷針等)直接刪除。
拓撲設備的規約轉換如表1所示,規約轉換后的拓撲設備信息如表2所示,描述了拓撲設備的規約轉換過程。
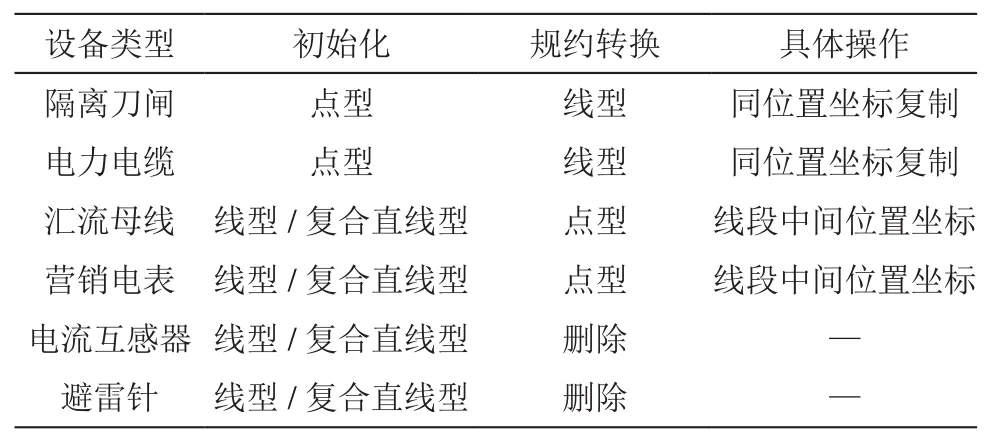
表1 拓撲設備的規約轉換
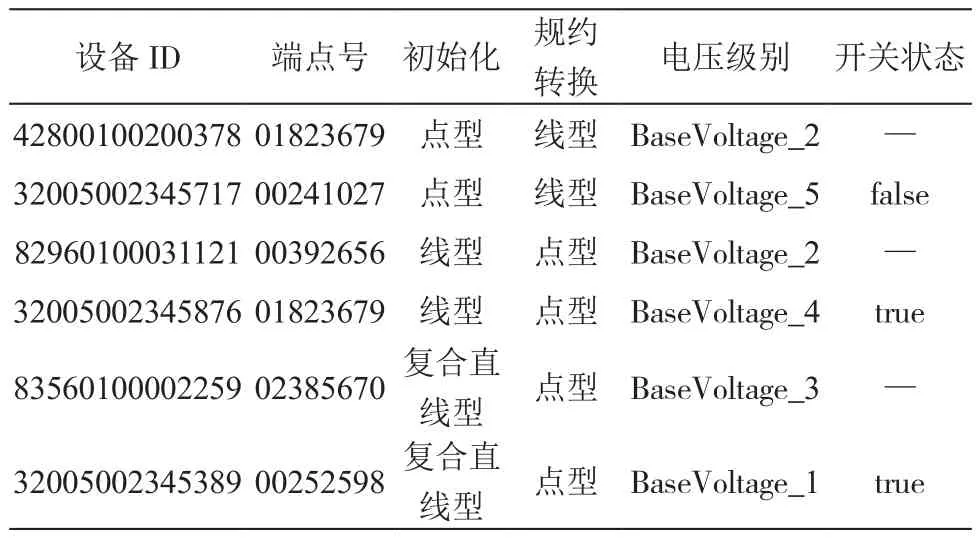
表2 規約轉換后的拓撲設備信息
3.2 配電網線路拓撲數據聯絡架構
上文完成了拓撲設備的規約轉換,以此為基石,本文將設備對應端點作為關鍵字段,實現端點關聯設備參數、不同種類設備規模以及端點定位的有效存儲,完成配電網線路拓撲數據聯絡架構的構建[4]。配電網線路拓撲數據聯絡架構如圖2所示。
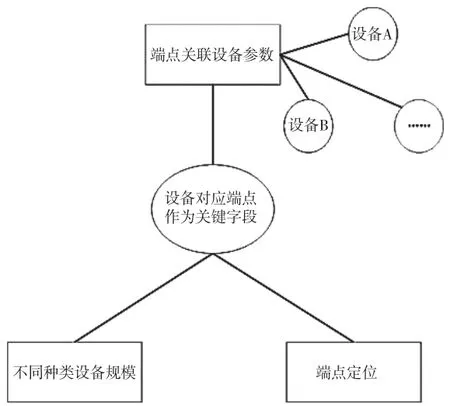
圖2 配電網線路拓撲數據聯絡架構
由于配電網的線路故障分析、設備靈敏性計算、無功補償、潮流計算、網絡架構升級以及負荷線損預測等探究需要使用到配電網線路拓撲數據聯絡架構中的數據,繼續以設備對應端點為關鍵字段,結合配電網線路拓撲數據聯絡架構中的數據建立端點坐標匹配表及線路拓撲數據匹配表[5]。
3.3 供電區域劃分及線路歸并
由于線路拓撲數據匹配表中的數據量巨大,不能直接用于線路故障分析、負荷線損預測等研究,本文根據拓撲的分布特征劃分供電區域,進而建立有向的線路拓撲數據匹配表。將各類變電站中的匯流母線視為開始節點,把與匯流母線相連的配電房、環網柜等節點當成結束節點。首先遍歷所有的開始節點,其次通過深度優先遍歷生成拓撲路徑,從而獲得有向線型線路拓撲。
每個配電網的供電區域都包含著很多不同的線路,而這些線路也許不通過變壓器、絕緣子等電力設備與其他線路直接相連接,這就需要縮小拓撲規模范圍,其方法是將線路進行簡化、整合,操作步驟如下。若原始線路中存在node1、node2、node3,而node1與node2、node2與node3分別通過類型相似的line1和line2相連,那么可以刪除node2,直接將line1與line2的電阻、容抗等參數疊加整合輸出成line3,通過line3直接連接node1和node2。線路進行簡化、整合后,線路拓撲的數據數量得到有效縮減。
4 基于Spark的拓撲數據分析
前文對采集的配電網原始數據進行整合、簡化和匹配等操作,最終獲得具有統一標準格式的線路拓撲數據,但由于各個環節數據挖掘和處理的時間與空間復雜度不一致,同時后續無功補償、潮流計算等研究需要高效率的拓撲數據分析,于是本文結合Spark中的內存分布式計算引擎、分布式圖形計算以及分布式數據分析完成線路拓撲中非標數據格式的標準轉化,實現過程如下。
(1)線路拓撲的CIM模型及SVG語言格式的數據實際上是由很多有規律性的字符數組構成的XML格式文本。基于Spark拓撲數據分析的關鍵一步便是把初始數據轉化成RDD格式的抽象數據集,而后在node的內存里進行數據存儲。圖3是線路拓撲的RDD存儲模式。
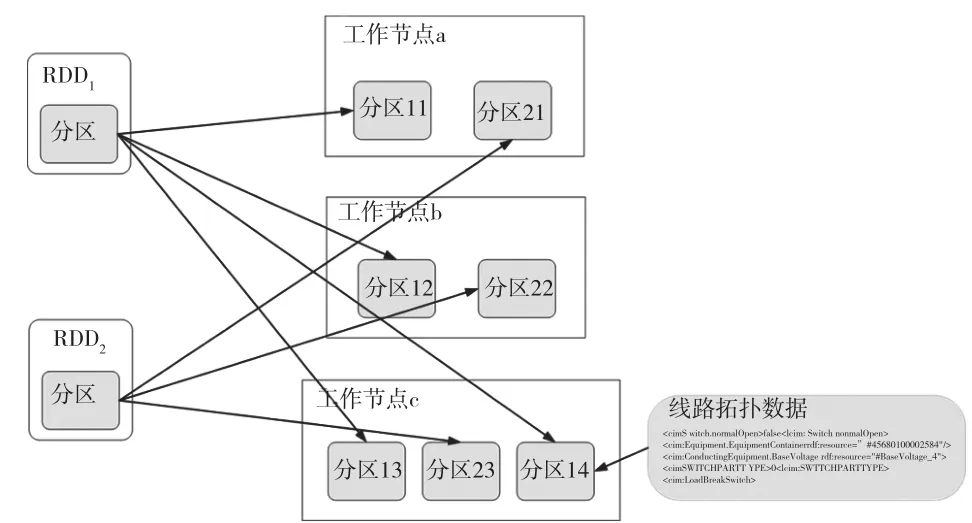
圖3 線路拓撲的RDD存儲模式
圖3中,線路拓撲數據是按分區劃分并在工作節點中實現存儲。RDD1和RDD2的數據都是在工作節點a、工作節點b以及工作節點c上完成存儲,而RDD1由分區11、分區12、分區13以及分區14組成,RDD2由分區21、分區22和分區23組成。
(2)使用Hive中的用戶定義表生成函數,將RDD形式存儲的線路拓撲數據轉換成能被系統直接掃描并使用的數據,極大地縮短了獲取線路拓撲數據信息的時間。本文以B供電公司的配電網數據為例,大約120種配電設備的總數量接近35萬,通過以上方式提取線路拓撲數據信息,總計得到384 426條地理位置數據、756 597條設備ID關聯端點號數據、304 541條電壓級別數據以及70 343條開關狀態數據。
(3)以設備對應端點為關鍵字段,結合配電網線路拓撲數據聯絡架構中的數據建立端點坐標匹配表及線路拓撲數據匹配表,表中包含215 643條端點坐標匹配數據和214 582條線路拓撲數據匹配數據。根據拓撲數據node與line的地理位置信息,繪制出B供電公司a區域的配電網線路拓撲結構圖。
(4)由于經常出現很多條線路直接連接在一起的現象,因此在對線路歸并整合時應該重復對提取的數據進行計算。就拓撲線路簡化、整合流程圖來說,使用并發編程框架將line1、line2和node1、node2、node3的數據轉換成RDD格式,同時使用分布式圖形計算模型將上述line和node轉換成線與點,同時在內存中歸并整合后存儲數據。Spark技術的最大優點就在于它不需通過磁盤而直接在內存中讀寫,這有利于減少配電網拓撲數據處理的時間開銷,從而提高運行效率。
5 基于粒子群優化算法的配電網數據挖掘分析
集成和處理后的配電網數據由于量大不免會存在一些離群數據文本,本文采用粒子群優化算法對配電網拓撲數據中的負荷聚類中心進行優化,并用K-means方法確定最佳聚類數。為了驗證粒子群算法的可行性,對B供電公司3個區域的配電網饋線運行數據進行了仿真測試,包括配電變壓器容量、配電變壓器月平均負荷數據和配電變壓器月最大負荷數據。根據不同的時間和區域進行混合、剔除處理,共有940個數據。
分別對樣本的相關饋線數據進行歸一化計算后,確定初始最優K值。根據粒子群算法對數據進行排序時,參考相關文獻的參數設置,當聚類數K=3時,最大迭代次數設置為200。粒子群優化算法后的排序效果如圖4所示。
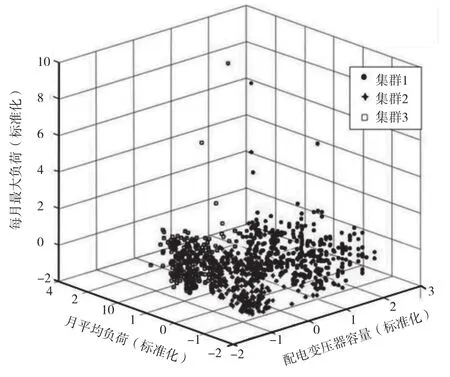
圖4 配電變壓器參數的三維散點
從數據集來看,有3個聚類,聚類1有600多個數據向量,聚類2有200多個數據向量,每個數據向量有3個特征,其中聚類的每個特征根據不同的簇分布。3類數據的樣本在一定程度上是交錯的,由于它們的高度不同,因此無法清晰看到樣本數量。特別是第一種數據點比較分散,但是其他種類的數據點比較集中。應清理平均月負荷的3個異常值,清理最大月負荷的9個異常值,即直線以上的12個點,從而完成配電變壓器運行數據的預處理。離群樣本診斷作為數據預處理中最為關鍵的一個環節,重點是找出和別的樣本有顯著差異的離群點。離群樣本剔除對故障預測模型的構建影響不大,但有助于提高模型的預測精度,因此離群樣本被視為噪聲。
為了測試和驗證聚類操作的可靠性,分析了從組中提取的拒絕最大負荷樣本的異常值,這可能是由于數據采集終端故障,導致無法收集一些數據,從而同時產生幾個月的異常數據,但這也表明異常值的診斷可靠。
6 結 論
本文重點研究了基于Spark的配電網線路拓撲數據挖掘和處理,實現了非標準數據的CIM/XML統一格式轉換,同時利用Spark中的內存分布式計算引擎、分布式圖形計算以及分布式數據分析等庫,對來自于配電網系統的CIM、SVG等數據進行提煉聚合,并使用抽象數據集RDD作為數據載體,極大縮短了數據并行處理的時間。而后通過采用粒子群優化算法使得聚類效果有了很大提高,粒子群聚類算法能夠有效、可靠地診斷和消除異常值,對研究配電網系統各類故障因素的影響具有重要意義。
猜你喜歡
中國特種設備安全(2022年6期)2022-09-20 02:52:28
經濟技術協作信息(2018年22期)2019-01-19 03:00:18
經濟技術協作信息(2018年32期)2018-11-30 01:43:16
電子制作(2018年11期)2018-08-04 03:26:08
電子制作(2016年23期)2016-05-17 03:54:05
電測與儀表(2016年5期)2016-04-22 01:14:14
工業設計(2016年12期)2016-04-16 02:52:00
河南電力(2016年5期)2016-02-06 02:11:24
電測與儀表(2015年13期)2015-04-09 11:57:38
設備管理與維修(2015年12期)2015-04-09 06:57:00
