融合評論的多任務聯(lián)合謠言檢測方法*
2022-09-21 08:36:34郭軍軍余正濤
計算機工程與科學 2022年9期
王 繁,郭軍軍,余正濤
(1.昆明理工大學信息工程與自動化學院,云南 昆明 650500;2.昆明理工大學云南省人工智能重點實驗室,云南 昆明 650500)
1 引言
微博用戶量急劇增加,信息發(fā)布門檻低,網(wǎng)絡運營平臺缺乏及時、有效的監(jiān)督機制,使得虛假信息、網(wǎng)絡謠言等充斥網(wǎng)絡。謠言借助微博獨有的特點進行廣泛傳播,對社會、企業(yè)和個人都造成了極大的不良影響。基于微博數(shù)據(jù)的謠言檢測,通過挖掘微博中的有效特征,開發(fā)準確的檢測和干預技術有助于緩解謠言傳播的負面影響。
謠言具有特殊性,為有意誤導讀者而撰寫的,也可能摻雜著真實內容而導致文本特征不足,因此單從新聞內容很難辨別真假。如圖1所示,深色用戶評論信息具有來自社交媒體人群的豐富信息,包括觀點、立場和情緒,對謠言的發(fā)現(xiàn)和甄別具有一定的指導意義;淺色用戶評論信息對微博謠言判定并沒有影響,有的甚至毫不相關,因此用戶評論的質量不同對謠言的判定所起作用也不同。目前國內外研究人員針對謠言的檢測主要通過探索新聞正文文本特征和用戶社交環(huán)境實現(xiàn)。Ruchansky等人[1]使用混合的深度學習框架同時對新聞文本、用戶響應和用戶特征進行建模,為假新聞檢測提供了全新的思路;Guo等人[2]利用神經(jīng)網(wǎng)絡對用戶評論進行層次化建模,以檢測用戶的虛假評論;Wu等人[3]通過對抗網(wǎng)絡從新聞內容的語義信息中捕獲差異化的可信度特征,并將其融合以獲取信息可信度評估。但是,這些方法對社交媒體數(shù)據(jù)之間的關聯(lián)性信息利用不足,用戶評論信息參差不齊,內含的噪聲信息會對謠言檢測帶來影響。此外,建立多任務聯(lián)合學習模型來訓練2個任務是提高網(wǎng)絡謠言檢測效果的一種有效而新穎的方法。Kochkina等人[4]提出的方法模擬了2個任務之間的信息共享和表示強化,為每個任務擴展了有價值的特征;Wu等人[5]通過過濾共享特征并作用于特定任務,實現(xiàn)假新聞檢測。然而典型的多任務學習方法中,共享特征未經(jīng)篩選就平等地用到各任務中,導致一些無用特征干擾甚至誤導檢測。如何既考慮微博正文與用戶評論之間的聯(lián)系,又考慮它們之間的差別,同時過濾和選擇用戶評論中的關鍵特征以提高謠言檢測準確率,是當前微博謠言檢測任務亟待解決的難題之一。本文期望通過多任務聯(lián)合學習的方式利用用戶評論的有效特征指導模型進一步提升分類效果。

Figure 1 Relevance and difference between microblog content and user comments圖1 微博正文與用戶評論的關聯(lián)與差異
本文設計了一種帶有過濾機制的多任務聯(lián)合學習方法,從微博正文和用戶評論的角度,通過引入共享特征過濾選擇機制丟棄無效特征和選擇有利特征來提升謠言檢測的性能。此外,為了更好地捕獲遠程依賴關系并提高模型的并行度,本文還應用Transformer編碼器模塊[6]對2個任務的輸入表示進行編碼。實驗結果表明,該方法的性能優(yōu)于基線方法,在微博謠言檢測中初步取得了較好的結果。本文的主要貢獻如下:
(1)提出一種多任務選擇和信息過濾機制實現(xiàn)多任務融合,設計了一個融合用戶評論篩選的多任務聯(lián)合學習模型,并首次引入用戶評論相關性檢測作為輔助任務來改善最終檢測性能。
(2)提出的模型通過門控機制和注意力機制來過濾和選擇多任務間的共享特征流實現(xiàn)對用戶評論的有效篩選,從而提升模型的檢測效果。
基于3萬條真實微博謠言檢測數(shù)據(jù)集進行實驗,對本文方法的性能進行全面評估。實驗結果表明,本文方法對微博謠言檢測是有效的。
2 相關研究
檢測的目標是在早期或者使用可解釋的因素有效地識別錯誤信息。謠言檢測最直接的方法就是檢查文本中主要內容的真實性,以判斷事件的真實性。目前謠言檢測方法大多是基于新聞內容和社交環(huán)境[7],包括文本特征、用戶信息和用戶響應等。
基于文本特征的方法旨在充分挖掘新聞內容特征,主要包括新聞文本、標題、圖片和視頻特征等。Potthast等人[8]探索了極端片面新聞與假新聞之間的寫作風格,提出一種評估文本相似性的方法;Guo等人[9]認為由人群引發(fā)的新聞評論情緒(社會情緒)在謠言檢測中也起著重要作用,提出了一種雙重情感特征框架來挖掘出版者情緒與社會情緒之間的關系。另外,典型的假新聞檢測被認為是一個文本分類問題,探索潛在的文本層次結構[10 - 12]可能促進假新聞的檢測。Karimi等人[11]提出一種分層的文本層次結構來探討真實新聞與假新聞之間的層次結構差異;Wang等人[12]提供了一個新的、公開的假新聞數(shù)據(jù)集并設計了一種新的混合卷積神經(jīng)網(wǎng)絡來整合元數(shù)據(jù)和文本。隨著計算機視覺CV(Computer Vision)和自然語言處理NLP(Natural Language Processing)領域的迅速發(fā)展,Abavisani等人[13]提出了多模態(tài)融合方法,引入交叉注意力模塊結合圖像和文本信息實現(xiàn)檢測任務,從視覺元素中提取視覺特征,以捕獲假新聞的不同特征,可以很好地檢測帶有部分真實新聞內容的虛假新聞。
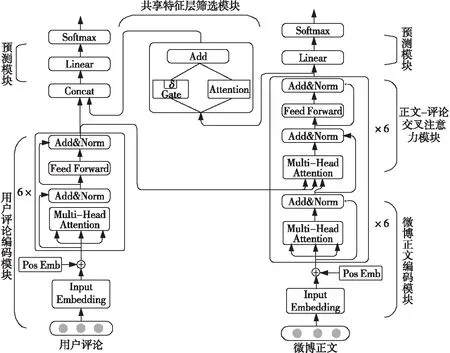
Figure 2 Framework of multi-task joint rumor detection method combined with comments圖2 融合評論的多任務聯(lián)合謠言檢測方法框架
基于社交環(huán)境的方法旨在利用用戶社交活動作為輔助信息來進行網(wǎng)絡謠言檢測。用戶在社交媒體平臺上的活動可以衍生出很多的社交語境特征,主要有基于用戶的特征、基于網(wǎng)絡的特征和基于響應的特征。可疑、低可信度用戶的特征更多表現(xiàn)為:賬號未經(jīng)驗證,賬號創(chuàng)建時間較短,用戶描述長度較短。從用戶配置文件中提取用戶特征[14,15]是一種假新聞檢測的有效手段。Lu等人[16]基于用戶個人信息特征構建圖感知共同注意網(wǎng)絡來提升謠言檢測性能。基于網(wǎng)絡的特征是通過構造特定的網(wǎng)絡來提取的,例如交互網(wǎng)絡[17]和傳播網(wǎng)絡[18,19]。Shu等人[17]利用出版社、新聞和用戶之間的三元關系搭建交互網(wǎng)絡實現(xiàn)假新聞分類;Monti等人[18]提出了利用幾何深度學習來學習假新聞中的特定傳播模式的方法;Shu等人[19]探索、驗證了真、假新聞分層傳播網(wǎng)絡的結構、時間和語言特點。
基于響應的特征代表了用戶的社會反應,包括立場和話題等。段大高等人[20]從微博評論的角度定義支持性、置信度和內容相關性3個特征來構建支持向量機算法判別消息真?zhèn)危籗hu等人[21]開發(fā)了文本評論聯(lián)合注意網(wǎng)絡,通過建立新聞句子和用戶評論之間的相互影響來學習特征表示,并通過注意權重來學習句子和評論的可解釋程度;Wu等人[22]提出了一種自適應交融網(wǎng)絡實現(xiàn)文本和評論之間的情感聯(lián)想和語義沖突的交互融合,建立特征關聯(lián)以提高謠言檢測的性能。但是,以上方法都只注重對用戶評論特征的挖掘及交互融合,忽略了用戶評論質量對謠言檢測也具有一定的影響,甚至會引入無用甚至負面的特征誤導檢測結果。
不同于上述已有方法,本文從評論信息有效利用的角度實現(xiàn)微博謠言檢測,首次提出了一種融合評論的篩選多任務聯(lián)合學習方法,融合用戶評論的同時采用門控和注意力機制有效地過濾和選擇用戶評論特征,以提高微博謠言檢測性能。
3 融合評論的聯(lián)合學習謠言檢測方法
3.1 檢測方法框架
針對用戶評論信息差異較大,評論質量影響謠言檢測性能的問題,本文提出一個融合評論的多任務聯(lián)合學習方法CMT-G&A(Comment Multi-task-Gate & Attention),其框架如圖2所示。該方法主要包括4個模塊,分別是微博正文-用戶評論編碼模塊、正文-評論交叉注意力模塊、共享特征層篩選模塊和事件預測模塊。
3.2 微博正文-用戶評論編碼模塊
3.2.1 微博正文編碼模塊
微博正文編碼模塊用于提取微博正文的文本特征。設E1為某一事件下的一條微博正文,每條正文長度為l1,C={c1,c2,…,cN}是一組響應E1的用戶評論,每條用戶評論長度為l2。本文使用Transformer編碼模塊[6]對微博正文特征嵌入進行編碼。為了能夠利用詞在序列中的位置信息,在編碼模塊中將位置編碼添加到詞嵌入表征中,它與詞嵌入表征具有相同的維數(shù)。編碼模塊核心是自注意力機制,具體如式(1)~式(3)所示:
ECon=E(x1,x2,…,xn)
(1)
ECon=Q=K=V
(2)
(3)

相較于僅執(zhí)行單一的注意力,本文使用不同的權重矩陣將輸入信息投影到多個不同的向量空間(注意力頭數(shù)),共同關注來自不同位置的不同表示子空間的信息是有益的,也即多頭注意力。多頭注意力通過不同的線性投影對Q、K和V進行h次線性投影,然后對h次投影結果并行執(zhí)行縮放點積注意計算,最后將這些注意結果串聯(lián)起來再次獲得新的表示。多頭注意力可以使參數(shù)矩陣形成多個子空間,讓矩陣學習多方面的信息。如式(4)和式(5)所示:
(4)
HCon=MultiHead(Q,K,V)=
Concat(head1,head2,…,headh)WO
(5)
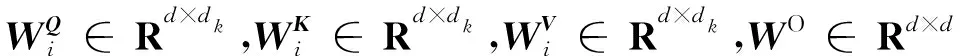
3.2.2 用戶評論編碼模塊
用戶評論編碼模塊與微博正文編碼模塊相似,都采用Transformer編碼模塊[6]對用戶評論特征嵌入進行編碼,如式(6)~式(8)所示:
ECom=E(x1,x2,…,xn)
(6)
ECom=Q=K=V
(7)
HCom=Transformer_encoder(Q,K,V)
(8)
其中,ECom為用戶評論輸入文本的詞嵌入表征;Q,K,V∈Rl2×d分別為查詢向量、鍵向量和值向量;HCom∈Rl2×d為用戶評論編碼模塊的輸出。
3.3 正文-評論交叉注意力模塊
用戶評論包含一些針對微博正文的有用信息,能對謠言的檢測起到促進作用。為了融合用戶評論信息來促進謠言檢測,本文仍采用Transformer編碼模塊[6]來提取正文-評論交叉注意力特征。不同之處在于該體系結構中,查詢向量Q是微博正文編碼模塊的輸出HCon,而鍵向量K和值向量V是用戶評論編碼模塊的輸出HCom,如式(9)和式(10)所示:
headi=
(9)
HShared=MultiHead(QCon,KCom,VCom)=
Concat(head1,head2,…,headh)WO
(10)
3.4 共享特征層篩選模塊
用戶評論大多是根據(jù)微博事件而產(chǎn)生的,在判斷用戶評論是否與該微博事件相關的過程中,微博正文特征的使用能夠有效促進用戶評論相關性檢測。為了根據(jù)特定任務選擇有價值的和合適的特征,本文在共享層后面設計了一個特征篩選模塊。共享特征篩選模塊由2個單元組成,如圖3所示,分別為門控篩選單元和注意力篩選單元。門控篩選單元用于過濾一些無用特征,注意力篩選單元用于關注用戶評論相關性檢測任務中有價值的共享特征。

Figure 3 Module of shared feature screening圖3 共享特征篩選模塊
門控單元采用一個單一的門控單元過濾共享特征中無用的特征。與LSTM(Long Short-Term Memory)[24]的遺忘門機制相似,其共享特征通過sigmoid激活函數(shù)作為一種門控狀態(tài),再與共享特征進行點乘運算通過tanh激活函數(shù)作為當前狀態(tài)的輸出,如式(11)和式(12)所示:
g=δ(W·HShared+b)
(11)
G=tanh(g⊙HShared)
(12)
其中,HShared∈Rl1×d為2個任務的共同特征;g∈Rl1×d為門控共享單元狀態(tài);G∈Rl1×d為共享特征HShared經(jīng)過門控機制過濾后的特征;W∈Rl1d×l1d和b∈Rl1×d為可訓練的參數(shù);δ為sigmoid激活函數(shù);⊙表示點乘操作。
注意力篩選單元以HShared作為輸入同樣采用transformer編碼模塊[6]來獲得更加有用的特征,如式(13)~式(15)所示:
HShared=Q=K=V
(13)
AShared=Transformer_encoder(Q,K,V)
(14)
FCom=G⊕AShared
(15)
其中,Q=K=V∈Rl1×d;AShared∈Rl1×d為共享特征HShared經(jīng)過注意力機制選擇后的特征。最后將過濾后的輸出特征G與經(jīng)過選擇后的輸出特征AShared相加作為共享特征層篩選模塊的輸出FCom。
3.5 事件預測模塊
用戶評論編碼模塊提取的特征與共享特征層篩選模塊的輸出特征進行拼接后,本文應用softmax函數(shù)分別實現(xiàn)對不同任務的分類,給出特定任務的概率分布預測,如式(16)~式(18)所示:
(16)
(17)
F1=[FCom;HCom]
(18)

得到用戶評論相關性檢測任務和謠言檢測任務的預測后,對模型進行訓練以最小化所有任務的預測和真實分布的交叉熵,如式(19)和式(20)所示:
(19)
(20)
其中,ζ為2個任務損失的加權和,λi為平衡損失參數(shù),ycon為微博正文的真實標簽,ycom為用戶評論相關性真實標簽。
4 實驗
4.1 數(shù)據(jù)集和評估指標
本文使用的數(shù)據(jù)集是從新浪微博平臺獲取的2020年疫情相關的熱門微博,共201條謠言微博及11 233條用戶評論,378條真實微博及20 334條用戶評論。在實際生活中,正常信息量通常遠大于謠言信息量,因此在構建疫情數(shù)據(jù)集時真實信息與謠言信息的比例大概為2∶1。謠言微博的選取主要以新浪微博上的微博小助手官方辟謠平臺為依據(jù),挑選其中轉發(fā)數(shù)超過50、評論數(shù)超過20的熱門微博,經(jīng)過篩選與預處理后形成json格式文件。數(shù)據(jù)收集完成后,首先對微博事件標注標簽,1為謠言微博,0為真實微博;然后針對某一個微博事件下的所有評論,同樣標注標簽,1表示該條用戶評論與微博描述的事件相關,0表示與微博描述的事件不相關。
數(shù)據(jù)其它預處理主要包括:(1)去除文本內容中的多余符號、超鏈接和特殊字符;(2)去除微博中相同的用戶評論信息。
本文使用準確率(A)、精確度(P)、召回率(R)和F1分數(shù)(F1)對謠言識別結果進行評價。
4.2 實驗設置
模型的超參數(shù)配置方面,本文通過預先訓練的搜狗新聞語料庫[23]來表示微博正文和用戶評論一個字(詞)的300維詞嵌入,這是一個包含36萬字/詞的搜狗新聞預訓練語料庫。將微博正文和用戶評論進行jieba分詞處理后,將處理完成的字或詞構建詞典,最后通過構建的詞典依次提取預訓練詞向量,其中作者把微博正文和用戶評論構建為一個詞典。微博正文-用戶評論編碼模塊、正文-評論交叉注意力模塊和共享特征層篩選模塊中的Transformer編碼模塊[6]頭數(shù)設置為2,最長用戶評論長度設置為30,最長微博正文長度設置為60,對于長度不足的采用0向量填充。數(shù)據(jù)批次設置為64,詞表大小設置為20 000,學習率設為5e-5,學習率衰減為0.9,dropout為0.5,參數(shù)采用Adam優(yōu)化器[25]更新。用戶評論相關性檢測任務損失平衡參數(shù)λ1=0.4,謠言檢測任務損失平衡參數(shù)λ2=0.6。本文將數(shù)據(jù)集分割為訓練集、驗證集和測試集,分別包含24 173,3 614和3 780條用戶評論。
4.3 基線模型分析
為了驗證融合評論的多任務聯(lián)合學習模型對微博謠言檢測任務的有效性,本文采用幾種非常典型的分類模型來比較編碼方式的差異性。另外,本文還將CMT-G&A與當前最先進的方法進行比較。
為了更加公平地比較,本文設置學習率、微博正文和用戶評論長度、dropout等參數(shù)與主模型一致;LSTM與GRU隱藏向量大小使用最佳性能參數(shù),設置為128;CNN卷積核數(shù)量設置為256,卷積核尺寸為(2,3,4)。本文使用的基線模型具體如下所示:
(1)BGRU(Bi-directional Gate Recurrent Unit):將微博正文和用戶評論分別通過雙向GRU[26]提取文本特征表示,用戶評論特征不經(jīng)過過濾直接參與評論相關性檢測輔助任務,用戶評論特征與微博正文特征拼接后作為共享特征經(jīng)過全連接層來實現(xiàn)謠言檢測主任務預測。
(2)BLSTM(Bi-directional Long Short-Term Memory):將微博正文和用戶評論分別通過雙向LSTM[26]提取文本特征表示,用戶評論特征直接參與評論相關性檢測輔助任務,用戶評論特征與微博正文特征拼接后作為共享特征經(jīng)過全連接層進行謠言檢測主任務預測。
(3)RCNN (Region-CNN):將微博正文和用戶評論分別通過雙向GRU[26,27]提取文本特征,通過最大池化分別對兩者特征進行降維,用戶評論直接通過全連接層進行評論相關性檢測輔助任務,用戶評論與微博正文特征拼接后作為共享特征經(jīng)過全連接層進行謠言檢測主任務預測。
(4)BLSTM-ATT(Bi-directional Long Short-Term Memory ATTention): 將微博正文和用戶評論分別通過雙向LSTM[26]提取文本特征,通過注意力機制[28]關注各自任務目標更關鍵的信息,抑制其他無用信息,用戶評論與微博正文特征拼接后作為共享特征經(jīng)過全連接層進行謠言檢測主任務預測。
(5)BGRU-ATT(Bi-directional Gate Recurrent Unit ATTention): 將微博正文和用戶評論分別通過雙向GRU[26,27]提取文本特征,通過注意力機制[28]關注各自任務目標更關鍵的信息,共享特征經(jīng)過全連接層進行謠言檢測任務預測。
(6)CMT(Comment Multi-Task):首先將微博正文和用戶評論分別通過微博正文-用戶評論編碼模塊提取各自文本特征;再通過正文-評論交叉注意力模塊提取共享特征進行謠言檢測主任務預測;最后共享特征不經(jīng)過共享特征篩選模塊而是直接與用戶評論拼接后進行用戶評論相關性輔助任務預測。
(7)MT-trans-G-A(Multi-Task-Gate-Attention):Wu等人[5]設計的多任務共享特征篩選框架,引入位置檢測任務和虛假新聞檢測任務來檢測假新聞。
(8)dEFEND(Explainable Fake News Detection):Shu等人[21]開發(fā)了正文評論聯(lián)合注意網(wǎng)絡,通過建立新聞句子和用戶評論之間的相互聯(lián)系去學習特征表示,并通過注意權重學習句子和評論的可解釋程度。
(9)CMT-G&A:在CMT模型基礎上通過加入門控機制和注意力機制來過濾和選擇共享特征,以實現(xiàn)對微博謠言的檢測,為本文所提的主要模型。
從表1所述的模型實驗結果可以發(fā)現(xiàn),本文基線模型CMT的準確率、精確率和F1值都超過了其他所有基線模型,表明其他基線模型在融合用戶評論的謠言檢測任務中預測效果略有不足;而基線模型CMT引入Transformer編碼模塊[6]對2個任務的輸入進行編碼,利用其長距離依賴和并行性,提高了模型的性能,表明了本文模型編碼方式的有效性;當前較先進模型中,MT-trans-G-A的準確率、精確率、召回率和F1值相比本文主要模型的要低,其原因可能是MT-trans-G-A更加注重多任務間共享特征的篩選,忽略了用戶評論特征,而用戶評論特征對提升謠言檢測任務性能更加有效;dEFEND則表現(xiàn)出了更好的預測結果,表明共同注意力能很好地挖掘微博正文和用戶評論的關聯(lián)性,相比本文主要模型結果較低的原因是微博用戶量更大、用戶評論數(shù)據(jù)更加嘈雜,評論質量是關鍵因素。CMT-G&A在引入門控機制和注意力機制后預測性能有很好的提升,相較于CMT準確率提升了6.1%,精確率提升了17.7%及F1值提升了7.7%。但是,召回率卻低于基線模型,原因可能是本文為了更好地模擬真實場景,數(shù)據(jù)集構建過程中謠言事件相較于真實事件更少,導致模型更加偏向于預測真實事件;同時分詞錯誤也是影響模型性能的重要因素,由于分詞錯誤導致模型無法準確識別很多關鍵詞的類別,進而影響模型預測結果。本文模型在另外3個性能指標上都達到了最優(yōu)結果,表明本文模型是有效的。
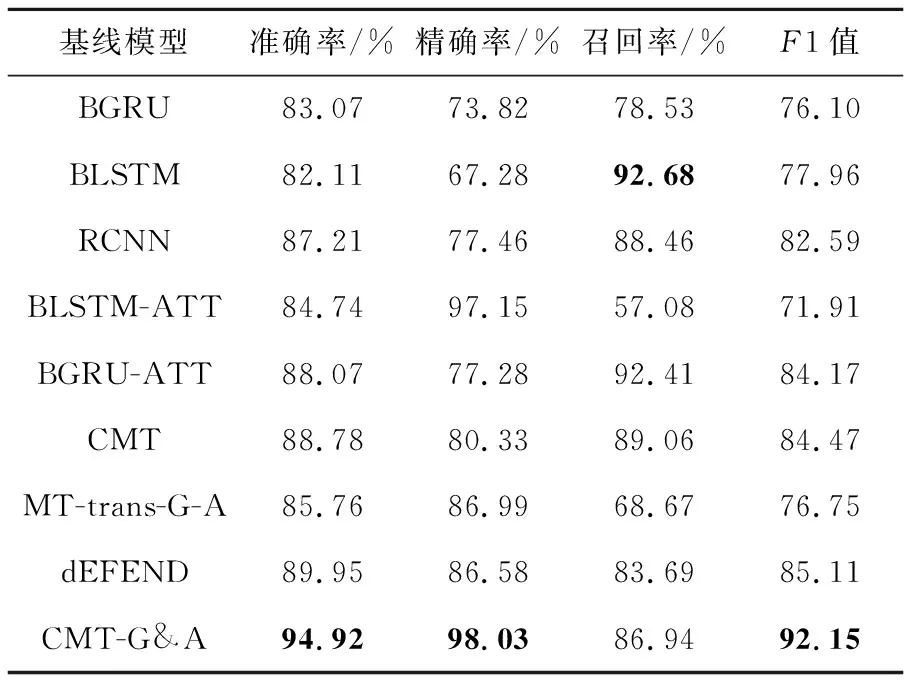
Table 1 Performance comparison of baseline models
4.4 消融實驗分析
本文為了驗證不同模塊的有效性,將CMT-G&A模型分解成幾個簡化的模型,評價指標的得分情況如表2所示,最優(yōu)結果用粗體表示。簡化模型具體如下所示:
(1)S-task:只將微博正文通過Transformer編碼[6]提取文本特征進行謠言檢測主任務預測,用戶評論相關性檢測任務不參與模型訓練。
(2)CMT-G:與CMT的不同之處在于,先將通過門控機制過濾無關特征后的共享特征與用戶評論特征拼接,然后再進行用戶評論相關性檢測輔助任務預測。
(3)CMT-A:與CMT的不同之處在于,先將通過多頭注意力機制選擇有效特征后的共享特征與用戶評論特征進行拼接,然后再進行用戶評論相關性檢測輔助任務預測。
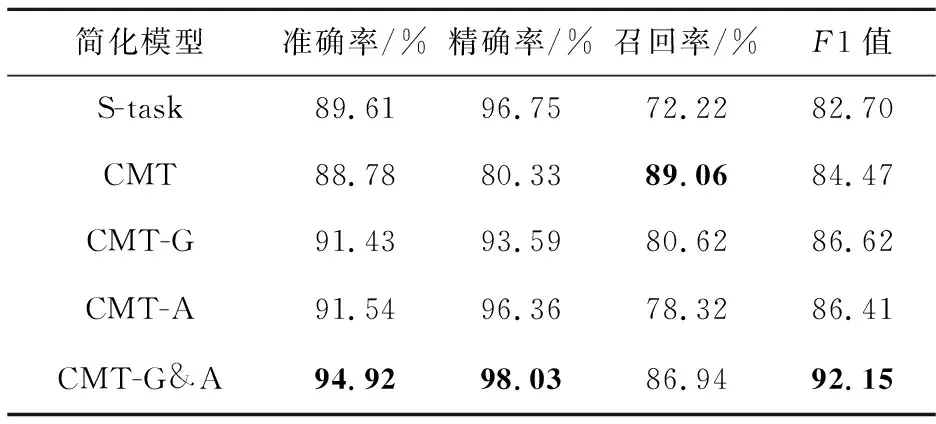
Table 2 Experimental results of simplified models
表2展示了模型CMT-G&A與簡化模型的實驗結果。CMT-G&A的結果在準確率、精確率和F1值上都明顯優(yōu)于其他4種模型。CMT相較于基于微博正文的單任務謠言檢測模型S-task,性能上有一些降低,原因可能在于融合用戶評論后的共享特征確實有一些無用甚至有害特征干擾了檢測。從CMT-G和CMT-A的實驗結果可以看出,在加入門控篩選單元或注意力篩選單元后,模型的準確率、精確率和F1值相比S-task的有較明顯的提升。CMT-G&A融合門控篩選單元與注意力篩選單元后性能最優(yōu),表明多任務聯(lián)合學習間的共享特征分別通過門控機制過濾和注意力機制選擇后對謠言檢測任務有促進作用。可見,在融合用戶評論的謠言檢測中,用戶評論的質量確實對謠言檢測性能有一定影響。本文提出的融合評論的篩選多任務聯(lián)合學習模型不僅能有效地挖掘微博事件中用戶評論的有效信息,而且多任務中共享特征的過濾和選擇能有效地促進微博謠言的檢測。
4.5 超參實驗分析
4.5.1 詞嵌入維度對檢測性能的影響
在深度學習中,模型的參數(shù)設置對實驗結果也會有很大的影響,通過調節(jié)模型中的一些重要參數(shù)能更大程度地提升模型性能。為了驗證隨機初始化和預訓練詞向量對模型效果的影響,本文做了如下實驗:
針對隨機初始化詞向量,分別設置維度為300,512和768;對于預訓練詞向量,選擇搜狗新聞語料庫[23]訓練的sou-gou詞向量;為了公平起見,本文選擇S-task、CMT、CMT-G&A 3個典型模型進行對比,實驗結果如圖4所示。

Figure 4 Sensitivity analysis about word embedding圖4 詞嵌入敏感性分析
在從圖4可以看出,CMT-G&A和CMT在預訓練的詞向量上表現(xiàn)出了更好的性能,S-task模型對于隨機初始化或預訓練詞向量變化不明顯,同時隨機初始化詞向量的維度過大和過小對模型的性能也有較大的影響。本文后續(xù)采用預訓練的sou-gou詞向量繼續(xù)開展實驗。
4.5.2 頭數(shù)目對檢測性能的影響
Transformer[6]中的自注意力機制能夠捕獲長距離依賴,并且能夠學習到句子內部結構和語法,通過設置多個頭可以使模型關注不同方面的信息。為了驗證不同多頭注意力對模型性能的影響,本文還做了如下實驗:對于主要模型CMT-G&A,對自注意力機制設置不同頭數(shù),實驗結果如圖5所示。從圖5可以看到,頭數(shù)設為2時模型的預測性能表現(xiàn)最好。其原因在于,頭數(shù)過多會造成注意力冗余,參數(shù)過多反而影響模型的性能;頭數(shù)過少又會導致注意力特征提取不充分,模型表達能力不足。本文后續(xù)將頭數(shù)設為2繼續(xù)開展實驗。

Figure 5 Sensitivity analysis about multi-head attention圖5 多頭注意力敏感性分析
4.6 重要詞匯分析
在對同一微博事件進行預測時,用戶評論中每個單詞的重要權值也不同,為了更加直觀地表示CMT-G&A模型如何從用戶評論中學到有用的信息,同時驗證用戶評論信息對謠言檢測任務的影響,本文從數(shù)據(jù)集中取出一個微博事件,統(tǒng)計了用戶評論對應微博事件的單詞權重并進行熱力圖展示,如圖6所示。
從圖6可知,模型針對同一事件在融合2條不同的用戶評論時,對用戶評論中詞的關注度是不一樣的。顏色深的部分表示當前用戶評論中對于微博事件注意力權重較高的詞,顏色越深權重越高。不考慮特殊符號例如“,”“。”等,用戶評論中“不信謠”“謠言”等關鍵詞表現(xiàn)出了較高的權重。實驗表明用戶評論也為微博事件的判定提供了一些重要的線索,融合用戶評論對謠言檢測是有效的,可以很大程度上幫助我們識別網(wǎng)絡謠言。
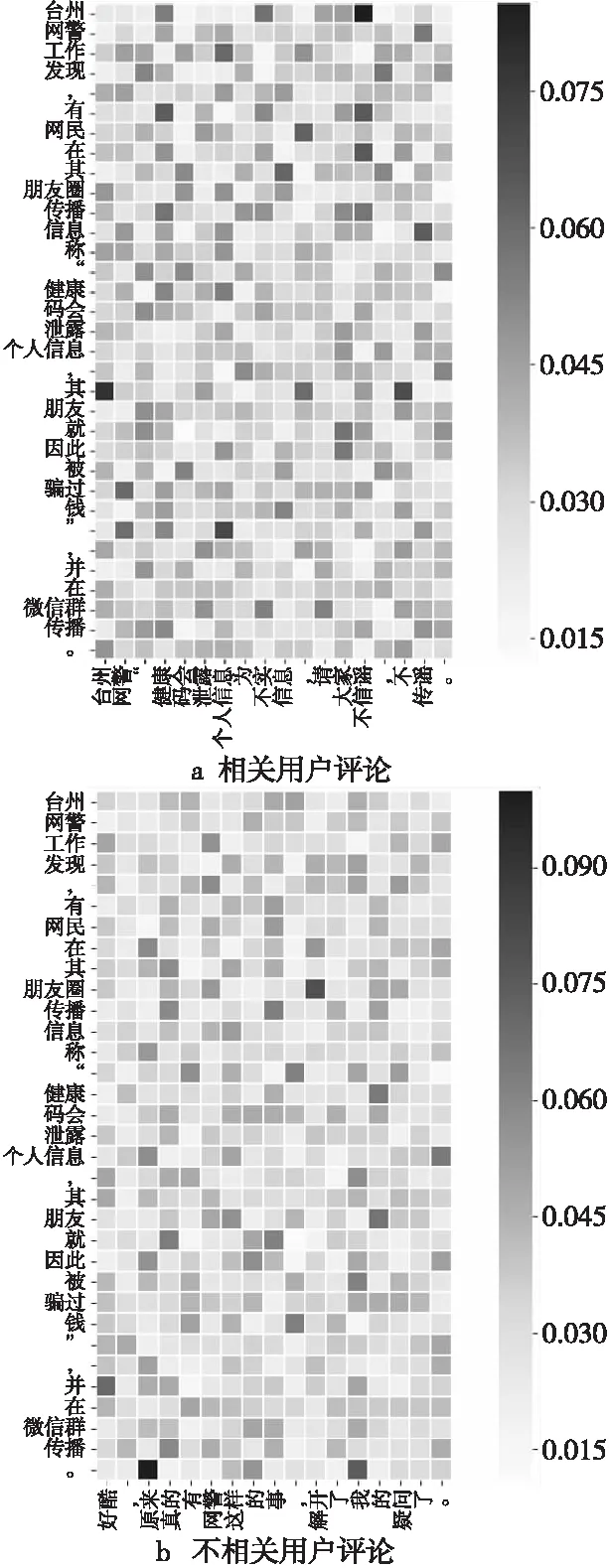
Figure 6 User comment weight visualization圖6 用戶評論權重可視化
5 結束語
本文針對微博謠言檢測任務中文本特征不足,用戶評論整體質量不高的問題,提出了一種融合評論的篩選多任務聯(lián)合學習方法,通過用戶評論與微博事件之間的關聯(lián)性,將謠言檢測任務作為主任務,用戶評論相關性檢測任務作為輔助任務,并通過聯(lián)合學習同時學習和更新主任務模型和輔助任務模型的參數(shù)。一系列實驗結果表明,融合評論的多任務聯(lián)合學習方法不僅能較好地融合用戶評論信息,而且用戶評論的過濾和選擇更好地提升了謠言檢測任務的性能。
未來將探索未標注的輔助特征,例如多媒體內容(圖片、視頻)往往比單獨的文字信息更容易引起注意,后續(xù)嘗試利用這些多模態(tài)特征來進一步提升謠言檢測任務的性能。
猜你喜歡
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
商用汽車(2016年4期)2016-05-09 01:23:12
