基于果蠅算法的空間數(shù)據(jù)庫位置冗余數(shù)據(jù)查詢
2022-09-28 09:28:52許玉龍
計(jì)算機(jī)仿真 2022年8期
關(guān)鍵詞:數(shù)據(jù)庫方法
姜 姍,高 遠(yuǎn),許玉龍
(河南中醫(yī)藥大學(xué),河南 鄭州 450046)
1 引言
互聯(lián)網(wǎng)空間數(shù)據(jù)庫是存儲數(shù)據(jù)、管理數(shù)據(jù)的主要方式[1]。但隨著信息技術(shù)的迅速發(fā)展,海量信息呈現(xiàn)爆炸式增長趨勢,導(dǎo)致空間數(shù)據(jù)庫出現(xiàn)數(shù)據(jù)冗余等現(xiàn)象[2,3]。因此,為了保證空間數(shù)據(jù)庫位置冗余數(shù)據(jù)能夠得到有效查看,需要對空間數(shù)據(jù)庫位置冗余數(shù)據(jù)進(jìn)行查詢。
文獻(xiàn)[4]提出 基于差分隱私的社交網(wǎng)絡(luò)位置近鄰查詢方法 ,通過網(wǎng)格化分割空間區(qū)域,依據(jù)用戶位置訪問量對隱私預(yù)算進(jìn)行分配。采用組合增量近鄰查詢算法,擴(kuò)大空間檢索范圍,實(shí)現(xiàn)過濾冗余數(shù)據(jù)查詢。該方法的查詢命中率較高,但存在查詢?nèi)哂鄶?shù)據(jù)時(shí)間消耗率高的問題。文獻(xiàn)[5]提出一種海量空間數(shù)據(jù)云存儲與查詢算法方法,該方法通過空間數(shù)據(jù)操作的主要特征,利用空間四叉樹模型組織存儲云平臺中的空間數(shù)據(jù),并構(gòu)建空間索引,采用兩步查詢法,完成對空間數(shù)據(jù)的查詢。該方法的大數(shù)據(jù)集空間查詢響應(yīng)具有較好的實(shí)時(shí)性,但存在查詢數(shù)據(jù)后空間占用率高的問題。針對上述問題,提出基于果蠅算法的空間數(shù)據(jù)庫位置冗余數(shù)據(jù)查詢方法。
2 填補(bǔ)空間數(shù)據(jù)
由于空間數(shù)據(jù)庫中的數(shù)據(jù)數(shù)量繁多,且容易出現(xiàn)冗余數(shù)據(jù),因此為了實(shí)現(xiàn)對空間數(shù)據(jù)庫位置冗余數(shù)據(jù)的查詢,首先要對空間數(shù)據(jù)庫中的缺失數(shù)據(jù)進(jìn)行填補(bǔ)。空間數(shù)據(jù)庫中的數(shù)據(jù)在缺失時(shí),首先構(gòu)建一個(gè)BP神經(jīng)網(wǎng)絡(luò)模型,利用BP神經(jīng)網(wǎng)絡(luò)對缺失數(shù)據(jù)進(jìn)行估算,如圖1所示。

圖1 BP神經(jīng)網(wǎng)絡(luò)模型
圖1中,將空間數(shù)據(jù)庫中不具有缺失數(shù)據(jù)屬性的樣本數(shù)據(jù)當(dāng)作網(wǎng)絡(luò)的輸入,而具有缺失數(shù)據(jù)屬性的數(shù)值當(dāng)作網(wǎng)絡(luò)的輸出。當(dāng)樣本數(shù)據(jù)中的已知數(shù)據(jù)訓(xùn)練網(wǎng)絡(luò)滿足這些要求后,應(yīng)將具有缺失數(shù)據(jù)的已知數(shù)據(jù)輸入到網(wǎng)絡(luò)中,待網(wǎng)絡(luò)輸出后,這些數(shù)值就是缺失數(shù)據(jù)的估計(jì)值[6]。
通過三層BP神經(jīng)網(wǎng)絡(luò),假設(shè)輸入層節(jié)點(diǎn)數(shù)目由m描述,輸出層節(jié)點(diǎn)數(shù)目由n代表,u描述的是隱含層節(jié)點(diǎn)數(shù)目,那么通過輸出層輸出的節(jié)點(diǎn)函數(shù)用方程定義如下
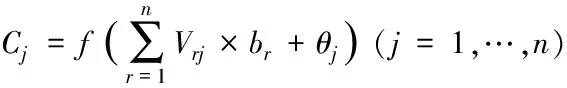
(1)
式中,經(jīng)隱含層到輸出層的連接權(quán)值由Vrj表示,隱含層節(jié)點(diǎn)值通過br描述,輸出層內(nèi)節(jié)點(diǎn)閾值通過θj代表,Cj就是輸出層的節(jié)點(diǎn)值。
節(jié)點(diǎn)在隱含層中輸出時(shí),用方程定義為
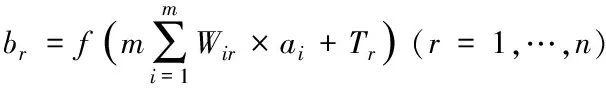
(2)
式中,Wir描述的是從輸入層到隱含層的連接權(quán)值,輸入層的節(jié)點(diǎn)值為ai,隱含層節(jié)點(diǎn)的閾值代表Tr。
神經(jīng)網(wǎng)絡(luò)在學(xué)習(xí)過程中的算法過程如下:
1)在(0,1)之間設(shè)置Wir、Tr、Vrj、θj的最小值。
3)在輸出層中,對節(jié)點(diǎn)輸出值和期望值進(jìn)行計(jì)算,其誤差用dj來表示

(3)

4)將誤差er逆向分配到隱含層節(jié)點(diǎn),則誤差er定義為
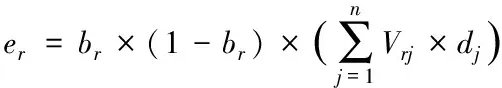
(4)
5)為了降低神經(jīng)網(wǎng)絡(luò)在學(xué)習(xí)時(shí)產(chǎn)生振蕩,需要通過添加慣性沖量技術(shù)對權(quán)值和閾值進(jìn)行調(diào)整[7]。利用添加慣性沖量技術(shù)消除高頻振蕩,從而獲取學(xué)習(xí)率的最大值,從而提升了學(xué)習(xí)速度[8]。因此,被調(diào)整后的權(quán)值Vrj和Wir分別表示為

(5)
被調(diào)整后的閾值表示為

(6)
式(5)和式(6)中,λ、β分別表示為取(0,1)范圍內(nèi)值的學(xué)習(xí)率,η、δ分別表示為動(dòng)量因子。那么整個(gè)訓(xùn)練集的誤差平方和E用方程表示如下

(7)
6)反復(fù)進(jìn)行步驟2)到步驟5),當(dāng)誤差dj滿足網(wǎng)絡(luò)要求或變成零時(shí),就可以停止訓(xùn)練,經(jīng)過上述步驟的反復(fù)迭代,直到滿足要求才可以獲取與之相匹配的神經(jīng)網(wǎng)絡(luò)模型。
7)測試集中,將已知數(shù)據(jù)中存在缺失數(shù)據(jù)的輸送到訓(xùn)練完成的網(wǎng)絡(luò)內(nèi),其中輸出值就是缺失數(shù)據(jù)的估計(jì)值。將估計(jì)值填補(bǔ)到空間數(shù)據(jù)庫中,從而實(shí)現(xiàn)空間數(shù)據(jù)庫的插補(bǔ)。
2.1 位置冗余數(shù)據(jù)分類
通過填補(bǔ)空間數(shù)據(jù)庫中的缺失數(shù)據(jù),從而獲得完整的空間數(shù)據(jù)。根據(jù)空間數(shù)據(jù)庫位置冗余的數(shù)據(jù),采用粒子群優(yōu)化算法[9]進(jìn)行數(shù)據(jù)挖掘和分類。
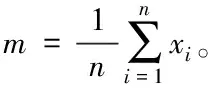
在非線性可行情形中,假設(shè)x和y是兩個(gè)向量,那么非線性函數(shù)φ對特征空間H進(jìn)行映射時(shí),它們之間的歐氏距離用方程定義為

(8)


粒子群優(yōu)化算法屬于智能優(yōu)化算法[12],假設(shè)在D維空間中,有粒子種群n個(gè),它們會構(gòu)建成種群X={x1,x2,…,xn},那么位于第i個(gè)粒子的位置為Xi={xi1,xi2,…,xin},目前為止粒子的速度為:Vi={vi1,vi2,…,vin},其中粒子i經(jīng)過的最好位置由Pi={pi1,pi2,…,pin}表示,那么所有粒子所經(jīng)過的最好位置就是:Pg={pg1,pg2,…,pgn}。那么第i個(gè)粒子在t+1時(shí)刻為

(9)
式中,r1和r2描述的是在(0,1)區(qū)間的隨機(jī)數(shù);c1和c2分別表示學(xué)習(xí)因子,一般來說,c1=c2=2。
在粒子群優(yōu)化算法中,每個(gè)粒子描述的都是一個(gè)解,將此算法放入模糊支持向量機(jī)中,通過FSVM訓(xùn)練獲取l個(gè)支持向量的粒子維數(shù),利用方程(9)對這些樣本進(jìn)行隸屬度計(jì)算。
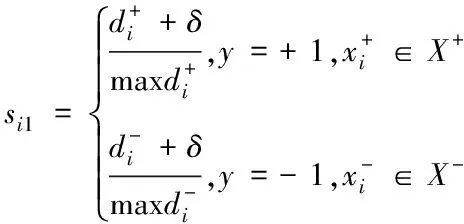
(10)

假設(shè)初始化粒子的位置范圍為[umin,umax],在初始化粒子群空間內(nèi)有l(wèi)個(gè)樣本權(quán)重向量,其中每個(gè)粒子都有自身的位置和速度,這些位置就是樣本的隸屬度,而速度會對隸屬度值進(jìn)行改變。完成對閾值的設(shè)定,當(dāng)粒子輸出時(shí),它的隸屬度要保持原值,但它的樣本隸屬度值要比設(shè)定的閾值大,否則其隸屬度值為0,說明該樣本不被選擇。
利用訓(xùn)練FSVM取得支持向量集并對訓(xùn)練樣本集進(jìn)行處理,從而獲取適應(yīng)度函數(shù),這時(shí)適應(yīng)度函數(shù)表示如下
(11)
式中,M描述的是測試集中的樣本數(shù)目,fi代表的是預(yù)測值,yi代表的是實(shí)際值。因此,粒子的適應(yīng)值越小越優(yōu)質(zhì),從而實(shí)現(xiàn)對冗余數(shù)據(jù)的挖掘和分類。
3 位置冗余數(shù)據(jù)查詢
果蠅算法屬于一種覓食行為,通過自身較好的嗅覺對空間數(shù)據(jù)庫中的不同數(shù)據(jù)進(jìn)行搜索,距離出現(xiàn)冗余位置的數(shù)據(jù)較近時(shí),它敏銳的視覺會迅速發(fā)現(xiàn)冗余數(shù)據(jù)的位置或種群其它個(gè)體聚集處,在基于果蠅算法的基礎(chǔ)上建立了CQAFF連續(xù)查詢攻擊算法,主要流程如下:
1)首先將果蠅種群參數(shù)在T時(shí)刻進(jìn)行初始化,其中:M表示種群規(guī)模,(x,y)描述的是種群初始隨機(jī)位置,Tmax代表最大迭代次數(shù)。
2)設(shè)置f(H)為查詢匿名度量,將其作為空間數(shù)據(jù)集合,i(x,y)代表果蠅個(gè)體,利用果蠅嗅覺確定式(12)和隨機(jī)距離d的位置冗余數(shù)據(jù)方向和距離,該公式如下

(12)
式中,rand()描述的是0到1之間的隨機(jī)數(shù)。
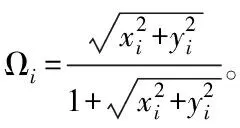

5)將上述步驟進(jìn)行反復(fù)操作,直到獲得果蠅的適應(yīng)度,并找到果蠅適應(yīng)度中的最大適應(yīng)度個(gè)體Φmax(xmax,ymax)及最小適應(yīng)度個(gè)體Φmin(xmin,ymin)。
6)種群位置向最大適應(yīng)度進(jìn)行隨機(jī)移動(dòng)
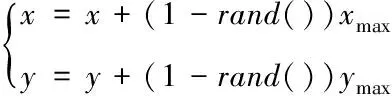
(13)
式中,xmax和ymax分別表示最大適應(yīng)度。
7)將T=T+1,并判斷最大迭代次數(shù)Tmax是否大于T=T+1,若是,就要返回到步驟2)重復(fù)執(zhí)行操作,直到迭代結(jié)束或獲取到最佳適應(yīng)度。
8)把實(shí)際查詢匿名度量f(H)輸出,即實(shí)際查詢匿名度量就是最優(yōu)解。通過上述步驟,實(shí)現(xiàn)基于果蠅算法的空間數(shù)據(jù)庫位置冗余數(shù)據(jù)查詢。
4 實(shí)驗(yàn)與分析
為了驗(yàn)證基于果蠅算法的空間數(shù)據(jù)庫位置冗余數(shù)據(jù)查詢方法的有效性,在MATLAB軟件平臺上進(jìn)行對比實(shí)驗(yàn)。實(shí)驗(yàn)在空間數(shù)據(jù)庫中共選取8組冗余數(shù)據(jù),數(shù)量分別為1000kB、2000kB、3000kB、4000kB、5000kB、6000kB、7000kB和8000kB。分別采用所提方法、文獻(xiàn)[4]方法和文獻(xiàn)[5]方法對查詢?nèi)哂鄶?shù)據(jù)的時(shí)間消耗率進(jìn)行對比,對比結(jié)果如圖2所示。

圖2 查詢?nèi)哂鄶?shù)據(jù)的時(shí)間消耗率對比結(jié)果
由圖2可知,隨著冗余數(shù)據(jù)數(shù)量的增加,不同方法的查詢?nèi)哂鄶?shù)據(jù)的時(shí)間消耗率隨之增大。所提方法在8組測試中,時(shí)間消耗率均在15%以下,說明在查詢?nèi)哂鄶?shù)據(jù)時(shí)用時(shí)較短,時(shí)間消耗較小。而文獻(xiàn)[4]方法的最高時(shí)間消耗率達(dá)到35%,最低時(shí)間消耗率達(dá)到17%;文獻(xiàn)[5]方法的時(shí)間消耗率的最高值為30%,最低值為13%。由此可知,文獻(xiàn)[4]方法與文獻(xiàn)[5]方法的時(shí)間消耗率要高于所提方法,表明時(shí)間消耗大,冗余數(shù)據(jù)查詢較慢。進(jìn)一步驗(yàn)證所提方法的空間占用率,選取空間數(shù)據(jù)8000kB,采用三種方法對查詢后的空間數(shù)據(jù)占用率進(jìn)行對比,對比結(jié)果如圖3所示。

圖3 空間位置數(shù)據(jù)查詢后空間占用率對比結(jié)果
根據(jù)圖3可知,所提方法從1000kB數(shù)據(jù)到8000kB數(shù)據(jù)的空間占用率一直保持在15%以下,而文獻(xiàn)[4]方法的初始空間占用率為22%,到8000kB數(shù)據(jù)時(shí)空間占用率達(dá)到29%;文獻(xiàn)[5]方法在空間數(shù)據(jù)數(shù)量為2000kB時(shí),最低空間占用率為23%,最高空間占用率為34%。由此可知,所提方法的空間占用率要小于文獻(xiàn)[4]方法和文獻(xiàn)[5]方法,從而節(jié)省了空間數(shù)據(jù)庫的空間。
通過圖2和圖3的對比分析可知,所用方法能夠快速實(shí)現(xiàn)冗余數(shù)據(jù)的查詢且在空間數(shù)據(jù)庫中的空間占用率較低,這是因?yàn)樵摲椒ú捎昧W尤簝?yōu)化算法對冗余數(shù)據(jù)進(jìn)行挖掘和分類,使空間數(shù)據(jù)庫中的訓(xùn)練樣本數(shù)據(jù)減少,以此提升了訓(xùn)練速度,進(jìn)而減少了時(shí)間的消耗和降低了空間占用率。
在此基礎(chǔ)上,選擇5組冗余數(shù)據(jù),分別采用三種方法對冗余數(shù)據(jù)查詢效率進(jìn)行對比分析,對比結(jié)果如表1所示。

表1 不同方法的冗余數(shù)據(jù)查詢效率測試
分析表1中的數(shù)據(jù)可知,當(dāng)冗余數(shù)據(jù)數(shù)量為5000kB時(shí),所提方法的平均冗余數(shù)據(jù)查詢效率為99%,而文獻(xiàn)[4]方法和文獻(xiàn)[5]方法的平均冗余數(shù)據(jù)查詢效率分別為66.2%和82%。由此可知,所提方法的查詢效率要優(yōu)于文獻(xiàn)[4]方法和文獻(xiàn)[5]方法,說明所提方法在數(shù)據(jù)查詢時(shí)空間數(shù)據(jù)庫運(yùn)行較快,進(jìn)而提升了查詢效果。
5 結(jié)束語
為了降低冗余數(shù)據(jù)查詢時(shí)間消耗率和空間占用率,提高冗余數(shù)據(jù)查詢效率,提出基于果蠅算法的空間數(shù)據(jù)庫位置冗余數(shù)據(jù)查詢方法,首先利用BP神經(jīng)網(wǎng)絡(luò)模型,估算空間數(shù)據(jù)庫中的缺失數(shù)據(jù),完成對空間數(shù)據(jù)庫的插補(bǔ)。然后使用粒子群優(yōu)化算法,對空間數(shù)據(jù)庫進(jìn)行挖掘和分類,獲取粒子的最優(yōu)位置。最后采用果蠅算法對分類后的空間數(shù)據(jù)進(jìn)行位置冗余數(shù)據(jù)查詢,提高了空間數(shù)據(jù)庫位置冗余數(shù)據(jù)查詢的整體有效性,解決了傳統(tǒng)方法中存在的問題,為今后的信息領(lǐng)域提供了重要基礎(chǔ)。
猜你喜歡
兒童故事畫報(bào)(2019年5期)2019-05-26 14:26:14
財(cái)經(jīng)(2017年15期)2017-07-03 22:40:49
財(cái)經(jīng)(2017年2期)2017-03-10 14:35:35
財(cái)經(jīng)(2016年15期)2016-06-03 07:38:02
Coco薇(2016年2期)2016-03-22 02:42:52
財(cái)經(jīng)(2016年3期)2016-03-07 07:44:46
財(cái)經(jīng)(2016年6期)2016-02-24 07:41:51
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
