VMP虛擬指令逆向分析算法
2022-10-01 02:41:20樂德廣王雨芳龔聲蓉
計算機工程與設計 2022年9期
樂德廣,趙 杰,王雨芳,龔聲蓉
(1.常熟理工學院 計算機科學與工程學院,江蘇 常熟 215500;2.淘寶(中國)軟件有限公司 CRO安全部,浙江 杭州 311121)
0 引 言
軟件保護是一種防止軟件被惡意攻擊而受到破解、篡改或盜版等威脅的軟件安全技術,是當前軟件安全研究領域的熱點[1]。常見的軟件保護技術有代碼混淆[2]、軟件加密[3]、數字水印[4]和虛擬機保護(virtual machine protection,VMP)[5]等。其中,虛擬機保護設計一套私有虛擬指令集和虛擬機架構,并將宿主程序的CPU指令變換成自定義的虛擬指令,大幅增加指令復雜度。當執行軟件時,由虛擬機中的解釋器對變換的虛擬指令進行解釋執行,從而在實現原始指令功能的同時,為軟件提供有效的保護。許多學者對此進行了大量的研究,提出了各種改進方法[6-8],并出現了VMProtect[9]、Code Virtualizer[10]和Themida[11]等商業軟件。
除了虛擬機保護的正向研究,部分學者針對許多惡意代碼利用虛擬機保護逃避檢測等問題從對虛擬機保護的逆向分析角度開展研究,如文獻[12]提出一種從程序執行路徑中自動識別和簡化虛擬化代碼的通用方法,它根據虛擬環境與真實環境間切換的邊界信息提取虛擬化代碼,但是此方法一次只能分析一條執行路徑且只能對部分代碼虛擬化進行分析。文獻[13]設計一個虛擬機保護的逆向分析框架,并使用多粒度動態手段和符號實現自動化指令追蹤、虛擬代碼提取和指令精簡。此框架在過濾干擾指令的同時保留有用信息以供分析,但不能保證符號執行所提取虛擬指令的完整性。
針對當前虛擬機保護分析方法對于虛擬指令還原方面存在的不足,本文提出一種結合動態數據流和語義特征分析的虛擬機保護軟件分析算法,利用動態調試將虛擬機解釋器動態執行過程中的數據流信息記錄成Trace文件,并提取虛擬機指令的執行軌跡,精確定位出虛擬機解釋器,然后通過聚類分析識別虛擬機的解釋例程,接著基于虛擬機解釋過程的語義特征采用語義特征分析算法對虛擬機解釋例程的指令執行過程進行局部變量表和操作數棧語義分析。最終結合操作數棧棧頂的變化值、操作數棧的讀次數和局部變量區的讀次數對虛擬指令進行還原。本文算法不僅能正確還原虛擬機保護程序的虛擬指令,而且大大降低逆向分析難度。
1 虛擬機軟件保護技術
本文所指的虛擬機是一種軟件保護架構,其主要思想是用虛擬機可識別的虛擬指令解釋執行宿主程序的受保護代碼,從而在完成軟件正常運行的同時,降低受保護代碼被惡意逆向攻擊的概率[7]。虛擬機保護前后軟件架構如圖1所示。
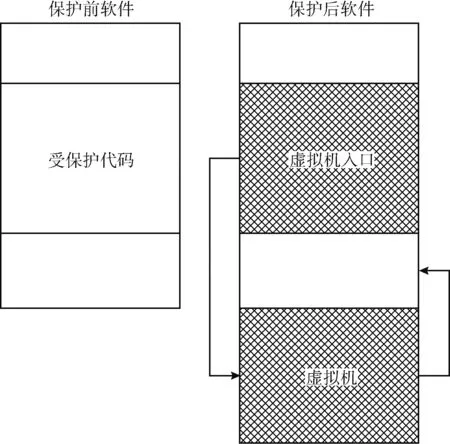
圖1 虛擬機保護的軟件架構
在圖1中,當保護后軟件運行到受保護代碼時,控制流轉向受保護軟件中嵌入的虛擬機執行。虛擬機中的初始化代碼對處理器現場環境進行保存并初始化虛擬機解釋器執行環境,包括對某些寄存器賦初值,將處理器的上下文信息轉移到虛擬機上下文環境等。然后讀取虛擬指令,并對虛擬指令進行解釋執行,直到完成所有虛擬指令的解釋執行。最后,還原處理器現場環境,跳出虛擬機,由處理器繼續執行程序后面未保護的代碼序列。
從圖1可以看出,虛擬機框架核心為虛擬指令集和虛擬機解釋器,其中虛擬機解釋器通常是一個使用宿主機機器指令實現的輕量級虛擬指令解釋器,其解釋執行過程主要包含取指、譯碼、分派和執行4個步驟。根據組織方式不同,虛擬機解釋器分為集中式解釋執行[14]和線索式解釋執行[12],其中集中式解釋執行過程如圖2所示。
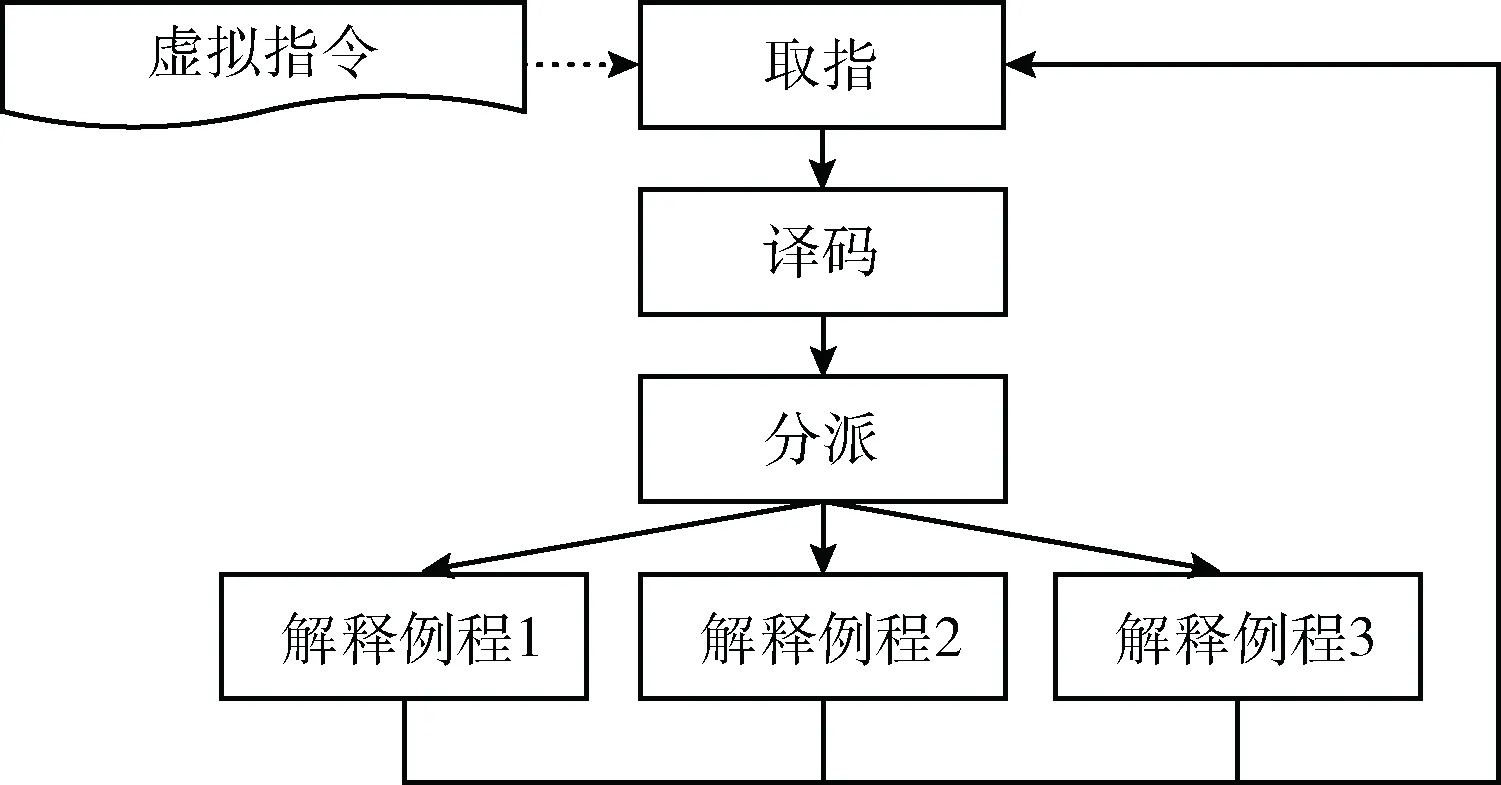
圖2 集中式解釋執行
在圖2中,虛擬機解釋器有一個統一的調度器作為所有虛擬指令的調度者。開始執行后,會取第一條虛擬指令并譯碼后跳轉到它對應的解釋例程,每個解釋例程執行完后,會跳轉回調度器,繼續執行下一個虛擬指令的取指、譯碼和分派后跳轉到它對應的解釋例程,直至整個虛擬指令序列執行完。從圖2可以看出,每個解釋例程結束之后須跳轉至共享的取指、譯碼與分派例程,代碼執行的控制流發生了轉移,不僅增加處理器所需執行的代碼量,而且破壞代碼的空間局部性,增加指令緩存負擔,因此集中式解釋器的性能較低[14]。近年來,一些虛擬機保護軟件采用了線索式解釋執行方式,該方式將取指、譯碼和分派代碼嵌入到每個解釋例程的最后,從而直接由一個解釋例程轉移至另一個解釋例程執行,如圖3所示。
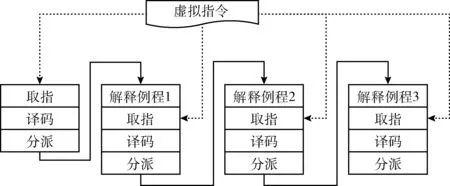
圖3 線索式解釋執行
在圖3中,虛擬機解釋器沒有統一的調度器,每個待執行解釋例程根據其執行的先后順序被串聯起來。開始執行后,會依次執行每個解釋例程,在上一條指令的解釋例程執行完后,控制流會跳到至下一個解釋例程。從圖3可以看出,每個線索式解釋執行有自己獨立的取指、譯碼和分派例程,控制轉移次數大大減少,提高代碼的局部性,減輕指令緩存負擔,從而提升虛擬解釋器的效率。
2 VMP虛擬指令逆向分析算法
2.1 動態追蹤記錄
獲取虛擬機動態執行信息是基于語義特征的虛擬機逆向分析重要環節。為此,本文通過指令動態追蹤的方法記錄虛擬機執行軌跡。一個執行軌跡代表了一個程序在運行中的動態指令的有限序列 {I1,…,In}。 可將虛擬機指令的執行軌跡記錄記作Trace。指令執行軌跡的記錄可以使用TEMU[15]等虛擬機軟件,或者IDA[16]等動態調試器。也可以使用Pin[17]等二進制插樁工具。由于IDA允許嵌入第三方插件腳本,本文選擇IDA調試器來搜集虛擬機保護程序的執行軌跡。圖4顯示了使用IDA調試器的trace功能執行一個被虛擬機保護的函數時,trace記錄了該函數執行的所有匯編指令序列。

圖4 trace記錄的匯編指令序列
從圖4中可以看出,該Trace記錄主要包含了以下信息:①完整執行的匯編指令;②被執行匯編指令的靜態地址;③每條指令執行后被修改的寄存器及其被修改后的值。由于虛擬機的解釋例程中往往采用了代碼混淆保護,實際執行到的指令條數規模龐大。為此,基于緩存延遲寫入技術,將執行期的每條指令的寄存器值和內存讀寫信息記錄為Trace。
2.2 解釋例程語義分析
本小節通過定位虛擬機的動態解釋例程位置,分析這些解釋例程上匯編指令的語義特征,從而確定虛擬指令的含義。虛擬機保護采用的是基于棧的虛擬機,其棧幀包括局部變量表和操作數棧兩個部分。每條虛擬指令在解釋執行時,根據虛擬指令的操作碼,會將操作數在操作數棧中進行計算,并保存在局部變量表中。不同的虛擬操作指令對局部變量表和操作數棧的讀寫次數以及對操作數棧棧頂的改變都有各自的語義特征。通過對這些特征的分析,從而確定它們對應的操作碼語義。圖5顯示了虛擬機解釋例程的語義分析流程。
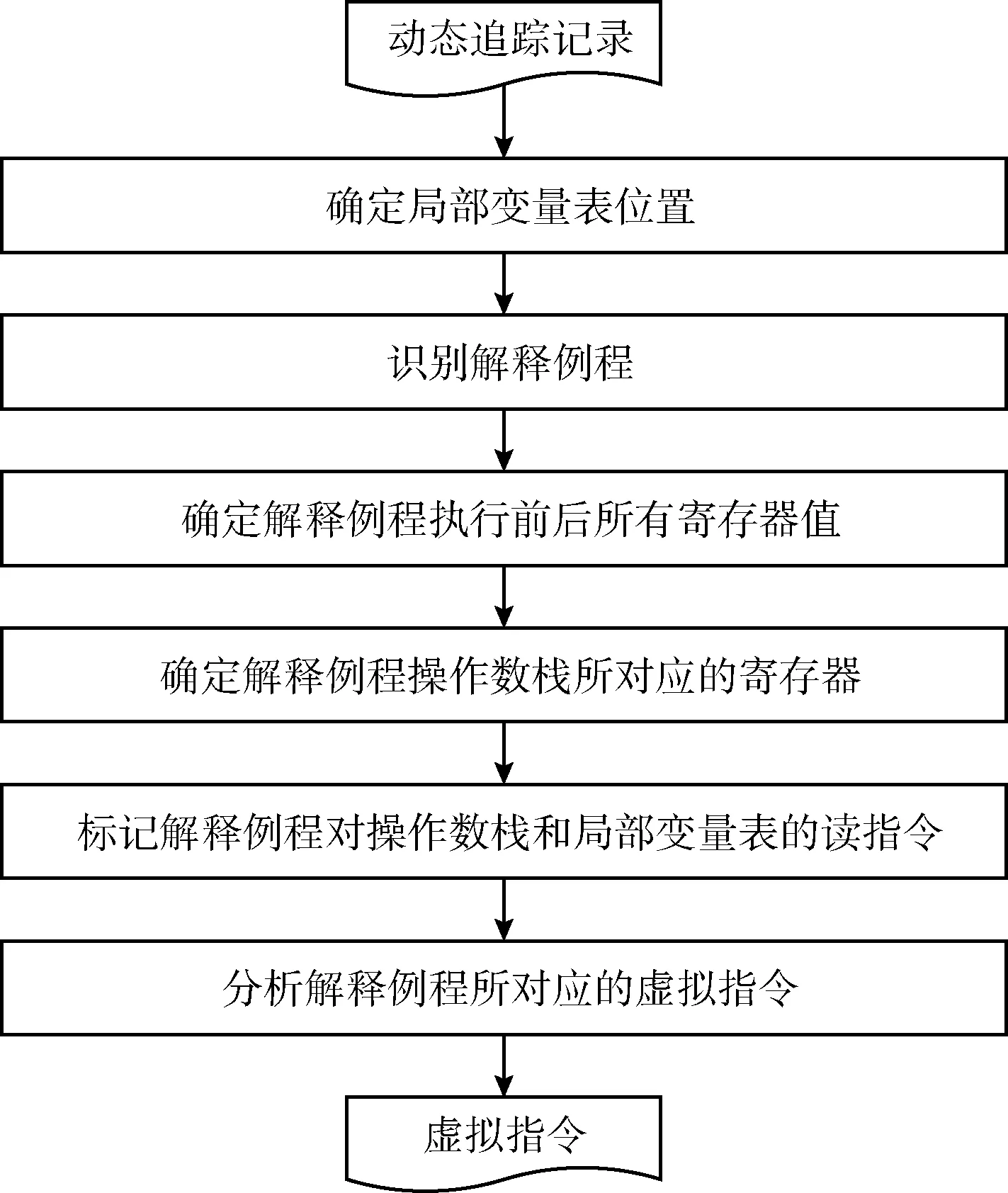
圖5 解釋例程語義分析流程
根據圖5所示的分析流程,具體步驟如下所示。
(1)確定局部變量表位置
當虛擬機保護后的可執行程序運行時,其在進入虛擬機之前,程序會開辟一段內存作為局部變量表。局部變量表的內存位置在離開虛擬機之前不會變化,虛擬機通過指令“sub esp,esp_space”來開辟局部變量表的內存空間,所以通過在進入虛擬機之前的Trace中查找“sub esp,esp_space”,并獲取Trace記錄中該條指令執行后ESP寄存器被修改后的值,即為局部變量表的位置:local_var_table_addr=esp。
(2)識別解釋例程
在大量的虛擬指令序列中,其虛擬機在完成一次解釋執行前,都會表現出固有的特征,比如跳轉到取指令的位置。針對采用線索式解釋執行的虛擬機解釋器,其通過以下兩種方式實現相鄰解釋例程的跳轉。
方式1:
xxxx: push reg
xxxx: ret
方式2:
xxxx: jmp reg
以上兩種方式中,reg的值是下一跳解釋例程的地址,通過在虛擬機的Trace記錄中匹配以上兩種情況可以進行解釋例程的劃分和識別。此外,每一個解釋例程執行結束之前,ESP寄存器都會指向局部變量表的位置,可以以該約束作為解釋例程識別的加強條件。解釋例程識別算法如算法1所示。
算法1:解釋例程識別算法
輸入:動態追蹤記錄(Trace)
輸出:解釋例程集合(vm_handlers)
(1)創建一個新的解釋例程。
(2)輪詢Trace記錄。
(3)獲取一條新指令。
(4)將該指令添加到解釋例程中。
(5)判斷解釋例程跳轉特征模式匹配是否成功?
(6)如果成功,則將當前的解釋例程存入解釋例程集合(vm_handlers)中,并新建一個解釋例程,跳轉到步驟(2)。
(7)如果不成功,判斷是否為最后一條指令?
(8)如果不是最后一條指令,跳轉到步驟(2)。
(9)如是最后一條指令,結束輪詢Trace記錄。
如算法1所示,輪詢Trace記錄,如果匹配到兩種解釋例程的結束特征,則創建一個新的解釋例程實例,之后把輪詢的后續指令添加到該實例中,直至一個新的特征出現,則表示該解釋例程的指令序列結束。以此類推,循環結束后,可以得到所有被執行的解釋例程的實例集合(vm_hanlders)。
(3)確定解釋例程執行前后所有寄存器值
根據步驟(2)識別的解釋例程,確定每個解釋例程執行前后寄存器的值。在虛擬機的Trace記錄中,第1行會顯示每個寄存器的值,之后Trace每條記錄的最后1列記錄每條指令執行后被修改的寄存器及其被修改后的值。根據這兩個條件,可以確定每個解釋例程執行前后所有寄存器的值。使用寄存器作為健值key的兩個map來記錄這兩組狀態,這里分別用vm_handler.enter_status和vm_handler.exit_status表示,如式(1)和式(2)所示

(1)
(2)
其中, key={eax,ebx,ecx,edx,edi,esi,esp,ebp}。 由于操作數棧所對應的寄存器會變化,即不同的解釋例程或者同一個解釋例程的開始和結束時的操作數棧所對應的寄存器可能不同,所以這里使用兩個map來記錄寄存器的動態值,后續步驟會利用這兩個map來計算操作數棧的變化值。確定解釋例程執行前后所有寄存器值算法如算法2所示。
算法2:確定解釋例程執行前后所有寄存器值算法
輸入:解釋例程集合(vm_handlers)
輸出:解釋例程執行前寄存器狀態(vm_hander.enter_status);解釋例程執行后寄存器狀態(vm_handler.exit_status)
(1)遍歷解釋例程集合。
(2)如果是第1個解釋例程,則將第1條指令中的寄存器及其值賦給vm_handler.enter_status和vm_handler.exit_status,即vm_handler(1).enter_status=inst1_status,vm_handler(1).exit_status=inst1_status。
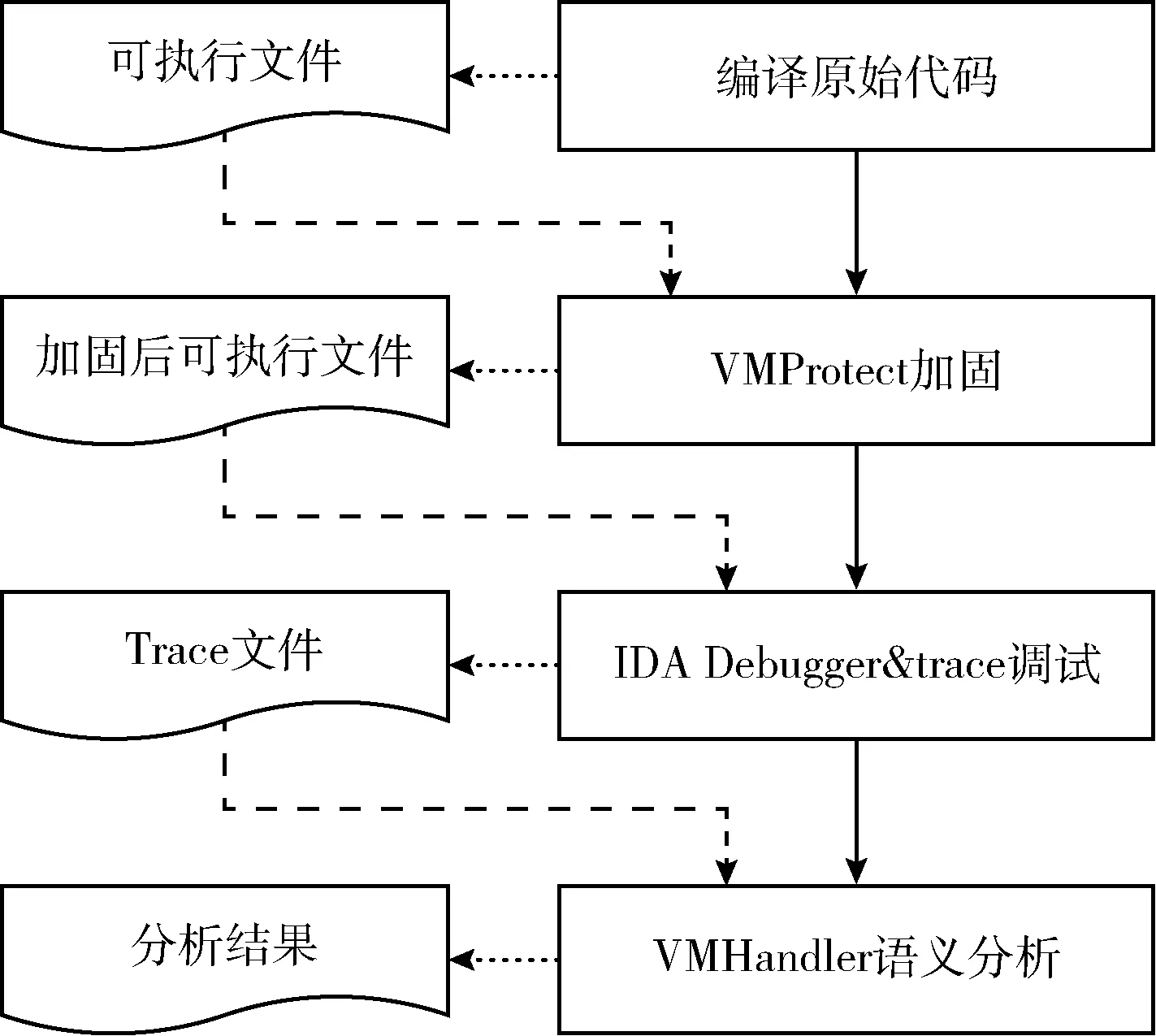
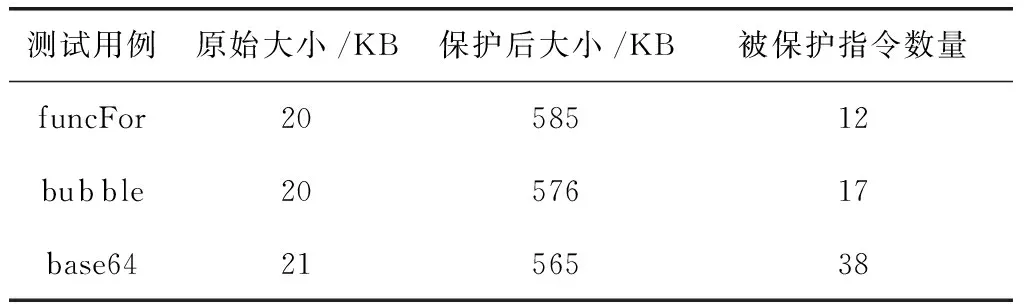
(3)如果不是第1個解釋例程,則將上一個解釋例程的exit_status賦給當前解釋例程的enter_status和exit_status,即vm_handler(i).enter_status=vm_handler(i-1).exit_status,vm_handler(i).exit_status=vm_handler(i-1).exit_status,其中1 (4)遍歷每個解釋例程中的指令。 (5)判斷是否有寄存器的值發生變化? (6)如果有寄存器的值發生變化,則獲取每條指令執行后被修改的寄存器及其被修改后的值,即vm_handler(i).chg_status,其中1≤i≤N。 (7)在vm_handler.exit_status中更新修改的寄存器值,即vm_handler(i).exit_status=vm_handler(i).chg_status,其中1≤i≤N。 在算法2中,inst1_status表示第1條指令寄存器及其值,vm_handler(i).chg_status表示當前解釋例程中修改后的寄存器及其值,N表示解釋例程數。 (4)確定解釋例程操作數棧寄存器 操作數棧所對應的寄存器(op_stack_reg)是指對操作數棧進行尋址的段寄存器。虛擬機中的操作數棧對應的寄存器并不固定,它可能通過寄存器輪轉的方式動態修改。首先確認在進入虛擬機之前,操作數棧所對應的寄存器。其初始匹配特征如下所示 mov reg, esp 通過匹配上述特征,可以找到初始操作棧所對應的寄存器,初始通過ESP寄存器傳遞,之后可能是 {eax,ebx,ecx,edx,edi,esi,esp,ebp} 中的任意寄存器即: op_stack_reg∈{eax,ebx,ecx,edx,edi,esi,esp,ebp}。 設每個解釋例程的操作數棧入口寄存器為op_stack_entry_reg,操作數棧出口寄存器為op_stack_exit_reg,則它們的初始值分別如式(3)和式(4)所示 op_stack_entry_reg = op_stack_reg (3) op_stack_exit_reg = op_stack_reg (4) 然后跟蹤分析操作數棧的變化情況進一步確定每個解釋例程操作數棧所對應的寄存器。虛擬機會通過以下兩種方式切換操作數棧所對應的寄存器。 方式3: xxxx:xchg op_stack_reg, reg1 xxxx:mov reg2, reg1 方式4: xxxx:mov reg, op_stack_reg 根據以上兩種方法所實現的判斷條件都不是強約束,即可能出現符合條件但操作數棧對應的寄存器沒有改變的情況。因此,進一步通過其變化值的范圍來增加識別的準確性,操作數棧用于在解釋執行時存放操作數,每次執行前后的變化范圍與其支持的操作數數量和字長有直接關系。在虛擬機的實現中,算數指令不改變操作數棧棧頂值,加載和存儲指令及操作數棧管理指令改變操作數棧棧頂值的范圍為[-8,8]。解釋例程操作數棧對應寄存器判定算法如算法3所示。 算法3:解釋例程操作數棧對應寄存器判定算法 輸入:解釋例程集合(vm_handlers);當前解釋例程的操作數棧寄存器(op_stack_reg) 輸出:操作數棧入口寄存器(op_stack_entry_reg);操作數棧出口寄存器(op_stack_exit_reg) (1)構建方式3正則表達式的特征匹配字符串。 (2)設置xchg_on標志為False。 (3)遍歷解釋例程集合。 (4)用當前解釋例程的操作數棧寄存器給解釋例程的操作數棧入口寄存器賦值,即op_stack_entry_reg=op_stack_reg。 (5)遍歷每個解釋例程中的指令。 (6)判斷方式3的xchg指令特征模式正則匹配是否成功? (7)如果方式3的xchg指令特征模式正則匹配成功,則設置xchg_on標志為True。 (8)判斷指令的操作數1(inst.op_data1)是否等于操作數棧寄存器? (9)如果指令的操作數1等于操作數棧寄存器,則操作數棧寄存器op_stack_reg等于指令的操作數2(inst.op_data2),即op_stack_reg=inst.op_data2。 (10)如果指令的操作數1不等于操作數棧寄存器,則操作數棧寄存器op_stack_reg等于指令的操作數1,即op_stack_reg=inst.op_data1。 (11)方式3的xchg指令特征模式正則匹配不成功,則判斷方式4特征模式正則匹配是否成功? (12)如果方式4特征模式正則匹配成功,則候選的操作數棧寄存器op_stack_reg_candidate為指令的操作數1,即op_stack_reg_candidate=inst.op_data1。 (13)判斷xchg_on是否為真True? (14)如果xchg_on為真True,則操作數棧寄存器op_stack_reg為指令的操作數1,即op_stack_reg=inst.op_data1。 (15)設置xchg_on標志為假False。 (16)計算操作數棧棧頂變化值op_stack_chg,即op_stack_chg=vm_handler.exit_status [op_stack_reg_candidate]-vm_handler.enter_status[op_stack_entry_reg]。 (17)判斷操作數棧棧頂值op_stack_chg的范圍是否為[-8,8]。 (18)如果操作數棧棧頂值op_stack_chg不在[-8,8]范圍,則出口操作數棧寄存器op_stack_exit_reg為op_stack_reg_candidate,即op_stack_exit_reg=op_stack_reg_candidate。 (19)如果操作數棧棧頂值op_stack_chg在[-8,8]范圍,則出口操作數棧寄存器op_stack_exit_reg為op_stack_reg,即op_stack_exit_reg=op_stack_reg。 在算法3中,遍歷解釋例程中的指令序列,使用正則表達式來匹配所述特征,如果匹配到xchg指令特征,則置xchg_on標志為True。待后續匹配到mov指令特征,認定操作數棧所對應的寄存器發生變化,記錄mov的另一個寄存器為op_stack_reg,并在遍歷結束后設置解釋例程的op_stack_exit_reg值為op_stack_reg。如果在匹配到mov指令特征之前沒有匹配到xchg指令特征,則判定其疑似發生變化并設置op_stack_reg_candidate。在解釋例程指令序列一次遍歷結束后,利用第(3)步驟的exit_status和enter_status判斷操作數棧頂的變化值op_stack_chg。如果按照操作數棧對應寄存器沒變化的情況計算其變化值超出了正常的變化范圍[-8,8],則認定疑似變化的op_stack_reg_candidate是真實變化的情況,修改該解釋例程的op_stack_exit_reg值為op_stack_reg_candidate。 (5)標記解釋例程中對操作數棧和局部變量表讀指令 現在每個解釋例程的操作數棧和局部變量表所對應的寄存器已經可知,以這些寄存器作為查找條件可找到每個解釋例程中對操作數棧和局部變量表讀操作的指令集合,分別如式(5)和式(6)所示 vm_handler.op_stack_insts={Is1,Is2,…Isi,…} (5) vm_handler.local_var_table_insts={Iv1,Iv2,…Ivi,…} (6) 解釋例程中對操作數棧和局部變量表的讀匯編指令特征如下所示 mov regX,[regBase+imm] 以上使用mov指令從對應的操作數棧或者局部變量表區域將數據讀出來。regBase表示操作數棧或者局部變量表對應的寄存器,其中局部變量表對應的寄存器是esp,操作數棧對應的寄存器會變化,由算法4確認。imm表示一個立即數。regX表示本次讀操作的被賦值的寄存器。把以上特征使用正則表達式匹配,其匹配算法描述如下所示: 算法4:解釋例程中對操作數棧和局部變量表讀的指令判定算法 輸入:解釋例程集合(vm_handlers);操作數棧入口寄存器(op_stack_entry_reg) 輸出:局部變量表讀指令(local_var_table_insts);操作數棧讀指令(op_stack_insts) (1)遍歷解釋例程集合。 (2)根據式(3)用操作數棧入口寄存器構建操作數棧讀指令的正則表達式匹配特征。 (3)遍歷每個解釋例程中的指令。 (4)判斷內存地址的讀寫操作。 (5)如果為讀內存地址,則進行局部變量表讀指令特征正則匹配。 (6)如果局部變量表讀指令特征正則匹配成功,則記錄該局部變量表讀指令vm_handler.local_var_table_insts.append(i)。 (7)否則,進行操作數棧讀指令特征正則匹配。 (8)如果操作數棧讀指令特征正則匹配成功,則記錄該操作數棧讀指令vm_handler.op_stack_insts.append(i)。 (6)分析解釋例程對應虛擬指令 基于以上步驟,可以進一步分析每個解釋例程對操作數棧棧頂的變化值(op_stack_chg),對操作數棧的讀次數(op_stack_read_times)和局部變量表的讀次數(local_var_table_read_times)。其中,對操作數棧棧頂的變化值可以根據式(1)和式(2)中的vm_handler.enter_status和vm_handler.exit_status通過式(7)進行計算 vm_handler.op_stack_chg= (7) 另外兩個值根據步驟(5)獲取的指令集合可知,其計算分別如式(8)和式(9)所示 vm_handler.op_stack_read_times= (8) vm_handler.local_var_table_read_times= (9) 根據這3個數據,可以推斷該解釋例程所對應的虛擬指令,將虛擬機的虛擬指令集進行簡化和寬歸類,分別為加載/存儲指令、算術指令、操作數棧管理指令和空指令。其中,加載/存儲指令涉及到一個變量或常量在局部變量表和操作數棧之間的傳遞。針對這類指令,它的典型特征分別是:vm_load加載指令將一個本地變量加載到操作數棧中,那么意味著對操作數棧會有一個壓棧操作,即體現在操作數棧頂變化值為-4或-8,具體的絕對值與壓棧變量的長度有關;另外,還會對局部變量區有1次讀操作。所以,當分析一個解釋例程對操作數棧棧頂的變化值為負數且對局部變量表的讀寫次數不為0,那么就推導其是一個vm_load加載指令。其中,當操作數棧頂變化之為-4時,為vm_iload表示將一個4字節長度的變量加載到操作數棧中,當操作數棧頂變化值為-8,為vm_lload表示將一個8字節長度的變量加載到操作數棧中。對應的,vm_store存儲指令有一個出棧操作,操作數棧的變化值為4或8,且對局部變量區有1次寫操作,其中vm_istore表示將一個4字節長度的數值從操作數棧存儲到局部變量表中,vm_lstore表示將一個8字節長度的數值從操作數棧存儲到局部變量表中。vm_const指令類似vm_load指令,不同的是加載的是常量,所以區別在于對局部變量區沒有讀寫操作。其中,vm_sipush表示將一個2字節的常量加載到操作數棧中,vm_iconst表示4字節的常量加載到操作數棧,vm_lconst表示8字節的常量加載到操作數棧。 算術指令vm_math的語義特征是它會去讀操作數棧而不改變操作數棧頂。讀的次數根據算術符需要操作數的個數。比如取反指令需要1個操作數,加法指令需要2個操作數,除法指令需要3個操作數。分別使用vm_math1、vm_math2 和vm_math3表示有1、2和3個操作數的情況。 操作數棧管理指令vm_pop用于直接控制操作數棧,它會將變量從操作數棧出棧從而改變操作數棧頂值,且對局部變量表沒有讀寫操作。其中,當出棧變量的字長分別為2、4、6和8時,它們對應的虛擬指令分別為vm_sipop、vm_ipop、vm_T6pop、和vm_dpop。 空指令vm_nop在當操作數棧棧頂變化值為0、操作數棧讀寫次數為0且局部變量表讀次數為0時,判定此解釋例程沒有執行任何操作。 根據如上所述,解釋例程的虛擬指令還原算法如算法5所示。 算法5:解釋例程的虛擬指令還原算法 輸入:操作數棧棧頂的變化值(op_stack_chg);對操作數棧的讀次數(op_stack_read_times);對局部變量表的讀次數(local_var_table_read_times) 輸出:解釋例程虛擬指令(byte_code) (1)判斷op_stack_chg操作數棧變化范圍是否為-2,-4或-8? (2)如果是,則進一步判斷局部變量表讀次數local_var_table_read_times是否大于0? (3)如果局部變量表讀次數local_var_table_read_times大于0,虛擬指令為Tload。 (4)如果局部變量表讀次數local_var_table_read_times小于或等于0,虛擬指令為Tconst。 (5)如果不是,則判斷op_stack_chg操作數棧變化范圍是否為0? (6)如果是,判斷操作數棧的讀次數op_stack_read_times是否大于0? (7)如果操作數棧的讀次op_stack_read_times數大于0,虛擬指令為Tmath。 (8)如果操作數棧的讀次數op_stack_read_times小于或等于0,虛擬指令為Tnop。 (9)如果不是,則判斷op_stack_chg操作數棧變化范圍是否為2、4、6或者8? (10)如果是,則進一步判斷局部變量表讀次數local_var_table_read_times是否大于0? (11)如果局部變量表讀次數local_var_table_read_times大于0,虛擬指令為Tstore。 (12)如果局部變量表讀次數local_var_table_read_times小于或等于0,虛擬指令為Tpop。 (13)op_stack_chg操作數棧變化都不屬于以上范圍,則虛擬指令為TUnknown,表示為未知虛擬指令。 為測試和評估本文算法,首先構建了虛擬機保護和逆向環境分別對合成測試用例和第3方的測試用例進行實驗。然后,通過分析逆向還原后的虛擬指令在給定對應輸入下的執行邏輯能否正確,并是否獲得和虛擬機保護前后相同的輸出結果,來驗證逆向還原結果的正確性。最后,分別從虛擬機保護前后和逆向還原后的指令數量比較和簡化效果進行有效性評估。 采用以下軟硬件環境進行測試:i5-4590 3.30 GHz處理器,Windows7操作系統,VS2017編譯環境,VMProtect版本v3.3.1和IDA版本v7.0。此外,用匯編語言和C語言實現待保護的原始代碼,用Python語言實現本文逆向分析算法,測試流程如圖6所示。 圖6 測試流程 在圖6中,每個測試步驟的左側表示該步驟輸出的內容,指向下一個測試步驟的虛線表示作為下一個步驟的輸入。其中,前2個屬于虛擬機加固保護的步驟,后2個步驟是逆向分析的過程。 正確性是指逆向還原后虛擬指令執行的邏輯與原匯編指令相比是否發送變化。根據逆向工程的定義,首先得保證經過逆向還原處理后的程序在功能上與原程序要保持相似或者一致,所以在逆向還原處理過程中必須得充分考慮每一步操作對程序功能將會造成的影響,即應用程序是否能正確進行逆向還原轉換。根據應用程序常見方法的內部邏輯特點及類型,構建funcAdd函數作為測試用例,其接受2個參數,并用匯編指令實現加法操作并返回結果。為了更加直觀地測試分析,直接以匯編指令作為原始輸入。采用VMProtect的API開始保護處標記VMProtectBegin()和結束保護標記VMProtectEnd()指定虛擬化保護的位置區間,其測試代碼如下所示。 __declspec(noinline) int funcAdd(int a, int b) { VMProtectBegin("funcA"); __asm { mov eax, b add a, eax } VMProtectEnd(); return a; } 使用VS2017編譯Release版本的可執行程序,把該可執行文件作為輸入,使用VMProtect v3.3.1進行代碼虛擬化保護,其界面如圖7所示。 圖7 VMProtect界面 VMProtect執行后輸出虛擬機保護的可執行程序,把該可執行程序作為輸入打開IDA,使用IDA Debugger調試該可執行程序,并通過trace記錄該可執行程序的運行指令。以參數7和38調用funcAdd函數,trace記錄共運行了4273條指令。然后把該trace文件作為輸入,使用本文逆向分析算法進行分析,分析結果如下所示。 358: istore_11 0xb50000 413: istore_9 0x21 473: istore_3 0x2bfb38 522: istore_4 0x2dccc0 578: istore_7 0x5aa56314 631: istore_2 0x206 681: istore_10 0x2 729: istore_8 0x15 778: istore_12 0x7efde000 824: istore_0 0xf8a785 870: istore_5 0xc19bf2a7 922: iconst 0x2bfb2c 957: iconst 0x4 1009: math_2 0x2bfb2c <> 0x4 = 0x2bfb30 1049: istore_0 0x216 1104: dpop 1131: iload_3 0x2bfb38 1177: iconst 0xfffffff8 1233: math_2 0x2bfb38 <> 0xfffffff8 = 0x2bfb30 1273: istore_6 0x217 1333: math_1 ldr 0x21 = [0x2bfb30] 1373: istore_14 0x21 1422: iload_14 0x21 1475: iload_3 0x2bfb38 1525: iconst 0xfffffffc 1581: math_2 0x2bfb38 <> 0xfffffffc = 0x2bfb34 1610: istore_13 0x213 1666: math_1 ldr 0x15 = [0x2bfb34] 1708: math_2 0x21 <> 0x15 = 0x36 1747: istore_13 0x206 1800: iload_3 0x2bfb38 1851: iconst 0xfffffffc 1903: math_2 0x2bfb38 <> 0xfffffffc = 0x2bfb34 1932: istore_10 0x213 1982: dpop str [0x2bfb34] = 0x36 2012: iconst 0x4010b3 2067: iload_11 0xb50000 2117: math_2 0x4010b3<>0xb50000 = 0xf510b3 2158: istore_15 0x202 2206: iload_12 0x7efde000 2268: iload_8 0x15 2317: iload_14 0x21 2371: iload_13 0x206 2426: iload_7 0x5aa56314 2476: iload_4 0x2dccc0 2531: iload_3 0x2bfb38 2577: iload_9 0x21 在以上分析結果中,每一行代表一條指令,其中第1列表示行號,第2列表示指令名稱,后面是具體的操作數。以上結果中的 “1708:math_20x21<>0x15=0x36” 虛指令表示2個操作數的算術指令,帶入加法運算驗證可知其確為加法指令。從該虛指令向上分析,根據記錄 “1333:math_1 ldr 0x21=[0x2bfb30]” 和 “1666:math_1ldr 0x15=[0x2bfb34]” 可知,這2個操作數都是使用ldr操作碼分別從不同的內存區域中讀取得到。從該虛指令向下分析,根據記錄 “1982:dpop str[0x2bfb34]=0x36” 可知,其運算結果使用str指令存入0x2bfb34內存區域。如上所述,根據本算法分析出的解釋例程序列,可從結果正確推出原始邏輯是加法操作。 為了證實本文算法逆向工程分析的有效性,下面進一步使用構造函數funcFor、冒泡排序算法bubble和base64編碼算法作為測試用例進行測試,其中funcFor的代碼如下所示。 int funcFor(int a,int b) { VMProtectBegin("funcFor"); int c=b/a; for (int i=0;i a+=b+i; } VMProtectEnd(); return a; } funcFor函數編譯后有12條匯編指令,即VMProtect保護12條匯編指令。然后以參數a=7和b=38調用funcFor函數,運行時其內部for的邏輯循環了5次,整個函數共執行了42條匯編指令;另外,再以參數數組 “{7,11,27,26,55,42}” 調用bubble冒泡排序算法,以參數"JEhu-VodiWr2/F9mixBcaAZTtjx4Rs9cJDLbpEG8i7hPKswcFdsn6MWwINP+Nwmw4AEPpVJevUEvRQbqVMVoLlw=="調用base64編碼算法。 上述3個函數的測試結果分別如表1和表2所示,其中表1表示靜態信息,包括保護前后可執行程序的大小和被保護的指令個數。表2表示動態信息,為VMP保護后程序的逆向分析結果,包括原始運行匯編指令數量、保護后運行的匯編指令數量,分析后得到的虛指令數量和算法分析的時間。 表1 靜態信息 表2 動態信息 從表2可以看出,原始指令執行的數量與虛擬機保護后執行的指令數量基本呈正相關,但bubble和base64并不呈正相關,虛擬機保護后運行的指令數量與分析后的指令數量呈正相關,分析時間與保護后的指令數量呈正相關。VMProtect虛擬化轉換后,匯編指令數量增加量級在500~2500倍左右,經過本算法分析簡化后,指令數量能夠簡化50倍左右。虛指令數量相比于原始指令數量,可獲知VMProtect在作虛擬化轉換時,指令量級增加量在10~50倍左右。因此,基于化簡后的虛指令樣本作進一步分析,能夠極大地降低逆向分析的難度。 由于虛擬機保護采用代碼虛擬化技術加固軟件,現有的靜態指令反匯編及控制流還原等方法逆向分析被虛擬機加固的代碼時存在較大困難。本文提出通過動態Trace數據流分析、聚類分析和特征識別等手段,獲取解釋例程語法語義信息,并將虛擬機動態解釋執行的解釋例程還原成相應的虛擬指令。實驗結果表明了本文算法的正確性和有效性,能夠在保持虛擬指令語義正確性的同時,大大較少逆向分析的指令,從而減輕逆向分析的難度。下一步工作將在對指令進行追蹤記錄時基于處理器硬件直接追蹤和記錄執行過程中的指令,進一步提升動態追蹤的記錄效率。其次,在進行虛擬機解釋例程的劃分識別過程中,可以利用機器學習中的聚類方法對解釋例程的指令特征進行聚類分析,進一步提高解釋例程識別的準確性。此外,虛擬機解釋執行過程的局部變量表和操作數棧語義特征作為本文算法的基礎,后續仍需對其語義相關的指令識別算法進行優化和改進,進一步提高本文算法的覆蓋率和完備性。
vm_handler.exit_status[vm_handler.op_stack_exit_reg]-
vm_handler.enter_status[vm_handler.op_stack_entry _reg]
length(vm_handler.op_stack_insts)
length(vm_handler.local_var_table_insts)3 測試與評估
3.1 測試環境
3.2 正確性測試與評估

3.3 有效性測試與評估

4 結束語
猜你喜歡
科普童話·神秘大偵探(2023年1期)2023-05-30 12:48:10民用飛機設計與研究(2020年4期)2021-01-21 09:15:02瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28當代陜西(2019年10期)2019-06-03 10:12:04測控技術(2018年5期)2018-12-09 09:04:26電子測試(2018年18期)2018-11-14 02:30:34電子制作(2018年18期)2018-11-14 01:48:24數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54山東工業技術(2016年15期)2016-12-01 05:31:22機電信息(2014年27期)2014-02-27 15:53:56
