基于機器學習的浐灞河水質參數遙感反演研究
2022-10-06 03:12:20王喆,連炎清,李曉娜,王璇,方焱,徐新涵
人民長江 2022年9期
王 喆,連 炎 清,李 曉 娜,王 璇,方 焱,徐 新 涵
(1.西安地球環境創新研究院,陜西 西安 710061; 2.中國科學院 地球環境研究所,陜西 西安 710061)
0 引 言
傳統的水質取樣和監測方法過程復雜、周期長、耗費大量的時間精力,且數據的頻次、時效和代表性遠遠滯后于環境管理與決策需求,特別是一些突發性、大范圍的環境質量變化不能被及時捕捉。而遙感技術具有大范圍、低成本、周期性動態監測的優勢,為水質監測和研究開辟了新的途徑,它克服了常規方法主觀性強、監測范圍小、長期趨勢分析困難的缺點,并可發現一些常規方法難以揭示的污染源和污染物的遷移特征,因此在內陸水質監測中發揮著越來越大的作用。
自20世紀70年代以來,遙感開始應用到水質監測研究中[1-2],幾十年來,國內外已經開展多種利用遙感數據建立水質參數反演模型以監測海洋、近岸地帶以及內陸水體水質環境變化的研究,并在估算光學活性參數方面取得了一定成果,如葉綠素a(Chl-a)、有色溶解有機物(CDOM)、濁度和透明度等[3-4]。而像TP、TN等非光學活性參數通常通過與光學活性參數建立關系進行估計。Li等[5]利用新安江水庫2013~2016年的實測水面TN、TP數據與準同步的Landsat8的OLI衛星影像,構建并驗證了2個經驗反演模型,估算了新安江水庫的TN和TP與不同波段組合的相關關系,效果比較理想。黃宇等[6]利用無人機高光譜成像儀,反演了星云湖與茅洲河的水質參數濃度,構建的水質反演模型精度較高。
近年來,隨著人工智能技術的發展,越來越多的研究把機器學習理論融入到水質遙感監測中。機器學習是指通過某些算法指導計算機利用已知數據來訓練模型,并利用訓練后的模型對新數據進行分析或者預測的過程,具有自適應、自學習、高效率和容錯性等優點,且能夠挖掘出數據隱藏的潛在關系和規律,在水質估測方面具有一定的優勢[7]。Guo等[8]采用多種機器學習算法對小型水體的總氮、總磷濃度進行反演,比較了不同算法的反演結果,對于城市排放污水具有一定的識別作用。Pahlevan等[9]采用混合密度網絡(MDN)機器學習模型,應用于內陸和沿海水域的Chl-a濃度的反演,有效提高了訓練數據的全局代表性。Hartling等[10]應用密集卷積網絡(DenseNet)算法,融合多源數據集遙感圖像識別城市環境中的優勢樹種,該方法有效提高了城市優勢樹種的分類準確率。李怡靜等[11]基于梯度提升決策樹算法構建了水質反演模型,該方法反演各類水質的精度較高且速度較快,具有實用價值。李玉翠等[12]在武漢市東湖采用多種經典機器學習算法建立了水質參數與影像反射率間的定量反演模型,并對東湖富營養化程度進行了評價。
浐灞河下游河段位于西安市浐灞生態區,該區是首個西北地區國家級水生態系統保護與修復示范區。該地區水源較為豐富,但受到周邊市區早期工業化與城市化開發的影響,水質較差,并且受早期挖沙采石影響河道破碎化嚴重。近些年經過治理,水環境狀況有了很大改善,但仍需要長期關注且實時監測,具有典型性。以該區域的浐灞河河段為研究區,選取水體中TN、CODMn兩個水質參數,采用人工神經網絡和隨機森林兩種機器學習方法,構建水質遙感反演模型,探究水質參數的時空演化規律。研究成果可為遙感技術監測水質提供借鑒,對于水環境質量提升具有重要的意義。
1 研究區概況及數據源
1.1 研究區概況
本研究以進入西安市城區的浐河灞河下游河段作為研究區域,包括浐河河段(桃花潭公園)和灞河河段(灞橋濕地生態公園)及匯合后至入渭口的河段,如圖1所示。該區域年均降水量小于700 mm,且年內分布不均,7~10月降水量占全年的60%以上。研究區域所在的浐灞生態區是陜西省經濟發展的重要依托,該區承接了上游的農業面源污染,且河段兩岸經濟和工業發達,分布有多個雨水排放口,導致河流水體出現一系列水環境問題,氮素(N)濃度超標、水質惡化等。
1.2 數據采集及處理
收集與水質參數采集時間一致的Sentinel-2衛星遙感數據用于提取水體和水質遙感反演的輸入數據,水質樣點實測數據用于驗證模型精度,以下介紹各數據獲取及處理過程。
1.2.1Sentinel-2數據及預處理
Sentinel-2A衛星于2015年6月23日發射,搭載的有效荷載為多光譜成像(multispectral instrument,MSI)。MSI傳感器有13個波段,分為可見光、近紅外和短波紅外3部分,中心波長范圍為490~2 190 nm。Sentinel-2A衛星的優勢在于更短的訪問周期和高分辨率,能夠更精確地刻畫河道水體。本研究在構建人工神經網絡反演模型時,需要衛星影像數據和水質采樣點時間相近,兩次采樣時間分別為2019年12月與2020年7月,獲取研究區相應時間段的Sentinel-2A衛星數據中的L1C影像數據。Sentinel-2A衛星傳感器的光譜相關參數如表1所列。

表1 Sentinel-2衛星相關參數Tab.1 Parameters of Sentinel-2
1.2.2提取水體范圍
遙感水體提取的發展歷經了幾十年,經歷了從目視解譯到光譜特征提取,自動分類再到光譜與空間信息結合等多個階段。多波段譜間關系法綜合利用了多個波段的光譜信息,提取效果往往要比單波段閾值法要好[13]。因此,本文采用多波段方法提取水體,綜合采用歸一化水體指數NDWI、改進的歸一化水體指數MNDWI、增強水體指數EWI這3種水體指數(見表2),增強水體信息同時抑制其他非水體信息[14],融合不同水體指數的水體提取優勢,利用ENVI5.1軟件中波段運算工具進行各水體指數計算,再對其灰度進行分割,確定最佳閾值,提取各采樣時間段的水體信息。
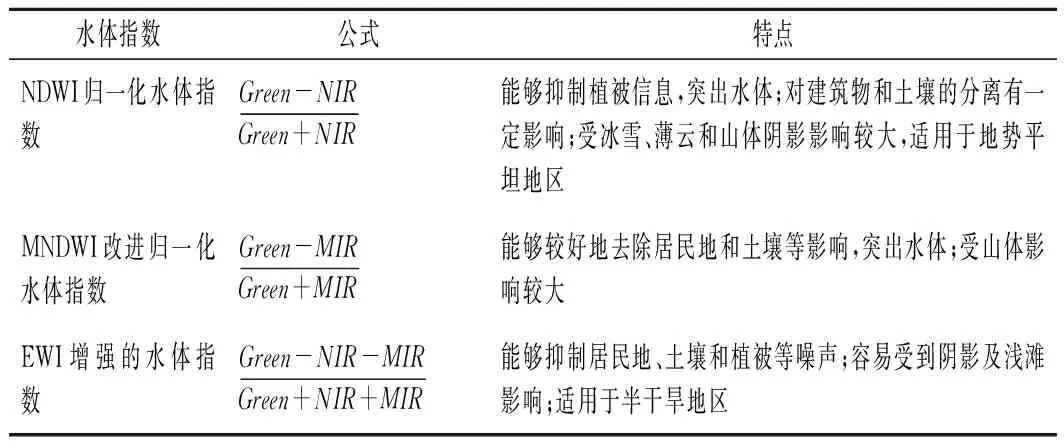
表2 水體指數物理意義及特點Tab.2 Physical significance and characteristics of water index
Sentinel-2衛星的B3波段為綠波段(Green),B8、B8A波段為近紅外波段(NIR),未設置中紅外波段。但是水體在B12波段(中心波長2 202.4 nm,半高寬242 nm)的光譜反射特性與在中紅外波段的反射特性相似,故本文用B12波段代替中紅外波段(MIR)參與波段計算。提取的水體如圖1所示。
1.2.3水質數據采樣及測定
分別在2019年12月(枯水期)和2020年7月(豐水期)選取浐灞河下游段的8個斷面的樣點數據,采樣過程嚴格按照HJ/T 91-2002《地表水和污水監測技術規范》[15]有關要求執行。選擇樣點TN、CODMn兩個水質參數,測定時需添加H2SO4調節。水質參數的測定嚴格按照GB 3838-2002《地表水環境質量標準》[16]執行,數據精度和準確度均符合國家水質檢測方法標準要求。其中,TN采用流動分析儀測定,CODMn采用酸性法測定。
2 研究方法
2.1 構建人工神經網絡模型
人工神經網絡(ANN,Artificial Neural Network)算法是一種強大的分類和回歸算法,其靈感來自于人腦的神經結構[17]。人工神經網絡以多個神經元為隱藏層將輸入數據與輸出數據進行連接,從而挖掘出輸入和輸出數據之間的潛在關系。目前,人工神經網絡在許多研究領域均得到廣泛應用[18-19],比如生物記憶、模式識別、圖像處理、衛星降水量估算、水庫調度。
本文構建的ANN模型將各水質樣點的B2~B8A波段像元值作為模型輸入,輸出模擬的水質參數濃度值,其中水質濃度實測值用于率定和檢驗。水質濃度實測值樣本數量為8個,該模型的隱藏層為單層,隱藏層神經元節點數量為8個(見圖2)。基于Platypus庫調用NSGA-Ⅱ算法優化ANN模型內部權重參數,將算法中種群規模設置為100,評價次數為5萬,二進制交叉算子(SBX)取值為(1.0,15.0),多項式變異概率(PM)取值為(0.125,20.0),完成反演過程。
2.2 構建隨機森林模型
為了充分檢驗ANN模型的擬合效果,選取隨機森林(Random Forests,RF)模型作為比較基準。隨機森林算法是一種通過集成大量的決策樹來改進分類和回歸樹(CART,Classification and Regression Tree)的方法[20]。在隨機森林回歸中,引入的隨機森林算法將自動創建隨機決策樹群,通過從訓練數據集中選擇隨機變量集,并采用隨機有放回抽樣的方法來構建每棵樹[21],最后通過對所有樹的均衡化來計算實測值的估測值。本文基于深度學習框架Tensor Flow構建RF反演模型,涉及的參數包括最大決策樹數量NE、決策樹最大深度MD和最大特征數MF,并采用試錯法確定參數取值為NE50-MD25-MF6。
2.3 留一法交叉驗證水質參數精度
為了驗證求解出來水質指標(TN、TP、CODMn)的代表性和適用性,引入留一法交叉驗證(LOOCV)進行論證[22]。留一法交叉驗證已經被證明能夠有效評價機器學習模型的歸納性特征,并且其結果是幾乎無偏的,且能夠充分利用所有樣本,適用于樣本數量較小的情景。該方法具體步驟為:從樣本數據集中選擇一個樣本數據作為驗證數據;然后使用剩下的樣本數據訓練模型,并用最先被排除的那個樣本數據來驗證模型精度,如此重復8次(樣本個數);最終提取8個樣本的預測結果進行統計分析。本文的采樣點數量為8個,交叉驗證K折數為8。
2.4 評價指標
為評價2種方法反演精度,引入決定系數(R2)與均方根誤差(RMSE)對估測模型進行精度檢驗。計算公式為
(1)
(2)

3 研究結果
3.1 ANN模型與RF模型結果與分析
選擇衛星遙感數據B2、B3、B4、B5、B6、B7、B8、B8A波段及實測水質數據建立水質反演模型。表3~4為反演結果及精度。
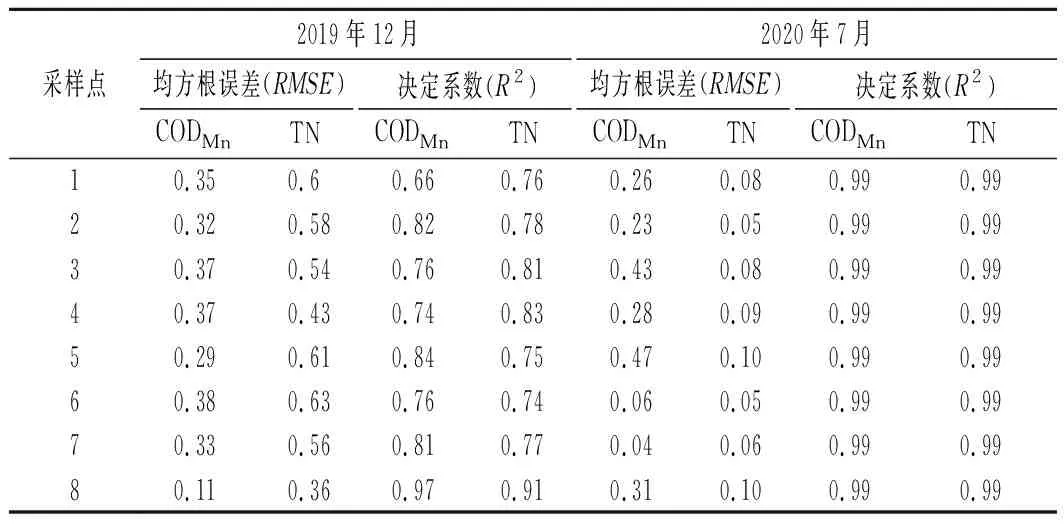
表3 ANN模型各水質參數反演結果均方根誤差與決定系數Tab.3 The inversion results of RMSE and R2 by ANN algorithm
應用留一法交叉驗證法得到ANN模型8個樣點的評價指標值(見表3),得到2019年12月TN、CODMn的平均均方根誤差分別為0.54和0.32,平均決定系數分別為0.79和0.80。由于本文選擇的樣本量較少,在做交叉驗證時可能存在較大的泛化誤差,分別計算了各評價指標的標準差。均方根誤差的標準差分別為0.09和0.08,決定系數的標準差分別為0.05和0.08。2020年7月TN、CODMn的平均均方根誤差分別為0.08和0.26,平均決定系數分別為0.99和0.99,均方根誤差的標準差分別為0.02和0.14,決定系數的標準差分別為0.001和0.001。各個評價指標的標準差較小,表明樣本量少并沒有帶來太大的泛化誤差,模型結果較為可靠。
RF模型各個樣點的評價指標值如表4所列。2019年12月TN、CODMn的平均均方根誤差分別為0.62和0.50,決定系數分別為0.65和0.48,均方根誤差的標準差分別為0.12和0.11,決定系數的標準差分別為0.14和0.22。2020年7月TN、CODMn的平均均方根誤差分別為0.8和4.63,決定系數分別為0.53和0.73,均方根誤差的標準差分別為0.15和1.18,決定系數的標準差分別為0.17和0.15。各個評價指標的標準差較小,表明樣本的泛化誤差較小,模型結果較為可靠。

表4 RF模型各水質參數反演結果均方根誤差與決定系數Tab.4 The inversion results of RMSE and R2 by RF algorithm
對ANN和RF兩種模型的指標評價結果分析可知:ANN模型估算得到的水質參數結果優于RF模型,ANN模型在本文研究區域體現出了優于RF模型的估算性能。因此,本文后續在進行水質參數濃度空間分布時采用ANN估算的水質參數。
3.2 各水質參數空間分布特征
利用ANN模型驗證后的模型參數,輸入水體各波段數值,得到了水體范圍內的水質參數濃度空間分布,如圖3~4所示。
整體來講,跨河建筑物濃度總體上比周圍河段高,世博園的河段CODMn與TN相較于上橋村河段含量較低,上橋村附近河段濃度高于中間河段,這是由于受到點源排放口的影響。
在圖3中,CODMn在2019年12月濃度為2.96~5.62 mg/L,平均值為3.46 mg/L,2020年7月濃度為3.24~13.93 mg/L,平均值為6.64 mg/L。2020年7月濃度值高于2019年12月。從空間分布來看,濃度高值出現在灞河上橋村附近河段、浐灞河交匯處及浐灞河匯合后秦漢大道西段處,這些地方是人口密度較大和工業分布較為集中區域。2020年7月濃度值高于2019年12月,主要原因是CODMn濃度值的變化主要反映的是有機物和生活污染問題,浐灞河周圍分布有大量的居民區和雨污排放口,夏季用水量增加,城市生活污水排放入水體,導致7月濃度整體上高于12月。
如圖4所示,TN在2019年12月濃度為5.30~7.77 mg/L,平均值為5.74 mg/L,2020年7月濃度為4.23~9.00 mg/L,平均值為5.42 mg/L。2019年12月TN值高于2020年7月,但2020年7月濃度變化幅度大于2019年12月,這是因為有幾個區域在7月出現高值,在灞河上橋村附近河段、浐灞河交匯處、浐灞河匯合后奧體隧道到秦漢大道西段河道及入渭口右岸處,原因是這些地方城市生活污水和工業企業廢水大量排放,且附近分布有多個排污口,雖然污水經處理后排放,但仍有大量污染物進入水體。此外,河流周圍還有農業和農村生活污水排放源,接納來自于農田和養殖業產生的污水,降水的季節差異性導致12月整體濃度值高于7月[23]。浐河河段TN濃度值呈現出12月整體上高于7月,同樣是由于大量居民日常生活的污水和工業生產的廢水在降水的季節性變化下引起的[24]。
4 結 論
本研究以浐灞河下游河段為研究河段,采用人工神經網絡和隨機森林兩種機器學習算法構建水質參數遙感反演模型,對水體中的TN、CODMn兩個水質參數進行遙感反演研究,主要得到了以下結論:
(1)本文基于Sentinel-2衛星遙感影像數據,融合多種水體指數法的優勢,更準確地提取了研究區河道水體。
(2)采用人工神經網絡算法與隨機森林算法,根據實測水質樣點參數CODMn與TN,構建了水質反演模型,經過對比分析,人工神經網絡模型在該地區具有良好的適用性。
(3)將ANN模型應用于整個河段水體,得到水質參數CODMn和TN的空間分布和變化特征,整體上水質參數波動較小,空間分布較為均勻,部分區域出現高值,可能與人類活動有關。此外,CODMn與TN也呈現出季節性規律,這與人類活動的季節性有關。當前,河流在遙感領域受到的關注相對較少,部分原因是河流空間尺度較小(<100 km)和水質參數變動范圍大。而長江水系水量較為豐沛,本文構建的水質監測模型對于長江流域水環境實時監測具有重要的參考價值,對于水環境質量提升具有借鑒意義。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
環境(2023年5期)2023-06-30 01:20:01
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
當代水產(2019年1期)2019-05-16 02:42:04
當代水產(2019年3期)2019-05-14 05:42:48
電子制作(2018年14期)2018-08-21 01:38:16
光學精密工程(2016年6期)2016-11-07 09:07:19
水利規劃與設計(2016年7期)2016-02-28 15:06:27
核科學與工程(2015年4期)2015-09-26 11:59:03
