基于混合監督式學習的輸電斷面功率極限快速評估方法
2022-10-09 11:30:18刁瑞盛徐建平
浙江電力 2022年9期
張 靜,葉 琳,刁瑞盛,徐建平,呂 勤
(1.國網浙江省電力有限公司,杭州 310007;2.國電南瑞南京控制系統有限公司,南京 211106;3.國網浙江省電力有限公司金華供電公司,浙江 金華 321000;)
0 引言
新型電力系統規劃與運行亟需解決高比例可再生能源帶來的間歇性、隨機性和不確定性等一系列難題。其中,及時、準確地評估大電網輸電斷面功率傳輸極限是保障電網安全、穩定、經濟運行的重要一環。功率極限的計算需考慮不同故障工況下的多種安全約束,使用電網模型進行大量潮流、暫態穩定、電壓穩定仿真計算,該過程通常需要占用大量在線計算資源,影響大規模電網區域間功率極限評估的實時性。
輸電斷面功率極限的制定通常采用離線方法,即針對電網未來典型運行方式(綜合考慮負荷水平、發電計劃、可再生能源出力、設備檢修計劃等因素)進行建模,首先生成收斂的基態潮流文件;然后,使用生成的基態潮流文件,在多種工況下進行批量仿真分析,搜索滿足電網電壓安全、頻率安全、暫態穩定性、電壓穩定性等多種約束的功率極限。可再生能源占比不斷提升導致的不確定性和電網的高復雜性和非線性,迫使輸電斷面傳輸極限的計算和使用趨于保守。為了更精準地評估傳輸極限以提升電網的安全穩定性和經濟性,國外(尤其是北美)ISO(獨立系統運營商)較為通用的方法是針對電網建立高精度運行模型,使用EMS(能量管理系統)生成可靠的實時運行工況潮流文件(5~15 min 為1 個周期),并搜索實時輸電極限,該過程通常需要占用大量計算資源。由于電網持續增大的規模和建模復雜度,考慮多種安全約束和完整“N-1”(或“N-k”)故障列表的在線安全穩定仿真將耗費大量計算時間和資源,難以滿足新型電力系統安全運行的實時性需求。因此,新型電力系統建設迫切需要快速、精準的在線評估方法來實現該目標。
為此,本文提出基于混合監督式學習算法的輸電斷面功率極限快速評估方法。首先收集海量電網運行方式(含歷史工況、檢修計劃、未來規劃信息等);針對每種電網運行方式,使用高精度建模仿真引擎進行給定故障下的功率極限仿真計算;提取電網穩態運行信息作為數據特征,并以輸電斷面功率極限作為預測目標,形成訓練樣本庫;進一步將樣本庫拆分為訓練集、驗證集和測試集;最終使用混合型監督式學習算法訓練預測模型并滾動更新,確保輸電斷面功率極限預測模型的長期有效性。
1 電網輸電斷面功率極限建模及計算方法
網絡阻塞是高比例可再生能源背景下新型電力系統面臨的重要挑戰之一,一旦輸電斷面實測功率超過其功率極限值,電網調度運行人員需要及時采取有效控制措施,將斷面功率控制在限值之下,以保證電網安全運行。每年世界范圍內由于電網阻塞導致的額外成本多達數十億美元。提高電網輸電能力最直接的方式是新建輸電線路等設備,但是其投資巨大,而且建設周期較長。因此,在滿足多種安全約束下提升現有輸線路功率傳輸容量,即“動態增容”,是行之有效的解決方法。
評估輸電斷面功率極限需要考慮基態和故障工況下的多種安全約束,包括熱穩極限、穩定性極限、電壓安全極限等。圖1 給出了以“2 區4 機”系統為例的輸電斷面功率極限計算的主要流程。主要包括以下步驟:

圖1 輸電斷面功率極限計算流程
步驟1:針對電網不同運行方式,綜合考慮電網基態信息、發電計劃、檢修計劃、負荷變化、可再生能源出力變化以及故障集,通過仿真生成合理運行方式文件(收斂的潮流斷面文件)。
步驟2:指定輸電斷面和功率調整策略(包括發電機出力調整、負荷調整等),增大或減小輸電斷面功率,同時掃描故障情況下輸電線路過載情況、電壓安全情況和電網穩定性(包括暫態穩定、電壓穩定和小信號穩定);如果沒有安全性問題,則繼續增大或減小輸電斷面功率。該過程持續至電網中發生安全、穩定性問題。
步驟3:通過電網仿真得出不同安全約束下的功率極限值,最終取最小值作為輸電斷面的功率極限。
該方法目前在北美電力系統規劃與調度部門應用廣泛,且已有商用軟件。但對于擁有多條輸電斷面的復雜大電網,考慮所有模型細節和完整故障列表的功率極限掃描需要占用大量計算資源,難以保證功率極限計算結果的實時性。
2 人工智能技術與監督式學習算法
2.1 機器學習簡介
AI(人工智能)技術起源于1956年達特茅斯學院會議,是指“數字計算機和計算機控制的機器人執行通常由智能生物體所完成的任務的能力”。近年來,AI 技術在自動駕駛汽車、生物信息識別以及眾多其他領域的成功應用顯示了其巨大潛力。在工程應用領域,機器學習算法是AI的重要組成部分,包括以下3個分支:
1)監督式學習通過訓練AI模型來建立輸入和輸出信息的匹配。用于訓練的樣本通常有明確的標記(類型或數值)。典型應用包括圖像分類、數值預測、過程優化、行為識別等。經典算法包括人工神經網絡、決策樹、隨機森林、SVR(支持向量回歸)、梯度提升機等。
2)無監督式學習通常用于聚類分析、大數據可視化、結構探索等,其訓練模型所用的樣本沒有特定標記。經典算法包括主成分分析、Kmeans等。
3)強化學習是為了達到特定控制目標所設計。強化學習智能體的訓練過程需要與環境進行大量交互,通過獎勵值的設計使得智能體不斷學習、演化,最終達到預期的控制性能。經典算法包括DQN(深度Q網絡)、DDPG(深度確定策略梯度)、PPO(近端優化策略)、SAC(最大熵)等。
機器學習算法在電力系統中的研究和應用多體現在負荷預測、可再生能源預測、異常監測、電壓安全和穩定性在線評估、自動電壓和潮流控制等方面[1-14],應用于輸電斷面功率極限評估的研究則鮮見報道。
2.2 監督式學習算法
2.2.1 人工神經網絡
ANN(人工神經網絡)是監督式學習的經典算法,可在復雜環境中建立多維輸入與多維輸出間的非線性匹配關系。作為一種表征學習方法,ANN 通常由輸入層、隱藏層和輸出層3 個部分組成,每層可包含若干神經元。ANN的構建包括線性變換函數〔式(1)〕、非線性激活函數〔式(2)〕、代價函數〔式(3)〕,其中含有誤差項和修正項:誤差項用來評估ANN樣本集擬合的好壞程度;修正項通過控制復雜度的方式防止過擬合現象。

式中:h(k)為第k個神經元函數;W為權重向量;f(·)為非線性激活函數;J(W,b)為代價函數;hW,b(·)為擬合結果;x和y分別為自變量輸入和輸出;b為偏置。
ANN 的訓練過程以最小化代價函數為目標,可以用隨機梯度下降法求解:

式中:wi為W的元素;Δ為變化量。
DNN(深度神經網絡)特指ANN 結構中含有許多隱藏層。
2.2.2 支持向量回歸
SVR 算法是用于解決分類問題的SVM(支持向量機)的一個分支,在1996年由Vladimir Vapnik等學者提出,可用于回歸分析,針對數值型目標進行預測。與SVM解決分類問題不同,SVR模型訓練的過程僅取決于訓練樣本庫的一個子集,因為訓練SVR 模型時計算的代價函數無需考慮邊界以外的樣本。SVR的訓練過程可描述為:

式中:xi為訓練樣本的數據特征;yi為目標值;=<W,xi>+b為第i個樣本的預測值;ε為誤差閾值。SVR 訓練過程中需要確保所有預測值都在偏差范圍ε以內。若該問題無解,則可通過添加松弛變量的方式得到近似解。
2.2.3 隨機森林
隨機森林是機器學習領域中的一種有效算法,可用于求解分類和回歸問題,其核心在于訓練預測多種模型,并綜合考慮多種預測模型輸出給出平均預測值,可有效修正單個決策樹模型過擬合問題,整體提升預測精度。隨機森林通常使用引導聚集算法。給定訓練集合數據特征向量X=(x1,x2,…,xn)和響應向量Y=(y1,y2,…,yn),重復K次訓練(每次訓練隨機選取n個樣本),對于第k次訓練使用以下算法分別訓練決策樹模型:
1)隨機選取n個樣本,獲取數據特征與響應向量Xk和Yk。
2)使用Xk和Yk作為訓練集,訓練模型fk。
使用隨機森林集成決策樹模型進行預測時,針對未知樣本數據特征,使用上述模型輸出平均值作為最終預測輸出,即:
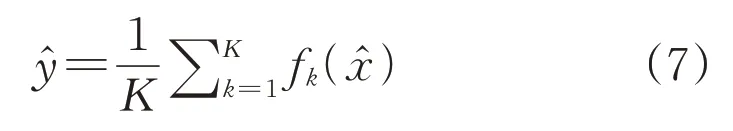
據報道,隨機森林的預測性能通常優于單個決策樹,但通常被認作“黑箱”模型,犧牲了單個決策樹模型的內在可解釋性。
2.2.4 梯度提升決策樹
類似于隨機森林算法,GBRT(梯度提升決策樹)的訓練過程也涉及到集成模型,但實現算法有所不同。梯度提升技術本質上是多回歸決策樹的集成模型,初始化一個常數模型,通過估計一個參數來最小化總體損失。然后,在每次迭代中訓練回歸決策樹,使經驗風險最小化。因此,訓練過程可以看作是函數空間中的梯度下降,在每次迭代中生長一棵樹來估計目標函數的梯度。為了減少過擬合,使用不同的學習率,并對模型進行不斷更新。該過程不斷重復,直到M棵樹長成。目前比較常用的梯度提升方法包括XGBoost、LightGBM和CatBoost。
3 基于混合監督式學習的輸電斷面功率極限快速評估方法
3.1 方法原理
本文采用監督式學習算法訓練AI模型,可對輸電斷面功率極限進行在線評估。該方法的框架如圖2所示。
3.1.1 運行方式生成
針對電網不同運行方式,采集大量(數月或數年)電網斷面潮流以及SCADA(數據采集與監控系統)數據,通過潮流計算得出收斂的電網運行狀態;針對未來運行工況,可通過添加負荷預測、可再生能源預測、檢修計劃、發電計劃等信息形成具有典型運行特征的電網運行方式文件。
3.1.2 輸電斷面功率極限計算
使用圖2所示方法流程和運行方式生成模塊的輸出,對電網不同運行方式i進行仿真分析,綜合考慮熱極限TL(i)、電壓極限VL(i)和穩定性極限SL(i),得出相應運行方式的輸電斷面功率傳輸極限值CL(i):

圖2 基于機器學習的輸電斷面功率極限評估方法
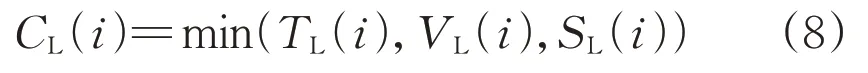
3.1.3 樣本庫生成
使用大量仿真數據可形成有效樣本庫對智能體進行訓練。本文所提方法中使用潮流態信息作為數據特征,包括發電機有功功率Pgen、發電機無功功率Qgen、線路有功功率Pline、線路無功功率Qline、負荷有功功率Pload、負荷無功功率Qload、母線電壓幅值Vm和母線電壓相角Va。針對每條訓練樣本記錄,歸一化處理不同類型數據特征,最終形成一維向量作為機器學習模型的輸入信息。模型的輸出信息定義為選中輸電斷面功率極限值。該樣本庫的生成方式如圖3所示,其中Ngen為發電機總數,Nload為負荷總數,Nline為線路總數,Nbus為母線總數。

圖3 樣本庫數據特征與預測目標
3.1.4 模型訓練
為了實現在線精準評估輸電斷面功率極限,本文采用多種監督式學習算法訓練模型,并從中選出最優模型,供在線應用。首先將樣本庫按一定比例隨機拆分為訓練集(例如占比80%)、驗證集(例如占比10%)和測試集(例如占比10%),其中訓練集和驗證集用來調試模型超參數以提升性能。
本文采用的算法包括DNN、隨機森林、SVR、GBRT 等。在模型訓練過程中需要進行超參數調節,即使用多核并行計算資源在超參數空間搜索驗證集中表現最好的模型,以提升模型整體準確性和可靠性。該模塊的最終輸出是不同算法模型中表現最好的算法。
3.1.5 模型應用與更新
使用上述過程生成的測試集,來評估經過調參后的機器學習模型在未知樣本集中的預測性能。最終,需要使用搜索到的最優超參數和所有可用樣本重新訓練模型,以供實時應用。值得注意的是,為了保證該方法的長期有效,需定期將新采集到的樣本加入至樣本庫中,不斷迭代以提升模型準確度和長期有效性。同時,可使用多種表現優異的算法進行加權平均,以提升整體功率極限評估的準確性,即:

式中:CL_final(i)為時刻i被用于實時調度運行的輸電極限評估值;M為所選擇的模型總數;θ為常數系數,且滿足CL(i,m)為時刻i第m種模型的功率極限值。
3.2 方法實現
本文所提方法中電網模型和運行數據可通過建模仿真手段或采集電網真實運行方式獲取,并以通用的文本文件形式保存;考慮多種安全約束下的輸電斷面功率極限計算可通過電力系統商業仿真軟件獲取;樣本庫的采集、機器學習模型框架搭建、模型訓練與超參數調節則通過Python3.7、Tensorflow、Keras等函數庫實現。
4 算例分析及討論
4.1 500節點電網模型
本文使用帶有真實運行特性的500節點電網模型測試所提方法的有效性。該開源模型及運行數據在美國能源部ARPA-E資助下由西北太平洋國家實驗室研發生成。該系統模型由多個脫敏后的真實電網子區域“縫合”并調整而生成,其運行數據代表1 h時間間隔的電網運行工況,綜合考慮負荷變化、發電計劃、“N-1”安全性等安全約束。該系統模型拓撲單線圖如圖4所示,模型的電力設備統計信息見表1。

圖4 500節點系統單線圖

表1 500節點電網模型信息
4.2 樣本庫生成
為了充分測試所提算法的有效性,本文使用500節點系統基態模型和電網典型運行特性,生成了8 000個運行工況,代表8 000 h的連續電網運行狀態。樣本生成過程中首先將系統負荷變化、發電計劃等信息添加至電網基態模型中,并計算潮流得到收斂解。如果出現線路過載、電壓越限等問題,則調整相應發電機組有功、無功和電壓控制設備,確保所產生樣本滿足安全性要求。以圖5中輸電斷面為例,連接在母線547上的3臺機組向右側區域送電,該輸電斷面由5條線路組成,包括線 路547-548、547-559、547-549、544-547、545-547。

圖5 輸電斷面單線圖
由于網絡結構的特殊性,該輸電斷面功率極限受限于暫態穩定性約束。使用圖1所述方法針對不同拓撲運行方式下的功率極限進行仿真計算,可以得出考慮多種安全約束下的功率極限值,如圖6(拓撲A—線路故障1)、圖7(拓撲B—線路故障2)所示。按照圖2 所示方法,形成樣本庫,并拆分為訓練集、驗證集和測試集。

圖6 輸電斷面功率極限(拓撲A)

圖7 輸電斷面功率極限(拓撲B)
4.3 模型性能比較
針對電網不同故障后的拓撲A和拓撲B工況,分別使用多種機器學習算法來訓練輸電斷面功率極限預測模型。在本文的兩個算例中,分別訓練了GBRT、SVR、DNN、隨機森林模型。經過超參數調節后的模型性能對比如圖8和圖9所示,相應的RMSE(均方根誤差)、MAE(平均絕對誤差)和MAPE(平均百分比絕對誤差)見表2、表3。在拓撲A 工況下,GBRT 和隨機森林算法在測試集中的MAPE為1.565 7%和1.799 5%;在拓撲B工況下,GBRT 和隨機森林算法在測試集中的MAPE為0.976 8%和1.096 8%。

表2 誤差對比(拓撲A)
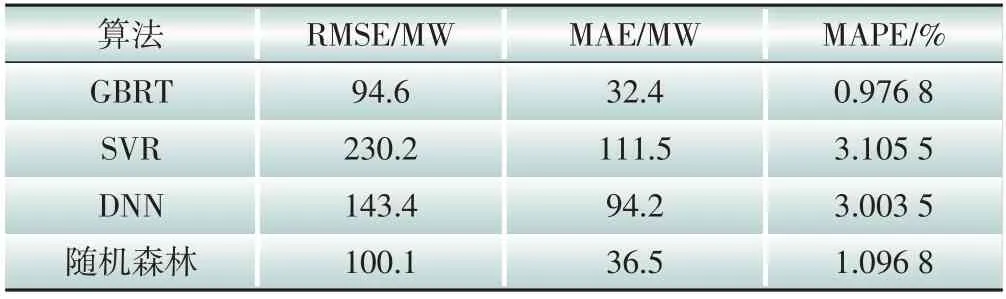
表3 誤差對比(拓撲B)

圖9 輸電斷面功率極限預測性能(拓撲B)

圖8 輸電斷面功率極限預測性能(拓撲A)
由測試結果比對可以看出,使用本文所提方法可以有效訓練監督式學習智能體模型,準確地在線評估輸電斷面功率極限值,其中GBRT 和隨機森林兩種模型效果最好。為了提升該方法的整體預測精度,可同時使用GBRT和隨機森林算法,并對相應結果進行加權平均,用于實時應用。
5 結語
為解決含高比例可再生能源的新型電力系統功率極限在線評估難題,本文提出了一種基于監督式機器學習算法的輸電斷面功率極限評估方法,可通過自動超參數調節訓練并定期預測模型,確保該方法的長期有效性。該方法的有效性在帶有真實運行特性的500 節點輸電網模型中得到了驗證。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
