支持多模態網絡的可擴展異構服務功能鏈并行編排部署系統
2022-10-09 12:47:58陳浩楊芫徐明偉裴丹尤藝霖
通信學報 2022年9期
陳浩,楊芫,徐明偉,4,裴丹,尤藝霖
(1.清華大學計算機科學與技術系,北京 100084;2.北京信息科學與技術國家研究中心,北京 100084;3.中關村實驗室,北京 100083;4.清華大學網絡科學與網絡空間研究院,北京 100084)
0 引言
隨著網絡功能虛擬化(NFV,network function virtualization)技術和虛擬網絡功能即服務(VNFaaS,virtual network function as a service)的興起[1-2],越來越多的公有云平臺,如Amazon Web Services、Google Cloud、Azure、AliCloud 等開始提供服務功能鏈(SFC,service function chain)服務。SFC 通常由多個虛擬網絡功能(VNF,virtual network function)串聯組成,如防火墻、負載均衡器等。多個串聯的網絡功能共同為租戶的網絡提供安全和性能優化等服務。過去,租戶通常采購硬件網絡功能在其本地網絡部署SFC。近年來,租戶為了節省資本支出(CAPEX,capital expenditure)和運維成本(OPEX,operating expense),開始選擇將SFC外包給公有云。在外包的過程中,租戶向公有云提交SFC 請求,而公有云的SFC 編排部署系統負責在數據中心內編排、部署這些SFC 請求。編排(又稱資源編排)是指在眾多功能基礎設施中選擇一部分設施來承載租戶提出的SFC 請求。具體而言,編排SFC 的過程包括:1) 計算SFC 中每個VNF 應被部署于哪一臺功能基礎設施上(如服務器);2) 計算SFC 中相鄰的2 個VNF 之間的網絡轉發路徑。部署SFC 的過程包括:1)在相應的功能基礎設施上啟動VNF 進程實例;2)下發流表實現SFC 建鏈[3]。
隨著租戶對個性化需求的提升和多元化終端的發展,多模態網絡[4]這一概念被提出。多模態網絡在數據層依托多種異構的全維可定義功能基礎平臺,借助控制層支持多模態尋址路由功能的控制器和服務層的“感知、決策、執行”一體的管理系統,滿足租戶專業化的需求。在多模態網絡中,數據中心作為重要的場景,其中的SFC 編排部署系統需要能夠結合上層租戶的需求和下層網絡的服務能力來管理網絡資源并承載業務。具體來說,多模態數據中心網絡中的SFC 編排部署系統面臨以下兩方面的問題。
首先,多模態網絡的服務層需要結合上層租戶的個性化需求實現SFC 編排部署。近幾年,租戶逐漸要求SFC 具有彈性擴容能力以應對流量的動態變化,公有云需要對租戶的SFC 進行擴容編排部署,從而保證租戶的業務不受影響[5-6]。隨著租戶對服務質量需求的提升,在未來多模態網絡中提供秒級的擴容編排部署變得十分重要。隨著數據中心網絡規模的增加,一個中型數據中心已經具備上萬臺服務器和上千臺交換機,低性能的SFC 編排部署系統設計很容易導致擴容編排部署時間過長,降低租戶的服務體驗。
其次,多模態數據中心網絡存在異構的功能基礎設施,如商用X86 平臺和基于Tofino 芯片的P4交換機[7]等,并且未來可能會加入新型功能基礎設施。多種異構功能基礎設施加劇了數據中心的管理復雜程度,對SFC 編排部署系統的軟件設計提出了很大的挑戰。
綜上所述,支持多模態的數據中心網絡中的SFC 編排部署系統需要同時滿足以下需求。
1) 管理萬臺服務器規模的數據中心,實現秒級的SFC 彈性擴容編排部署。
2) 支持在異構功能基礎設施上開展SFC 的統一編排和部署,其中異構設施至少包括基于X86 平臺的服務器和基于可編程芯片的交換機。
如何在未來多模態的大規模數據中心網絡中滿足以上需求是SFC 編排部署系統需要面對的重要問題。
學術界已經提出了一些SFC 編排部署系統,如Stratos[8]、NFV-RT[9]、Apple[10]、Hyper[11]、MicroNF[12]。Stratos、Apple 和NFV-RT 的擴容編排時間復雜度較高且不支持異構SFC 的編排部署。Hyper 和MicroNF 能夠對異構設備進行編排部署,但是它們不具備彈性擴容編排部署能力。Daisy[13]是為千臺服務器規模的數據中心設計的SFC 編排部署系統,然而它的可擴展性不足以勝任萬臺服務器規模的數據中心。Daisy 采用的編排算法的計算時間與拓撲規模近似且成正比,因此當拓撲規模較大時,Daisy 的編排時間會超過1 min。例如,在1 536 臺服務器構成的Leaf-Spine 數據中心網絡中,Daisy擴容5 Tbit/s 的SFC 所需的編排時間達到了247 s。綜上所述,以上編排部署系統均無法滿足在萬臺服務器的數據中心網絡內實現秒級擴容編排部署這一個性化需求。
在多模態網絡中,異構SFC 編排部署系統面臨的最大挑戰是高可擴展性。具體而言,本文的目標是在萬臺服務器規模的數據中心中實現秒級的擴容編排部署。為應對這一挑戰,可以利用數據中心網絡拓撲結構的特點對其進行分區,將每次編排決策的區域限制在一個分區內便可減少編排時間。進一步地,多個分區的編排任務可以通過增加編排算法實例的方式實現并行的擴容編排,進一步減少SFC 的擴容編排時間。
本文設計并實現了支持多模態網絡環境的可擴展異構服務功能鏈并行編排部署(SHOD,scalable heterogeneous SFC parallel orchestration and deployment)系統。SHOD 系統將數據中心劃分為多個不相交的分區,避免分區不連續或多個分區重疊導致的SFC 編排失敗,從而保證SFC 編排部署的正確性。不同于已有的SFC 編排部署系統采用的單一編排器設計方案,SHOD 系統采用分區并行編排的思路,通過負載均衡的方法將不同的SFC 擴容請求分配到不同的編排器實例,保證耗時最長的一個編排器實例的編排時間在秒級。客觀上,增加編排器數量必然會減少擴容編排時間,然而過多的編排器實例會占用過多的計算存儲資源。為了最優化編排器實例數量,SHOD 系統構建了期望編排時間模型,根據該模型計算出滿足期望編排時間的最少編排器數量。此外,SHOD 系統還采用了中介者設計模式來提供對異構SFC 的支持,實現了對基于X86 服務器、P4 可編程設備甚至新型多模態功能基礎設施的網絡功能的統一編排部署與建鏈。
本文的主要貢獻如下。
1) 不同于已有SFC 編排部署系統的單編排器設計,本文提出了基于并行編排器設計的可擴展SFC 編排部署系統,可以支持萬臺服務器規模的數據中心的秒級擴容編排。
2) 不同于已有的異構SFC 編排部署系統,SHOD 系統采用了符合單一權職原則的中介者設計模式,使新型異構功能基礎設施及其控制器可以靈活加入系統,而不需要修改編排器。
3) 實現了SHOD 原型系統,支持基于Fastclick的容器化VNF[14]和基于P4[15]可編程交換機的網絡功能,實驗結果顯示,SHOD 系統可以實現秒級異構SFC 編排部署。
1 相關工作
近年來,學術界出現了很多關于SFC 編排部署系統的研究工作[8-13]。Stratos[8]是一個支持SFC 水平擴展的SFC 編排部署系統,其系統結構可以分為轉發器控制器和資源管理器兩部分。轉發控制器負責向交換機下發流表并建立新的SFC。資源管理器包括SFC 資源瓶頸檢測器和水平擴展模塊。當檢測器檢測到服務器資源不足時,Stratos 會啟動新的VNF 實例;當檢測到網絡帶寬不足時,Stratos 會將SFC 遷移到網絡不擁塞的區域。Stratos 的平均編排速度大約為每秒67 條SFC,不足以滿足大規模數據中心內秒級的編排需求。
NFV-RT[9]是為數據中心網絡設計的SFC 編排部署系統,其系統結構包括控制器和資源管理器兩部分。NFV-RT 對所有的SFC 請求進行初始編排,編排過程分成3 個階段。首先,計算租戶的SFC 實例數量以滿足租戶的帶寬請求;然后,將租戶的所有SFC 分配到數據中心的一個分發點(PoD,point of delivery)中;最后,確定每個網絡功能實例部署的服務器。NFV-RT 不支持對可編程設備的網絡功能進行擴容編排,同時其單編排器的設計導致NFV-RT 缺乏在大規模拓撲下實現秒級擴容編排部署的能力。
Apple[10]是為軟件定義網絡(SDN,software defined network)設計的SFC 編排部署系統,由資源編排器和SDN 控制器組成。SDN 控制器包含動態處理器和優化引擎。動態處理器負責檢測虛擬機的資源使用量是否超過閾值來判斷是否需要進行SFC 擴容。優化引擎通過運行求解器計算最優的編排部署方案,然而其編排時間復雜度是非多項式的,無法滿足數據中心內的快速彈性擴容編排需求。
Hyper[11]是一個異構SFC 編排部署系統,由編排器、中介者、硬件功能管理器、軟件功能管理器和轉發策略實施器組成。Hyper 同樣采用了中介者來實現對不同的異構設備的管理,但是其中介者同時負責網絡功能的編排部署和拓撲收集,不符合軟件工程中的單一權職原則,造成系統過于僵化。同時,Hyper 還將SFC 建鏈的功能劃分到編排器中,將網絡功能編排的功能劃分到中介者中,這種設計導致Hyper 對基于求解器的編排算法無法提供很好的支持,降低了Hyper 的應用范圍。同時,Hyper的單編排器設計無法支持大規模數據中心的秒級彈性擴容編排。
MicroNF[12]是一種異構SFC 建鏈系統。它通過微服務架構來承載不同的分組處理模塊,通過消除SFC 中的重復模塊并采用可編程網卡降低了SFC的時延;同時提出了策略解析器屏蔽底層設備的異構特性,減輕編排器的壓力。然而,MicroNF 并未對大規模的數據中心編排進行設計,導致其缺乏擴展性。
Daisy[13]是一個高可擴展的異構SFC 編排部署系統,支持對SFC 進行水平擴容和流量工程。Daisy提出了3 個算法實現SFC 的編排,分別是隨機分配算法、NetPack 算法和VNFSolver 算法。其中,NetPack 算法可以在較短的時間內實現SFC 編排,然而在大規模的數據中心拓撲下,其編排時間依舊會超過1 min,不足以滿足未來多模態網絡數據中心的秒級彈性擴容編排需求。
2 系統設計
2.1 總體結構設計
SHOD 系統是一個可以應用于多模態數據中心網絡中的高可擴展異構SFC 編排部署系統。SHOD系統的總體設計思想主要有以下兩點。1) 利用中介者設計模式實現服務層模塊對異構控制器組的統一調用,并且按照單一權職原則對中介者進行設計,以提升系統各模塊的內聚性。2) 利用分區并行編排系統的設計,實現對大規模數據中心的秒級擴容編排,以提高SHOD 的可擴展性。
SHOD 總體結構如圖1 所示。從整體上看,SHOD依照多模態智慧網絡的技術體系框架[4]而采用分層設計,包括服務層模塊和控制器組兩部分。服務層模塊主要負責響應租戶的SFC 請求,并針對數據中心的流量變化做出擴容調整。控制器組負責根據服務層模塊的編排結果,將SFC 部署到相應的數據中心異構功能基礎設施上。SHOD 系統結構的創新點主要體現在服務層模塊的獨特設計,具體如下。
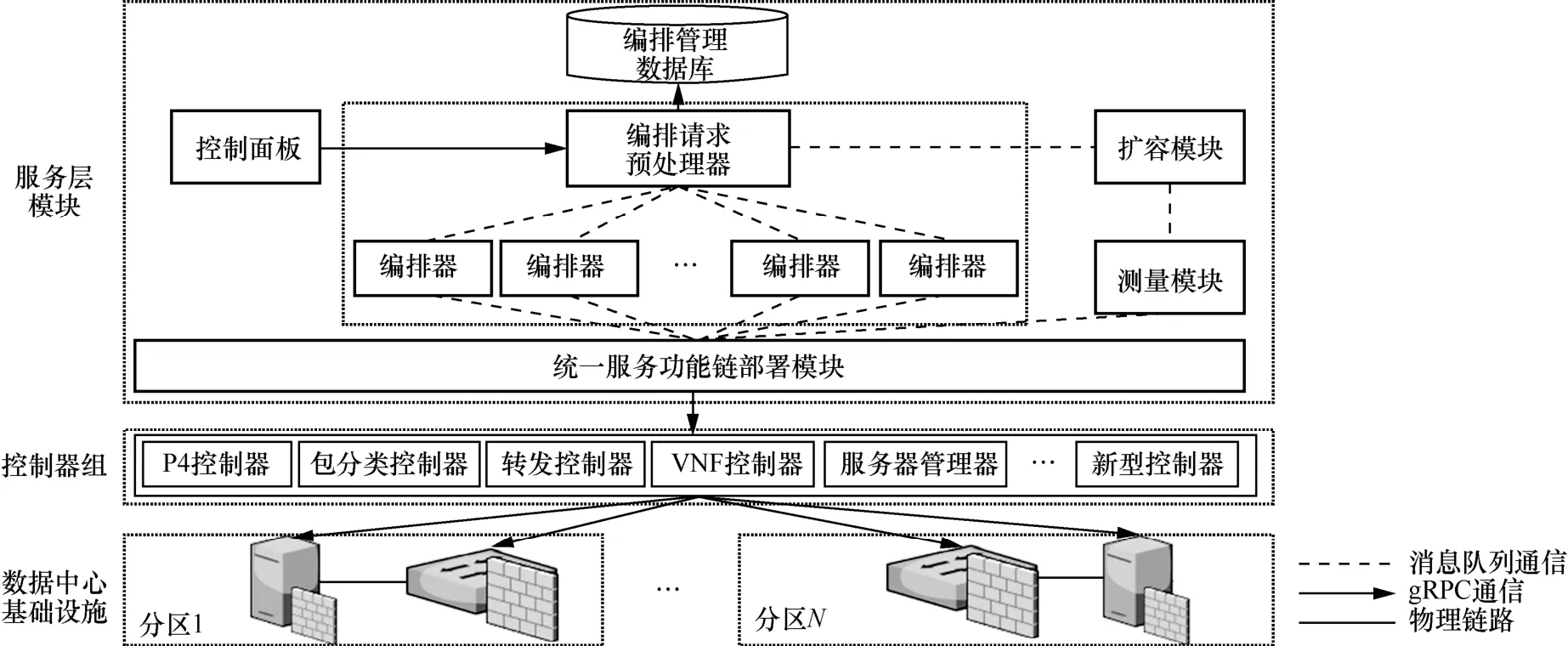
圖1 SHOD 總體結構
1) 不同于已有的SFC 編排部署系統,SHOD系統采用了多編排器的設計,通過編排請求預處理器對編排請求的負載均衡功能實現了并行化編排,大大提高了擴容編排速度。
2) 相對于僵化的傳統SFC 編排部署系統,SHOD 系統創新性地采用單一權職原則的中介者設計模式,由此設計出了統一服務功能鏈部署模塊。該模塊定義了和控制器交互的統一應用程序接口(API,application programming interface),屏蔽了異構控制器的具體實現,使SHOD 系統更容易添加未來新型的多模態網絡基礎設施控制器,大大增加了系統的靈活性。
2.2 服務層模塊
SHOD 系統的服務層模塊包括控制面板、編排請求預處理器、編排管理數據庫、編排器、統一服務功能鏈部署模塊、測量模塊和擴容模塊。
控制面板是SHOD 系統的Web 前端部分。租戶可以登錄控制面板頁面提交SFC 編排部署請求。租戶的SFC 請求內容包括SFC 中的網絡功能種類、網絡功能之間的連接順序,以及SFC 的帶寬需求。隨后,租戶的SFC 編排部署請求會被發送到編排請求預處理器。
編排請求預處理器負責對所有租戶的SFC 擴容編排部署請求進行預處理。這一過程包括給每個租戶的請求分配一個通用唯一識別碼(UUID,universally unique identifier),將租戶的請求注冊到編排管理數據庫。為滿足未來多模態網絡中的秒級擴容編排需求,編排請求預處理器還需要將所有租戶的請求負載均衡到各個編排器實例中,同時保證任意一個編排器的編排時間為秒級。
編排器負責對租戶的SFC 擴容請求進行編排。對于租戶請求的SFC,編排器將其視為邏輯SFC;然后,編排器根據租戶的邏輯SFC 帶寬需求計算對應的SFC 實例數量,以及網絡功能實例和異構功能基礎設施節點之間的映射關系;最后,編排器計算網絡功能實例之間的網絡轉發路徑。為了提升編排系統的可擴展性,SHOD 系統采用了多編排器實例的設計。在完成對租戶SFC 的擴容編排之后,編排器會將編排結果填入擴容部署請求命令,并發送給統一服務功能鏈部署模塊。
統一服務功能鏈部署模塊是連接服務層模塊與控制器組的重要樞紐,專門為異構功能基礎設施環境設計。由于不同種類功能基礎設施的部署接口不同,需要為每種功能基礎設施實現一個控制器,由此產生的多種異構設備控制器給編排部署帶來了軟件系統靈活性方面的挑戰。考慮到未來多模態數據中心網絡會不斷地加入新型設備和更多第三方廠商的網絡功能,SFC 編排部署系統必須能夠靈活添加新型控制器。為了滿足這一需求,SHOD 系統采用中介者模式設計了統一服務功能鏈部署模塊,它連通了SHOD 系統的服務層模塊和控制器組。通過規定統一的SFC 部署接口,SHOD 系統實現了對底層設備和控制器的封裝,避免了為特定設備開發特定服務層模塊而帶來的系統僵化問題。
具體地,統一服務功能鏈部署模塊負責對來自編排器的SFC 擴容部署請求進行復制和分發,即為每一個控制器復制一個SFC 擴容部署請求命令,并將該命令發送到對應的控制器上,包括P4 部署命令、包分類部署命令、轉發路徑部署命令、VNF 部署命令和服務器部署命令。SHOD 系統的統一服務功能鏈部署模塊是符合單一權職原則的,它僅負責請求命令的復制和分發。為實現對異構設備控制器的抽象隔離,統一服務功能鏈部署模塊對控制器提供了統一的API,具體如下。
1) ADD_SFC(SFC),添加邏輯SFC。
2) ADD_SFCI(SFC_instance),添加SFC 實例。
3) DEL_SFCI(SFC_instance),刪除SFC 實例。
4) DEL_SFC(SFC),刪除邏輯SFC。
5) GET_SERVER_SET(),獲取服務器信息。
6) GET_TOPOLOGY(),獲取數據中心拓撲。
7) GET_SFCI_STATE(SFC_instance),獲取SFC實例的流量和狀態信息。
隨著新型設備的出現,SHOD 系統不需要對統一編排部署模塊進行修改。根據軟件工程的依賴倒置原則,僅需要開發符合統一服務功能鏈部署模塊API 的設備控制器,即可實現對新型設備的控制,滿足了未來多模態數據中心網絡中靈活添加新型功能基礎設施的需求。
測量模塊負責收集數據中心的所有信息,包括異構功能基礎設施(如服務器)的狀態信息、交換機組成的拓撲信息、每條SFC 實例的狀態信息和流量信息。不同設備的信息收集功能由各個設備的控制器封裝并通過統一的接口提供。
擴容模塊主要根據測量模塊測量到的SFC 流量信息,依據預先指定好的規則決策是否對租戶的SFC 進行擴容。SHOD 采用對網絡功能實例進行性能建模的方法得到單一SFC 實例可以處理的最大流量。當擴容模塊檢測到某一條SFC 實例的輸入流量超過了其最大可承載流量時,擴容模塊會生成添加SFC 實例的請求并發送給編排請求預處理器。
2.3 并行編排設計
并行SFC 編排是SHOD 系統為滿足未來多模態數據中心網絡的秒級編排需求而提出的核心設計。并行SFC 編排的基本思想是通過將數據中心進行分區來實現分區間的并行編排。然而,數據中心拓撲并不能被隨意劃分,原因如下。1) 錯誤的劃分方式可能導致分區的不連通,進而導致分區內編排失敗;2) 如果劃分的任意2 個分區之間有重疊,則會導致并行編排出錯,例如,2 條SFC 實例被2 個編排器實例編排到同一臺服務器上,但是該服務器的資源不足以承載這2 條SFC 實例。
為此,SHOD 系統采用了數據中心不相交分區的方法。不相交分區方法的主要流程為:1)以POD為最小粒度進行分區;2) 合并相鄰的POD 組成更大的分區,直到滿足最大可接受的拓撲規模。
相比于已有的SFC 編排部署系統,SHOD 系統的并行編排計算速度更快,可以在萬臺服務器規模的數據中心將期望擴容編排時間降低至秒級。然而多個編排器實例會占用更多的CPU 和內存資源。過多的額外CPU 和內存消耗會影響SFC 編排部署系統中其他模塊的性能。為減少并行編排占用的資源,需確定滿足期望編排時間的最小編排器數量。
為此,SHOD 系統采用了基于數據驅動的方法建立期望編排時間模型來確定最小的編排器數量。建模的總流程為:首先,分析編排算法,并給出編排算法的期望計算時間模型;然后,通過構造各種SFC 擴容編排部署請求,并記錄編排算法的計算時間,來實現對編排算法的期望計算時間的擬合。本文提出的基于數據驅動的期望編排時間模型建立方法適用于任意類型的編排算法,對于如何提升編排算法本身的計算速度已經超出本文工作的研究范圍。
本文以Daisy 使用的算法NetPack[13]為例闡述最小編排器數量的確定方法,該方法需要分析編排算法來建立期望編排時間模型。NetPack 算法可以分為兩層循環。
第一層循環根據所有的服務器構建服務器集合進行編排。在第一層循環內,針對每一個網絡功能,NetPack 會無放回地從服務器集合中隨機選擇一臺服務器。設Nse為數據中心服務器的數量,其中有臺服務器的資源不足以承載租戶請求的SFC,C為SFC 的長度。每當NetPack 算法隨機選擇的服務器是臺資源不足的服務器之一時,NetPack 會繼續重新隨機選擇,直到選擇到資源充足的服務器。根據這一過程,可以得出NetPack 算法隨機選擇服務器的期望選擇次數Ecnt為
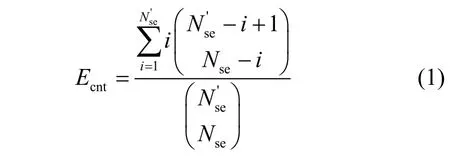
其中,i表示第i次選擇到資源充足的服務器。NetPack 算法在i=1 時立即選擇到資源充足的服務器的概率為
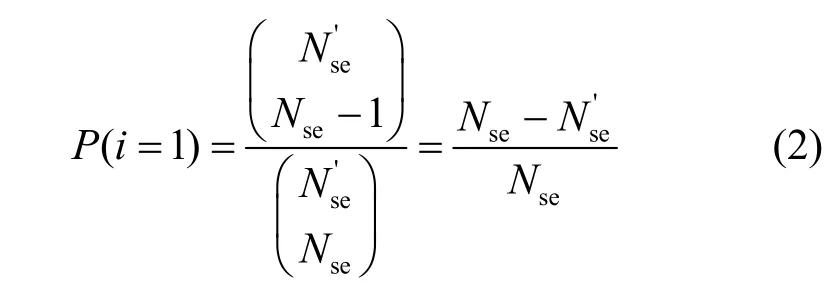
則式(1)的上界為
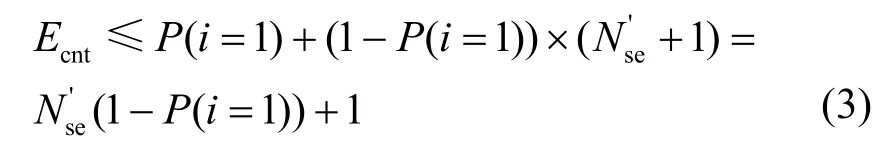
由于數據中心的服務器利用率普遍較低,資源不足的服務器數量通常遠小于總服務器數量Nse,即此時P(i=1) ≈ 1,則Ecnt≈ 1。
第二層循環中,NetPack 算法調用深度優先搜索(SFC,depth first search)實現無向圖中的SFC 實例路徑計算。在滿足SFC 請求帶寬BW 遠小于數據中心可用帶寬BWava的條件下,即BW ?BWava時,NetPack 算法的第二層循環僅需要進行一次復雜度為O(Nsw)的DFS,其中Nsw為數據中心交換機的數量。
綜上所述,在滿足條件BW ?BWava和的情況下,NetPack 計算一條SFC 實例的期望計算時間復雜度為O(NswC)。該期望計算時間復雜度和Daisy[13]的實驗結果相符合:Daisy 的實驗結果顯示,NetPack 算法的計算時間與拓撲規模Nsw近似成正比。基于此計算時間復雜度,本文方法建立的擴容編排時間模型E(t) 為
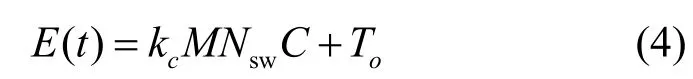
其中,kc是擬合系數;M是需要擴容的SFC 實例數量;To是編排系統的固有時間,即租戶的擴容編排請求進入編排系統到擴容部署請求命令被發送到統一服務功能鏈部署模塊之間的時間差。
為了驗證式(4)能否準確描述SHOD系統的編排時間,本文通過比較模型計算出的期望編排時間與實際的編排時間平均值之間的均方誤差(MSE,mean square error)來驗證其準確性。本文分別在5 個不同規模的Fat-Tree 拓撲[16]下采集了NetPack 算法的編排時間數據,其中POD 的數量K分別為20、24、28、32、36。在每個拓撲下,本文分別測量了擴容100 條、300 條、500 條、700 條、900 條SFC 實例的編排時間數據,其中擴容100 條、300 條、700 條、900 條的編排時間作為訓練集,擴容500 條的編排時間作為測試集。具體地,模型擬合系數、固有時間及均方誤差如表1 所示。

表1 模型擬合系數、固有時間及均方誤差
從表1 可以看出,本文所提模型的最大MSE僅為1.3 s。K=36 的Fat-Tree 拓撲下的模型預測時間與真實編排時間的比較如圖2 所示。

圖2 模型預測時間與真實編排時間的比較
從圖2 中可以看出,本文模型預測時間和真實編排時間是吻合的,基于式(4)的模型可以較好地描述系統期望編排時間。
基于本文模型可以推導出編排器實例數量的計算式。假設期望在Ts 內編排M條SFC 實例進行擴容,同時要保證每個編排器處理的SFC 實例數量相同。設編排器數量為n,則每個編排器的編排區域中的設備數量大約是總設備數量的處理的SFC 實例數量為總SFC 實例數量的則可以得到編排器實例數量應滿足
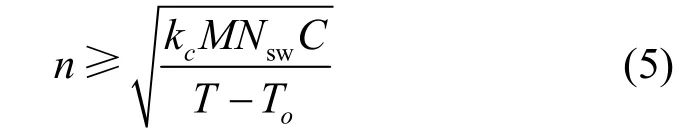
取滿足式(5)的最小整數作為編排器的數量,在得到最小的編排器數量后,編排器預處理器會將M條SFC 實例分配到n個編排器實例中進行并行編排。
2.4 控制器組
為了實現對異構設備的統一部署,SHOD 系統為每一種設備都提供了對應的控制器。SHOD 系統按照基礎設施的種類將控制器劃分為5 種,分別是服務器控制器、包分類控制器、P4 控制器、VNF控制器和轉發控制器。服務器控制器負責收集每臺服務器的狀態信息和資源信息,并把全部信息發送到測量模塊。包分類控制器用于數據中心網關的流量分類,負責在網關下發規則,并將不同的SFC 流量進行區分。P4 控制器和VNF 控制器是實現SFC部署的重要組件。編排器輸出的SFC 實例編排結果中,有一部分SFC 實例被編排到了P4 交換機上,這些網絡功能由P4 控制器負責部署。P4 控制器會在相應的P4 交換機上下發網絡功能對應的規則,如訪問控制列表(ACL,access control list)。另一部分SFC 實例被編排到基于X86 的商用服務器上,這些虛擬網絡功能由VNF 控制器部署。
網絡功能的部署時間不僅與功能基礎設施的種類有關,也和網絡功能的數量有關。通常,在一臺基礎設施上部署的網絡功能數量越多,需要的部署時間就越長。基于這一觀察可知,僅僅通過優化部署模塊無法保證秒級的SFC 部署,還需要避免編排器在同一臺基礎設施上編排過多的網絡功能實例。為了實現秒級的異構SFC 部署,針對任意一種功能基礎設施,需要得到其部署網絡功能的數量和部署時間之間的對應關系。SHOD 系統通過實際測量的方法得到每臺功能基礎設施的部署網絡功能數量和相應的部署時間。根據這一對應關系,可以根據期望部署時間得到每臺功能基礎設施的最大可部署網絡功能數。通過將可部署網絡功能數量的限制條件添加于SHOD 系統的編排算法中,可以保證在期望時間內完成SFC 的部署。以NetPack 算法為例,在第一層循環算法判斷一臺服務器資源是否充足。SHOD 系統在此處加入一個判斷語句來判斷一臺服務器的最大可部署網絡功能數量。如果已經超過了該數量限制,則這一層循環不選擇該服務器。本文在實驗部分展示了在測試床中測量的異構基礎設施網絡功能部署時間與網絡功能數量之間的對應關系。
在完成對網絡功能的部署之后,還需要轉發控制器實現SFC 的建鏈。目前,已經有很多種SFC 建鏈方法。考慮到易部署性,SHOD 系統采用了網絡服務頭(NSH,network service header)[17]實現跨設備的建鏈,該方法支持多達224條SFC,可以滿足大規模數據中心的基本需求。轉發控制器將NSH 轉發規則下發到服務器所在的軟件交換機上實現NSH建鏈。
3 系統原型實現
本文采用Python 語言實現了SHOD 原型系統。原型系統基于RabbitMQ 消息隊列作為服務層模塊以及控制器之間的通信機制。采用MySQL 作為編排管理數據庫。在控制層中,P4 控制器采用gRPC實現了對P4 的遠程控制,轉發控制器同樣使用gRPC 實現了對基于BESS 的軟件交換機的控制,包分類控制器采用gRPC 對網關進行管理,VNF 控制器則采用Docker API 實現在遠程服務器上啟動虛擬網絡功能容器。
本文實現了基于BESS 的軟件交換機用于SFC建鏈,還采用FastClick 實現了多種VNF,包括無狀態防火墻、負載均衡器、Monitor 等。此外,還實現了基于Tofino S9180-32X P4 交換機的無狀態防火墻用于部署ACL。
4 系統性能評估
4.1 實驗設置
本文主要通過真實實驗來驗證SHOD 系統的可擴展性,并通過小規模測試床評估了SHOD 系統的擴容部署時間。真實實驗中,SHOD 系統被部署于一臺Intel Silver 4210R 服務器上,編排管理數據庫載入了真實數據中心拓撲,即常見的Fat-Tree[16]拓撲。對于擁有K個POD 的Fat-Tree 拓撲,每個POD 由一層個機架交換機(ToR,top of rack)和個聚合交換機組成完全二分圖。此外,還有個核心交換機,每個核心交換機分別與每個POD 中的一臺聚合交換機相連。為評估不同拓撲規模下SHOD系統的彈性擴容編排時間,本文分別在20 個、24 個、28 個、32 個和36 個POD 的Fat-Tree 拓撲下進行了實驗。其中,K=36 的Fat-Tree 拓撲包含1 620 臺交換機和11 664 臺服務器。機架交換機和聚合交換機之間的鏈路帶寬設置為10 Gbit/s,聚合交換機和核心交換機之間的鏈路帶寬設置為10 Gbit/s,每臺核心交換機都可作為數據中心的網關,它們負責與主干網的連接。租戶的流量由數據中心網關進入數據中心網絡。租戶的SFC 請求帶寬大小設置為服從10~100 Mbit/s 分布的隨機變量。本文隨機生成了100 條SFC,并按照已有的研究[18-19]將生成的SFC長度范圍限制在2~7,SFC 中的網絡功能主要由ACL 防火墻、NAT、Monitor、WAN 優化器、IDS、VPN 和負載均衡器組成。為了測量SHOD 的可擴展性,本文測量了SHOD 對所有SFC 擴容2~10 倍所需的擴容編排時間,并設定擴容編排期望時間T為25 s。本文通過SHOD 系統的消息接口向編排請求預處理器提交所有的SFC 擴容編排請求,并在統一服務功能鏈部署模塊處記錄所有請求的編排時間。本文的對比方案包括已有的編排系統Daisy 和運行NetSolver-ILP[20]算法的編排系統。
為進一步考察SHOD 系統的擴容部署時間,本文搭建了小規模測試床。該測試床由一臺商用交換機、一臺Tofino S9180-32X P4 交換機、一臺Intel E5-2603v4 服務器和一臺Intel Silver 4210R 服務器組成。其中,商用交換機用于連接P4 交換機和服務器的控制平面,P4 交換機用于部署ACL 網絡功能,第一臺服務器用于部署虛擬網絡功能,第二臺服務器用于運行SHOD 系統。
除非在實驗中有特殊說明,否則默認的SFC 長度為7,初始SFC 實例數量為100,默認需要擴容900 條SFC 實例,拓撲為K=36 的Fat-Tree。實驗一共進行5 次,取平均值和標準差作為最終結果。
4.2 異構SFC 擴容部署時間
在測試床中,本文測量了異構SFC 的擴容部署時間。部署的SFC 包括一個基于P4 類型的無狀態防火墻以及一個基于VNF 類型的無狀態防火墻,擴容SFC 實例數量分別為1~5 個。根據阿里云提供的防火墻實例的規則數量范圍,本文設置每個防火墻實例的ACL 規則為100 條。圖3 展示了在不同擴容SFC 實例數量下,基于P4 類型和基于VNF類型的無狀態防火墻的擴容部署時間。從圖3 可以看出,即使在擴容SFC 實例數量為5 時,SHOD 的SFC 擴容部署依然可以在秒級時間內完成。通過測量,本文發現基于P4 的無狀態防火墻的擴容部署時間遠遠小于基于X86 的擴容部署時間。P4 類型的網絡功能擴容部署時間不超過1 s,而VNF 類型的網絡功能擴容部署時間比較長,這是因為本文采用DPDK 實現的VNF 類型的無狀態防火墻需要較長的大頁內存初始化過程。

圖3 擴容部署時間與擴容SFC 實例數量的關系
除此以外,隨著擴容SFC 實例數量的增加,擴容部署時間也隨之增加。具體地,當擴容SFC 實例數量為1 時,VNF 的擴容部署時間僅需1 s,而當擴容SFC 實例數量大于或等于2 時,每條SFC 實例的平均部署時間大約為2.3 s。造成這一現象的原因是本文所實現的VNF 控制器原型采用了docker API,而docker API 在單臺服務器上是串行調用的。當僅需部署一條SFC 實例時,docker API 可以立即返回部署成功的指令。而當部署第二條及之后的SFC 實例時,docker API 需要等待前一個SFC 實例部署完成,然后才能進行下一個SFC 實例的部署。
在得到不同功能基礎設施的部署時間與SFC 實例數量之間的關系后,可以通過限制每臺設備的網絡功能實例可編排數量來保證秒級部署時間。例如,當期望部署時間限制在11 s 內時,測試床平臺中的P4交換機的網絡功能實例部署數量最多為50 個,而服務器的網絡功能實例部署數量最多為5 個。通過限制編排器在每臺設備的最大網絡功能編排數量,SHOD可以保證在任意一臺設備上部署SFC 的時間為秒級。
4.3 擴容編排時間
在測試床實驗中,SHOD 系統和Daisy 系統的編排時間相差不大,均約為2 s。這是因為測試床的規模較小,無法體現出SHOD 系統的可擴展性。為此,本文在大規模拓撲下進一步比較編排時間。
在測量大規模拓撲下的擴容編排時間之前,本文首先通過模型確定最小資源使用量的編排器數量。為確定最小的編排器數量,SHOD 系統針對每一個拓撲都建立了一個期望計算時間模型,具體擬合系數如表1 所示。SHOD 系統在不同POD 數量K下的最小編排器數量如表2 所示。

表2 最小編排器數量
在得到最小化資源使用量的編排器數量之后,本文測量了在不同拓撲規模下,SFC 編排系統Daisy和SHOD 的SFC 擴容編排時間,同時本文還比較了基于Gurobi 求解器的編排算法NetSolver-ILP[20],實驗結果如圖4 所示。從圖4 可以看出,采用NetSolver-ILP 算法的編排時間是最長的,在最大的拓撲下其編排時間可達8 h,遠超期望編排時間限制。NetSolver-ILP 的編排時間主要由求解器模型的構建時間和模型的求解時間兩部分組成。由于在大規模拓撲下,最優化模型的限制條件和決策變量數非常大,導致求解器模型的構建時間就已經超出了秒級,而模型的求解時間則比求解器模型的構建時間更多。Daisy的SFC擴容編排時間會隨著拓撲規模的增長而急劇增長,在K=36 的Fat-Tree 拓撲下,Daisy 的擴容編排時間達到了300 s,遠超秒級擴容編排的要求。與之相對應,SHOD 的擴容編排時間并不會隨著拓撲規模的增長而增加。在所有拓撲下,SHOD 的擴容編排時間均小于25 s。具體地,按照拓撲從小到大分別是16 s、17 s、23 s、21 s 和24 s。SHOD 能夠將編排時間降低至秒級的原因在于其采用了并行編排的設計,隨著拓撲規模的增加,SHOD 會相應地增加編排器實例的數量來降低擴容編排時間。

圖4 不同拓撲規模下的擴容編排時間
本文還考察了不同擴容SFC 實例數量下的擴容編排時間,如圖5 所示。基于求解器的編排算法NetSolver-ILP 的編排時間依舊遠超分鐘級。隨著擴容SFC 實例數量的增加,Daisy 的擴容編排時間也會線性增加。這是因為Daisy 采用的NetPack 編排算法的期望編排時間與需要擴容的SFC 實例數量呈正比例關系。與Daisy 不同,SHOD 的擴容編排時間可以保持在期望編排時間以內,這是因為SHOD 可以通過增加編排器實例的方法降低編排時間,相比于單編排器設計的Daisy,SHOD 在大規模數據中心網絡中的可擴展性更好。
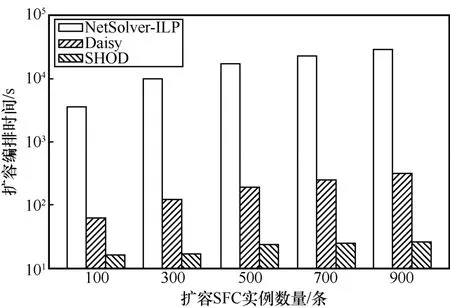
圖5 不同擴容SFC 實例數量下的擴容編排時間
4.4 系統CPU、內存資源占用開銷
在小規模測試床實驗中,SHOD 系統和Daisy系統的CPU 占用率和內存占用率基本相同,大約為5%和90 MB。
在大規模拓撲下,為了將SFC 擴容編排時間降低至秒級,SHOD 采用了多編排器設計。多個編排器會占用額外的計算存儲資源。本文評估了在不同拓撲規模下,SHOD 的CPU 占用率和內存利用量。
平均CPU 占用率如圖6 所示。從圖6 可以看出,隨著拓撲規模的增加,NetSolver-ILP 的CPU 占用率基本保持在125%~150%,這是由于NetSolver-ILP使用的Gurobi 求解器會使用到多個核心并發求解優化模型,因此其CPU 占用率會超過100%。Daisy 的CPU 占用率會隨著拓撲規模的增加而逐漸接近100%,這是因為Daisy 僅使用一個編排器運行其NetPack 算法,因而其CPU 占用率不會超過100%。SHOD 的CPU 占用率雖然會隨著拓撲規模的增加而緩慢增加,但是從整體上看SHOD 的CPU 占用率與其他對比方案都在同一數量級內,例如K=36 的Fat-Tree 拓撲下,SHOD 的平均CPU 占用率相比于Daisy 僅提高了1.5 倍,相比于NetSolver-ILP 僅提高了70%。這是因為SHOD 采用了數據驅動的建模方式計算出了資源使用量最小化的編排器數量,使SHOD 的CPU 占用率和其他對比方案大致相同。
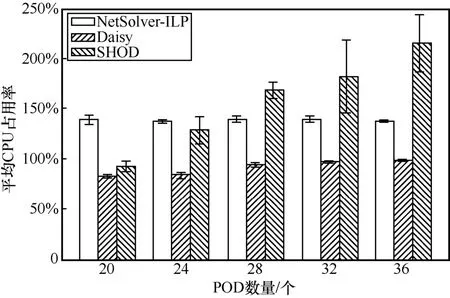
圖6 平均CPU 占用率
平均內存資源使用量如圖7 所示。其中,在最小的拓撲下,NetSolver-ILP 使用了14.1 GB 內存。在最大的拓撲下,其內存資源使用量最高可達到64.5 GB。NetSolver-ILP 使用大量內存的原因在于其求解器建模的優化模型有大量的決策變量和限制條件。相比之下,采用NetPack 算法的Daisy 和SHOD 的平均內存資源使用量最大僅約為860 MB,遠小于NetSolver-ILP。而SHOD 的內存資源使用量相比于Daisy 僅僅提高了3 倍,這對于當今的大內存商用服務器來說是完全可以接受的。
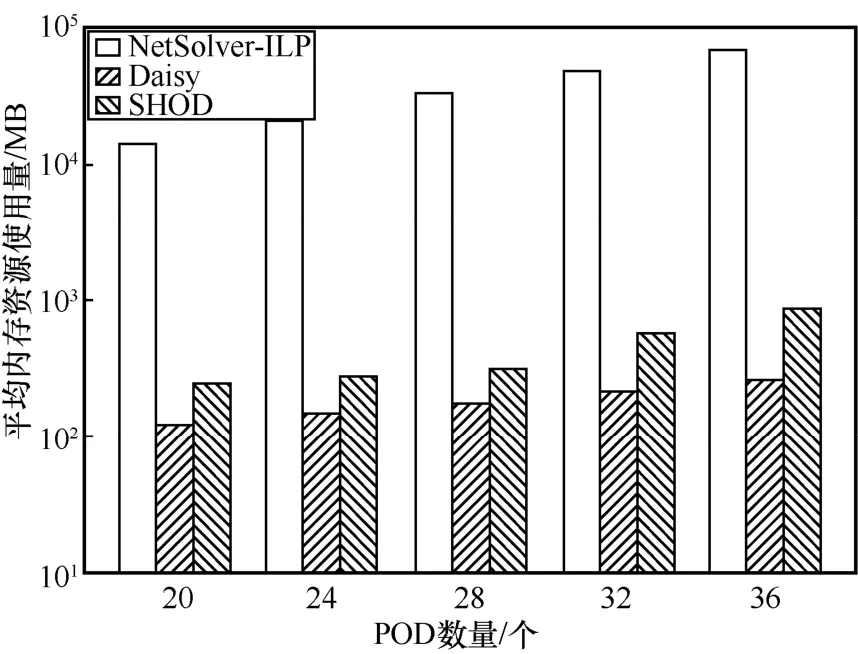
圖7 平均內存資源使用量
5 結束語
本文為未來多模態網絡中的大規模復雜公有云提出了一種可擴展的彈性異構服務功能鏈編排部署系統。通過并行的編排器設計,實現了對大規模網絡的彈性擴容編排。通過符合單一權職原則的中介者設計模式,實現了對異構網絡設備的統一編排部署和建鏈。實驗結果表明,SHOD 系統可以在秒級完成對萬臺服務器規模的數據中心的服務功能鏈擴容編排部署。
猜你喜歡
中華詩詞(2022年6期)2022-12-31 06:41:24
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
家庭影院技術(2017年9期)2017-09-26 03:41:45
中國科技論壇(2017年7期)2017-07-25 08:49:53
媽媽寶寶(2017年2期)2017-02-21 01:21:24
國際漢語學報(2016年1期)2017-01-20 08:21:20
