數據平衡與模型融合的用戶購買行為預測
2022-10-10 09:25:10李伊林段海龍林振榮
計算機應用與軟件 2022年9期
李伊林 段海龍 林振榮
1(江西省水利科學研究院 江西 南昌 330029) 2(南昌大學信息工程學院 江西 南昌 330031)
0 引 言
隨著電子商務的快速發展,電商平臺每天會產生海量的用戶瀏覽、購買、商品評價等用戶行為數據。如果電子商務平臺能夠從海量的用戶行為數據中挖掘用戶潛在的意圖,就能夠為用戶提供更加個性化的服務和更加精準的營銷活動。
國內外的大部分學者對于用戶行為預測的研究主要都是基于客戶的歷史行為數據,在對購買行為預測的研究中,葛紹林等[1]構建了基于深度森林的預測模型對用戶購買行為進行預測。張鵬翼等[2]利用機器學習中的分類模型,結合C&R決策樹和(Logistics)邏輯回歸模型,利用電子商務平臺消費者數據進行消費行為預測。用戶購買行為預測的復雜性使得單一的算法容易對用戶購買行為預測陷入過擬合,為此許多學者提出了多模型融合的方法來解決這一問題。祝歆等[3]、劉瀟蔓[4]分別應用Logistic回歸、支持向量機、這兩者的融合方法搭建了購買預測模型,證明融合算法的精確程度高于單一算法,并指出嘗試其他算法以及融合算法是未來的研究方向。李旭陽等[5]結合LSTM算法預測的時序性提出了一種基于LSTM與隨機森林相結合的預測模型,通過實驗發現融合模型在準確率和召回率上均比單一隨機森林模型更高。
綜上本文提出基于XGBoost融合模型對用戶購買行為進行預測。融合模型利用LSTM、XGBoost、LR算法從不同角度對用戶行為進行預測,然后用XGBoost算法擬合各個算法的預測結果作為最終的預測結果。
1 改進的欠采樣方法
用戶網絡購物行為數據存在的最大的問題就是數據分布不均衡,用戶購買的過程中存在大量的用戶點擊、瀏覽、加購物車等數據,但是用戶的下單數據的比例卻很少[6]。為了提升不均衡數據的建模效果,提高少數類樣本分類精確度,可通過算法層面和數據層面進行數據均衡化處理,即設計學習算法或改進學習算法提升其對少數類樣本的識別率,或者利用欠采樣、過采樣或兩者結合的方法降低數據集的不均衡度。
隨機采樣是當前解決類別不平衡問題最簡單和應用最廣泛的采樣技術,隨機欠采樣方法通過隨機的刪除適量的多數類樣本數據以達到平衡數據集的效果[7-8],但是隨機刪除負多數類樣本可能會刪除到一些典型的樣本,使得模型預測精度下降。隨機欠采樣數據平衡方法偽碼描述如算法1所示。
算法1隨機欠采樣算法
輸入:訓練集S,正負樣本比率Sr。
輸出:數據平衡后的數據集。
P=S+,N=S-
//從樣本集S提取出正樣本與負樣本數據
//分別放入樣本數據集P、N
while len(P)/len(N)>Sr:
//循環從負樣本集刪除樣本,
//直到達到設定的平衡率
Rondomifrom(0,len(N))
//隨機生成負樣本的下標i
DeleteN[i]
//刪除下表i的負樣本
end
S=P+N
//合并正負樣本數據集
針對隨機欠采樣數據平衡方法造成數據信息丟失的問題,本文在隨機欠采樣方法的基礎上提出了基于K-means算法[9]的改進隨機欠采樣方法。改進的隨機欠采樣數據平衡方法的流程如圖1所示。
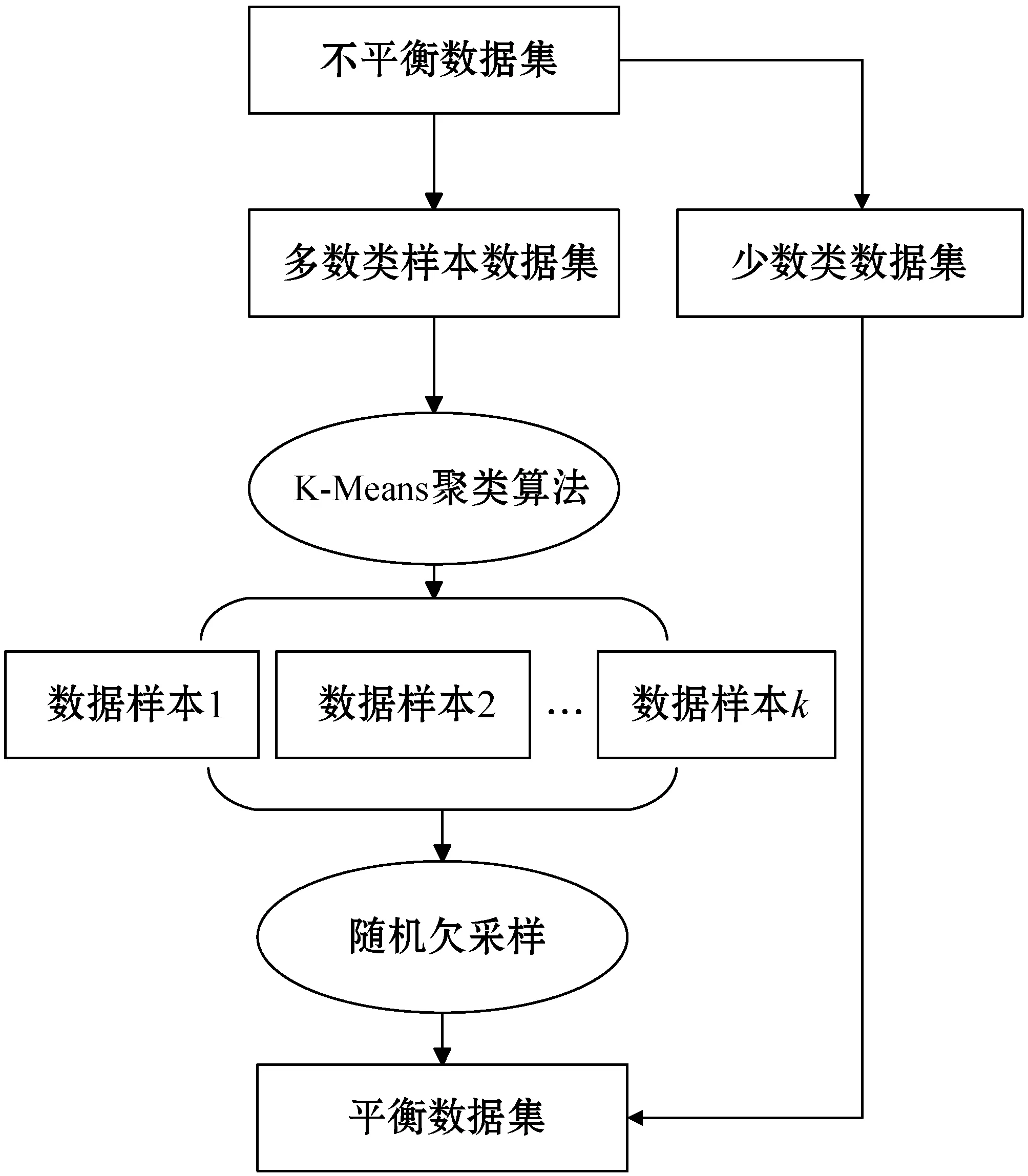
圖1 改進欠采樣方法流程
改進的欠采樣數據平衡方法是在隨機欠采樣平衡方法加入K-Means算法對多數類樣本數據進行聚類,首先運用K-Means算法將多數類樣本劃分為多個簇類,然后利用隨機欠采樣方法從各個不同的簇類中選取一定比例的樣本加入新的樣本集,最后將新的樣本集與少數類樣本集合。
K-Means算法的初始化聚類中心對最終的聚類結果影響很大[10],傳統的K-Means算法初始化聚類中心是在數據集中隨機選取數據對象作為聚類中心,如果在初始化聚類中心時選擇的中心樣本的距離很近的話會導致K-Means算法難以收斂。基于這種思想本文對傳統K-Means算法初始化聚類中心的過程進行了改進,在初始化聚類中心點時使得這些聚類中心盡可能分散。改進初始化聚類中心的具體流程如下:
1) 獲得聚類數k和數據樣本總數s,將數據集全部加入聚類中心候選數據集中。
2) 隨機地從聚類中心候選數據集中選擇一個數據作為一個聚類中心,并計算所有數據樣本與該聚類中心的歐氏距離,然后將距離最近的前s/k條樣本數據移出聚類中心候選數據集。
3) 重復步驟2)直到獲得k個聚類中心點。
2 用戶購買行為預測模型
2.1 極限梯度提升算法
極限梯度提升算法(eXtreme Gradient Boosting,XGBoost)是由Chen等[11]提出的一種規模較大的算法。當XGBoost使用樹算法作為基分類器時,它就是在GBDT算法的基礎上做了一些改進。XGBoost算法對每棵樹進行了預剪枝,傳統GBDT只用損失函數的一階導數信息進行優化,XGBoost算法對損失函數進行了二階泰勒展開,同時用到了一、二階導數信息,相當于使用牛頓法優化損失函數[12-14]。
XGBoost算法采用加法模型的方式訓練模型,每次新增的基模型都是在上一個基模型的基礎上訓練得到的。
(1)
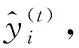
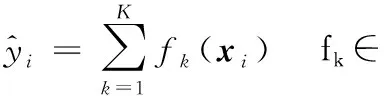
(2)
XGBoost算法在損失函數里引入了正則項,提升了單棵樹的泛化能力。式(3)給出了損失函數的計算方法,損失函數包含預測結果的誤差評估和正則項,正則項是樹的復雜度之和,用于控制模型的復雜度。
(3)
正則項的展開形式如式(4)所示,參數T表示葉子節點的個數,參數w表示葉子節點的預測值。通過參數γ可以對葉子節點的數量進行限制,參數λ可以調節葉子節點的預測值大小防止出現預測值過大的情況,通過這兩個參數可以有效地防止過擬合。
(4)
2.2 融合預測模型構建
基于預測模型的預測特點,融合模型的基學習器使用LSTM算法、XGBoost算法、邏輯回歸算法,融合模型中基學習器算法與不同類別的預測算法能夠結合各類算法的優勢提高融合預測模型的泛化能力。融合模型的構造過程描述如下:
(1) 運用改進的過采樣平衡方法處理數據集的正負樣本不平衡問題,得到數據集D。
(2) 將訓練數據集D平均地劃分成2份數據集D1、D2。
(3) 用訓練數據集D1分別訓練LSTM模型、XGBoost預測模型、LR預測模型作為融合模型的基學習器。
(4) 將訓練數據集D2輸入到各個基學習器獲得模型的預測結果,并將預測結果加入到數據集D2的特征屬性中。
(5) 用訓練集D2訓練XGBoost模型作為元學習器,完成融合模型的訓練。
融合模型構建流程如圖2所示。
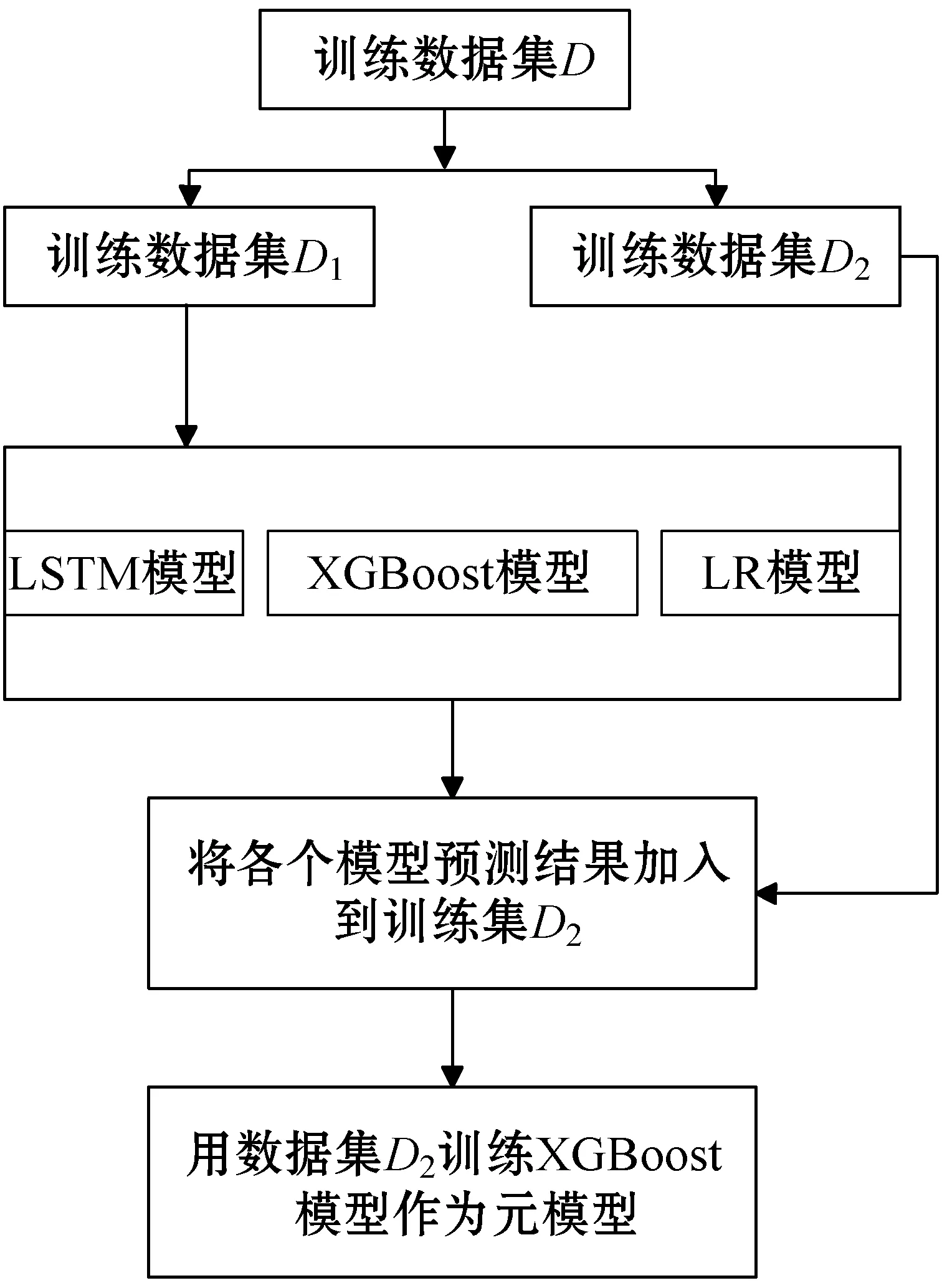
圖2 融合模型構建流程
3 實 驗
3.1 數據介紹
本文的實驗數據是JData數據挖掘大賽提供的京東商城真實的在線交易數據。數據集給出2016年2月1日到2016年4月15日的線上交易數據。數據集包含用戶基本信息、商品基本信息、用戶對商品的評價信息、用戶對商品的交互信息,其中備注說明為“脫敏”的字段的具體信息是做了信息隱藏等處理后的內容,以免用戶等具體信息泄露。數據集的具體信息如表1-表4所示。
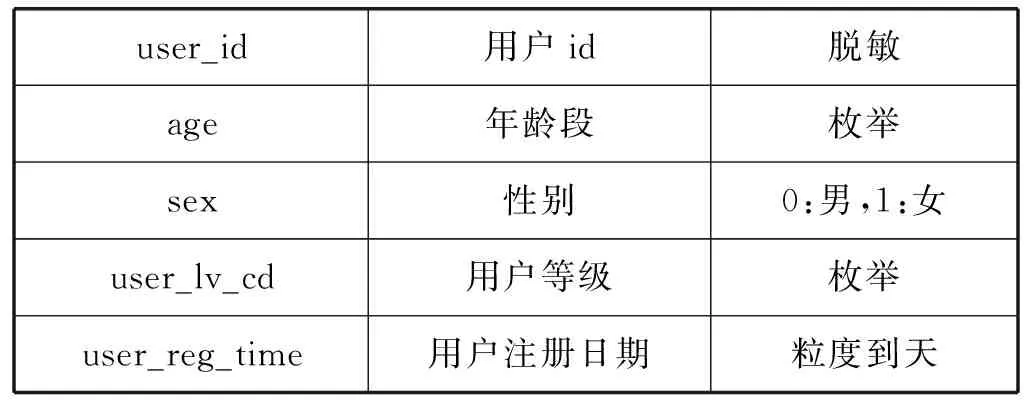
表1 用戶基本信息
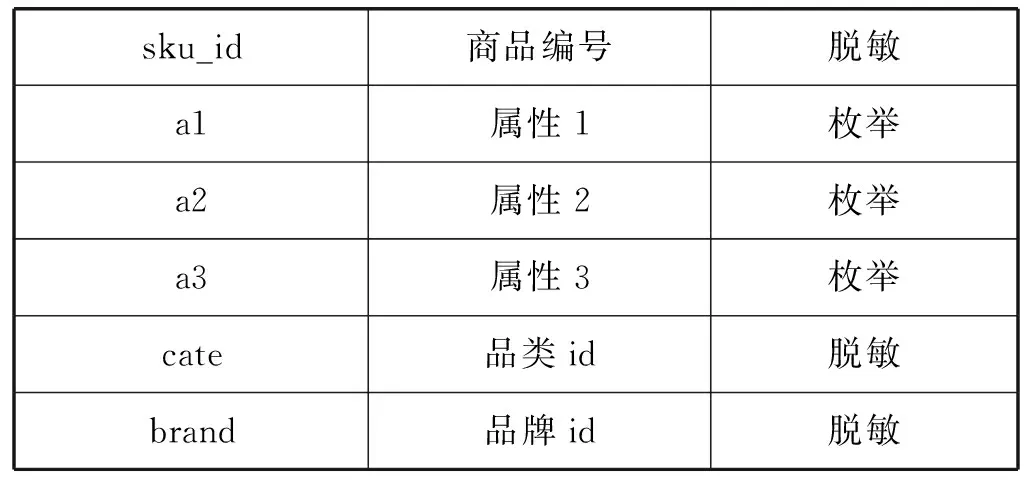
表2 商品基本信息
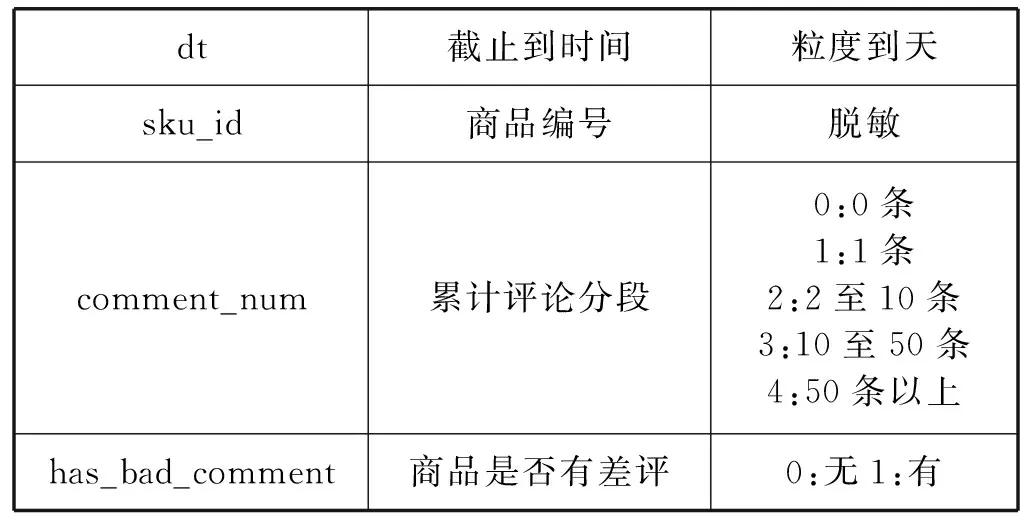
表3 商品評論數據

表4 用戶行為數據
3.2 數據清洗
對用戶商品交互行為分析發現用戶的點擊行為非常大,結合電子商務用戶行為研究可以認為點擊行為對于購買行為的影響非常低可以忽略不計。對于瀏覽行為非常大卻沒有購買行為的用戶可以認定為爬蟲用戶,這類用戶主要是為了獲取商城的商品數據,這類數據對預測模型的訓練會產生很大影響,所以需要將這類用戶的行為數據去除。本文對原始數據的清洗過程如下:
(1) 特征數據缺失用-1填充。
(2) 數值化特征值,對原始數據中的用戶屬性的性別進行數值化。
(3) 對特征值進行獨熱編碼,本文對用戶的行為數據(如加購物車、瀏覽商品、購買商品)進行獨熱編碼處理。
(4) 刪除異常數據,異常數據主要來自于一些基本上沒有記錄的用戶,還有一些就是特別活躍但卻沒有任何購買記錄的爬蟲用戶的相關數據。如果將這些值放入到訓練集的話會嚴重影響模型的精度,所以將這些異常數據刪掉。
3.3 特征提取
經過特征提取與特征選擇后,本文最后所用到的預測特征體系由用戶特征群、商品特征群、商品類別特征群、用戶-商品特征群構成。本文選取的特征情況如下:
(1) 用戶特征群。用戶特征群由用戶的基本特征和用戶的衍生特征構成。用戶的基本特征包括:用戶的等級;用戶購買商品的種類數;用戶購買商品的品牌、類別數。用戶的衍生特征包括:用戶對商品的四種交互行為(瀏覽、收藏、加購物車、關注行為)的購買轉化率;用戶的購買活躍度(用戶購買商品的總次數與購買商品的實際天數的比值);用戶購買活躍度在所有用戶中的排名。
(2) 商品特征群。商品特征群由商品的基本特征和商品的衍生特征構成。商品基本特征包括:商品的類別、品牌等各類屬性;購買該種商品的人數。商品的衍生特征包括: 商品的四種交互行為(關注、收藏、加購物車)的購買轉化率;商品的購買人數在該商品所屬品類的排名;商品的購買轉化率在該商品所屬類別的排名;商品的四種交互行為的趨勢(商品預測日期前1天的四種交互行為的數量與日平均交互行為數量的比值)。
(3) 商品類別特征群。商品類別特征群包括:不同的商品類別包含的商品的數量;不同的商品類別購買的總人數。
(4) 用戶-商品特征群。用戶-商品特征群包括:預測日期前,該用戶對該商品的四種交互行為數;預測日前第1天、第2天、第3天,該用戶對該商品四種交互行為數;預測日前5天、前7天、前9天、前11天,該用戶對該商品四種交互行為數。
3.4 模型評價指標
對于數據類別不平衡的預測存在正樣本數量稀少、樣本分布較為稀疏的情況,這種情況下預測模型會偏向識別負樣本而正樣本很難識別到,在實際應用中正樣本的識別具有更高的價值。為了更清楚地看到正樣本的預測效果,本文采用混淆矩陣、召回率等來評價數據不平衡的分類問題[15]。表5給出了二分類問題的混淆矩陣。
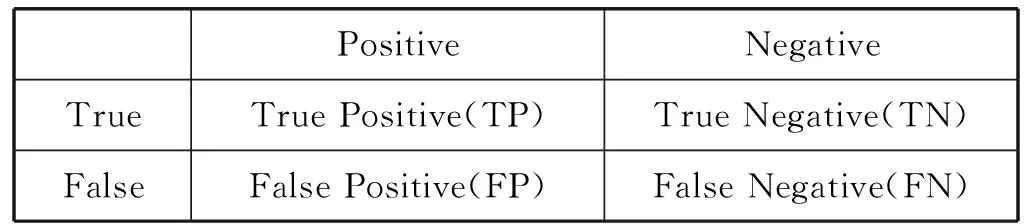
表5 混淆矩陣
針對本文的預測情況的解釋:定義U-S(U:user_id用戶id,S:sku_id商品id)表示用戶和商品的對應關系,模型預測的輸出結果就是U-S對,U-S值為1表示用戶購買該商品,U-S值為0表示用戶不購買該商品。TP是指模型預測為購買情況且實際也購買了的U-S的數量,FP是指模型預測為會產生購買而實際沒有購買的U-S數量,TN是指模型預測為不會產生購買而實際上產生購買的U-S數量,FN是指模型預測為不會產生購買實際上也沒產生購買的U-S數量。
本文主要關注的是購買行為預測的效果不需要知道未購買行為的預測效果,所以預測模型的評價指標有購買行為預測的精確率(precision)、召回率(recall)。精確率就是模型預測的所有U-S值為1的正確率,這體現了模型對正樣本預測的準確率。召回率是指預測對的U-S占所有的實際U-S結果的比率,這體現模型預測正確的U-S對在所有的實際U-S結果的命中率。精確率和召回率的數學公式表示如下:
(5)
為了更好地評價模型,本文選用F1值作為模型的評價指標,F1值計算方法如下:
(6)
3.5 模型參數設置
實驗所用的XGBoost預測模型是基于Python的XGBoost類庫構建的。LSTM預測模型是基于Keras神經網絡庫和Scikit-learn機器學習庫構建,LR預測模型是基于Scikit-learn機器學習庫構建的。通過不同參數組合的方式,對模型的預測結果進行了比較最終確定了模型主要的參數。
(1) XGBoost模型。eta=0.01,n_estimators=700,max_depth=4,min_child_weight=3,gamma=0.3,subsample=0.9,colsample_bytree=0.8,即在模型參數調優的模型學習步長為0.03,決策樹的數量為700個,樹的最大深度為4,最小葉子權重為3,正則項系數gamma為0.3,訓練樣本數據的采樣比例為0.9,樣本特征的采樣比例為0.8。
(2) LSTM模型。LSTM預測模型是堆疊式LSTM架構,第一層LSTM的units=200,第二層LSTM的units=50,全連接層輸出維度1,激活函數使用tanh,損失函數使用mse,優化器選用adam。
(3) LR模型。penalty=L2、C=0.5、solver=liblinear、max_iter=100、class_weight=balance,即模型的正則化方式為L2,懲罰系數0.5,使用了坐標軸下降法來迭代優化損失函數,模型迭代訓練100次,由模型計算不同類別樣本的權重。
3.6 實驗結果分析
通過對實驗數據集的分析發現訓練集的正負樣本比例存在嚴重失衡,為了更好地訓練預測模型本文提出數據平衡策略處理訓練數據集。在數據劃分后對訓練數據集的分析中發現未加入數據平衡策略的原始數據樣本數據的正負樣本比達到0.002 9,訓練集正負樣本嚴重失衡,為此本文利用欠采樣平衡方法對數據進行平衡發現正負樣本比為0.05時模型預測效果較好。表6給出了XGBoost預測模型、LSTM預測模型和LR預測模型在欠采樣平衡方法下的預測效果。對比各個模型在欠采樣數據平衡方法下的預測效果,XGBoost模型的預測F1值要明顯高于其他兩種預測算法,就單一預測模型來說XGBoost對于用戶購買行為預測是一個很好的選擇。
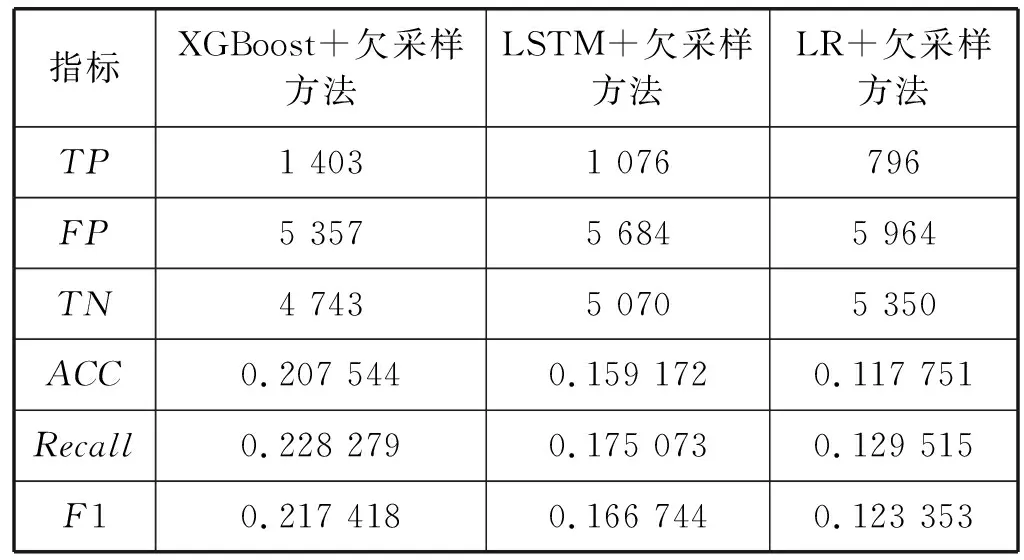
表6 欠采樣平衡方法下各模型預測效果
為了測試不同的k值對基于K-Means算法的欠采樣數據平衡方法的影響,對比了不同k值基于K-Means算法的欠采樣平衡方法下各個模型的預測效果,圖3顯示了各個模型在不同k值的基于K-Means算法的欠采樣平衡方法的預測F1值。
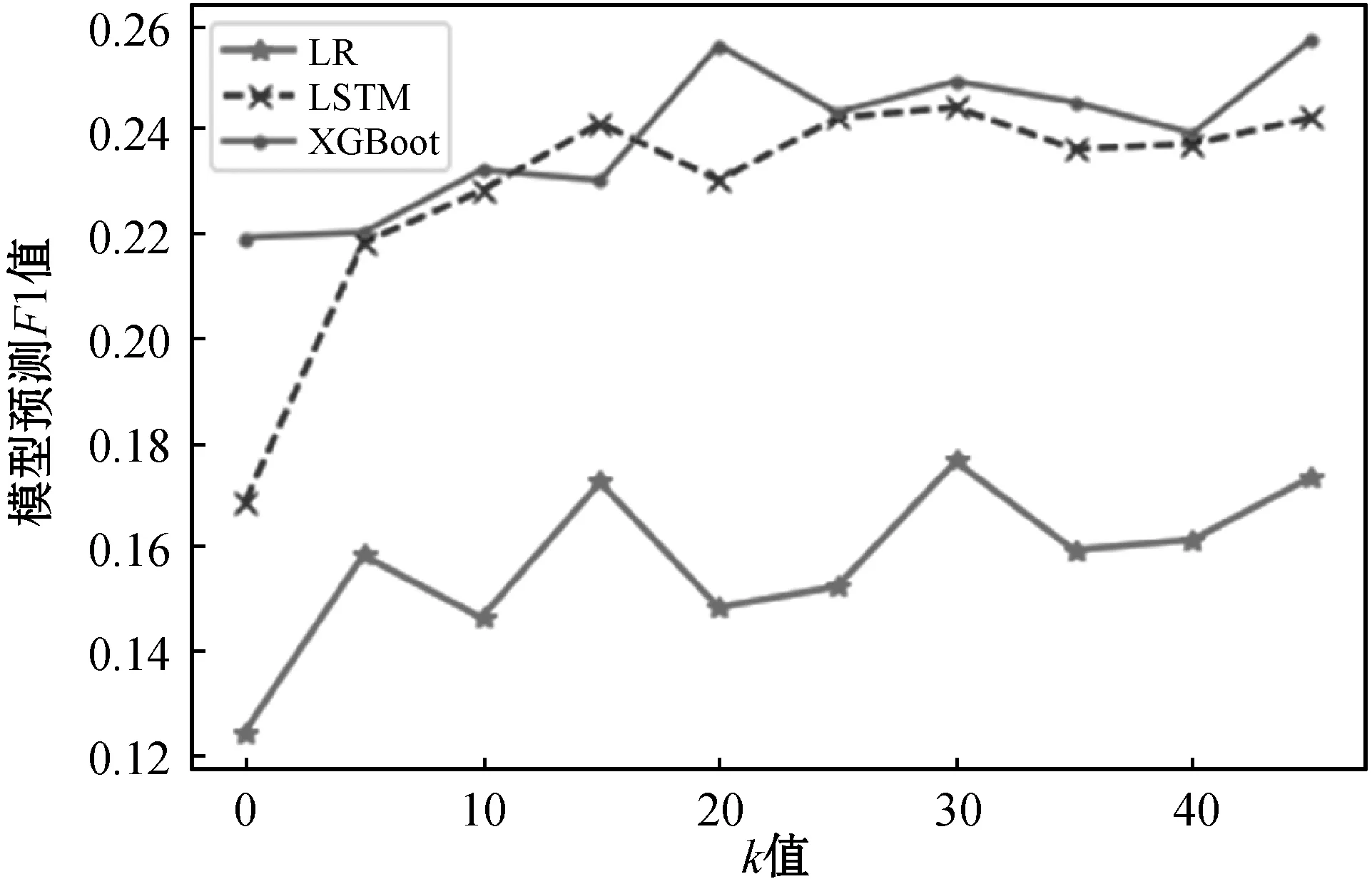
圖3 不同k值的改進隨機欠采樣方法下模型的預測效果
可以看出在隨機欠采樣平衡方法中加入K-Means算法后數據平衡效果有了明顯的提高。對比XGBoost預測模型、LSTM預測模型和LR預測模型在不同k值基于K-Means算法的改進欠采樣平衡方法的F1值,k值為30時各個模型的預測F1值都比較高。表7給出加入k值為30的改進欠采樣平衡方法后各個模型的預測效果。

表7 加入數據平衡算法模型預測效果
如圖4所示,在改進欠采樣數據平衡方法下各個模型的預測效果相較于隨機欠采樣數據平衡方法下的預測效果都有了明顯的提升,其中LSTM預測模型預測F1值增長了48%,XGBoost預測模型預測F1值增長17%,LR預測模型預測F1值增長40%。在改進隨機欠采樣據平衡方法后LR預測模型和LSTM預測模型的預測效果提升較大。
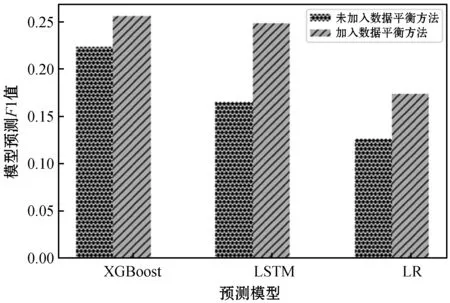
圖4 是否加入平衡方法各個模型預測F1值
為了提高預測模型對用戶購買行為預測的準確率。本文結合XGBoost在過擬合處理、訓練速度方面的優勢和LSTM算法處理時序性問題的優勢,通過集成方法將多種算法組合起來進行預測。圖5展示了融合預測模型與各個單一預測模型的預測效果,融合模型相對于單一的預測模型預測效果有很大的提升,融合模型F1值相對于預測效果最好的XGBoost預測模型提升了9%。
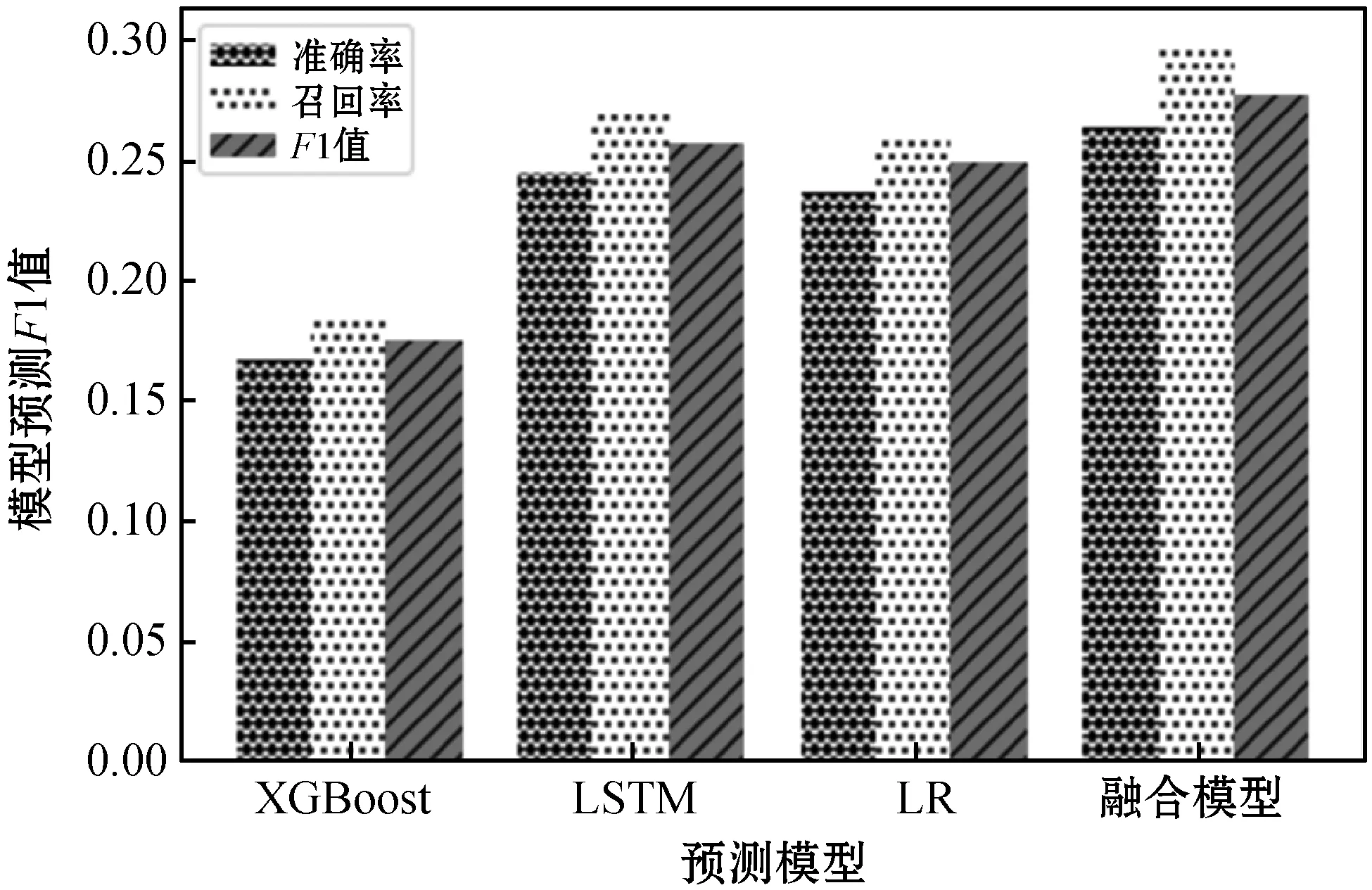
圖5 融合模型與單一模型預測效果對比
為了進一步比較各個模型的穩定性,本文將測試數據集的5個預測周期的數據劃分出5份測試數據集分別測試各個預測模型,預測結果如圖6所示。單一預測模型預測效果最好的是XGBoost預測模型,XGBoost預測模型對各個測試集的預測F1值要高于LSTM預測模型和LR預測模型,但是XGBoost預測模型對不同測試集的預測F1值差別較大。對比XGBoost預測模型的預測效果,基于XGBoost的融合模型的預測效果和預測的穩定性都要優于單一的XGBoost預測模型。

圖6 各個模型的預測F1值
4 結 語
對用戶行為數據進行分析發現用戶行為數據存在不平衡問題,正負樣本的嚴重失衡會對模型的預測效果造成嚴重影響,對此針對數據的嚴重失衡問題提出基于K-Means算法的欠采樣平衡方法,有效地解決了數據集的正負樣本嚴重失衡的情況。
本文對LR算法、LSTM算法、XGBoost算法進行分析,比較了各個預測算法的特點,利用Stacking集成方法將這些算法進行融合獲得融合預測模型算法。最后利用京東大數據提供的公開數據集設計了相關實驗,從模型預測準確率、性能等各項指標評估了各個算法模型。實驗表明模型基于XGBoost融合預測模型在預測穩定性和預測效果方面要明顯優于傳統的單一機器學習模型。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
