基于數據增強和神經網絡的小樣本圖像分類
2022-10-15 15:54:26嚴家金
現代信息科技 2022年15期
嚴家金
(1.安徽理工大學 計算機科學與工程學院,安徽 淮南 232001;2.安徽理工大學 環境友好材料與職業健康研究院(蕪湖),安徽 蕪湖 241003)
0 引 言
目前,深度學習已得到了廣泛的研究和應用,深度學習的引入使圖像數據集上的分類準確率得到了極大的提高,而這些模型大部分是基于卷積神經網絡并且需要大規模的數據集,但在實際應用中存在著很大的局限性,例如在疾病診斷、害蟲分辨、工業故障檢測等方面都沒有足夠數量的樣本去訓練,這就是所謂的小樣本學習。
小樣本學習是從人類能夠運用少量數據快速學習中得到的啟發。當訓練數據不足時,如何實現以及怎樣獲得一個具有良好性能和泛化能力的學習模型,是小樣本學習的最終目的。小樣本圖像分類的學習模型基于卷積神經網絡模型,一般分為兩種:元學習和度量學習。基于元學習的小樣本學習有兩種:基于數據增強的小樣本學習,基于模型優化的小樣本學習。
對于小樣本問題,多采用對抗生成網絡(Generative Adversarial Nets, GAN)進行數據增強。雖然GAN能使用現有數據來緩解數據量不足的問題,但是標準數據擴充只能產生有限的替代數據。基于GAN改進的DAGAN模型可以從數據集中獲取數據,并推衍生成同類數據項,是一種有效的數據增強模型。卷積神經網絡VGG是牛津大學計算機視覺組和Google DeepMind公司一起研發的,不僅在ILSVRC分類和定位任務上取得極高的準確性,而且還適用于其他類型的圖像識別。但在訓練樣本較少的情況下,單純的VGG模型很難取得理想的分類結果。使用注意力機制能夠使網絡模型更加關注重要信息并且適當過濾那些與目標任務無關的信息,使模型能夠在有限的樣本下提取到更多的有效信息。
綜合上述分析,本文為了解決樣本數量不足的問題采用了DAGAN網絡,在網絡中輸入圖片能夠按類生成多張圖片以此來擴充樣本。為了取得更好的分類效果,本文在VGG19中引入了注意力機制,在每個卷積層之后加入SE模塊以提高分類準確率,最后對主動學習進行改進并結合DAGAN提出了主動數據增強學習(Active Data Augmentation Learning)策略,通過主動數據增強學習策略找到最利于分類的樣本集大小,這樣不但可以減少不必要的訓練,而且還可以在有限的時間和資源的條件下,進一步提高分類的效率和準確率。
1 相關工作
1.1 數據增強對抗生成網絡(DAGAN)
在DAGAN中生成網絡模型由一個編碼器組成,該編碼器獲取輸入圖像(class C),將其向下投影到低維空間。對隨機向量(z)進行變換并與該向量連接;它們都將被傳送到解碼器網絡,再由解碼器網絡生成增強圖像。對抗網絡模型經過訓練,能夠區分來自真實分布和虛假分布的樣本。這樣的對抗博弈訓練能夠使模型從舊圖像生成同類但看起來完全不同的樣本,能有效地擴大訓練集,從而很好地解決訓練樣本數量不足的問題。
1.2 VGG
VGG在AlexNet的基礎上進行了改進,在VGG中使用3個3×3卷積核代替7×7卷積核,使用2個3×3卷積核代替5×5卷積核。這是因為使用3×3卷積核在感受野不變的情況下可使參數和層數變得更深,并使用三個全連接層。同時驗證了通過適當地加深網絡結構能夠提升性能。VGG結構圖如圖1所示。

圖1 VGG結構圖
1.3 注意力機制
注意力機制可以用人的視覺機制來直觀地解釋。例如,人類的視覺系統往往把注意力集中在圖像中的某些重要信息上,從而會忽略一些不重要的信息。所以注意力機制也可以理解成在輸入上不同的部分施加不同的注意力,去影響某個時刻的輸出,這里的注意力就是權重。同時通過反向傳播算法,使網絡能夠自適應地學習到最合適的權重參數。
2 主動數據增強學習和VGG-SE
2.1 VGG-SE和主動數據增強學習模型
在現實世界中,某些方面的某些類別只有少量的樣本數據,但深度學習模型在很大程度上依賴大量的訓練數據。那么在疾病診斷、人臉識別、臨床實驗、手寫字體識別等在現實中只能得到較少樣本的領域,深度學習模型的準確率是比較低的。因此,本文為了提高深度學習模型的分類準確率,同時緩解訓練過程中樣本數量不足的問題,提出了VGG-SE和主動數據增強學習。VGG-SE和主動數據增強學習模型結構如圖2所示。
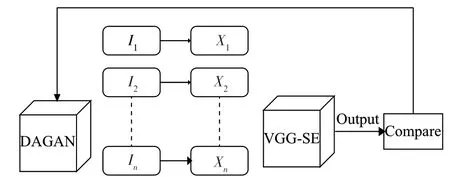
圖2 VGG-SE主動數據增強網絡模型
由圖2可以看出,本文模型包含兩個部分:引入注意力機制的分類網絡(VGG-SE)和基于DAGAN的主動數據增強學習。VGG-SE用于樣本的識別和分類,而主動數據增強學習則用來緩解樣本數量不足的問題。
2.2 VGG-SE
為了提升VGG的性能,在VGG中引入注意力機制(即VGG-SE)來提高整體網絡模型的分類準確率。由Momenta公司設計的SENET(Squeeze-and-Excitation Networks)在2017年ImageNET中榮獲分類比賽的冠軍,其提出的SE模塊結構簡單、易于實現,可以十分方便地加載到現有的網絡模型中。SE模塊能夠根據不同特征通道的重要程度對通道進行排序,以此增強重要的通道,減弱不重要的通道。SE模塊結構圖如圖3所示。
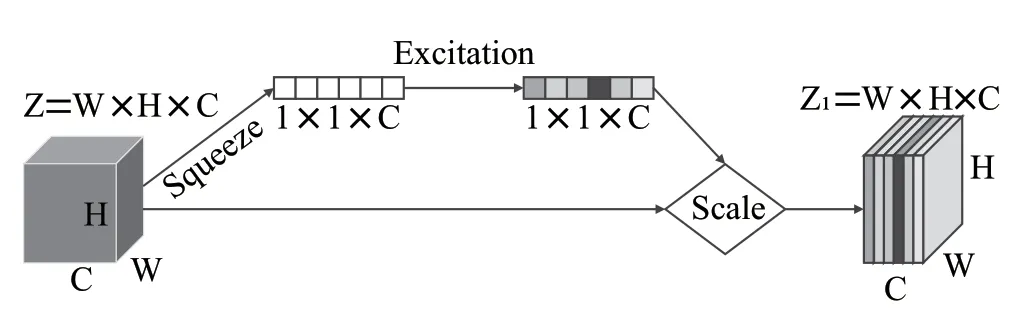
圖3 SE模塊結構
對輸入特征圖Z進行Squeeze操作,將它的每一個二維通道都變成一個具有全局感受野的實數,再使其變成1×1×C向量;再對這個向量進行Excitation操作,為每個特征通道生成權重;最后通過Scale操作,將計算得出的各通道權重和輸入特征圖Z相對應通道的二維矩陣相乘就可以得到輸出特征圖Z。
本文將SE模塊加在VGG每一個卷積層的后面,以便在每次卷積之后都能對所獲得特征圖的每個通道進行加權處理,從而在每次訓練過程中都能有效地提升有用的特征并抑制不重要的特征,如此進行良性循環達到更為準確的分類結果。改進的模型結構如圖4所示。
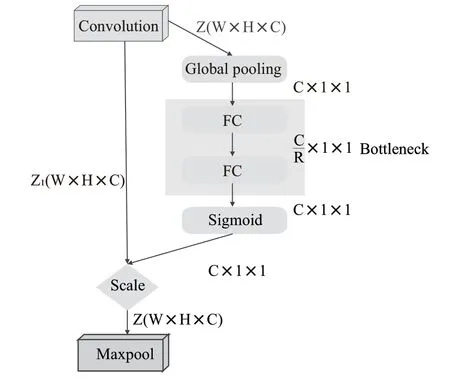
圖4 VGG-SE模型結構
使 用Global pooling作 為Squeeze操 作,兩 個Fully Connected層構成一個Bottleneck結構就可以去建模通道間的相關性,且輸出與輸入特征相同數目的權重。首先將特征維度降低到輸入的1/(是經過訓練后得到的參數),再經過ReLu函數激活后通過Fully Connected 層回到之前的維度,通過Sigmoid函數獲得0~1之間歸一化的權重,最后對歸一化后的權重進行Scale操作加權到每一個通道的特征上。
2.3 主動數據增強學習
事實證明深度神經網絡學習存在著訓練時間過長、計算量過大、過擬合、欠擬合等各種問題。為了適當緩解這些問題,本文對主動學習進行改進,提出了主動數據增強學習策略。
學習策略主要包括兩大部分:
(1)讓各個類別的少量樣本構成初始訓練集(),用經過訓練DAGAN的每50輪生成的樣本數據集作擴充訓練集(,,),再用初始訓練集去訓練網絡模型VGGSE,按類別計算模型輸出的loss,當某類別的loss大于預先設定的閾值時,則向該類別加入擴充訓練集,在該類別輸出的loss小于預先設定的閾值時則停止擴充。
(2)對每個類別進行標號(分別為1,2…),每個初始訓練集為,…X,,…I為其對應的擴充訓練集,L為每個類別輸出的loss值,設計一個分段閾值=0.2、=0.1、=0.05。訓練總共分為2輪,前輪時L與比較,中間/2輪時L與比較,后/2輪時L與比較輪時比較;當L大于閾值時則向該類別加入擴充訓練集,若小于閾值則不用加入。
主動數據增強學習結構示意圖如圖5所示。
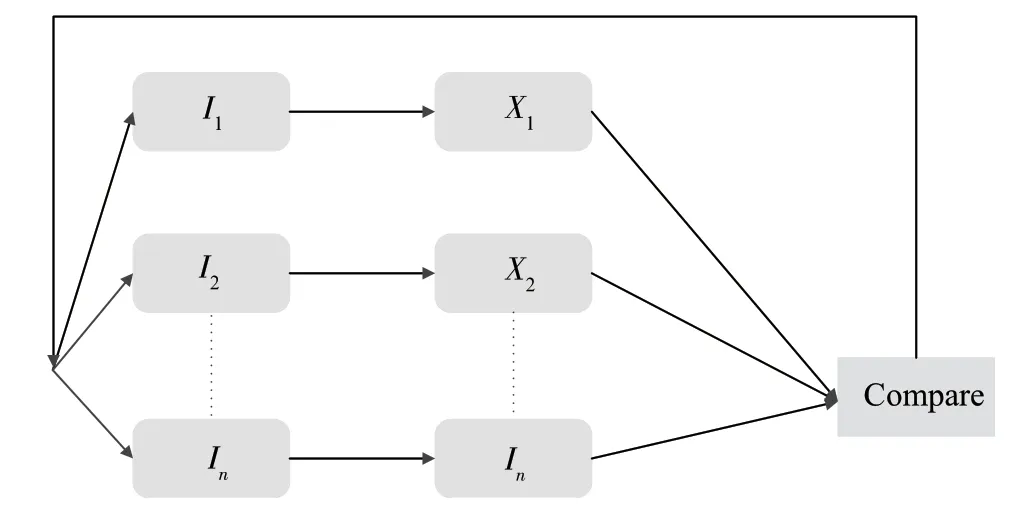
圖5 主動數據增強學習結構示意圖
3 實驗和分析
3.1 數據集描述
為了測試所提出改進模型的有效性,采用MiniImageNet和Omniglot兩個數據集。MiniImageNet數據集包含100個類,每100個類都有600張圖片,每張圖片的大小為84×84。Omniglot數據集包含50個不同的字母及其1 623個不同的手寫字符,每個字符都有20張圖片,通過將圖片進行90°、180°、270°旋轉來擴充訓練集。
MiniImageNet數據集信息描述如表1所示。
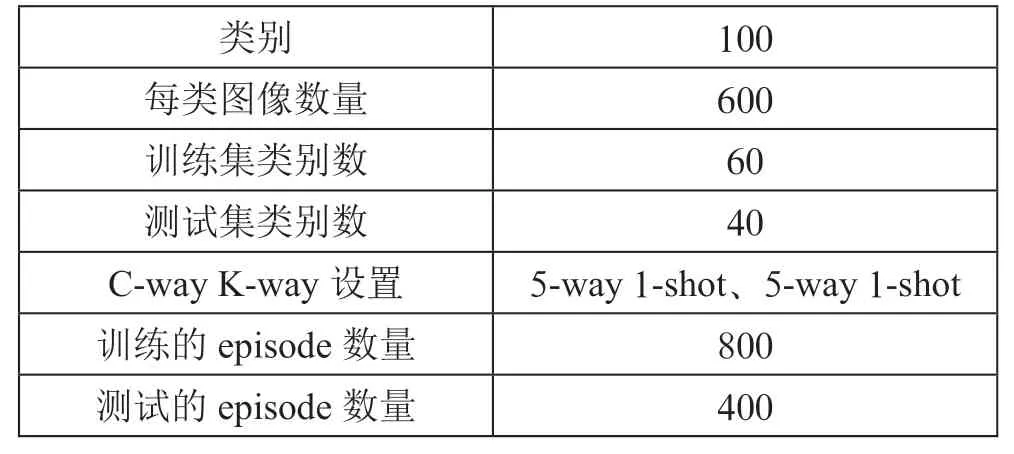
表1 MiniImageNet信息描述
Omniglot數據集信息描述如表2所示。
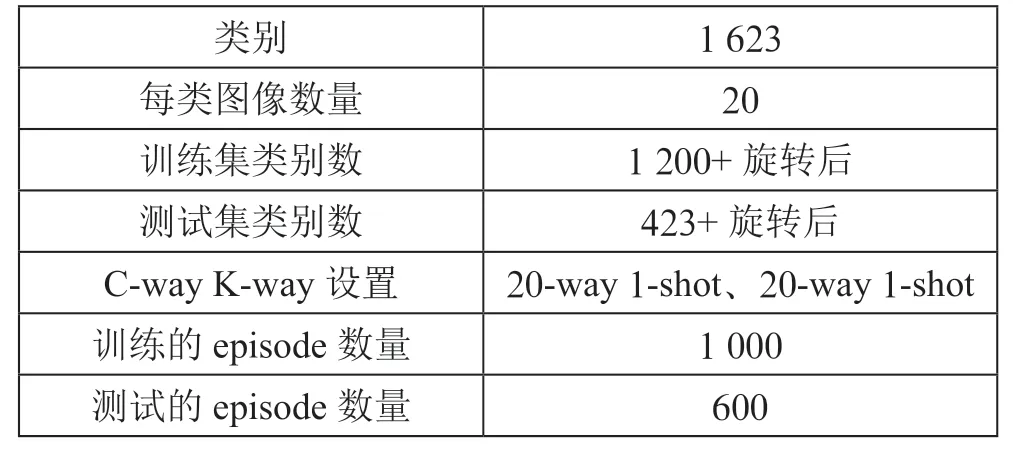
表2 Omniglot信息描述
3.2 實驗結果與分析
改進模型在兩塊Tesla P100 16 GB的顯卡上進行訓練和測試。本文改進的模型使用VGG19作為主干網絡,輸出層采用Sigmoid激活函數,其他層均采用Relu激活函數。
在實驗中,改進模型的訓練初始學習率設置為0.001,訓練總輪數為2輪,前輪時loss值與主動數據增強學習中的閾值比較,中間/2輪時loss值與比較,后/2輪時loss值與比較;當loss值大于設定的閾值時則向該類別加入擴充訓練集,若小于閾值則不用加入,學習率每次下降百分之零點一,在本次實驗中使用MiniImageNet數據集的運行輪數為400輪,使用Omniglo數據集的運行輪數為200輪。通道數從3通道擴充到64,從64擴充到128,從128擴充到256,再從256擴充到512,在每一層擴充通道的時候加上SENet對通道追加注意力機制,在對通道進行注意力操作時,首先對通道進行壓縮,在通過Sigmoid激活函數學習訓練權重后,對通道進行還原。實驗結果如表3、表4所示。
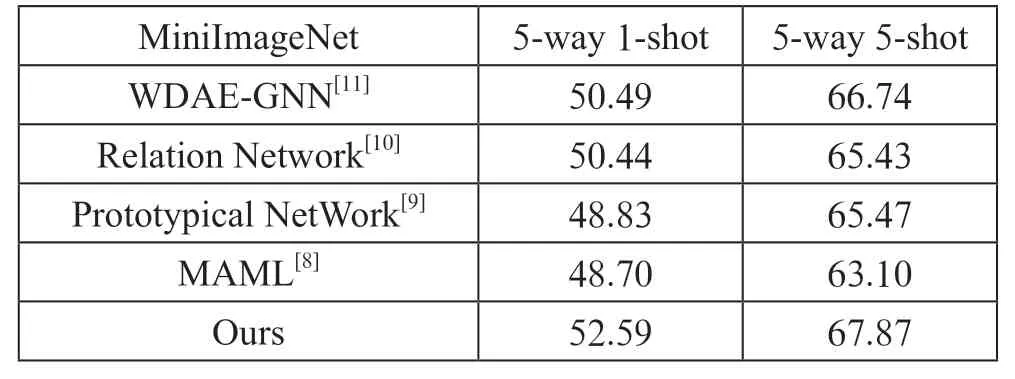
表3 在MiniImageNet數據集上的實驗結果
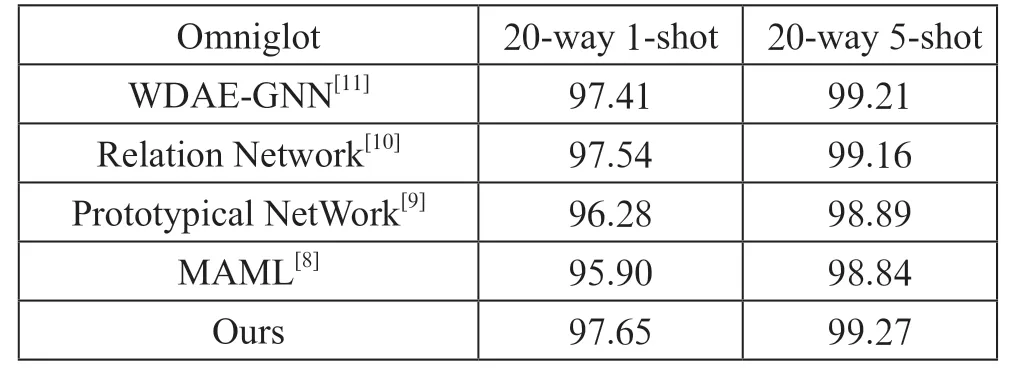
表4 在Omniglot數據集上的實驗結果
由表3和表4可以看出,在MiniImageNet數據集中,本文提出的方法在5-way 1-shot方式中的測試準確率比其他實驗模型平均高2.98%,在5-way 5-shot方式中的測試準確率比其他實驗模型平均高2.67%;在Omniglot數據集中,本文提出的方法在20-way 1-shot方式中的測試準確率比其他實驗模型平均高0.86%,在20-way 5-shot方式中的測試準確率比其他實驗模型平均高0.24%。這是因為本文通過設置閾值對loss值的時刻關注,在避免網絡過擬合的同時,在不同階段加入新的訓練樣本,使網絡的魯棒性更好。實驗中對通道進行壓縮可以適當降低學習成本。在每經過一個大的特征提取層時,網絡就能學習到更多抽象的高維特征,緊接著通過對通道注意力機制的關注,使網絡能夠輕松捕捉到各個類別間的差異,從而使得在樣本數量越少、類別數量越少時,本文模型可以取得較好的分類結果。
4 結 論
本文提出了主動數據增強學習,并在已有的網絡VGG上引入了注意力機制。主動數據增強學習能夠有效地緩解在小樣本分類中樣本數量不足的問題,用DAGAN進行數據增強能生成大量的同類型樣本,再通過主動數據增強學習合理使用訓練集的樣本量防止過擬合或欠擬合。在VGG中引入注意力機制能通過不同的通道去提升重要的特征或抑制不重要的特征從而提高網絡的分類效果。實驗證明,本文提出的方法在MiniImageNet數據集和Omniglot數據集上都取得了比基準模型更好的效果。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
