面向語義分割模型的外接多尺度投票網絡
2022-10-16 12:27:58朱杰龔聲蓉周立凡徐少杰鐘珊
計算機工程 2022年10期
朱杰,龔聲蓉,周立凡,徐少杰,鐘珊
(1.東北石油大學 計算機與信息技術學院,黑龍江 大慶 163318;2.常熟理工學院 計算機科學與工程學院,江蘇 蘇州 215000)
0 概述
語義分割是計算機視覺領域的重要課題之一,其目的是為圖像中的每一像素分配類別標簽。得益于卷積神經網絡(Convolutional Neural Networks,CNN)能夠提取高層語義信息的獨特優勢,基于CNN 的語義分割算法[1-3]取得了巨大成功,在精度、速度上均超越了傳統圖像語義分割算法。然而,語義分割網絡在提取高層語義信息時需不斷下采樣,容易丟失部分空間細節信息,導致網絡在目標邊緣、長條狀目標,尤其是小目標處的分割效果不佳。
目前,主流語義分割網絡[4-6]在訓練時通常采用批處理方式提高內存利用率、減少迭代次數、協同批量歸一化[7],同時減少內部協變量偏移,加速深度網絡訓練。梯度下降的方向越準確,引起的訓練震蕩越小,分割精度提升越明顯。但此類方法嚴重依賴高性能顯卡(如GPU 集群)才能設置較大的批處理參數,達到較高的分割精度。低端顯卡由于顯存有限,僅能設置較小的批處理參數,有時甚至無法進行訓練。此外,需要通過選取合適的預訓練權重,在高性能顯卡中不斷更換訓練策略、調參、驗證才能獲得具有較高精度的模型,且在修改網絡后,還需重新進行上述步驟,運行周期長,占用計算資源過多。
本文提出面向語義分割模型的外接多尺度投票網絡,將共享網絡中的分割網絡與各尺度注意力頭剝離開,僅訓練各尺度注意力頭,以方便網絡收斂。將各尺度注意力頭在最佳分割模型下的預測結果按投票權值進行加權融合,通過融入混合池化模塊,聚合權值圖中的近程與遠程整體背景,為整個網絡提供全局信息,擴大感受野,從而緩解權值圖中長條狀目標擬合間斷與缺失的問題。引入類內、類間投票注意力模塊,并嵌入1×3、3×1 卷積塊,以獲取類內投票權值與類間投票權值關系,改善投票權值圖的邊緣擬合效果。
1 相關研究
近年來,基于CNN 的圖像語義分割方法取得了重大進展。本節將討論針對目標邊緣、長條狀目標、尤其是小目標分割效果不佳的3 類相關改進方法,即上下文信息采集、多尺度特征圖融合、多尺度圖像共享網絡方法。
1.1 上下文信息采集
獲取圖像上下文信息是擴大卷積網絡感受野的有效方法,ZHAO等[3]提出金字塔 池化模塊(Pyramid Pooling Module,PPM)融入多尺度上下文信息,可增強不明顯的小目標、條狀目標(例如與周圍環境顏色相近的路桿、行人)的捕獲能力。CHEN等[8]提出空洞空間金字塔池化(Atrous Spatial Pyramid Pooling,ASPP),將空洞卷積與金字塔池化方法相結合,從而鋪抓更充分的上下文信息。CHEN等[4]在此基礎上提出利用編碼器-解碼器結構逐步重構空間信息,可更好地捕捉目標邊緣。FU[9]等提出雙注意力網絡獲取像素間、通道間的特征依賴關系信息,改善了類內混淆、目標邊緣缺失等問題。HOU等[10]提出條狀池化方法,更易于捕獲遠程特征依賴關系,改善了長條狀目標的分割效果。但上述方法在下采樣過程中容易丟失細節信息,導致較細的長條狀目標難以成功分割,在長條狀目標的邊緣處存在分割模糊的問題。
1.2 多尺度特征圖融合
LONG等[1]提出全卷積神經網絡進行圖像語義分割,在實驗中觀察到不同深度的卷積層分割結果存在較大差異,提出使用跳躍連接方法將淺層獲取到的細節信息與高層語義信息進行融合。RONNEBERGER等[2]在LONG 等的基礎上提出類U型的編碼器-解碼器結構,將更多淺層細節、紋路特征與深層語義特征進行融合,改善了小目標與目標邊緣處的分割效果。ZHANG等[11]針對語義層和淺層的差異較大,淺級特征噪音較多,簡單地融合淺層和深層的效果不佳問題,在淺層特征中引入語義信息,并在深層特征中引入高分辨率細節,以有效融合淺層與深層的特征。FAN等[12]提出短期密集連接模塊,提取具有可伸縮感受野和多尺度信息的融合特征。但上述方法只能提取單一尺度圖像特征,細節信息的提取能力有限。
1.3 多尺度圖像共享網絡
在同一網絡下,不同尺度圖像的分割結果存在部分差異,基于此,CHEN等[13]將多個調整尺度的圖像輸入注意力網絡,加大各尺度權重。YANG等[14]在CHEN 等的基礎上提出多尺度網絡分支方法,并在預測階段融合特征。TAO等[15]針對上述方法依賴固定放縮比例與數量的尺度組合提出多層次多尺度注意力機制,以擬合相鄰尺度間的注意力權重,同時在預測分割結果時靈活擴展更多尺度,使網絡獲得更高的分割精度。但網絡需承擔額外尺度的輸入,訓練復雜度高。
為利用網絡在不同尺度下的分割優勢,DAI等[16]與PAPANDREOU等[17]分別使用平均池化、最大池化融合各尺度的分割結果。但由于網絡對各尺度的分割優勢不同,因此武斷地取最大值或平均值容易導致正確分割的像素被其他尺度干擾,精度提升效果不佳,甚至下降。受共享網絡[15]啟發,本文將分割網絡與各尺度注意力頭融為一體。但在訓練時,除了在原尺度上的訓練開銷,網絡需額外承擔其他尺度的輸入,這成倍增加了訓練復雜度。此外,尺度間的差異難以界定,以致網絡較難收斂,且當修改網絡后需重新訓練,原模型的價值喪失。
針對上述訓練成本過高的問題,本文期望復用具有最高精度的模型,并在其基礎上改善模型在小目標、長條狀目標、目標邊緣處的分割效果。得益于現有的語義分割網絡通過采用隨機尺度縮放進行數據增強,使圖像放縮后也能保持較高分割精度的方法,本文定量分析圖像縮放后的不同分割效果,將放縮后的各尺度圖像輸入同一已訓練的分割網絡中,以達到提高分割精度的目的。
2 外接多尺度投票網絡
2.1 投票網絡總體結構
圖1 所示為投票網絡結構,其中每個模塊已用虛線框出。其中:通道數C1為分割類別數;通道數C2為網絡層數,設為64;H 為高度,值為1 024;W為寬度,值為2 048;α為位置注意力權重;β為通道注意力權重;可視化指使用三線性插值(2 倍),各通道逐點相加,將各像素點歸一為0~255。當只使用TAO 網絡時,發現提升效果不明顯,通過分析發現該網絡主要存在以下問題:未利用每一類的投票權值偏好;未獲取較全面的上下文信息;未挖掘類內投票權值與類間投票權值關系;投票權值圖在目標邊緣處有一定概率會發生擬合間斷。針對上述問題,本文分別構建4個相應的模塊進行改進。
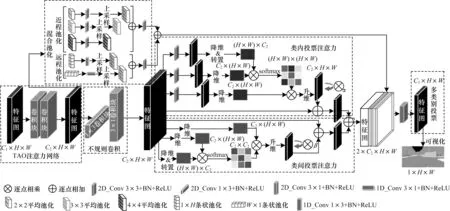
圖1 外接投票網絡結構Fig.1 Structure of external voting network
2.1.1 多類別投票模塊
由于TAO 網絡僅輸出通道數為1 的注意力圖,忽視了每一分割類別存在特有的投票權值偏好。為此,本文提出多類別投票模塊,以擴大投票選擇空間。以語義分割數據集Cityscapes[18]為例,該數據集包含19 個類別,多類別投票模塊在此數據集上分割所得的結果特征圖含19 個通道,得到19 個類別的投票權值圖,由于改方法在每一個類上分別進行投票,因此擴大了19 倍的投票選擇空間。
2.1.2 混合池化模塊
在TAO 網絡中,由于網絡層數較少,導致感受野過小,無法獲取較遠距離的投票信息與整體投票信息,以致較大目標與長條狀目標的投票權值擬合效果不佳。在語義分割任務中構建上下文信息采集模塊[3,6,10]是改善該問題的常見方法。HOU等[10]提出混合池化方法,有效改善了長條狀目標與較大目標的分割效果,且計算開銷不大。為改善投票權值圖在大目標與長條狀目標處的擬合效果,受HOU等[10]啟發,本文利用混合池化模塊聚合近程與遠程的相關投票權值信息。圖1 左上角所示為混合池化模塊,其中近程池化融合了3 種不同尺度的標準空間池化模塊,且引入標準2D 卷積塊進行擬合,因此更容易捕捉近程投票信息,能夠改善較大目標的投票擬合效果。遠程池化通過水平與垂直池化方法將水平與垂直的信息分別壓縮到1D,并引入1D 卷積塊進行擬合,從而更容易捕獲到遠程投票信息,改善長條狀目標的投票擬合效果。
2.1.3 類內、類間投票注意力模塊
在語義分割任務中,金字塔池化僅能獲取全局的上下文信息,卻無法利用全局視圖中像素、類別間的關系。文獻[9]提出一種位置注意力機制捕獲特征圖中任意2 個通道間的空間依賴關系。由于投票網絡無法學習到類內、邊緣權重的相鄰關系,導致類內混淆,邊緣間斷。類內注意力模塊通過所有位置特征的加權,選擇性地聚合每個位置的特征,使網絡學習相鄰位置關系。類間投票注意力模塊能學習到更多類間關系,并能選擇性地強調相互依賴的通道映射。此外,令注意力圖分別乘以初始為0的α、β可學習參數,若某一注意力方法無法提升精度,參數便會趨近于0,能夠避免精度下降。
2.1.4 不規則卷積模塊
針對常規卷積核長寬相同,較難學習線條狀特征的問題,MOU等[19]提出1×3 與3×1 的非對稱卷積,可更好地捕捉線條狀特征。由于投票網絡亟需擬合線條狀的目標邊緣信息,如圖1 中不規則卷積模塊所示,因此本文參考文獻[19]引入1×3、3×1 卷積,后接一個批量歸一化(Batch Normalization,BN)與激活函數ReLU,改善投票權值圖中目標邊緣的擬合效果。
為增加本文方法的可解釋性,將投票權值圖各通道逐點相加,歸一化到0~255 之間,并將其進行可視化,結果如圖1 右下黑白圖像所示。本文將在3.4 節對投票權值圖的可視化圖進行具體分析。
2.2 各尺度分割結果對比
為驗證本文方法的前提條件,即不同尺度的相同圖像在同一已訓練分割網絡下的分割結果不同,本文采用在開源框架OpenMMLab[20]訓練的最佳DeepLabv3+[4]語義分割網絡模型,并在無人駕駛標桿數據集Cityscapes[18]上進行實驗。
圖2 所示為不同尺度圖像的預測流程,其中小尺度圖像為長寬縮小1 倍,原尺度為原圖,大尺度圖像的長寬放大1 倍,將其分別輸入到已在Citysca-pes數據集下訓練的DeepLabv3+模型中,得到各自的分割結果。如某像素歸類為車輛,則用對應顏色掩膜掩蓋,最后將掩膜與原圖疊加。為便于觀察,將圖2中小尺度圖像上采樣2 倍、原尺度圖像不變、大尺度圖像下采樣2 倍,各尺度保持同樣長寬大小,并將預測的分割掩碼疊加在原圖上,分割結果如圖3 所示(彩色效果見《計算機工程》官網HTML 版),其中小目標用白圈標出,長條狀目標用黑圈標出。
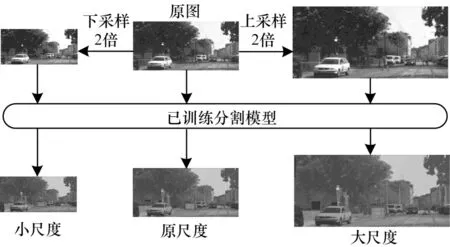
圖2 不同尺度圖像的預測流程Fig.2 Prediction process of different scale images
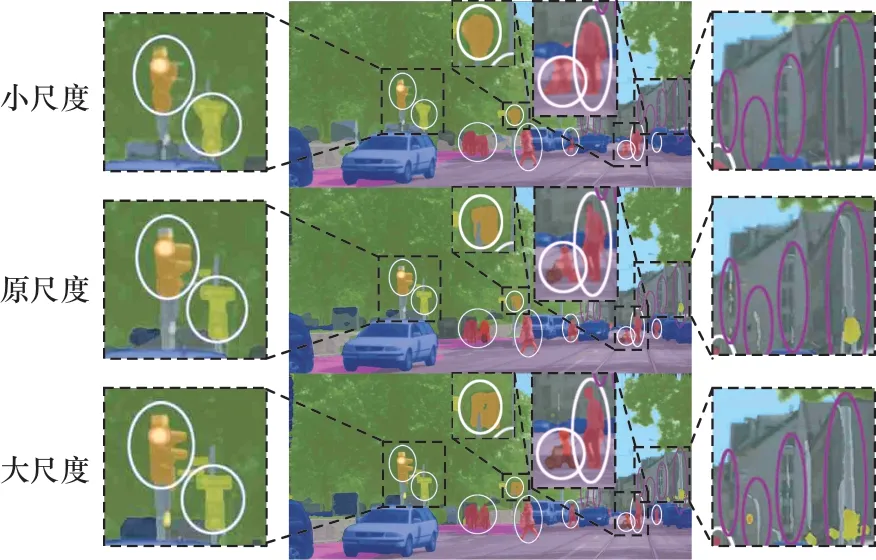
圖3 不同尺度圖像的分割結果對比Fig.3 Results comparison of different scale segmentation
為方便敘述,按每組虛線框出現的順序對虛線框進行標號,從左至右分別為左1、左2、左3、左4,從左至右觀察圖3 可以發現以下現象:
1)在左1 虛線框中,在分割目標邊緣時,大尺度圖像相較于原尺度圖像、小尺度圖像,分割結果愈加精細。
2)在左2 虛線框中,原、大尺度圖像的分割結果過于追求細節,導致目標內部分割間斷。小尺度圖像在邊緣處分割得不平整,在目標內部不過分追求細節,更注重目標整體信息,目標內部分割效果較好。
3)在左3 虛線框中,在分割小目標時,大尺度圖像能夠正確分割出騎手小目標,而原尺度、小尺度圖像將騎手誤識別成行人,且邊緣分割效果明顯弱于大尺度圖像。
4)在左4 虛線框中,在分割長條狀目標時,大尺度圖像的分割效果相較于原尺度圖像、小尺度圖像,捕捉的長條狀目標信息依次增多,漏檢概率逐漸降低。
以上實驗數據將在第3 章節中給出,并測試各尺度總體及不同類的分割精度。總體上,原尺度圖像的總精度最高,小尺度圖像的總精度最低。而在某些類別中,如行人、騎手(小目標),柵欄、路桿(長條狀目標),大尺度圖像的分割精度高于原圖。但由于目標內部分割效果不佳,限制了大尺度圖像的分割精度。
根據上述實驗,各尺度圖像的分割結果都有獨特的優勢,本文旨在結合各尺度圖像優勢,提升分割精度。
2.3 訓練方式
與一般語義分割網絡的訓練方式不同,投票網絡不改變分割網絡模型,僅訓練投票網絡。在網絡訓練方式上,本文沿用TAO等[15]的方法,僅訓練相鄰尺度間的相對關系,并靈活增加其他尺度,不再針對某一尺度額外訓練。將給定的輸入圖像按因子r進行縮放,其中r=0.5 表示按因子2 下采樣,r=2 表示按因子2 進行上采樣,r=1 代表原圖。由上文多尺度預測的實驗結果可知,下采樣2 倍的圖像與原圖的分割精度相差較大,更能突出尺度間的相對差異,因此本文采用小尺度圖像和原圖進行訓練。
如圖4 所示,將原尺度圖像和下采樣2 倍的圖像分別輸入已經過訓練的DeepLabv3+網絡中,得到各尺度預測特征圖F。為保持相同尺度,將小尺度預測的特征圖上采樣(三線性插值)2 倍后,輸入需訓練的投票網絡中,擬合小尺度的投票權值圖Wr=0.5,并用1 減去小尺度的投票權值結果,作為原尺度的投票權值圖(1-Wr=0.5)。即若小尺度某一像素投票權值為0.2,那原圖對應像素的投票權值為0.8。最后將小尺度和原尺度的投票權值圖分別與對應尺度預測的特征圖相乘后相加,經過Softmax 函數得到投票后的預測結果,其表達式如式(1)所示:
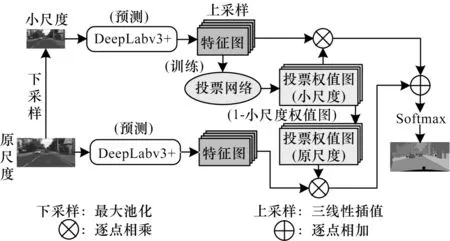
圖4 投票網絡的訓練結構Fig.4 Training structure of voting network
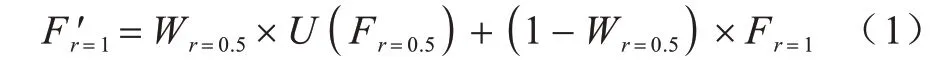
其中:U代表將特征圖上采樣2 倍;D代表下采樣2 倍。
2.4 預測方式
在訓練得到相鄰尺度間的投票網絡后,在預測時分層次靈活地應用此網絡,并將若干相鄰尺度的預測結果進行整合。采用下采樣2 倍、原尺度、上采樣2 倍的圖像進行舉例,如圖5 所示。
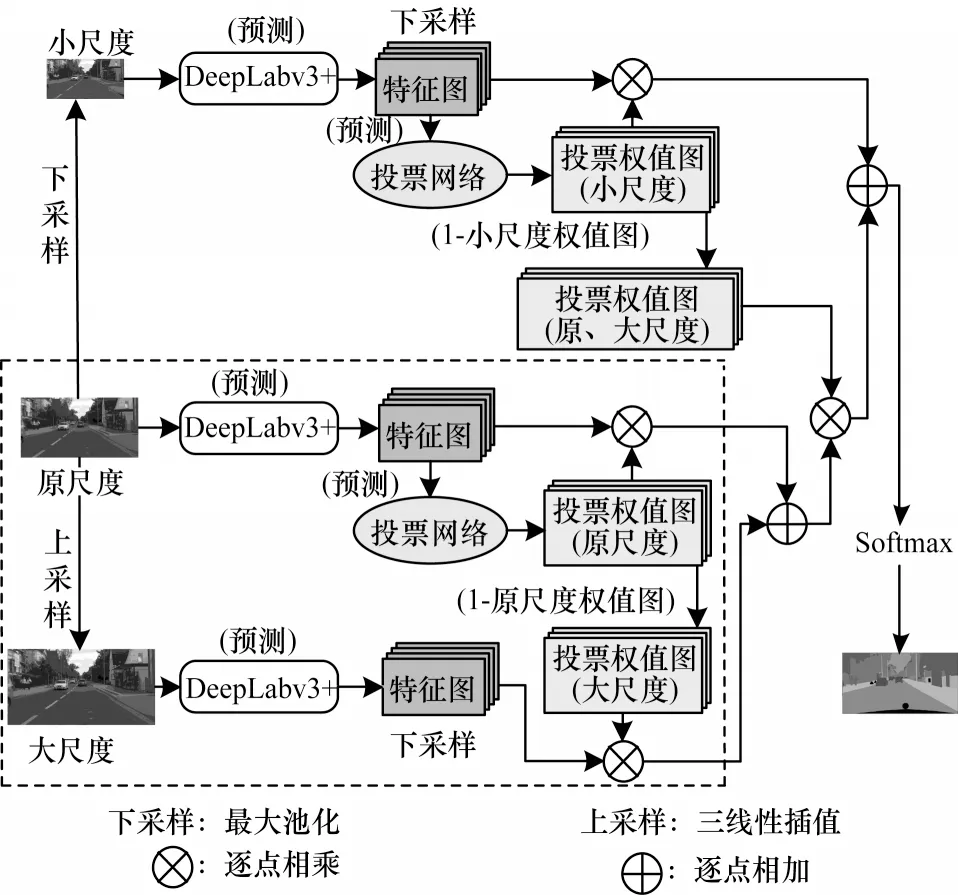
圖5 投票網絡的預測結構Fig.5 Prediction structure of voting network
將原圖分別進行上、下采樣,其中,圖5 虛線框內為大尺度圖像和原圖的成對預測結構(與訓練結構相同),并得到大尺度圖像和原圖投票的預測結果,如式(2)所示:
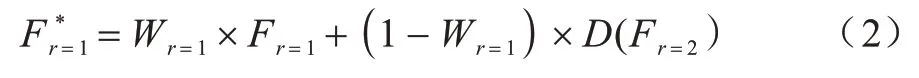
將圖5 中虛線框圈出的部分作為一個整體,與小尺度分割結果以相同方式結合,得到最終的分割結果,表達式如式(3)所示:
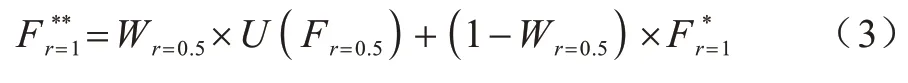
3 實驗結果與分析
3.1 實驗環境
使用深度學習框架Pytorch[21]實現投票網絡,本文實驗的硬件和軟件環境如表1 所示。將本文網絡在Cityscapes[18]大型街景數據集上進行驗證。該數據集是目前公認的具有較強權威性、專業性的圖像語義分割評測數據集,包含了50 個城市不同場景、背景、季節的街景,提供了5 000 張精細標注圖像、20 000 張粗略標注圖像,分別對應精細和粗略兩套評價標準。本文采用精細標注的5 000 張高分辨率圖像進行實驗,其標注了19 個語義類,并以精細評價標準驗證本文方法。
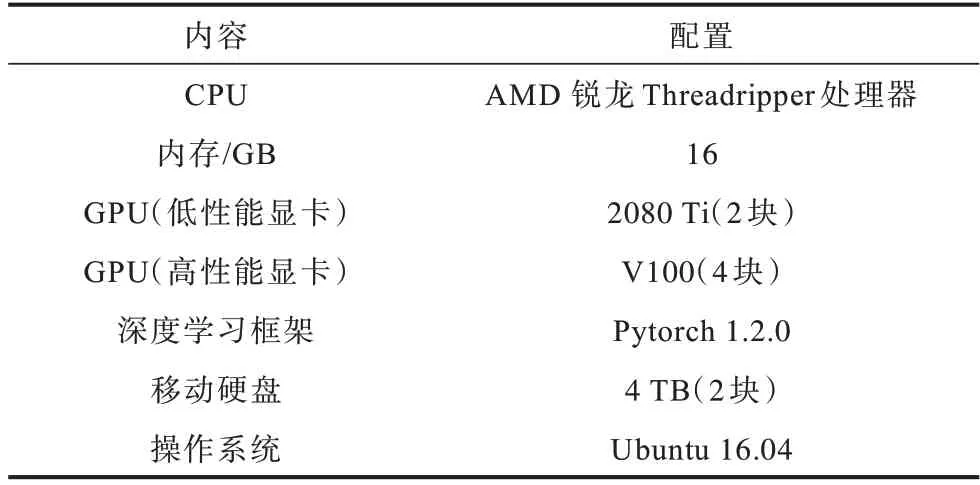
表1 實驗硬件與軟件配置Table 1 Experimental hardware and software configuration
本文在訓練投票網絡時與一般分割網絡不同,并不直接將圖像輸入網絡,而是保留不同尺度圖像的分割結果,再輸入投票網絡進行訓練。采用開源框架OpenMMLab[20]共享的不同分割網絡模型進行實驗,以保證實驗的可靠性與公平性。為保證實驗的一致性,實驗均選用在高性能顯卡、相同訓練策略下得到的模型,并將其定義為最佳模型。具體訓練細節如下:采用4 塊V100 顯卡訓練,骨干網絡選取ResNet50-B[22],以隨機梯度下降算法優化模型,交叉熵為損失函數,動量設為0.9,學習率為0.01,權重衰減為0.000 5,隨機尺度縮放比例為0.5~2 倍,隨機裁剪大小為769×769 像素,批處理參數設為8,迭代訓練80 000 次。根據以上規則在不同分割網絡上訓練模型。
以DeepLabv3+網絡為例,在網絡中輸入不同尺度的圖像,得到不同尺度的分割結果,再將其經過上、下采樣操作變回原圖的大小,轉換成NumPy 格式保存。其中,通道數為分割類別數,長寬與原圖相同,每張圖像各尺度分割結果的文件大小為155 648 KB。
在訓練投票網絡時,由于無需再重新訓練分割網絡,僅需訓練投票網絡,因此僅采用2 塊低性能顯卡2080 Ti 訓練,并以隨機梯度下降算法優化模型,將批處理參數設為2,動量設為0.9,學習率為0.001,學習率衰減乘數因子為0.1。由于目標邊緣占圖像比例較小,因此采用Focal Loss[23]作為損失函數,從而緩解邊緣和整體圖像比例嚴重失衡的問題。在Cityscapes 數據集[18]中,投票網絡進行80 000 次迭代訓練后,通過結合各尺度分割結果,達到對比網絡中較高分割精度。
3.2 評價指標
本文采用語義分割中通用的評價指標平均交并比(mean Intersection over Union,mIoU)評價本文方法,通過計算各類預測值和真實值2 個集合的交并集之比,再取其平均值,mIoU 的表達式如式(4)所示:
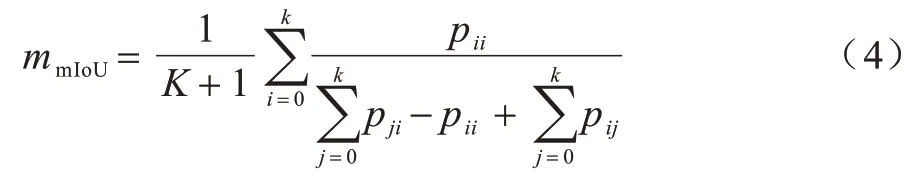
設存在K+1 個類別,存在一個背景類,pij代表i類被錯誤預測成j類的像素數量;pii代表預測正確的像素數量,通過計算預測結果與真值的重合程度判斷分割效果。mIoU 的值域為0~1,數值越大,代表分割精度越高。
3.3 投票網絡有效性驗證
為驗證本文網絡的有效性,選用經過開源框架OpenMMLab 訓練的 DeepLabv3+最佳網絡(DeepLabv3+*網絡)作為基線網絡與其他網絡進行對比,測試不同網絡對不同尺度圖像的分割精度。此外,將文獻[16]所提網絡和文獻[17]所提網絡在不同圖像尺度(圖像放縮為原尺度后,對應像素求平均值)上進行實驗。結果如表2 所示,其中:1.0 代表圖像原尺度,2.0 代表圖像的長寬各放大2 倍,0.5 代表圖像的長寬各縮小2 倍,0.25 代表圖像的長寬各縮小4 倍;分割網絡采用4 塊V100 顯卡訓練,投票網絡僅采用2 塊2080Ti顯卡訓練,由于訓練投票網絡需在分割網絡模型基礎上進行,為進行區分,將本文方法的訓練顯卡用+2*2080Ti表示(下同)。由表2 可知,實驗結果與前文所述相同,mIoU 的提升效果不佳,但本文網絡的精度提升幅度最大。與DeepLabv3+*網絡在尺度為1.0的圖像下的mIoU值相比,本文網絡在組合原尺度和大尺度圖像時,mIoU提升0.76個百分點,在組合3個尺度時,mIoU提升0.89個百分點,在組合4 個尺度時,可提升0.92 個百分點。由表2 還可以得知,投票網絡在最佳網絡模型基礎上可達到的較高分割精度為80.30%。
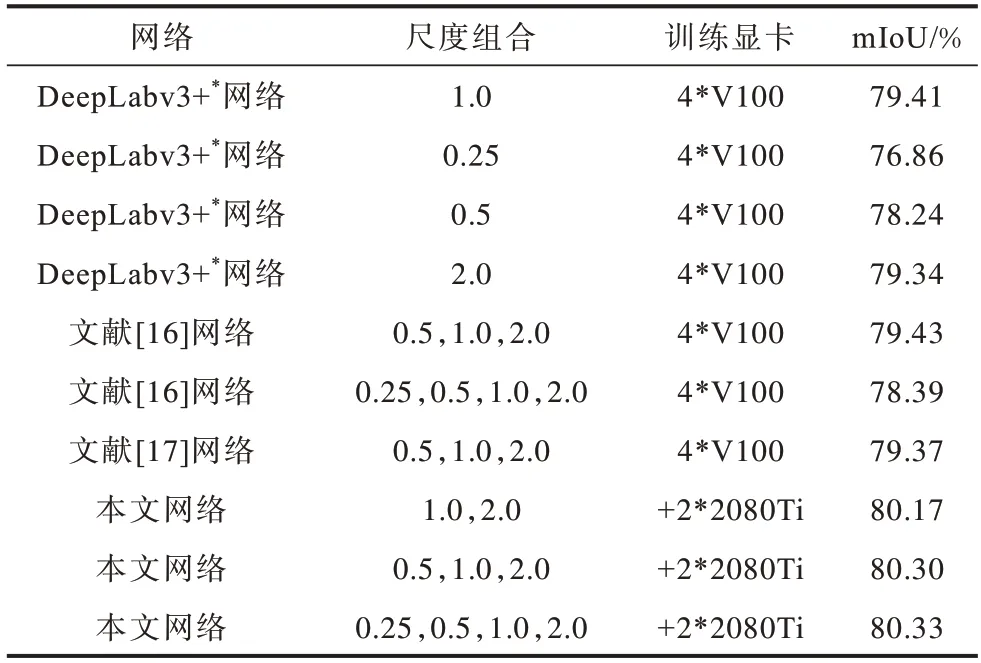
表2 不同網絡的實驗結果對比Table 2 Comparison of experimental results of different networks
為驗證本文方法的通用性,基于3.1 節下的規則,選用FCN[1]與PSPNet[2]網絡訓練的最佳模型(分別為FCN 模型*、PSPNet模型*)進行實驗,并使用在2*2080Ti顯卡上訓練出的DeepLabv3+[13]模型(DeepLabv3+(本地))進行對比實驗,結果如表3所示。由表3可以看出,本文網絡可以在其他經典網絡的基礎上提高模型的分割精度。且由于FCN 模型邊緣分割的效果弱于PSPNet和DeepLabv3+(本地)模型,因此在使用本文網絡時精度提升幅度更大。
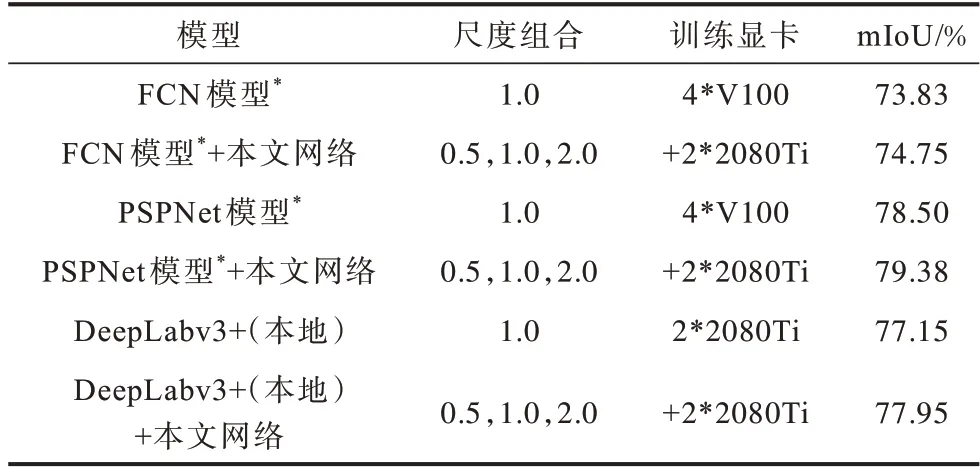
表3 不同語義分割模型的結果對比Table 3 Comparison of results of different semantic segmentation models
3.4 投票權值可視化
為增加本文方法的可解釋性,將投票網絡學習到的權值圖進行可視化。以相鄰尺度的投票權值圖為例,分別將原尺度、大尺度的投票權值圖各通道合并,并歸一化到0~255 之間,得到圖6、圖7 所示的灰度圖。其中某像素越趨近于白色,權值越趨近于255,即投票權重越大;像素越趨近于黑色,權值越趨近于0,即投票權重越小。
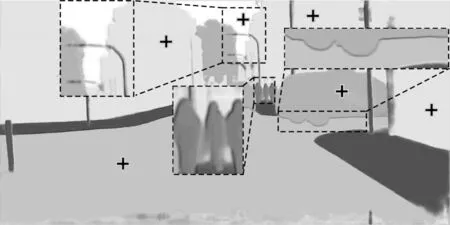
圖6 原尺度投票權值圖可視化Fig.6 Visualization of the original scale voting weight map
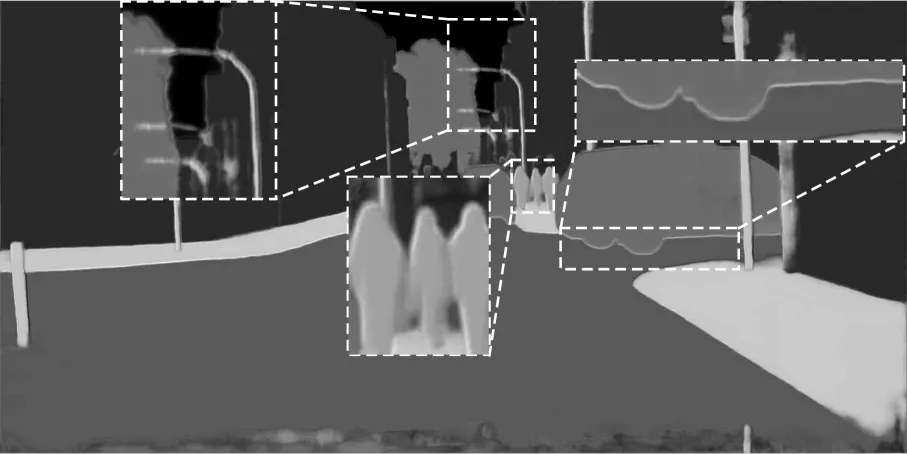
圖7 大尺度投票權值圖可視化Fig.7 Visualization of the big scale voting weight map
為方便敘述,按每組虛線框出現的順序對虛線框進行標號,從左至右分別為左1、左2、左3。由圖6、圖7 可知:
1)在小目標、長條狀目標處,如在左1、左2 虛線放大框中,路桿(長條狀目標)與行人(小目標)內部在大尺度權值圖中更趨近白色,在原尺度中趨近黑色,即網絡更趨向于相信大尺度圖像的分割結果。權值圖并未完全趨近白色,這說明網絡避免了大尺度面臨的內部分割間斷問題。
2)在目標邊緣處,如在左3 虛線放大框中,車輛邊緣在大尺度權值圖中更趨近白色,在原尺度中趨近黑色,即網絡在邊緣處更趨向于相信大尺度的分割結果。在左2 虛線放大框中,也可明顯發現在邊緣處更趨近白色。
3)相較于目標邊緣,網絡在目標內部稍趨向于相信原尺度的分割結果,而在非小、長條狀目標內部,這一趨勢更為明顯。如圖6 中十字形標出的非小、長條狀目標內部區域,在原尺度權值圖中更趨近白色,在大尺度中趨近黑色,即在非小、長條狀目標內部,網絡更趨向于相信原尺度的分割結果。
綜上,圖6、圖7 顯式地驗證了本文網絡的有效性。
3.5 消融實驗
為驗證本文網絡中各子模塊的有效性,選用經過開源框架OpenMMLab 訓練的DeepLabv3+最佳網絡(DeepLabv3+*網絡)進行消融實驗,并量化分析各模塊的作用,即在Deeplabv3+*基礎上加入各模塊,從而分析本文網絡各模塊的作用。該實驗中模塊的添加為逐漸累積的過程,比如在添加多類別投票模塊(+多類別投票模塊)的基礎上,再添加混合池化模塊,以此類推,結果如表4 所示,其中,TAO 網絡(本地)表示將TAO 網絡在本文網絡上進行實驗。
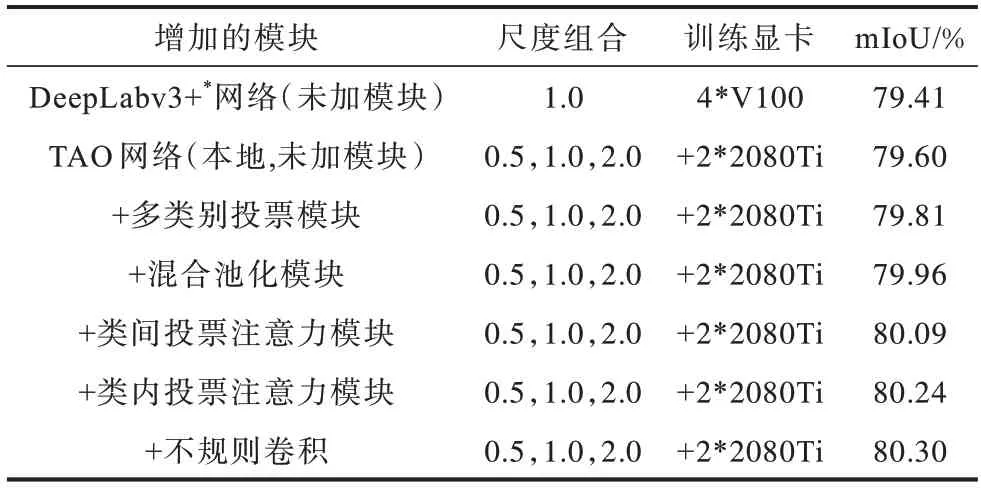
表4 本文網絡各模塊的消融實驗結果Table 4 Ablation experiments for each module of network in this paper
由表4 可知,與DeepLabv3+*網絡相比,TAO 網絡(本地)的mIoU 提升效果不明顯。通過分析發現,TAO網絡由于未考慮每一類的投票權值偏好,因此投票選擇空間有限。此外,TAO 網絡僅堆疊了2 層卷積,感受野過小,因此通過融入混合池化模塊可分別獲取近程與遠程的相關投票權值信息,尤其改善長條狀目標的投票權值擬合效果。為進一步獲取類內、類間投票權值關系,本文在投票網絡中分別加入類內、類間雙投票注意力模塊,以獲取相鄰投票權值關系,選擇性地加強相互依賴的類間投票映射。如表4 所示,當加入類間投票注意力模塊時,精度相比僅增加多類別投票模塊和混合池化模塊可提升0.13 個百分點,當加入類內投票注意力模塊時,精度在此基礎上可提升0.15 個百分點。最后本文通過采用不規則卷積優化投票權值圖在目標邊緣的處理,從而提升投票權值圖的目標邊緣擬合效果,但由于邊緣所占像素較小,因此在總體精度上僅有較小幅度的提升。
3.6 投票網絡與共享網絡對比
為量化分析投票網絡與共享網絡的差異,采用本地2 塊2080Ti 顯卡對網絡進行訓練,結果如表5 所示。由于投票網絡在模型外部訓練,而共享網絡的多尺度注意力頭在模型內部訓練,所以采用內、外分別表示共享網絡和投票網絡。
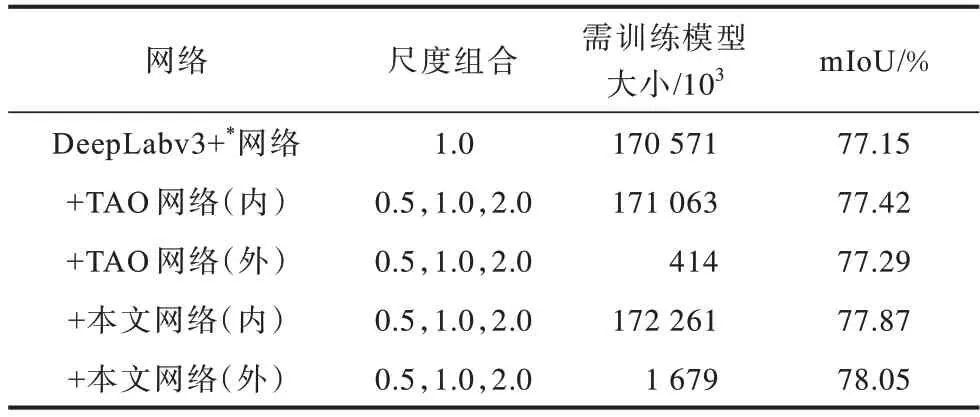
表5 投票網絡與共享網絡的實驗結果對比Table 5 Comparion of experimental results between voting network and sharing network
對比表5中TAO 網絡(外)與TAO 網絡(內)的數據可知,TAO 網絡(外)的mIoU 略低于TAO 網絡(內),但需訓練的模型大小卻大幅降低,縮小了413 倍。對比本文網絡(內)與本文網絡(外)的數據可知,本文網絡(外)的mIoU 高于本文網絡(內),其訓練模型縮小了102 倍。
相較而言,共享網絡需擬合的參數多,訓練復雜度高,較難收斂。而本文將不同尺度圖像的預測結果用于訓練外接投票網絡,與用于共享網絡相比,最佳模型的預測結果比網絡內部的特征圖更穩定,能夠學習更可靠的投票模型,且參數量較小,更易收斂。
為進一步顯式分析,將TAO等[15]的大尺度注意力權值圖與本節模型外方式擬合出的投票權值圖進行對比。如圖8 所示,為方便敘述,按每組虛線框出現的順序對虛線框進行標號,從左至右分別為左1、左2、左3、左4。其中左1 為TAO 等的大尺度權值圖,左4 為本文網絡的大尺度權值圖。對比發現,本文網絡對小、長條狀目標更敏感。如兩圖中最左邊虛線放大框所示,左4 的行人(小目標)比左1 更清晰,邊緣勾勒也更明顯。另外,如兩圖中最右邊虛線放大框所示,左1 幾乎丟失了路桿信息(長條狀目標),而左4 的路桿信息被成功捕獲。如兩圖中的中間虛線放大框所示,車輛邊緣被成功勾勒出了邊緣,相較左1 而言,左4 圖片更清晰。從整體上,左4 的層次感也優于左1 圖片,即尺度間的投票權值相差更大,越偏向于正確尺度的分割圖。

圖8 投票權值對比Fig.8 Comparison of voting weights
3.7 不同類別的mIoU 對比
為對比不同類別的mIoU,在Cityscapes 數據集中選取有代表性的類,包括交通標志、行人、騎手、摩托車等小目標的類;路桿等長條狀目標的類;小汽車、公共汽車等中目標的類;人行道、馬路等大目標的類。選用經過開源框架OpenMMLab 訓練的DeepLabv3+最佳網絡(DeepLabv3+*網絡)進行實驗,結果如表6 所示。由表6 可知,前3 行分別為不同尺度(0.5、1.0、2.0)圖像輸入DeepLabv3+*網絡的各類分割精度,表6 最后2 行分別為以模型外訓練方式的TAO*網絡與本文網絡在0.5、1.0、2.0 尺度組合下的分割精度。在表6 前3 行中,原圖的總精度相對最高,小尺度總精度相對較低。在具體類中,原尺度在大部分類中分割精度最高,小尺度中大目標的類別分割精度與原圖的差距小于其他類,大尺度中小、長條狀目標的分割精度優于原圖。但內部分割間斷拉低了整體精度,而本文通過結合小、原尺度的分割結果彌補了該缺陷。
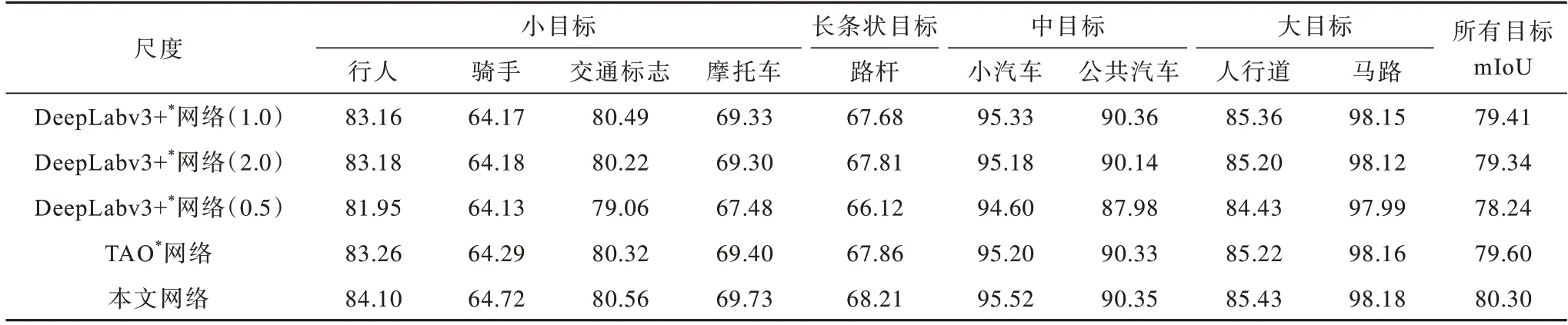
表6 不同網絡對不同類別圖像的mIoU 值對比Table 6 mIoU value comparison of different types of images by different networks %
表6 第4 行為將TAO*網絡以模型外方式訓練后測試的分割精度,與原尺度分割結果對比,網絡的mIoU 有一定提升,但提升幅度較小。本文在此基礎上進行改進后,在大部分類別中提升幅度較大。實驗結果也驗證了相比于其他類,網絡在小目標、長條狀目標處的分割精度較低。本文網絡可更好地改善小目標、長條狀目標的分割效果,但不可忽視的是,在表6 中,使用本文網絡分割屬于中目標的公共汽車類的分割精度相比于原尺度有小幅下降。而圖7已驗證了本文網絡可在中目標的邊緣處進行優化,理論上來說不應有所下降。通過結合分析屬于大目標的馬路類分割精度提升幅度過小,猜測此時投票網絡已經陷入局部最優,還未能充分把握中目標與大目標間正確的尺度關系,導致在目標內部出現像素投票偏差,在一定程度上限制了分割精度的提升幅度。
4 結束語
本文提出一種面向語義分割模型的外接多尺度投票網絡,在外接投票網絡結構中,分別對多類別投票模塊、混合池化模塊、類內與類間投票注意力模塊及不規則卷積4 個模塊進行改進,以更好地擬合投票權值。在消融實驗中驗證每個模塊的有效性,并通過可視化的投票權值圖,進一步證明CNN 網絡在不同尺度圖像中的分割偏好。實驗結果表明,相比FCN、PSPNet、DeepLabv3+等分割網絡,本文網絡的mIoU 分別提升了0.92、0.88、0.80 個百分點,尤其提高了對小目標、長條狀目標、目標邊緣處的分割精度。下一步將利用不同尺度的分割偏好及引入注意力機制,把握中目標與大目標間更正確的尺度關系,從而提高網絡對中目標以及大目標的分割精度。
