融合吸引排斥和雙向學習的改進粒子群算法
2022-10-17 11:00:26汪雅文伏云發
計算機工程與應用 2022年20期
關鍵詞:能力
汪雅文,錢 謙,馮 勇,伏云發
昆明理工大學 信息工程與自動化學院,云南省計算機技術應用重點實驗室,昆明 650500
粒子群算法(particle swarm optimization,PSO)是一種群智能優化算法,由Eberhart和Kennedy[1]在1995年首次提出。該算法由于操作簡單,不依賴于目標問題的梯度信息等優點,一經提出便在眾多領域得到了成功應用,例如神經網絡分類[2]、圖像分割[3]、機械的位置控制[4]、雷達站布局優化[5]、路徑規劃[6]等。雖然PSO算法有較好的優化性能,但在對一些復雜問題進行優化時仍存在“早熟”、種群多樣性缺失和收斂速度慢等現象,引起這些現象主要是因為PSO算法在進化過程中難以有效地平衡局部搜索能力與全局搜索能力[7]。許多學者針對PSO算法的不足提出了很多的改進方法,文獻[8]提出了一種將粒子的慣性權重w與粒子的位置信息相關聯的改進方法,可以更精確地調節算法中的w,使粒子的搜索行為得到了更好的平衡,改善了算法易“早熟”收斂的缺陷;文獻[9]提出了一種異步變化策略來更新算法中的學習因子,通過該算法的學習能力使得算法陷入局部極值的幾率大大減小;文獻[10]提出了一種能夠將種群動態地分層的自主學習策略,通過利用不同階層粒子的特性采取不同的學習模式,增加了粒子的多樣性,使該算法的收斂速度和精度得到了提高;文獻[11]定義了一種高斯變異策略,使種群多樣性得到了保持,降低早熟收斂的概率;文獻[12]將遺傳算法與PSO算法相融合,豐富了算法在進化過程中的群體多樣性,提升了算法的收斂速度。
雖然上述改進使算法的性能獲得了一定程度上的提升,但PSO算法仍有很大的改進空間,為了使算法同時擁有較好的收斂性能和收斂精度,進一步加強PSO算法的性能,在已有研究的基礎上,本文提出了一種新的改進的PSO算法。首先,將借鑒文獻[13]中天牛須搜索思想提出的一種雙向學習策略和一種改進的吸引-排斥策略融入PSO算法的全局尋優過程中,雙向學習策略能夠允許粒子在尋優過程中進行雙向學習,豐富種群的多樣性;吸引-排斥策略使粒子能夠在全局最優粒子的吸引力和全局最差粒子排斥力的合力方向上隨機地移動尋找最優解,以增強算法的局部尋優能力和收斂能力;然后提出了雙重自適應策略,使雙向學習策略速度更新公式中的慣性權重w和學習因子c根據算法的進化現狀動態地調整,這種雙重自適應的方式能夠有效地控制算法全局搜索行為與局部搜索行為之間的平衡;形成融合吸引排斥和雙向學習的改進粒子群算法(integrating attraction-repulsion and bidirectional learning IPSO,ARLIPSO),通過對本文所提出的改進算法進行仿真測試,結果表明本文算法可以更好地在尋優過程中跳出局部極值,減小出現“早熟”收斂的可能,使算法的性能得到提升。
1 基本PSO算法
PSO算法是基于鳥群或魚群尋找食物的社會行為方式而產生的一種算法[14]。群體中的每個個體都在自己已有的搜索方向和歷史上尋找更好的解,即向個體的歷史經歷中最好的解學習;此外,每個個體都從其他成員那里學習,通常是向群體當中表現最好的個體學習。粒子群優化算法可概括為,初始化種群個體的位置和速度、速度更新、位置更新。如果種群大小為N,則在D維搜索空間中PSO算法的更新公式如下:
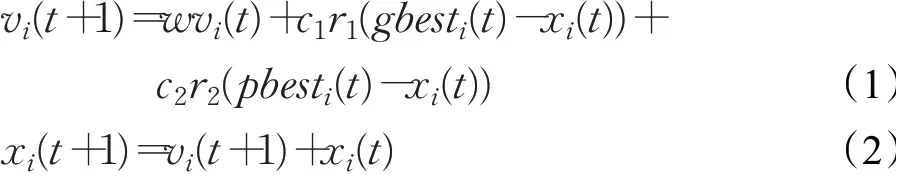
其中,第i個粒子的速度、位置分別為vi、xi,i=1,2,…,N,t為當前代數,w為慣性權重,c1、c2為學習因子;r1、r2為均勻隨機數,范圍在0和1之間,gbesti(t)為全局最優個體對應的位置,pbesti(t)為個體歷史最優對應的位置。
2 融合吸引排斥和雙向學習的改進粒子群算法(ARLIPSO)
為了提高算法的全局搜索和局部搜索能力提出了融合吸引排斥和雙向學習的方法,通過雙向學習方法來增加種群多樣性,提高算法的全局尋優性能;通過吸引-排斥方法來增加算法的局部搜索和收斂能力。此外,為了克服單一性的學習因子和慣性權重在優化復雜函數時無法很好地調節尋優進程的問題,提出了雙重自適應策略,使雙向學習策略速度更新公式中的慣性權重w和學習因子c根據算法的進化現狀動態地調整。
2.1 雙重自適應優化策略
在標準PSO算法中,粒子更新的影響因素主要包括全局最優位置、個體歷史最優位置和粒子原有的速度。其中,慣性權重w的大小決定了粒子當前速度對下一代速度更新的影響程度,學習因子c1、c2分別決定了個體歷史最優位置和全局歷史最優位置對速度更新影響的程度。由此可以看出慣性權重w和學習因子c是影響算法性能的主要參數。文獻[15]提出了一種使慣性權重w在線性和非線性之間進行動態調整的方法。文獻[16]采用了余弦函數使學習因子c隨著不同的搜索階段非線性地變換的方法。上述文獻所提出的方法均在不同程度上加強了算法的搜索能力,減少了算法的“早熟”收斂情況。在前人研究的基礎上,本文提出了一種雙重自適應優化策略,使算法在尋優過程中能夠自適應地同時調節慣性權重w和學習因子c,使算法前期的全局搜索能力和后期的局部搜索能力得到提升。
2.1.1 改進的慣性權重
慣性權重w對PSO算法的全局搜索和局部搜索能力有著很大程度的影響[17],對w加以適當的調整,能夠使算法的尋優能力以及收斂速度同時得到提升。若使算法的全局搜索能力較強,則需要較大數值的慣性權重w;若使算法的局部搜索能力較好,則需要較小數值的慣性權重w,若采用固定數值的w,算法無法根據進化的情況來調整搜索能力,會增加陷入“早熟”收斂的可能性。文獻[8]指出PSO算法的尋優過程是復雜的,單一變化w的方法很大程度上限制了算法在復雜尋優進程中的調節能力,容易出現“早熟”收斂,所以本文提出了一種新的改進慣性權重的方法,使慣性權重非線性取值,根據粒子的迭代次數進行適當的調整,能夠使慣性權重在復雜系統中呈現出動態變化關系,進而使算法在全局搜索和局部搜索之間達到一定的平衡。ARLIPSO算法的慣性權重w的更新方式如下:
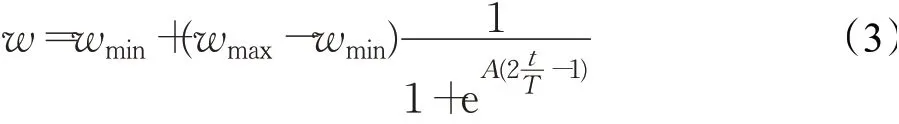
其中,wmin為慣性權重最小值,取值為0.1;wmax為慣性權重最大值,取值為0.8;A是控制曲線曲率的參數,經過測試A取值為6;t為當前迭代次數;T為最大迭代次數。
慣性權重w的非線性變化曲線如圖1所示。在算法初期,w能夠維持比較平穩的狀態,使粒子在此期間保持比較大的更新速度,確保算法具有較好的全局搜索能力,在算法的早期階段提高了種群多樣性,避免出現“早熟”的情況;而在算法后期階段,為了提高算法的收斂能力,使算法的慣性權重w值快速降低,使粒子能夠以較小的步長更新,實現更加精細的搜索。
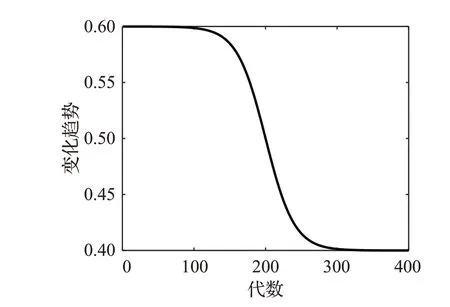
圖1 慣性權重w自適應曲線Fig.1 Adaptive curve of inertia weight w
2.1.2 改進的學習因子
文獻[18]證明了單粒方法在探索方面較優且降低了計算復雜度,因此本文同樣采用了單粒更新方式。即從較優的粒子中隨機選取一個粒子xk作為學習對象,并在此基礎上提出了更進一步的自適應單粒學習因子。學習因子c更新公式如下:
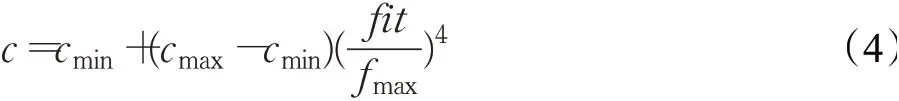
其中,cmin為學習因子最小值,取值為0.5;cmax為學習因子最大值,取值為2;fit為當前粒子個體的適應度值,fmax為當代粒子中最大的適應度值。
學習因子c數值的變化趨勢如圖2所示,本策略中,學習因子的大小決定了粒子向xk學習的程度。在算法初期,學習因子較小,且呈緩慢上升的趨勢,使粒子較少的向xk學習,提升算法的全局尋優能力;在算法的后期,學習因子以較大幅度上升,使粒子更多地向xk學習,起到提高算法局部搜索能力的作用。
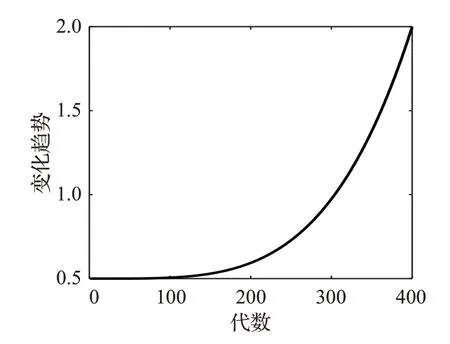
圖2 學習因子c自適應曲線Fig.2 Adaptive curve of learning factor c
2.2 雙向學習策略
本文借鑒了天牛須搜索算法的主要思想,提出了一種雙向學習策略,其中適應度評估、行為學習和種群排序是本策略的重要組成部分。不同于標準PSO算法的是,本策略的搜索過程是基于社會學習原理,粒子隨機選擇一個較優者學習,提高了全局搜索能力。但由于種群整體往較優者逼近,導致多樣性不足,因此通過雙向學習的方法,豐富種群多樣性,提高算法全局搜索能力。即粒子在解空間搜索時,每一次進化都會進行正反方向的學習行為。在每一次迭代時,先將個體按照適應度值由優到差進行排序,再從中隨機選擇一個比xi好的個體作為學習對象即xk(1≤k≤i),排序如圖3所示。然后對正向學習(xk-xi)和反向學習(xi-xk)對應的適應度值進行評估,并從兩種學習方式中選擇適應度值更優的一種作為更新方式,改進后的粒子速度與位置更新公式為:
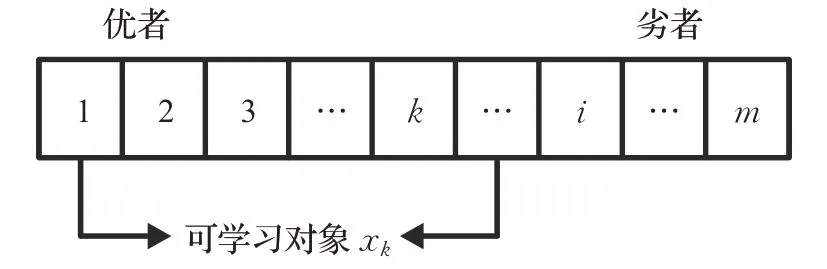
圖3 粒子適應度排序Fig.3 Fitness ordering of particles
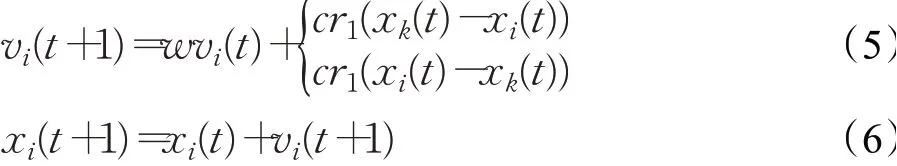
其中,第i個粒子的速度、位置分別為vi、xi,i=1,2,…,N,t為當前代數,r1為均勻隨機數,w為慣性權重,按照公式(3)更新;c為學習因子,按照公式(4)更新。粒子每次更新時會根據公式(5)同時進行正向學習和反向學習兩種行為,粒子通過學習獲得了新的適應度,并向產生適應度值較優的方向移動。這種雙向學習的粒子更新方式不但擴大了算法的搜索范圍,使算法的全局尋優能力得到了提高,一定程度上也減小了算法陷入局部最優的可能性。
2.2.1 雙向學習策略的偽代碼
雙向學習策略的偽代碼如下:

2.2.2 雙向學習策略的測試
本文使用函數F1和F2來測試雙向學習策略的性能。其中,F1為單峰函數,定義域為-10<xi<10,F1全局最小值為0;F2為多峰函數,定義域為-100<xi<100;F2全局最小值為0,函數F1、F2表達式如下所示:
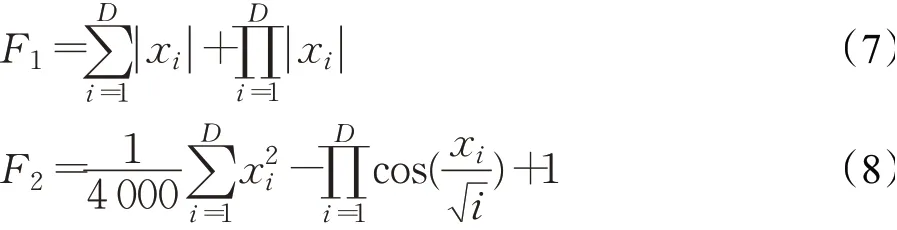
本次測試維度D設置為20,種群大小設置為100,進化代數為400,c1=c2=1.5、w=0.9,將PSO算法與本文方法各獨立進行20次仿真實驗;種群進化過程中,每次迭代時粒子選擇正向學習和與之相反方向的反向學習次數的曲線圖如圖4所示,優化結果對比如表1所示。

圖4 正反向學習次數Fig.4 Number of forward and reverse learning
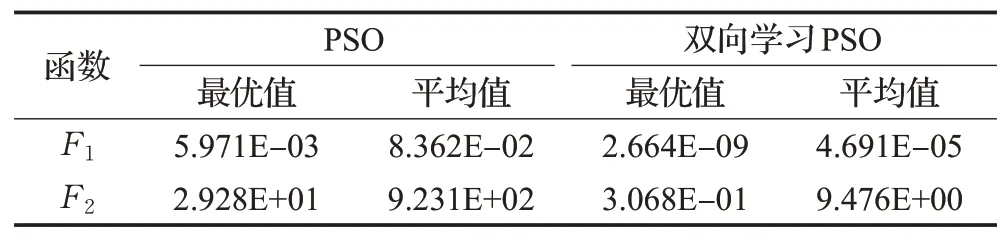
表1 函數F1、F2的優化結果對比Table 1 Comparison of optimization results of functions F1 and F2
圖4結果表明,在測試函數F1中種群接近一半的個體采用了反向學習的方法,豐富了種群的多樣性,從而提高了算法的全局搜索能力;在函數F2中每次進化時個體采用正向學習次數的曲線呈波峰形狀,函數F2有很多的局部極小值點,當種群集中在局部極值附近時,反向學習的方法擴大了種群搜索范圍,有助于算法跳出局部最優。通過對比表1的優化結果證明了本學習方式在單峰測試函數和多峰測試函數中均優于傳統PSO算法的單向學習,說明了本策略的有效性。
2.3 吸引-排斥策略
擬態物理學方法提出具有速度和位置的個體,通過個體之間虛擬力(引力和斥力)的作用產生速度,進而改變個體位置[19]。通過PSO算法速度更新公式可知,粒子在更新過程中受到了個體最優粒子和全局最優粒子引力的影響,這種作用力規則在一定程度上具有局限性,對此文獻[20]通過算法的不同搜索階段,分別構造了引斥力規則和雙引力規則,提高了種群的多樣性,使算法在很大程度上減小了陷入局部極值的可能性。
在前人研究的啟發下,本文從擬態物理學角度構造出一種新的粒子間作用方式,通過對比粒子適應度值的大小提出了一種新的吸引-排斥策略。該策略將標準PSO算法中粒子的更新受全局最優個體以及自身歷史最優個體的雙引力作用,擴展為粒子在受全局最優粒子gbesti吸引的同時還受全局最差粒子gworsti的排斥,使得粒子在引力和斥力所產生的合力作用下朝著更優的方向進化。其中,(gbesti-xi)為全局最優粒子對xi的吸引,-(gworsti-xi)為全局最差粒子對xi的排斥,本策略中粒子的更新公式為:
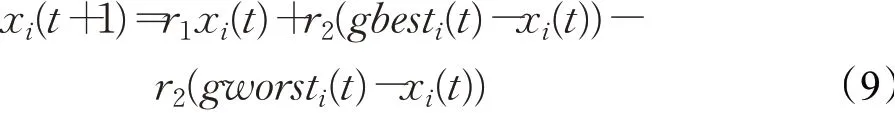
其中,r1為[0,1]范圍內的均勻隨機數,r2=1/2(1-r1),第i個粒子的位置為xi,i=1,2,…,N,t為當前代數,公式(9)中引力、斥力占比相同,引斥力使粒子向適應度值較好的個體聚攏,同時也遠離適應度值較差的個體,使得粒子更快逼近最優值,提高了算法的局部尋優能力。
2.4 自適應抉擇因子F
采用自適應的抉擇因子F,使雙向學習和吸引排斥兩種方法在不同進化時期有所側重,有利于保持種群多樣性和收斂能力之間的平衡。R是0到1之間的隨機數,其中,R<F時,采用雙向學習策略;R≥F時,采用吸引排斥策略。由圖5F變化曲線可知,F在進化初期以大于0.5的數值緩慢下降,使得算法更加側重于雙向學習策略;進化后期F以小于0.5的數值快速減小,使得算法更側重于吸引-排斥策略,在整個尋優過程中兩種方法處于一個動態平衡的狀態。在提高種群的豐富度的同時加快了算法的收斂速度。自適應抉擇因子F的更新公式如下:
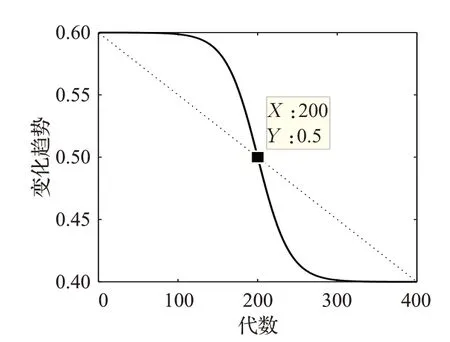
圖5 自適應抉擇因子曲線Fig.5 Curve of adaptive decision factor
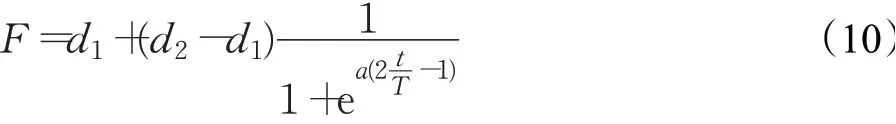
其中,d2=0.6,d1=0.4,a=10,t為當前迭代次數,T為最大迭代次數。融合雙向學習與吸引-排斥的策略不僅考慮了種群的多樣性,而且也提高了算法的收斂速度,有效地平衡了算法的全局和局部搜索的能力。
3 算法步驟
ARLIPSO算法的流程如下:
輸入:算法迭代次數T、種群規模N。輸出:最優位置x。
步驟1初始化粒子群個體,包括位置x、速度v,粒子數量N和算法參數。
步驟2計算群體中各個粒子適應度函數值fit。
步驟3將fit由優到差排序,每個個體從群體中隨機選取一個較優個體作為學習對象xk,更新全局最優個體gbesti和全局最差個體gworsti。
步驟4根據公式(3)、(4)、(10)自適應地更新w、c和抉擇因子F。
步驟5若R<F采用雙向學習策略,即公式(5)、(6)更新粒子的x、v;反之采用吸引-排斥策略,即公式(9)更新粒子。
步驟6更新所有粒子適應度函數值fit。
步驟7t=t+1,若t<T轉步驟3,否則執行步驟8。
步驟8輸出x,結束。
4 仿真實驗及結果分析
4.1 測試函數及對比算法
為了驗證本文提出的ARLIPSO算法的性能,對表2給出的9個測試函數進行了仿真測試,其中,f1~f5為單峰值測試函數,f6~f9為多峰值測試函數。此外,將本文提出的ARLIPSO算法的測試結果與近年來新提出的自適應慣性權重混沌PSO算法(CPSO-NAIW)[8]和基于學習與競爭的改進PSO算法(LC-PSO)[21]進行比較,這些對比算法的優化性能在相應的文獻中已經得到證明,它們在各方面都比標準PSO算法優秀。
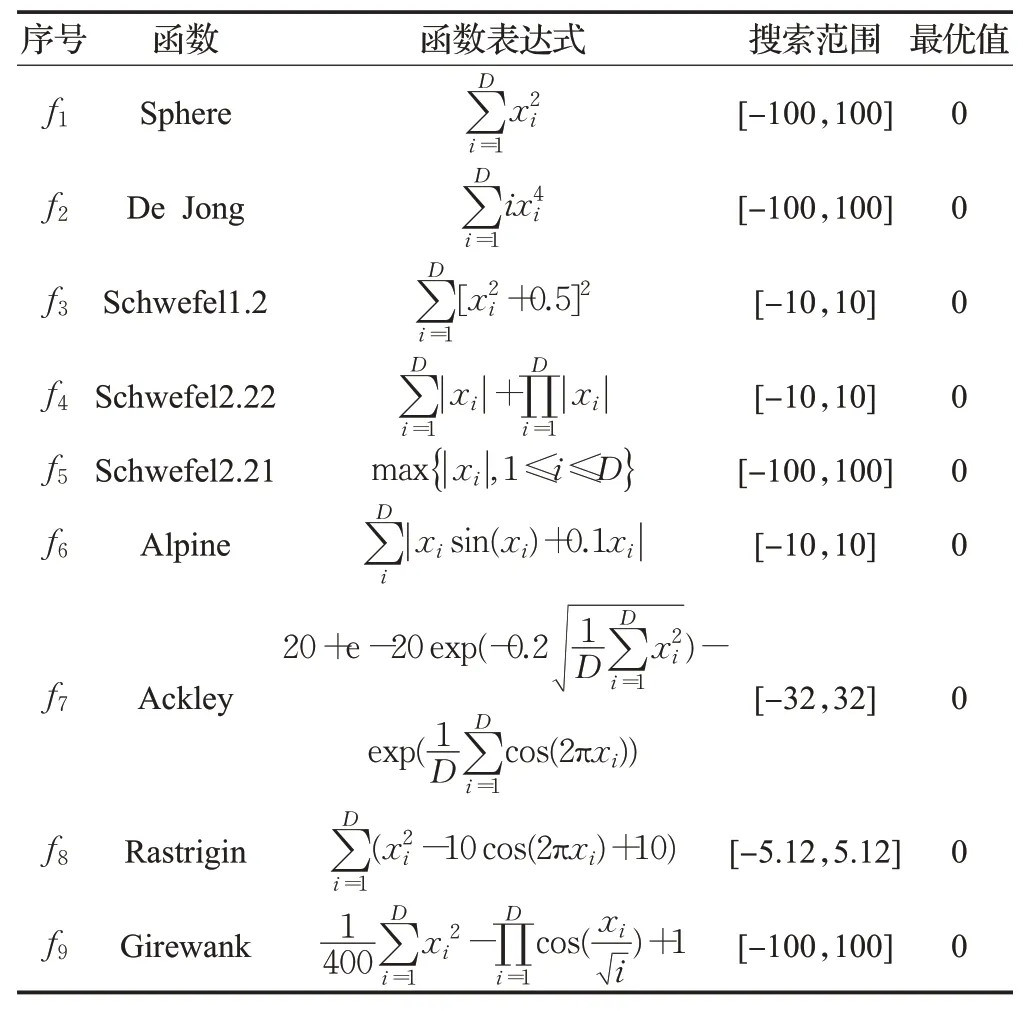
表2 測試函數Table 2 Test functions
4.2 測試方案與實驗分析
在對比實驗分析中,具體實驗參數設置為:算法的種群數量N設置為100,最大進化代數為400代。ABLPSO算法中,wmin=0.1、wmax=0.8,cmin=1.494 45、cmax=2,CPSO-NAIW算法與LC-PSO算法的其他參數設置與原文獻保持一致。為了避免算法的隨機性保證實驗的公平性,針對每種算法,在上述9種函數的測試中,3種算法分別獨立進行30次仿真實驗,本文采用3個參量作為評估算法性能的指標:(1)最優值,反應算法求解質量好壞的標準。(2)均值(Mean),表示算法最優解的平均值,均值越小說明算法的搜索性能越好。(3)標準差(STD),用來反映算法穩定性的指標,STD越小表明算法穩定性越強。
4.2.1 單峰值函數優化下的性能分析
表3給出了3種算法在5個單峰測試函數上不同維度的優化結果。對比表中數據可以得出,ARLIPSO算法的最優值、Mean和STD多數都為最優,說明該算法的收斂能力和尋優能力相比于另外兩種算法更為突出。通過對比3種算法的Mean可知,ARLIPSO算法雖然沒有達到理想最優值,但優化能力仍要優于另外兩種算法,此外相對于CPSO-NAIW而言,LC-PSO算法較好。從實驗結果上看,雖然函數從10維到60維,隨著維度的提高尋優的復雜度也增加了,但ARLIPSO算法的優化能力并沒有降低。對比表中的STD可知,算法ARLIPSO的標準差在5個測試函數中均為最小,說明該算法每次的優化結果波動較小,穩定性較另外兩種算法更為出色;而算法CPSO-NAIW的STD值多部分在3種算法中最大,特別是在函數f2中雖最優值取到了理想值0,但其Mean值在3種算法中最小,表明該算法穩定性最差,適用性最差。
圖6給出了本次實驗中3種對比算法在9種測試函數中測試時隨機選取的尋優收斂曲線。由圖6中(a)~(e)可以看出,與CPSO-NAIW算法和LC-PSO算法相比,ARLIPSO算法在單峰值函數優化的收斂速度和收斂精度方面具有明顯的優勢,其中,CPSO-NAIW算法整體上的尋優能力表現最差。證明了ARLIPSO算法擁有較好的局部尋優能力。
4.2.2 多峰值函數優化下的性能分析
表4給出了3種算法在4個多峰測試函數上不同維度的優化結果。其中f6~f9可以作為測試算法能否有效跳出局部最優值的評價函數,通過對比分析可知,算法ARLIPSO在優化多峰函數時,無論低維還是高維,均值Mean和標準差STD兩個性能指標都大幅度優于其他兩種算法,說明其全局尋優能力較好。實驗結果顯示,ARLIPSO算法在函數f8、f9上均值都達到了理想最優值0,CPSO-NAIW算法尋優效果整體最差,歸因于該算法在搜索后期跳出局部極值的能力有所缺陷,總之,相比于LC-PSO和CPSO-NAIW兩種算法,ARLIPSO算法優化能力更強,收斂速度更快。

表4 3種算法在函數f6~f9中的優化結果對比Table 4 Comparison of optimization results of three algorithms in function f6~f9
從圖6中(f)~(i)可以看出,ARLIPSO算法的尋優能力在優化多峰函數時也表現出眾,由圖6(f)的優化曲線可知,CPSO-NAIW算法相比其他兩種算法其收斂速度非常快,即在迭代初期曲線就呈水平狀態,但由于局部最優值的存在,導致收斂精度極低,反之ARLIPSO算法雖然收斂速度慢,但收斂精度最高,表明ARLIPSO算法能夠在雙向學習策略的作用下保持種群的多樣性,即使是復雜的多峰值函數也能取得良好的優化結果。
4.3 算法計算復雜度分析
數學模型的參數擬合決定了算法的時間復雜度[22]。設種群最大迭代數目為Tmax,種群大小為N,其中,Tmax、N的數值越大,其計算的時間復雜度O(TmaxN)也就越大。ARLIPSO和對比算法(CPSO-NAIW、LC-PSO)采用了相同的種群規模,ARLIPSO采用了兩種不同的進化策略,即雙向學習策略和吸引-排斥策略,通過自適應抉擇因子F調整種群的進化策略,實現不同的進化功能。因為這兩種策略是作為算法尋優附加模塊參與計算,所以該操作沒有使算法本身進行更深層次的循環,使得ARLIPSO基本運算的頻度與標準PSO相同,時間復雜度仍為O(TmaxN),沒有多余地增加算法的時間復雜度。而本文選取的另外兩種對比算法(CPSONAIW、LC-PSO)分別采用了混沌優化擺脫局部極值法和社會學習法。CPSO-NAIW使用的擺脫極值法,使算法在原有的基礎上額外地增加擺脫極值的循環操作,增加了算法的時間復雜度。LC-PSO基本運算的頻度與標準PSO相同,沒有多余地增加算法的時間復雜度。與對比算法相比,ARLIPSO在沒有增加時間復雜度的情況下,尋優精度更高,所以此算法更優。
5 結束語
為了解決PSO算法存在收斂速度較慢且難以跳出局部最優值的問題,本文提出了ARLIPSO算法,該算法提出一種雙向學習的策略與吸引-排斥策略相結合的方法,在提高了全局尋優能力的同時提高了局部搜索能力。此外還采用了雙重自適應優化策略,對雙向學習策略中的慣性權重和學習因子進行自適應調整,使算法的全局尋優能力和局部尋優能力達到更好的平衡。最后,通過對9個測試函數進行仿真實驗,表明本文提出的ARLIPSO算法在單峰值和多峰值函數尋優中都具有較好的收斂速度和尋優精度。
猜你喜歡
發明與創新(2022年30期)2022-10-03 08:40:56
中學生數理化·七年級數學人教版(2022年6期)2022-06-05 06:50:58
意林(兒童繪本)(2020年2期)2021-01-07 02:12:04
動漫星空(興趣百科)(2020年12期)2020-12-12 05:31:40
作文成功之路·小學版(2020年5期)2020-06-11 12:48:46
意林(兒童繪本)(2019年9期)2019-10-15 08:51:46
中國生殖健康(2019年10期)2019-01-07 01:21:14
人大建設(2018年6期)2018-08-16 07:23:10
新高考(英語進階)(2018年1期)2018-04-18 14:00:11
文理導航·科普童話(2017年5期)2018-02-10 19:42:14
