適于少樣本缺陷檢測的兩階段缺陷增強網絡
2022-10-17 11:01:14李恭楊彭鐵根
計算機工程與應用 2022年20期
陳 朝,劉 志,李恭楊,彭鐵根
1.上海大學 通信與信息工程學院,上海 200444
2.寶山鋼鐵股份有限公司 中央研究院,上海 201999
在工業制造領域,如何在生產過程中準確檢測出產品的表面缺陷對于產品的質量控制有著重大意義。近幾年,深度學習技術在智能制造領域嶄露頭角,它利用大量數據可以訓練出用于缺陷檢測的模型,大大提高了缺陷檢測的準確率。但在實際的生產過程中,缺陷產品出現的比率非常低,上百萬個樣本中僅能找出幾千個缺陷樣本,對于一些較為罕見的缺陷,甚至只能收集到幾個到幾十個缺陷樣本,這會造成各類樣本數量不均衡且少的問題。如果只有少量缺陷樣本參與訓練,模型會容易過擬合,這會造成該類缺陷的檢測性能急劇下降的情況。少樣本學習便是針對該問題而提出的解決方案,它基于先驗知識并利用從少量樣本中學習的新知識來對模型微調[1],從而實現對新樣本的缺陷檢測。綜上所述,提出一種針對工業生產場景的基于少樣本學習的缺陷檢測模型是非常有必要的。
少樣本目標檢測是計算機視覺領域的一個新興分支,在近幾年受到了廣泛關注。2019年,Kang等人[2]在單階段檢測模型的基礎上提出了一個基于少樣本學習的目標檢測模型,將少量的樣本通過一個重新加權模塊來得到多個類別相關的特征向量,并與特征圖相乘,之后進行分類和回歸計算。Yan等人[3]基于雙階段檢測模型,用骨干網絡生成的特征向量與感興趣區域特征相乘并輸入到檢測器中,取得了不錯的檢測性能。此外,Yang等人[4]提出了FSDet,該模型利用兩個編碼器得到每個類別的特征向量和感興趣區域(region of interest,ROI),然后對兩組特征向量進行聚合操作,并將這些向量用作檢測器的輸入。通過這種方法,模型可以充分利用訓練樣本和測試樣本的特征和相關性,進而提升檢測性能。然而,上述少樣本目標檢測模型屬于通用的少樣本目標檢測模型,在缺陷檢測任務中的表現不理想,不適合直接應用到工業場景中。
目前,工廠中普遍使用傳統的圖像處理方法來進行產品的表面缺陷檢測。Borselli等人[5]提出利用缺陷邊緣的亮度變化較大的特點來檢測缺陷。李軍華等人[6]對提取到的兩種區域特征進行加權融合,在生成綜合特征向量后送入分類器,提升了瓷磚的缺陷檢測效果。Tolba等人[7]提出將Gabor濾波器[8]應用于缺陷檢測,并取得了不錯的效果。黃夢濤等人[9]提出了基于改進Canny算子的模型,該模型能夠減少噪聲的干擾并突出待檢測的缺陷區域,進而提升了檢測性能。然而,這些方法都存在較大的局限性,只能在某些缺陷類別上取得良好的檢測效果。隨著深度學習的發展,多項研究[10-12]證明了基于卷積神經網絡的模型在缺陷檢測任務上的優越性。Yi等人[10]提出了一種端到端的模型來提高缺陷檢測的性能。Ren等人[11]優化了一個兩階段的目標檢測模型,使其更適合用于缺陷檢測。徐鏹等人[12]改進了YOLOv3[13]網絡,不僅適當減少了網絡的參數量,還提升了模型在鋼板表面缺陷檢測的準確率。上述方法通過對現有模型的修改,使其更適合用于缺陷檢測。但是,這些模型在訓練階段依然需要大量的缺陷樣本,當只提供少量的缺陷樣本時,它們的檢測性能會急劇下降。
在實際工業場景的缺陷檢測任務中,很多時候難以提供大量的缺陷樣本。針對這個問題,李鈞正等人[14]提出用數據增強方法來增廣數據集,在鋼板表面缺陷檢測任務中取得了良好的結果。Wang等人[15]提出在少樣本訓練之前進行缺陷圖像的預處理,利用噪聲正則化等策略,提升了模型訓練的魯棒性并獲得了良好的檢測性能。張藝橋[16]提出了YO-FR算法,在定位階段采用YOLOv3[13]的結構,在分類階段采用Faster R-CNN[17]的結構。上述的幾種方法嘗試利用數據增強、數據預處理和模型集成的策略來解決少樣本學習的問題,但并未針對工業場景中少樣本缺陷檢測任務來設計一種全新結構的少樣本缺陷檢測模型。與上述方法不同的是,本文提出了一個全新的基于元學習的少樣本缺陷檢測模型,即兩階段缺陷增強網絡(two-phase defect enhancement network,TDENet),且首次利用了無缺陷樣本來提高少樣本缺陷檢測的性能。同時還構建了一個用于少樣本缺陷檢測的新數據集,即工業表面缺陷(industrial surface defects,ISD)數據集。在缺陷檢測過程中,數量遠超過缺陷樣本的無缺陷樣本通常會被忽略,導致其無法被有效利用。因此,ISD數據集額外添加了200個無缺陷樣本,便于本文探究對無缺陷樣本的利用。此外,本文提出的少樣本缺陷檢測模型將整個訓練過程分為兩個階段:第一階段需要大量的基類缺陷樣本來獲得預訓練模型,第二階段只需要少量的基類和新類的缺陷樣本即可在預訓練模型的基礎上學習新特征。
本文的主要貢獻包括以下三個方面:
(1)提出了適用于工業場景中缺陷檢測任務的基于元學習的少樣本缺陷檢測模型,首次將無缺陷樣本的應用引入到少樣本缺陷檢測領域,并為少樣本缺陷檢測任務構建了一個新的ISD數據集。該數據集中同時包含缺陷樣本和無缺陷樣本,旨在促進少樣本缺陷檢測領域的發展,并提高對工廠實際生產中大量存在卻被忽視的無缺陷樣本的重視。
(2)針對少樣本缺陷檢測提出了一個兩階段缺陷增強網絡TDENet,它將整個訓練過程分為兩個階段。其中,第一個階段基于大量樣本訓練得到一個預訓練模型,第二個階段基于少量樣本對預訓練模型進行模型微調。此外,在第二個階段添加了一個新的網絡分支,使得兩個階段的網絡結構不同。在這個新的網絡分支上應用了新提出的缺陷突顯模塊(defect prominence module,DPM)。DPM利用特征向量相減操作以借助無缺陷樣本的特征來加強缺陷區域的特征。之后,TDENet利用特征聚合操作來綜合不同網絡分支輸出的特征,進一步提升了缺陷檢測性能。
(3)在ISD數據集、皮革和木材數據上進行了全面的實驗,與最先進的少樣本目標檢測模型相比,TDENet在不同的工業場景下都取得了最優的缺陷檢測性能。
本文已經將相關實驗設置、數據集以及源代碼公布在https://github.com/chenzhao339/TDENet。
1 構建數據集
由于目前沒有適用于少樣本缺陷檢測課題的數據集,所以本文基于東北大學(North East University,NEU)表面缺陷數據集[18]和磁瓦(magnetic tile,MT)數據集[19],構建了一個適用于少樣本缺陷檢測的新數據集,即ISD數據集。NEU鋼鐵表面缺陷數據集包含1 800個缺陷樣本,其中每個缺陷類都有300個樣本。MT數據集共有387個缺陷樣本和952個無缺陷樣本,其中包含了5個缺陷類,各類樣本數量如表1所示。雖然這兩個數據集屬于兩種不同的材料,但它們的背景和缺陷區域具有一定的相似性,使得它們可用于少樣本缺陷檢測的研究。

表1 MT數據集中各類樣本數量Table 1 Number of samples of every class in MT dataset
遵循現有的少樣本學習策略[3],ISD數據集包含基類Cbase和新類Cnovel兩部分。其中,基類為樣本較多且多樣的缺陷類型,而新類為樣本較少的缺陷類型。本文提出的ISD數據集選取NEU數據集中的5個缺陷類作為基類,并選取MT數據集中的所有類作為新類,還從MT數據集中隨機選取了200個無缺陷樣本,以緩解少樣本學習過程中新類缺陷數據缺乏的問題。如表2所示,ISD數據集共有2 087個樣本,其中,1 500個樣本屬于基類,387個樣本屬于新類,200個樣本屬于無缺陷樣本。在少樣本學習過程中,將該數據集隨機地劃分為訓練集和測試集,且這兩個部分相互獨立。訓練集根據少樣本學習策略[3]分為兩部分,第一部分用于第一階段的訓練,包括基類中每個缺陷類的200個缺陷樣本(共有5個類);第二部分用于第二階段的訓練,包括基類和新類中每個類10個缺陷樣本(共有10個類)和10個無缺陷樣本。測試集則是包括基類中每類90個樣本以及105個氣孔缺陷樣本、75個斷裂缺陷樣本、47個裂紋缺陷樣本、22個磨損缺陷樣本和88個凹凸不平缺陷樣本。

表2 ISD數據集的組成Table 2 Composition of ISD dataset
MT數據集原本針對的任務為顯著性檢測,因此其中的缺陷二值圖需要轉換為缺陷檢測的標注方式,即xml文件,轉換步驟如下所述:
(1)獲取每個缺陷位置。根據二值圖中缺陷的連通關系,得到每個連通域的坐標信息,并將每個連通域視為獨立的缺陷[20]。
(2)生成缺陷檢測標注文件。基于單個缺陷的坐標信息及其對應的缺陷類,可以生成缺陷檢測的標注文件,即標明缺陷類的邊界框。這些標注文件與原始缺陷圖像是一一對應的關系。
圖1展示了ISD數據集中缺陷類的部分樣本。從圖中可以看出,基類和新類之間的差異較小,這有利于基類和新類之間的知識遷移。

圖1 ISD數據集中所有缺陷類的樣本Fig.1 Samples of all defect classes in ISD dataset
2 提出少樣本缺陷檢測模型
2.1 兩階段缺陷增強網絡
在少樣本學習過程中,由于新類缺陷的樣本量不足,導致基于傳統的訓練策略得到的模型對于新類缺陷的檢測性能不如基類缺陷的檢測性能。這說明傳統的訓練策略在樣本很少的情況下無法很好地學習新類缺陷的特征。針對這個問題,本文提出了一個兩階段缺陷增強網絡TDENet,該網絡在兩個訓練階段采用不同的網絡結構。
本文提出的TDENet使用Faster R-CNN[17]作為基本的檢測框架,并將整個訓練過程分為兩個階段。第一個訓練階段與Meta R-CNN[3]類似,即基于大量的基類樣本訓練得到一個可檢測基類缺陷的預訓練模型。如圖2所示,第一個訓練階段的網絡由兩個分支組成。其中,第一個網絡分支基于Faster R-CNN的主干網絡輸出特征圖,之后利用區域生成網絡(region proposal network,RPN)來獲取各個類別的感興趣區域相關的特征圖(即ROI特征向量)。RPN的網絡結構如圖3所示,它以主干網絡輸出的特征圖為輸入,并經過一個卷積核為3×3的卷積層。然后分為兩個分支,第一個分支用于錨框的二分類,判斷錨框中是否含有缺陷,但不關注缺陷的類別;第二個分支用于錨框的回歸計算(即計算相對于真實邊框的偏移量)。最后綜合兩個分支獲取的錨框信息來進行候選框的生成并輸出。如圖2所示,TDENet的第二個網絡分支基于預測頭重構網絡(predictor-head remodeling network,PRN),并利用缺陷樣本來生成缺陷類注意力特征向量缺陷類注意力特征向量編碼了訓練樣本的第n類缺陷信息,可用于生成缺陷類相關的特征圖。這個過程可以用公式(1)表述:

圖2 TDENet第一個訓練階段的網絡結構Fig.2 Network structure of first training phase of TDENet
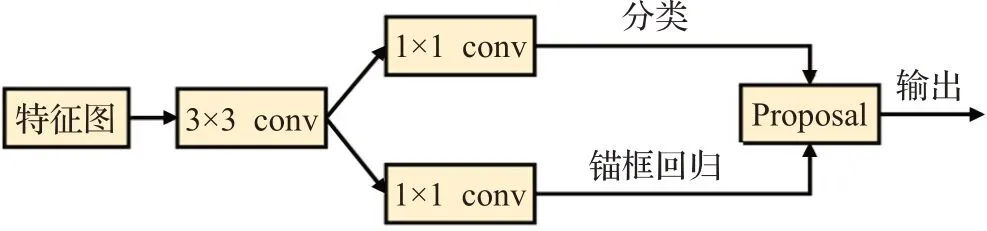
圖3 RPN網絡結構Fig.3 Network structure of RPN
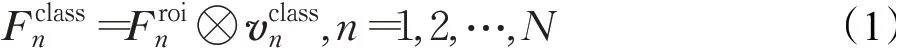
其中,?代表特征向量與特征圖的逐元素相乘,N代表訓練集的缺陷類數量的維度均為128×2 048(其中128表示感興趣區域ROI的數量),且的維度為1×2 048。之后,通過分類和回歸計算,TDENet可以根據獲得缺陷的類別和位置信息。
與第一個訓練階段不同,第二個階段需要少量的基類和新類樣本。在不考慮背景差異的情況下,本文發現不同材料的缺陷特征具有一定的相似性,例如鋼鐵的劃痕缺陷和磁瓦的裂紋缺陷。因此,如圖4所示,TDENet在第二個訓練階段引入了第三個網絡分支,目的是為了同時利用輸入的缺陷樣本和無缺陷樣本來增強網絡對新類的缺陷區域特征的提取能力。具體來說,TDENet在第三個分支上添加了一個缺陷突顯模塊(DPM),它可以利用從缺陷樣本和無缺陷樣本中提取到的特征,將這兩個特征相減來生成缺陷區域特征突顯向量然后利用每個缺陷類的來生成缺陷區域特征突顯的特征圖。這個過程可以用公式(2)來表述:

圖4 TDENet第二個訓練階段的網絡結構Fig.4 Network structure of second training phase of TDENet


其中,FC(·)代表全連接層,⊙代表特征圖在通道維度進行串聯的操作,且的維度為128×4 096,Fn的維度為128×2 048。特征圖在通道維度進行串聯的特征聚合操作可以在保持原有效果的同時提高模型對于新類缺陷的感知。之后使用全連接層來壓縮特征的維度。最后通過邊框的分類和回歸計算,可以得到基類缺陷和新類缺陷的檢測結果。
此外,TDENet中兩個訓練階段的損失函數與Meta R-CNN[3]的保持一致,可以用公式(4)來表述:

其中,Lreg表示邊框回歸的平滑L1損失函數,Lcls表示分類的交叉熵損失函數,Lmeta表示旨在提高特征向量表征能力的交叉熵損失函數,可以用公式(5)表述:


2.2 缺陷突顯模塊
由于常見的缺陷檢測模型并不能很好地基于少量樣本來提取新類缺陷的特征,所以本文提出了缺陷突顯模塊(defect prominence module,DPM)來更好地利用無缺陷樣本,并用于提升第二個訓練階段的新類缺陷表征能力。
如圖5所示,DPM包括兩部分。第一部分將少量的新類樣本輸入PRN以生成缺陷類注意力特征向量,這些向量編碼了新類缺陷的特征信息。第一部分中的卷積層使用M×M的卷積核,其中M設置為7。因為背景信息一般是全局信息,所以將第二部分的卷積核擴展為S×S,其中S=2M-1,即S為13。該做法可以更好地提取無缺陷樣本的全局特征,并生成無缺陷的特征向量vdf。之后通過和vdf的相減操作可得到特征突顯的特征向量,這可以減少背景的干擾并突顯缺陷區域的特征信息。該過程可由公式(6)表述:

圖5 DPM的網絡結構Fig.5 Network structure of DPM
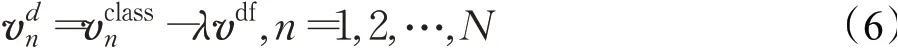
其中,λ是vdf的比例系數,其作用是減少無缺陷樣本中的噪聲對計算結果的干擾。λ的值不能設置太大,該參數值的選取將在3.4節中進一步說明。
對于缺陷檢測任務,激活函數引入了非線性因素,使模型得到高維的深度特征。本文使用sigmoid激活函數是因為sigmoid激活函數的輸出范圍(0,1)比tanh激活函數的輸出范圍(-1,1)更集中。此外,sigmoid激活函數輸出的特征向量的每個值都在區間(0,1)上且總和不受約束,而softmax激活函數輸出的特征向量的每個值雖然都在區間(0,1)上,但其所有值的總和限制為1。相比之下,softmax激活函數在計算過程中更容易出現信息丟失的問題,所以選用sigmoid激活函數可以使輸出的特征在傳遞的過程中不容易發散,同時可以減少特征提取過程中信息丟失的風險。DPM+輸出的特征向量在之后會用于檢測框的分類和回歸,而sigmoid激活函數可以兼顧TDENet的分類和回歸,保證候選框的分類和回歸效果。因此,DPM+可確保在進行特征向量的減法操作時更好地保留特征向量中的重要特征,進而提升新模型在新類缺陷上的檢測性能。3.5節中的消融實驗也證明了DPM+確實可以減少缺陷檢測的錯誤并優化性能。
3 實驗設計與結果分析
3.1 實驗數據集
本文利用兩個不同的缺陷數據集來測試模型的缺陷檢測性能。第一個數據集是ISD數據集,其中有1 500個鋼鐵表面缺陷樣本,387個磁瓦表面缺陷樣本以及200個無缺陷樣本。第二個數據集是MVTec公司提出的缺陷數據集[21],該數據集包含皮革、木材、牙刷、膠囊和螺絲等樣本,其中皮革和木材的樣本與ISD數據集中的樣本具有一定的相似性且都屬于平面上的缺陷。因此選用該數據集中的皮革和木材樣本作為接下來的實驗數據集。由于該數據集對缺陷區域做了像素級別的標注,所以需要利用第1章中提出的方法將像素級別的標注轉換為缺陷檢測的標注文件。在該數據集中,皮革樣本共有245個無缺陷樣本、19個顏料缺陷樣本、19個切裂缺陷樣本、17個折疊缺陷樣本、19個膠水缺陷樣本和18個戳裂缺陷樣本;而木材樣本共有247個無缺陷樣本、8個顏料缺陷樣本、10個孔洞缺陷樣本、10個水跡缺陷樣本和21個刮傷缺陷樣本。本文隨機抽取樣本作為訓練集和測試集,以滿足后續的實驗需求。
3.2 實驗設置
首先,采用第1章構建的ISD數據集中的訓練集,分兩個階段來訓練模型。第一個階段采用ISD訓練集的第一部分,即基類缺陷中每個類的200個樣本(共計5類)進行訓練,獲取預訓練模型。第二個階段采用訓練集的第二部分,即從ISD數據集中隨機選擇10個無缺陷樣本并分別在每個缺陷類(共計10類)中隨機選擇k個缺陷樣本(即k-shot)進行模型的微調,其中k值可以為1,5和10。測試階段采用第1章中構建的測試集,即5類基類缺陷共450個樣本以及5類新類缺陷共337個樣本。
其次,利用3.1節中提到的皮革和木材數據集來訓練模型。第一個訓練階段的設置與上一段的描述保持一致,均采用ISD數據集的第一部分參與訓練。對于皮革數據集的訓練,第二個訓練階段從皮革數據集中隨機選取10個皮革無缺陷樣本,并分別在ISD數據集中的基類和皮革數據集中每個類(共10類)隨機選取k個缺陷樣本(即k-shot)進行模型的微調,其中k值可以為1,5和10。皮革缺陷的測試集包括9個顏料缺陷樣本、9個切裂缺陷樣本、7個折疊缺陷樣本、9個膠水缺陷樣本和8個戳裂缺陷樣本。而對于木材數據集的訓練,第二個訓練階段從木材數據集中隨機選取10個木材無缺陷樣本,并分別在ISD數據集中的基類和木材數據集中每個類(共9類)隨機選取k個缺陷樣本(即k-shot)進行模型的微調,由于樣本量不足,此時的k值只能為1和5。木材缺陷的測試集包括3個顏料缺陷樣本、5個孔洞缺陷樣本、5個水跡缺陷樣本和16個刮傷缺陷樣本。
本文提出的模型采用ResNet-101[22]作為主干網絡,基于NVIDIA Titan XP GPU進行實驗,并使用隨機梯度下降(stochastic gradient descent,SGD)算法進行訓練。第一個訓練階段將批尺寸設置為8,學習率設置為0.008,權重衰減設置為0.000 5。而在第二個訓練階段批尺寸將減小到4。
3.3 對比實驗
本文將TDENet與三個少樣本目標檢測模型FRCN+ft[3]、Meta R-CNN[3]和FSDet[4]進行比較,在ISD數據集、皮革和木材數據集上進行了實驗,并采用mAP作為評估指標。其中,FRCN+ft表示按照少樣本學習策略[3]訓練得到的Faster R-CNN模型。為了公平比較,三個比較模型也是按照同樣的少樣本學習策略重新訓練得到。
3.3.1 定量分析
表3呈現了在ISD數據集上本文提出的模型和三個少樣本目標檢測模型的k-shot(k=1,5,10)性能評估結果。表中記錄了IoU閾值為0.5時,對應的mAP大小。與FRCN+ft相比,TDENet對于新類缺陷的檢測性能在各種情況下都有較大的提升。具體來說,在1-shot、5-shot和10-shot時,mAP的增長分別為3.64、3.86和4.40個百分點。與Meta-RCNN相比,TDENet對于新類缺陷的檢測性能有很大的提升,在1-shot、5-shot和10-shot時分別提高了2.75、1.81和2.81個百分點。值得注意的是,Meta R-CNN在兩個訓練階段使用相同的網絡結構,而TDENet使用了兩種不同的網絡結構。

表3 在ISD數據集上的性能評估Table 3 Evaluations on ISD dataset單位:%
這表明本文在兩個訓練階段采用不同網絡結構的方法是有效的。此外,TDENet在新類上的檢測性能比FSDet高得多。從表中可以觀察到,與FSDet相比,TDENet對于新類的檢測性能有了非常大的提升,在1-shot、5-shot和10-shot時分別提升了19.04、21.04和5.52個百分點。雖然FSDet對于基類缺陷的檢測性能比TDENet高,但對于新類的檢測性能比較低。而這種情況也說明FSDet不適合少樣本缺陷檢測任務。從表3可以看出,TDENet對于新類缺陷的檢測性能最高,同時也保證對于基類缺陷的檢測性能的穩定。雖然FSDet在1-shot和5-shot時對于基類缺陷的檢測性能略高,但對于新類缺陷的檢測性能卻出現了大幅度下滑。表4呈現了基于皮革和木材數據集的性能評估結果。從中可以觀察到,TDENet在皮革和木材數據上的缺陷檢測性能都達到了最優。綜合以上的比較,可以看出TDENet在不同的工業場景中均擁有比其他幾個模型更好的缺陷檢測性能。

表4 在皮革和木材數據集上的性能評估Table 4 Evaluations on leather and wood datasets 單位:%
3.3.2測試結果展示
圖6展示了一些具有代表性的少樣本缺陷檢測模型的實驗結果,包括ISD數據集,皮革以及木材數據集的測試結果。圖中的Grounnd Truth表示缺陷樣本的真實標注值。與真實值相比,TDENet表現出了最好的缺陷檢測性能。與此同時,其他模型的檢測結果并不理想,檢測框的位置與真實值有很大的偏移,甚至是遺漏了部分重要缺陷。如圖6(a)和圖6(c)所示,FRCN+ft的檢測結果遺漏了一些缺陷。在圖6(b)的第3列中,Meta R-CNN檢測到與真實缺陷相似的偽缺陷,而這些偽缺陷會干擾真實缺陷的檢測準確率。在圖6(c)中,Meta R-CNN在同一個缺陷位置上生成了2個不同類別的檢測框。此外,Meta R-CNN和FSDet甚至無法檢測到某些樣本中的任一缺陷,這是很嚴重的錯誤。因此,與其他模型相比,TDENet的缺陷檢測性能更為穩定,更適合用于不同工業場景下的表面缺陷檢測任務。

圖6 少樣本缺陷檢測模型的測試結果Fig.6 Test results of few-shot defect detection models
3.4 參數選取
圖7中藍色的線表示模型對于ISD數據集的基類(即鋼鐵表面缺陷)在10-shot情況下的檢測效果,橙色的線表示模型對于ISD數據集的新類(即磁瓦表面缺陷)在10-shot情況下的檢測效果。如圖7所示,在ISD數據集上,新類的正確率比基類的正確率高。從圖1(a)可以看出,圖中第1列、第3列和第4列的鋼鐵表面缺陷是線狀缺陷和面狀缺陷,較為簡單;但第2列和第5列的鋼鐵表面缺陷是散點狀缺陷,較為復雜。從圖1(b)可以看出,圖中的五列磁瓦表面缺陷是線狀缺陷和面狀缺陷,且每張圖一般只有一個缺陷,較為簡單。基于以上分析可知,鋼鐵表面缺陷比磁瓦表面缺陷更加復雜且背景多變,缺陷檢測的難度更高。圖6(a)和圖6(b)的缺陷檢測結果也驗證了上述分析,其中兩類散點狀缺陷較難檢測,拉低了對于鋼鐵表面缺陷的檢測效果。因此,圖7中新類的正確率比基類的正確率高。

圖7 參數值λ的選取實驗Fig.7 Selection experiment of parameter value λ
在vclassn與vdf的特征向量相減操作中,比例系數λ是最重要的參數。如圖7所示,本文進行了多次實驗以找出最合適的λ值,當λ值為0.05時,TDENet對于ISD數據集中基類和新類缺陷的檢測性能都是最佳。當選取的λ值小于0.05時,TDENet的缺陷檢測性能會下降。而導致這種情況的原因主要是,當λ太小時,從無缺陷樣本中提取到的特征就會不起作用。此外,當選取的λ值大于0.05時,TDENet的缺陷檢測性能也會下降。而這主要是因為中的部分值在特征向量相減操作后變為零,從而遺失了部分特征信息。因此,當λ的值設置為0.05時,TDENet可以較好地利用無缺陷樣本,并獲得良好的缺陷檢測性能。
3.5 消融實驗
本文做的消融實驗結果如表5所示,其中[·,·]代表在通道維度進行特征圖串聯的操作。在消融實驗中用IoU閾值為0.5時的mAP作為性能評價指標,且在第二階段的訓練中,每次從新類數據中選取k個樣本參與模型的微調,以獲得最終的缺陷檢測模型。從表中可以看出TDENet中提出的新模塊的有效性。之后,本文將要探討兩個方面的問題:(1)針對TDENet的三個網絡分支輸出的特征,不同的利用方法對缺陷檢測性能的影響;(2)本文提出的缺陷突顯模塊的有效性。本文所有的消融實驗基于ISD數據集,并將Meta R-CNN的缺陷檢測性能設置為消融實驗研究的基準(即Baseline)。
3.5.1 如何利用TDENet的三個分支更有效
在網絡結構上,TDENet在第二個訓練階段有三個網絡分支。其中,第一個分支由缺陷檢測的骨干網絡ResNet和RPN組成,輸出的是ROI特征。而PRN和DPM作為兩個特征提取模塊分別屬于第二個和第三個分支,旨在從樣本中提取出更多有價值的特征。這兩個分支可分別提取到兩種特征圖,即之后,本文探索了三種使用這兩種特征圖的方法:(1)只利用DPM提取出的特征圖且不進行特征聚合;(2)將這兩種特征圖進行逐通道求和來實現特征聚合;(3)將這兩種特征圖在通道維度進行串聯以實現特征聚合。
從表5可以看出,對使用(1)中的方法獲得的模型進行測試(即表中第2行的實驗),發現其檢測性能有所提升。與Baseline相比,它在1-shot、5-shot和10-shot時的檢測性能分別增加了0.19、0.98和0.81個百分點。這說明第三個網絡分支能夠利用無缺陷樣本來增強缺陷區域的特征,進而提升缺陷檢測性能。對使用(2)中的方法獲得的模型進行測試時(即表中第3行的實驗),發現其檢測性能出現顯著性下降。與Baseline相比,它在1-shot、5-shot和10-shot時的檢測性能分別減少了0.37、3.47和2.06個百分點。查看圖像檢測結果可發現,雖然使用(2)中的特征聚合方法可以使較為明顯的缺陷更容易被檢出,但同時也會降低不明顯的缺陷的分類得分,進而使這些不明顯的缺陷更容易被拋棄。與之不同的是,對使用(3)中的方法獲得的模型進行測試時(即表中第4行的實驗),發現其檢測性能相對于使用(1)中的方法獲得的模型有了進一步的提升。在1-shot、5-shot和10-shot時,其檢測性能分別增加了0.33、0.40和1.41個百分點。此外,從實際的圖像檢測結果來看,有更多的不明顯缺陷被檢出。這說明,利用特征圖在通道維度進行串聯的操作可以整合PRN和DPM這兩個模塊提取的缺陷特征,在保證較明顯缺陷的檢測性能穩定的同時,更容易檢測出那些不明顯的缺陷。
3.5.2 缺陷突顯模塊是否能提高TDENet的性能
本文提出缺陷突顯模塊(DPM)以提高模型在只有少量樣本輸入時對于新類缺陷的表征能力。從表5容易看出,缺陷突顯模塊可以提升模型對于新類缺陷的檢測性能。與Baseline(即表中第1行的結果)相比,加入DPM后,在1-shot、5-shot和10-shot時的mAP均有所增長。而性能提升的主要原因是DPM利用了無缺陷樣本的特征以突出特征圖中缺陷區域的特征。此外可以觀察到,與Baseline相比,加入DPM后,在1-shot時的檢測性能提升很小。出現這種情況的主要原因是當輸入的樣本很少的時候,訓練集數據不具有多樣性,導致DPM提取的特征不足。但是當更多的樣本作為輸入時,檢測性能會得到提高。
本文提供了兩個配備不同激活函數的DPM+變體,即配備softmax激活函數的DPM+w/soft和配備tanh激活函數的DPM+w/tanh,其中DPM+w/soft和DPM+w/tanh分別表示移除PRN的最后一層(即sigmoid層),然后在特征向量的相減操作之后分別添加一個softmax和tanh激活函數。如表5所示,相比于DPM+w/soft和DPM+w/tanh較差的表現,DPM+更能提升缺陷檢測的性能。與使用DPM并在通道維度進行特征圖串聯的模型(即表中第4行的實驗)相比,使用DPM+并在通道維度進行特征圖串聯(即表中第7行的實驗)可以將模型的檢測性能,分別在1-shot、5-shot和10-shot上提升2.23、0.43和0.59個百分點。因此,DPM+可以減少特征向量相減運算過程中的計算誤差,使特征向量中的重要特征得到更好的保留,進而提升了少樣本缺陷檢測模型的性能。

表5 TDENet中提出的新組件的消融實驗Table 5 Ablation experiments for novel components proposed in TDENet 單位:%
4 結語
本文構建了一個用于少樣本缺陷檢測的新數據集,旨在促進少樣本缺陷檢測的研究,并且該數據集對提升工業生產的產品質量有著實際的意義。針對部分工業場景中難以提供大量缺陷樣本的問題,本文提出了TDENet,它遵循少樣本學習策略并將整個訓練過程分為兩個階段,僅利用少量樣本就可以在很大程度上提高對于罕見缺陷的檢測效果。同時,在TDENet中提出了DPM模塊,以更好地利用無缺陷樣本來提升模型對于新類缺陷的表征能力。此外,在DPM的基礎上,本文提出了DPM+,可以更好地處理特征信息丟失的問題。基于ISD數據集,皮革和木材數據集的對比實驗以及消融實驗證明了TDENet性能的優越性以及其中各個模塊的有效性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
