基于機器學習的私人汽車保有量影響因素分析及預測
——以新疆為例
2022-10-17 08:09:10周亞林葉琴郭杰王雪成
交通運輸研究 2022年4期
周亞林,葉琴,郭杰,王雪成
(1.交通運輸部科學研究院,北京 100029;2.新疆交通科學研究院有限責任公司,新疆 烏魯木齊 830011;3.干旱荒漠區公路工程技術交通運輸行業重點實驗室,新疆 烏魯木齊 830011)
0 引言
隨著經濟的發展,我國私人汽車保有量在不斷增加。從2000 年到2021 年,我國私人汽車保有量從625 萬輛增加到2.6 億輛,增長了41倍[1-2]。私人汽車保有量的高速增長帶來了城市交通擁堵、空氣污染等一系列問題。對私人汽車保有量的影響因素進行分析進而科學地預測私人汽車保有量,對于測算私人汽車的二氧化碳排放量、評估私人汽車對能源和環境的影響、科學規劃城市道路、制定交通擁堵緩解措施等非常重要。
目前,已有不少文獻對汽車保有量的影響因素及預測進行了研究。孫璐等[3]基于主成分分析法,Cao等[4]、Yang等[5]基于固定效應和隨機效應模型、林耿堃等[6]基于多元線性回歸模型分析了汽車保有量的影響因素。Ha等[7]進一步拓展了研究方法,基于柬埔寨金邊市數據,運用多元Logit模型以及機器學習中的神經網絡和隨機森林方法,分析家庭汽車保有量影響因素,發現家庭收入是最重要的影響變量,其次是16歲以上家庭成員的數量和工作出行次數。以上研究發現私人汽車保有量會受到多類因素的影響,包括宏觀經濟因素、公共交通服務水平、汽油價格、交通管理政策等,而經濟增長是汽車保有量增長的一個重要驅動因素。在分析汽車保有量影響因素的基礎上,很多學者對未來汽車保有量進行了預測,其中最常用的是計量經濟學法。如李瑞敏等[8]、劉愷[9]、萬芳[10]基于計量經濟學模型,蔣艷梅等[11]基于新產品擴散Logistic 模型及兩種參數估計方法,諶小麗等[12]基于指數平滑模型對我國汽車保有量進行了預測。也有部分學者探索了其他汽車保有量預測方法,如Huo等[13]構建了燃料經濟性和環境影響(FEEI)模型,Hao等[14]建立了包含3個子模型的混合模型對我國私家車保有量進行了預 測;Wu等[15],Lu等[16]基于Gompertz曲線,Hsieh等[17]基于蒙特卡洛模擬,Feng等[18]基于Cui-Lawson 模型預測了未來我國的汽車保有量。另外,還有部分學者采用神經網絡方法對汽車保有量進行了預測。例如,夏鈺等[19]基于神經網絡BP算法對出租汽車保有量進行預測,結果表明神經網絡預測模型在交通預測方面具有較高的計算精度;吳文青等[20]基于Simpson 改進的灰色神經網絡預測了汽車保有量,證明基于Simpson 公式的灰色神經網絡預測精度高于灰色神經網絡模型和單一預測模型。
整體而言,目前汽車保有量的影響因素分析和預測研究主要是基于傳統的統計學、計量經濟學和宏觀經濟學模型,較少采用機器學習方法,相應缺少強大的模式識別能力,難以很好地擬合變量之間的復雜關系。而少數基于機器學習的汽車保有量影響因素分析或預測研究,或是以家庭為研究對象開展影響因素分析[7],或是直接基于機器學習模型進行預測而忽略了對汽車保有量影響因素的分析[19-20]。基于此,本研究將構建基于機器學習的私人汽車保有量影響因素分析及預測模型,通過極度梯度提升樹(Extreme Gradient Boosting,XGBoost)提取私人汽車保有量最重要的影響因素,并在比較不同機器學習方法預測精度的基礎上,篩選出預測效果最好的方法對私人汽車保有量進行預測,從而為測算私人汽車碳排放量、制定私人汽車管理政策提供依據。
1 模型方法介紹
隨著人工智能的發展,機器學習被廣泛應用于各領域的因素識別和預測。機器學習研究如何利用學習經驗改善模型自身的性能,其主要從輸入的數據中產生模型的算法,挖掘輸入數據之間的關系,即“學習算法”[21]。機器學習的具體方法有很多,包括XGBoost、隨機森林、神經網絡、支持向量機等。在交通運輸領域,已有大量研究采用了機器學習方法,如基于隨機森林方法對交通出行方式選擇進行預測[22],基于k 鄰近算法和支持向量回歸模型對交通流進行預測[23],基于神經網絡方法對公路貨運量[24]、鐵路貨運量[25]、鐵路客流發送量[26]、貨車交通流量需求[27]以及城市軌道交通客流[28]等進行預測,均具有良好的預測效果。
為更準確地識別私人汽車保有量的影響因素并預測未來的私人汽車保有量,本研究將構建基于機器學習的私人汽車保有量影響因素及預測模型。該模型首先基于歷史數據,采用XGBoost 方法識別出影響私人汽車保有量的主要影響因素。然后通過比較預測精度篩選出機器學習中預測效果最好的方法,并將識別出的主要影響因素納入預測模型,從而對未來的私人汽車保有量進行預測。模型具體結構如圖1所示。
1.1 XGBoost方法
本研究擬采用機器學習中的Boosting 方法分析私人汽車影響因素。Boosting 是機器學習中一種常用的集成學習方法,其主要思想是通過多個弱學習器的組合來得到一個強學習器,從而提升性能。XGBoost 方法[29]是一種典型的Boosting 算法,在學習器模型選擇、算法運行效率優化、算法魯棒性等方面,均比以往方法有較大提升,因此被廣泛應用于各種分類或回歸任務中。XGBoost中常用的底層學習器為決策樹,假設集成模型中共有K個決策樹,其中第k個決策樹的輸出結果為fk(xi),則XGBoost方法的最終輸出為:
式(1)中:xi為第i個輸入樣本;yi為對該樣本的預測值。
XGBoost模型的優化目標L為:
式(2)中:為真實輸出值;l(yi,)為損失函數,用于計算預測值和真實值之間的誤差;γ和α為加權系數;T為葉子節點個數;w為決策樹對應的權重;M為樣本數量。
在優化過程中,通過不斷構建決策樹來得到最終的XGBoost模型。具體而言,在第t次迭代優化過程中,需尋找對預測誤差降低最多的決策樹ft加入到集成模型中,第t次迭代的優化目標L(t)如式(3)所示。
通過迭代優化以上損失函數,即可讓XGBoost訓練得到較好的預測模型。
模型的解釋性是XGBoost 方法的一項重要優勢。由于XGBoost 的底層是由決策樹實現的,因此對于最終訓練得到的模型,可進行決策過程解釋,有助于深入了解模型做出預測的邏輯。同時,XGBoost 方法可得到不同輸入特征的重要性度量,因此可有效篩選出重要的影響因素。
1.2 神經網絡方法
神經網絡是一種模仿生物神經網絡系統的機器學習模型,可有效擬合不同的函數。神經網絡可創建自主學習系統,相比其他機器學習算法,其學習能力更強且具有較強的數據處理能力,因此被廣泛應用于預測領域。
神經網絡由多個層疊加組成,主要包括一層輸入節點、一層輸出節點、一個或多個中間層。在每一層中,由多個神經元的共同作用得到輸出結果[30]:
式(4)中:fi為該層第i個神經元的輸入;wi為該神經元的權重,通過訓練得到;b為偏置量;o為該層的輸出。
神經網絡的訓練主要依賴反向傳播算法,通過尋找使輸出損失函數最快下降的方向,來調整神經網絡的權重。對于多層神經網絡,需利用鏈式法則計算得到每一層中權重參數的求導結果。一旦訓練完成,神經網絡的形式就固定下來,通過對神經網絡的前向推導,可得到最終的輸出結果。
2 私人汽車保有量影響因素分析——以新疆為例
2000 年以來,新疆私人汽車保有量不斷提升,年均增長率超過18%(見圖2)。本文將運用前文介紹的模型對新疆私人汽車保有量進行影響因素分析及預測。基于新疆2000—2020年的統計數據,首先識別影響私人汽車保有量的影響因素,然后在此基礎上預測到2030年新疆私人汽車保有量。
2.1 影響因素篩選
根據不同學者的研究(見表1),私人汽車保有量的影響因素主要分為4 類:(1)宏觀經濟因素,包括人均GDP、產業結構、城鎮化率、居民人均可支配收入等;宏觀經濟因素是影響私人汽車保有量的主要因素,GDP 的增長和生活水平的提高會提升人民對出行質量的需求;在發展中國家,隨著人均GDP、人均收入等的增加,私人汽車保有量一般會相應增長;(2)公共交通因素,主要指標為城市人均公共交通運營數或客運量,包括人均公共汽電車數量或公共汽車載客量、出租車數量等,完善的公共交通設施可使公共交通出行更具吸引力,從而對私人汽車出行形成一定替代;(3)道路條件因素,包括人均道路面積、人均公路里程等,一般而言,良好的行車條件會使居民傾向于私人汽車出行;(4)汽油價格因素,燃油價格的增長會提高私人汽車使用成本,從而會影響消費者對私人汽車的購買意愿。
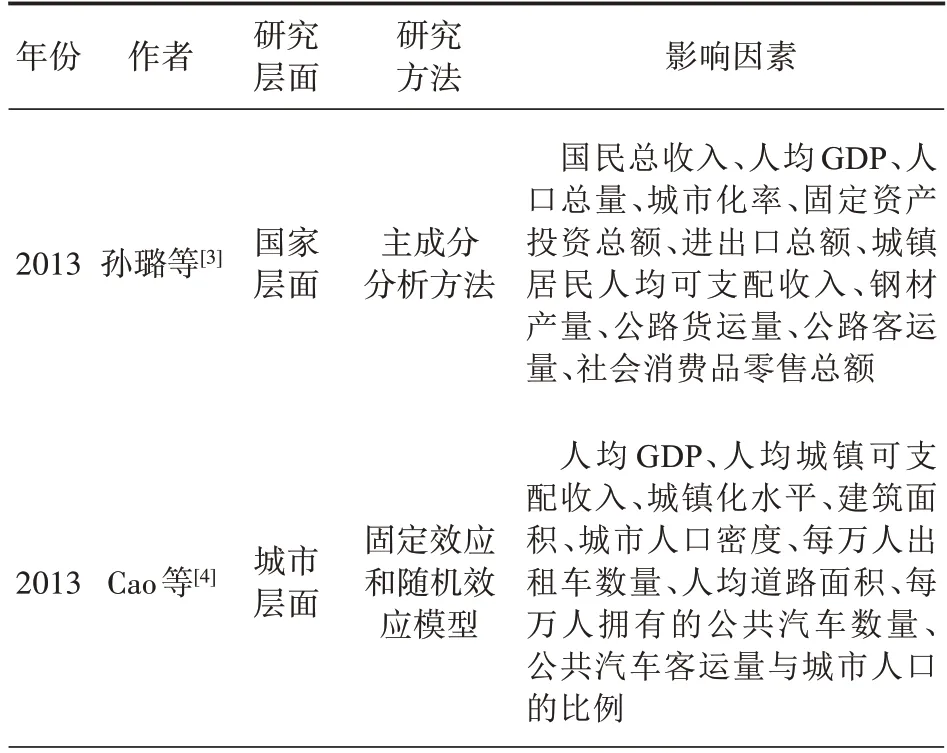
表1 私人汽車保有量影響因素相關研究

表1 (續)
在相關文獻研究成果的基礎上,考慮數據的可得性,本研究選取了9 個可能影響私人汽車擁有量的因素,包括人均GDP、城鎮化率、第三產業占比、城鎮居民人均可支配收入、人均道路面積、每萬人公路里程、每萬人公共汽電車數量、每萬人出租汽車數量以及汽油價格。人均GDP、城鎮化率、第三產業占比、城鎮居民人均可支配收入、人均道路面積、每萬人公路里程、每萬人公共汽電車數量、每萬人出租汽車數量等指標所需原始數據均來源于國家統計局,汽油價格選取了烏魯木齊92號清潔汽油年均價格數據,來源于CEIC數據庫。
由于輸入的因素較多,且不同因素對最終預測的影響不同,某些因素可能與最終預測結果相關性很低,因此在對私人汽車保有量進行預測時,首先需要對影響私人汽車保有量的因素進行篩選和分析,從而提高最終預測的準確性。本研究基于2003—2020年新疆私人汽車保有量及其影響因素相關數據,將樣本劃分為訓練集和測試集,其中訓練集為2003—2016年的數據,測試集為2017—2020 年的數據。本研究采用XGBoost 模型在訓練集中學習,從而得到新疆私人汽車保有量影響因素的分析結果。
2.2 影響因素分析結果
在應用XGBoost 模型過程中,通過逐次剔除每個輸入特征后觀察其對最終結果的影響,可以得到每個特征的重要性分值。圖3 所示為基于XGBoost 模型學習到的不同輸入變量(新疆私人汽車保有量影響因素)的重要性程度的可視化。從圖中可看出,人均GDP 及城鎮化率兩個因素對于新疆私人汽車保有量具有最重要的影響。
為更清晰地理解XGboost 模型的工作過程,本研究對XGBoost 模型進行更多的可視化,展示XGBoost模型中的兩個決策樹推理過程,如圖4所示。對于輸入的變量,在每個節點中,根據條件來判斷選擇左右子節點,直至到達最終的葉子節點,則得到該決策樹的輸出。通過綜合多個決策樹的輸出結果,即可得到模型最終的預測值。由圖4 可看出,XGBoost 模型會首先根據人均GDP來決定預測模型的走向,這也驗證了人均GDP 這一因素對于私人汽車保有量的影響尤為重要。
3 私人汽車保有量預測——以新疆為例
基于XGBoost 方法計算結果,本研究篩選出重要的影響因素,構建預測模型,對未來新疆的私人汽車保有量進行預測。
3.1 預測方法比較
在機器學習方法中,XGBoost 方法、隨機森林方法、神經網絡方法等均可應用于預測。本研究基于已有數據,首先對以上3 種方法的預測效果進行對比。圖5 展示了不同方法在訓練集中的擬合效果。由圖5可看出,XGBoost、神經網絡和隨機森林模型均能很好地在訓練集中對輸入變量進行學習和擬合,得到的預測值和真實值基本一致。
本研究進一步在測試集中評估了模型的效果,如圖6 所示。神經網絡方法在測試集中的表現達到了較好的水平,預測值和真實值最接近。同時,XGBoost 方法和隨機森林方法雖然在訓練集的擬合中取得了良好效果,但在測試集中的表現劣于神經網絡方法。另外,在2020 年,基于3種方法的預測結果和真實值均有較大差異。2020年,受新冠肺炎疫情影響,新疆人均GDP 相比2019年有所下降,基于模型預測得到的2020年新疆私人汽車保有量也有所下降。但實際上2020年新疆私人汽車保有量相比2019 年仍保持了7.7%的增長,這可能是由于公共交通服務受限激發了居民對私人汽車的需求。
本研究進一步對3 種方法的預測效果進行定量評估。均方根誤差(Root Mean Square Error,RMSE)常被用于評價預測的精度,其計算公式為:
式(5)中:yi為對該樣本的預測值;為真實值。
RMSE 越小表示模型預測精度越高。表2 展示了XGBoost、神經網絡以及隨機森林3種方法的RMSE 值。可以看出,神經網絡方法的RMSE 指標數據小于其他兩種方法,顯示神經網絡模型具有更好的預測精度。

表2 不同方法的RMSE值
3.2 預測模型參數設置
基于上文的分析結果,本研究將以新疆私人汽車保有量最重要的兩個影響因素,即人均GDP和城鎮化率作為預測模型的輸入,運用預測效果更好的神經網絡方法來對未來新疆私人汽車保有量進行預測。本研究對未來宏觀經濟發展設置了低、中、高3 種情景。根據《新疆維吾爾自治區國民經濟和社會發展第十四個五年規劃和2035年遠景目標綱要》[31],到2025 年新疆常住人口城鎮化率將不低于60%;根據《新疆城鎮體系規劃(2012—2030)》,到2030 年新疆城鎮化率將達66%~68%[32],因此,本研究設定在低、中、高3個發展情景下,到2025 年新疆城鎮化率分別為60%,61%和63%,到2030 年新疆城鎮化率分別為66%,67%和68%。不同情景下2022—2030 年新疆人均GDP 增長率則分別參考不同機構或學者對于未來我國人均GDP 增長率的預測數據進行設定[33-35],詳見表3。
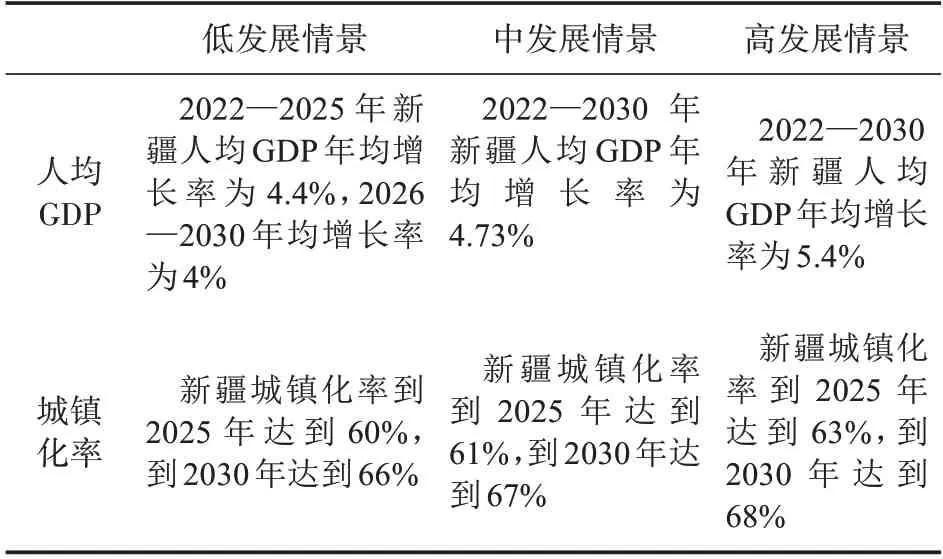
表3 新疆未來不同發展情景相關參數設定
3.3 預測結果
基于神經網絡的新疆私人汽車保有量預測結果如圖7、表4 所示。根據預測結果,隨著未來新疆人均GDP 及城鎮化率的提升,新疆的私人汽車保有量將繼續保持不斷增長態勢。在低發展情景下,未來新疆私人汽車保有量年均增長率為5%,到2025 年,新疆私人汽車保有量將達到516.5萬輛,到2030年將達到650.2萬輛;在中發展情景下,新疆私人汽車保有量年均增長率為5.6%,到2025 年和2030 年保有量將分別達到525 萬輛和687.7 萬輛;在高發展情景下,新疆私人汽車保有量年均增長率將達到6.4%,到2025年和2030 年保有量預計將分別達到541.2 萬輛和734.3萬輛。

表4 不同情景下2021—2030年新疆私人汽車保有量預測結果
4 結語
本研究基于機器學習方法構建了私人汽車保有量影響因素分析及預測模型。以新疆2003—2020 年數據為基礎,采用機器學習中的XGBoost方法分析了影響私人汽車保有量的因素,結果顯示人均GDP 和城鎮化率是對私人汽車保有量影響最大的因素。在此基礎上,通過對比XGboost、隨機森林以及神經網絡3 種方法的預測效果,采用預測效果最好的神經網絡方法建立新疆私人汽車保有量預測模型,對2021—2030年新疆私人汽車保有量進行了預測。在本研究中,因樣本數據量有限,在少量數據上訓練得到的神經網絡的泛化能力略差,即雖然在已知的數據集(訓練集)上擬合效果較好,但在對訓練數據之外的私人汽車保有量進行預測時,精度可能會下降,故未來的研究中需進一步豐富樣本數據量。另外,基于2003—2016 年的數據分析顯示,人均GDP 和城鎮化率是對私人汽車保有量影響最大的兩個因素,但在一些特殊年份(如2020 年),其他因素如公共交通服務水平等相比而言對私人汽車保有量可能有更大的影響。因此,本研究的預測方法仍有一定的局限性,未來在對機動車保有量進行長期預測時,可考慮將基于歷史數據的定量分析與政策等定性分析結合,或根據不同的增長階段提出更詳細的模型,從而更好地捕捉影響私人汽車保有量的因素,實現更科學準確的預測。
猜你喜歡
中老年保健(2022年5期)2022-08-24 02:36:04
當代陜西(2021年12期)2021-08-05 07:45:46
四川文學(2021年4期)2021-07-22 07:11:54
兒童時代·快樂苗苗(2017年7期)2018-01-24 18:28:45
作文大王·低年級(2016年4期)2016-04-18 00:24:37
冰雪運動(2016年4期)2016-04-16 05:54:56
劍南文學(2015年1期)2015-02-28 01:15:15
絲綢之路(2014年9期)2015-01-22 04:24:46
決策探索(2014年21期)2014-11-25 12:29:50
兒童與健康(2011年4期)2011-04-12 00:00:00
