基于混合分類的插電式新能源汽車行為需求預測
2022-10-20 03:41:32唐菲鄭振
現代信息科技 2022年13期
唐菲,鄭振
(1.武漢船舶職業技術學院,湖北 武漢 430050;2.武漢軟件工程職業學院,湖北 武漢 430205)
0 引 言
插電式新能源汽車(Plug-in New Energy Vehicles,PNEV)是介于純電動車和燃油汽車之間的一種新能源汽車,是減輕碳排放、提高可持續發展的有效途徑。從電力系統的角度來看,PNEV 車主的電力需求與傳統電力消費的峰值負載高度一致,其動態性為預期負載曲線帶來很大的不確定性。關于PNEV 行為建模的研究可分為基于情景的方法和數據驅動的方法。基于場景的方法大多采用了蒙特卡洛法,這些方法依賴于根據參數(即PNEV 出發時間、到達時間和行駛距離)的概率分布定義的搜索空間生成大量隨機樣本。例如,可使用正態分布函數和高斯分布函數為每個參數生成樣本,或使用聯合概率分布函數來生成出發時間和到達時間。這些方法具有較高的計算成本、效率低下,且需要大量的數據樣本來覆蓋搜索空間。在數據驅動方法中,部分現有研究使用自回歸綜合移動平均模型等時間序列預測工具對PNEV 的需求進行預測,但是PNEV 行為和需求的不確定性會影響這些工具的準確性。還有研究利用基于神經網絡的數據驅動方法來克服上述PNEV 出行行為預測中的不足。但是目前的研究采用了淺層神經網絡,其結構無法提取大型數據集的主要特征。除此以外,基于神經網絡的方法缺乏考慮在PNEV 的隱藏行程模式對電力需求計算的影響。本文提出了基于深度學習的解決方案,以彌補現有研究的不足。深度學習是解決具有復雜相互關系的大維度問題的有力工具。深度學習能夠完全從歷史數據中自動提取大維度數據的主要特征。本文將真實世界的PNEV 數據饋入至深度分類器,以便根據其中存在的隱藏行為模式自動對數據進行聚類,并為每個簇分配一個深度網絡,以捕獲和預測每個簇的獨特行為。為了進一步提高預測結果的準確性,本文我們利用了深度長短期記憶(Long Short Term Memory,LSTM)網絡,以模擬行為的短期變化以及出行模式特征的長期趨勢。本文提出了一個稱為聚合器的中介機構,通過充電計劃和合同,聚合器旨在從技術和經濟角度滿足其PNEV 的充電需求。
1 分類和預測方法設計
為了提高充電效率,聚合器需要準確地估計PNEV日前(Day-Ahead,DA)的行駛行為。PNEV 行為和需求預測的流程如圖1所示,該方案采用深度LSTM 網絡進行分類和預測。
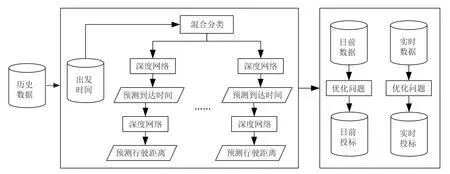
圖1 PNEV 行為和需求預測的流程
每個深度LSTM 網絡都是通過堆疊LSTM 塊來構建,每個LSTM 塊是一個層。本文使用深度LSTM 網絡進行分類和預測任務,除了網絡的最后一層配置外,這兩個任務中網絡的整體結構是相同的。在預測網絡中,將整流線性單元(Rectified Linear Unit,ReLU)作為最后一層的激活函數,并使用均方誤差(Mean Squared Error,MSE)函數來計算訓練誤差;而在分類過程中,分別使用SoftMax 激活函數和分類交叉熵(Categorical Cross Entropy,CCE)函數作為網絡最后一層的激活函數和誤差計算函數。為了提高所提出方法的魯棒性和穩定性,避免訓練過程中的過擬合問題,在損失函數中附加了L2 正則化項,并應用了概率分別為0.001 和0.5的dropout 技術。
為了發掘PNEV 行駛數據中隱藏的行駛模式,將基于K-means 的無監督方法和基于深度LSTM 網絡的有監督方法結合。分類任務的流程如算法1 所示:

在算法1 中,使用K-means 算法以無監督的方式對出發時間數據進行聚類,并根據Davies-Bouldin(DB)索引確定最佳簇數。該索引定義為簇內和簇間距離的比率,即:

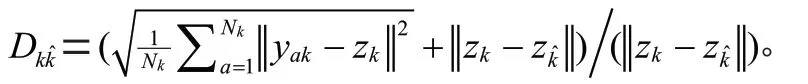
對PNEV 數據進行分類的是減少每個深度網絡需要學習和預測的數據量,從而提高整體預測的準確性。為了預測到達時間和行駛距離,為每個簇分配了兩個深度LSTM 網絡——一個學習出發時間和到達時間之間的映射來預測到達時間,另一個學習出發時間、到達時間和行駛距離之間的映射以預測行駛距離。預測過程如算法2 所示:

在測試過程中,兩個深度LSTM 網絡按以下順序執行:第一個深度LSTM 網絡將深度分類器提供的出發時間數據作為輸入,并預測相應的到達時間。然后,預測的到達時間與相應的出發時間一起被饋送到第二個深度LSTM 網絡,以預測與每個數據對相關的行進距離。這樣,出發時間、到達時間和行駛距離之間的相關性被保留在預測的旅行參數中,以提高預測的準確性。
2 充電需求優化問題
最大限度地降低PNEV 車主的充電成本是一個重要的目標。假設聚合器通過利用PNEV 的需求靈活性并在日前能源市場(Day-Ahead energy Market,DAM)和實時市場(RTM)中獲取預期的充電需求來最小化PNEV 的充電成本。
聚合器需要解決如下所示的優化問題以確定其DAM 能源投標:
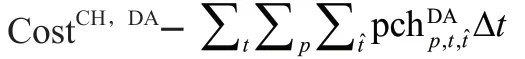
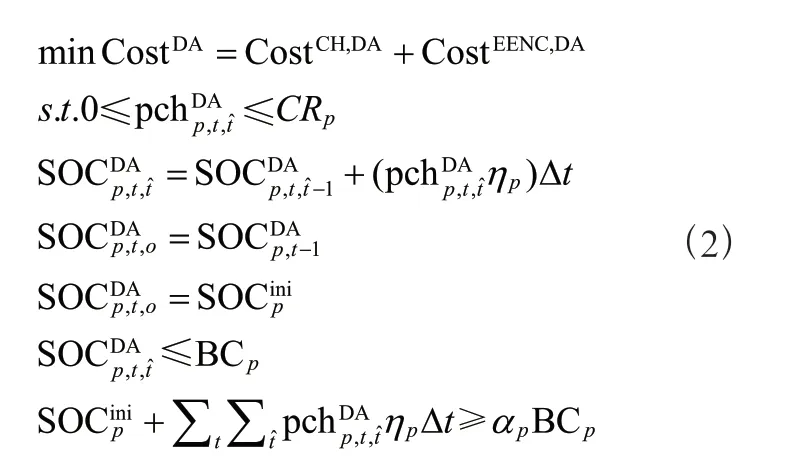
隨后本文建立了如下所示的RTM 優化問題,以評估聚合器在投標部署當天的性能:
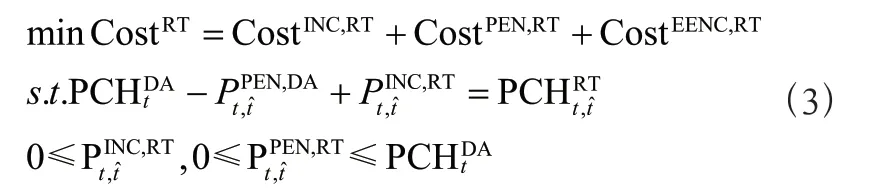
優化問題的目標是最小化RTM 聚合器的成本Cost,該項由3 個成本組成:Cost是指從RTM 獲取額外能源需求的成本;Cost是指無法使用中標的DAM 能源的成本;Cost是指投標部署當天的PNEV 的EENC。
3 實驗評估
實驗評估部分進行數值模擬,使用了從北京電動汽車監控與服務中心收集得到的大量新能源出租車數據來訓練提出的深度學習模型的方法。其中,80%的數據集用于訓練,10%的用于驗證,10%的用于測試。為了制定最佳的充電任務,考慮了一個中壓配電網絡,該網絡由21 個節點組成,最大需求為310 kW,每個節點的滯后功率因數為0.98。每個饋線段的電流容量為314 安培,允許電壓偏差為5%。為了在網絡中模擬負荷,隨機生成負荷曲線,而DA 和RTM能源價格則從充電樁運營商獲取。低于中標DA 投標的消耗罰款價格設置為給定日期最高能源價格的30%,將最低PNEV 的荷電狀態(State Of Charge,SOC)設定為75%,將和設置為各自市場最高能源價格的50%。使用CPLEX 工具對優化問題進行求解。對于神經網絡的訓練,使用了MATLAB 中的Classification Learner分類學習器和Deep Network Designer 工具箱分別用于執行LSTM 網絡的分類和訓練程序。分類和預測任務中的深度LSTM 網絡分別由100 和300 個LSTM 區塊構建,其中設置為15。實驗使用作為評估指標,其定義為:
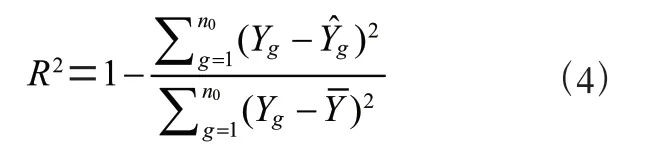
實驗首先通過根據出發時間對PNEV 數據進行無監督聚類,得到五個不同的簇,如圖2所示,表示數據集中存在五種隱藏的旅行模式。隨后,使用深度LSTM 網絡進行有監督分類任務,結果如表1所示。由該結果可知,深度LSTM 網絡具有較高的分類精度和準確性。

表1 分類精度和準確性
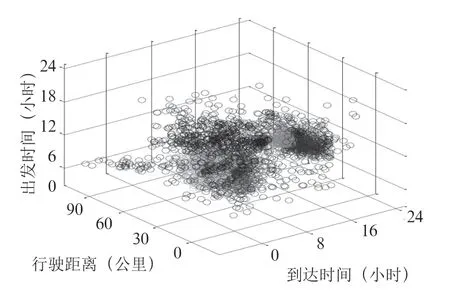
圖2 無監督聚類結果
進行分類后,使用深度LSTM 網絡分別為每個簇預測到達時間和行駛距離。為了驗證分類任務的有效性,實驗部分將在分簇后和未分簇的數據上進行預測,結果如表2所示。分簇對預測精度的影響在行駛距離上比到達時間更明顯,即經過分簇后,行駛距離的預測精度有顯著提高。

表2 R2 指標對比
4 結 論
本研究提出了基于深度學習的預測方法,該方法使用深度LSTM 網絡預測PNEV 的行駛行為及其電力需求。實驗結果表明,所提出的分類方法可以提高預測的準確性。本研究結果表明,基于深度學習的方法在PNEV 需求建模中提供了出色的性能。在未來的研究工作中,將考慮不同價格的充電產品、充電和換電的服務,結合PNEV 車主的個人信息,進一步提高分類和預測的性能。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
