基于優化支持向量機的玉米淀粉含量估計
2022-10-21 12:19:20馮惠妍
科學技術創新 2022年27期
馮惠妍
(黑龍江八一農墾大學,黑龍江 大慶 163319)
淀粉是目前重要的可再生工業原料,我國玉米淀粉約占總產量的80%[1],可以通過化學計量方法,將玉米用0.3%的亞硫酸浸漬后,進行破碎、過篩、沉淀等工序制成和獲得含量。而結合近紅外光譜技術不需要破壞樣品,可獲取樣品的光譜信息,通過光譜分析可實現對樣品的定性判斷和定量分析。近紅外光譜技術已被廣泛應用在農產品檢測中。文獻[2]結合主成分分析,建立了不同種類淀粉的定性判別模型和基于PLS建立了淀粉混合物的預測模型;文獻[3]研究了近紅外光譜結合支持向量機檢測甘薯粉絲摻假木薯淀粉和玉米淀粉的可行性。因此結合近紅外光譜技術,分析近紅外光譜數據,實現對玉米淀粉含量的有效估計具有重要實際應用意義。本研究基于玉米近紅外光譜數據,以玉米淀粉含量指標為研究對象,擬首先使用多種數據預處理方法及其組合方法進行光譜的預處理,利用主成分分析算法PCA 進行光譜數據特征提取的基礎上,再結合使用粒子群優化PSO 算法,實現對支持向量回歸算法中的重要參數,懲罰因子C 和核函數參數gamma 的參數尋優,以此構建一個優化SVR 的玉米淀粉的回歸預測模型,實現對玉米淀粉含量的有效預測估計。
1 數據準備
公開的玉米近紅外光譜數據包括80 個玉米樣品,波長范圍為1 100-2 498 nm,間隔2 nm(700 個通道),數據列中包括指標淀粉含量值,其最大值66.4 720、最小值62.8 260、平均值64.6 956 以及標準差0.81 559。
光譜預處理在大多數情況下可以改善預測結果,但是有時使用源光譜也可產生很好的結果[4],因此本文首先考慮使用源光譜建立模型。文中選擇使用的光譜 預 處 理 方 法 有 源 光 譜、SNV、SNV+SG、MSC、MSC+SNV、FD MSC+SNV+FD[5]。
高維的光譜數據增加了構建模型的難度和復雜度,通常需要從高維的數據中提取出數據特征,研究使用主成分分析PCA 提取出數據主成分[6],簡化了數據規模為后續建模做準備。
數據進行特征提取后,使用SPXY(Sample set Partitioning based on joint X-Y distance)算法以4:1的比例劃分訓練集和預測集。
2 建模及模型評價
2.1 建模
支持向量機(Support Vector machine,SVM)是一種基于統計學理論的機器學習算法,由Cortes 和Vapnik 于1995 年提出,算法嘗試尋找具有最大間隔的超平面來區分不同類別的樣本,其中間隔定義為不同類別的樣本到分類超平面的距離。目前該算法思想已廣泛應用于分類和回歸問題中,并且大多數情況下運行效果相對較優[7]。支持向量回歸(Support Vector Regression,SVR)是使用SVM 來擬合曲線,做回歸分析。考慮研究使用的光譜數據的非線性和RBF(Radial Basis Function)實現分類問題的實驗效果成功[8],本研究選擇RBF 作為SVR 的核函數,RBF 核函數有兩個重要的參數:C 和gamma,不同參數所建模型的預測能力不同,可以選擇網格搜索實現參數優化,但是耗時長,因此本文選擇粒子群優化算法進行SVM的2 個重要參數尋優。
粒子群算法(Particle Swarm Optimization)是由美國社會心理學家J.Kennedy 和電氣工程師R.Eberhart于1995 年共同提出[9]。算法的基本思想受到許多對鳥類的群體行為進行建模與仿真研究結果的啟發。算法的主要步驟:
(1) 隨機初始化D 維空間中的每個粒子的位置x 和速度v。

(2) 計算粒子適應度值F:選擇模型預測的預測值與真實值之間的RMSE 作為適應度值F。
(3) 更新每個個體最優值和全局最優值。
(4) 更新粒子的速度和位置。
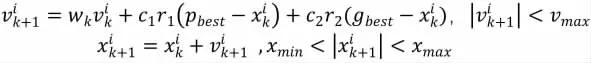
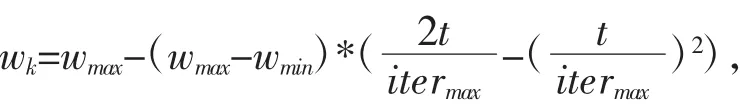

圖1 基于PSO 算法優化SVR 的玉米淀粉預測模型
2.2 模型評價
為了評價所建立模型的預測性能,本文采用三種評估方法:均方根誤差(Root mean square error,RMSE),RMSE 越小說明模型預測精度越高;決定系數(coefficient of determination,R2)值越接近1,模型穩定性越好;預測相對分析誤差RPD[10],Chang 等提出的相對分析誤差評判等級:RPD≥2 時,模型具有很好的預測效果,屬A 類模型,可用于定量預測;1.4≤RPD<2時,模型有一定的預測效果,屬B 類模型,可用于粗略的預測;RPD<1.4 時,模型的預測效果較差,屬C 類模型,不能用于定量預測[11]。
3 實驗結果
SVM 算法中參數C 和gamma 的設置范圍[0.1,100],PSO 算法中慣性權重的最大值0.9,最小值0.4,迭代次數設置為100,粒子個數分別設置為20、30、40、50、60。考慮PSO 算法可陷入局部最優,文中采用重復執行20 次取最好結果為最終的預測結果。不同預處理方法時,模型的預測結果如下:
(1) 源光譜時,PCA 各維度時模型的預測RMSE 及各維度時PSO 算法設置不同粒子數時的預測RMSE 如圖2 所示。從圖2 中可以得出,當25 維度特征提取時,粒子個數設置為50 時預測集的RMSE最小,不同粒子數時的訓練集和預測集的運行結果,如表1 所示,其中粒子個數50 時訓練集的RMSE 為0.4732,R2為0.7075,預測集的RMSE 為0.3292,R2為0.6084,RPD 為1.6504>1.4,預測模型具有一定的預測效果。
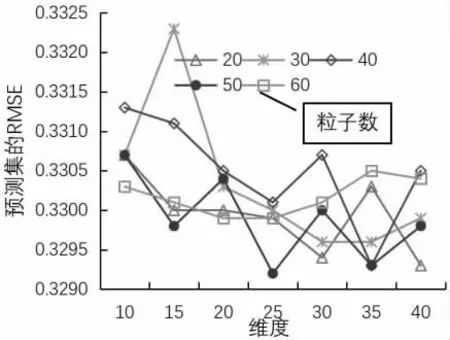
圖2 源光譜時模型的預測RMSE

表1 降維25、不同粒子數時模型的運行結果
(2) SNV 預處理時,PCA 各維度時模型的預測RMSE 及各維度時PSO 算法設置不同粒子數時的預測RMSE 如圖3 所示。從圖3 中可以得出,當10 維度特征提取時,粒子個數設置為50 時預測集的RMSE最小,不同粒子數時的訓練集和預測集的運行結果,如表2 所示,其中粒子個數50 時訓練集的RMSE 為0.1657,R2為0.9628,預測集的RMSE 為0.2044,R2為0.8853,RPD 為3.05>2,預測模型具有很好的預測效果。
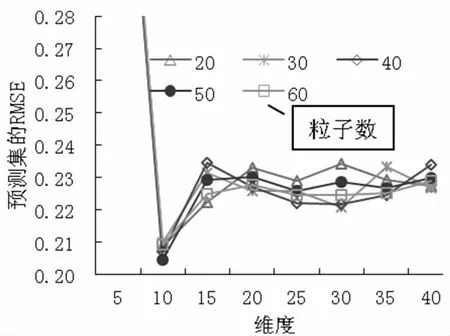
圖3 SNV 預處理時模型的預測RMSE

表2 降維10、不同粒子數時模型的運行結果
(3) SNV+SG 預處理時,SG 選取平滑點數為7,多項式次數為3。PCA 各維度時模型的預測RMSE 及各維度時PSO 算法設置不同粒子數時的預測RMSE如圖4 所示。從圖4 中可以得出,當10 維度特征提取時,粒子個數設置為50 時預測集的RMSE 最小,不同粒子數時的訓練集和預測集的運行結果,如表3 所示,其中粒子個數50 時訓練集的RMSE 為0.1681,R2為0.9617,預測集的RMSE 為0.2047,R2為0.8850,RPD 為3.0466>2,預測模型具有很好的預測效果。
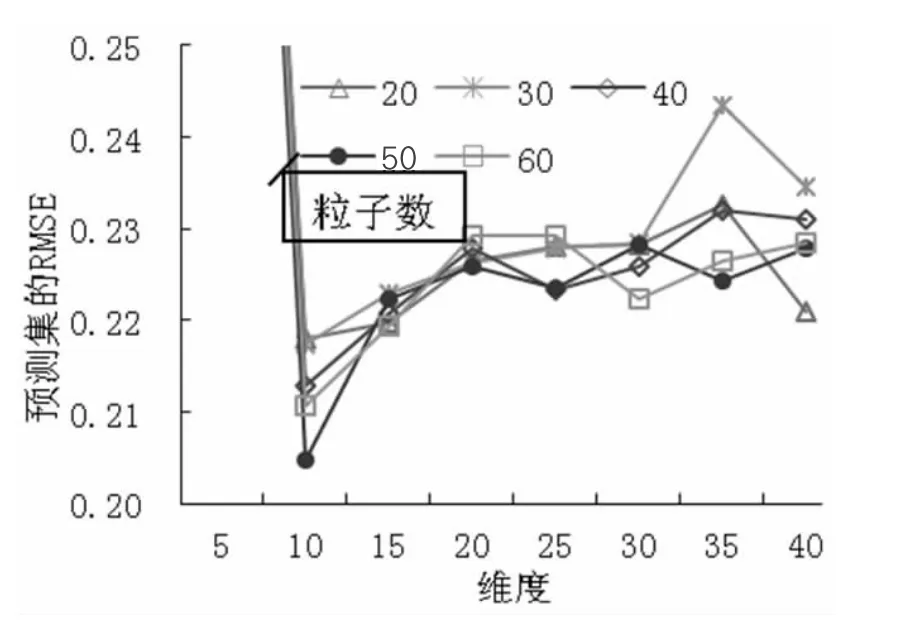
圖4 SNV+SG 預處理時模型的預測RMSE

表3 降維10、不同粒子數時模型的運行結果
(4) MSC 預處理時,PCA 各維度時模型的預測RMSE 及各維度時PSO 算法設置不同粒子數時的預測RMSE 如圖5 所示。從圖5 中可以得出,當10 維度特征提取時,各粒子數設置時預測集的RMSE 幾乎相等,不同粒子數時的訓練集和預測集的運行結果,如表4 所示,其中粒子個數50 時訓練集的RMSE 為0.1754,R2為0.9583,預測集的RMSE 為0.2037,R2為0.8861,RPD 為3.0611>2,預測模型具有很好的預測效果。
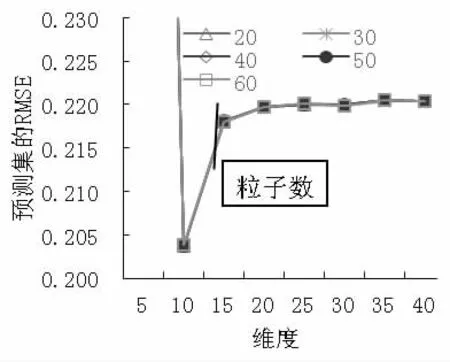
圖5 MSC 預處理時模型的預測RMSE
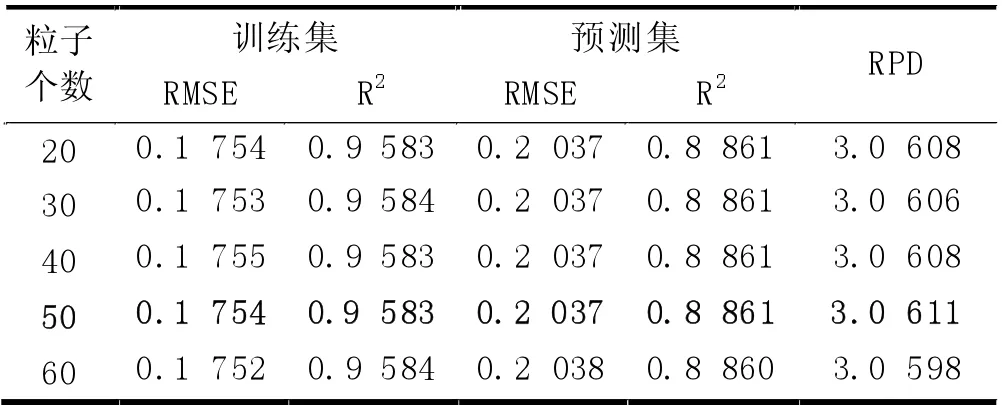
表4 降維10、不同粒子數時模型的運行結果
(5) MSC+SNV 預處理時,PCA 各維度時模型的預測RMSE 及各維度時PSO 算法設置不同粒子數時的預測RMSE 如圖6 所示。從圖6 中可以得出,當10維度特征提取時,各粒子數設置時預測集的RMSE 幾乎相等,不同粒子數時的訓練集和預測集的運行結果,如表5 所示,其中粒子個數60 時訓練集的RMSE為0.1754,R2為0.9583,預測集的RMSE 為0.2036,R2為0.8863,RPD 為3.0631>2,預測模型具有很好的預測效果。
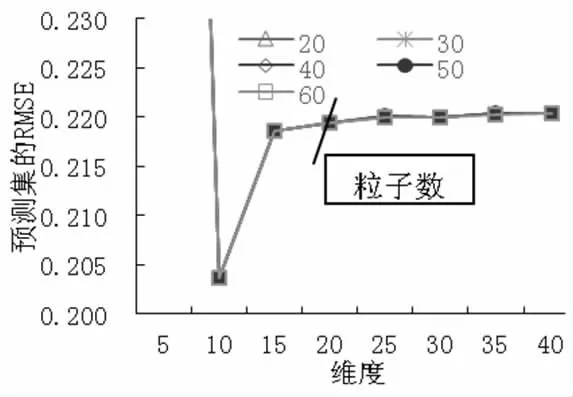
圖6 MSC+SNV 預處理時模型的預測RMSE
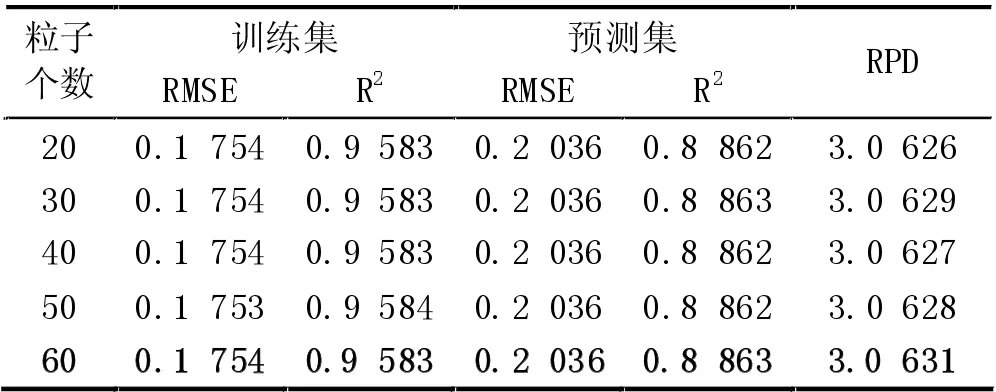
表5 降維10、不同粒子數時模型的運行結果
(6) FD 預處理時,PCA 各維度時模型的預測RMSE 及各維度時PSO 算法設置不同粒子數時的預測RMSE 如圖7 所示。從圖7 中可以得出,當10 維度特征提取時,各粒子數設置時預測集的RMSE 幾乎相等,不同粒子數時的訓練集和預測集的運行結果,如表6 所示,其中粒子數60 時訓練集的RMSE 為0.6470,R2為0.4393,預測集的RMSE 為0.4014,R2為0.5095,RPD 為1.4747。預測模型具有一定的預測效果,但是預測精度和模型的穩定性相對不高。

圖7 FD 預處理時模型的預測RMSE
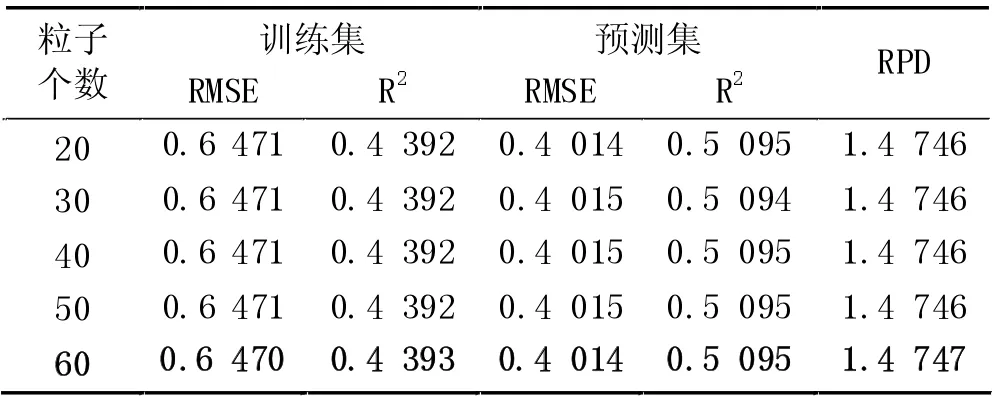
表6 降維10、不同粒子數時模型的運行結果
(7) MSC+SNV+FD 預處理時,PCA 各維度時模型的預測RMSE 及各維度時PSO 算法設置不同粒子數時的預測RMSE 如圖8 所示。從圖8 中可以得出,當45 維度特征提取時,有最小的預測RMSE,不同粒子數時的訓練集和預測集的運行結果,如表7 所示,其中粒子數40 時訓練集的RMSE 為0.2329,R2為0.9261,預測集的RMSE 為0.2718,R2為0.7625,RPD為2.1196。預測模型的預測效果良好,但是預測模型的預測精度和模型的穩定性相對不高。
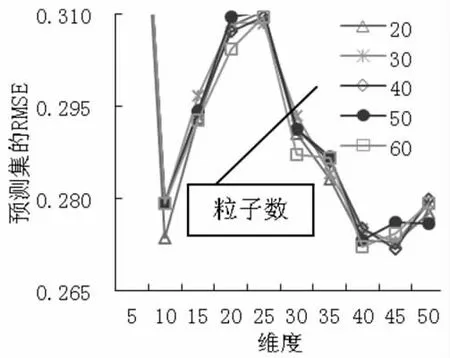
圖8 MSC+SNV+FD 預處理時模型的預測RMSE
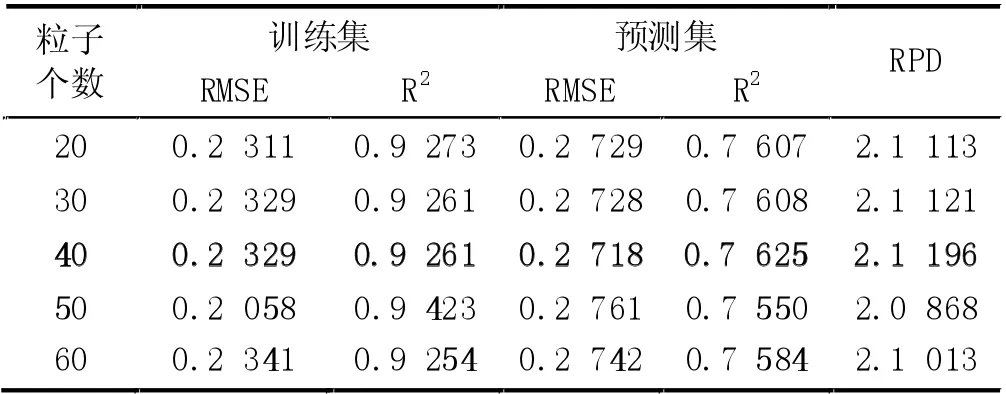
表7 降維45、不同粒子數時模型的運行結果
4 結論
本文基于玉米光譜數據,結合粒子群優化算法,優化支持向量回歸模型中的參數C 和gamma,建立了一個用于玉米淀粉含量預測的預測模型。實驗對比不同預處理和PSO 算法中設置不同粒子數時的預測效果,從實驗結果得出結論如下。
(1) 預處理方法中,選擇SNV,SNV+SG、MSC、MSC+SNV、MSC+SNV+FD 的預處理后建立的模型的預測效果均高于未進行預處理,即使用源數據時建立的預測模型的預測效果;而基于FD 的預處理方法建立的預測模型不理想,這也就說明針對本文的光譜數據,選用合適的預處理方法有助于提升模型的預測精度。
(2) 使用PSO 進行SVR 建模的參數優化時,不同的粒子個數設置影響模型的預測效果。進行MSC和MSC+SNV 預處理時的模型預測結果優于預處理是SNV、SNV+SG 和MSC+SNV+FD 時的預測結果。其中MSC+SNV 預處理時,PCA 主成分10 時,PSO 的粒子數為60 時,預測模型最優。
因此,針對玉米近紅外光譜數據集,文中提出的PSO 優化SVR 的建模方法能夠有效的預測玉米淀粉含量。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
少先隊活動(2021年4期)2021-07-23 01:46:22
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
攝影之友(影像視覺)(2019年3期)2019-03-30 01:36:50
光學精密工程(2016年6期)2016-11-07 09:07:19
沈陽醫學院學報(2015年1期)2015-12-27 13:44:40
醫學教育管理(2015年3期)2015-12-01 06:43:16
核科學與工程(2015年4期)2015-09-26 11:59:03
中國艦船研究(2014年5期)2014-05-14 06:43:09
