屬性網絡表示學習研究綜述
2022-10-31 08:17:26
山東科技大學學報(自然科學版) 2022年5期
(山東科技大學 計算機科學與工程學院,山東 青島 266590)
隨著互聯網、物聯網、移動互聯網的迅速發展,網絡數據資源呈現爆炸式增長。以微博、微信、Twitter、Facebook等為代表的社會化媒體,具有信息實時性、信息開放性、內容全面性、用戶自由性、信息傳播范圍廣、信息傳播速度快等諸多優點,滿足了人們對于信息多樣化和溝通個性化的需求,已經成為人們日常交流的重要平臺,提供了大量數據資源。社交網絡分析與挖掘成為近年來的熱門研究課題,包括社區發現[1-2]、鏈接預測[3-4]、節點分類[5-6]、推薦[7-8]等技術。
由于網絡數據中的節點不是孤立存在的,相互之間存在關聯,因此難以并行化、分布式處理,直接對原始網絡進行分析與挖掘往往具有很高的計算代價,導致網絡分析的效率極低。一種有效的解決思路是,將原始網絡無損或最小損失地轉化到向量空間進行處理。由此,網絡表示學習應運而生。
網絡表示學習,旨在將原始網絡中的節點表示成低維的稠密向量,同時最大程度地保留節點在原網絡中的信息和屬性。DeepWalk算法[9]充分利用網絡的結構信息,利用截斷隨機游走和神經語言模型獲得節點的表示。Tang等[10]認為僅考慮節點之間的一階近似會丟失許多有用的信息,從節點擁有相同鄰居的數量出發,進一步考慮了二階近似,來保存網絡的局部結構和全局結構。Cao等[11]考慮了更高階的網絡結構信息,通過奇異值分解分別學習節點的k階表示,再將這些表示拼接起來作為節點最終的向量表示。上述算法保留了網絡中拓撲結構的特征,但只從拓撲結構的角度對網絡進行表示學習,無法獲得高質量的節點表示,導致在后續任務上表現不佳。
在實際應用中,越來越多的節點屬性信息被記錄。如在微博中,每個用戶除了擁有自己相對穩定的屬性(性別、年齡、血型、星座等)之外,在平臺上的一些社交行為,如發表博客、轉發、評論等,也產生了大量的文本信息,這些文本信息也可以建模成用戶的屬性。在微信平臺中,既包括好友關系,也包括個人的特征和朋友圈信息,這些都是用戶屬性的重要體現。此外,引文網絡中論文的摘要信息、互聯網中網頁內容的關鍵詞、維基百科中每個詞條所對應的文本描述等也是可用的屬性信息。這些都是屬性網絡模型的典型代表。因此,屬性網絡已經被廣泛應用于社交網絡、學術網絡、信息系統的建模。
屬性網絡表示學習旨在將網絡中節點的屬性信息以及拓撲結構信息,同時映射成聯合的低維向量。屬性網絡的普適性和靈活性,使得屬性網絡表示學習具有重要的研究意義和應用價值。首先,結合屬性信息進行網絡表示學習,能夠進一步提升模型在網絡分析任務上的性能。其次,融合屬性信息在某種程度上為節點之間的關系提供一種額外的相似度信息輔助。最后,與異質信息網絡相比,屬性網絡表示學習的信息融合程度更高、普適性更強。
本研究對現有的屬性網絡表示學習算法進行分類,如圖1所示。首先將屬性網絡表示學習劃分為靜態屬性網絡表示學習和動態屬性網絡表示學習,然后按照網絡的類型將靜態屬性網絡表示學習劃分為同構屬性網絡表示學習和異構屬性網絡表示學習。在此基礎上,根據算法的核心技術,進一步分為基于矩陣分解的方法、基于神經網絡的方法、基于自編碼器的方法、基于隨機游走的方法和其他方法。
1 相關定義
定義1屬性網絡[12]。給定屬性網絡G=(V,E,X),其中V表示屬性網絡中節點的集合,E表示屬性網絡中邊的集合,X表示網絡中的屬性信息。


定義4同構屬性網絡[14-15]。給定同構屬性網絡G=(V,E,X),其中X是所有節點特征組成的特征矩陣;存在節點類型映射函數φ:V→P,其中P包含所有節點的類型;邊關系映射函數φ:E→K,其中K包含所有邊的鏈接關系;若|P|=1并且|K|=1,則是同構屬性網絡。如圖2所示,社交網絡即為同構屬性網絡,該網絡中只存在一種類型的節點,節點之間邊的鏈接關系也是單一的。
定義5異構屬性網絡[14-15]。給定異構屬性網絡G=(V,E,X),其中X表示異構屬性網絡的屬性信息,存在節點類型映射函數φ:V→O以及邊關系映射函數φ:E→R,網絡中的每個節點vi∈V和每條邊ei∈E能夠通過映射函數φ和φ找到對應的節點類型oi∈O和邊關系ri∈R;若|O|<1或者|R|>1,則是異構屬性網絡。如圖3所示,電子商務網絡即為異構屬性網絡,該網絡中存在用戶和商品這兩種類型的節點,用戶節點與商品節點之間存在購買、收藏以及添加到購物車等鏈接關系。

圖1 屬性網絡表示學習方法分類Fig. 1 Classification of attributed network representation learning methods

圖2 社交網絡示例Fig. 2 An example of social networking

圖3 電子商務網絡示例Fig. 3 An example of electronic commerce network
問題定義屬性網絡表示學習[12,16]。給定屬性網絡,屬性網絡表示學習的目的是學習節點或邊的向量表示。表1給出了論文中主要的符號及其解釋。
2 靜態屬性網絡表示學習
靜態屬性網絡表示學習可分為同構屬性網絡表示學習和異構屬性網絡表示學習,根據使用的技術,如矩陣分解、自編碼器、神經網絡、隨機游走等,將代表性算法作如下劃分。

表1 論文中的常用符號Tab. 1 Notations used in this paper
2.1 同構屬性網絡表示學習
1) 基于矩陣分解的方法
傳統的網絡表示學習方法缺乏對網絡結構信息和屬性信息的融合,使學習到的向量表示在后續任務上表現不佳。因此,一些算法嘗試結合屬性信息,如文本信息、標簽信息等,來學習節點的表示。如TADW(text-associated DeepWalk)算法[17]基于矩陣分解的思想將節點的文本特征融合到網絡表示學習中,首先證明DeepWalk[9]是一種矩陣分解,將矩陣M分解為矩陣W與H的乘積;然后TADW在此基礎上將節點的文本特征引入到矩陣分解過程中,如圖4所示,將矩陣M分解為W、H和T三部分的乘積,其中T表示節點的文本特征,相對應的損失函數如式(1)所示,該算法交替優化W和H矩陣以最小化損失函數。
(1)

圖4 TADW算法的主要思想[17]Fig. 4 Main idea of TADW algorithm
AANE(accelerated attributed network embedding)算法[18]將上述矩陣分解的過程進行分布式處理,以提升表示學習的效率。但該算法僅適用于處理網絡中的文本屬性,不能利用節點的標簽信息,學得的表示向量缺少區分能力。Tu等[19]基于最大間隔思想優化了DeepWalk算法,將節點的標簽信息加入到節點的表示學習過程中,并設計了半監督的網絡表示學習模型MMDW(max-margin DeepWalk)。MMDW首先將DeepWalk轉化為矩陣分解的形式,即M=XTY,其中X是節點的向量表示矩陣,Y是節點的內容表示矩陣,然后利用SVM[20]訓練向量表示X,并且在分類過程中引入Biased Gradient,使向量表示朝著準確的預測方向更新,以此提高節點表示的區分能力。
2) 基于神經網絡的方法
圖卷積網絡主要包括基于譜域上的圖卷積和基于空間域上的圖卷積。基于譜域上的圖卷積網絡算法主要利用傅立葉變換將圖數據變換到譜域上進行圖卷積,GCN(graph convolutional network)[21]為此類方法中的代表性算法,如圖5所示。多層圖卷積網絡通過輸入層、隱藏層以及輸出層學習特征向量,但該算法需要花費較多計算成本。基于空間域上的圖卷積網絡算法是直接對圖數據進行圖卷積,此類方法中的代表性算法有GraphSAGE(graph sample and aggregate)[22],該算法通過訓練一組聚合函數,從節點局部鄰域中聚合特征信息,經過訓練后能夠為新加入網絡的節點生成嵌入。GAT(graph attention networks)算法[23]在此基礎上結合注意力機制為相同鄰域內的節點分配不同的權重系數,且不需要事先了解整個圖結構,解決了以往基于譜方法的理論問題。

圖5 多層圖卷積網絡(GCN)[21]Fig. 5 Multi-layer graph convolutional network(GCN)
3) 基于自編碼器的方法
MMDW算法主要利用節點的標簽信息,忽略了邊上的標簽信息。Tu等[24]提出TransNet算法,該算法基于邊上的標簽信息學習節點的表示,將邊上的多個標簽形式化地表示為節點之間的關系。該算法利用深度自編碼器以及轉換機制[25-26]對節點之間進行交互建模,在社會關系網絡中驗證了模型提取節點之間關系的強大能力。GAE(graph auto-encoder)與VGAE(variational graph auto-encoder)算法[27]利用GCN[21]構建編碼器來學習節點的向量表示,通過解碼器重構圖結構數據,學得的向量表示融合了結構信息與屬性信息,在后續的鏈接預測任務中表現出色。兩者學習網絡的方法稍有不同,GAE結合自編碼器對網絡進行表示學習,而VGAE為變分自編碼器[28-29]。
不同于GAE和VGAE僅重構圖結構,Salehi等[30]提出的GATE算法重構圖結構以及節點屬性,基于自編碼器和自注意力機制[23]學習節點的嵌入,能夠應用于直推式以及歸納式學習。Pan等[31]提出ARGA(adversarially regularized graph autoencoder)和ARVGA(adversarially regularized variational graph autoencoder)算法,利用編碼器和生成對抗網絡[32]來學習節點的向量表示,這兩個算法對節點的屬性信息和結構信息進行編碼,并且通過生成訓練模塊使節點的表示更具有魯棒性。ARGA與ARVGA的區別在于,前者使用圖自編碼器[26],后者采用變分圖自編碼器[26]。在下游任務性能中,兩者在不同數據集上的應用效果差距不明顯。
4) 基于隨機游走的方法
現有的嵌入方法大多忽略了將節點的屬性信息編碼到表示學習過程中,Li等[33]為解決此問題提出PPNE算法,該算法將網絡拓撲結構和節點的屬性信息融合到網絡嵌入過程中,共同優化屬性驅動目標函數和結構驅動目標函數學得節點的向量表示。與上述方法不同,Pan等[34]提出的TriDNR方法將節點的結構、內容和標簽信息融合到節點的向量表示中,將網絡中的關系劃分為“節點-節點”“節點-內容”和“標簽-相關內容”,該算法對這三種關系分別建模來學習節點的表示。
標簽信息有時不易獲取,Wang等[35]提出了無監督的稀疏屬性網絡嵌入算法SANE(sparse attributed network embedding),該算法利用截斷隨機游走產生節點序列,對節點和屬性之間的關系進行建模,借助CBOW(continuous bag of words)[25,36]和注意力機制[37-38]學習節點的向量表示。Guo等[39]認為現有的大部分算法都是直推式,并且未同時考慮局部和全局的結構信息,基于RPR(rooted page rank)[40]提出了SPINE(structural identity preserved inductive network embedding)算法以解決該問題,該算法通過合并網絡的結構和內容信息學習節點的嵌入,并且利用Skip-Gram 負采樣方法和正采樣策略增強節點間的結構相似性,在節點分類任務上表現出色。
5) 其他方法
現有的聚合器忽略了節點之間的交互,Zhu等[41]提出了BGNN(bilinear graph neural network)算法以解決此問題。該算法結合FM(factorization machines)方法[42-43]編碼節點之間的交互,實現增強傳統的線性聚合器的目的。Cheng等[44]提出了AFN(adaptive factorization network)算法,該算法的主要思想是將特征嵌入轉換為對數空間,并且將特征組合中每個特征的冪作為要學習的系數,在模型訓練過程中逐漸優化此系數,從而實現從數據中自適應學習任意階特征交互。Xu等[45]提出了圖推理學習算法GIL(graph inference learning),該算法同時考慮節點屬性、節點間路徑和圖拓撲結構來構建結構關系,從已標記的節點中推斷未標記節點的標簽,提高了半監督節點分類的性能。
對同構屬性網絡學習算法,在核心技術、數據集、時間復雜度、評測任務等方面進行對比,如表2所示。

表2 同構屬性網絡學習算法對比Tab. 2 Comparison of learning algorithms for attributed homogeneous networks
2.2 異構屬性網絡表示學習
1) 基于矩陣分解的方法
維基百科是著名的異構網絡數據來源之一,在以前的語義分析大多局限于單一類型的關系。Zhao等[50]基于此問題提出坐標矩陣分解(coordinate matrix factorization,CMF)算法,該算法認為維基實體之間存在“實體-實體”“類別-實體”和“詞-實體”三種關系,在語義空間學習實體、詞與類別的表示,通過矩陣分解實體與實體的系數矩陣X、類別-實體系數矩陣Y和詞-實體系數矩陣Z獲得向量表示,如圖6所示。

圖6 CMF算法的主要思想[50]Fig. 6 Main idea of CMF algorithm
2) 基于神經網絡的方法
異構網絡中的內容信息和關系信息是非常重要的,HNE(heterogeneous network embedding)算法[51]將異構內容和關系融合到表示學習過程中。以文本-圖片異構網絡為例,HNE將網絡中的鏈接關系劃分為“圖片-圖片”“文本-文本”和“圖片-文本”三種關系,然后對其進行相似性建模,該算法捕獲了異構組件之間的復雜交互。Zhang等[52]指出很少有算法能同時有效地考慮異構結構信息和節點的異構內容信息,為此提出HetGNN(heterogeneous graph neural network)算法以同時捕獲結構異質性和非結構化內容異質性。該算法首先基于重啟隨機游走的方法來采樣節點的鄰居序列,然后結合神經網絡編碼節點的異構內容,最后引入注意力機制[23]來學習不同類型的鄰居對節點表示的影響。
3) 基于自編碼器的方法
Liu等[53]提出一種歸納式網絡表示學習模型,利用神經網絡將節點的屬性信息、不同類型的節點信息和邊的信息融合到表示學習過程中。該算法可嵌入以前未看到的節點或孤立節點,且不需要額外的訓練。為了解決基于查詢的數據集推薦問題,HVGAE(heterogeneous variational graph autoencoder)算法[54]結合變分圖自編碼器[27]學習論文和數據集的表示,在此基礎上根據所查詢的論文與數據集之間的相關性將前若干個相關數據集進行推薦。
4) 其他方法
Li等[55]針對異構屬性信息網絡的半監督聚類問題提出SCHAIN(semi-supervised clustering in heterogeneous attributed information networks)算法,該算法結合屬性的相似性和基于鏈接的相似性實現半監督聚類,其中利用必須鏈接集和不可鏈接集作為監督約束以促進聚類效果。Zhang等[56]認為元圖是捕獲異質網絡中的豐富語義以及潛在關系的強大工具,但現有方法沒有充分利用元圖,所以設計了mg2vec算法以解決此問題,該算法融合一階以及二階元圖嵌入以獲得最終的節點嵌入。
針對不同的評測任務,對異構屬性網絡表示學習算法的核心技術、評價指標以及性能等方面進行對比,如表3所示。

表3 異構屬性網絡學習算法對比Tab. 3 Comparison of learning algorithms for attributed heterogeneous networks
3 動態屬性網絡表示學習
盡管動態屬性網絡在生活中的應用非常廣泛,但是相關研究比較少。DANE(dynamic attributed network embedding)算法[58]是基于動態屬性網絡表示學習的方法,將模型分成離線模型和線上模型兩部分,其中離線模型能夠學習節點在時刻t的嵌入,線上模型基于矩陣攝動理論[59]更新節點的嵌入。但該算法不能應用到大規模網絡場景中,否則時間復雜度會很高。Liu等[60]提出適合大規模屬性網絡表示學習的DRLAN(dynamic representation learning framework for large-scale attributed networks)算法,能捕捉網絡中高層非線性并保存拓撲結構和節點屬性的高階相似度。
現有的鏈路預測算法絕大多數都是為靜態網絡設計的,忽略了網絡的動態變化。為此,Li等[61]提出SLIDE(streaming link prediction for dynamic attributed networks)算法,能有效地研究網絡的結構和節點屬性的動態變化對鏈接預測的影響。不同于傳統的時序鏈接預測技術忽略了動態網絡中潛在的非線性特性以及鏈接權重,Lei等[62]提出GCN-GAN(GCN-generative adversarial network)算法,將動態圖定義為一系列的圖快照,然后利用GCN提取每張圖快照的結構特征,并且采用LSTM[63]捕捉動態圖中的演變模式,利用全連接層預測下一個時間切片的拓撲結構,最后訓練鑒別器以判斷輸入的數據是否是真實數據,從而使預測的帶有權重的鏈接更有代表性。
超圖保存了高階結構的信息,廣泛應用在分類、檢索等任務上。Zhang等[64]提出基于動態環境的DHSL算法,從標簽空間以及特征空間更新超圖結構。但是該算法僅在初始特征嵌入時更新超圖結構,忽略了特征之間的高階關系。為解決此問題,Jiang等[65]設計了DHGNN(dynamic hypergraph neural networks)算法,該算法利用K-NN(K-nerual neighbor)方法以及K-means聚類方法基于全局和局部的特征更新超圖結構,并結合自注意力機制聚合鄰接超邊的特征。
針對不同的評測任務,對動態屬性網絡表示學習算法的核心技術、評價指標以及性能等方面進行對比,如表4所示。
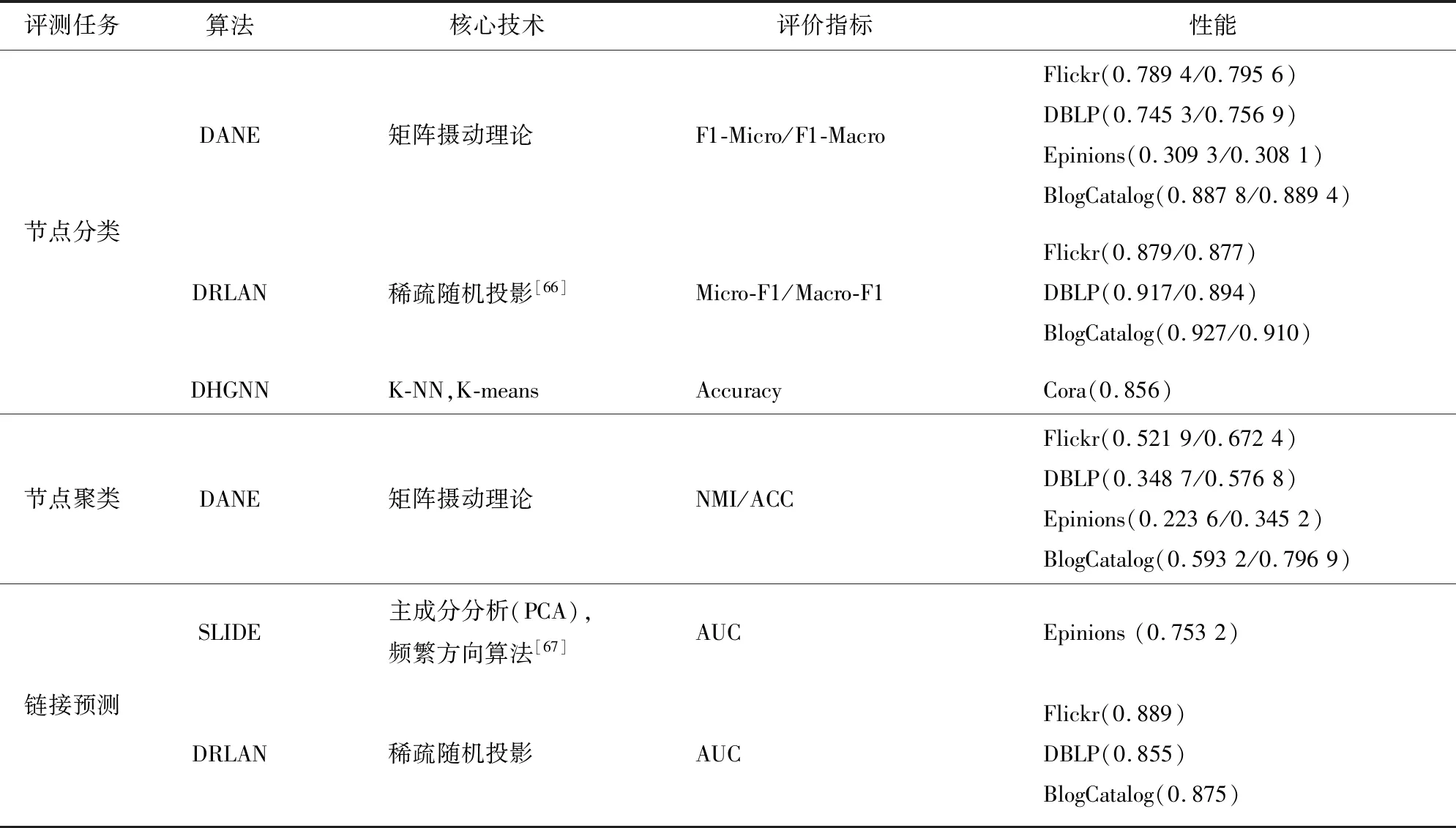
表4 動態屬性網絡學習算法對比Tab. 4 Comparison of learning algorithms for attributed dynamic networks
4 總結與展望
綜上所述,國內外學者已經在屬性網絡表示學習方面取得諸多研究成果,促進了該領域的發展,但仍存在一些工作需進一步研究。
1) 屬性信息的分析視角可以更加廣泛化、立體化,如屬性類型的多樣化、屬性信息的完整性、屬性信息的部分缺失性、屬性的隱含關系等;
2) 如何將多種類型的屬性信息,如文本內容、類別標簽、個體特征等,更好地與拓撲信息進行有機融合;
3) 在學習表示向量時如何更好地利用屬性網絡中的局部與全局特征等。
這些研究將有助于提高屬性網絡表示學習的信息融合度,增強其表達能力,改善自學習能力,提高任務感知的應用能力以及魯棒性等。
猜你喜歡
兒童故事畫報(2019年5期)2019-05-26 14:26:14
中華手工(2017年2期)2017-06-06 23:00:31
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
中外會展(2014年4期)2014-11-27 07:46:46
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
祝您健康(1987年2期)1987-12-30 09:52:28
