基于Go 實現的分布式主鍵系統研究
2022-11-03 03:19:00河南理工大學計算機學院河南焦作454000
無線互聯科技 2022年15期
(河南理工大學 計算機學院,河南 焦作 454000)
秦攀科,李有卿*
0 引言
單機時代,一個數據庫就可以滿足業務的需要,數據庫的主鍵選擇很簡單,直接借助數據庫的自增主鍵就可以實現,其他類型復雜的主鍵,在單進程服務中也可以很簡單地實現。 但是,隨著系統規模的擴大,越來越多的公司開始使用微服務架構,這時就面臨著數據庫主鍵一致性的問題。 傳統來說,UUID 是可以解決分布式主鍵問題的[1-2],但是大多數公司都采用MySQL數據庫[3],而UUID 的無序和跳躍會導致數據庫的性能急劇下降,并且UUID 長度很長,因此采用UUID 是不可取的。 雪花算法在時間范圍內基本有序,同時也可以保障多進程下不會出現主鍵重復,但是也有可能生成重復的主鍵,而且生成的主鍵長度也較長,在前端展示的時候會精度丟失,需要后端額外轉化為字符串。越來越多的系統需要定制有一定特殊格式和規則的主鍵,開發人員需要去實現特定要求的主鍵,這會讓業務參與到分布式主鍵的開發,造成人力資源浪費。 所有的這一系統問題都急需解決,因此,分布式主鍵系統應運而生,可以支持多種分布式主鍵生成規則,通過Grpc方式的遠程過程調用提供多種語言的SDK 支持[4-5],不僅方便,而且RPC 可以讓系統性能得到提升[6]。 內部通過Namespace 做系統空間隔離,不同種類的主鍵通過主鍵類型做區分。 此系統上線后,所有業務系統都可以直接調用該系統提供的SDK,集成分布式主鍵。
1 分布式主鍵介紹
1.1 雪花算法
目前,最主流的分布式主鍵生成算法是基于雪花算法的,其結構如圖1 所示。
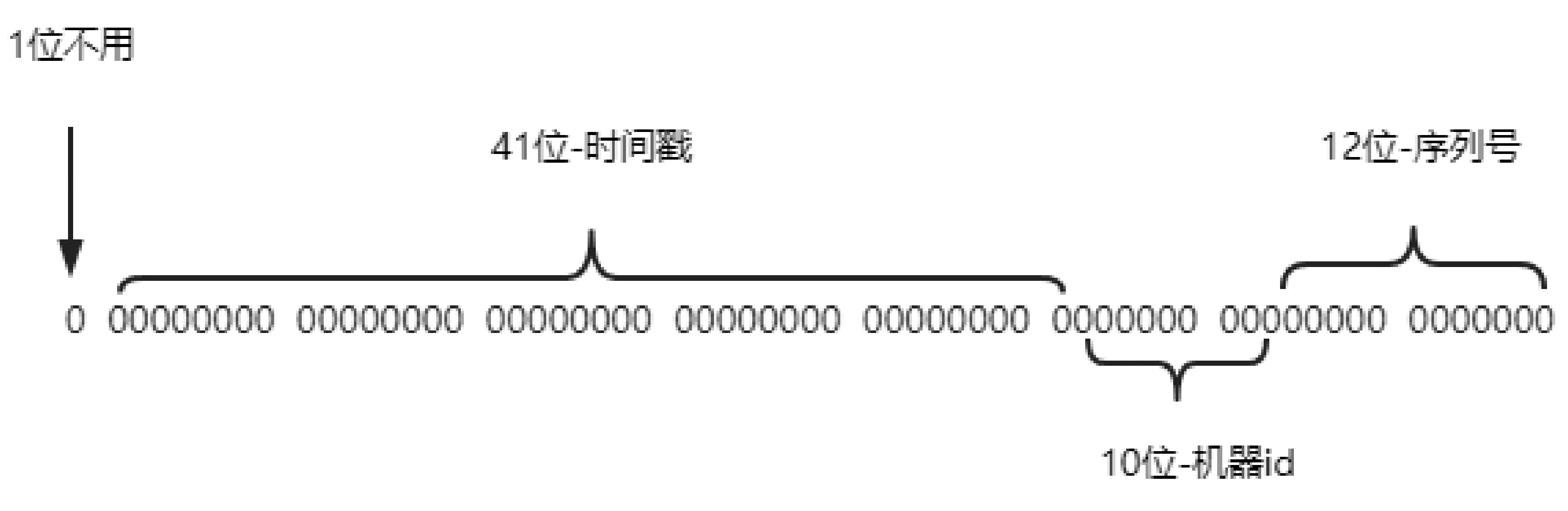
圖1 雪花算法的結構
可以看到,雪花算法是由64 個二進制數組成。 其中,第一位是符號位,其值永遠為0;接著是41 個二進制位表示時間,精確到毫秒值;然后是10 個二進制位表示機器標識;最后是12 個二進制位標識某一毫秒能產生的唯一主鍵個數,即2 的12 次方,4 096 個數字。基于雪花算法的結構,可以保證:(1)所有生成的id 按時間趨勢遞增;(2)因為機器標識的隔離,整個分布式系統不會產生重復的id。
雪花算法存在的問題:(1)機器標識只有10 個二進制位,也即最多只支持1 024 個服務使用,現在的大型系統服務節點可能遠遠不止1 024 個。 (2)要保證1 024 個節點分配到的機器標識都是唯一的。 (3)時鐘回撥問題。 當時鐘回撥,會產生重復的主鍵,這是難以接受的。 (4)雪花算法的機器id 的分配問題。 當機器多起來,需要仔細考慮保證每臺機器能分到唯一的機器標識。
1.2 基于Redis 的分布式主鍵
有一種分布式主鍵的實現方式是基于Redis 的[7],Redis 的自增命令可以很好地提供自增主鍵,但特別依賴Redis,也不是完美的實現方式。 若Redis 宕機,又沒有開啟持久化,會導致主鍵出現重復,對Redis 的性能造成影響,同時,易于他人通過主鍵推測系統規模。 所以,沒有特殊需求定制全局自增的主鍵,不建議使用這種方式。但在某些特殊場景中,Redis 自增主鍵有著很大效果。 此外,通過Redis 的過期機制,也可以很好地模擬出定期自增主鍵,這種類型的主鍵在很多場景都有著廣泛的應用。Redis 在緩存和分布式協調方面也有著廣泛的應用[8],已經成為開發領域內不可或缺的基礎組件。
1.3 基于MySQL 的號段模式主鍵
有一種分布式主鍵的生成方式是通過MySQL 數據庫的號段模式[9],向數據庫申請取得一段范圍數據的使用權,其他節點將不再使用這段范圍數據,以此保證數據的唯一[10]。 分配號段時,需要分布式鎖保證分配范圍不會出現多分配的問題。 號段模式的問題在于如何決定號段范圍的大小,分配太大,服務重啟會導致范圍失效,浪費一定數量的范圍;太少,容易頻繁觸發分布式鎖,并頻繁觸發數據庫操作,影響性能。 當然,號段的優點也很明顯,主鍵可以從0 開始,生成的主鍵比較短[11],對于前端展示比較友好,也可以彌補雪花算法主鍵長的缺點。
1.4 Go 語言介紹
Go 語言可以直接編譯成機器碼[12],不依賴其他庫,部署方便,屬于靜態語言。 在語言層面就支持并發,是Go 最大的特色,可以充分利用多核的優勢。 Go內置Runtime,支持垃圾回收,而且簡單易學,只有25個關鍵字,但是表達能力非常強大,幾乎支持了大多數面向對象語言的特性:繼承、重載、對象等[13]。 基于Go強大的能力,其廣泛應用于區塊鏈開發、物聯網開發以及云原生基礎服務支撐,K8s,Docker,Etcd 等都是基于Go 語言開發的,可見Go 語言的發展前景極好。 考慮到Go 語言兼顧高性能和開發效率,貼近K8s,可以很方便地使用K8s 進行部署,因此使用Go 語言開發一個分布式主鍵系統[14]。
2 搭建分布式主鍵系統
2.1 分布式主鍵系統總體設計
搭建分布式主鍵系統可以解決以下問題:(1)統一分布式主鍵服務[15],通過Rpc 的方式去使用分布式主鍵,方便業務端的開發。 (2)優化雪花算法的缺點,包括時間回撥、機器id 分配以及上限問題。 (3)可以同時滿足多種分布式主鍵的實現,方便地擴展業務端的需求,只需直接調用即可。
分布式主鍵系統核心整體調用如圖2 所示,分布式主鍵系統可以讓業務系統直接接入,然后,就可以直接使用各種類型的分布式主鍵。 非常顯著地減輕了業務端的壓力。 同時,業務端調用分布式主鍵系統通過Grpc 的方式,這就保證了調用的實時性。 業務端調用分布式主鍵系統如圖3 所示,通過Ingress 的方式路由到分布式主鍵服務集群。
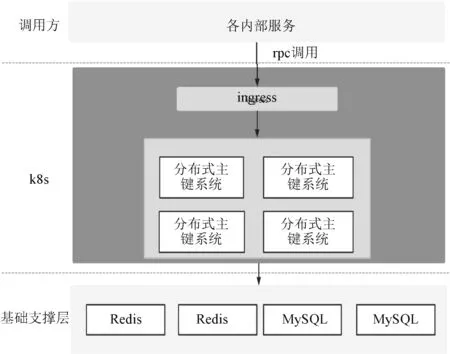
圖2 分布式主鍵系統
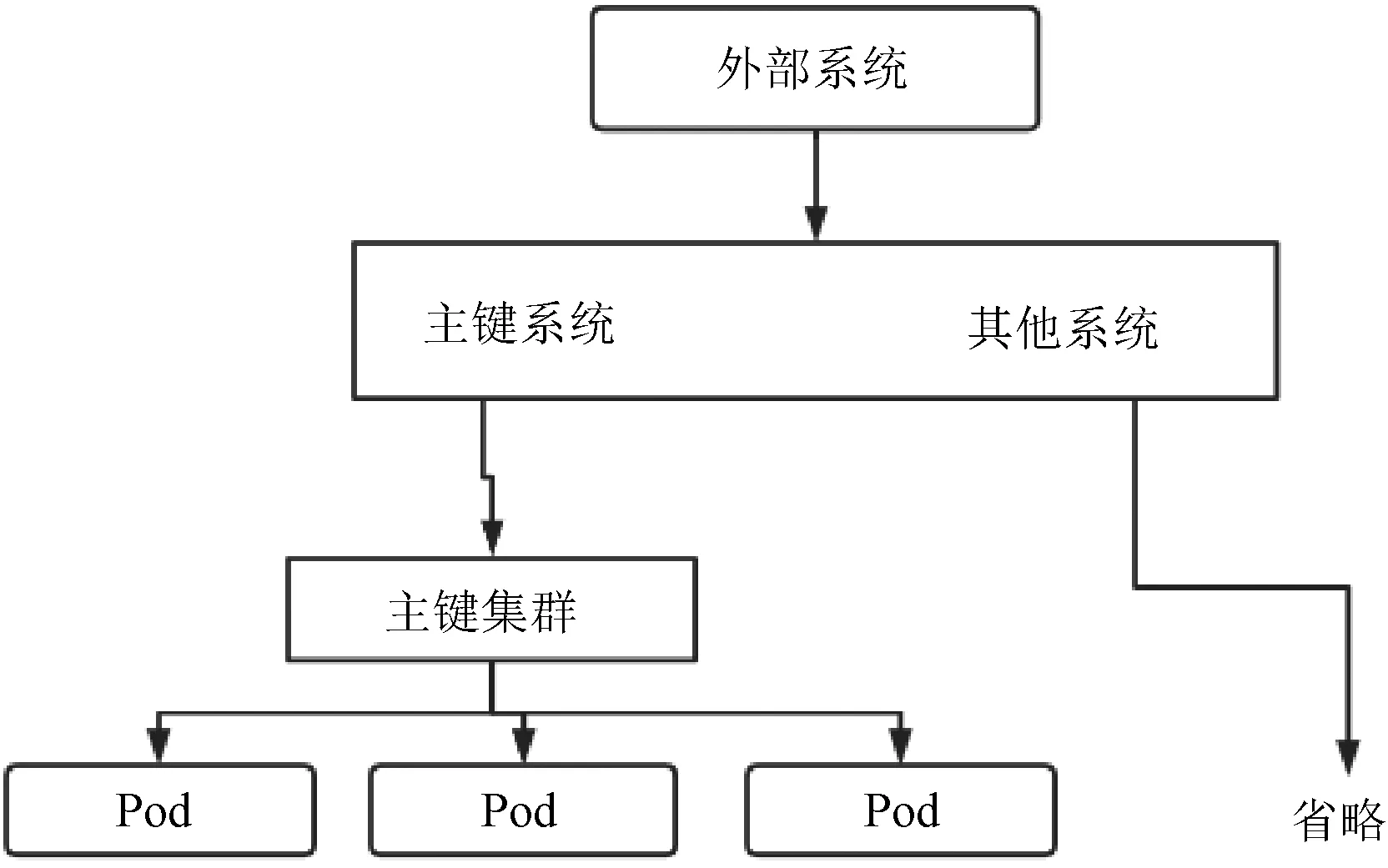
圖3 業務端調用分布式主鍵系統
2.2 Grpc 協議字段設計
該分布式主鍵系統采用Go 語言開發,使用Grpc遠程過程調用,Grpc 是一個高性能開源的統一的RPC調用框架。 RPC 即遠程過程調用,使得應用程序之間可以進行通信,而且也遵從Server/Client 模型。 使用的時候客戶端調用Server 提供的接口就像調用本地的函數一樣。 Grpc 最大的好處就是快和體積小,Grpc 可以通過Protobuf 定義接口,Protobuf 可以將數據序列化為二進制編碼,這可以大幅減少數據量,從而提升傳輸 性能。 Grpc 的通信字段定義如圖4 所示。

圖4 Grpc 的通信字段定義
該Proto 文件提供了接口的請求結構和返回結構,并定義了一個服務,對外提供了獲取主鍵的方法。 該分布式唯一主鍵系統目前對外提供3 種類型的分布式主鍵:(1)基于MySQL 數據庫號段的;(2)基于Redis自增的;(3)基于雪花算法的。
2.3 實現基于MySQL 的號段模式的主鍵
基于MySQL 號段模式實現分布式主鍵是以前許多公司經常采用的方法。 號段可以理解為批量獲取。 比如,開發人員會經常批量獲取多個數據緩存在本地,提升系統效率。 當需要分布式主鍵時,就向數據庫獲取一個號段,如[1,10 000],于是,當需要主鍵時,就可以在這個范圍自增,等用到了10 000,再使用則超過了范圍,此時需要再次向數據庫申請號段。 數據庫的表設計如圖5 所示。

圖5 數據庫的表設計
這個數據表是用來記錄自增步長以及當前自增id的最大值,對于自增邏輯的判斷則是在系統實現中做的。 這種方案不會強依賴數據庫,即使數據庫宕機,系統緩存的號段也可以再使用一段時間。 不過,該分布式主鍵系統是一個集群,集群多個服務會發生同時申請號段的情況。 在這種情況下,就會發生數據一致性的問題,解決辦法有:(1)使用數據庫的樂觀鎖,加一個Version 字段,在修改的時候只有跟以前的Version 一樣才會成功;(2)使用分布式鎖。 本文采用第二種方式。
2.4 實現基于Redis 的自增模式主鍵
這個方式的實現很簡單,通過Redis 的Incr 命令實現。 由于Redis 的單線程特性,天生就支持并發。 但是,這種方式也有著缺點:(1)過于依賴Redis,如果Redis 出了問題,就無法生成主鍵;(2)Redis 需要開啟持久化,要不然Redis 重啟就會導致主鍵重復;(3)性能比較依賴Redis。 所以,基于Redis 的主鍵有著特殊的使用場景。
2.5 實現并優化雪花算法
針對時間回撥問題,改進的思路是:啟動時間采用的是“歷史時間”,每次請求只增加序列值,序列值滿了,然后才把“歷史時間”增加1。 具體做法是,在進程啟動后,把當前時間(實際處理采用了延遲20 ms 啟動)作為這個機器進程的時間戳中的起始時間字段。每次有數據請求時,序列號自增1,當序列號到達最大值,時間戳字段自增1,也就是時間增加1 ms,然后序列號從0 開始計算。 當特別巨大的請求過來時,進程中的時間戳達到真實的當前時間戳,這個時候如果出現時間回撥,就采用業界常用的方式,首次等待,然后等待一會兒回撥時間,時間超過一定量就拋出異常。
針對機器id 分配和回收問題,機器id 一共占了10個二進制位, 也就是最多1 024 個。 其中5 個Workerid,5 個Dataid。 id 的分配通過Redis 實現,核心代碼如圖6 所示。

圖6 核心代碼
其邏輯就是,Redis 存了Workerid 和Dataid,各進程通過分布式鎖的方式去取1 個Workid 和Dataid 聯合唯一的id。
3 結語
通過Go 語言結合Grpc 的方式開發了分布式主鍵系統,支持3 種分布式主鍵,對外提供RPC 遠程調用。這個分布式主鍵服務可以極大地提高開發效率,讓分布式主鍵跟業務開發解耦。 同時也解決了雪花算法存在的幾個缺點,讓雪花算法生成主鍵更加可靠。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
家庭影院技術(2017年9期)2017-09-26 03:41:45
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
