融合文字與標簽的電子病歷命名實體識別①
2022-11-07 09:08:32杜昕娉高延軍馬慧敏
計算機系統應用 2022年10期
趙 奎,杜昕娉,高延軍,馬慧敏
1(中國科學院 沈陽計算技術研究所,沈陽 110168)
2(中國科學院大學,北京 100049)
3(中國醫科大學附屬第四醫院,沈陽 110032)
4(東軟集團股份有限公司 醫療解決方案事業本部,沈陽 110003)
1 引言
醫療電子病歷[1]現今在臨床診斷中被廣泛應用,近幾年伴隨著機器學習、深度學習的快速發展,結構化電子病歷得到了大眾的關注.由于難以將醫生對病癥的描述進行統一,使得結構化醫療術語無法建立.具體來說,對于同一種疾病,不同的醫生在表達方式、中文的繁簡體,英文字母的大小寫上的區別,導致在醫療領域難以形成規范化的標準.
命名實體識別(NER)是自然語言處理(NLP)中信息抽取任務的一種,在NLP 的基礎建設中有著較為廣泛的應用.結構化的電子病歷需要實體的準確描述,不能存在歧義或表述不明.中文由于沒有明確的分隔符,使得實體識別的難度大大增加.就模型訓練而言,使用詞作為最小粒度還是字作為最小粒度會隨著不同的應用場景有不同的效果,難以確定使用哪種方式最好.
就提高命名實體識別的準確率方面,孟捷[2]使用條件隨機場CRF 先對文本進行分詞,之后對分詞結果進行屬性標注,并在詞典中引入ICD-10 標準,使得實體識別取得了較好的效果.江濤[3]提出了一種兼顧字詞并通過自注意力機制延長實體聯系距離的WCLSTM 模型,使用Word2Vec 訓練的100 維詞向量嵌入模型,并與Bi-LSTM 和Lattice-LSTM 模型進行對比.沈宙鋒等人[4]基于XLNet-BiLSTM 模型,通過對電子病歷的序列化表示,使得一詞多義的問題得到了更好的解決.王若佳等人[5]在使用無監督學習的AC 自動機上對中文電子病歷進行分詞,結合條件隨機場和不同的實體類別,得到了較好的識別模板.Zhang 等人[6]為解決中文實體的邊界問題,提出了一種基于單詞方法和基于字符方法進行識別的方式,在研究中,為解決字符缺乏詞級別信息和詞邊界信息,使用了一種融合自匹配詞特征的神經實體識別模型,并在訓練集上取得了不錯的效果.Ji 等人[7]提出一種句子級的基于多神經網絡模型的協同協作方法來進行實體識別,通過Word2Vec、GloVe、ELMo 對特定漢字嵌入預訓練,在BiLSTM-CRF 和CNN 模型上進行了模型測試.李丹等人[8]提出了一種部首感知的識別方法,該方法將部首信息編碼到字向量中,利用BiLSTM-CRF 結合Bert 模型,使實體識別有一定的提高.
在過去的研究中,大部分研究人員著重在于對文字進行處理,而對標簽在文本的上下文中的作用以及文本的預處理結果是否符合規范缺少關注.查閱資料中考慮到,如果可以在研究文字的同時挖掘電子病歷標簽中的隱含信息,對于命名實體識別工作會有幫助.例如,病歷中常用“宮頸癌”作為疾病術語,那么在宮頸一詞中被預測為疾病的實體,應該以3 個字的可能性較大,不會出現諸如“宮頸的癌”或“宮頸的癌變”這樣的實體,從而提高實體識別的準確性,且多頭注意力機制使得模型在訓練過程中關注模型感興趣的部分,對于模型的訓練有益.基于以上描述,本文以建立結構化電子病歷為目的,從電子病歷的實體識別開始研究,提出WT-MHA-BiLSTM-CRF 模型,該模型同時考慮文字和標簽中的信息.為保證模型的可信性,將實驗結果與BiLSTM-CRF[9],BiGRU-CRF,MHA-BiLSTM-CRF 模型進行了對比.
2 電子病歷數據預處理
2.1 類別定義
人工將實體分類分為以下6 個方面: 病癥,身體部位,手術,藥物,化驗檢驗,影像檢驗.在測試中發現,如果直接以中文作為類別標簽,會導致訓練結果較差,因此本文將上述6 個類別使用英文簡寫代替,病癥的標簽為DISEASE,身體部位的標簽為BODY,手術的標簽為OPERATION,藥物的標簽為MEDICINE,化驗檢驗的標簽為LAB-CHECK,影像檢驗的標簽為IMGCHECK.實驗期望得到的實體識別效果如圖1 所示.
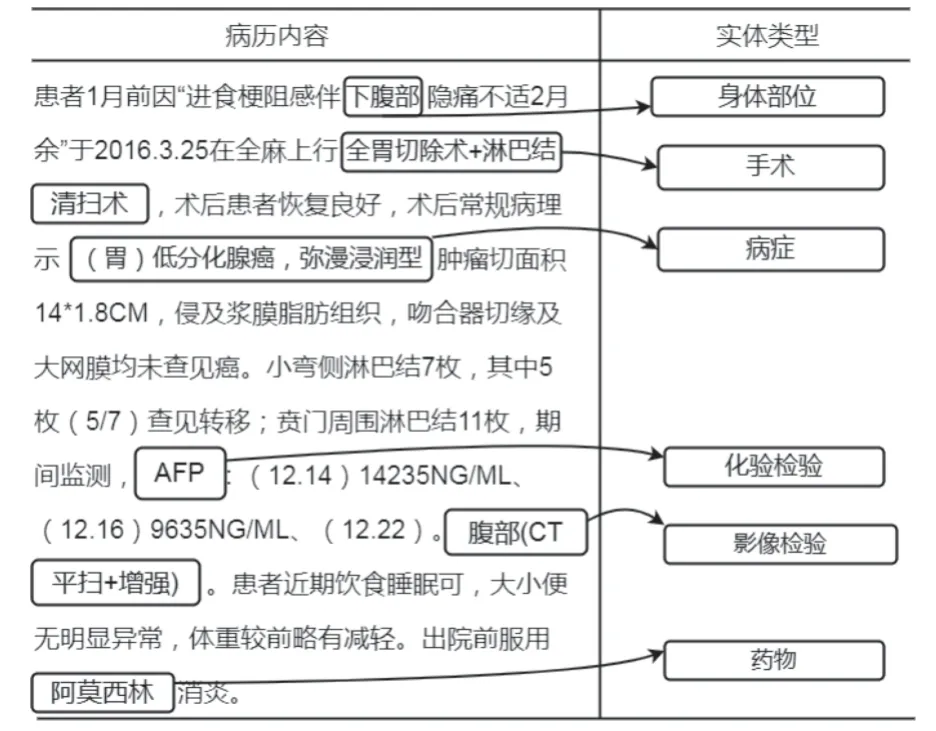
圖1 電子病歷實體對應關系圖
2.2 原始數據清洗
數據清洗的過程主要利用Python 程序將原始文本中的空格,首尾標點符號以及一些錯誤符號進行刪除,并檢查人工標記的起始位置和終點位置的實體是否標記有誤,例如起始位置開始過早或者終點位置結束過晚等情況.為了防止標點符號的使用不一致情況,本文將原始文本中的標點全部使用英文標點表示.實驗發現,沒有進行過數據清洗的數據會比進行過數據清洗的數據在訓練結果上產生的誤差在10%左右,說明對于原始數據進行清洗在模型訓練中存在一定的作用.
3 模型結構
本文提出的一種融合文字與標簽的WT-MHABiLSTM-CRF 模型結構如圖2 所示.在模型中,輸入層獲取電子病歷的每個文字及文字對應的標簽,將文字和標簽分別建立字典,得到每個字和標簽對應在字典中的序號,即向量化表示后的結果,將兩者進行結合,輸入到multi-head attention[10]中,attention 機制會使得模型在句子中捕捉到更多的上下文信息,其輸出結果是在3 個維度上的加權整合,并映射到模型設定的矩陣維度上.該輸出的結果作為BiLSTM 模型的輸入,BiLSTM 模型根據上下文信息,計算每個字符在每一個類別中的概率值大小.基于BiLSTM-CRF 模型拋棄了Softmax 層并使用CRF 進行代替,CRF 層在訓練過程中可以自主學習到一些約束規則,這些約束可以保證預測標簽的合理性,CRF 層將BiLSTM 層的輸出結果作為輸入,進一步約束,得到更加準確的輸出結果,整體模型將CRF 的輸出作為最后的預測結果,并與標準結果進行比對,計算預測的誤差.
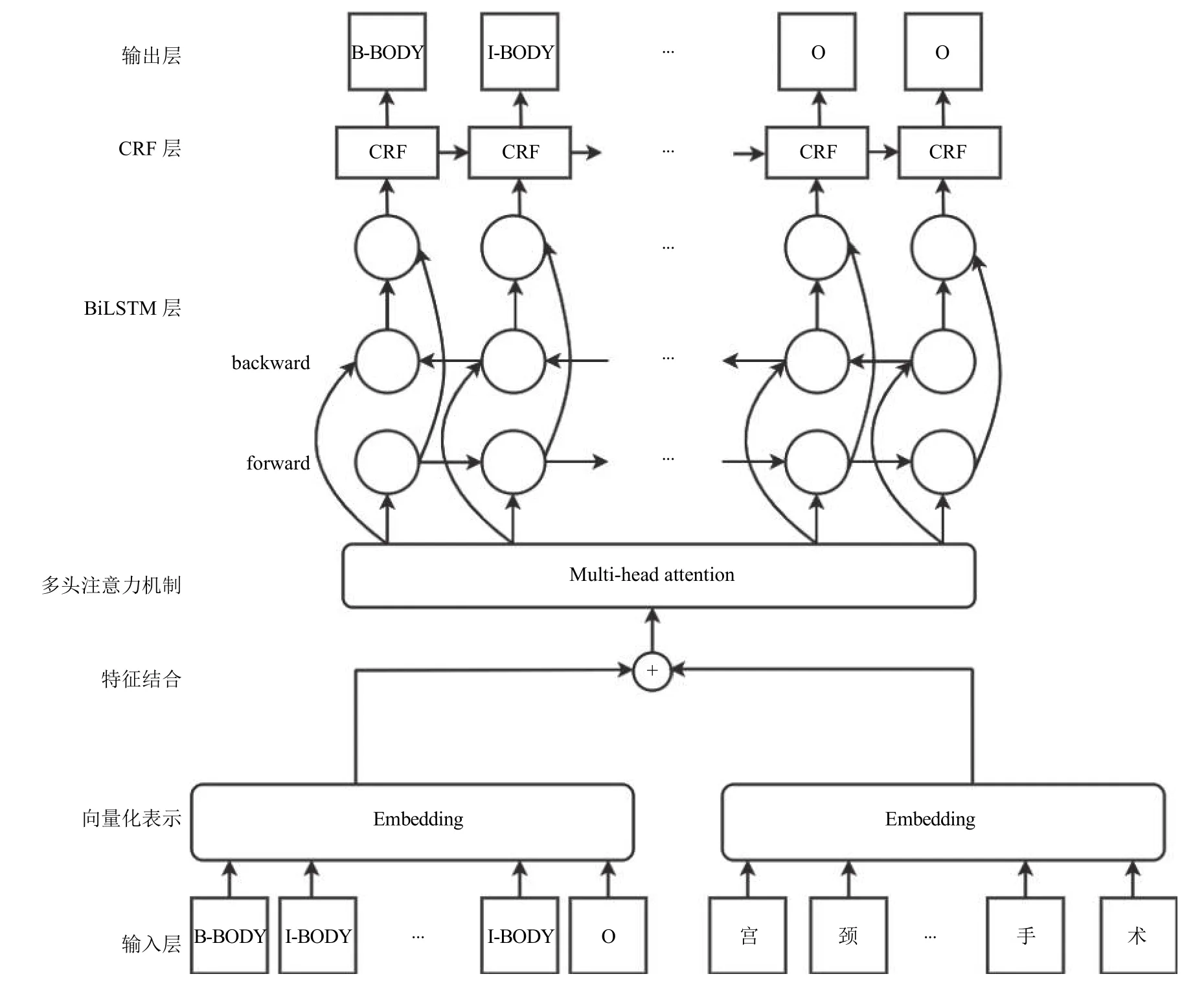
圖2 WT-MHA-BiLSTM-CRF 模型結構圖
本文提出的模型相對于傳統的命名實體識別模型來說,同時關注文字和標簽中的信息,使得輸入信息更加充分,發現標簽中的隱含信息對模型結果帶來的價值.
3.1 BiLSTM 模型
雙向長短期神經網絡(BiLSTM)[11]是一種為解決循環神經網絡(RNN)中梯度消失或者梯度爆炸問題而提出的模型,它較好地解決了RNN 在長依賴訓練過程中的缺陷.長短期神經網絡(LSTM)是一種單向網絡,主要使用門機制[12]來解決RNN 中的長期依賴問題,其模型結構如圖3 (圖中sig 代表Sigmoid 函數)所示.
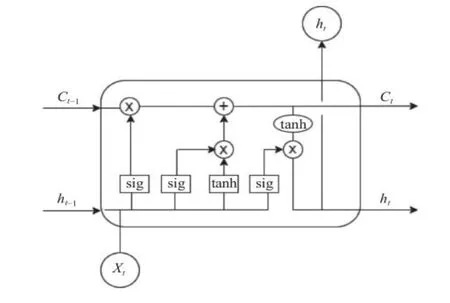
圖3 LSTM 模型結構圖
LSTM[13]在隱藏單元中提出了3 種門的概念: 輸入門,輸出門,遺忘門.式(1)和式(2)體現了輸入門與單元狀態更新的計算公式:
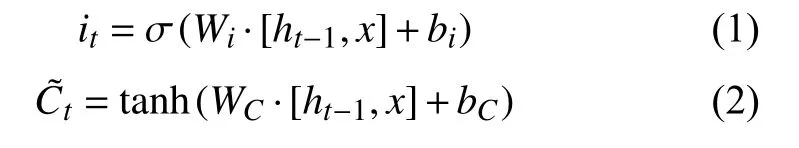
輸入門用來確定當前輸入中被保存狀態的個數,其中,it為輸入門,W、b分別表示權重矩陣和偏置向量,σ(·)代表Sigmoid 激活函數,tanh(·)代表tanh 激活函數,其表達式分別為式(3)和式(4)所示.
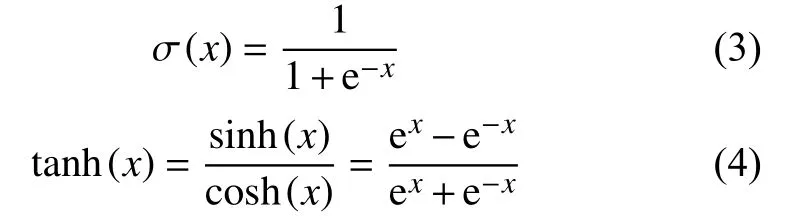
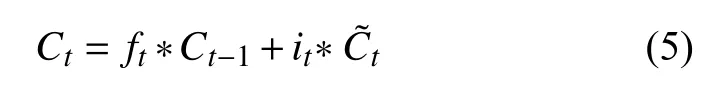
輸出門將會決定傳輸多少個單元狀態作為 LSTM的當前輸出值,通過計算隱藏節點ht來計算預測值和下一個時刻的輸入,式中ot代表輸出值.
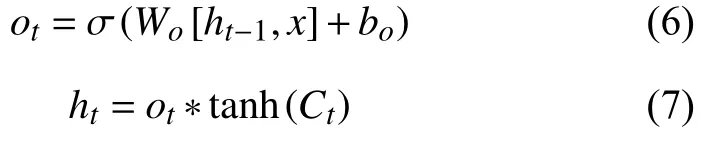
遺忘門負責上一個時刻的單元狀態保存多少到當前時刻,表現為Ct-1中哪些特征將被用于計算Ct,遺忘門ft中的每個值位于[0,1]中,計算公式見式(8).
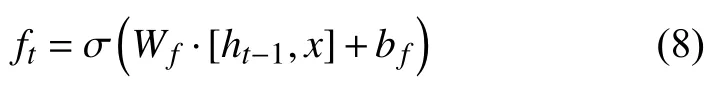
單元狀態作為LSTM 中的核心部分,始終貫穿整個計算,其計算表達式為:
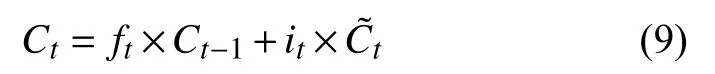
本文使用的BiLSTM 模型相對于LSTM 模型來說,能夠在未來上下文的預測中有較好的表現,使得訓練不僅能夠接受前文的序列也可以得到后續序列,在進行命名實體識別的過程中會有更好的效果.
3.2 GRU 模型
門控循環單元(GRU)也是為了解決循環神經網絡存在的長期依賴問題而提出的,模型中使用了更新門和重置門兩種門機制,使得模型在訓練效果不變的同時,計算更加簡單,其計算過程如式(10)-式(13)所示.
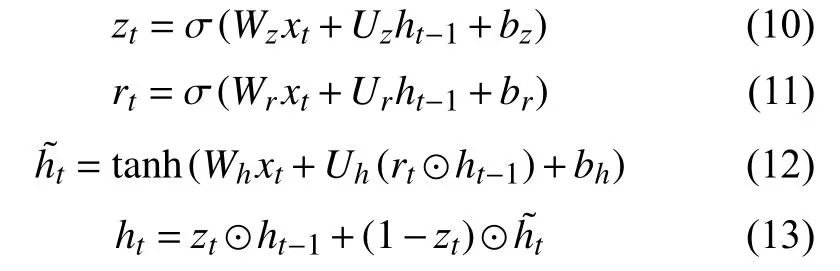
其中,σ(·)、tanh(·)同上述描述,代表哈達馬乘積,用于計算兩個階相同矩陣的對應位置,并將它們相乘得到一個新矩陣,zt代表更新門,其作用是決定多少信息從之前狀態ht-1保存到當前狀態ht,以及在候選狀態h~t中得到多少信息.rt代表重置門,決定了候選狀態h~t的計算是否依賴于之前狀態ht-1.
3.3 Multi-head attention 原理
由于單層的attention 所包含的信息可能不夠支持眾多的下游任務,因此2017年谷歌推出的Transformer將其堆疊成multi-head attention (MHA),其本質是多次的self-attention[14]計算.Attention 機制[15]會使網絡在訓練過程中更多的注意到輸入包含的相關信息,而對無關信息進行簡略,從而提高訓練的準確性.
Self-attention 對輸入的每個詞向量創建3 個新向量:Query、Key、Value,這3 個向量分別是詞向量和Q,K,V三個矩陣乘積得到的,Q,K,V三個矩陣是一個需要學習的參數,其定義如下所示:
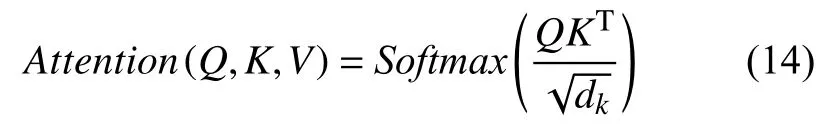
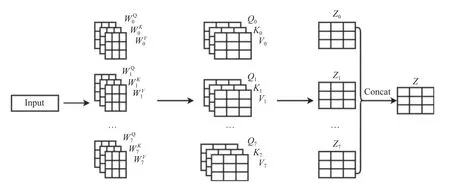
圖4 Multi-head attention 計算過程圖
MHA 定義如式(15)所示:
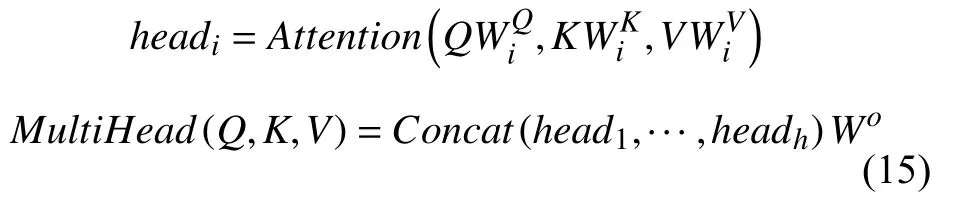
其中,WiQ,WiK,WiV是需要訓練的參數權重,Wo屬于Rdmodel×hdV,dmodel代表了模型中Q,K,V的維度,Concat()代表拼接函數,用于將多層的Q,K,V函數拼接起來.
3.4 CRF 模型
條件隨機場(CRF)[16]是一種較為經典的條件概率分布模型,通過觀測序列X=(x1,x2,···,xn)來計算狀態序列Y=(y1,y2,···,yn)的條件概率值p(y|x),CRF 的簡化定義公式如下:

其中,w代表權值向量,F(y,x)表示全局特征函數.CRF 模型可以自主的學習到文本中的約束,例如在命名實體識別[17]中,I-標簽的后面不會出現B-標簽,O 標簽的后面不會出現I-標簽等,這些約束會幫助訓練結果更加合理.
CRF 模型通過式(17)得到評估分數,式中Emit代表BiLSTM 輸出的概率,Trans代表對應的轉移概率.
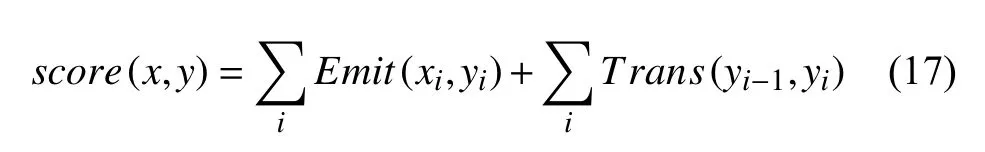
最后模型使用最大似然法來進行訓練,相應的損失函數為:
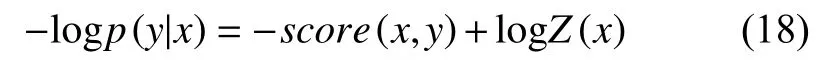
由于Z(x)無法直接計算,因此使用前向算法進行推導,在深度學習框架中可以對損失函數進行求導或者梯度下降的方法來優化,使用Viterbi 算法進行解碼,從而找到最優結果.
4 實驗及結果分析
4.1 實驗數據集
實驗過程中比較了4 種模型的訓練情況,使用人工標注過的1 000 份數據集,按照6:2:2 的比例將數據劃分為訓練集、驗證集、測試集.在實體識別中常用的實體標注方式[18]包括BIO、BIOE、BIOES 等,本實驗使用BIO 標注方式,具體的標注情況與實體數量見表1 和圖5 所示.根據第2.2 節中所述,數據集的準確性對模型最終結果存在影響,因此實驗對原始數據進行預處理,主要包括中英文統一,利用程序檢查原始數據集中是否有啟始位置錯誤信息,并針對錯誤信息進行修改.
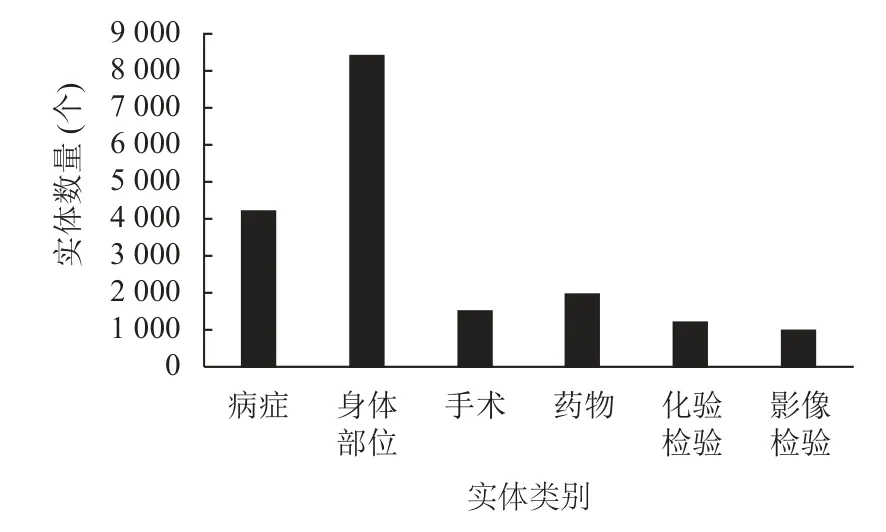
圖5 實體數量圖
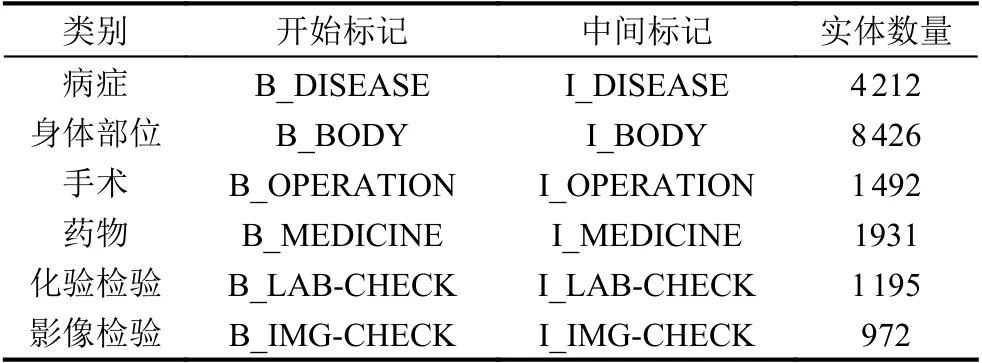
表1 數據標注表
4.2 數據集評價指標
實驗使用精確率(結果中的P值)、召回率(結果中的R值)和F1 值作為模型評價指標,其中精確率代表在所有預測結果中為正確的個數在實際正確分類所占的比例; 召回率代表所有預測正確的結果在實際正確中的占比;F1 值使用加權和平均來保證兩者在結果中的作用,由于綜合考慮了精確率和召回率的結果,因此F1 的值往往作為實驗結果的最有力的證明,其值越高說明實驗的效果越好,三者的計算過程見式(19)-式(21).
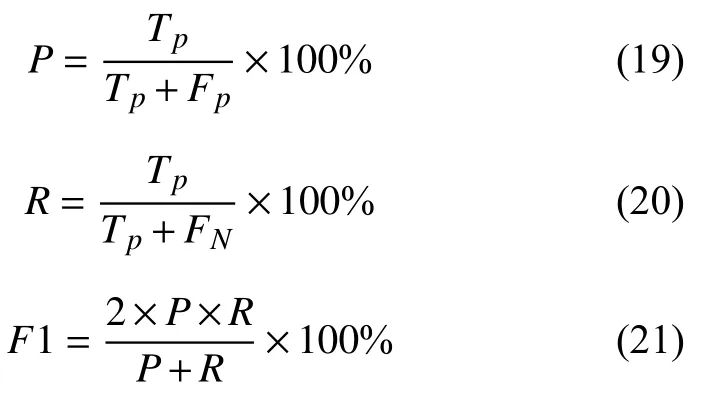
其中,Tp表示在測試集中正例被正確分類的個數,Fp代表負例被錯誤分類為正例的個數,FN表示正例被錯誤分類為負例的個數.
4.3 實驗環境與結果
本文中命名實體識別模型基于PyTorch 框架,詳細實驗環境設置見表2 所示.

表2 訓練環境表
訓練中模型的詳細參數為: 每次訓練選取的樣本數batch_size 值為64,學習率lr 設定為1E-4,訓練輪數epoch 設置為30,時序模型的網絡層數設置為1,詞向量維數為128,使用Adam 優化器,丟失率dropout 值為0.5.
本文對4 種模型進行了測試來增強模型結果的說服力,4 種模型定義如下.
(1)BiLSTM-CRF: 使用單層的BiLSTM 網絡,并將模型的輸出結果直接作為條件隨機場的輸入計算最終結果.
(2)BiGRU-CRF: 使用單層的BiGRU 模型,將輸出結果投入CRF 計算.
(3)MHA-BiLSTM-CRF: 對字向量做Embedding后先進入mutli-head attention 模型中,模型輸出的結果作為BiLSTM 模型的輸入,其結果作為CRF 層輸入.
(4)WT-MHA-BiLSTM-CRF: 同時對字、標簽做Embedding,將兩者結合,作為mutli-head attention 的輸入,之后進入BiLSTM 模型訓練,最終進入CRF 層進行訓練.
表3 展示了4 種模型在各個實體上的精確率、召回率和F1 值,從結果來看,WT-MHA-BiLSTM-CRF 在大多數的實體分類結果上均有一定的提高,與BiLSTMCRF 模型的比較中,在病癥方面F1 值提高了3%,身體部位提高了6%,手術提高了4%,化驗檢驗提高了7%,影像檢驗提高了11%.但是在藥物的類別方面,WT-MHA-BiLSTM-CRF 的結果與其他模型相比有些下降,初步分析原因是,由于本文提出的模型是針對字和標簽同時作為模型的輸入來進行訓練,并且經過attention 機制的處理,在實驗過程中,可能過度的對某些字、標簽產生了過度的關注,而使得分類結果產生了誤差,因而導致分類效果的下降,在以后的研究中會針對這一方面進行深入研究.最后,圖6 展示了WTMHA-BiLSTM-CRF 模型在各個實體中的預測結果.
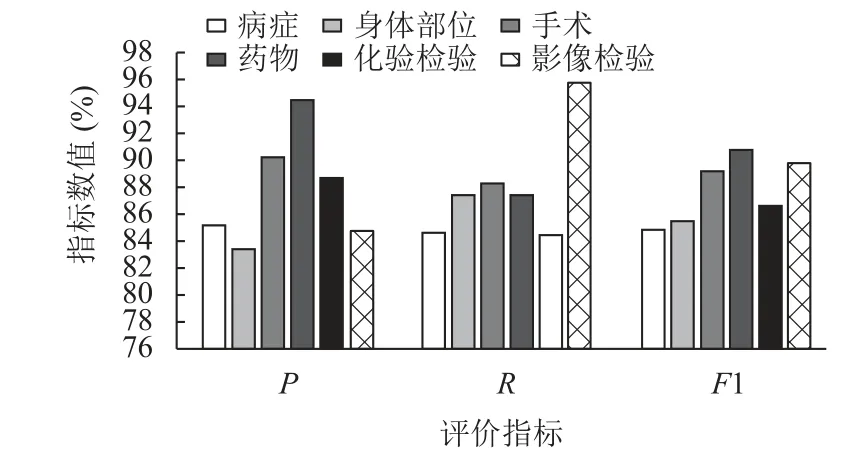
圖6 WT-MHA-BiLSTM-CRF 模型各類別結果圖

表3 實驗結果表(%)
5 結論與展望
本文提出了一種結合字與標簽同時訓練的WTMHA-BiLSTM-CRF 模型,用于解決結構化電子病歷中命名實體識別的問題.傳統的BiLSTM-CRF 模型更多的注重字在模型中訓練產生的結果,忽略了標簽中可能隱含的信息,因此在訓練輸入之前,將字和標簽同時做Embedding 處理.并使用mutli-head attention 使模型更多的注意力放在關鍵的字和標簽上,BiLSTM 結合上下文得到每個字的類別概率,模型的最后使用CRF對分類結果進行處理,使得模型的預測輸出更有說服力.從實驗結果中可以看出,該模型在大部分的類別識別中均有提升.對于個別類別來說,考慮到模型的結果中可能有部分信息被過度關注,導致訓練結果上有些許問題,在以后的研究中也會針對這個問題著重來處理.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
中外會展(2014年4期)2014-11-27 07:46:46
