Android系統(tǒng)微信數(shù)據(jù)多重融合恢復方法
2022-11-07 10:49:06蔣烈輝葛方麗
計算機應用與軟件 2022年10期
朱 兵 蔣烈輝 葛方麗 薛 兵
1(鄭州大學 河南 鄭州 450000) 2(信息工程大學 河南 鄭州 450000) 3(鄭州信息工程大學先進技術研究院 河南 鄭州 450000)
0 引 言
現(xiàn)如今智能手機的系統(tǒng)多樣,Android系統(tǒng)占據(jù)了中國甚至全球絕大部分的手機市場。微信作為最大的獨立消息傳遞應用程序之一,其功能多樣為智能終端用戶提供了免費文本和語音通信等服務[1]。正是由于微信的流行,犯罪分子利用微信進行違法犯罪行為越為突出。具有一定反偵察意識的犯罪分子會故意刪除微信上的數(shù)據(jù),恢復微信數(shù)據(jù)是司法取證的關鍵,從中獲得犯罪線索或關鍵證據(jù)會直接影響案件能否成功偵破。因此,針對Android手機微信的數(shù)據(jù)恢復技術研究有著普遍且十分重要的意義。
1 國內(nèi)外研究現(xiàn)狀
童宇等[2]提出了基于SQLite數(shù)據(jù)庫的空閑頁鏈表的恢復方法對已刪除的微信聊天記錄進行了恢復和提取,但該方法只是從微信數(shù)據(jù)庫文件“EnMicroMsg.db”中進行刪除恢復,因此可恢復數(shù)據(jù)源并不完整,實驗驗證其恢復率只能達到27%。張艷姣[3]提出了基于SQLite數(shù)據(jù)庫的自由塊鏈表的恢復方法,該方法也是依賴微信主庫實現(xiàn)微信數(shù)據(jù)的恢復。這兩種傳統(tǒng)微信數(shù)據(jù)恢復方法恢復數(shù)據(jù)源并不完整、恢復率低。文獻[4]分析Whats App的表結(jié)構、信息接收與數(shù)據(jù)刪除機制,認為此應用不會從SQLite中直接刪除數(shù)據(jù),可以提取被邏輯刪除的數(shù)據(jù),恢復了SQLite被刪除的數(shù)據(jù)。文獻[5]研究了Firefox中數(shù)據(jù)庫表格式,從數(shù)據(jù)庫中存儲的查詢記錄入手,利用回滾日志文件實現(xiàn)了數(shù)據(jù)庫已刪除記錄的恢復。但是此方法局限性較大,僅適用于特定應用。文獻[6]針對Android手機的存儲技術進行研究,提出了一種基于SQLite存儲結(jié)構的數(shù)據(jù)恢復方法和一種基于SQLite預寫日志的數(shù)據(jù)恢復方法,解決了預寫日志存儲分片的問題,從日志文件的角度對數(shù)據(jù)進行刪除恢復。該方法并不適用于微信的刪除恢復,研究發(fā)現(xiàn)微信中涉及恢復的索引庫日志文件是回滾日志。文獻[7]用靜態(tài)分析的方法研究了微信的加密方式,在此基礎上提出了MTP協(xié)議下恢復手機中被刪除微信數(shù)據(jù)文件的方法,該方法不會損傷手機的存儲設備,但對微信具體的刪除恢復效果并未詳述。文獻[8]研究了微信信息的數(shù)據(jù)取證原理,重點對加密聊天記錄數(shù)據(jù)庫進行了詳細的解密分析,并給出了在不同取證環(huán)境下的數(shù)據(jù)庫解密過程,但是并未詳細描述解密后的微信數(shù)據(jù)恢復方法。
從以上研究可以看出,目前傳統(tǒng)的微信取證技術研究多依賴于主庫文件,并未對微信索引庫文件和日志文件有所研究。但是在我們的研究取證工作中發(fā)現(xiàn)索引庫和日志文件中有大量可恢復數(shù)據(jù)。綜上,本文的研究融合了微信主庫、索引庫、索引庫回滾日志文件的數(shù)據(jù)對微信刪除數(shù)據(jù)進行恢復。解密和脫密數(shù)據(jù)庫文件和回滾日志文件獲取多重數(shù)據(jù),提出并詳細介紹Android系統(tǒng)微信數(shù)據(jù)多重融合恢復方法的算法流程,最后進行對比實驗驗證本文方法的有效性。
2 SQLite數(shù)據(jù)結(jié)構分析
2.1 SQLite數(shù)據(jù)庫文件
微信的主庫和索引庫文件都屬于SQLite類型的數(shù)據(jù)庫文件,在該數(shù)據(jù)庫中,微信數(shù)據(jù)分別存儲在多個Btree頁中,其中表的索引存放在B-tree頁中,表數(shù)據(jù)存放在B+tree頁中。而所有表或索引的根頁編號都存儲在系統(tǒng)表sqlite_master中,系統(tǒng)表的根頁為page1。
數(shù)據(jù)庫中一個Btree頁由頁頭、單元指針數(shù)組、未分配空間和單元內(nèi)容區(qū)四部分組成。Btree頁內(nèi)部進行空間分配和回收是以數(shù)據(jù)單元為基本單位,一個單元包含一條payload(單元記錄)。頁內(nèi)所有單元的內(nèi)容都是由頁的底部向上增長,稱為單元內(nèi)容區(qū)。由于單元大小可變,所以需要記錄其起始位置,即單元指針。頁頭之后單元指針數(shù)組中保存著單元指針。單元指針數(shù)組是由上向下增長,與單元內(nèi)容區(qū)相向增長。一個完整的SQLite數(shù)據(jù)庫文件主要包含文件頭和Btree頁[9]。SQLite數(shù)據(jù)庫文件結(jié)構如圖1所示。
數(shù)據(jù)庫文件頁面中頁頭的偏移量為1的兩個字節(jié)代表第一個自由塊的偏移量,自由塊的前2個字節(jié)指向下一個自由塊,形成自由塊鏈表直到自由塊前2個字節(jié)值為0,表示沒有下一個自由塊[4]。文件頭偏移量為32的四個字節(jié)代表空閑頁鏈表首指針,空閑頁有兩種類型:trunk page(主干頁)和leaf page(葉子頁)。文件頭偏移為32處的指針指向空閑鏈表的第一個主干頁,每個主干頁指向多個葉子頁[10]。
2.2 索引庫回滾日志文件
回滾日志文件始終位于與對應數(shù)據(jù)庫文件相同的目錄中,并且具有與數(shù)據(jù)庫文件相同的名稱,但是附加了字符串“-journal”[5]。日志文件的結(jié)構主要由日志頭部與一系列回滾日志記錄頁組成。回滾日志頁面的前4個字節(jié)表示數(shù)據(jù)庫文件的頁數(shù),隨后N個字節(jié)為頁大小,表示事務開始前數(shù)據(jù)庫文件中對應頁的原始數(shù)據(jù)。最后4個字節(jié)為校驗和,用以校驗當前記錄是否有效[6]。回滾日志文件存儲結(jié)構如圖2所示。
3 解密與脫密數(shù)據(jù)文件
SQLite數(shù)據(jù)庫被廣泛應用于 Android手機來保存大量的用戶數(shù)據(jù),微信應用的用戶數(shù)據(jù)會由SQL存儲引擎存儲和加解密引擎加密存儲到微信本地目錄下的SQLite數(shù)據(jù)庫中[7]。微信主庫、索引庫、索引庫回滾日志文件都需要解密和脫密之后才能進行數(shù)據(jù)分析和恢復,因此微信數(shù)據(jù)庫文件和日志文件的解密、脫密是在獲取數(shù)據(jù)之前需要做的重要工作。
3.1 主庫文件解密與脫密
EnMicroMsg.db(微信主庫)文件的解密密鑰password是IMEI(國際移動設備身份號碼)與UIN(用戶信息)拼接后計算32位 MD5值,然后取前7位。即:
Hash=MD5(IMEI+UIN)
password=Hash[0-6]
微信主庫脫密密鑰的獲得為:
dec_key=kdf(password,pass_sz,salt,salt_sz,
Kdf_Iter,key_sz)
其中:“pass_sz”是密碼的長度;“salt”是加密數(shù)據(jù)庫“EnMicroMsg.db”的前16字節(jié)[8];“salt_sz”是鹽值的長度;“Kdf_Iter”是PBKDF2的迭代次數(shù),默認值為4 000,“key_sz”是密鑰的長度;主庫的默認頁面大小page_size為1 024。
主庫獲取脫密密鑰的完整計算過程如圖3所示。
3.2 索引庫及索引庫回滾日志文件解密與脫密
FTS5IndexMicroMsg_encrypt.db(微信索引庫)文件和FTS5IndexMicroMsg_encrypt.db-journal(微信索引庫回滾日志)文件的解密和方式相同,本節(jié)僅闡述微信索引庫解密和脫密過程。與微信主庫獲取解密密鑰不同的是,如果UIN是負值不能直接進行MD5拼接,需要把它加上一個最大無符號數(shù)Max之后得到的正數(shù)作為最終的UIN與IMEI進行MD5拼接。
FTS5IndexMicroMsg_encrypt.db(加密微信索引庫)文件的解密密鑰password是IMEI、UIN、微信id三者拼接后計算32位 MD5值,然后取前7位。即:
Hash=MD5(IMEI+UIN+WX_ID) orHash=
MD5(IMEI+(UIN+Max)+WX_ID)
password=Hash[0-6]
索引庫與主庫的解密參數(shù)有所不同,迭代次數(shù)kdf_iter為64 000,索引庫的默認頁面大小page_size為4 096,微信索引庫脫密密鑰的獲得為:
Salt=ByteCopy(Pages[0][:16])
HMAC_Salt=ByteCopy(Salt)
Key=pbkdf2.Key(password,salt,Kdf_Iter,32,sha1.New)
HMAC_Key=pbkdf2.Key(Key,HMAC_Salt,2,32,sha1.New)
索引庫獲取脫密密鑰的完整計算過程如圖4所示。
4 多重融合恢復方法
4.1 恢復方法
通過對微信數(shù)據(jù)庫文件內(nèi)部結(jié)構研究發(fā)現(xiàn),除了微信主庫中的message表中存儲的有微信消息記錄以外,微信索引庫的FTS5IdexMessage_content表和FTS5IdexMessage_data表中均存儲有微信消息記錄。前者以明文的形式存儲未被刪除的記錄,后者主要存儲的是被刪除的記錄。Android手機新版本微信所采用的日志模式為 PERSIST模式,微信索引庫對應的回滾日志文件并沒有被刪除,僅清空頭部標識。
上述發(fā)現(xiàn)為本文Android手機微信數(shù)據(jù)的恢復帶來了新的思路,不僅可以在微信主庫中獲取數(shù)據(jù),微信索引庫和索引庫回滾日志文件中也能獲取數(shù)據(jù)。因此本文提出一種基于Android系統(tǒng)微信數(shù)據(jù)的多重融合恢復方法,該方法采用基于SQLite數(shù)據(jù)庫的空閑頁鏈表或者自由塊鏈表[9]的恢復技術融合了微信主庫、索引庫、回滾日志文件對微信刪除數(shù)據(jù)進行恢復。下面詳細介紹Android系統(tǒng)微信數(shù)據(jù)的多重融合恢復方法:
1) 主庫采用傳統(tǒng)恢復方法進行數(shù)據(jù)恢復,即基于SQLite數(shù)據(jù)庫的空閑頁鏈表或者自由塊鏈表的恢復方法。
2) 根據(jù)數(shù)據(jù)庫文件內(nèi)部結(jié)構直接對微信索引庫數(shù)據(jù)進行提取和恢復。
3) 計算索引庫回滾日志文件的校驗和。
4) 利用校驗和對回滾日志文件頁記錄進行分組恢復。
5) 主庫和索引庫的恢復數(shù)據(jù)進行對比去重。
6) 回滾日志的恢復數(shù)據(jù)與步驟5)已經(jīng)對比去重之后的數(shù)據(jù)再次進行對比去重。
7) 將最終恢復的數(shù)據(jù)寫入數(shù)據(jù)庫,完成所有數(shù)據(jù)恢復。
多重融合數(shù)據(jù)恢復方法如圖5所示。
4.2 索引庫數(shù)據(jù)恢復算法
微信索引庫中FTS5IdexMessage_content表存儲著未被刪除的消息記錄,而FTS5IdexMessage_data表中主要存儲著已經(jīng)被刪除的微信消息記錄,但也會存在部分沒有被刪除的消息記錄。所以本文在恢復時,需要融合這兩個表中的數(shù)據(jù)進行對比去重,其恢復算法為:
Begin:
DataBase Db=OpenDb(“path”);
//打開path路徑下的數(shù)據(jù)庫
//獲取該數(shù)據(jù)庫中FTS5IdexMessage_content表的根頁號
int crpage=getRootPage(“FTS5IdexMessage_content”,Db);
closeDB(Db);
//關閉數(shù)據(jù)庫句柄
File file=OpenFile(“r”,“path”);
//將數(shù)據(jù)庫文件以只讀方式打開
//將文件句柄定位到FTS5IdexMessage_content表開始位置
feek(file,pageNum*crpage,BEGIN);
String temp=read(file,4,2);
//當前第四個位置開始兩個字節(jié)為本頁單元內(nèi)容的個數(shù)
int cNum=int.Parse(temp);
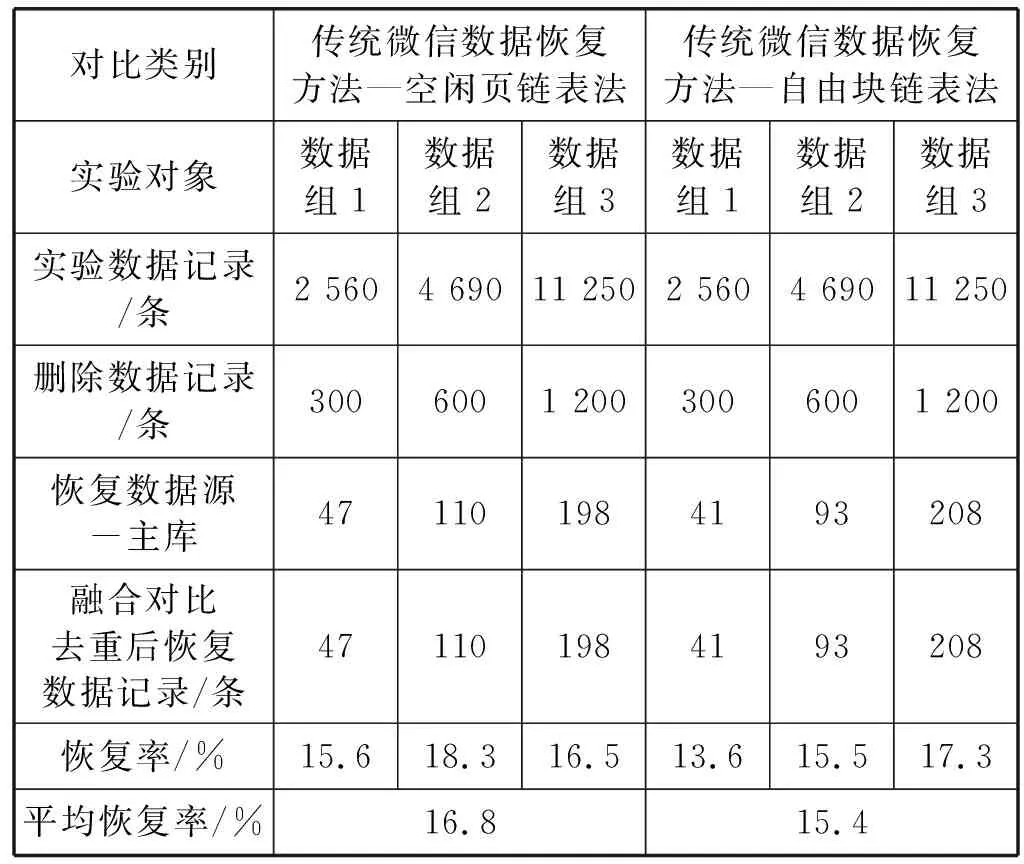
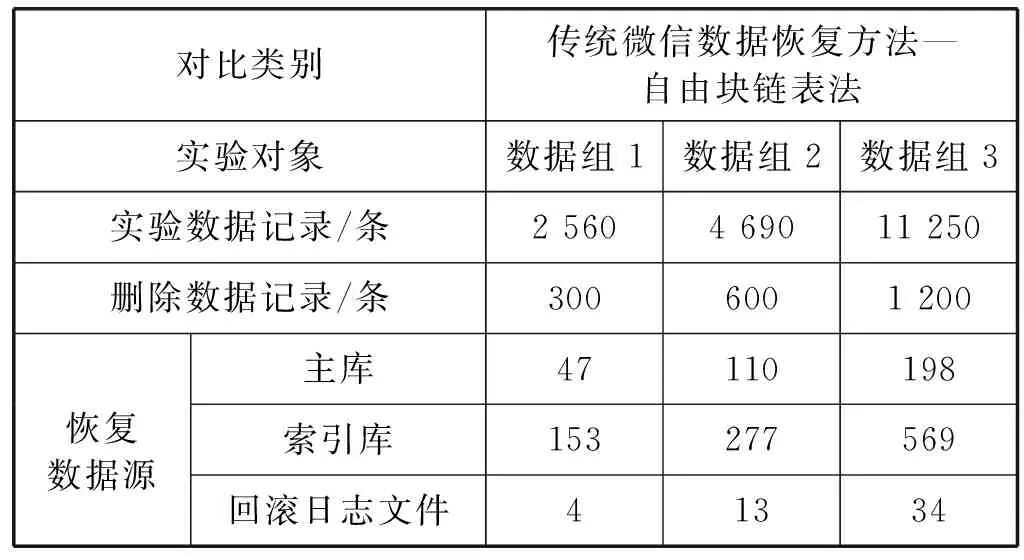
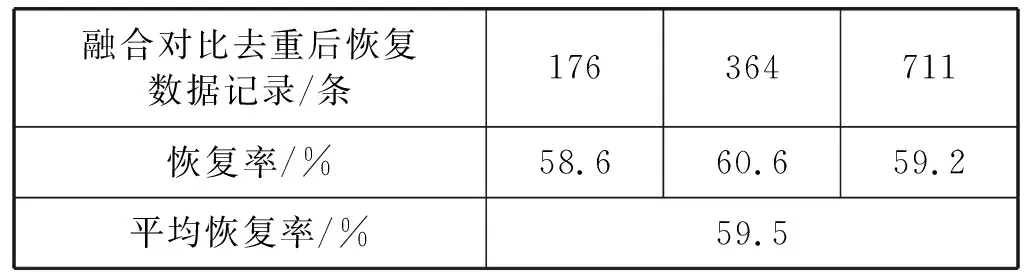
for(int i=0;i int cSize=getCSzie(file); //獲取當前單元區(qū)內(nèi)容大小 String content=read(file,0,cSize); //讀取當前單元內(nèi)容 write(“newFile1”,content); //將內(nèi)容寫入到newFile1中 } closeFile(file); end //對FTS5IdexMessage_data也執(zhí)行上述偽代碼邏輯, //然后存入newFile2中 File file1=OpenFile(“r”,“newFile1”); File file2=OpenFile(“r”,“newFile2”); File file=OpenFile(“r”,“newFile”); //對文件句柄file1與file2內(nèi)容進行去重合并, //然后寫入到file中 mergeOperate(file1,file2,file); WriteDb(“newDb”,file,type); //根據(jù)文件中的type標記將內(nèi)容寫入數(shù)據(jù)庫中 closeFile(file1,file2,file); //關閉文件句柄 Android 4.1.1版本及之后的微信,每次數(shù)據(jù)庫事務結(jié)束后,回滾日志文件仍然保留,文件頭部標識被清空。根據(jù)回滾日志文件結(jié)構,日志文件的每個記錄頁的最后4個字節(jié)均為校驗和。計算頁面數(shù)據(jù)的校驗和時,校驗和初始值是隨機生成的,會寫入回滾日志文件頭信息中,所以針對日志頭被清空的情況,逆向分析計算校驗和,根據(jù)校驗和對日志文件進行數(shù)據(jù)分組,提取回滾日志文件中的數(shù)據(jù)。 校驗和chkSum是一個無符號的32位整數(shù),計算公式如下: top=size(page)/200 (1) offset=size(page) mod 200+4 (2) offset+200(i-1)) (3) 通過式(1)-式(3)得到rChkSum后截取為 32位無符號整數(shù)得到最終校驗和chkSum。其中:top表示本頁記錄選取字節(jié)數(shù);offset為首字節(jié)偏移量;getVal為取當前字節(jié)值[10];absAddr為記錄頁面起始位置的指針。微信索引庫回滾日志文件數(shù)據(jù)恢復的算法為: Begin: File Rj=OpenFile(“r”,“path”); //打開path路徑下的日志文件 chkSum=getChkSum(); //根據(jù)上述公式獲取校驗和 String[] contentlist=getContentSplit(Rj,chkSum) //將日志文件中的內(nèi)容按校驗和chkSum分割開, //分割以后存儲在contentlist里 File newFile=OpenDb(“w”,“newPath”); //打開對應路徑下的文件 Write(newFile,contentList); //將得到的回滾日志數(shù)據(jù)寫入新文件中 closeFile(Rj); //關閉日志文件句柄 closeFile(newFile); //關閉新文件句柄 end 本文方法對索引庫中兩個表恢復出來的數(shù)據(jù)進行對比去重,對主庫和索引庫中恢復出來的數(shù)據(jù)進行融合對比去重,再與回滾日志文件中的恢復數(shù)據(jù)進行對比去重。恢復數(shù)據(jù)對比去重算法思想為:恢復的每一條數(shù)據(jù)包含createTime時間戳(固定6字節(jié))、talker交互方和content聊天內(nèi)容。依據(jù)時間戳對恢復數(shù)據(jù)逐條進行插入排序,判斷時間戳是否相同,逐字節(jié)對比聊天內(nèi)容,如果不同插入恢復數(shù)據(jù)庫,如果相同則刪除重復記錄。 恢復數(shù)據(jù)對比去重具體算法如下: Begin: mergeOperate(file1,file2,file): //獲取文件1和2中的數(shù)據(jù)個數(shù) int num1=getDataNum(file1); int num2=getDataNum(file2); //創(chuàng)建2個基本元素結(jié)構為DataType的數(shù)組用來存儲 //2個文件中數(shù)據(jù),包括時間戳以及聊天內(nèi)容等 DataType[] datas1=new DataType[num1]; DataType[] datas2=new DataType[num2]; //分別獲取文件1和文件2中所有的數(shù)據(jù)并存儲到數(shù)組中 getData(file1,datas1); getData(file2,datas2); //將數(shù)據(jù)按照時間戳從小到大排序 sortDataByTimestamp(datas1); sortDataByTimestamp(datas2); //創(chuàng)建一個棧用來存儲去重后的數(shù)據(jù) InitStack(datas); //循環(huán)去重 for(int i=0,j=0;i //如果兩個數(shù)據(jù)的時間戳相等且聊天內(nèi)容相等,將數(shù)據(jù) //去重后放入棧中 if(equal(datas1[i].timestamp,datas2[j].times tamp&& equal(datas1[i].content,datas2[j].content){ push(datas,datas1[i]); }else{ push(datas,datas1[i]); push(datas,datas2[j]); } } //將剩余數(shù)據(jù)放入棧中 while(i push(datas,datas1[i]); i++; } while(j push(datas,datas2[j]); j++; } write(file,datas); //將去重后的數(shù)據(jù)寫入file文件 end 實驗選用三組不同數(shù)據(jù)量的Android手機作為實驗對象。數(shù)據(jù)組1中10部手機搭載Android9.0,微信版本為7.0.6,微信數(shù)據(jù)量2 560條;數(shù)據(jù)組2中10部手機搭載Android9.0,微信版本為7.0.3,微信數(shù)據(jù)量4 690條;數(shù)據(jù)組3中10部手機搭載Android9.0,微信版本為7.0.6,微信數(shù)據(jù)量11 250條。實驗使用工具為WinHex、DB Browser for SQLCipher.exe、Navicat Premium 12等軟件。 本實驗采用Android手機微信多重融合恢復方法分別對主庫、索引庫、索引庫回滾日志文件這三部分進行數(shù)據(jù)恢復,再對恢復出來的數(shù)據(jù)進行對比去重。并且與傳統(tǒng)微信數(shù)據(jù)恢復方法進行對比,驗證本文方法的有效性。 選取數(shù)據(jù)組1實驗中一部手機的數(shù)據(jù),對主庫、索引庫刪除數(shù)據(jù)恢復結(jié)果包括聊天時間、交互方和聊天數(shù)據(jù),主庫中恢復出三條數(shù)據(jù),索引庫中恢復出8條數(shù)據(jù),如圖6、圖7所示。 在回滾日志中的記錄即為數(shù)據(jù)庫文件中存儲頁面內(nèi)容的數(shù)據(jù)副本,所以只需從頭到尾讀取回滾日志分組,并將日志中找到的內(nèi)容寫到數(shù)據(jù)庫文件的適當位置。回滾日志文件提取出一條數(shù)據(jù)如圖8所示。 最后融合從主庫、索引庫和索引庫回滾日志這三個文件中提取恢復的數(shù)據(jù)進行對比去重,如圖9所示。 本文方法對比傳統(tǒng)的微信恢復方法分別對三組不同數(shù)據(jù)量的微信數(shù)據(jù)進行刪除恢復。實驗結(jié)果分別如表1、表2所示。 表1 傳統(tǒng)恢復方法實驗結(jié)果 表2 多重數(shù)據(jù)融合恢復方法實驗結(jié)果 續(xù)表2 從表1實驗結(jié)果數(shù)據(jù)中發(fā)現(xiàn),傳統(tǒng)恢復方法的恢復數(shù)據(jù)源單一,只能從微信主庫中恢復數(shù)據(jù)。傳統(tǒng)空閑頁鏈表法對數(shù)據(jù)組2恢復效果最好,恢復率達到了18.3%,對三組數(shù)據(jù)的平均恢復率為16.8%。傳統(tǒng)自由塊鏈表法對數(shù)據(jù)組3的恢復效果最好,恢復率達到了17.3%,對三組數(shù)據(jù)的平均恢復率為15.4%。 從表2實驗結(jié)果數(shù)據(jù)可以發(fā)現(xiàn),多重數(shù)據(jù)融合恢復方法擴大了恢復數(shù)據(jù)源,可以對主庫、索引庫、索引庫日志文件分別進行數(shù)據(jù)恢復。三組微信數(shù)據(jù)的恢復中,多重數(shù)據(jù)融合恢復方法在數(shù)據(jù)組2中的恢復效果最好,融合對比去重后恢復數(shù)據(jù)記錄364條,恢復率達到了60.6%,數(shù)據(jù)組3的數(shù)據(jù)量最大,但是恢復效果卻不是最好的,融合對比去重后恢復數(shù)據(jù)記錄711條,只達到了59.2%。本文方法對三組數(shù)據(jù)的平均恢復率達到了59.5%,對比傳統(tǒng)的微信數(shù)據(jù)恢復方法恢復率顯著提高,進一步驗證了本文方法的可行性和有效性。 隨著網(wǎng)絡時代的到來,即時通信軟件更加受到了人們歡迎,人們常常在生活、辦公中都會用微信進行溝通交流。與此同時,微信的數(shù)據(jù)恢復對于手機取證也是非常重要的環(huán)節(jié)之一。本文在傳統(tǒng)微信數(shù)據(jù)恢復方法的基礎上,提出一種Android系統(tǒng)微信數(shù)據(jù)的多重融合恢復方法對已刪除的微信聊天記錄從微信主庫、索引庫和索引庫回滾日志文件中進行了恢復和提取,顯著提高了微信數(shù)據(jù)的恢復率。 此外,由于微信版本的不斷更新,我們在實驗中發(fā)現(xiàn)數(shù)據(jù)量越大,能夠從索引庫和回滾日志中恢復出的數(shù)據(jù)越有限。并且還存在記錄被部分覆蓋和全覆蓋,在這種情況下記錄只能部分恢復或者無法恢復,降低了數(shù)據(jù)恢復率。這些微信數(shù)據(jù)恢復中遇到的困難也是今后研究的方向。4.3 回滾日志恢復算法
4.4 對比去重算法
5 實 驗
5.1 實驗過程
5.2 對比實驗結(jié)果及分析
6 結(jié) 語
猜你喜歡
中國信息化周報(2016年47期)2017-03-25 17:33:41財經(jīng)(2017年2期)2017-03-10 14:35:35財經(jīng)(2016年15期)2016-06-03 07:38:02Coco薇(2016年2期)2016-03-22 02:42:52財經(jīng)(2016年3期)2016-03-07 07:44:46財經(jīng)(2016年6期)2016-02-24 07:41:51Coco薇(2015年1期)2015-08-13 02:47:34中國信息化周報(2015年27期)2015-08-12 22:09:31中國信息化周報(2015年28期)2015-08-06 22:08:50中國信息化周報(2015年13期)2015-06-01 21:47:12
