基于多階段評價選擇遺傳算法的材料訂購和運輸最優化問題研究
2022-11-18 08:31:10王子怡
科技與創新 2022年22期
關鍵詞:評價
王子怡
(西南林業大學大數據與智能工程學院,云南 昆明 650051)
1 研究背景
本研究中的某建筑企業所用原材料主要是木質纖維和其他植物素纖維材料,總體可分為A、B、C 3種類型。該企業計劃每年按48周安排生產,在生產之前,還需要提前制定24周的原材料訂購和轉運計劃。因此,需要根據產能要求確定原材料的供應商和相應每周原材料的訂購數目,并在最后委托合適的第三方物流公司轉運生產的原材料。該企業每周的產能為2.82萬m3,每立方米產品需要消耗A類、B類或C類原材料。同時供應商供貨量可能多余或少于訂貨量,所以企業需要保證庫存里有不少于2周生產需求的原材料數目[1]。
2 基于TOPSIS的供應商重要性評價模型
2.1 供應商重要性評價體系
先衡量供應商對生產企業重要性的評價指標并給出具體定義,然后構建出供應商重要性衡量體系,具體如下。
失信次數ηi:供應商未按量供貨(包括不供貨的情況)的次數。
失信率α:供應商未能按量供貨的次數占企業向該供應商訂購次數的比例。公式為α=ηi/ηn,其中,ηi為供應商未能按量供貨的次數(包含未供貨的次數),ηn為生產企業向該供應商訂貨的次數。
供貨次數ω:各供應商240周中提供貨物的次數。
供貨次率ψ:各供應商240周中提供貨物的次數占240周的比例。公式為ψ=ω/N,其中N取值為240。
單周最大供貨量β+:各供應商240周中供貨量最大的1周的供貨數量。該指標可以有效衡量供應商的最大供貨能力,供應商的重要性很大程度體現在供應商的供貨能力,從數據中可以得到各供應商5年來的最佳供貨數據,從而可以分析該供應商的供應能力,有助于生產企業進行決策。
總供貨量β:供應商240周總供貨量。為了衡量供應商的供貨實力,對供應商5年來供貨總量的評定很有必要,供應商5年來能提供的貨物數量在一定程度上反映了這家供應商的綜合實力,這可以作為企業向供貨商訂購貨物的依據,供貨實力強的供應商,企業會優先考慮大額訂單。
平均供貨量β-:供應商平均每次供貨的貨物數量。公式為β-=εi/ηn,其中,εi為供應商5年總共提供的貨物,ηn為5年來供應商向生產企業供貨的次數。在供應商供貨能力的評定上,需要比較均衡地了解每家供應商的供貨能力,平均值是一組數據中最有代表性的統計量,其能較好地衡量出每家供應商的平均供貨水平。
供貨率ε:供應商提供的貨物占企業訂購貨物的比例。公式為ε=βi/βn,其中,βi為供應商提供的貨物數量,βn為企業訂購的貨物。衡量供應商供應能力的另一重要指標是供貨過程中能提供的數量。
供貨量標準差γ:反映供應商供貨數據的離散程度,即240周總體供貨量與平均供貨量離差平方的算術平均數的平方根,公式為其中,βi為供應商每周提供的貨物量,為240周平均每周提供的貨物量。考慮到供應商每次供貨量數值變化不確定,故需采用標準差對供貨量進行分析,為了觀察供貨數據的波動性,衡量供應商的供貨穩定性,采用該指標衡量供應商供貨能力的波動性。
以上9個評價指標,可層次構成供應商重要性評價體系。
2.2 TOPSIS分析過程
TOPSⅠS(Technique for order preference by similarity to ideal solution)法是用于研究與理想方案相似性的順序選優技術。可以理解為,數據越大越優,數據越小越劣,結合數據間的大小,計算正負理想解與評價對象的距離以及綜合得分,最后得出優劣方案的排序[2]。
TOPSⅠS分析通常分為以下幾步:①特征數據屬性正向化處理;②正向化矩陣標準化得到標準矩陣M③找出最優矩陣向量M+和最劣矩陣向量M-;④分別計算評價對象與正理想解距離D+或負理想解距離D-;⑤計算各評價對象與最優方案的相對近似度C,進行排序即可得到結果。由TOPSⅠS方法可知,對供應商的失信率、供貨率、供貨量標準差、平均供貨量、總體供貨量等評價指標進行正向化處理和標準化處理后,建立TOPSⅠS模型。
2.3 數據預處理
對所有特征數據進行正向化處理即把所有指標轉化為極大型,所有的數字越大,評分越高。對處理后的數據進行標準化處理,在多指標評價體系中,由于各評價指標的性質不同,通常具有不同的量綱,所以在數據樣本充足的情況下,往往直接使用標準化對數據進行無量綱預處理,便于不同指標之間進行加權和求和。
綜上可知,各個評價指標最終綜合表現為與正理想解的相對近似度。相對近似度越大,供應商越重要。該相對近似度大小的確定需要根據9個指標的數據進行求解,求解過程及結果在下面模型求解中給出。
2.4 模型的求解
假設有n個待評價對象,m個評價指標的標準矩陣為M。取最優矩陣向量M+,取最劣矩陣向量M-,然后計算評價對象與正理想解的距離、評價對象與負理想解的距離,即可計算各評價對象與最優方案的相對近似度C。
計算得到綜合排名前27的供應商如下:201、S140、S229、S361、S108、S151、S340、S282、S139、S275、S329、S308、S330、S395、S131、S356、S268、S306、S348、S194、S126、S352、S143、S307、S247、S284、S374。
3 遺傳算法模型
3.1 供應商最少
該問題要求在盡可能滿足生產需求的情況下選擇最少的供應商數量。根據供應商重要性排名,綜合考慮各供應商的供貨能力和供貨穩定性,考慮采用各供應商平均供貨量來表示各供應商每周的供貨能力。這里提出一個新的數量名詞,出產量φ,即供應商提供的貨物能為生產企業帶來的產能,然后在50家最重要的供應商中按順序累加其每周出產量直到滿足生產需求,求出最少供應商數,即計算出的最少供應商數n為22。
3.2 最經濟的訂購方案
模型的建立。該問題要求制定未來24周每周最經濟的原材料訂購方案,實際上就是要從上文中的50家供應商中組合出最經濟的方案。選擇使用遺傳算法進行迭代優化選擇,遺傳算法是根據基因變異的思想進行隨機優化的搜索方法,結合自適應的概率優化算法,能夠在全局范圍內尋找最優解,滿足題目要求,公式如下:
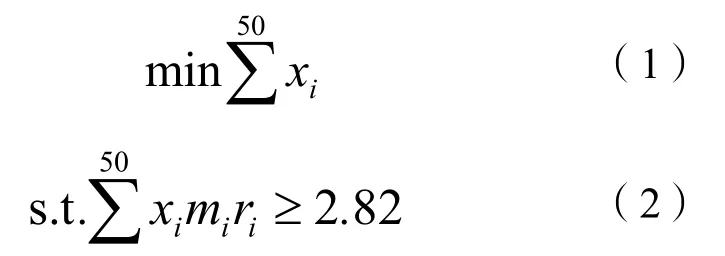
式(1)(2)中:xi為是否向第i個企業訂貨,xi=0或1;mi為第i個供應商的供貨量;ri為該企業所提供材料的系數。

這是個0-1背包問題,很難用傳統的線性規劃求解,故本題設計用遺傳算法來解決[3]。
首先,確定種群數量,給染色體編碼,隨機生產第一代種群;其次,確定個體評價方案,判斷是否滿足停止條件,若是則停止,輸出最優解,否則繼續進行操作,通常第一代種群不會滿足停止條件;最后,對種群進行選擇、交叉、變異操作,得到下一代種群,再進行評價,反復循環,直到滿足生產需求。
其中遺傳算法的主要流程如圖1所示。
根據圖1的算法流程,首先對種群進行編碼,然后初始化種群并進行多階段評價與選擇,在一般的遺傳算法中,通常只有一個評價和選擇階段。本文需要在滿足生產的條件下,還要求價格最低,所以首先以供貨量為評價指標來評價個體的適應性。在選擇過程中,按供貨量從大到小進行排序,淘汰后50%的個體。而第二階段的評價與選擇和上述過程一致,適應性指標換成了總價。選擇過程采用升序方式,選擇前50%的個體保留下來。
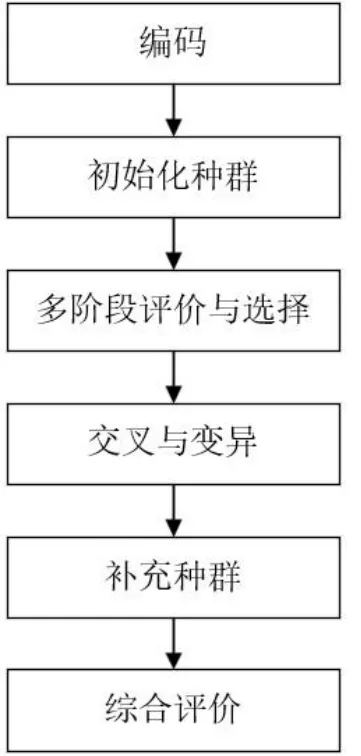
圖1 遺傳算法的流程
做完多階段評價與選擇后則進行交叉與變異和補充種群的操作。本算法在交叉和變異階段進行了種群個體數量的補充。在生物界,交叉出現的情況比變異多,故在交叉階段補充70%的個體,在變異階段補充30%的個體。
最后是綜合評價階段。在迭代完成后,將所有個體按照供貨量升序、價格降序聯合排序,找出最接近于2.82萬的個體作為輸出結果。
根據以上算法得出原材料訂購方案,如圖2所示。
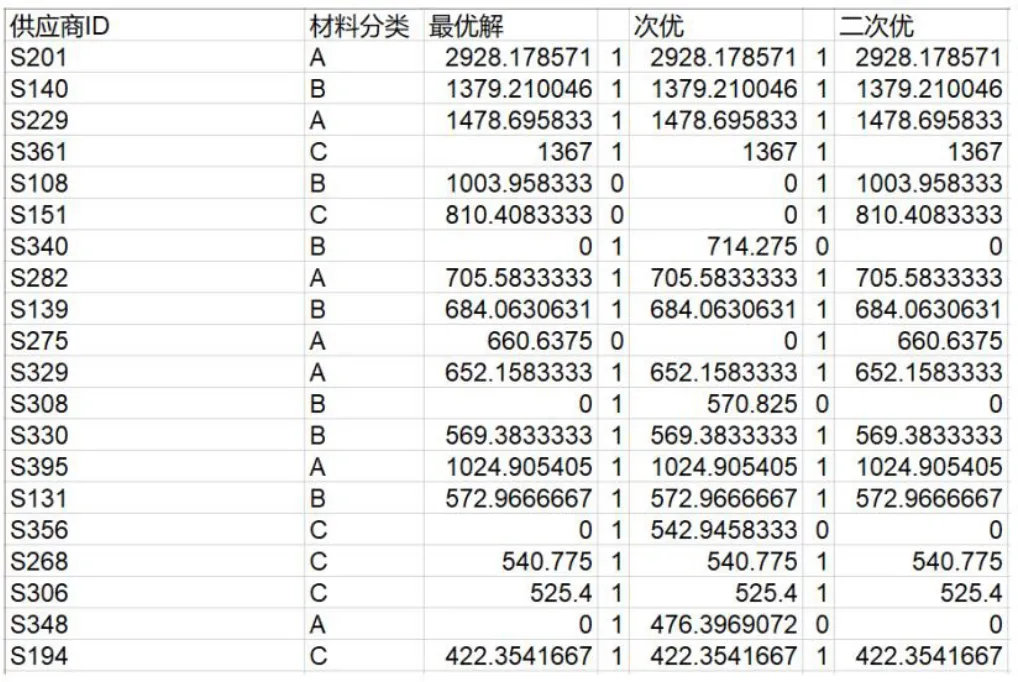
圖2 原材料訂購方案
圖2中展示了最優解、次優解和二次優解的訂貨方案。例如最優解中首先選擇了編號為S201的供應商,它的供貨量為2 982.178 571。同時,分析本文將最優解、次優解和二次優解三者之間的差異可知,最優解與次優解有20個不同的供應商。
4 模型評價與推廣
4.1 模型優點
采用遺傳算法的優點如下:①快速隨機的搜索能力;②搜索從群體出發,具有潛在的并行性,可以同時進行多個個體的比較;③搜索使用評價函數啟發,過程簡單。
采用Topsis綜合分析方法的優點如下:①不需要目標函數,是無人監督的分析方法;②對于數據分布及樣本量、指標多少無嚴格限制,可以既適用于小樣本資料,也適用于多評價單元、多指標的大系統。
4.2 模型缺點
采用遺傳算法的缺點如下:①遺傳算法的編程實現比較復雜,首先需要對問題進行編碼,找到最優解之后還需要對問題進行解碼;②另外3個算子的實現也有許多參數,如交叉率和變異率,并且這些參數的選擇嚴重影響解的品質,而目前這些參數的選擇大部分是依靠經驗。
采用Topsis綜合分析方法的缺點如下:①求解規范決策矩陣比較繁雜;②對于正理想解和負理想解的求解過程比較困難;③不確定指標的選取個數為多少,個數確定才能很好地去刻畫指標的影響力度。
猜你喜歡
石油瀝青(2021年4期)2021-10-14 08:50:44
世界科學技術-中醫藥現代化(2021年10期)2021-03-02 05:52:06
現代檢驗醫學雜志(2016年3期)2016-11-15 01:59:56
中學語文(2015年21期)2015-03-01 03:52:11
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
中國工程咨詢(2015年2期)2015-02-14 02:59:26
西南軍醫(2015年1期)2015-01-22 09:08:16
中國音樂教育(2014年9期)2014-05-20 10:26:24
治淮(2013年1期)2013-03-11 20:05:18
俄羅斯問題研究(2012年1期)2012-03-25 09:54:51
