基于大數(shù)據(jù)技術(shù)的分布式電商信息實(shí)時(shí)展示系統(tǒng)的設(shè)計(jì)與實(shí)現(xiàn)
2022-11-22 09:08:16李云鵬
信息記錄材料 2022年9期
李云鵬
(西北工業(yè)大學(xué) 陜西 西安 710129)
0 引言
隨著電子商務(wù)、移動(dòng)網(wǎng)絡(luò)以及社交軟件的興起,將我們推向了一個(gè)以PB(1024TB)為單位擁有海量信息的大數(shù)據(jù)時(shí)代。面對(duì)海量的數(shù)據(jù)信息,我們迫切需要以更高效的方法進(jìn)行數(shù)據(jù)挖掘、數(shù)據(jù)處理,這也是我們?cè)诖髷?shù)據(jù)時(shí)代所面臨的新挑戰(zhàn)。為解決數(shù)據(jù)的存儲(chǔ)和計(jì)算方面的難題,需要大數(shù)據(jù)技術(shù)來(lái)構(gòu)建大數(shù)據(jù)平臺(tái)[1]。傳統(tǒng)的大數(shù)據(jù)平臺(tái)包括Hadoop、Spark、Flink等。這些大數(shù)據(jù)平臺(tái)具有對(duì)海量數(shù)據(jù)進(jìn)行分析的能力,可以將海量數(shù)據(jù)轉(zhuǎn)化為生產(chǎn)力,從而產(chǎn)生實(shí)際價(jià)值。針對(duì)不同的數(shù)據(jù)類(lèi)型以及復(fù)雜的應(yīng)用場(chǎng)景,對(duì)數(shù)據(jù)的計(jì)算模式分為以下四種:批處理計(jì)算、流計(jì)算、圖計(jì)算以及查詢分析計(jì)算。本文將聚焦于流計(jì)算進(jìn)行探討。
在傳統(tǒng)的數(shù)據(jù)處理過(guò)程中,我們先將數(shù)據(jù)存入數(shù)據(jù)庫(kù)中,當(dāng)需要時(shí)再去數(shù)據(jù)庫(kù)中進(jìn)行檢索,將處理結(jié)果返回給請(qǐng)求的用戶,更多應(yīng)用于離線計(jì)算場(chǎng)景中。而針對(duì)實(shí)時(shí)性要求較高的場(chǎng)景,我們期望延時(shí)在秒甚至是毫秒級(jí)別,于是引出了一種新的數(shù)據(jù)計(jì)算結(jié)構(gòu)——流式計(jì)算,即對(duì)無(wú)邊界的數(shù)據(jù)進(jìn)行連續(xù)不斷地處理。當(dāng)今市面上主流的Spark平臺(tái),也推出了流式處理子框架——Spark Streaming。Spark Streaming是一個(gè)高吞吐、高容錯(cuò)、低延時(shí)的實(shí)時(shí)處理系統(tǒng),可以從Kafka、flume、kinesis或者TCP套接字等多種數(shù)據(jù)源中獲取數(shù)據(jù),然后利用復(fù)雜的操作(如map、reduce、window等)對(duì)數(shù)據(jù)進(jìn)行處理,最終將處理后的數(shù)據(jù)輸出到文件系統(tǒng)、數(shù)據(jù)庫(kù)或者控制臺(tái)上,具體的輸入輸出過(guò)程如圖1所示。本文基于流計(jì)算的算法,提出一種針對(duì)電商信息進(jìn)行實(shí)時(shí)展示的系統(tǒng)設(shè)計(jì)與實(shí)現(xiàn)方案。
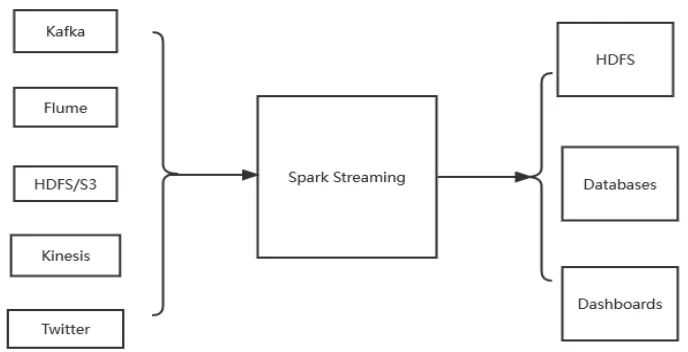
圖1 Spark Streaming框架的數(shù)據(jù)處理示意圖
1 環(huán)境部署
首先,為高效構(gòu)建分布式處理系統(tǒng),從而保證數(shù)據(jù)的高效處理,需在不同的數(shù)據(jù)節(jié)點(diǎn)分別部署好基于Linux(如Ubuntu、Debian等)系統(tǒng)運(yùn)行環(huán)境,以保證對(duì)海量實(shí)時(shí)數(shù)據(jù)能高效進(jìn)行模擬分析。本文推薦的大數(shù)據(jù)框架、數(shù)據(jù)庫(kù)系統(tǒng)、輔助中間件軟件及版本如下:Hadoop2.7.1,Spark2.4.0,Kafka2.11,Zookeeper3.6.3,MYSQL5.7.31。配置好基本的環(huán)境后,啟動(dòng)集群環(huán)境,啟動(dòng)了Zookeeper服務(wù)以及Kafka服務(wù)后,使用JPS命令進(jìn)行驗(yàn)證,如圖2所示。出現(xiàn)Master節(jié)點(diǎn)以及NameNode節(jié)點(diǎn),證明服務(wù)已經(jīng)成功啟動(dòng),系統(tǒng)具備可運(yùn)行條件。
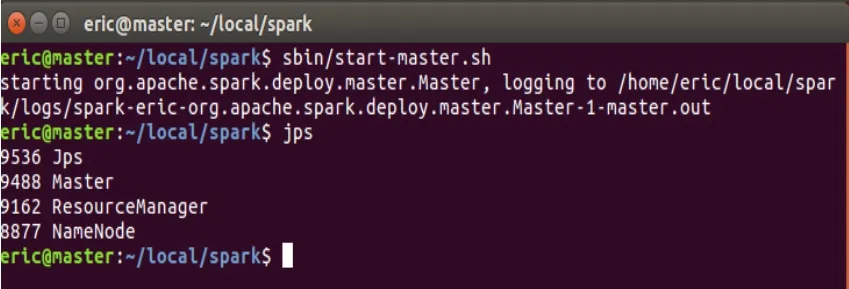
圖2 驗(yàn)證服務(wù)啟動(dòng)
2 核心技術(shù)概述
2.1 Spark Streaming流計(jì)算處理框架
與其他大數(shù)據(jù)框架Storm、Flink一樣,Spark Streaming是在Spark Core(一種基于RDD數(shù)據(jù)抽象,用于數(shù)據(jù)并行處理的基礎(chǔ)組件)基礎(chǔ)之上用于處理實(shí)時(shí)計(jì)算業(yè)務(wù)的框架[2]。其實(shí)現(xiàn)原理就是把輸入的流數(shù)據(jù)按時(shí)間切分,切分的數(shù)據(jù)塊用離線批處理的方式進(jìn)行并行計(jì)算。輸入的數(shù)據(jù)流經(jīng)過(guò)Spark Streaming的receiver組件,數(shù)據(jù)被切分為DStream,然后DStream被Spark Core的離線計(jì)算引擎執(zhí)行并行計(jì)算。Spark Streaming與其他主流框架的對(duì)比如表1所示。
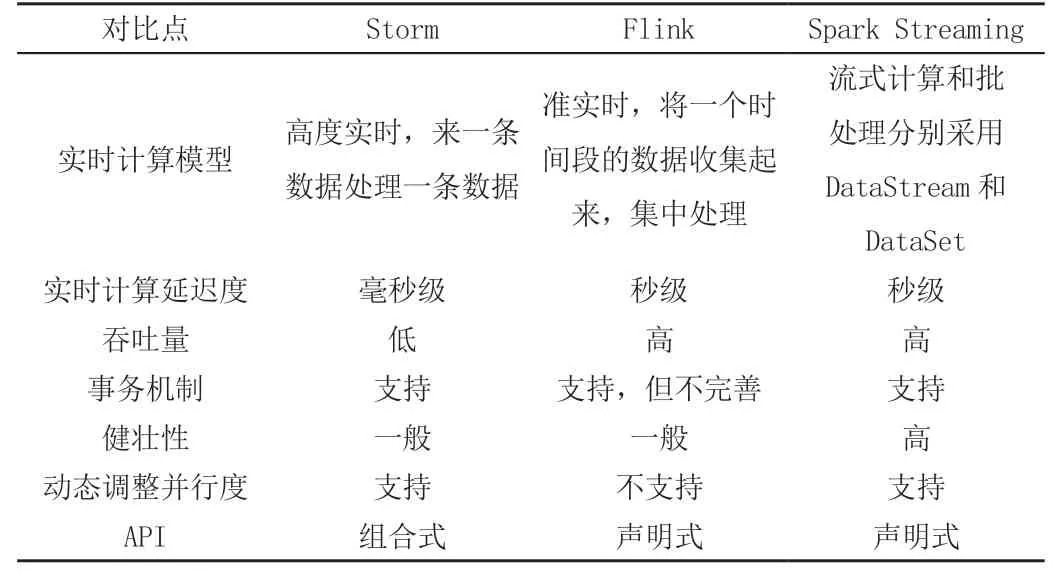
表1 Spark Streaming與其他主流框架的主要性能對(duì)比
2.2 Kafka分布式發(fā)布訂閱消息體系
Kafka是一種高吞吐量的分布式發(fā)布訂閱消息系統(tǒng),以生產(chǎn)者/消費(fèi)者模式,通過(guò)隊(duì)列交換數(shù)據(jù),在實(shí)時(shí)計(jì)算領(lǐng)域有著非常強(qiáng)大的功能。本系統(tǒng)主要利用Spark Streaming計(jì)算框架實(shí)時(shí)地讀取Kafka中的電商數(shù)據(jù)然后進(jìn)行并行計(jì)算。Kafka在本系統(tǒng)中起到了一個(gè)中間件的作用,即搭建了程序間的數(shù)據(jù)管道,用來(lái)轉(zhuǎn)換并響應(yīng)實(shí)時(shí)數(shù)據(jù)[3]。
2.3 WebSocket通信機(jī)制
WebSocket是HTML5中服務(wù)端和客戶端進(jìn)行雙向文本或二進(jìn)制數(shù)據(jù)通信的一種新協(xié)議。它與HTTP通信協(xié)議不同的是,WebSocket提供全雙工通信[4]。對(duì)于傳統(tǒng)的HTTP通信方式,只有當(dāng)客戶端發(fā)起請(qǐng)求后,服務(wù)器端才會(huì)發(fā)送數(shù)據(jù)。而WebSocket則可以讓服務(wù)器主動(dòng)發(fā)送數(shù)據(jù)給客戶端,是服務(wù)器推送技術(shù)的一種[5]。由于本系統(tǒng)后臺(tái)產(chǎn)生新的數(shù)據(jù),需要在前臺(tái)頁(yè)面實(shí)時(shí)展示出來(lái),故選擇了WebSocket通信機(jī)制。
本系統(tǒng)借助的Flask-socketio模塊,封裝了Flask對(duì)WebSocket的支持,WebSocket在連接建立階段是通過(guò)HTTP的握手方式進(jìn)行的,當(dāng)連接建立后,客戶端和服務(wù)端之間就不再進(jìn)行HTTP通信了,所有信息交互都由WebSocket接管。Flask-SocketIO使Flask應(yīng)用程序可以訪問(wèn)客戶端和服務(wù)器之間的低延遲雙向通信,使客戶端建立與服務(wù)器的永久連接。
2.4 基于Scrapy的爬蟲(chóng)框架
Scrapy是由Python基于twisted框架開(kāi)發(fā)的一種高效、快速的web信息抓取框架,用于抓取web站點(diǎn)并從頁(yè)面中提取結(jié)構(gòu)化的數(shù)據(jù),只需要少量的代碼,就能高效地獲取所需數(shù)據(jù)。Scrapy集成了高性能異步下載、隊(duì)列、分布式、解析、持久化等諸多功能。值得注意的是,由于網(wǎng)站數(shù)據(jù)具有一定的商業(yè)價(jià)值,需科學(xué)合理地使用爬蟲(chóng)工具進(jìn)行數(shù)據(jù)獲取,本系統(tǒng)所獲取的數(shù)據(jù)僅用于學(xué)術(shù)探索,且已經(jīng)獲取相關(guān)網(wǎng)站授權(quán)。
3 電商信息實(shí)時(shí)展示系統(tǒng)詳細(xì)設(shè)計(jì)
網(wǎng)上購(gòu)物,作為一種依托于互聯(lián)網(wǎng)的新型購(gòu)物方式,為人們的生活帶來(lái)了不少的便利。諸如淘寶、京東、亞馬遜等眾多電商平臺(tái)產(chǎn)生了大量的購(gòu)物數(shù)據(jù),通過(guò)合法的爬蟲(chóng)技術(shù)實(shí)時(shí)爬取這些數(shù)據(jù),并進(jìn)行可視化分析,從數(shù)據(jù)中提取關(guān)鍵信息,從而有利于對(duì)電商平臺(tái)進(jìn)行升級(jí)。因此,基于大數(shù)據(jù)相關(guān)技術(shù)(Spark Streaming+Kafka+We bsocket+Scrapy)本文設(shè)計(jì)并開(kāi)發(fā)了電商信息實(shí)時(shí)展示系統(tǒng),后期通過(guò)源碼剖析,針對(duì)并行化的方向進(jìn)行了系統(tǒng)的優(yōu)化升級(jí)。
3.1 總體設(shè)計(jì)
在本系統(tǒng)中,通過(guò)爬取到的電商平臺(tái)的交易數(shù)據(jù)及購(gòu)物日志(注:此類(lèi)信息為電商平臺(tái)主動(dòng)公布,僅作學(xué)術(shù)研究,不涉及版權(quán)問(wèn)題;如個(gè)別電商平臺(tái)未公布,需與平臺(tái)進(jìn)行聯(lián)系,以免侵權(quán)),模擬實(shí)時(shí)數(shù)據(jù)流的產(chǎn)生,用Spark Streaming框架分析每秒購(gòu)物人數(shù),每秒鐘平臺(tái)上用戶的操作類(lèi)型等,并利用WebSocket將數(shù)據(jù)實(shí)時(shí)推送給客戶端,最后瀏覽器將接收到的數(shù)據(jù)實(shí)時(shí)展現(xiàn)在web端,進(jìn)行了數(shù)據(jù)的可視化展示。本系統(tǒng)采用模塊化設(shè)計(jì)思路,共分為以下四個(gè)模塊:數(shù)據(jù)獲取模塊、實(shí)時(shí)數(shù)據(jù)模擬模塊、Spark Streaming實(shí)時(shí)處理模塊以及可視化展示模塊。本系統(tǒng)總體架構(gòu)圖如圖3所示。
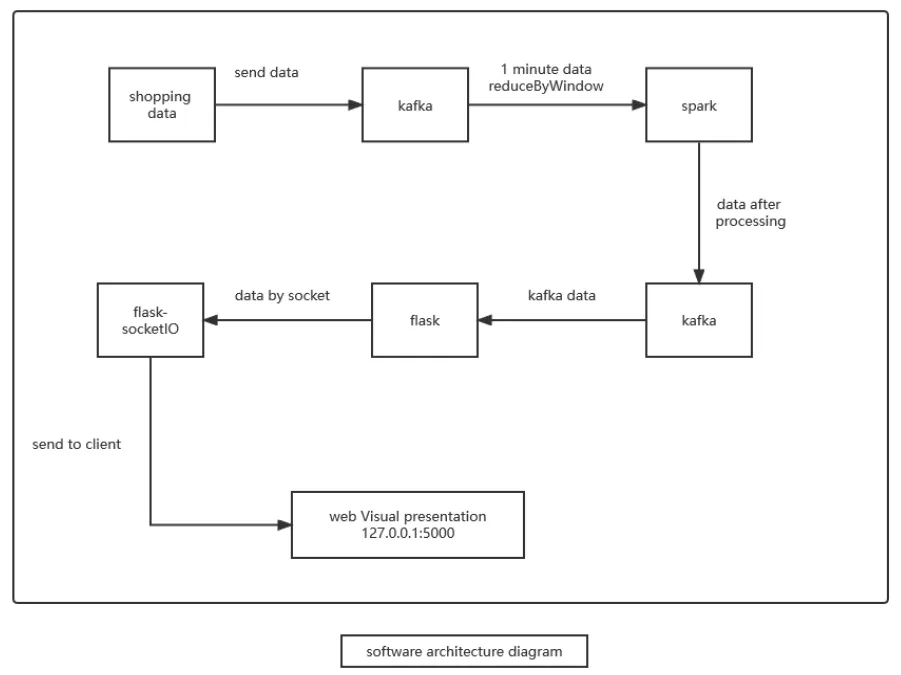
圖3 系統(tǒng)總體架構(gòu)圖
3.2 數(shù)據(jù)獲取模塊設(shè)計(jì)
數(shù)據(jù)獲取模塊通過(guò)爬蟲(chóng)技術(shù),借助Python提供的Scrapy、Requests等庫(kù),爬取電商平臺(tái)的購(gòu)物日志,并以csv的格式存儲(chǔ)到了本地。由于僅做研究使用,本系統(tǒng)中需要關(guān)注的數(shù)據(jù)只有:gender項(xiàng),其中0表示女性,1表示男性,2和NULL表示未知性別;action項(xiàng),其中0表示點(diǎn)擊行為,1表示加入購(gòu)物車(chē),2表示購(gòu)買(mǎi),3表示關(guān)注商品;cat_id項(xiàng),表示商品類(lèi)別id。該數(shù)據(jù)集包含上萬(wàn)條用戶購(gòu)物日志,可模擬大批量的實(shí)時(shí)數(shù)據(jù)。然后實(shí)時(shí)數(shù)據(jù)模擬模塊把對(duì)數(shù)據(jù)進(jìn)行預(yù)處理后發(fā)送給Kafka,接下來(lái)Spark Streaming再接收gender數(shù)據(jù)進(jìn)行后續(xù)處理。
3.3 實(shí)時(shí)數(shù)據(jù)模擬模塊設(shè)計(jì)
該模塊需要啟動(dòng)Kafka服務(wù),實(shí)例化多個(gè)Kafka生產(chǎn)者,用于讀取用戶日志文件。每次讀取一行或多行,對(duì)關(guān)注的數(shù)據(jù)進(jìn)行清洗后,每隔固定時(shí)間發(fā)送給Spark Streaming實(shí)時(shí)處理模塊,這樣在固定時(shí)間間隔內(nèi),可發(fā)送一定數(shù)量的購(gòu)物日志,以便后期進(jìn)行可視化展示。
3.4 Spark Streaming實(shí)時(shí)處理模塊設(shè)計(jì)
該模塊為整個(gè)系統(tǒng)的核心模塊,基于Spark流計(jì)算的模式按秒來(lái)處理Kafka發(fā)送來(lái)的數(shù)據(jù)流。利用Spark Streaming接口reduceByKeyAndWindow,設(shè)置窗口大小和滑動(dòng)步長(zhǎng)進(jìn)行數(shù)據(jù)處理、格式轉(zhuǎn)換等操作,并把檢查點(diǎn)文件寫(xiě)入分布式文件系統(tǒng)HDFS。最后,再實(shí)例化一個(gè)KafkaProducer實(shí)例,用于向Kafka投遞消息,這里發(fā)送數(shù)據(jù)的topic為result。由于Web端最后可視化展示所需要的數(shù)據(jù)又來(lái)自Kafka,所以可以實(shí)例化一個(gè)KafkaConsumer來(lái)測(cè)試實(shí)時(shí)處理模塊是否已經(jīng)把處理后的數(shù)據(jù)發(fā)送到“result”的topic上,測(cè)試結(jié)果如圖4所示。

圖4 測(cè)試結(jié)果
3.5 可視化展示模塊設(shè)計(jì)
本模塊主要利用Flask-SocketIO接收來(lái)自kafka的處理后的數(shù)據(jù),并將結(jié)果實(shí)時(shí)推送到瀏覽器端,同時(shí)存入MySQL數(shù)據(jù)庫(kù)進(jìn)行數(shù)據(jù)備份。通過(guò)編寫(xiě)對(duì)應(yīng)的html文件以及js文件,實(shí)時(shí)接收服務(wù)端的消息,利用pycharts在web端繪制可交互的圖表,將結(jié)果實(shí)時(shí)進(jìn)行展示。值得一提的是,該可視化圖表均為動(dòng)態(tài)展示效果,隨著時(shí)間變化實(shí)時(shí)數(shù)據(jù)改變,圖表也隨之而變化。后期,針對(duì)不同的數(shù)據(jù),均可進(jìn)行不同形式的可視化展示。部分效果圖如圖5、圖6所示。
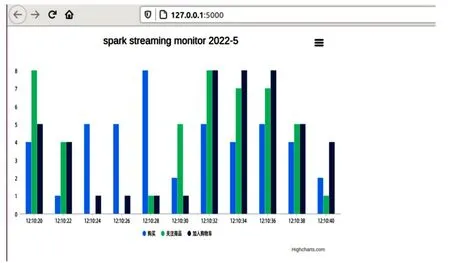
圖5 效果圖1
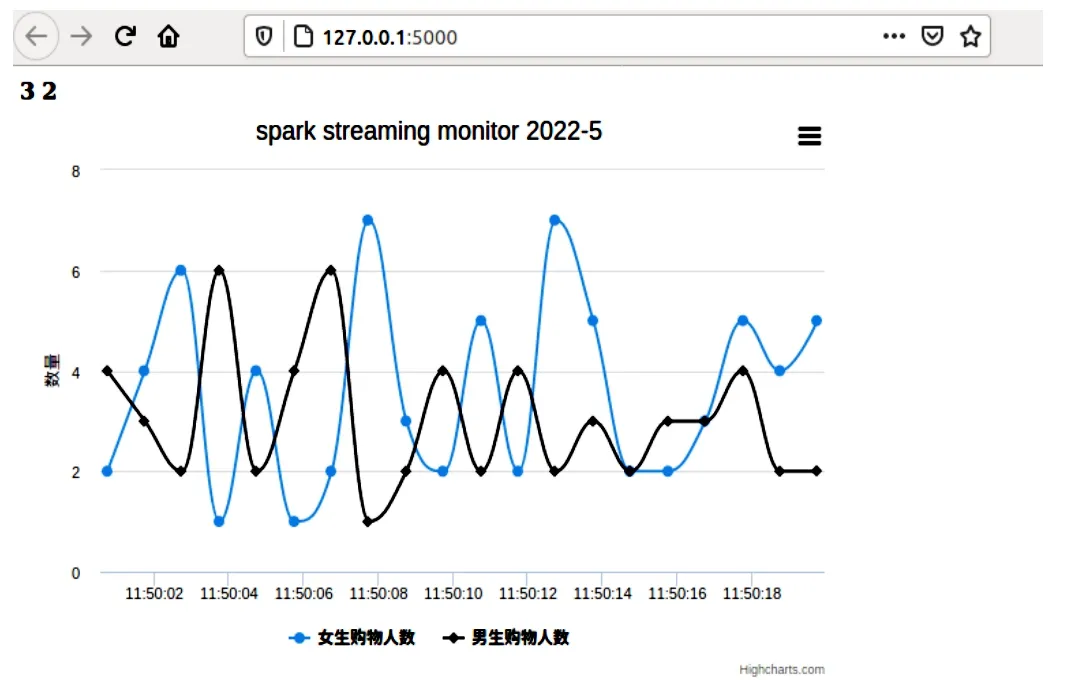
圖6 效果圖2
4 結(jié)語(yǔ)
綜上所述,本文基于分布式大數(shù)據(jù)技術(shù),設(shè)計(jì)并實(shí)現(xiàn)了電商信息實(shí)時(shí)展示系統(tǒng),可以實(shí)時(shí)模擬流數(shù)據(jù),并借助Spark Streaming對(duì)數(shù)據(jù)進(jìn)行處理,并做可視化動(dòng)態(tài)展示。針對(duì)系統(tǒng)的優(yōu)化問(wèn)題,參考了Spark框架中的部分開(kāi)源代碼,進(jìn)行了分析測(cè)試,選用了高性能算子,替代常規(guī)的算子,達(dá)到性能上的提升。通過(guò)Spark Streaming、Kafka、WebSocket等技術(shù),可將此開(kāi)發(fā)模式復(fù)制到其他類(lèi)似應(yīng)用場(chǎng)景,對(duì)海量數(shù)據(jù)實(shí)時(shí)處理提供了一種可行的解決方案。
猜你喜歡
工業(yè)設(shè)計(jì)(2022年8期)2022-09-09 07:43:20
北京測(cè)繪(2022年6期)2022-08-01 09:19:06
師道·教研(2022年1期)2022-03-12 05:46:47
云南化工(2021年8期)2021-12-21 06:37:54
北京測(cè)繪(2021年7期)2021-07-28 07:01:18
軍民兩用技術(shù)與產(chǎn)品(2021年10期)2021-03-16 06:05:30
北京測(cè)繪(2020年12期)2020-12-29 01:33:58
海洋信息技術(shù)與應(yīng)用(2020年1期)2020-06-11 12:43:56
裝備制造技術(shù)(2019年12期)2019-12-25 03:06:46
傳媒評(píng)論(2019年4期)2019-07-13 05:49:14
