基于多階段雙殘差網絡的圖像去雨模型
2022-11-24 01:53:34周冬明
無線電工程 2022年11期
楊 浩,周冬明,趙 倩,李 淼
(云南大學 信息學院,云南 昆明 650504)
0 引言
雨天采集到的圖像因為存在大量的雨條紋,造成關鍵細節模糊和被遮擋,使得圖像質量下降。這不僅嚴重影響人類的視覺感知,而且對圖像分類[1]、目標檢測[2]和圖像分割[3]等各種高級計算機視覺任務的執行帶來干擾。因此,近年來圖像去雨方法受到國內外廣泛關注[4-5]。圖像去雨是為了從雨天采集到的圖像中恢復干凈的背景圖像,這是一個具有挑戰性的逆向問題。
目前,針對這個逆向問題已經做了大量工作,這些方法主要可以分為2類:基于視頻數據的去雨算法[6]和基于單幅圖像的去雨算法[4-5]。基于視頻的去雨算法可以利用前后相鄰幀的信息進行融合,從而大大降低了去雨的難度。而基于單幅圖像的去雨算法無法利用這個信息,且雨線的隨機分布特性使雨條紋的位置難以確定,因此單幅圖像去雨一直是一個極其困難的問題。由于有雨的視頻也是由多幀有雨圖像構成,所以單幅圖像去雨算法不僅可以處理單幅圖像,也可以用于處理視頻的每一幀圖像來實現視頻去雨。因此,單幅圖像的去雨算法具有重要的研究意義和廣泛的應用前景。
在深度學習被用于單幅圖像去雨處理之前,傳統的圖像去雨算法主要是基于先驗的圖像去雨方法。這些方法通過對圖像雨線層施加各種先驗[4,8-9]并通過多次迭代優化來去除雨線。然而,這些去雨方法模型建立復雜、計算量大,并且去雨效果不理想,去雨后的圖片細節大量丟失且有雨條紋殘留。針對這些缺點,數據驅動的基于深度學習的方法通過卷積神經網絡從數據中學習特征,并以端到端的方式將雨圖像直接映射到無雨圖像。基于深度學習的圖像去雨方法比起傳統去雨算法獲得了前所未有的成功[10-13]。然而,大多數方法仍無法有效保留帶有較多雨線場景的背景圖像細節,現有方法往往在雨痕去除和細節保持之間進行折中,導致輸出圖像細節模糊和存在偽影等,大大地影響了單幅圖像去雨算法的實際應用。
為了解決以上問題,本文提出了一種基于多階段雙殘差網絡的圖像去雨。相比其他方法,使用多階段網絡將圖像去雨問題分解為多個子問題并逐漸去除雨線,從而能夠更徹底地去除雨線。相比起其他多階段方法,本文算法的優點在于不同階段間的信息進行交換。通過不同階段的信息交換不僅能減少信息在不同階段傳輸過程中的丟失,還簡化了數據流使網絡優化更加穩定。此外,本文提出了一個雙殘差圖像重建網絡,與傳統殘差網絡相比,該網絡擁有更多恒等映射路徑,減少了信息丟失。最后,通過一個有監督的注意力機制在無雨圖像的監督下實現將上一階段的有用特征傳遞到下一階段進行圖像重建,豐富了下一階段的特征。通過在4個合成數據集和1個真實數據集上對實驗結果的客觀評價和主觀評價,本文提出的去雨算法相較于其他算法而言,色彩失真更小,圖像細節恢復更好。同時,還在后續高級計算機視覺任務上對本文的去雨圖像進行測試,本文算法能夠有效提高后續計算機視覺任務的精度。
1 相關工作
1.1 基于先驗的去雨算法
傳統的圖像去雨算法往往被看作是一個圖像先驗信息的優化問題。基于先驗的方法是利用各種先驗或假設對雨痕的方向、密度和尺寸進行建模,然后利用該模型進行去雨。Kim等[4]建立了一個橢圓形的核函數,分析每個像素位置橢圓核的旋轉角度和縱橫比來檢測雨條紋區域,然后通過自適應選擇非局部鄰域像素及其權重,對檢測到的雨痕區域進行非局部均值濾波來去除雨條紋。Kang等[14]利用雙邊濾波器將圖像分解為低頻和高頻部分,然后通過字典學習和稀疏編碼將高頻部分分解為“雨分量”和“非雨分量”,從圖像中移除雨線分量。Chen等[15]的方法既不需要雨點檢測,也不需要耗時的字典學習階段。相反,由于雨條紋在成像場景中往往表現出相似和重復模式,提出了一種從矩陣到張量結構的低秩模型來捕捉與時空相關的雨條紋。Li等[5]通過對背景層和雨紋層都施加高斯混合模型約束來去除雨條紋,這些約束可以適應各種背景外觀以及雨帶的形狀,相比其他傳統方法能夠更好地去除雨條紋。基于傳統算法的圖像去雨在去除較小的雨條紋時取得了不錯的效果,但對于大雨或驟雨產生的雨條紋,傳統算法幾乎無法去除雨條紋。
1.2 基于深度學習的去雨算法
近幾年,隨著深度學習技術的日漸成熟,深度學習被逐漸應用于圖像去雨領域,基于深度學習的圖像去雨算法不再依賴于先驗知識,而是直接估計雨線的生成模型。Fu等[16]第一次將深度卷積神經網絡用于單幅圖像去雨,首先將圖像分為細節層和基礎層,然后直接從合成數據集中學習雨天圖像細節層與真實圖像細節層之間的非線性映射關系,通過優化目標函數來提升去雨效果,而不是增加卷積層的數量。Yang等[17]為了更好地去除真實場景下的雨線,提出了一種新的雨圖模型和去雨架構,在現有模型的基礎上標出雨水的位置,網絡根據提取到的特征,先檢測雨水位置再估計雨線,最后提取出背景層來完成去雨,另外,還將去雨視作多階段任務進行循環操作,每個循環過程都執行上述操作以達到更好的去雨效果。Fu等[18]基于殘差網絡的啟發,加深了去雨網絡的深度,提出了深度細節網絡,將雨圖分解為高頻部分和低頻部分,并且將高頻部分映射到雨紋層,從而縮小了有雨圖像到干凈圖像的映射范圍,使得學習過程變得更加容易。為了進一步提高去雨效果,在訓練過程中利用先驗圖像域知識對高頻信息進行提取,從而去除背景干擾,使模型聚焦于圖像中的雨條紋,從而更好地去雨。Li等[19]提出了一種采用空洞卷積增大感受野來逐階段去除雨紋的架構,該架構將去雨過程分為幾個階段,在去雨的每一個階段使用一個具有多個空洞卷積的上下文擴展網絡,每個通道對應一個去雨模式,并且利用遞歸神經網絡(Recurrent Neural Network,RNN)來保存前一階段的有效信息,從而有利于下一階段的去雨。Wei等[20]使用半監督學習方法,通過有監督學習下合成的雨條紋來適應真實無監督學習中的雨條紋,通過這種方式來提高去雨模型的泛化能力,以此解決有雨數據集缺少問題。Ren等[21]考慮到大量堆疊網絡層數會導致參數增多并且造成過擬合,從而不考慮使用更深、更復雜的模型,轉而使用多個階段來解決問題,在去雨的每個階段使用遞歸運算讓每個階段的網絡參數共享,從而大幅減少了網絡參數,并且取得了很好的去雨效果。Jiang等[22]考慮到雨線與相機之間距離的不同會導致不同雨線有不同程度的尺寸和模糊度,因此采用多個分辨率和多個尺度之間的互補信息來表示雨條紋,從輸入圖像尺度和層次深度特征的角度來探討雨條紋的多尺度協同表示來去除雨條紋,對于不同位置的相似雨型,采用遞歸計算得到全局紋理,并且在空間維度上挖掘出互補和冗余的信息來表示目標雨型,從而完成去雨。Wang等[23]考慮到現有的基于深度學習的去雨方法缺乏可解釋性,提出了一種雨核模型與深度學習相結合的去雨方法來更徹底地去除雨線。Chen等[24]基于控制理論中的反饋機制提出了一種基于錯誤檢測和誤差補償的方法來去除雨線。Fu等[25]考慮到基于深度卷積神經網絡的去雨方法大多都是通過疊加普通卷積層來實現,而這些卷積層通常只能考慮到局部關系而很少考慮全局信息,由此提出了一種雙圖卷積神經網絡進行圖像去雨,第1個圖卷積神經網絡用于提取特征圖中像素間的全局位置信息,第2個圖卷積神經網絡用于提取特征圖跨通道的全局信息。與普通的卷積神經網絡相比,2個圖卷積神經網絡能從一個新的維度提取特征,從而能夠更好地處理復雜空間的長雨紋。Zamir等[26]提出了一個多階段圖像恢復架構,在前2個階段使用編碼器-解碼器架構來提取圖像的多尺度特征,而在最后一個階段對原始分辨率的圖像進行直接處理來保證圖像細節不丟失,在每2個階段之間采用一個有監督注意力機制模塊來保證每個階段都能利用恢復以后的圖像信息,該網絡不僅在每個階段的前后進行跳躍連接,還在不同階段之間進行信息交換,從而避免信息在傳播過程中丟失。
基于深度學習的單幅圖像去雨算法相比傳統算法在去雨效果上獲得了很大的進步,但目前基于深度學習的算法還存在一些問題。Ren等[21]提出的多階段去雨算法,雖然參數量很少,但只是單一地采用遞歸來運算,而忽略每個階段之間有用信息的交換。Jiang等[22]雖然加強了雨圖特征的提取,但僅僅采用單一階段來去雨使得去雨不徹底。Zamir等[26]使用多個階段逐漸去雨,但是忽略了深層次特征提取的重要性。
2 本文方法
2.1 網絡總體架構
提出的網絡總體框架如圖1所示,在每個階段的開始有一個特征提取網絡,該模塊能夠提取圖像的各種雨線細節和多尺度特征。隨后緊跟一個通道注意力(Channel Attention,CA)模塊,為不同的通道分配不同的加權參數,從而使得有用特征傳到下一階段。在雙殘差圖像重建網絡中,使用雙殘差網絡來對圖像進行恢復。在前2個階段的最后,使用一個有監督注意力模塊,在標簽圖像的監督下只允許有用特征傳播到下一階段。在去雨的3個階段中,本文算法并不是簡單地將3個階段串接起來,而是在各個階段之間使用特征融合模塊把不同階段之間的信息進行融合,從而防止圖像細節信息在連續傳播過程中丟失。
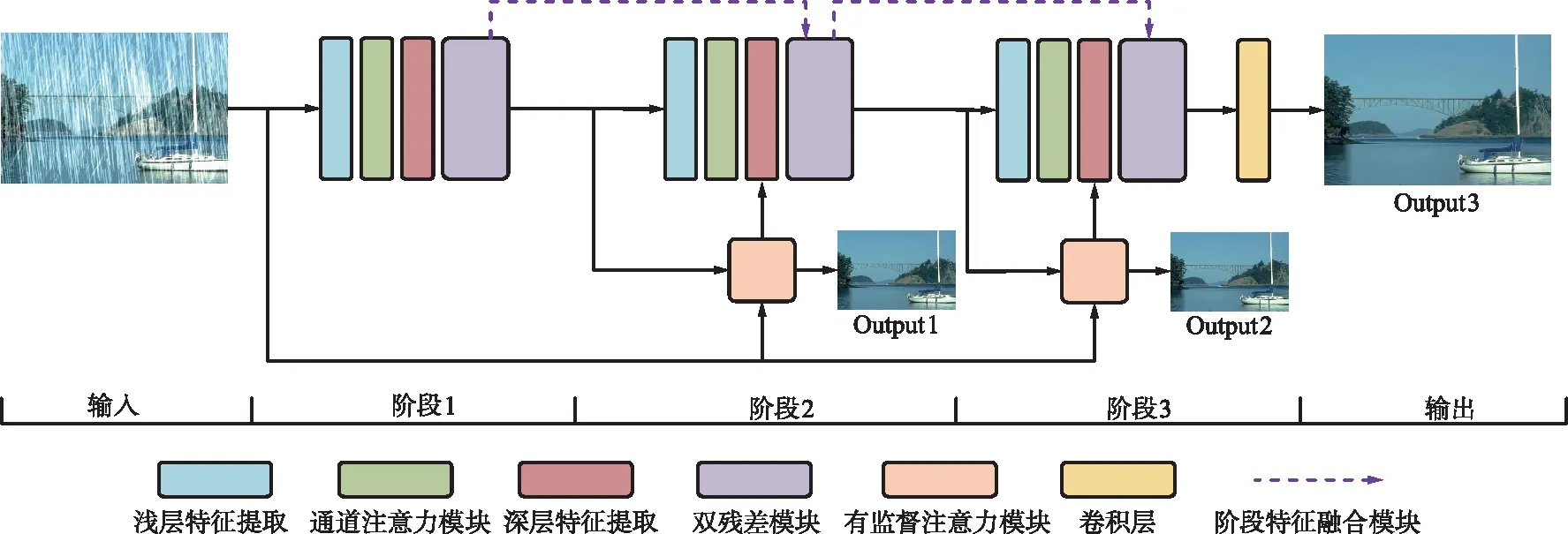
圖1 網絡總體框架
2.2 雙殘差圖像重建網絡
殘差網絡(ResNet)是為了解決傳統的深層神經網絡中層數過深而出現退化現象而提出的。文獻[27]指出,濫用網絡層數不僅不能提升網絡的學習能力,使用更深層的網絡效果反而會更差。本文提出的雙殘差圖像恢復網絡如圖2所示,該網絡不僅在每個殘差塊中添加一個跳躍連接,還在每個殘差塊的中間和下一個殘差塊的中間額外添加了一個跳躍連接,為網絡提供了更多的恒等映射通道,從而降低整體訓練難度和梯度下降的訓練速度,也防止信息在傳播過程中的消失。受Liu等[28]啟發,本文使用普通卷積層和空洞卷積層相結合,在擴大感受野的同時能夠保留細化的特征,同時加入SE-ResNet[29]以獲取全局感受野。本文的圖像恢復網絡由6個雙殘差堆疊塊組成,并且從輸入到輸出的最外層使用殘差連接。前3個為DRB(Dual-residual Block),后3個為DRBS(Dual-residual Block with SE-ResNet)。DRB由2個普通卷積和2個空洞卷積構成,對于普通卷積均使用3×3卷積核,而3個DRB中空洞卷積的膨脹速率逐漸減小,分別為12,8和6,從而能夠使網絡在連續的3個DRB中以從粗到細的方式定位雨線。DRBS均采用普通的3×3卷積核,并且在最后加入SE-ResNet[25]來獲得全局感受野。在圖像恢復模塊中,所有卷積核后面均使用ReLU激活函數。該模塊輸入為特征提取模塊的特征圖,輸出特征圖被傳遞到下一階段。

圖2 雙殘差圖像恢復網絡
2.3 特征提取模塊
淺層網絡因為層數淺,具有較小的感受野,所以輸出得到的特征圖包含更多的局部信息,從而能更好地提取圖像的紋理特征和細節特征等淺層特征。而深層網絡具有更大的感受野,所以能夠提取更多的全局信息,比如圖像的輪廓特征和形狀特征等深層特征。本文在每個階段的開始使用一個淺層特征提取模塊,通過一個CA模塊后輸入到深層特征提取模塊進行深層特征提取,然后將深層特征提取模塊輸出的特征圖傳輸到雙殘差網絡。
為提取淺層特征,本文在圖像輸入部分使用一個3×3的卷積進行淺層特征提取。在該卷積之后為一個CA模塊,使得更有用的淺層特征通過該模塊。CA模塊之后使用一個具有8個殘差塊的殘差網絡進行深層特征提取。深層特征提取模塊如圖3所示,由2個卷積和一個ReLU激活函數組成。特征提取模塊為:

圖3 深層特征提取模塊
RB(x)=C(δ(C(x))),
(1)
FEM(x)=RBt(RBt-1,RBt-2,…,RBo(x)),
(2)
式中,C表示卷積;δ為ReLU激活函數;RB為殘差塊;FEM為特征提取模塊。
為了逐步融合來自上一階段雙殘差網絡的特征,提出了一個特征融合模塊(Feature Fusion Module,FFM),如圖4所示。來自雙殘差網絡第2個DRB和第1個DRBS的特征圖被輸送到FFM中。在FFM中,輸入的2個特征圖首先通過2個CA對不同通道的特征進行加權,然后把來自2個卷積的特征圖拼接,最后通過一個1×1卷積進行通道合并。在FFM中的所有卷積后面均使用ReLU激活函數。殘差塊采用跳躍連接的方式將信息傳遞到更深層,解決了深層次網絡中的梯度消失問題,從而提升網絡的學習能力。
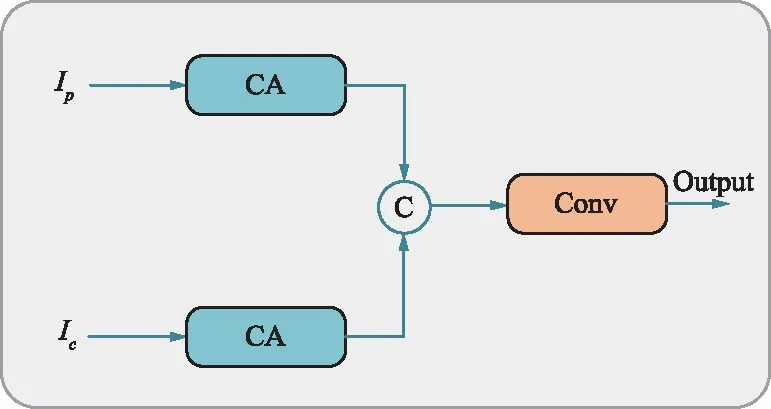
圖4 特征融合模塊
2.4 有監督注意力機制
現有的多階段圖像去雨網絡大多直接把上一階段得到的去雨圖像信息傳遞到下一個連續的階段,從而向下一階段傳遞了很多冗余的特征。受Zamir等[26]啟發,本文算法在前后2個階段之間引入一個使用標簽圖像進行監督的注意力模塊,如圖5所示。在標簽圖像的監督下,該模塊利用前一階段的輸出來計算注意力圖,這些注意力圖被用來提取上一階段的有用特征,使得上一階段的特征能夠有選擇性地傳遞到下一階段,該模塊的計算如下:
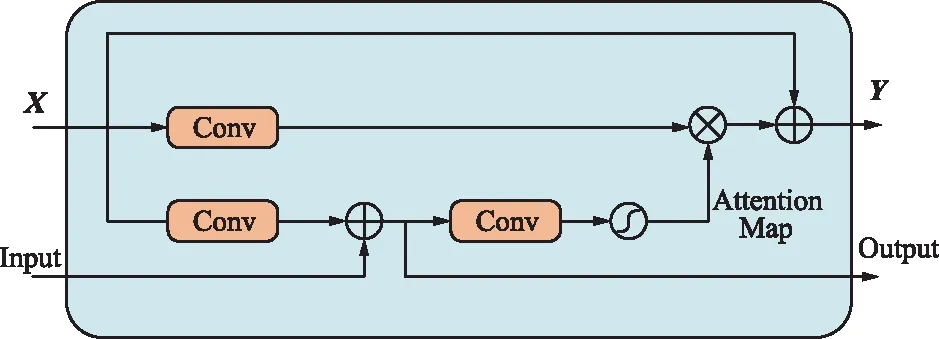
圖5 有監督注意力機制
F=SAM(X,I)=Att?C(X)+X,
(3)
Att=σ(C(C(X)+I)),
(4)
O=C(C(X)+I),
(5)
式中,F為傳到下一階段的有用特征;X為上一階段的輸出;Att為注意力圖;I為去雨前的圖片;O為該階段去雨后的圖片。
該模塊為每個階段提供了無雨圖片的監督信息。在標簽圖像的局部監督下,利用標簽圖像的信息和前一階段的輸出來計算注意力圖,進而調整輸出來抑制當前階段無用的信息特征,只允許有用的信息傳遞到下一個階段。
2.5 損失函數
用于訓練網絡的廣泛使用的損失函數是均方誤差(Mean Square Error,MSE)。然而,由于MSE平方項的過度懲罰,通常會產生過度平滑的結果,不利于恢復清晰的圖像細節。為了獲得擁有更多細節的視覺效果,本文使用結構相似性(Structural Similarity,SSIM)作為損失函數。通過計算去雨輸出圖像和無雨標簽圖像的SSIM,對SSIM取負值作為網絡的損失函數,計算如下:
(6)
式中,uX和uY分別表示去雨圖像X和標簽Y圖像的均值;σXY表示去雨圖像和標簽圖像的協方差;常數C1和C2是為了避免分母為零,本文根據經驗取C1=0.01,C2=0.03[26]。SSIM用X和Y的均值作為亮度的估計,二者的方差作為對比度的估計、協方差作為整體圖像結構相似程度的度量。
本文算法的總體損失函數定義如下:
(7)
式中,S為階段數;XS為第S個階段經過網絡去雨以后的圖像;Y為無雨標簽圖像。將3個階段輸出的SSIM求和后取負值得到損失值。
3 實驗結果與分析
本文提出的網絡架構基于Pytorch實現,實驗所使用的環境為Windows10,處理器為Intel(R)Core(TM)i7-10700K CPU@5.1 GHz,32G RAM,顯卡為單個NVIDIA GeForce RTX 3090。訓練時對圖像進行隨機剪裁的方式進行處理,輸入到模型的圖片大小為128 pixel×128 pixel。使用ADAM優化器對模型進行訓練,其中動量參數β1與β2分別為0.9和0.999,模型初始學習率為2×10-4,進行1 000次迭代,使用余弦衰減策略逐漸減少到1×10-6,Batch size為4。本文選擇最近的公開源代碼的去雨算法進行對比實驗,包括經典的去雨算法GMM[5],DSC[8]和基于深度學習的去雨算法DerainNet[16],JORDER[17],SEMI[20],DuRN[28],PreNet[21],RCDNet[23],RLNet[24],DualGCN[25]。
3.1 數據集介紹
本文算法在不同的數據集上使用相同的設置進行訓練和測試,分別為Rain100L[17],Rain100H[17],Rain12[5]和Rain800[30]。Rain100L為小雨數據集,僅僅包含單一方向的雨線,數據集中共有1 800張訓練圖片和100張測試圖片。Rain100H是大雨數據集,與Rain100L張數相同并在此基礎上增加了共5種方向的雨線。Rain800包含800張訓練圖片和100張測試圖片,Rain12數據集包含12張測試圖片。
3.2 結果分析
本文通過在Rain100H數據集上進行訓練,在包括Rain100H的共4個合成數據集上進行測試,并通過峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)[31]和SSIM[32]指標來進行評估。與之前的工作相同,本文在所有方法中統一使用Y通道(YCbCr顏色空間)來計算圖像的PSNR和SSIM的數值。對于早期的方法以及未提供訓練代碼的方法,本文直接采用提供的預訓練模型進行測試,并將輸出的去雨圖片計算PSNR和SSIM。在所有的對比方法中,DSC為傳統去雨算法,其他為深度學習算法,在去雨算法JORDER中直接使用公布的測試結果進行測試,在方法GCN,RCDNet,JORDER,DerainNet,SEMI中直接使用了作者的預訓練模型進行測試,對于方法RLNet,DuRN,PreNet,使用與本文算法相同的數據集并使用默認的設置重新進行訓練,并將最終結果與本文提出的算法進行對比。
在不同數據集上的評估指標如表1所示。本文提出的算法在4個數據集上進行訓練和測試,比較PSNR和SSIM。相比DualGCN方法,本文算法在Rain100L,Rain100H,Rain12和Rain800數據集上PSNR分別提高了1.46,1.01,0.02和5.92 dB,SSIM分別提高了0.026,0.003,0.003和0.079。從而說明,本文提出的算法在去除雨線和恢復被雨線損壞的背景圖片細節方面有更好的效果。除了對PSNR和SSIM量化指標的分析以外,本文還隨機選取Rain100H數據集中的6張測試結果和Rain800數據中的4張測試結果從主觀效果層面對去雨效果進行評價,結果如圖6~圖8所示。由圖6和圖7結果對比可知,其他算法在去雨時雨線殘留明顯,背景恢復細節較差,而本文恢復出來的圖片更加清晰。為了觀察圖片的細節表現,如圖7所示對一張去雨后圖片進行放大展示細節。由圖7可以看出,本文算法的去雨效果在細節恢復上比其他方法要好,DuRN恢復出來的無雨圖像比較模糊,GCN和RLNet整體觀感比DuRN好但細節恢復比本文算法差,邊緣不夠銳利。因此,本文算法的細節恢復主觀上比其他方法更好。
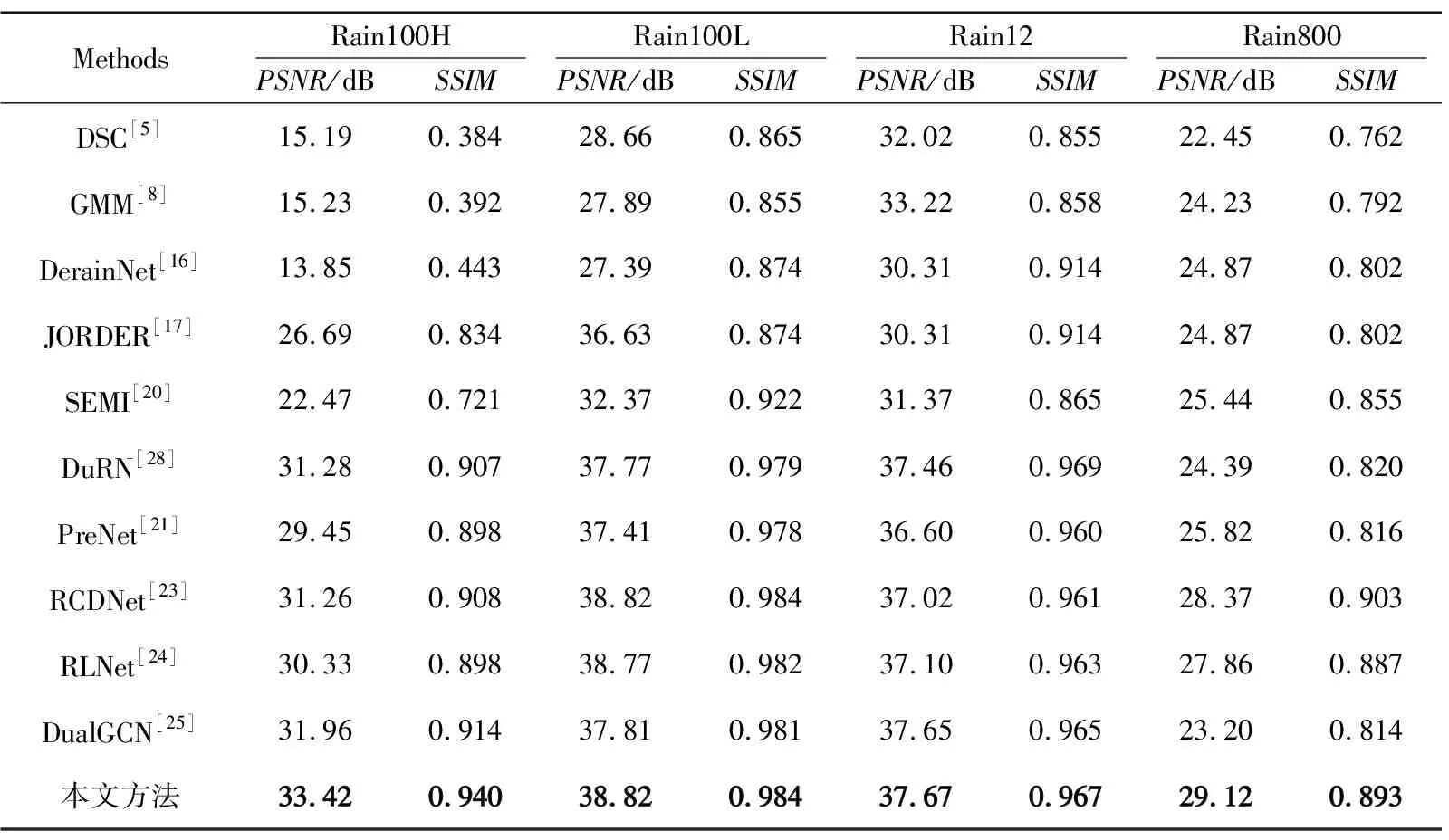
表1 在不同數據集上的評估指標

圖6 Rain100H數據集上的測試結果

圖7 Rain100H數據集上的細節對比

圖8 Rain800數據集上的測試結果
3.3 真實雨圖測試
為了測試真實環境下的去雨效果,本文在LPNet[33]收集整理的300張真實雨圖上進行測試,并從中隨機選取了3張進行對比,測試所用的模型為Rain100H上訓練的模型,測試結果如圖9所示。由圖9可以看出,其他算法都存在去雨不徹底導致雨條紋殘留明顯以及去雨后的圖片不清晰、存在偽影以及細節部分丟失等問題。在雨條紋過大,對背景圖像造成嚴重遮擋的情況下,其他方法去雨效果大大降低,特別是傳統算法在真實雨圖上表現不佳。本文算法能解決上述問題,達到更好的去雨效果,有更好的應用價值。

圖9 真實數據集上的測試結果
3.4 消融實驗
為了驗證本文算法中的各個模塊的有效性,在數據集Rain100H上進行消融實驗,其包括網絡的階段數以及不同模塊的組合與不同損失函數。
3.4.1 去雨階段數的討論
為了對本文所使用的多階段網絡結構的有效性進行驗證,對網絡的去雨階段數進行了消融實驗,如表2所示。
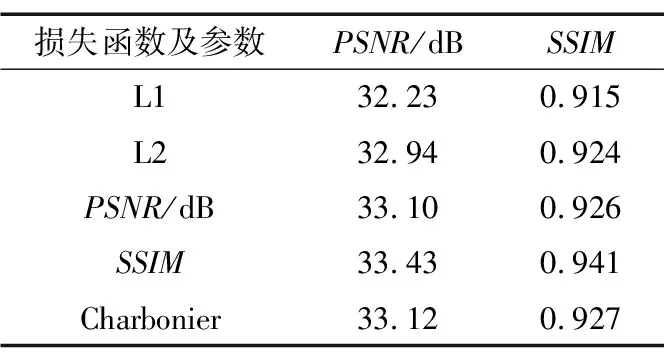
表2 不同損失函數的消融實驗
由表2可以看出,隨著階段數的增加,訓練的網絡能夠得到更好的效果。2階段去雨網絡的PSNR與SSIM相比1階段分別提升了1.11 dB和0.06,但4階段去雨網絡相比3階段PSNR與SSIM只提升了0.03 dB和0.01。不同階段數評估指標如圖10所示。由圖10可以看出,隨著階段數的增加,網絡效果提升越小,但過多的階段數占用了更多的計算資源,所以本文綜合考慮采用階段數量為3。

圖10 不同階段數評估指標
3.4.2 損失函數消融實驗
混合損失函數被廣泛地應用于圖像恢復及各種視覺任務中,如SSIM+L2損失以及SSIM+L1損失等,但是混合損失函數的加入加重了網絡超參數調節的負擔。Ren等[21]的經驗表明,單個損失函數已經足以訓練本文提出的網絡。本文對L1,L2損失、SSIM損失、PSNR損失和Charbonnier損失[34]進行了消融實驗。不同損失函數的消融實驗如表3所示。由表3可以看出,當使用SSIM損失的時候能夠得到最高的PSNR和SSIM。

表3 不同模塊組合的消融實驗
3.4.3 網絡組成消融實驗
為了驗證本文提出的網絡結構的有效性,在Rain100H數據集上對不同模塊的組合進行消融實驗,如表4所示。

表4 不同階段數的消融實驗
由表4可以看出,當僅僅使用雙殘差模塊(DRM)時該網絡去雨效果一般,當加入一系列本文使用的網絡模塊以后PSNR和SSIM都得到了很大的提升。當將網絡模塊由DRM替換成密集殘差塊(RDB)以后效果下降,證明了本文所使用的DRM的有效性。同時,層數越深的深層特征提取模塊效果越好,證明深層特征提取在圖像去雨網絡中的重要性。所以本文提出的網絡最終使用表4中PSNR和SSIM指標最高的組合所對應的網絡結構。
3.5 在目標檢測上的應用
為了驗證本文的去雨算法在后續高級計算機視覺任務上的應用價值,利用Google API對去雨前后的圖片進行測試,如圖11所示。被暴雨的雨線所遮擋的圖像在目標檢測中的精度大幅下降,對車的檢測精度只有80%并且無法檢測出人物。而去除雨線以后的圖像對車的檢測精度達到了95%,能夠額外檢測到人物,準確率為73%。說明本文算法能夠將在惡劣天氣下采集到的圖像通過去除雨線來有效地提高后續計算機視覺任務的準確度。

圖11 對目標檢測性能提升的評估
4 結束語
本文基于多階段架構提出了一種端到端的多階段去雨算法,使得雨線逐漸被去除的同時,背景圖像的細節紋路也能夠更好地恢復。另外,在不同階段之間加入特征融合模塊以及引入帶有標簽圖像進行監督的注意力機制,使得有用的特征能夠更有效地傳播到下一個階段。本文算法在5個數據集上進行了測試,并采用PSNR和SSIM作為圖像質量評價標準對本文的去雨效果進行評估,與現有的算法比較,本文的去雨效果突出。此外,本文對圖片在后續計算機視覺任務上進行了測試,去雨以后的圖片能達到更高的精度。
然而,本文提出的算法也存在不足,由于數據集的局限性使得該網絡針對雨線的去除效果較好,但是當有雨圖像中存在雨滴或者雨霧的時候,本文算法存在一定缺陷。收集真實的數據集或者合成更接近于真實的數據集供更多的研究者使用是本文接下來的研究方向。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
艦船科學技術(2022年15期)2022-09-14 09:21:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年19期)2018-11-14 02:37:08
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
自動化學報(2017年11期)2017-04-04 02:52:58
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
