基于局部運(yùn)動(dòng)約束的改進(jìn)PWStableNet電子穩(wěn)像網(wǎng)絡(luò)
2022-11-24 01:53:34徐鑫偉蘭太吉薛旭成吳夢(mèng)飛
無線電工程 2022年11期
關(guān)鍵詞:方法
徐鑫偉,蘭太吉,薛旭成,吳夢(mèng)飛
(1.中國科學(xué)院長(zhǎng)春光學(xué)精密機(jī)械與物理研究所,吉林 長(zhǎng)春 130033;2.中國科學(xué)院大學(xué),北京 100049)
0 引言
視頻穩(wěn)定是業(yè)余和專業(yè)視頻拍攝的共同需求。在業(yè)余方面,特定的視頻穩(wěn)定設(shè)備通常是十分昂貴的,而隨著以手機(jī)為主的手持式攝像機(jī)的普及,業(yè)余用戶每天拍攝出來的視頻占比越來越大,不具有穩(wěn)定器的攝像設(shè)備在拍攝過程中經(jīng)常會(huì)受到高頻抖動(dòng)的干擾,導(dǎo)致拍攝的視頻帶有比較明顯的抖動(dòng),視覺質(zhì)量大幅降低。將帶有抖動(dòng)的視頻重新穩(wěn)定下來是一項(xiàng)非常有意義的研究[1]。
電子穩(wěn)像技術(shù)以僅需要計(jì)算、無需額外設(shè)備就能達(dá)到穩(wěn)像效果的優(yōu)勢(shì)成為了當(dāng)今主流的穩(wěn)像方法。一些傳統(tǒng)電子穩(wěn)像方法[2-3]需要提取特征軌跡或使用光流法估計(jì)攝像機(jī)的運(yùn)動(dòng),然后對(duì)其進(jìn)行平滑以實(shí)現(xiàn)穩(wěn)定,最后根據(jù)固定網(wǎng)格計(jì)算出一個(gè)全局單應(yīng)矩陣或幾個(gè)同形矩陣以將晃動(dòng)的幀重新翹曲成穩(wěn)定的幀。由于相機(jī)運(yùn)動(dòng)而產(chǎn)生的視差和深度的變化,使得這些傳統(tǒng)方法難以產(chǎn)生穩(wěn)定的視頻。此外,這些方法通常依賴特征點(diǎn)的提取,魯棒性較差,并在處理低質(zhì)量視頻(如夜景視頻、模糊視頻、有水印的視頻和帶有噪聲的視頻)時(shí)可能會(huì)穩(wěn)像失敗。
近年來,卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Networks,CNN)在計(jì)算機(jī)視覺任務(wù)上取得了巨大的成功,比如圖像識(shí)別[4]、目標(biāo)檢測(cè)[5]和分割[6]。特別是一些傳統(tǒng)的視頻處理問題已經(jīng)可以用深度神經(jīng)網(wǎng)絡(luò)重新解決,如圖像去噪去模糊[7]、圖像效果增強(qiáng)[8]等。通過創(chuàng)建一個(gè)實(shí)際的數(shù)據(jù)集在構(gòu)建好的神經(jīng)網(wǎng)絡(luò)上面進(jìn)行訓(xùn)練,CNN也可以實(shí)現(xiàn)視頻穩(wěn)定的效果。
Wang等[9]設(shè)計(jì)了一種用于多網(wǎng)格翹曲變換學(xué)習(xí)的網(wǎng)絡(luò),該網(wǎng)絡(luò)能夠獲得與傳統(tǒng)方法相當(dāng)?shù)男阅埽⑶覍?duì)低質(zhì)量的視頻更具魯棒性。Xu等[10]設(shè)計(jì)了一種對(duì)抗性網(wǎng)絡(luò),用來估計(jì)一個(gè)仿射矩陣,通過仿射矩陣可以生成穩(wěn)定的幀。然而,這些方法在固定網(wǎng)格的基礎(chǔ)上估計(jì)一個(gè)或一組仿射矩陣,對(duì)于不同深度變化的場(chǎng)景不夠靈活和準(zhǔn)確。與傳統(tǒng)的穩(wěn)定方法相比,基于CNN的穩(wěn)定方法具有更強(qiáng)的魯棒性,因?yàn)樗軌蚝芎玫靥崛「呔S抽象特征,而不是依賴于特征點(diǎn)提取和匹配,特征點(diǎn)提取和匹配的準(zhǔn)確性很大程度上取決于視頻的質(zhì)量。在基于仿射變換或基于網(wǎng)格變換方面,它們與傳統(tǒng)的方法非常相似,在強(qiáng)視差、深度變化以及有遮擋的情況下,這些方法是非常脆弱的,很容易把視頻幀像素翹曲到錯(cuò)誤的位置。
Zhao等[11]提出了一種新的名為PWStableNet的CNN來消除各種不穩(wěn)定視頻的抖動(dòng),其學(xué)習(xí)的對(duì)象是為每個(gè)不穩(wěn)定幀像素提供理想位置的像素翹曲場(chǎng),通過像素翹曲場(chǎng),可以將抖動(dòng)視頻幀中的每個(gè)像素轉(zhuǎn)換到穩(wěn)定位置。與傳統(tǒng)方法的每幀估計(jì)一個(gè)單應(yīng)性變換或基于固定網(wǎng)格估計(jì)幾個(gè)單應(yīng)的變換方法相比,像素翹曲場(chǎng)為每個(gè)像素提供翹曲方向。每幀計(jì)算2個(gè)像素翹曲場(chǎng)分別代表像素橫向翹曲方向和縱向翹曲方向,可以為穩(wěn)定視圖中的每個(gè)像素提供理想的單獨(dú)位置,一旦某個(gè)位置發(fā)生了計(jì)算錯(cuò)誤,對(duì)整體的影響很小,所以對(duì)退化模糊的圖像具有很強(qiáng)的魯棒性并且可以很好地處理視差,也可以處理不同對(duì)象之間的不連續(xù)深度變化。該網(wǎng)絡(luò)能夠有效處理各種低質(zhì)量、高深度的抖動(dòng)視頻,是當(dāng)前魯棒性最好的深度學(xué)習(xí)穩(wěn)像方法,同時(shí)對(duì)比其他的深度學(xué)習(xí)方法在運(yùn)算速度上有所提升。
PWStableNet在處理有噪聲、有模糊、帶水印和大深度等低質(zhì)量抖動(dòng)視頻有魯棒性和通用性很強(qiáng)的優(yōu)點(diǎn),但該網(wǎng)絡(luò)也存在缺乏有效局部運(yùn)動(dòng)抑制,易產(chǎn)生過度翹曲,造成局部失真的問題。本文針對(duì)此處進(jìn)行改進(jìn)創(chuàng)新,在訓(xùn)練過程中以損失函數(shù)的形式對(duì)生成的像素翹曲矩陣在空間上添加頻域損失計(jì)算來抑制高頻成分的出現(xiàn),并利用MeshFlow網(wǎng)格流模型[12]對(duì)局部區(qū)域運(yùn)動(dòng)劇烈程度進(jìn)行評(píng)估,添加局部運(yùn)動(dòng)損失阻止過度運(yùn)動(dòng)。實(shí)驗(yàn)測(cè)試結(jié)果表明,改進(jìn)后的PWStableNet能夠有效抑制局部失真并且在峰值信噪比(Peak Signal to Noise Ratio,PSNR)、幀間結(jié)構(gòu)相似度(Structural Similarity Index,SSIM)和穩(wěn)定度(Stability)等客觀指標(biāo)上有所提升。
1 PWStableNet的基本結(jié)構(gòu)
PWStableNet的基本結(jié)構(gòu)如圖1所示,網(wǎng)絡(luò)結(jié)構(gòu)的輸入是給定的一組共2w+1張連續(xù)、不穩(wěn)定的視頻幀,主體部分是一個(gè)多級(jí)級(jí)聯(lián)的編碼解碼卷積網(wǎng)絡(luò)用來估計(jì)幀間運(yùn)動(dòng)的抖動(dòng),網(wǎng)絡(luò)輸出一個(gè)像素級(jí)的翹曲場(chǎng),該翹曲場(chǎng)由2個(gè)翹曲矩陣組成,指示了穩(wěn)定幀每個(gè)像素應(yīng)該由哪個(gè)不穩(wěn)定幀像素移動(dòng)而來。通過這些翹曲場(chǎng),可以將抖動(dòng)幀中的像素轉(zhuǎn)換到新的位置組成穩(wěn)定幀。與以往基于固定網(wǎng)格估計(jì)單應(yīng)矩陣或少量同形矩陣的方法相比,PWStableNet提出的像素級(jí)翹曲場(chǎng)可以為穩(wěn)定視圖中的每個(gè)像素提供合適的單獨(dú)位置,并能很好地處理不同物體之間的視差甚至不連續(xù)的深度變化。
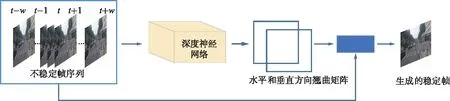
圖1 PWStableNet的基本結(jié)構(gòu)
1.1 系統(tǒng)輸入
神經(jīng)網(wǎng)絡(luò)輸入需要足夠量的信息,要想將一幀圖像穩(wěn)定下來需要用到相鄰視頻幀的信息,因此網(wǎng)絡(luò)以待穩(wěn)定幀前后w幀作為輸入。如圖1所示,待穩(wěn)定幀為第T幀,網(wǎng)絡(luò)輸入是t-w~t+w幀,共2w+1幀。輸入幀圖像半徑w的大小決定信息量的大小,會(huì)對(duì)穩(wěn)定效果和處理速度產(chǎn)生一定的影響。
1.2 像素翹曲場(chǎng)
像素翹曲場(chǎng)是與圖片像素寬、高相同,通道數(shù)為2的一組矩陣,用來映射穩(wěn)定幀和不穩(wěn)定幀之間的關(guān)系。像素翹曲場(chǎng)的映射關(guān)系如圖2所示。
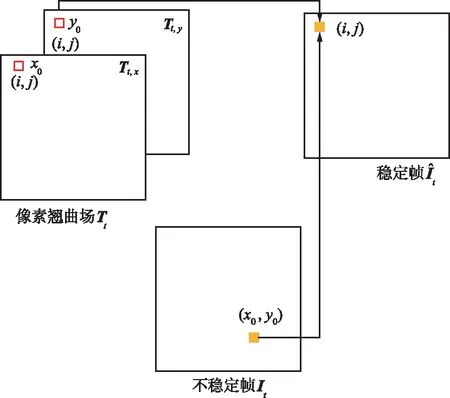
圖2 像素翹曲場(chǎng)的映射關(guān)系
1.3 神經(jīng)網(wǎng)絡(luò)主體結(jié)構(gòu)
神經(jīng)網(wǎng)絡(luò)主體結(jié)構(gòu)如圖3所示,可以看到有三級(jí)級(jí)聯(lián)的網(wǎng)絡(luò)結(jié)構(gòu),每級(jí)結(jié)構(gòu)相似,主要是編碼器-解碼器框架,類似于U-Net[13]的結(jié)構(gòu)。以單一級(jí)結(jié)構(gòu)來看,其編碼器由若干個(gè)抽象層組成,這些抽象層能夠提取大大小小的特征信息,在較深的層上有較多的通道。它的解碼器由與編碼器對(duì)應(yīng)的信道編號(hào)相同、大小相同的反卷積層組成,并通過跳躍連接與對(duì)應(yīng)的反卷積層相連接。以級(jí)間結(jié)構(gòu)來看,每級(jí)結(jié)構(gòu)都與相鄰的級(jí)自上而下保持連接,意義在于當(dāng)前級(jí)的各層能夠?qū)W習(xí)其前一級(jí)的剩余特征,在更細(xì)節(jié)位置得到更精確的估計(jì)。每級(jí)結(jié)構(gòu)都輸出一個(gè)翹曲場(chǎng)Tn(n表示級(jí)序數(shù)),這些學(xué)習(xí)了更多圖像細(xì)節(jié)的翹曲場(chǎng)相疊加得到該幀最終輸出的翹曲場(chǎng)T。
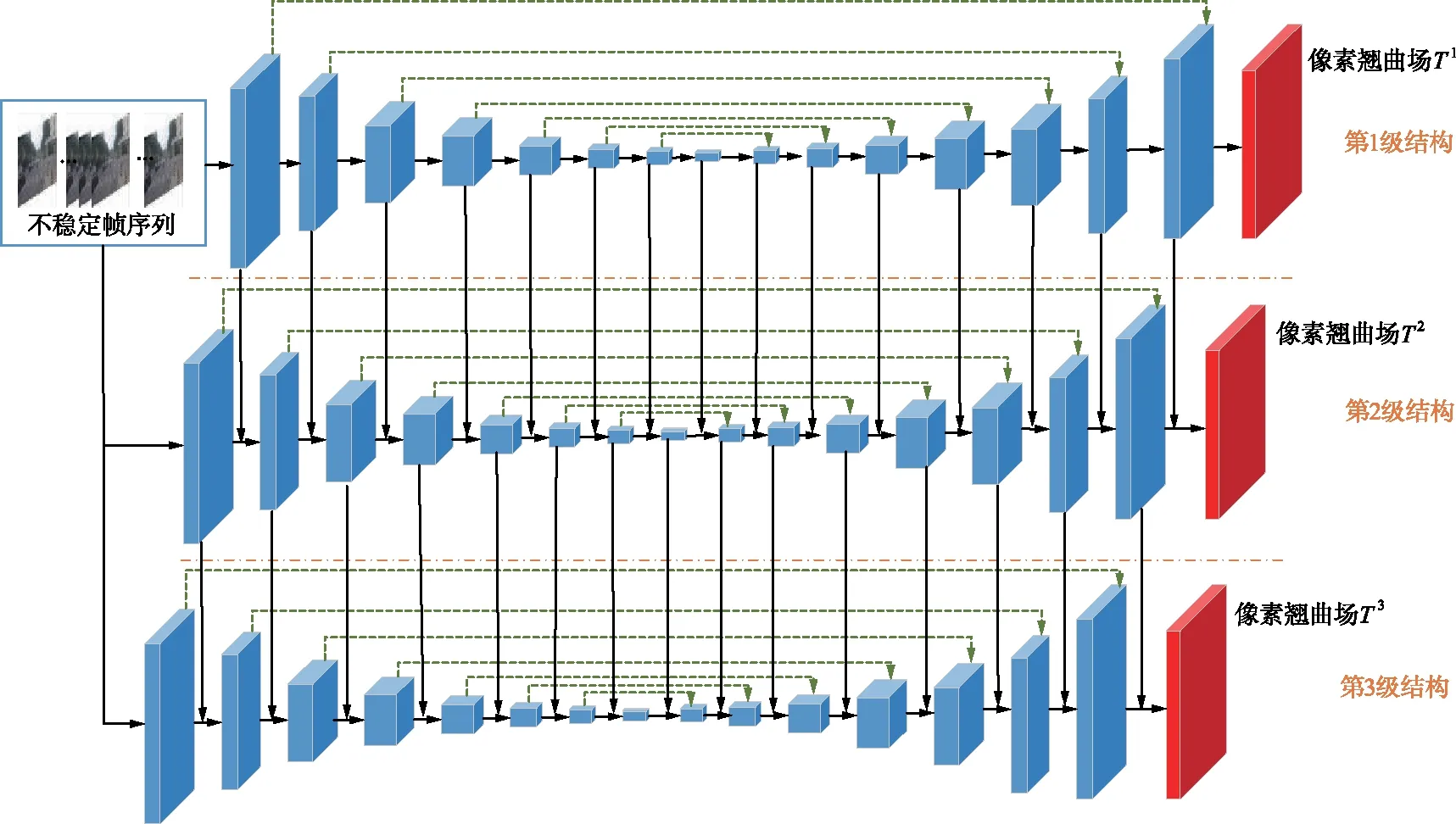
圖3 神經(jīng)網(wǎng)絡(luò)主體結(jié)構(gòu)
2 改進(jìn)與創(chuàng)新
在性能測(cè)試時(shí)發(fā)現(xiàn),原生的PWStableNet網(wǎng)絡(luò)模型生成的視頻整體上穩(wěn)定,但是偶爾在局部會(huì)產(chǎn)生不穩(wěn)定區(qū)域,出現(xiàn)不正常的扭曲失真,經(jīng)過分析并查閱文獻(xiàn)后發(fā)現(xiàn)了導(dǎo)致該問題的一部分原因。像素級(jí)翹曲矩陣為每個(gè)像素安排位置,擁有極高的自由度,但是原網(wǎng)絡(luò)對(duì)像素自由運(yùn)動(dòng)只做了簡(jiǎn)單的幀間均方差進(jìn)行約束,缺乏更加直接有效的約束來防止過量運(yùn)動(dòng)。其后果就是輸出的翹曲場(chǎng)很容易發(fā)生個(gè)別像素點(diǎn)的誤匹配,把像素移動(dòng)到過遠(yuǎn)或過近的位置,增加了輸出圖像的噪聲,一定區(qū)域內(nèi)誤匹配數(shù)量過多則會(huì)局部圖像失真,降低生成的穩(wěn)定圖像的質(zhì)量。
2.1 對(duì)翹曲場(chǎng)增加頻域約束
在查閱相關(guān)文獻(xiàn)后,受到基于光流的視頻穩(wěn)定神經(jīng)網(wǎng)絡(luò)[14]的啟發(fā),在網(wǎng)絡(luò)訓(xùn)練過程中采用對(duì)生成的翹曲矩陣加強(qiáng)空間平滑度的方式,來抑制局部失真和減少噪聲。加強(qiáng)空間平滑度的方法常見的有總變分約束和Yu等[15]提出的線性翹曲場(chǎng)約束。然而,這2種方法存在著一定的局限性,總變分約束對(duì)局部噪聲的抑制作用較強(qiáng),而對(duì)畸變的抑制作用較弱;線性翹曲場(chǎng)約束難以控制,因?yàn)閺?qiáng)約束限制了像素級(jí)翹曲場(chǎng)處理大規(guī)模非線性運(yùn)動(dòng)的靈活性,而弱約束不能很好地抑制局部形變[14]。因此,加強(qiáng)翹曲場(chǎng)空間平滑度的方法應(yīng)該滿足以下3個(gè)條件:一是能保證像素級(jí)翹曲矩陣的處理抖動(dòng)視頻幀的靈活性;二是能抑制輸出圖像的局部形變;三是能減弱輸出圖像的整體和局部噪聲。在頻域利用傅里葉譜約束的方法能夠同時(shí)滿足以上條件,適合作為加強(qiáng)翹曲場(chǎng)空間平滑度的方法。
具體實(shí)現(xiàn)方法是在訓(xùn)練過程中對(duì)翹曲場(chǎng)中的每個(gè)翹曲場(chǎng)進(jìn)行傅里葉變換得到其頻譜,再對(duì)頻譜進(jìn)行加權(quán)運(yùn)算得到新的頻譜,新頻譜的L2范數(shù)就作為此幀翹曲場(chǎng)頻域損失函數(shù)的值,計(jì)算公式為:
(1)
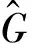
(2)
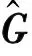
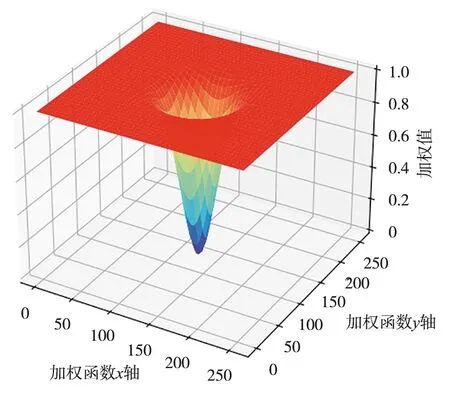
圖4 倒置高斯加權(quán)函
2.2 對(duì)穩(wěn)定幀增加局部運(yùn)動(dòng)約束
頻域約束是通過對(duì)翹曲矩陣進(jìn)行整體性約束來抑制局部失真的發(fā)生,屬于間接方法,圖像的局部失真程度可以采用更為直接的方式進(jìn)行評(píng)估。Liu提出的MeshFlow模型[12]和SteadyFlow模型[16]都能很好地檢測(cè)局部區(qū)域內(nèi)的幀間移動(dòng)。MeshFlow模型基于KLT稀疏光流特征匹配[17],SteadyFlow模型基于稠密光流,二者效果上相似,但是MeshFlow計(jì)算復(fù)雜度遠(yuǎn)低于SteadyFlow。為了提升計(jì)算效率加快運(yùn)行速度,本文采用MeshFlow模型來計(jì)算局部區(qū)域的幀間運(yùn)動(dòng),評(píng)估局部區(qū)域不穩(wěn)定程度。
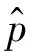
(a)相鄰圖像的一對(duì)特征點(diǎn)
所有匹配的特征都會(huì)將它們的運(yùn)動(dòng)傳播到附近的網(wǎng)格頂點(diǎn),每個(gè)網(wǎng)格頂點(diǎn)會(huì)接收多個(gè)來自不同特征點(diǎn)的運(yùn)動(dòng)矢量。因此需要篩選出其中一個(gè)來代表此頂點(diǎn)運(yùn)動(dòng)矢量。中值濾波器經(jīng)常用于光流估計(jì),并被視為高質(zhì)量流估計(jì)的訣竅[18]。這里借用了該研究的稀疏運(yùn)動(dòng)規(guī)則化的類似思想,采用中值濾波篩選出代表頂點(diǎn)區(qū)域的運(yùn)動(dòng)矢量。所有帶有運(yùn)動(dòng)矢量的網(wǎng)格頂點(diǎn)組成了一個(gè)稀疏運(yùn)動(dòng)場(chǎng),表示了幀間的運(yùn)動(dòng)情況。
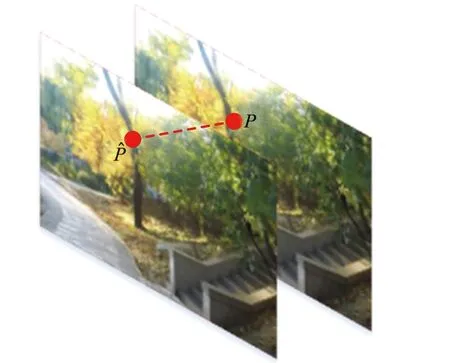
網(wǎng)格運(yùn)動(dòng)矢量分解如圖6所示,每個(gè)網(wǎng)格頂點(diǎn)運(yùn)動(dòng)矢量一般可以分解為2個(gè)部分:一個(gè)是表示整個(gè)幀全局運(yùn)動(dòng)的全局矢量;另一個(gè)是表示局部細(xì)節(jié)自由運(yùn)動(dòng)的局部自由矢量。
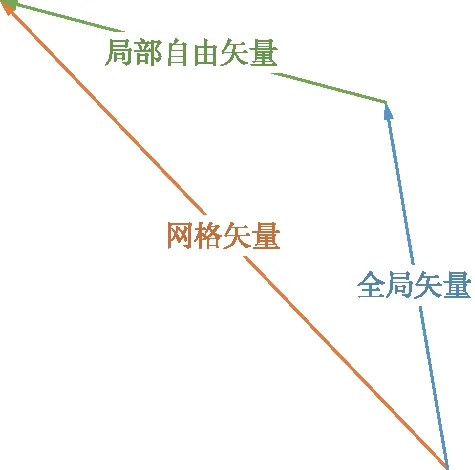
圖6 網(wǎng)格運(yùn)動(dòng)矢量分解
目的是計(jì)算出局部區(qū)域的不穩(wěn)定程度,全局矢量與局部區(qū)域不穩(wěn)定度無關(guān),應(yīng)該采用代表局部自由運(yùn)動(dòng)的局部自由矢量來衡量局部運(yùn)動(dòng)劇烈程度。局部自由矢量可以由網(wǎng)格矢量與全局矢量相減得到,因此需要計(jì)算出全局矢量。前面提到MeshFlow模型的特征點(diǎn)由KLT光流特征匹配[17]生成,可以借鑒傳統(tǒng)方法利用這些特征點(diǎn)計(jì)算出全局仿射變換,把網(wǎng)格頂點(diǎn)坐標(biāo)帶入到仿射變換模型中得到新網(wǎng)格頂點(diǎn)的位置:
(3)
式中,[X′,Y′]表示仿射變換后的網(wǎng)格頂點(diǎn)坐標(biāo);[X,Y]表示仿射變換前網(wǎng)格頂點(diǎn)的坐標(biāo);m11,m12,m21,m22,b1,b2均為全局仿射變換的參數(shù)。全局矢量則定義為:
(4)
在訓(xùn)練過程中根據(jù)網(wǎng)絡(luò)輸出的翹曲場(chǎng)T生成一個(gè)穩(wěn)定幀,這個(gè)穩(wěn)定幀與上一個(gè)穩(wěn)定幀組成相鄰幀,構(gòu)建出MeshFlow網(wǎng)格模型并計(jì)算所有網(wǎng)格頂點(diǎn)的局部自由矢量。用這些局部自由矢量組成的稀疏運(yùn)動(dòng)場(chǎng)的L2范數(shù)來衡量此幀局部區(qū)域運(yùn)動(dòng)的劇烈程度,一個(gè)視頻所有幀局部損失相加作為該視頻的損失函數(shù):
(5)
式中,t表示幀序數(shù);Lt,m為該幀的局部運(yùn)動(dòng)損失;N表示一幀網(wǎng)格頂點(diǎn)數(shù)量;n表示網(wǎng)格頂點(diǎn)序數(shù);Mt,n,g表示第n個(gè)根據(jù)特征點(diǎn)直接求出的網(wǎng)格頂點(diǎn)矢量;Mt,d為根據(jù)仿射變換求出的全局矢量。
3 結(jié)果分析
在公開數(shù)據(jù)集DeepStab[9]上進(jìn)行訓(xùn)練,該數(shù)據(jù)集共有61對(duì)穩(wěn)定、不穩(wěn)定視頻數(shù)據(jù),數(shù)據(jù)集中的穩(wěn)定視頻稱為真穩(wěn)定視頻,以45對(duì)視頻作為訓(xùn)練集,8對(duì)視頻作為驗(yàn)證集,8對(duì)視頻作為測(cè)試集。網(wǎng)絡(luò)模型學(xué)習(xí)率采用階梯式下降的方法,初始狀態(tài)學(xué)習(xí)率為0.01,之后每經(jīng)過10輪,學(xué)習(xí)率下降10倍。本文所有實(shí)驗(yàn)數(shù)據(jù)結(jié)果均在同一硬件平臺(tái)上運(yùn)行,CPU型號(hào)為Intel i9-12900k,GPU型號(hào)為Nvidia RTX-3090,在此平臺(tái)上進(jìn)行測(cè)試輸出視頻的平均幀率為79幀/秒,能夠達(dá)到拍攝視頻實(shí)時(shí)處理的需求。
3.1 主觀效果
本文的改進(jìn)之處在于引入了更多的約束來改善PWStableNet易發(fā)生局部失真的缺點(diǎn),卷積網(wǎng)絡(luò)結(jié)構(gòu)未發(fā)生改變,處理低質(zhì)量視頻的優(yōu)秀能力得以保留,同樣具有很強(qiáng)的魯棒性。
用肉眼難以直接察覺到穩(wěn)定后視頻微小的局部運(yùn)動(dòng),但是可以通過幀間差分圖像來實(shí)現(xiàn)局部運(yùn)動(dòng)可視化。網(wǎng)絡(luò)改進(jìn)前、網(wǎng)絡(luò)改進(jìn)后和真穩(wěn)定視頻的幀間差分圖如圖7所示,白色區(qū)域表示了相鄰幀之間發(fā)生了運(yùn)動(dòng)的物體的基本輪廓,白色區(qū)域的密集程度能夠反映幀間運(yùn)動(dòng)的劇烈程度。由圖7可以看出,改進(jìn)后白色區(qū)域的密集程度接近于真穩(wěn)定視頻,明顯低于改進(jìn)前,說明改進(jìn)后的局部運(yùn)動(dòng)受到了抑制,減少了局部失真發(fā)生的可能性,主觀效果優(yōu)于改進(jìn)前。本文改進(jìn)后在局部區(qū)域運(yùn)動(dòng)上更符合穩(wěn)定視頻的要求。

(a)改進(jìn)前幀間差分
3.2 客觀評(píng)價(jià)
一般電子穩(wěn)像方法輸出的幀邊界會(huì)有一部分無信息區(qū)域,處理這些區(qū)域的方法通常是直接裁剪,為了方便比較,把所有方法輸出的視頻都裁剪到一個(gè)公共區(qū)域。為了評(píng)估,改進(jìn)了網(wǎng)絡(luò)的有效性,除了損失函數(shù)組成不同,網(wǎng)絡(luò)結(jié)構(gòu)以及其他超參數(shù)均保持一致。本文改進(jìn)后的穩(wěn)像網(wǎng)絡(luò)除了與改進(jìn)前網(wǎng)絡(luò)進(jìn)行對(duì)比,還與原不穩(wěn)定視頻和基于光流特征匹配的傳統(tǒng)方法[2]進(jìn)行對(duì)比,共4組對(duì)照數(shù)據(jù)。測(cè)試對(duì)象為數(shù)據(jù)集DeepStab[9]上的8個(gè)不穩(wěn)定視頻,根據(jù)視頻內(nèi)容的特征分為“常規(guī)”“運(yùn)動(dòng)”“低照度”和“視差”4種類型,對(duì)應(yīng)攝像機(jī)在日常使用過程中經(jīng)常遇到的情況。為了定量比較提出的網(wǎng)絡(luò)和以前的方法,計(jì)算了3個(gè)客觀指標(biāo):PSNR,SSIM和穩(wěn)定度,下面簡(jiǎn)要地說明這3個(gè)指標(biāo)。
① PSNR:能夠反映穩(wěn)定后視頻圖像結(jié)構(gòu)信息的完整程度,其值越高,表示受到噪聲影響越小,穩(wěn)定后圖像質(zhì)量越高,失真程度越小[19]。
② SSIM:能夠衡量相鄰兩幀之間圖像相似程度,一般認(rèn)為穩(wěn)定的視頻相鄰幀之間結(jié)構(gòu)是相似的,幀間結(jié)構(gòu)相似度越高說明視頻越穩(wěn)定。
③ 穩(wěn)定度:用于衡量視頻的穩(wěn)定程度,一般認(rèn)為穩(wěn)定的視頻內(nèi)的運(yùn)動(dòng)緩慢的低頻成分占比較大,穩(wěn)定度計(jì)算了視頻內(nèi)的低頻成分所占的比例。計(jì)算方法采用與文獻(xiàn)[10]相同的方法,將每個(gè)幀分割成4×4個(gè)網(wǎng)格,記錄每個(gè)網(wǎng)格頂點(diǎn)經(jīng)過所有幀的歷史路徑,并將每個(gè)頂點(diǎn)路徑視為一維時(shí)域信號(hào)進(jìn)行頻域分析。每個(gè)頂點(diǎn)的穩(wěn)定度計(jì)算為最低頻率分量(除去直流分量,第2~6低的頻率)在全頻率的占比。該視頻的穩(wěn)定度的值為計(jì)算所有網(wǎng)格頂點(diǎn)穩(wěn)定度的平均值。
客觀指標(biāo)對(duì)比結(jié)果如圖8所示,第1,2號(hào)視頻對(duì)應(yīng)“常規(guī)”類型;第3,4號(hào)視頻對(duì)應(yīng)“運(yùn)動(dòng)”類型;第5,6號(hào)視頻對(duì)應(yīng)“低照度”類型;第7,8號(hào)視頻對(duì)應(yīng)“視差”類型,相同類型的視頻指標(biāo)數(shù)據(jù)相近。從PSNR指標(biāo)上進(jìn)行分析,改進(jìn)后的網(wǎng)絡(luò)與改進(jìn)前性能持平,二者均高于傳統(tǒng)方法;從SSIM指標(biāo)上進(jìn)行分析,本文方法性能略高于傳統(tǒng)方法與改進(jìn)前網(wǎng)絡(luò);從穩(wěn)定度上進(jìn)行分析,不同類型的視頻上呈現(xiàn)出不同的結(jié)果。在“常規(guī)”類型的視頻中,本文方法性能略高于傳統(tǒng)方法和改進(jìn)前網(wǎng)絡(luò);在“運(yùn)動(dòng)”類型的視頻中,3種方法性能接近;在“低照度”和“視差”類型中,傳統(tǒng)方法數(shù)據(jù)指標(biāo)高于2種基于神經(jīng)網(wǎng)絡(luò)的方法,其原因就在于傳統(tǒng)方法處理這2種類型的視頻時(shí)穩(wěn)像失敗,生成了含有大量空白區(qū)域的幀,空白區(qū)域網(wǎng)格頂點(diǎn)的運(yùn)動(dòng)矢量為零導(dǎo)致了穩(wěn)定度異常提高。總體上看,本文改進(jìn)后網(wǎng)絡(luò)的客觀評(píng)價(jià)指標(biāo)更好。

(a)測(cè)試視頻編號(hào)及類型
本文方法是基于PWStableNet改進(jìn)而來,與改進(jìn)前網(wǎng)絡(luò)相對(duì)比進(jìn)行針對(duì)性的分析是評(píng)判改進(jìn)有效性的重要內(nèi)容。數(shù)據(jù)內(nèi)容為有效穩(wěn)像占比,如表1所示,用于衡量穩(wěn)像方法的有效程度,以不穩(wěn)定視頻指標(biāo)到真穩(wěn)定視頻指標(biāo)之差為尺度1,以不穩(wěn)定視頻指標(biāo)到穩(wěn)像方法指標(biāo)為有效穩(wěn)像,即:
(6)
式中,R為有效穩(wěn)像占比;Ho為穩(wěn)像方法的指標(biāo);Hu為不穩(wěn)定視頻的指標(biāo);Hs為真穩(wěn)定視頻的指標(biāo)。
表1對(duì)比了網(wǎng)絡(luò)改進(jìn)前后輸出的結(jié)果在不同視頻的3個(gè)指標(biāo)上的具體數(shù)據(jù)。由表1中數(shù)據(jù)可以看出,提升的指標(biāo)(加粗的數(shù)值)占多數(shù)約71%,以平均值來看,3種指標(biāo)均有不同程度的提升,總的提升均值為7.73%。這些客觀評(píng)價(jià)指標(biāo)說明了在引入2個(gè)新約束后的PWStableNet網(wǎng)絡(luò)在綜合性能上優(yōu)于改進(jìn)前。
表1 改進(jìn)前后有效穩(wěn)像對(duì)比
4 結(jié)束語
本文對(duì)現(xiàn)有的視頻穩(wěn)像網(wǎng)絡(luò)PWStableNet進(jìn)行改進(jìn),解決改進(jìn)前網(wǎng)絡(luò)易發(fā)生局部失真的問題。對(duì)卷積網(wǎng)絡(luò)引入了2個(gè)新的約束:像素翹曲場(chǎng)的頻域約束和局部自由運(yùn)動(dòng)矢量的約束,來減少穩(wěn)定視頻在局部區(qū)域的多余運(yùn)動(dòng),抑制局部失真,生成更穩(wěn)定的視頻。這2種約束的優(yōu)點(diǎn)在于以直接和間接2種方式進(jìn)行評(píng)估,更加細(xì)致、全面地計(jì)算出局部自由運(yùn)動(dòng)大小。經(jīng)過實(shí)驗(yàn)對(duì)比驗(yàn)證,本文改進(jìn)后的網(wǎng)絡(luò)生成的視頻在幀間差分具有更好的效果,同時(shí)在PSNR,SSIM和穩(wěn)定度等客觀性能指標(biāo)上較其他算法更優(yōu)。隨后的研究重點(diǎn)內(nèi)容將集中在優(yōu)化網(wǎng)絡(luò)結(jié)構(gòu)、提升計(jì)算效率上,以獲得更好的運(yùn)算速度和穩(wěn)像效果。
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(bào)(2021年2期)2021-05-25 02:07:46
中學(xué)生數(shù)理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(bào)(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長(zhǎng)指南(2015年7期)2015-08-11 15:03:12
小雪花·成長(zhǎng)指南(2015年4期)2015-05-19 14:47:56
