基于GPU的非合作突發TDMA信號實時檢測
2022-11-24 01:53:36呂志強
無線電工程 2022年11期
呂志強,劉 凱
(上海大學 通信與信息工程學院,上海 200444)
0 引言
海事衛星通信系統主要由同步通信衛星、移動終端、海岸地球站以及協調控制站等組成,通過一系列終端向用戶提供不同寬帶的網絡接入、移動實時視頻直播等通信能力,在移動通信領域占有越來越重要的地位。非合作通信中,接收端不知道有關發送信號的調制參數,是一種非授權接入通信方式,因此要對突發信號進行準確匹配,為后續的信號調制方式識別與解調提供基礎,是非合作方獲取通信內容的重要保證。研究非合作通信中高效檢測識別信號是非常有價值的,如在軍事通信中對敵方的情報截獲,需要對大量突發信號進行高效、快速的檢測;在民用領域,為保證無線電頻譜管理的有效性,政府常常需要對民用信號進行檢測對比。而海事衛星突發信號由于分布不均勻且信號持續時間較短,相鄰的突發信號間距可能較近、數據量大,這些不利條件都增加了突發信號檢測的準確度和速度。
隨著對無線高速數字通信的研究和突發信號檢測與同步技術等先進理論的提出,信號的檢測[1]與同步根據研究方式不同可分為4大類:基于線性理論的時域、頻域、時頻域和基于非線性理論的微弱特征信號檢測同步方法[2]。時域檢測法[3]中主要有能量檢測、相關檢測、取樣積分與數字式平均[4]等。GPU具有多個計算單元和多種內存,適合于計算量較大且計算簡單的任務,眾多學者已將GPU的多線程技術應用到圖像處理[5-6]和衛星信號處理[7-9]等實時性要求較高的領域。
針對所研究的海事衛星信號,為解決數據量大且檢測準確度低的問題,從工程實現角度出發,設計了基于GPU的雙窗口能量檢測和分段差分相關檢測的雙重檢測方案。借助GPU強大的通用計算能力,挖掘并行度,從多維度線程和流架構兩方面實現并行處理,通過合理地利用不同內存,設定合適的維度、塊數以及塊內線程數來盡量實現合并的內存訪問,保證最大的內存帶寬等優化方式,由CPU與GPU相互協調合作,加快了計算速度,提高了系統的整體性能。通過仿真和實際信號的測試實驗表明,所提方法具有較高的檢測成功率,單路速度提升約40倍。
1 系統架構設計
本文旨在研究基于GPU的非合作海事衛星信號的檢測識別,非合作通信流程如圖1所示。在高斯白噪聲信道中,通過分析通信協議,確認突發和連續信號的傳輸格式等屬性,利用傳輸幀中的獨特碼等條件檢測不同類型的信號,計算信號的信噪比等參數。在實際工程中,需要實現多路多頻點處信號的實時檢測和解調,算法復雜度很高,僅用CPU無法達到理想的運行性能,于是利用GPU的并行計算能力,在CUDA架構下,利用CPU+GPU的異構模型,將整個信號檢測方案按一定策略給CPU和GPU劃分任務,由GPU完成多路多頻點下變頻的并行和雙重檢測算法的優化,完成信號檢測后,信號數據量大大減少,然后在CPU上進行信號的頻偏、相偏估計和解調處理。
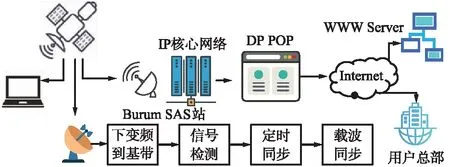
圖1 非合作通信流程
突發信號檢測流程如圖2所示,首先需要把信號采樣率由Fs1變采樣到目標采樣率Fs2,在目標頻點進行數字下變頻,由于突發信號的長度和分布不同,需要進行文件頭部數據的差分相關檢測,滑動的距離要大于最大的突發信號長度。這是因為如果信號在讀入數據開始時就一直持續存在,雙窗口能量檢測就會失效,會出現漏檢的問題,檢測的目的是寧可錯檢,也不漏檢。如果頭部并沒有檢測到信號,則使用雙滑窗對信號進行粗檢測,標記出信號的大概位置,以大概位置為中心,前后滑動的位置作為起點,分別進行獨特碼字的差分相關檢測,當信號中的獨特碼和本地獨特碼[10]完全匹配對齊時,相關峰值最大,從而得到突發信號的準確位置。
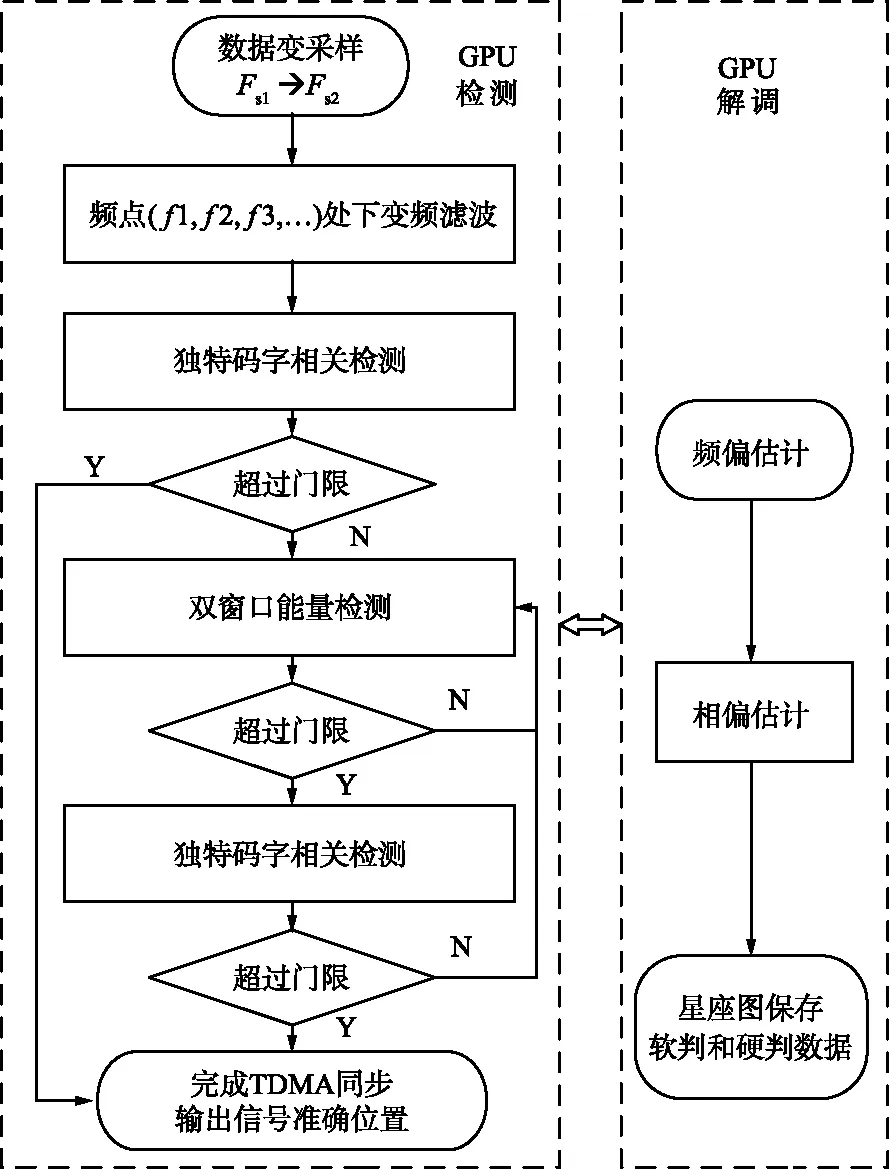
圖2 突發信號檢測流程
2 突發檢測算法研究
2.1 雙滑動窗口能量檢測法
通過設置2個連續滑動窗口,分別計算窗口的接收能量,用能量比作為判決變量。經典的雙滑動窗口算法[11-13]原理如圖3所示。窗口An與Bn同時向前移動,其中An與Bn分別為窗口An與Bn的采樣點能量和。計算公式如下:
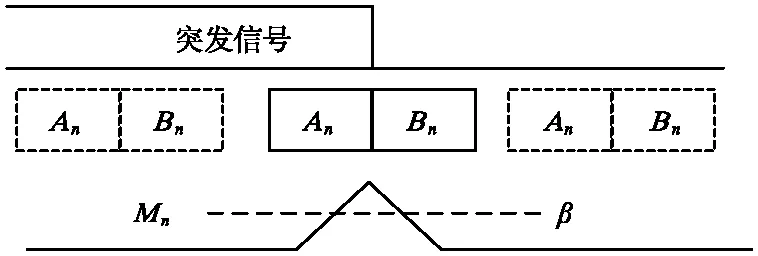
圖3 雙滑窗能量檢測
(1)
(2)
式中,L為窗口長度;rn為第n個采樣點的值。Mn為這2個窗口的比值,公式如下:
(3)
當Mn達到最大值Mmax時,其中參數β為參考閾值,β的取值與信噪比有關,且其大小會影響漏檢與虛檢概率,當Mmax大于β時便可判斷信號的大概位置。滑動窗口的寬度與信號寬度有關,一般取最小信號寬度。
2.2 基于獨特碼的分段差分相關檢測法
本文研究的是TDMA信號,精確地找到信號起點并進行保存,對后續解調至關重要。經過前面雙窗口的粗略檢測后,得到大概位置,以步長1為間隔左右移動后,將已知序列的獨特碼與偏移起點后的信號進行歸一化相關,暫存所得到的相關值和對應的起點,求得最大的相關值,若大于設定閾值,則更新對應的準確起點。
通過使用CoolEdit軟件查看衛星信號的時頻圖,存在不同長度的信號,分布在不同的頻點且間隔較小,實際衛星信號時頻域如圖4所示。根據通信協議,確定信號的時間長度主要為5,20 ms和80,2.2 ms,可以分為幀頭式、幀頭幀尾式和分布式,如表1所示。
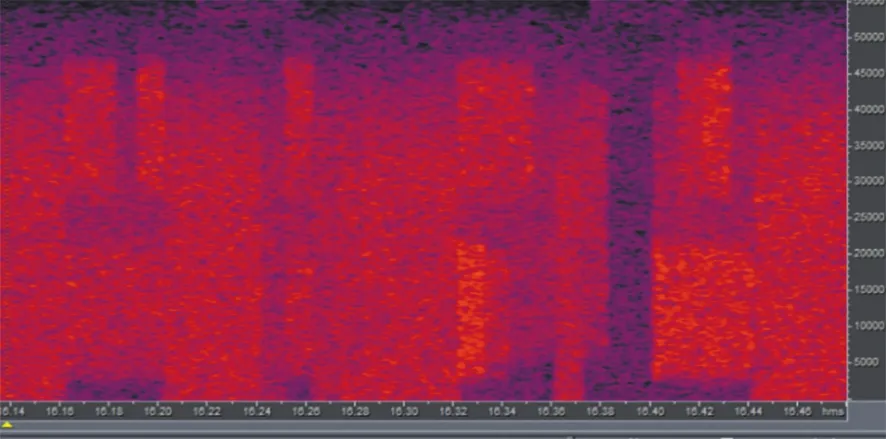
圖4 實際衛星信號時頻域

表1 海事衛星信號類型參數
TDMA信號幀結構如圖5所示。
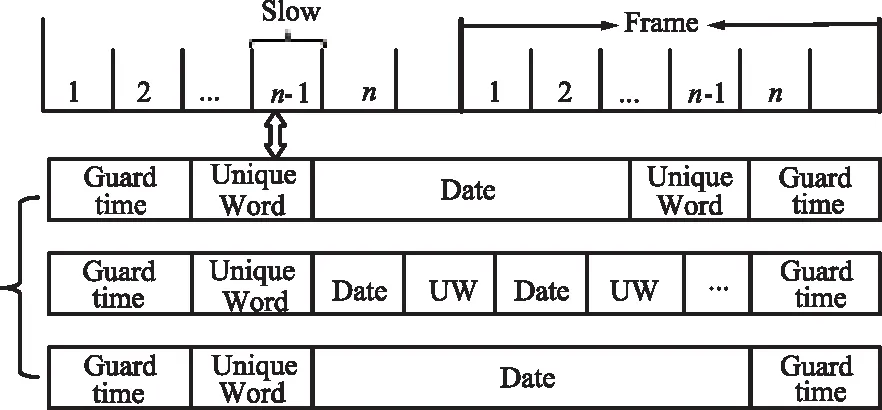
圖5 TDMA信號幀結構
以分布式為例進行說明,分布式信號的定義為:信號的獨特碼數據以信號起點開始,按照通信協議中規定的標號位置,不均勻地分布在整幀信號當中。
由于多普勒頻移的存在,衛星接收到固定地球站發來的信號,頻譜發生偏離,而衛星轉發給移動站的信號,在移動站收到后,也會產生一個頻率,當頻偏超過500 Hz,僅做相關檢測的性能大大降低。為了減小多普勒頻移對信號檢測的影響,采用分段差分相關的檢測方法。
分段差分相關檢測算法[14]結合了直接相關檢測和差分相關檢測算法的優點,將接收信號和本地序列分割成了等長的子序列,又將子序列分別直接相關,子序列間相關結果進行差分求和累加。設相關符號長度L=M×N,其中子序列數為M,長度為K。本地序列C={c0,c1,…,cM-1},其中cm={cm,0,cm,1,…,cm,K-1},cm,k=cmK+k表示第m子段中第k個本地符號,經變采樣[10-11]和下變頻后得到復基帶數據。以檢測的位置為起點,按照通信協議標記位置開始取值組合,得到含噪信號為R={R0,R1,…,RM-1},其中Rm,0={rm,0,rm,1,…,rm,K-1},rm,k=rmK+k=smK+k+wmK+k,其中smK+k,wmK+k分別為采樣信號中第m段子序列信號中第k個符號精確采樣時刻的有用信號值、噪聲值。
設recm為第m段接收信號和本地符號子序列的直接相關結果:
(4)
檢測結果為:
(5)
對信號的識別結果取模值后進行峰值搜索檢測,其算法流程如圖6所示。
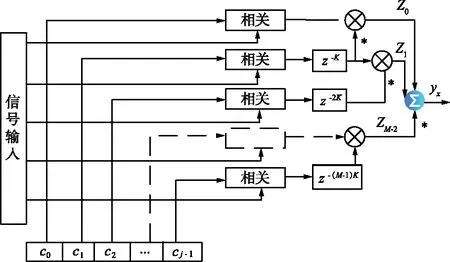
圖6 分段差分相關檢測算法流程
3 突發檢測CUDA并行處理
3.1 數據訪問的內存優化
GPU內存的訪問遵循合并對齊原則[15],因為GPU是以整個線程束為單位進行調度,一個線程束包括32個線程,一個線程束訪問一段連續內存時,就出現合并內存,線程束的對齊與合并內存訪問模型如圖7所示。
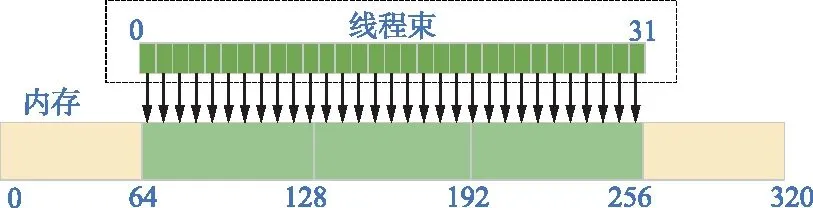
圖7 內存訪問模型
將參與運算的數據放到共享內存中,運算速度更快,例如計算窗口能量和時,將窗口內數據放到共享內存。信號的獨特碼模板放在常量內存中,當使用常量內存中的信號模板時,NVDIA硬件將把單次內存讀取操作廣播到每個半線程束。在半線程束中包含16個線程,是線程束中線程數量的一半,如果在半線程束中每個線程從常量內存的相同地址讀取模板數據,那么GPU只會產生一次讀取請求并在隨后將數據廣播到每個線程;如果從常量內存中讀取大量數據,這種方式產生的內存流量只使用全局內存的1/16。
3.2 多維度線程優化加速
為了大幅提升檢測性能,將雙滑窗能量檢測和基于獨特碼的分段差分相關檢測的雙重算法方案并行化處理,設計了多維度block和流架構并行優化多路多頻點的檢測。
雙滑動窗口法主要的計算量在于每滑動一次,都要分別計算2個滑動窗口的能量和,而每次滑動時要計算的數據都是相互獨立的[16],所以將算法在GPU中處理,用CUDA對其并行編程。
對于多路多頻點數據的同時處理,可以在block的X維度上劃分各路數據從而實現粗粒度上的并行,例如block.x0處理第1路數據,block.x1處理第2路數據,block.x(N-1)處理第N路數據;在block的Y維度上劃分每一路的不同頻點,例如block.y0處理第1個頻點,block.y1處理第2個頻點,block.y(M-1)處理第M個頻點,然后在每個block上分配多個thread,每個block里所有的thread再按照放置數據的長度等進行細粒度上的并行處理,如圖8所示。

圖8 多路多頻點CUDA并行編程模型
使每個thread處理的信號能量比的點數最多支持2 048個float類型的點,由于16 kB局部內存的限制,thread的數量等于輸入的基帶信號長度減掉16 kB后除以16 kB。按照輸入的信號長度為2 MB,計算可得每個頻點的突發數量最多允許128個,例如窗口的長度為WLEN,思路是先讓每個thread計算一個窗口長度WLEN的數據能量和,并放置于共享內存中,計算完成后再讓多線程去計算比值,最后找出第1個超出閾值的點進行輸出,如圖9所示,其中參與運算的信號數據都暫存在共享內存中。
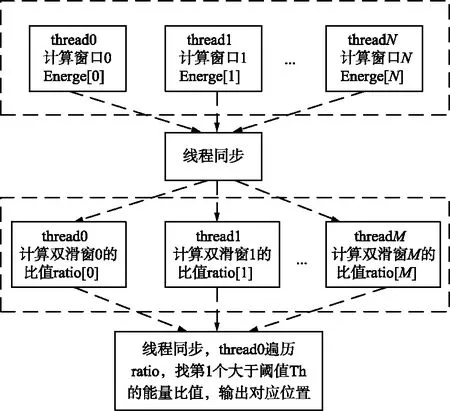
圖9 每個block處理流程
雙滑動窗能量檢測出信號的粗略位置后,在對應位置前后的范圍進行獨特碼字的相關檢測,檢測出第1個時隙信號的精確位置,即完成TDMA信號的時隙同步。以檢測出的第1個信號時隙為基礎,每隔1個時隙做1次能量和差分相關檢測,如果匹配到突發信號則截取輸出,這就是同步跟蹤過程[17]。
為了盡可能地把并行處理放到GPU中,設計了三維的block進行處理,類比雙窗口能量檢測的線程優化,將block的X維度作為路數,并行處理每路的數據,block的Y維度作為頻點數,每路信號存在于不同的頻點處,需要數字下變頻后再檢測,block的Z維度作為雙窗口能量檢測突發數量的最大值,一維thread的X維度為同步跟蹤起點的搜索范圍,設置為128。
分段差分相關檢測GPU工作流程如圖10所示。可以看到,把數據按照每一路讀進內存,每一路中包含有下變頻后不同頻點處的數據。通過前面能量檢測得到的信號粗略位置,在相關檢測過程中,以能量檢測的位置為基準,前后偏移64個點,分別以偏移后的位置為信號起點,偏移的點數可以根據具體GPU的性能來進行分配,但數量應為32的整數倍。這是由于設備是以整個線程束為單位進行調度[18-19],如果不把線程塊上的線程數目設置成32的整數倍,則最后一個線程束中有一部分線程是沒有用的,會耗損多次內存訪問事務。
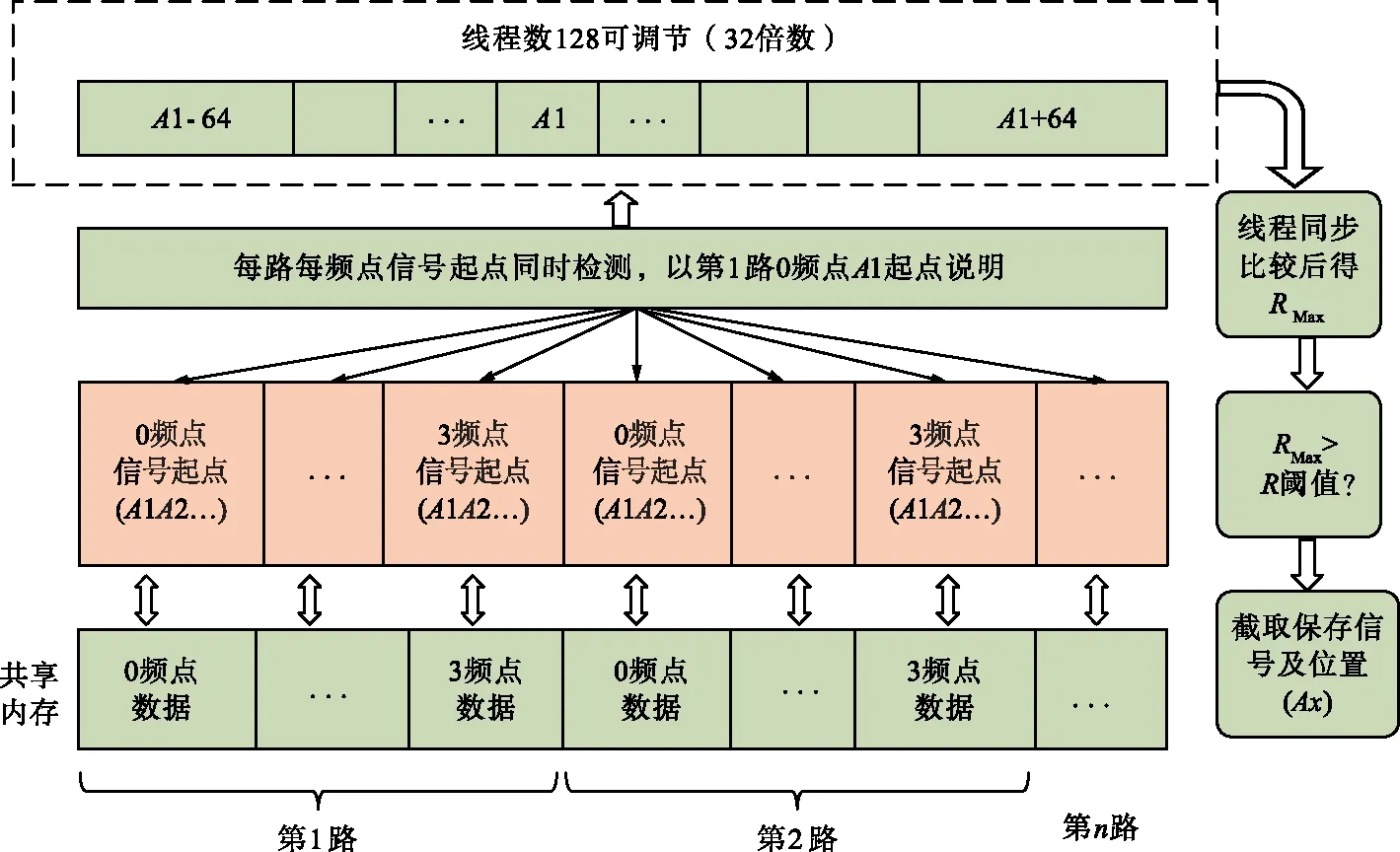
圖10 分段差分相關檢測GPU工作流程
每個新的起點分配一個線程,不同的起點處同時做差分相關檢測,數據的I路和Q路存放在共享內存中,分別與模板做乘加運算,計算出相關值,在GPU中需要進行同步操作,等待不同的線程全部處理結束,判斷出128個相關值中的最大值,超過規定閾值則截取保存信號,更新信號準確位置;否則,丟棄,繼續下一個準確位置的檢測。
考慮到一個完整的信號因為數據處理而被分割開,信號的起始點在上一段數據中,信號的結束點在下一段數據中,但可以把信號的起始點包含在緩存數據中,則在檢測過程中,信號在前一數據段的檢測中,判決達不到閾值而被丟棄,下一段數據中可以檢測出完整的信號。
3.3 基于流處理架構優化加速
在CUDA中使用多個流并行執行可以進一步提高計算性能,線程流中可以有多個線程塊,線程塊中可以有多個線程。上述使用的并行處理都是線程級別的,即CUDA開啟多個線程,并行執行核函數內的代碼,而線程流可以處理多個函數和同一個函數的不同參數。
以整個信號檢測算法為例,原本程序的3大步驟是順序執行的:先從主機拷貝初始化數據到GPU,再在GPU上執行核函數,數字下變頻濾波、雙窗口能量檢測以及差分匹配相關,順序執行,最后將計算結果從GPU拷貝到CPU,進行解調。當數據量很大時,每個步驟的耗時很長,后面的步驟必須等前面執行完畢才能繼續,整體的耗時相當長,當每次讀入一路數據就達到幾十MB時,多路讀入時主機和設備間拷貝將占用上百毫秒的時間,有可能要比核函數計算的時間要多。信號檢測流程處理架構如圖11所示,可以將每一路數據用流來執行,每一路再執行多個頻點的同時信號檢測,這樣也就是將上述第一維度用流來代替執行,在每個線程流中同時執行多個頻點的信號檢測,其余分配方式不變,流水線并發執行,性能會有很大的提升。
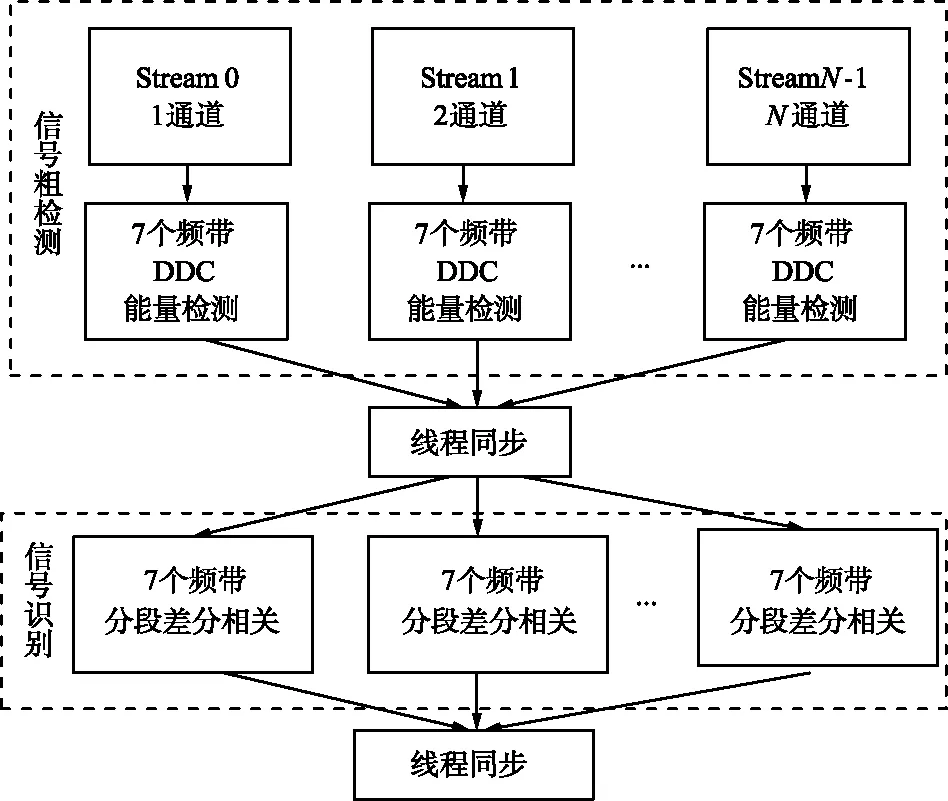
圖11 信號檢測流處理架構
4 實驗結果與分析
4.1 仿真結果
仿真條件:實際的衛星信號,符號速率為33.6 kHz,采樣速率為537.6 kHz,信號中心頻點出現在12.5 kHz附近,數字下變頻之后的信號如圖12所示,信噪比為6 dB,驗證使用不同數據類型進行相關檢測的性能,碼元/波形時域直接相關峰值如圖13所示。
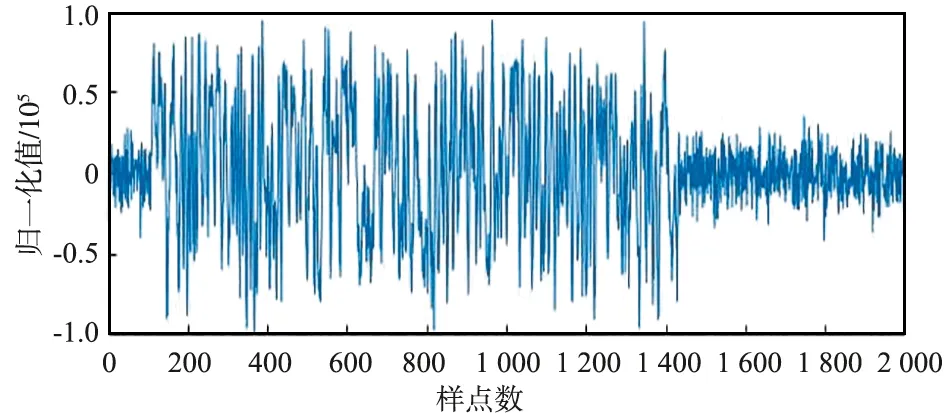
(a)DDC信號的實部
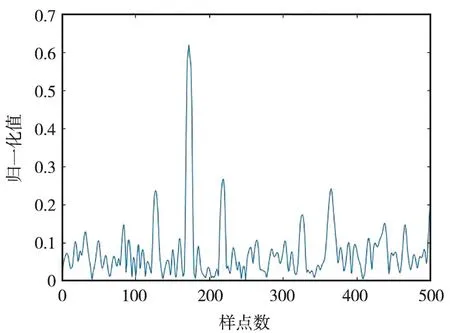
(a)碼元時域直接相關
碼元/波形時域分段差分相關峰值如圖14所示。
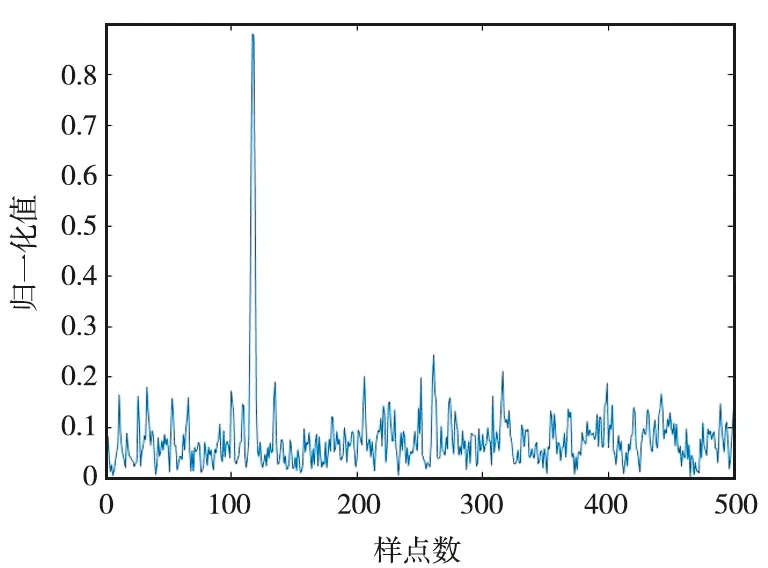
(a)碼元時域差分相關
由仿真結果可知,波形相關檢測的效果更好,對噪聲的抑制能力更強,分段差分相關相比于直接相關檢測具有更高的峰值比,易于閾值的設定,減小誤檢率,即使在較低信噪比的條件下,該算法依舊能較準確地對信號起始位置進行高效、精準地定位,漏檢率低,滿足工程要求。
4.2 實驗環境
本次實驗采用的平臺詳細配置如表2所示。

表2 實驗平臺的配置
在不同的信噪比下,信號突發數恒為1 000幀的信號時,60 MB的數據包,7個檢測頻點,測試了單路和多路信號C代碼、多維度和流架構的CUDA代碼,實驗加速比如表3所示。實驗表明,用CUDA對檢測算法進行并行優化的程序,在相同的信噪比條件下,單路速度提升約40倍,5路速度提升約60倍,10路速度提升約100倍,并且隨著處理路數越多,信號檢測頻點越多,CUDA加速越明顯,流架構的使用更進一步提升了檢測性能。
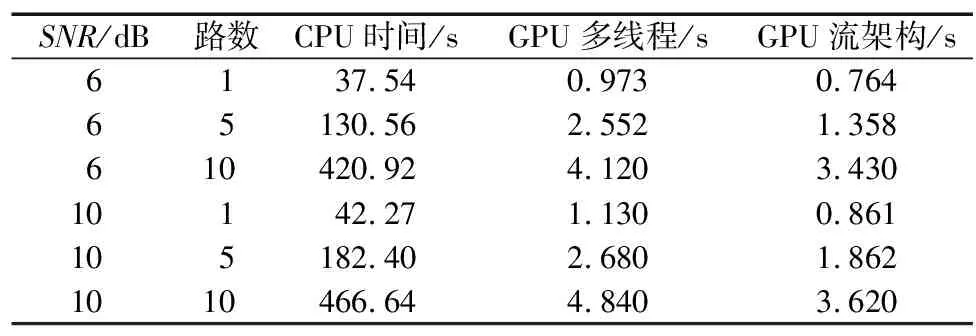
表3 實驗加速比
另外,由信號的采樣率537.6 kHz和數據量60 MB可計算出信號的時間約為57 s,小于程序的處理時間,所以是實時處理的,同時可實現最高64路信號的實時檢測。
誤檢概率和漏檢概率如圖15和圖16所示,在信噪比相同的情況下,分段差分相關檢測的漏檢概率與誤檢概率要低于直接相關檢測,當信噪比達到7~8 dB時,檢測方案非常實用且性能穩定,達到10 dB時具有理想的漏檢概率和誤檢概率。
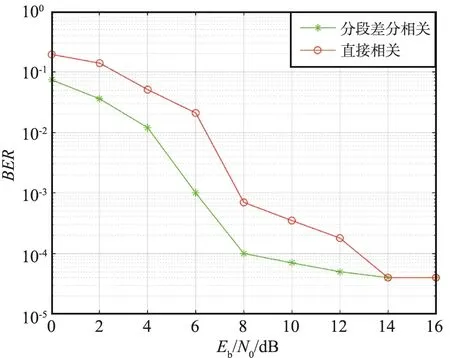
圖15 誤檢概率
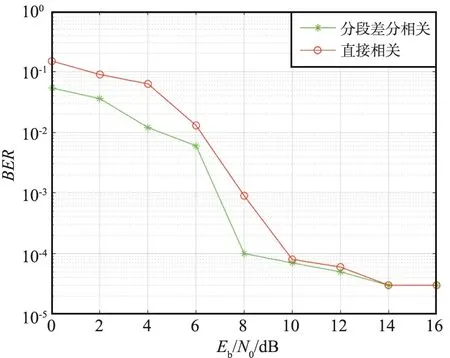
圖16 漏檢概率
5 結束語
本文研究了非合作通信條件下突發信號的檢測算法,在GPU平臺上實現了多路多頻點衛星信號的檢測并行化。利用分段差分的算法提高了信號檢測的準確率,利用GPU的多線程結構和流架構對檢測算法并行化處理,從內存訪問事務和內存存取方面進一步提高了信號檢測的實時性,具有極大的靈活性,今后可以使用算力更強的GPU運算,只需調整kernel函數的線程維度參數,就可以發揮設備的最大潛力,進一步提高檢測性能。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
鴨綠江(2021年35期)2021-04-19 12:24:18
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
中國生殖健康(2019年3期)2019-02-01 06:12:26
海峽科技與產業(2016年3期)2016-05-17 04:32:12
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
