基于深度學習的駕駛艙面板字符識別
2022-11-24 07:37:16彭衛東李娜魏麟
新型工業化 2022年9期
彭衛東,李娜,魏麟
中國民用航空飛行學院 航空電子電氣學院,四川廣漢,618307
0 引言
隨著深度學習技術的發展,其已在智能語音識別、自然語言的處理、計算機視覺、圖像識別與視頻分析及多媒體等諸多新興領域中應用。字符識別技術也隨著深度學習技術的不斷發展逐漸成熟,其應用范圍也逐漸擴展,未來在各領域中將會扮演重要角色[1]。傳統的字符識別流程包括對字符進行預處理、識別階段和進行后處理三個部分,其中識別階段對每個字符進行分割、單字符處理和單字符輪廓查找,再進行后處理得到比對結果。在對字符組進行單個分割操作時產生的誤差積累[2],使得傳統方法對字符識別速度和精度效果不佳。隨著深度學習技術的發展,針對字符分割累計誤差,以及特征提取依賴人工、識別速度慢等缺點,提出了深度學習端對端字符識別方法,即單階段算法,對整個字符一次性進行檢測識別,減少了由于字符分割造成的誤差累積[3-4],由數據驅動進行特征提取,模型泛化能力更好,且檢測識別速度和精度有大幅度提升。單階段主要識別算法有Yolov1[5]、Yolov2[6]、Yolov3[7]、SSD[8]等,其中Yolo系列算法是采用回歸思想檢測識別,SSD取卷積神經網絡不同的特征層檢測輸出,是一種多尺度的檢測方法。本實驗在考慮面板字符特征的基礎上,選用Yolo系列端對端深度學習方法[9],并結合OpenCV的深度神經網絡(deep neural network,DNN)模塊調用訓練好的模型來識別面板字符。
1 總體設計方案
將檢測識別設計分為數據預處理、數據訓練以及目標檢測識別三個階段。使用公開字符數據集中圖片和自收集圖片組成本實驗的整體數據集,數據標注軟件將數據集標注成訓練所需要的文件格式,數據進行迭代訓練使用的是輕量級Yolo-Fastest算法,收斂生成針對字符識別的權重文件,檢測識別部分選擇OpenCV開源庫的深度學習DNN模塊,調用部署訓練好的深度學習模型來檢測面板字符,使其運行效率更高。
1.1 Yolo算法介紹
Yolo算法是單階段目標檢測網絡,其算法采用回歸思想,將目標檢測轉成回歸問題。如圖1所示為Yolo算法基本檢測流程,使用卷積神經網絡得到一個固定大小的特征圖,接著CNN將輸入圖像劃分成S×S網格,每個單元格負責預測中心點落在該格子內的目標,每個網格預測B個邊界框(bounding box)和邊界框位置(x,y,w,h)及置信度(confidence score),用非極大值抑制算法得到最后的目標結果。在Yolo系列算法中,Yolo-Fastest模型尺寸最小,檢測精度優于Yolov1、Tiny Yolov2 和 Tiny Yolov3,檢測速度優于Yolov2,能夠支持PyTorch、Tensorflow、Keras、Caffe等深度學習庫,且在硬件設備上更容易部署[10]。本次實驗類別只有一類Text類,在考慮精度和速度的同時,選擇Yolo-Fastest為本次實驗的算法模型檢測面板字符,使用OpenCVDNN深度學習模塊調用訓練好的模型最后識別面板字符。

圖1 Yolo檢測流程
1.2 Yolo-Fastest網絡結構介紹
Yolo-Fastest是一種開源的基于Yolov3框架的輕量級目標檢測算法,傳統Yolov3基于Darknet53網絡,共有73層,其中卷積核大小為3*3和1*1的卷積層有53層,其余為殘差層。Yolo-Fastest網絡由主干網絡和深層網絡層組成,主干網絡用于提取圖像特征,深層網絡層的作用是提取目標物的邊界框,Yolo-Fastest為減少模型的參數量和運算量,在主干網絡中大量采用深度可分離卷積并減少了網絡的層數,主干網絡由27個層組成,第一層為標準卷積層,其余層均為深度可分離卷積層,深度可分離卷積極大減少了計算量,縮小了網絡模型[11]。Yolo-Fastest的損失函數是在Yolov3損失函數的基礎上將x,y,w,h的坐標損失從交叉熵損失換成了CloU[11],式(1)-(3)為其損失函數計算公式,公式中的損失函數考慮了重疊面積、中心點距離和長寬比。其中v是長寬比的相似性,c是對角線距離,a是權重參數。
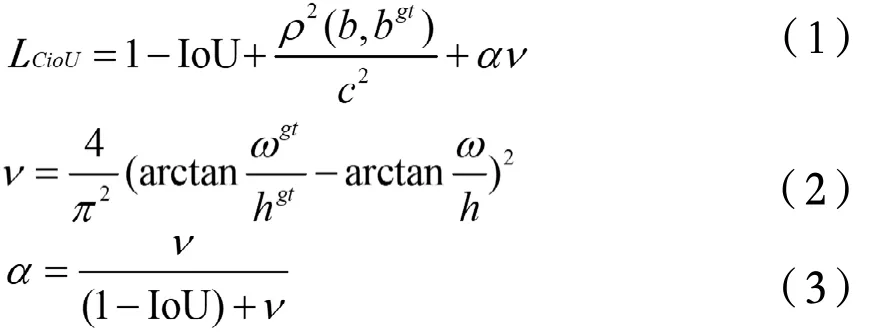
2 實驗設計
2.1 數據預處理
Yolo-Fastest使用VOC數據集框架模型,所以需要根據VOC數據集的框架構建數據集。本實驗使用ICDAR2013公共數據集以及自收集圖片共同組成實驗數據集,選用VOC2007數據集制作軟件對原圖片統一命名,處理生成xml格式標注文件,文件內容有圖片文件名、尺寸大小以及圖片中包含的目標以及目標信息,其中xmin和ymin分別為每個目標框的左上角坐標,xmax和ymax為右下角坐標;xml格式轉換成Yolo使用的標注txt格式文件,標注后的每個txt文件包含5個數值,分別是所標注內容的類別、歸一化后的中心點x坐標、歸一化后的中心點y坐標、歸一化后的目標框寬度w、歸一化后的目標框高度h[12],本實驗的實驗數據集類別只有text類,標注內容的類別顯示為0。
2.2 數據訓練
數據集進行訓練時,需要對配置文件進行修改,根據硬件配置和數據集類型修改Yolo-Fastest的配置文件中相關參數,將類別classes設置成1,圖片輸入信息為416*416*3,權重衰減系數為0.0005,防止過擬合,初始學習率為0.001,執行指令生成預訓練權重文件,生成的預訓練權重文件大小為821kB。開始正式訓練,將訓練次數設置成35000,每訓練1000次,保存一次權重。
2.3 OpenCV-DNN模塊調用Yolo-Fastest
OpenCV開發的DNN模塊可以專門用來實現深度神經網絡的相關功能。OpenCV無法訓練模型,但可以載入訓練好的深度學習框架模型,用該模型做預測,OpenCV在載入模型時會使用DNN模塊對模型進行重寫,使得其運行效率更高。
OpenCV的DNN模塊做Yolo-Fastest的前向推理時,所需要調用的是訓練數據集時的配置文件和訓練數據集最后生成的權重文件。DNN模塊重新部署深度學習模型時,需要用到如下關鍵函數處理,OpenCV的DNN模塊通過讀取輸入的配置文件和訓練好的權重文件來初始化Yolo-Fastest網絡。detect函數對輸入的圖像做目標檢測,畫出圖中物體的類別和矩形框,其中dnn.blobFromImage實現了每一幀圖片的預處理,dnn.NMSBoxes根據給定的檢測boxes和對應的scores進行非最大抑制處理,目標檢測算法會給圖片上所有物體產生多的候選框,候選框可能會相互重疊,非最大抑制就是保留最優的候選框。
3 結果分析
用A320飛機駕駛艙靜態模型圖片和計算機攝像頭動態識別模型圖片進行對比測試。先使用OpenCV的DNN模塊加載Darknet模型配置和已經訓練好的權重文件來做測試,檢測識別單張圖片所需要的時間約為16.01ms,如圖2所示。用計算機攝像頭近距離實時識別駕駛艙面板模型,截取隨機一幀圖片識別的時間約為13.74ms,如圖3所示。用Yolo-Fastest模型進行檢測識別單張圖片需要438.992ms。可以看出,使用OpenCV的DNN模塊部署深度學習模型識別面板字符的速度更快。

圖2 OpenCV-DNN識別結果

圖3 截取某一幀圖片識別結果
4 結論
本文使用主流的Yolo系列目標檢測算法,制作字符數據集并用Yolo-Fastest算法生成模型權重文件,在圖片檢測識別部分使用OpenCV實現神經網絡的DNN模塊,部署調用訓練好的配置文件和模型權重文件,識別駕駛艙面板字符。從實驗結果可以看出,該方法識別字符的速度較快,能夠滿足駕駛艙字符識別的實時性,具有一定的應用價值。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
