高校圖書個性化推薦系統設計
2022-12-01 11:02:14郭晨睿
科教導刊·電子版 2022年25期
郭晨睿
(洛陽師范學院 信息技術學院,河南 洛陽 471934)
0 引言
高校圖書館具有琳瑯滿目、資源豐富的藏書,為高校師生提供了自由完善的圖書借閱服務。但是,用戶從海量的圖書中準確地找到自己想要借閱的圖書資源往往花費大量的時間與精力,且隨著圖書數量的增多,搜尋自己感興趣圖書的難度越來越高。
因此,圖書個性化推薦系統應運而生,圖書個性化推薦系統是通過對大量的借閱歷史等信息進行挖掘的基礎上,根據用戶的興趣、偏好等特征及圖書資源的特征,向用戶推薦其可能感興趣的圖書資源,節省用戶挑選查找圖書的時間與精力,提高了圖書資源的利用率。目前圖書館主要采用新書與熱門圖書的推薦方式為用戶推薦圖書,上述方式在一定程度上滿足了用戶對圖書的需要,但缺少對圖書的個性化推薦,且推薦效率較低,不能滿足大部分用戶的需求[1-5]。
1 高校圖書個性化推薦系統
1.1 系統總體結構
根據用戶對圖書的需要設計了高校圖書個性化推薦系統,該圖書個性化推薦系統主要由顯示層、推薦層和數據層三個部分組成,如圖1(P105)所示。
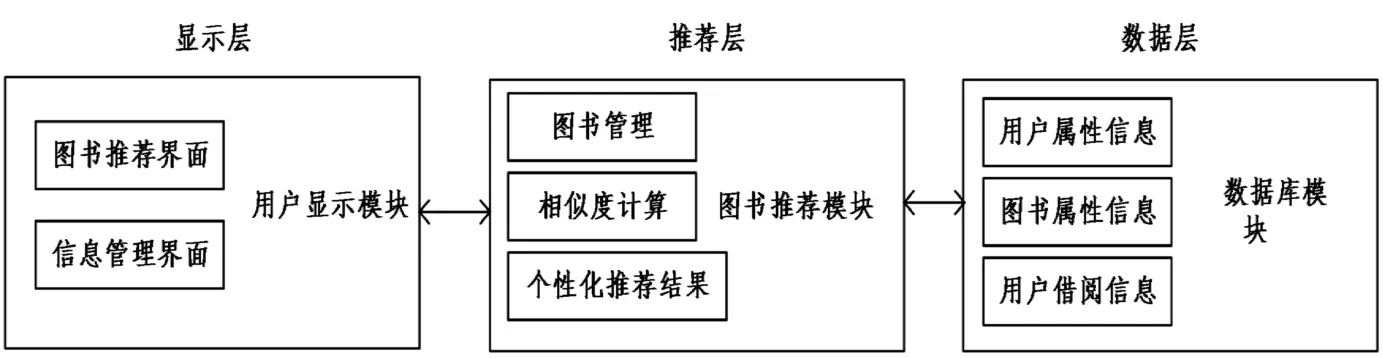
圖1 系統總體結構圖
位于系統最底層的是數據層,由數據模塊組成,數據層負責用戶屬性信息、圖書屬性信息以及用戶借閱信息的收集,收集到的相關數據通過圖書推薦模塊通過相似度計算獲取個性化推薦結果[6]。數據層包含了大量的用戶信息、圖書信息以及用戶對圖書的借閱信息,為圖書個性化推薦提供了數據支持。
推薦層是圖書推薦系統的核心,由圖書推薦模塊組成,在接收到顯示層用戶的查詢后,將由數據層提供的數據利用個性化推薦算法對圖書進行快速處理,處理結束后將推薦結果反饋到顯示層推薦給用戶。管理員與用戶的各項操作均需要通過推薦層進行處理。
系統的顯示層由用戶顯示模塊組成,通過系統的顯示界面與用戶實現人機交互。高校師生通過用戶顯示模塊登錄系統后,利用圖書名稱等相關信息對圖書進行檢索與查看,并將圖書推薦模塊生成的推薦圖書展示給用戶。
1.2 系統功能模塊
根據用戶個人需求的高校圖書個性化推薦系統功能主要包括用戶信息管理、圖書信息管理以及個性化推薦三部分,如圖2(P105)所示。
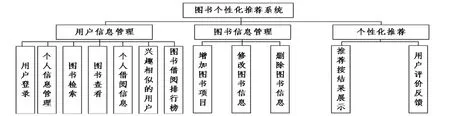
圖2 系統功能結構圖
(1)用戶信息管理。該功能主要包括用戶登錄、個人信息管理、圖書檢索、圖書查看、個人借閱信息、興趣相似的用戶以及圖書借閱排行榜。用戶登錄推薦系統后通過個人信息管理部分進行個人密碼、郵箱與手機號等相關信息的修改;可以進行圖書的檢索與查看;可以查看自己借閱圖書的歷史信息;可以通過興趣相似的用戶功能關注、查看與自己具有相似興趣的用戶的相關信息(用戶可以設置自己的信息是否讓別人查看);可以通過圖書借閱排行榜查看借閱熱門的圖書。
(2)圖書信息管理。該功能主要包括增加圖書項目、修改圖書信息與刪除圖書項目三部分。管理員登錄系統后,選擇利用該功能添加新進的圖書,并刪除已經報廢的圖書,還可以對圖書的數量等信息進行更改。
(3)個性化推薦。該功能主要包括推薦結果展示與用戶評價反饋兩部分,用戶通過推薦結果展示獲取系統個性化推薦的結果,并通過反饋區域對該系統推薦結果提出意見與建議,為進一步優化系統做提供理論支持。
1.3 系統工作流程
圖書個性化推薦系統的工作流程如圖3所示。從圖3中可以看出圖書個性化推薦共分為9個步驟,系統數據初始化,主要是對用戶的學科、性別與年齡等相關信息的權重系數的初始化;數據采集過程主要采集用戶的基本信息(包括:姓名、學號、專業與性別等信息)、圖書屬性信息(包括:圖書名稱、作者、類別、ISBN等信息)以及用戶的借閱信息;數據預處理階段主要是對收集到的數據進行數據清洗,并將清洗后的數據進行分類匯總后存儲到圖書個性化推薦系統的數據庫中;分別使用協同過濾與用戶專業計算用戶之間的相似度,并將二者進行線性加權求和獲得最終的相似度,生成具有相似興趣的用戶并展示在“興趣相似的用戶”功能處,然后將生成的圖書推薦目錄顯示在“推薦結果展示”功能處。
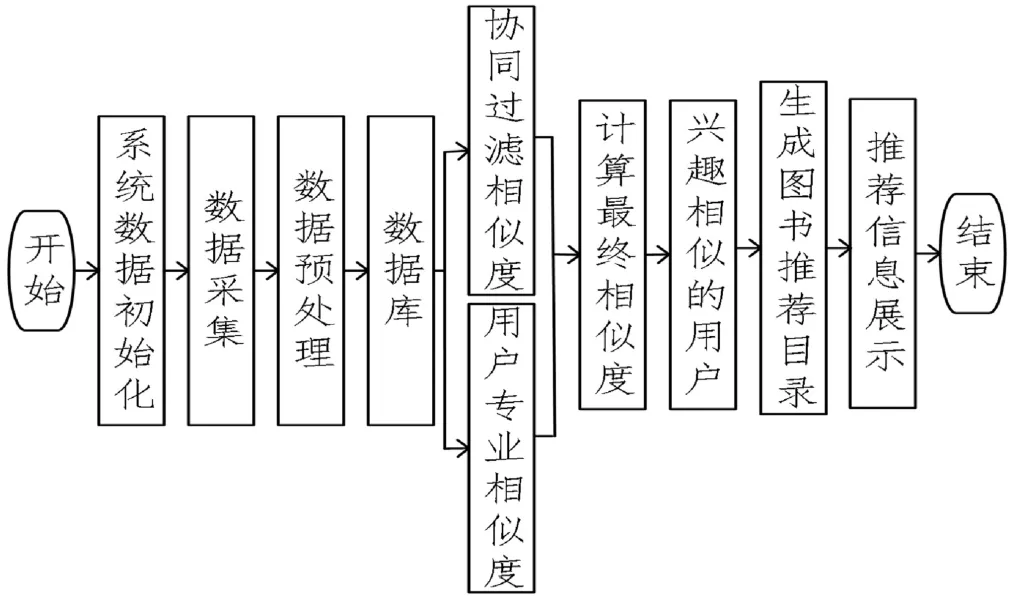
圖3 圖書推薦系統工作流程圖
1.4 基于協同過濾的圖書個性化推薦算法
1.4.1 基于協同過濾的用戶相似度計算
使用協同過濾計算用戶之間的相似度,需要用戶對圖書的評分,當前高校圖書管理系統中沒有用戶對圖書的評分或評分較少,本文根據用戶借閱圖書的時長來計算用戶對圖書的評分,將讀者的借閱信息轉化為相應的評分信息,量化用戶對圖書的喜愛程度[5]。默認用戶借閱圖書的時間越長表明用戶對圖書的評分越高,同時考慮每位用戶的閱讀速度等因素,采用公式1計算用戶對圖書的評分。

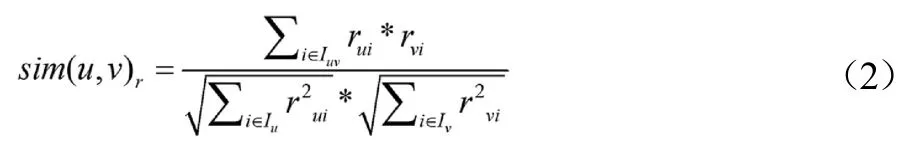
1.4.2 基于用戶專業的相似度計算
由文獻[2]可知:屬于相同或相近專業的用戶,相同或相近專業的用戶在圖書借閱行為上具有極大的相似性。根據這一原理,認為同一學院或不同學院相近專業的用戶具有很高的相似性,根據用戶的學院、專業等信息計算用戶之間的相似度。依據國家標準學科分類與代碼表,按照三個級別對學科進行分類[3],用戶 和用戶 的學科距離使用表示,如果用戶u和用戶v的三級學科一致則;如果用戶u和用戶v的二級學科一致則,如果用戶u和用戶v的一級學科一致則,如果用戶u和用戶v的不級學科一致但是一級學科相似則,如果用戶u和用戶v的一級學科不一致且一級學科也不相似則。用戶u和用戶v的學科相似度由公式3計算獲得。

1.4.3 用戶相似度
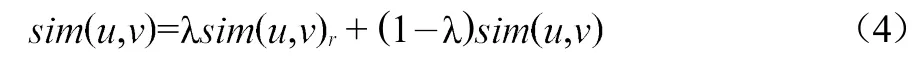
1.5 生成推薦目錄
通過公式4計算目標用戶與其他用戶之間的興趣相似度,找到目標用戶興趣最相近的位用戶,并根據這位用戶對圖書的評分,預測目標用戶對未看過的圖書的評分,并依據預測評分值將的評分圖書作為推薦圖書推薦給目標用戶,并顯示在“推薦結果展示”功能處。
均值中心化的基本思路是用戶對圖書的標準化評分的正負情況可以直觀地表現用戶對該圖書的喜好或厭惡程度。把用戶對圖書的評分減去該用戶對所有圖書評分的均值。因此,首先需要計算目標用戶u對所有圖書評分的均值,然后將目標用戶u對所有圖書的評分都減去均值。然后通過公式5計算用戶u對圖書i的評分作為目標u用戶借閱圖書的概率。

2 系統測試
為了檢測本文研究圖書個性化推薦系統的推薦性能,選取某高校圖書館作為實驗對象,根據該校計算機科學與技術專業某學生登錄本文的推薦系統,系統推薦結果如圖4所示。從圖4系統的推薦結果展示中可以看出,本文的圖書推薦系統可針對該用戶個人的興趣偏好為其推薦符合用戶個性化需求的《大話數據結構》《機器學習》等圖書,有效驗證了本文圖書個性化推薦系統的推薦有效性。
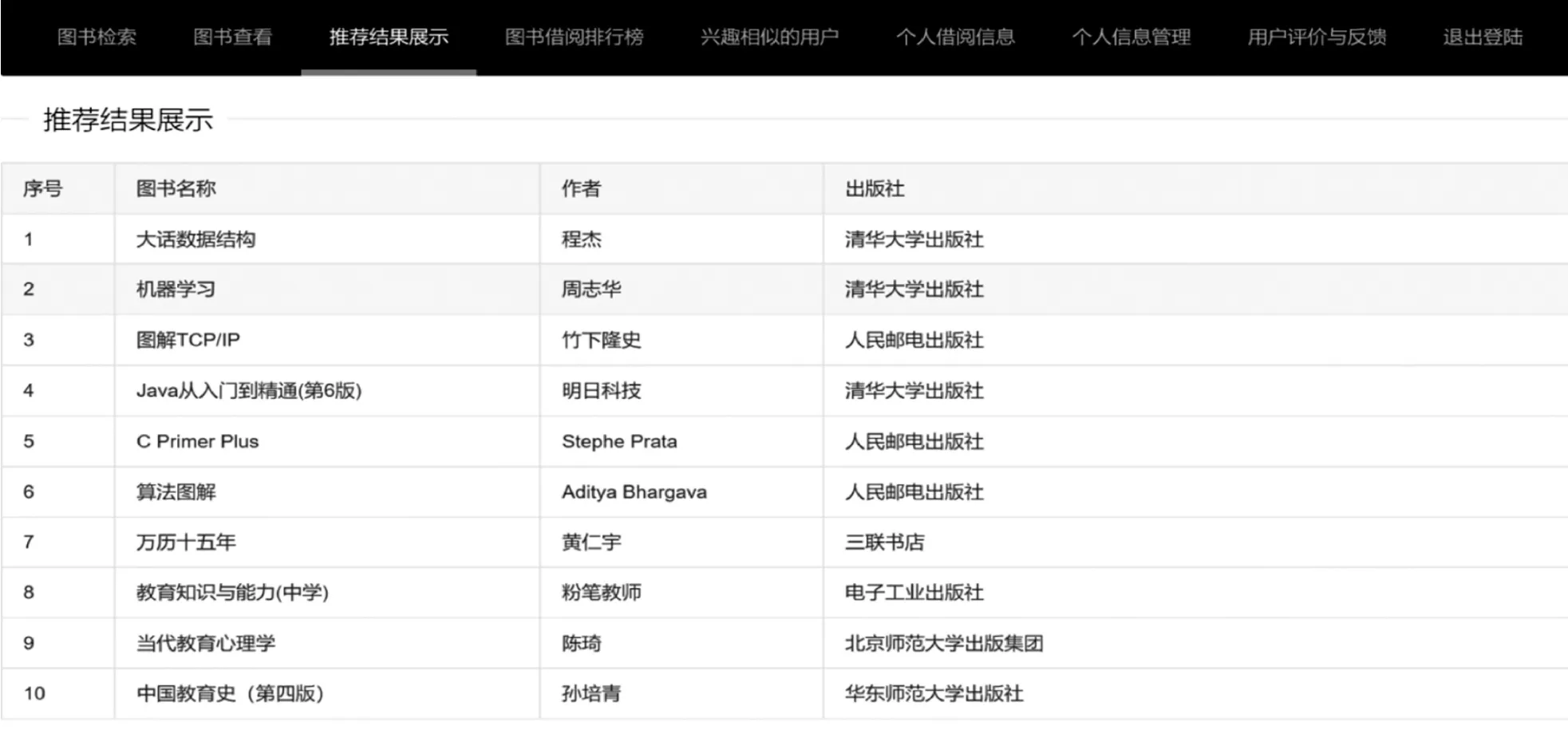
圖4 圖書個性化推薦系統推薦頁面
3 結語
高校圖書個性化推薦系統的好壞對學生閱讀習慣的養成具有重要作用,高效的圖書推薦系統不僅可以有效節約學生找書的時間,優化借閱體驗,提高學生的閱讀興趣,擴展學生的閱讀視野;同時可以把圖書館中的圖書有針對性的推薦給可能會借閱的學生,提升了圖書館圖書的利用率。本文首先利用用戶的借閱時長計算用戶對其借閱圖書的評分,并結合基于用戶的協同過濾算法計算用戶與用戶之間的相似度;然后使用用戶的專業計算用戶與用戶之間的相似度;將協同過濾與用戶專業計算獲得的相似度進行線性加權求和,獲得用戶與用戶之間最終的相似度;最后,使用均值中心化計算用戶借閱圖書的概率,推薦圖書并生成推薦圖書目錄,興趣相似的用戶功能幫助許多用戶找到了志同道合的朋友。
猜你喜歡
寧波大學學報(理工版)(2022年4期)2022-07-08 05:12:02
華北理工大學學報(自然科學版)(2021年3期)2021-07-03 09:06:34
軍事文摘·科學少年(2017年4期)2017-06-20 23:29:09
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
中央社會主義學院學報(2016年2期)2016-05-04 04:18:29
創業家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
