基于伴隨式數據采集和決策樹算法的智庫人才信息處理技術
2022-12-01 06:00:34韋冬妮車彬張澤龍唐夢媛齊彩娟
電子設計工程 2022年23期
關鍵詞:信息
韋冬妮,車彬,張澤龍,唐夢媛,齊彩娟
(國網寧夏電力有限公司經濟技術研究院,寧夏 銀川 750002)
智庫是企業戰略研究以及擁有強大競爭力的關鍵,企業智庫信息的管理覆蓋面廣、涉及數據量大,需要應用的技術手段眾多[1-3]。目前,企業智庫通常缺乏系統、高效的數據管理模式,且在利用智庫數據進行培養結果評價和人員崗位匹配等方面不夠深入,海量的數據管理難以產生邊際效益[4-7]。企業智庫蘊含著大量關于人才培養過程的數據信息,如何結合先進的信息處理技術,深入挖掘出它的價值,推動企業人才隊伍建設,是值得重點研究的問題。
針對此問題,該文將伴隨式數據采集和決策樹技術應用于智庫信息處理,實現了人才評價分類與精準崗位匹配,優化了企業人才資源的配置。
1 伴隨式數據采集技術
數據采集是實現智庫信息流動、人才評價的基本前提。智庫人才評價的實現是以動態學習、數據分析為基礎,通過存儲、訪問、處理相關學習數據,在智庫人才信息管理的同時實現伴隨式評價[8]。
該文構建的基于伴隨式智庫信息系統架構,如圖1 所示。其包括系統層、服務層、數據層和應用層[9],從課程面授、實踐操作、案例示范、崗位指導這四類不同的培養場景出發,實時獲取人才素質數據信息,并動態分析人才素質特征,從而實現人才素質特征的準確智能分類[10]。
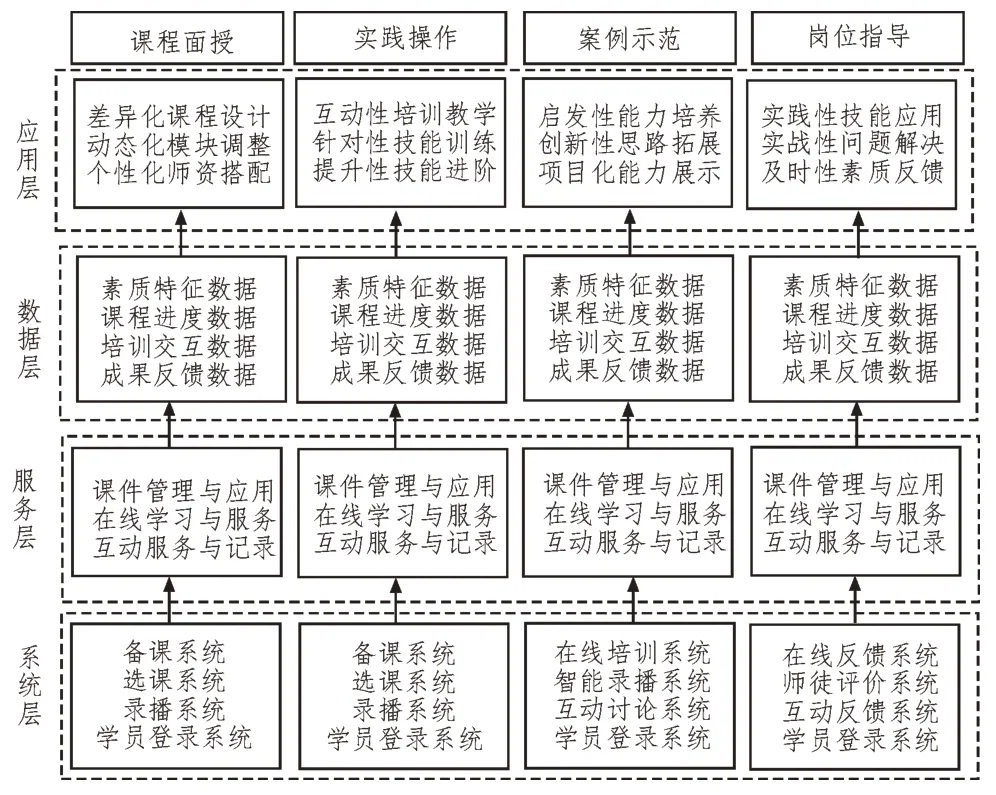
圖1 基于伴隨式數據采集的智庫信息系統架構
1.1 數據存儲
數據存儲技術主要用于實現學員個人信息、曾參與的項目成果、工作學習經歷等人才素質數據的大規模存儲。該文采用了Hadoop 分布式文件系統(HDFS),該系統是當前的主流大數據存儲框架方案之一。HDFS 適用于海量數據結構場景,融合元數據與數據塊技術實現數據信息的集中管控和分布式儲存,不但具有高度容錯的性能,而且適用于智庫海量數據的存儲,同時,也可以兼顧數據使用過程中的準確抽取。
1.2 數據訪問
數據訪問技術能夠支持學員根據自身情況隨時獲取智庫信息系統的教學內容等課程數據,采用的核心技術主要有Pig、Hive、Sqoop 等。Pig 是一種適用于HDFS 系統的高級編程語言,能夠實現將數據查詢請求分解為快速優化的MapReduce 運算,且支持并行處理;Hive 是一種數據庫管理工具,能夠實現HDFS 系統中海量數據的快速檢索與獲取;Sqoop 是一種開放性的數據處理工具,能夠實現HDFS 系統與常規數據庫的數據信息傳輸。
1.3 數據處理
數據處理技術用于實現培訓指導過程中教學互動數據的處理分析,具體的技術解決方案為HBase和Flume。HBase 是一種針對列存儲應用的非關系型數據庫,其綜合性能優異,可以實現大規模數據集的實時讀寫;Flume 是由Cloudera 開發的日志收集系統,提供分布式數據流收集服務。
1.4 數據分析
數據分析技術利用智庫信息系統中學員參與課程的數據,為學員提供崗位匹配、課程評價、課程改進等相關數據服務。其中,通常使用的數據分析技術有Mahout 和Hama 技術。Mahout 是開放性的代碼庫,支持分散式人工智能學習,能夠實現應用服務程序的快捷創建;Hama 可以支持海量數據并行計算,在矩陣分析、圖譜計算等方面應用廣泛。
2 基于決策樹的人才崗位匹配算法
人才崗位匹配是利用智庫信息系統中的相關數據,通過決策樹算法實現素質分析和崗位匹配的過程。在智庫信息系統中,學員的相關數據信息是海量、無序的。為了從大規模數據中提取學員素質特征,通常利用信息處理技術來實現[11]。目前在信息處理技術方面,經常使用的有聚類算法和決策樹算法[12]。決策樹算法是一種利用樹狀結構實現數據分類的人工智能算法,其關鍵技術在于構建決策樹。在決策樹生成的過程中已實現數據樣本的分類,對于后續待分類的樣本,僅需依據已生成的決策樹由上至下搜索,即可實現快速、精準地分類[13]。
2.1 決策樹算法
2.1.1 信息熵
信息熵表征的是一個隨機變量的不確定性,在現實世界中,隨機變量的特征只能通過有限次數的樣本進行模擬。對于有限的樣本集合,信息熵表征該樣本集合的混亂程度,其值越高說明樣本集合的不確定度越強。對于樣本集合D,其信息熵定義為:
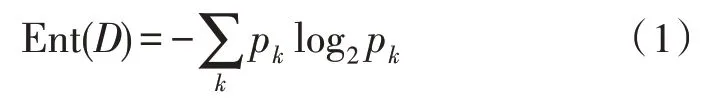
式中,Ent(D)為樣本集合D的信息熵;pk為樣本集合D中第k個樣本所占的比例。
以屬性A對樣本集合進行劃分,屬性A可能取值的集合為{a1,a2,…,aV},其中V為屬性A可能取值的種類數量,記DV為屬性A上取值為av的樣本集合,即有:

則根據屬性A進行分類,降低樣本集合D的不確定度收益,其信息增益為:

式中,Gain(D,A)為根據屬性A進行分類時,樣本集合D的信息增益。
2.1.2 決策樹的生成與計算流程
決策樹算法的關鍵在于生成決策樹,決策樹生成的過程主要為:以數據樣本的信息增益最大為分類依據,從初始節點開始直至末端節點,不斷重復地尋找最優的劃分數據樣本的屬性特征[14-16]。具體實現過程描述如下:
1)構建訓練集合。訓練集合由描述性屬性元素和目標屬性元素構成,構建訓練集的過程,其本質是將學員的素質特征數據從智庫信息系統的海量數據中抽取出來,為構建決策樹提供數據分析基礎。
2)根據目標屬性元素計算訓練集原本的信息熵,計算方法如式(1)所示。
3)搜索初始節點。首先,對于每一個描述性的屬性進行分類;然后,根據式(3)計算訓練集合的信息增益;最后,選取信息增益最大的描述性屬性作為初始節點。
4)對于每個節點,根據所有其他描述性屬性進行分類,計算訓練集合的信息熵增益,選取信息增益最大的描述性屬性作為分支節點。
5)重復步驟4),直至滿足以下條件之一,結束循環:①所有末端節點的元素均屬于目標屬性;②所有描述性屬性均已劃分完畢;③描述性屬性的某個取值未有樣本。
決策樹算法流程如圖2 所示。
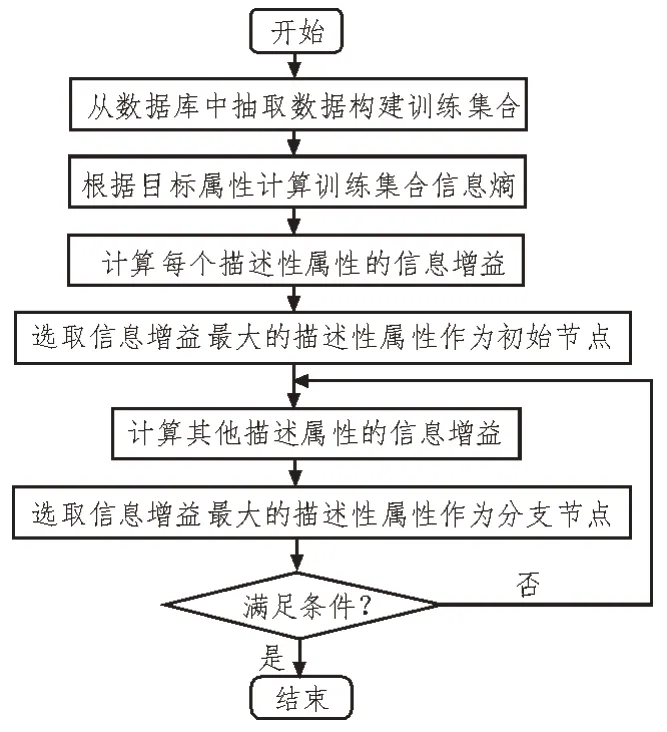
圖2 決策樹算法流程
2.2 基于決策樹算法的智庫信息處理
該文將伴隨式數據采集和決策樹算法應用于智庫信息處理,提出了基于決策樹算法的人才分類方法,如圖3 所示。首先,基于在伴隨式數據收集過程中獲取的學員信息數據構建訓練集。通過決策樹算法生成決策樹,對于待分類的學員將其數據信息輸入已生成的決策樹,再輸出人才分類結果。
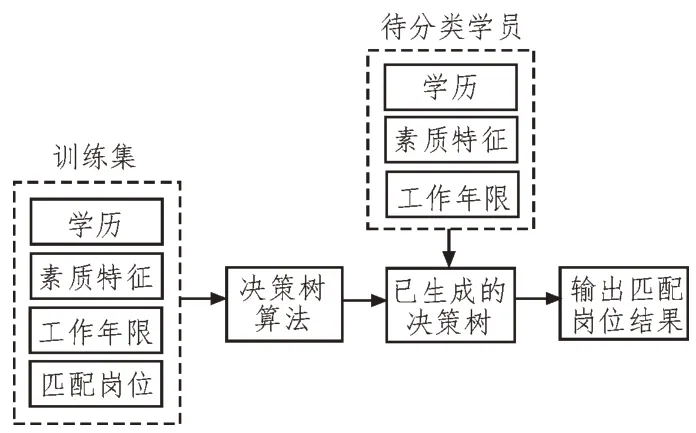
圖3 基于伴隨式數據采集和決策樹算法的智庫信息處理方法
1)分類屬性
如表1 所示,智庫人才分類即決策樹算法中的目標屬性為可能匹配的崗位,元素值包括:一般研究員、骨干研究員和項目管理員。智庫人才的特征信息即決策樹算法中的描述性屬性為學歷、工作年限和素質特征,其中學歷屬性元素值包括本科和碩士,工作年限包括小于3 和大于或等于3,素質特征包括顯性、綜合和隱性。
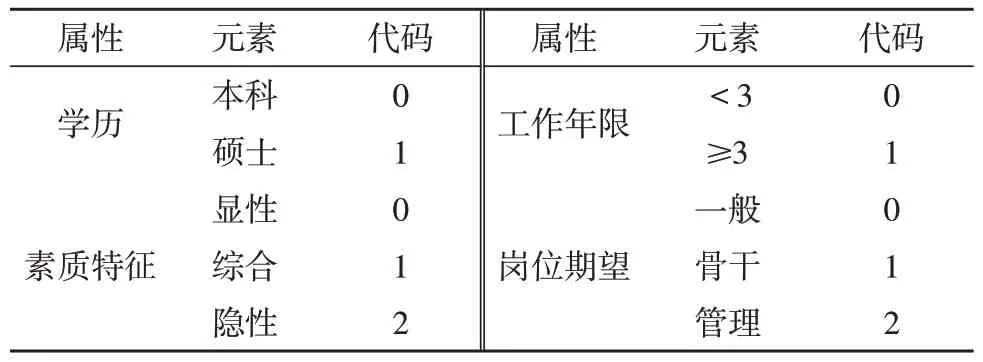
表1 基于智庫的人才屬性元素
2)構造訓練集
從智庫中隨機抽取學員信息構成訓練集,訓練集由目標屬性元素和描述性屬性元素構成。
3 算例分析
為了驗證該文所提基于伴隨式數據采集和決策樹算法的智庫信息處理方法的正確性和有效性,以寧夏電力智庫為例,隨機抽取10 名學員構成訓練集。訓練集中的學員信息數據如表2 所示。

表2 寧夏電力智庫構建的訓練集
3.1 決策樹的生成
目標屬性為匹配崗位,首先計算訓練集的信息熵:

1)以學歷為初始節點的信息增益:
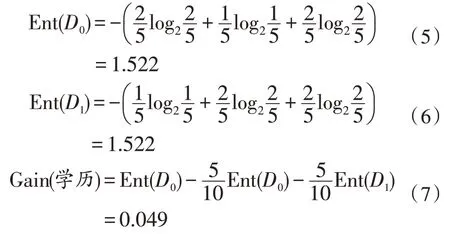
2)以工作年限為初始節點的信息增益:
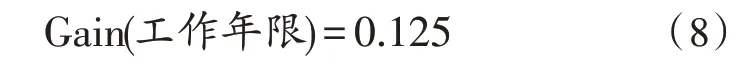
3)以素質特征為初始節點的信息增益為:
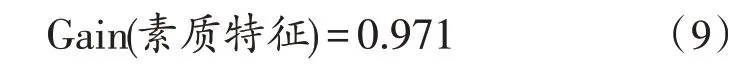
根據上述計算結果,選擇信息增益最大的描述性屬性素質特征作為決策樹的初始節點。
后續對于素質特征的每個分支,計算以其他描述性屬性為分支節點的信息增益,選擇信息增益值最大的節點作為分支節點。重復上述步驟直至生成決策樹,如圖4 所示。

圖4 生成的決策分析樹
3.2 決策樹的應用
從智庫中隨機抽取5 名學員的信息,根據上節中生成的決策樹,將學歷、工作年限和素質特征的信息數據作為輸入,輸出匹配崗位結果。
分析匹配崗位過程為:首先從決策樹的初始節點出發,根據素質特征的取值搜索至該分支;然后依據其他描述性屬性,從上至下依次搜索,直至末端節點即可得到該學員的匹配崗位結果。
利用200 名學員對已生成的決策樹進行測試,并驗證其準確性,部分學員的崗位匹配結果,如表3所示。

表3 崗位匹配結果
在測試結果數據中,最終有198 名學員匹配崗位與實際相同,匹配準確率為99%,表明所提算法能夠實現人才的智能分類。
4 結束語
該文開展了伴隨式數據采集和決策樹算法在智庫信息處理中的應用研究,構建基于伴隨式數據采集的智庫信息系統架構。利用智庫信息數據,通過決策樹算法實現人才素質特征與崗位的準確匹配。經算例分析表明,文中所提方法能夠簡單、高效地實現人才的評價與崗位配置,匹配準確率達99%,對提升人才的崗位匹配度和工作效率具有現實意義。但人才崗位匹配只是智庫信息數據應用的一個方面,因此有必要進一步挖掘其在人才業績考核、崗位晉升等方面的應用,這將在下一步研究中展開。
猜你喜歡
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
大眾創業(2009年10期)2009-10-08 04:52:00
數字社區&智能家居(2009年7期)2009-09-29 08:16:48
數字社區&智能家居(2009年11期)2009-06-25 04:30:34
數字社區&智能家居(2009年3期)2009-04-21 03:09:04
數字社區&智能家居(2009年2期)2009-03-27 04:33:44
數字社區&智能家居(2009年12期)2009-02-03 07:50:48
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
