決策樹算法在高校畢業(yè)生就業(yè)預(yù)測中的應(yīng)用
——以普洱學(xué)院為例*
2022-12-05 11:36:24普洱學(xué)院王嬌
數(shù)字技術(shù)與應(yīng)用 2022年11期
普洱學(xué)院 王嬌
近幾年,我國大學(xué)畢業(yè)生數(shù)量不斷增多,畢業(yè)生的就業(yè)問題是當(dāng)前高校工作的重點(diǎn)。運(yùn)用行之有效的方法分析預(yù)測就業(yè)趨勢具有實(shí)際意義。該文將數(shù)據(jù)挖掘技術(shù)用于應(yīng)用型高校畢業(yè)生就業(yè)情況的分析中,利用普洱學(xué)院畢業(yè)生就業(yè)數(shù)據(jù),引入C4.5 算法,計(jì)算信息增益率指標(biāo),構(gòu)建分類決策樹,建立畢業(yè)生就業(yè)預(yù)測模型。通過對模型的測試,構(gòu)建模型預(yù)測結(jié)果混淆矩陣,得到預(yù)測模型的準(zhǔn)確率達(dá)到83.33%。
就業(yè)是民生之本,對經(jīng)濟(jì)發(fā)展有著重要的作用[1]。近些年,高校招生規(guī)模不斷擴(kuò)大,隨之大學(xué)畢業(yè)生群體也在不斷地壯大。2022年高校畢業(yè)生總規(guī)模達(dá)到1076 萬人,創(chuàng)下歷史新高,且受到新冠疫情的影響,畢業(yè)生就業(yè)壓力隨之增大,且需要面臨更加復(fù)雜嚴(yán)峻的形式。為適應(yīng)社會(huì)發(fā)展,國家相關(guān)部門支持各大高校轉(zhuǎn)型為應(yīng)用型大學(xué),鼓勵(lì)培養(yǎng)應(yīng)用型人才。國家對應(yīng)用型高校畢業(yè)生就業(yè)工作十分地重視。
在信息收集和分析手段有限的年代,不僅無法全面了解畢業(yè)生的在校信息,而且也無法精準(zhǔn)、及時(shí)的掌握畢業(yè)生就業(yè)情況。隨著現(xiàn)代社會(huì)信息化程度越來越高,大數(shù)據(jù)技術(shù)應(yīng)用到了各行各業(yè)中。在許多方面,數(shù)據(jù)挖掘技術(shù)被廣泛地運(yùn)用在教育教學(xué)中,如:關(guān)聯(lián)分析技術(shù)、決策樹算法、隨機(jī)森林算法、神經(jīng)網(wǎng)絡(luò)等技術(shù)。利用數(shù)據(jù)挖掘技術(shù)發(fā)現(xiàn)數(shù)據(jù)中蘊(yùn)藏的有價(jià)值信息,指導(dǎo)實(shí)際工作。
教育及就業(yè)相關(guān)的數(shù)據(jù)庫中的數(shù)據(jù)量迅速增長,各省大學(xué)生就業(yè)信息管理系統(tǒng)逐漸建立完善,對大學(xué)生在校學(xué)習(xí)情況及畢業(yè)就業(yè)情況能夠較全面的掌握。但是,目前對于現(xiàn)有的信息管理系統(tǒng),管理者主要還是側(cè)重于查詢、更新、存檔等功能,并未充分利用管理系統(tǒng)中的數(shù)據(jù)進(jìn)行深入分析[2]。如何挖掘應(yīng)用型高校畢業(yè)生就業(yè)數(shù)據(jù)的價(jià)值,而數(shù)據(jù)挖掘技術(shù)恰恰就是最好的解決方法[3]。在數(shù)據(jù)挖掘中,分類是一項(xiàng)非常關(guān)鍵的分析手段,實(shí)現(xiàn)分類的方法有多種,如:異常檢測、決策樹、隨機(jī)森林等。
利用現(xiàn)有就業(yè)數(shù)據(jù)進(jìn)行合理預(yù)測,將為應(yīng)用型高校在制定學(xué)生培養(yǎng)計(jì)劃和能力提升方面提供理論依據(jù)。本文基于決策樹C4.5 算法,對普洱學(xué)院畢業(yè)生的就業(yè)數(shù)據(jù)進(jìn)行分類研究,通過設(shè)置英語成績、計(jì)算機(jī)成績、專業(yè)課成績、是否掛科、是否就業(yè)等變量,建立關(guān)于就業(yè)的C4.5 決策樹模型。
1 相關(guān)概念
1.1 決策樹
決策樹是數(shù)據(jù)挖掘分類算法中常見分類方法,通過有效的監(jiān)督學(xué)習(xí),輸出容易理解的結(jié)果,可用于分類及預(yù)測。1966年,Hunt 等人在其研發(fā)的概念學(xué)習(xí)系統(tǒng)中首次提出決策樹的概念[4]。自1986年Quinlan J R 提出了ID3 算法后,該算法在機(jī)器學(xué)習(xí)等多領(lǐng)域都得到了很大的發(fā)展,因此在數(shù)據(jù)挖掘和應(yīng)用中具有較好的前景。決策樹在各個(gè)領(lǐng)域中運(yùn)用非常廣泛,如醫(yī)學(xué)疾病分類、氣象分類、銀行用戶分類、電子郵件分類等。利用訓(xùn)練集數(shù)據(jù)集構(gòu)建分類決策樹后,可以利用測試集數(shù)據(jù)集對模型的分類進(jìn)度進(jìn)行檢驗(yàn),以此確定所構(gòu)建的模型是否適用于分析該問題。決策樹是一種通過從上到下的遞歸形式,以樹狀形式呈現(xiàn)分類規(guī)則和分類結(jié)果的算法,在樹的每一個(gè)節(jié)點(diǎn)上通過對比并選擇屬性值,以此判斷該節(jié)點(diǎn)向下的分支,在樹的葉節(jié)點(diǎn)處得到分類結(jié)果[5]。決策樹分類結(jié)果易于使用者理解,算法實(shí)現(xiàn)容易,它不需要使用者具備更多的數(shù)據(jù)挖掘知識,便可通過決策樹誠信的樹形結(jié)果進(jìn)行分析、理解。實(shí)現(xiàn)決策樹常見的算法包括:ID3、C4.5、CART 和CLS 等[6]。
1.2 ID3 算法
ID3 算法是由J.Ross Quinlan 提出。該算法把信息論中的一些概念引入其中,以信息熵和信息增益作為基礎(chǔ),以此作為數(shù)據(jù)屬性劃分的標(biāo)準(zhǔn),最終實(shí)現(xiàn)對數(shù)據(jù)集的分類。
1.2.1 信息熵
Shannon 在1948年把熱力學(xué)中的熵引入信息論,提出了信息熵的概念,又被稱為香農(nóng)熵。他用數(shù)學(xué)公式的形式闡明了概率與信息冗余的關(guān)系。利用熵可以把隨機(jī)變量的不確定程度描述出來。
設(shè)X為離散型隨機(jī)變量,概率分布為:
p(xi)=P(X=xi),i=1,2,3,…,n
Shannon 把隨機(jī)變量X的熵H定義為:

隨機(jī)變量X的熵依賴于X的分布,約定0 ·log0 = 0。
1.2.2 條件熵
條件熵H(Y|X)是在X已知的條件下Y的不確定性,定義為:
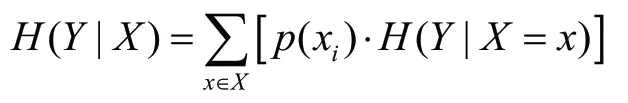
1.2.3 信息增益
信息增益是在X已知的條件下,Y的熵值較沒有任何條件確定時(shí)減少的程度[7]。定義為:
Gain(Y,X)=H(Y)-H(Y|X)
信息熵與條件熵相減就是信息增益。一般,信息增益越大,表示所用劃分屬性獲得的“純度增加”越大。ID3 算法以此選擇決策樹的劃分屬性,一般用于處理離散型數(shù)據(jù)。從信息增益計(jì)算公式中可以看出,該算法具有傾向于取值較多的特征[8]。
1.3 C4.5 算法
J.Ross Quinlan 對ID3 算法進(jìn)行改進(jìn)提出了C4.5 算法,信息增益率作為該算法劃分屬性的判斷指標(biāo)[9]。ID3算法的所有優(yōu)點(diǎn)都能在C4.5 算法中體現(xiàn)出來。同時(shí),C4.5 算法可以處理離散變和連續(xù)變量,消除了ID3 算法的多值特征傾向[10]。與ID3 算法相比,C4.5 算法在效率和準(zhǔn)確程度上也有很大的提高[11]。
信息增益率在信息增益的基礎(chǔ)上兼顧了為獲取信息增益所付出的“代價(jià)”,消除了特征取值較多時(shí)帶來的影響,等于信息增益除以特征的固有值,定義為:

確定各屬性的信息增益率,選取信息增益率最高的屬性作為根節(jié)點(diǎn),以此標(biāo)準(zhǔn)進(jìn)行迭代,最終構(gòu)建出分類決策樹。
本文利用C4.5 算法對畢業(yè)生的就業(yè)相關(guān)數(shù)據(jù)進(jìn)行分類分析。主要探討該算法在應(yīng)用型高校畢業(yè)生就業(yè)預(yù)測中的可行性。通過建立就業(yè)預(yù)測模型,希望為高校開展就業(yè)指導(dǎo)工作提供幫助。
2 基于決策樹算法在應(yīng)用型高校畢業(yè)生就業(yè)預(yù)測中的應(yīng)用
2.1 數(shù)據(jù)來源及梳理
本文選取畢業(yè)生中英語成績、計(jì)算機(jī)成績、專業(yè)課成績、是否掛科、是否就業(yè)5 個(gè)變量,隨機(jī)抽取普洱學(xué)院數(shù)學(xué)與統(tǒng)計(jì)學(xué)院12 名畢業(yè)生的相關(guān)數(shù)據(jù)建立決策樹模型。為方便建模,對采集到的數(shù)據(jù)進(jìn)行預(yù)處理。從教務(wù)系統(tǒng)中導(dǎo)出學(xué)生各科在校成績,對各類型科目取平均成績,如:英語成績?yōu)榇髮W(xué)外語1 和大學(xué)外語2 的平均值。且認(rèn)定85 分以上為優(yōu)秀,70 ~85 為良,70 分以下為差,數(shù)據(jù)如表1所示。

表1 畢業(yè)生情況表Tab.1 Graduate fact sheet
2.2 模型構(gòu)建
2.2.1 計(jì)算類別的信息熵
在樣本數(shù)據(jù)中,9 人就業(yè),3 人未就業(yè),故P就業(yè)=9/12,P未就業(yè)=3/12。由信息熵計(jì)算公式可得:

2.2.2 分別計(jì)算每一個(gè)屬性劃分方式的條件熵
以英語成績?yōu)槔铍S機(jī)變量X 為英語成績,則X取值為{優(yōu)、良},其概率分別為根據(jù)條件熵計(jì)算公式可得:

同理可計(jì)算出屬性“計(jì)算機(jī)成績”“專業(yè)課成績”“是否掛科”的條件熵分別為:0.6701、0.7704、0.2704。
2.2.3 計(jì)算信息增益
根據(jù)信息增益計(jì)算公式可得:
Gain(Y,X) =0.8113-0.4686=0.3427
同理可計(jì)算出屬性“計(jì)算機(jī)成績”“專業(yè)課成績”“是否掛科”的信息增益分別為:0.1412、0.0409、0.5409。
2.2.4 計(jì)算屬信息增益率
根據(jù)信息增益率計(jì)算公式可得:

同理可計(jì)算出屬性“計(jì)算機(jī)成績”“專業(yè)課成績”“是否掛科”的信息增益率分別為:0.1020、0.0344、0.5890。
2.2.5 建立決策樹模型
由計(jì)算結(jié)果可知,屬性“英語成績”的信息增益率最高,故選擇該屬性為分裂屬性作為根節(jié)點(diǎn)。分裂后,“英語成績”為優(yōu)的條件下,類別是“純”的,即畢業(yè)生就業(yè)情況類別均為就業(yè),故把此定義為葉節(jié)點(diǎn)。從“英語成績”為良向下繼續(xù)進(jìn)行分裂,依次按照2.2.1 ~2.2.4 的方法進(jìn)行計(jì)算,構(gòu)建出C4.5 算法的決策樹,如圖1所示。
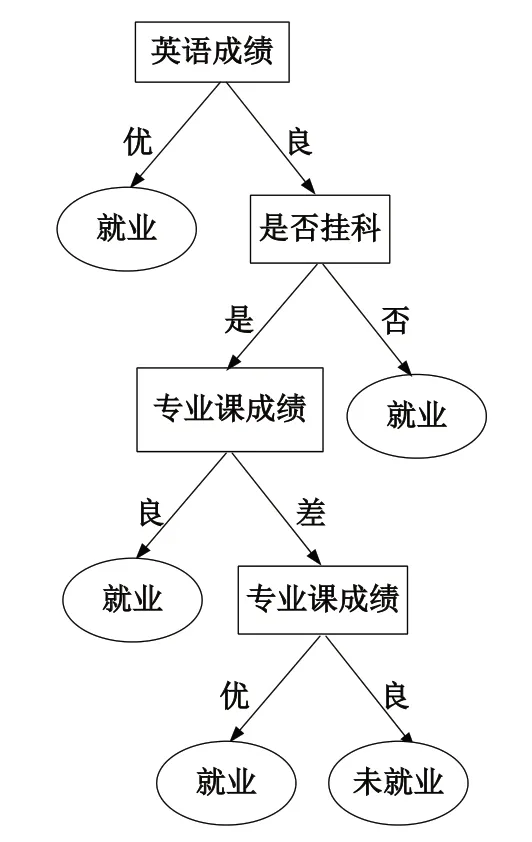
圖1 畢業(yè)生就業(yè)預(yù)測模型圖Fig.1 Graduate employment prediction model diagram
2.2.6 模型預(yù)測
為驗(yàn)證決策樹模型的精確度,根據(jù)圖1的決策樹,對樣本數(shù)據(jù)精選了驗(yàn)證,利用驗(yàn)證結(jié)果得到預(yù)測混淆矩陣,如表2所示。結(jié)果表明,該決策樹模型精確度達(dá)到83.33%,模型能夠得到較好的預(yù)測結(jié)果。

表2 預(yù)測結(jié)果表Tab.2 Forecast result table
3 結(jié)語
本文采用決策樹C4.5 算法,對普洱學(xué)院畢業(yè)生的就業(yè)數(shù)據(jù)進(jìn)行了分析,得到了預(yù)測精度較高的決策樹分類模型。預(yù)測模型能夠處理定性數(shù)據(jù)和定量數(shù)據(jù),能夠很好地適應(yīng)就業(yè)相關(guān)數(shù)據(jù)的分析,模型構(gòu)建簡單、快速,結(jié)果直觀,便于理解。能夠?yàn)閼?yīng)用型高校畢業(yè)生就業(yè)情況的預(yù)測提供有效的預(yù)測,為高校幫扶畢業(yè)生就業(yè)提供一定的理論基礎(chǔ)。本文不足之處在于,訓(xùn)練樣本較少,可能存在一定的偏差,在進(jìn)一步地研究中將選取更大的訓(xùn)練樣本,考慮更多的相關(guān)屬性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
中華手工(2017年2期)2017-06-06 23:00:31
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
中外會(huì)展(2014年4期)2014-11-27 07:46:46
