基于高維時序特征補充的直播行業用戶流失預測模型
2022-12-09 09:12:58鄭桂钖
科技與創新 2022年23期
鄭桂钖,徐 寬
(1.華南理工大學工商管理學院,廣東 廣州 510000;2.中國科學技術大學大數據學院,安徽 合肥 230000)
1 研究背景
隨著科技經濟不斷進步,市場全球化的進程繼續深入,消費者的選擇也越來越多,面對愈發激烈的市場競爭,各行各業愈發重視用戶這一可謂“根基”的資源,且相較于保留老用戶,新用戶的獲取成本通常要成倍地高于前者[1]。因而用戶流失預警對企業而言重要性不言而喻。提高用戶流失的預測精度,有助于構建用戶流失預警體系,讓實現對不同用戶的挽留、轉化、精準營銷成為可能,從而提高企業的收益。
國內外學者在用戶流失(Customer Churn)問題上主要集中在電信、金融行業。隨著移動互聯網的興起,近些年來也有學者關注在線電商、游戲、社交等行業。早期用戶流失研究致力于通過實證研究尋找影響用戶流失的因素上,目前主要的研究工作都是圍繞用戶行為數據進行建模、分析,以總結用戶流失行為的規律,或者對用戶流失行為進行預測,即用戶流失預測。在這個問題上,各領域各行業的研究大概可以分為2個方向:①將預測用戶的流失時間,基于用戶生命周期對用戶剩余的生存期進行一個預測,這種方向大多結合生存分析進行研究[2];②將用戶流失視為一個流失(Churn)與非流失(Non-Churn)這樣一種二分類的問題,這也是絕大多數研究的方向。
目前的用戶流失預測模型中,除了行業的選擇外,主要差異集中在流失的定義、特征的選擇及具體模型的選擇。
在電信、金融、保險等偏合約性質的行業用戶的定義較為簡潔,在這些行業中用戶離開一個服務提供商到另一個服務提供商的行為即被稱為用戶流失[3];但在電商、游戲、社交等互聯網相關的非合約性質的行業中用戶的流失沒有一個明確的公認標準,最常見的是以最長連續無有效活躍天數(假設為T,下稱閾值)作為判斷標準,當用戶連續不登陸天數大于T時則認為用戶流失[4],通常而言閾值T與產品的用戶黏性呈負相關關系,同時這種樸素的方法也受企業管理層對于用戶流失敏感性的影響。
特征選擇普遍是基于相關領域知識的,如前面提到有部分學者著重研究影響用戶流失的因素,通常選擇可描述流失相關因素及用戶行為指標來構建特征;此外,也有一些學者結合其他社科領域的知識,如考慮同個社交網絡中用戶間的相互影響來對特征進行補充[5]。時間序列中往往包含了許多動態信息,但過去的研究往往只是對時間序列進行等距測量或聚類,并簡單地視為離散特征輸入[6],而鮮有考慮到深入挖掘時間序列的信息。
針對于將用戶流失預測作為二分類問題的研究在建模算法上選擇多種多樣,從算法原理上大致可以分為以決策樹、貝葉斯、邏輯回歸為代表的基于傳統統計學算法,以支持向量機、隱馬爾可夫為代表的基于統計學習理論算法,基于啟發式學習的預測算法,基于神經網絡的深度學習算法及目前最熱門的基于集成學習的算法。不同的方法各有特點,在不同的研究中表現也有所不同,但通常來說神經網絡和集成學習算法表現會更優[7]。
綜上所述,目前用戶流失預測研究大部分集中在電信、金融、保險等合約關系明確的領域,而對互聯網行業的研究相對較少,尤其是直播行業,若能較好地針對體量巨大的互聯網行業用戶進行準確的流失預測,將帶來十分可觀的經濟效益。針對以往研究中粗糙的流失定義及缺乏對時間序列信息的挖掘問題,本文將從數據表現出發對用戶流失進行更細粒度的指標量化和定義,同時對時間序列這一重要信息進行深入挖掘,對互聯網直播行業用戶進行流失預測,最后探究不同算法模型下與基于領域知識的模型在流失預測效果的差異。
2 理論與方法
2.1 時間序列特征
通過對時間序列進行特征提取,再將提取后的特征用以模型訓練是解決機器學習中時序相關問題的常見做法。如何從時間序列中提取有效特征也是一個熱門的研究領域,早期學者們通常會提取與序列分布相關的基本特征,如最大值、最小值、偏度、峰度等[8]。除此之外,在不同應用領域下也提出了針對性的帶領域知識的特征抽取算法,如基于小波特征來監測齒輪震動以診斷機器故障[9],通過提取擬合指數函數的參數來估計軸承的剩余壽命[10]等。在后期,FULCHER等[11]提出了(Highly Comparative Time-series Analysis,HCTSA)框架并開發了HCTSA工具箱,其原理是利用龐大的科學工作語料庫,集成天體物理學、金融、數學、工業應用等各個領域的特征生成算法,構建出時間序列的數千個特征,包括數據值的分布信息(如高斯性,離群值的性質)、自相關結構(如功率譜度量)、平穩性(性質如何隨時間變化,如一階差分)、熵和時間可預測性的信息理論度量、線性和非線性模型對數據的擬合狀況等,并使用線性分類器進行特征選擇,以求全面地量化和理解時間序列蘊含的有效信息。文獻[12]也證明了在許多標準數據集上,基于HCTSA時間序列特征建模的方法在分類任務上表現優于傳統的基于時間序列相似度方法。
受FULCHER和JONES等的啟發,2016年CHRIST等[13]在HCTSA的基礎上,提出了基于可擴展假設檢驗的時間序列特征提取(Feature Extraction on basisof Scalable Hypothesis tests,FRESH)算法框架。FRESH將特征抽取算法精簡至63種,在不同參數下計算后共計得到794個特征;另外,FRESH使用基于假設檢驗的方法進行特征選擇。2018年CHRIST等[14]也基于Python完成了對應軟件包TSFRESH的實現,在特征提取與過濾算法上實現高度并行,同時也兼容了常見的機器學習框架,如scikit-learn,numpy等,便于直接應用到實際生產研究中。同時,在UCR標準時間序列分類數據集上的評估結果表明,FRESH方法在預測精度和計算開銷上相較于經典的基于時間序列相似度方法及特征篩選算法均有一定優勢[13]。
2.2 算法原理
本文涉及的機器學習算法的原理如表1所示。
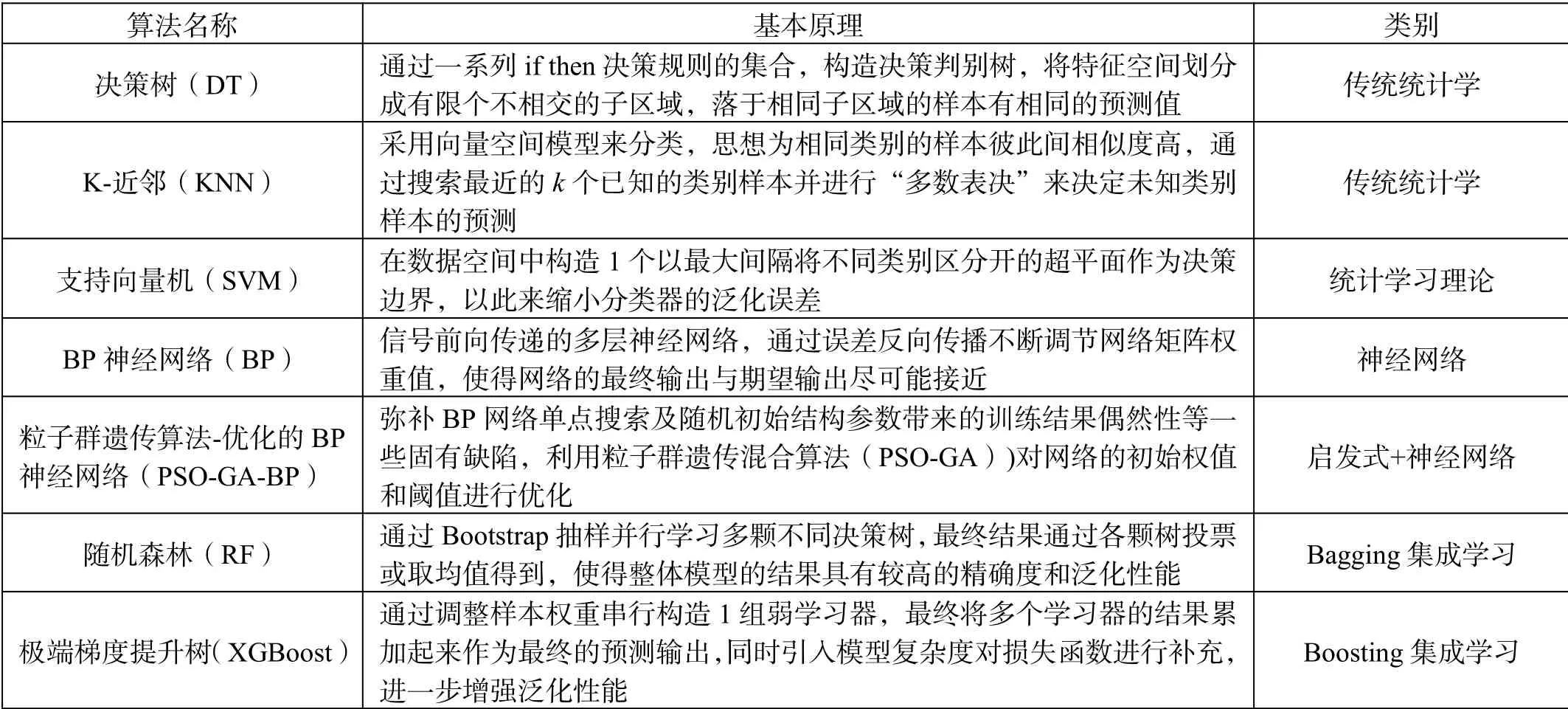
表1 算法概要
3 實例分析
3.1 數據來源
本文使用的數據來自國內某移動互聯網研發公司的一款海外直播APP,以2020-10-01的某大區直播活躍用戶于2020-09-18—2020-10-01共14 d內的各類行為及個人基本信息數據為基礎,對這部分用戶進行流失預測。其中,活躍用戶定義位用戶當天在直播房間內總時長不低于3 min,太少的時長有可能是因為用戶僅僅為了簽到或誤操作,并不包含有效行為信息。出于信息完整性及實際考慮,數據中剔除了注冊日期少于14 d的用戶,一方面這部分用戶在過去周期內的數據不完整;另一方面注冊少于14 d的用戶大體上算是新用戶,他們的行為規律相比于已經長注冊時間用戶而言不夠穩定,同時存在大量的用戶注冊后短時間內便流失,這些用戶往往非APP的目標用戶,他們的流失也并非企業關心的。
最終數據集中共包括219 910個用戶,其中有45 099名用戶被標記為流失用戶,占比20.51%。
3.2 問題描述
用戶流失預測的本質就是利用用戶過去一段時間的行為特征等信息,從而來預測用戶在未來一段時間是否會流失。因此從大層面上看,首先需要對用戶流失做出合適的定義,接著選擇相應的特征信息用以最后的建模預測。
而從時間維度上看,整個流失預警過程可以分為以下3個窗口:首先是行為觀察窗口,在該窗口內對用戶的特征進行收集,并在窗口末尾用以模型訓練;從而來預測用戶在未來的一段時間內是否流失,也即進入了流失預測窗口;最后是流失判別窗口,該窗口可以觀察在預測窗口中定義為流失的用戶是否真正流失,從而來輔助流失定義。用戶流失預警過程如圖1所示。
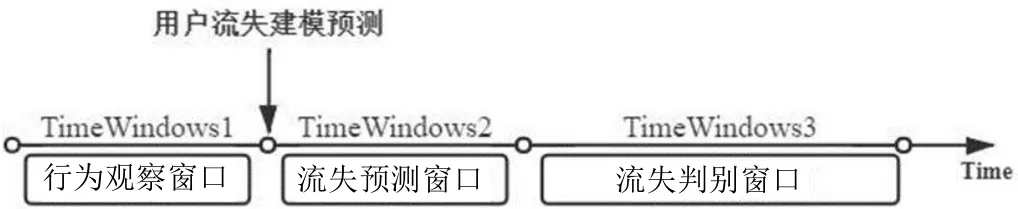
圖1 用戶流失預警過程
3.3 特征構建
在模型特征信息選擇上分別構建2組特征,一組主要由用戶的行為特征及個人特征屬性組成,也是絕大多數研究所使用的,稱為常規特征;另一組為對用戶TW1的時長時間序列進行提取后的特征,稱為高維時間序列特征。
3.3.1 常規特征
常規特征主要由以下4部分信息組成:①用戶活躍相關信息,包括活躍/上麥的天數及總時長、平均時長,進房次數等;②用戶營收相關信息,包括送禮/收禮人數、次數、金額,最大充值金額,背包禮物余額等;③用戶社交相關信息,包括發送IM消息數量、關注主播數、好友數、被關注數等;④用戶個人畫像信息,包括國家、年齡、性別、注冊至今天數、是否有過充值/消費行為等。
從直觀上來說,用戶在TW1內的行為是對其行為特征最好的刻畫,但考慮到不同用戶對于APP的黏性及所處生命周期階段不同,因此將用戶的歷史行為信息也納入特征中,最終常規特征共包含41維特征。
3.3.2 高維時序特征
通過TSFRESH框架提取了用戶在TW1內的每日活躍時長序列的794個特征,主要包括以下幾個部分:①時間序列值分布的基本統計信息,包括分布、散度、高斯性值、離群值屬性等;②線性相關性,包括自相關性、功率譜特征等;③平穩性,包括StatAv、滑動窗口測量、預測誤差等;④信息論與復雜性度量,包括自互信息、近似熵、Lempel-Ziv復雜度等;⑤線性和非線性模型擬合,包括自回歸移動平均(ARMA)、高斯過程和廣義自回歸條件異方差(GARCH)模型的擬合優度、估計和參數值等。
3.4 數據預處理及特征工程
數據質量及特征工程的好壞會顯著影響建模結果的準確和有效性,也是研究的可靠性保障,其主要包含以下工作。
3.4.1 異常值、缺失值處理
將超過正常使用所能達到的數據定義為異常數據,如異常心跳上報的時長數據及觸發相應風控策略的營收數據等。經過統計,存在異常數據的用戶占比低于0.01%,故將這部分用戶直接剔除。而在缺失值上,最高缺失特征缺失值占比為0.29%,分別使用眾數、均值對離散及連續變量進行缺失值填充。
3.4.2 特征篩選
特征篩選目標是盡可能在不引起重要信息丟失的前提下去除掉冗余甚至無關特征,保留與預測目標相關的特征。使用費舍爾精確檢驗(Fisher'sexact test)[15]及曼-惠特尼U驗(Mann-Whitney U test)對二分類特征及數值特征進行假設檢驗篩選;針對高維時序特征,使用Benjamini-Yekutieli方法[16]控制多次假設檢驗的錯誤發現率FDR(False Discovery Rate)。顯著性水平α均取0.05。經過篩選后,常規特征保留39維,高維時序特征保留326維。
3.4.3 數據標準化
實驗中所使用的KNN是基于歐氏距離的算法,在計算過程中必須消除特征量綱的影響;同時,對于使用梯度下降來優化的算法,如SVM、BP、LSTM,歸一化有助于加快收斂,因而在這些模型訓練前,將對連續特征進行z-score標準化處理,同時在離散特征上采用獨熱編碼。
3.5 實驗設計
上文中提到,過去研究中具體用于流失預測建模的算法繁多,從大方向上主要可以分為傳統統計學、統計學習理論、啟發式、神經網絡及集成學習5類。面對各式各樣的算法選擇,實驗的第一部分將基于常規特征,選擇各類算法中的主要代表模型來進行建模,探究不同模型的表現,同時也將得到的最優模型作為后續實驗模型參照的baseline基準模型;同時,針對過去研究中對時序特征缺乏考慮的問題,實驗的第二部分先使用高維時序特征進行建模,再將常規特征與高維時序特征進行融合建模,觀察高維時序特征是否有助于提升模型表現。特征建模簡要流程如圖2所示。
模型構建的具體過程如圖3所示,首先用特征工程的方法對初始數據集進行預處理,然后將清洗好的數據集按7∶3的比例隨機拆分為訓練集與測試集。訓練集用以模型訓練,以準確率為目標使用對半網格搜索(Halving Grid Search)[17]或貝葉斯優化(Bayesian Optimization)[18]選擇最優參數,并進行5折交叉驗證。確定最優參數后使用完整訓練集進行模型訓練,而后在測試集上進行預測得到預測結果,并使用準確率(Accuracy)、召回率(Recall)、F1值(F1-score)及AUC值全面地評估模型效果。

圖2 特征建模簡要流程

圖3 流失預測模型構建過程
3.6 實驗結果
3.6.1 基于常規特征建模
從算法使用頻率、趨勢及數據特性出發,在這部分實驗中,以決策樹DT、最近鄰算法KNN作為傳統統計學算法的代表,以支持向量機SVM作為統計學習理論算法代表,以粒子群遺傳混合算法優化的BP神經網絡作為啟發式算法與神經網絡的代表,并選擇隨機森林RF和XGBoost作為Bagging和Boosting等集成算法的代表。實驗預測結果如表2所示。
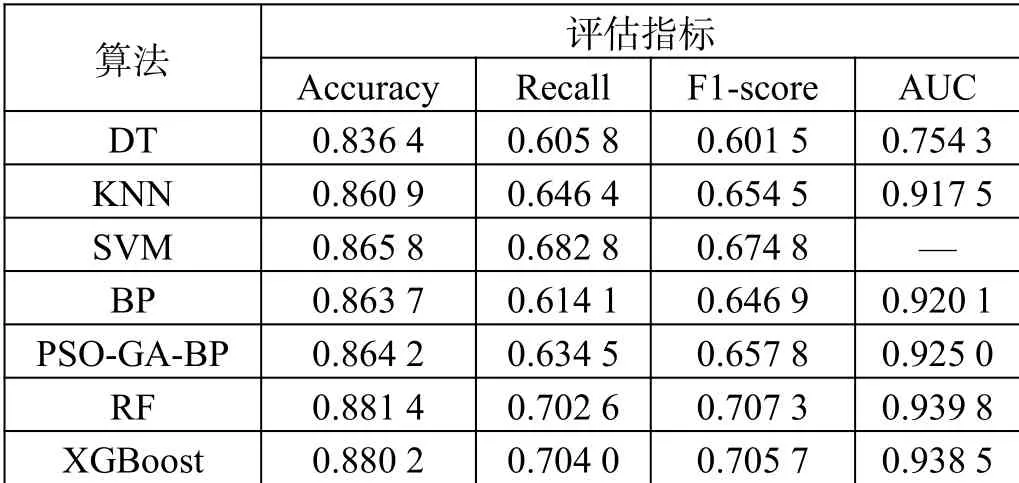
表2 基于常規特征建模的模型預測結果
從表2中可以看到,集成學習算法總體表現最優,基于Bagging集成學習的隨機森林算法在準確率、F1值及AUC值取得最高得分,而基于Boosting集成學習的XGBoost在召回率上有最佳得分。此外,基于統計學習方法的SVM表現最優,經過PSO-GA改進后的神經網絡次之,改進后的神經網絡也相較改進前在正例樣本表現上更優,有更高的覆蓋率和F1值,而基于傳統統計學習的決策樹及K近鄰算法表現較差。因此,選擇基于常規特征進行建模的隨機森林模型作為后續實驗參照的基準模型。同時由于集成學習算法的出色表現,后續建模也更傾向使用集成學習算法。
3.6.2 基于時序及融合特征建模
這部分實驗首先使用HCTSA方法提取出的時序特征進行建模,模型算法選擇使用在前面表現較好的隨機森林及XGBoost;然后將時序特征與常規特征進行融合,使用融合后的特征進一步對模型進行訓練,觀察模型在3組特征下的表現情況,如表3、表4所示。
為了讓實驗結果更加直觀可視化,將實驗結果以圖4的方式呈現出來。從圖4中可以看出,無論是隨機森林還是XGBoost,基于常規特征建模的模型表現比基于高維時序特征建模的表現更好,這也意味著比起只考慮時間相關特征的高維時序特征,包含了如營收、社交及用戶畫像等多樣化且更全面的常規特征在預測中有著不可忽視的作用;另一方面,基于融合特征建模的模型在各個指標的表現均優于在常規特征基礎上建模的模型,尤其在召回率及F1值上有顯著提高。相較于常規特征建模,2個模型在召回率上分別提升了5.98%及6.83%,在F1值上分別提升了2.39%及3.42%,這說明模型不僅整體預測精確度更佳,同時也提升了對于正例樣本的捕捉能力,即對流失用戶的判別能力,這也恰恰是流失預警模型最為需要和關注的。這也體現出高維時序特征的優勢,其全面的信息彌補了常規特征中對時序缺乏深入挖掘的不足;同時,常規特征中考慮特征更加多樣全面也補充了特征來源,將2種特征融合互為補充后模型得以進一步優化提升。
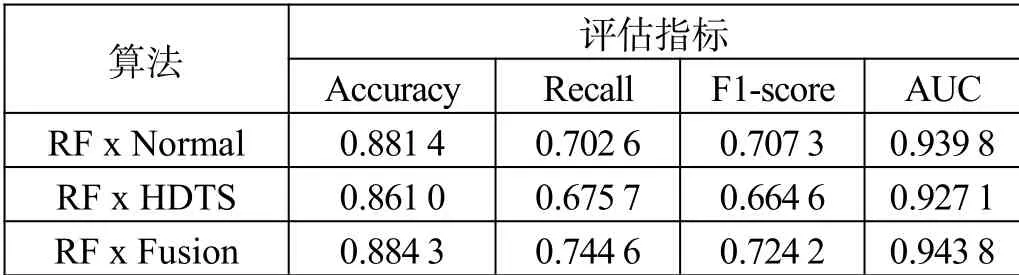
表3 基于時序及融合特征的隨機森林結果

表4 基于時序及融合特征的XGBoost結果
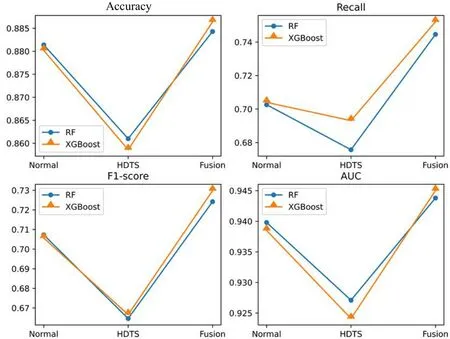
圖4 模型的準確率、召回率、F1值和AUC對比圖
4 總結
本文使用某直播APP真實的業務數據對用戶進行流失預測。首先基于過去研究中常涉及的常規特征,選擇常見的算法進行預測對比,包括基于傳統統計學的KNN、統計學習方法SVM、啟發式優化神經網絡PSO-GA-BP、集成學習算法RF、XGBoost等,得出集成學習算法總體表現最優的結論。然后從用戶過去的活躍時長序列中提取高維時序特征,與常規特征進行融合,用于集成學習算法訓練。數據結果表明,基于融合特征方法能夠使模型得到進一步的優化提升。
本文在時序特征的提取上只考慮了用戶時長這一時間序列,未來可進一步考慮對更多序列進行特征提取以獲取更多信息,如用戶操作序列等。同時,預測流失用戶的最終目的是提前判別用戶狀態,進而采取一定手段留住用戶,探索如何更有針對性地將預測結果與客戶挽留措施相結合也是非常有價值的方向,尤其在用戶價值評定及具體挽留成本方面,目前研究仍較匱乏,對用戶進行全面合理的價值評定及采用適當的成本進行高效促活,將有助于提升企業的切實收益。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
