基于動態時序移位的視頻特征學習方法
2022-12-11 12:23:34談偉峰程春玲
計算機技術與發展 2022年12期
談偉峰,程春玲,毛 毅
(南京郵電大學 計算機學院、軟件學院、網絡空間安全學院,江蘇 南京 210023)
0 引 言
視頻動作識別是計算機視覺領域中一個重要的任務,旨在從視頻片段識別對應的動作類別。由于視頻中包含豐富且復雜的信息,其中圖像的空間信息和時間維度上的時序信息是所有視頻都具備的基本信息,因此對視頻動作的特征表達的學習也變得尤為復雜。隨著深度學習在圖像領域的成功應用,卷積神經網絡(Convolutional Neural Network,CNN)[1]能夠很好地滿足對圖像的空間特征的學習,獲得深層次的圖像特征表達。但是,對于視頻動作識別任務而言,僅依賴CNN提取到的空間特征無法達到較好的識別效果。因此,如何利用時序信息來增強動作特征表達成為一個重要研究方法,即如何有效學習時序特征。
不同于CNN只處理單張圖像,時序信息的學習需要考慮多個連續視頻幀,而無論是利用CNN網絡結構學習連續兩幀之間的光流場信息,還是利用LSTM[2]學習連續視頻幀的上下文依賴關系,在已經使用了CNN學習空間特征基礎上都會極大地增加網絡模型的復雜度,帶來額外的開支。TSM(Temporal Shift Module)[3]在不增加網絡結構的前提下,對從基礎網絡(ResNet-50[4])提取出的特征沿時間維度進行移位操作,實現了時序信息的建模。但TSM是按固定的通道比例來選擇需要進行時序移位的通道,所獲取的時序信息也只是針對部分淺層通道而言的,且未考慮到時間維度上的特征移位對整個特征結構的影響。
因此,考慮到不同層次通道上的時序信息對識別結果的貢獻存在差異,并且時序移位改變了全局時空特征結構,提出基于全連接神經網絡的動態時序移位和全局時空特征學習方法。在對不同時間維度上特征進行移位時,將產生信息共享,而信息間的差異很大程度上決定了交互后的有效性,因此可以利用不同時間維度上特征之間的相關性,作為時序移位通道的選擇依據。在相關性學習方法的選擇上,該文采用全連接神經網絡,不僅是因為其能很好學習多個特征間的長期依賴關系,而且可以用于學習全局時空特征。固定全連接網絡學習時序特征間相關性的學習參數,用于后期的全局時空特征學習,大大減少了模型的復雜度和參數量。
1 相關工作
1.1 基于深度學習的時序特征學習方法
現有的基于深度學習的視頻動作識別的網絡結構主要分為Two-Stream、C3D(Convolution 3 Dimension)、CNN+RNN三大類。
Simonyan等[5]首次提出了雙流網絡(Two-Stream Network),采用兩個分支的網絡架構分別捕捉視頻的空間和時間特征,然后對兩種特征的分類結果進行融合。Feihtenhofer等[6]沿襲了雙流網絡結構,提出了5種融合時間特征和空間特征的策略,將融合的特征用于分類,更有效地利用了時空信息。Wang等[7]將不同的CNN基礎架構(GoogLeNet[8],VGG-16[9])與雙流網絡相結合,并對比了不同CNN架構下的雙流網絡的準確率。Xiong等[10]針對當前網絡對長期動作(long-range)時間結構理解不足且訓練樣本較小等問題,提出了稀疏時間采樣策略和基于視頻監督的策略,創建了時域分割網絡(Temporal Segment Network,TSN)。在海洋鉆井的實際應用場景下,文獻[11]利用雙分支網絡融合關鍵點和光流軌跡,實現了人體動作的識別。文獻[12]為進一步增強特征表達能力,引入深度信息,分別提取了RGB視頻特征表示和深度視頻的直方圖特征表示,并對分類結果進行融合。黃菲菲等人[13]則利用HIS顏色空間模型,分別提取H、S、I三個通道下的HOG特征,并對分類結果進行等比例融合。
除了單獨使用一個網絡結構學習時序信息,還可以將時間視為第三個維度,使用三維卷積(3D Conv)提取視頻的時空特征。Tran等[14]提出了C3D模型,對所有網絡層均采用3×3×3卷積核尺寸,在C3D基礎上又提出了Res3D網絡[15],即在深度殘差學習網絡(ResNet8-style)中執行3D卷積,其精度高于C3D模型。Qiu等[16]對Inception-v3[17]進行分析后發現,1×3和3×1的2D卷積可以替代3×3的卷積核,并且計算量更小,于是從卷積核的尺寸設計的角度出發提出了偽3D網絡。
隨著RNN在NLP中的成功應用,體現出RNN在處理序列信息方面具有極好的能力,因此有人提出使用RNN學習視頻的時序信息。LRCN[18]結合了CNN和LSTM,將由CNN獲取到的空間特征視為有序的序列,作為LSTM的輸入進一步學習時序特征。
無論是使用單獨的網絡學習時序特征,還是使用三維卷積,都大大增加了網絡的結構、訓練參數及計算量,很大程度上犧牲了識別的速度,且對設備的計算能力有著更高的要求。因此,針對時序信息的學習成本較大的問題,該文在時序移位(Temporal Shift)的基礎上提出了動態時序移位方法(Dynamic Temporal Shift,DTS),從多個時間維度上特征間的相關性出發,動態選擇不同層次通道進行時序移位,既不需要添加額外的網絡結構,也學習到了更有效的時序特征。
1.2 基于時序移位的時序特征學習方法
針對現有主流的視頻動作識別方法中存在的模型復雜度較高、網絡參數較多的問題,TSM(Temporal Shift Module)將從基礎網絡中提取到多個連續幀的空間特征,沿時間維度對部分通道進行移位操作,從而促進了時間維度上信息的交互,建立了相鄰幀之間的聯系。TSM將常規的卷積操作分解為位移和乘積累加兩個步驟,假設1D卷積為W=(w1,w2,w3),輸入為X,輸出Y=conv(W,X)=w1Xi-1+w2Xi+w3Xi+1。首先,對輸入X進行移位:
(1)
然后,乘以卷積核參數并累加:
Y=w1X(-1)+w2X0+w3X(+1)
(2)
第一步的移位操作并不會產生任何的計算量,通過創建與輸入尺寸相同的零變量,并使用Python中的切片符號(Slice Notation)對輸入進行移位,最后將移位后的特征值賦值給零變量即可實現移位操作。第二步的卷積操作與移位前的卷積操作一致,并沒有引入額外的計算成本。
GSN(Gate-Shift Networks)[19]基于分離空間和時間的思想,利用門控單元來決定是否進行時序移位操作。GSN首先在輸入層使用空間卷積(2D Conv),然后將學習到的空間特征作為門控單元的輸入;門控單元由單個3D時空卷積核和tanh激活函數構成,利用3D卷積學習短期時空信息,tanh激活函數則為短期時空信息提供了一個門控平面,決定了是否對門控單元的輸入進行時序移位。
無論是TSM還是GSN,進行時序移位操作都必須考慮以下兩個問題:
(1)移位的通道數。如果移動的通道太多,雖然不會增加任何計算量,但大量數據的移動和賦值會增加內存的占用以及模型推斷的時延;如果移動的通道太少,時序信息間的交互太少,不足以學習到有效的時間特征。
(2)移位的通道。將部分通道沿時間維度進行移位,在一定程度上破壞了時空特征的整體結構,尤其是當某個通道上多個時間維度的特征間相關性很低時,對該通道進行移動不僅不能有效獲取時序信息,甚至可能是噪聲。
針對上述兩個問題,TSM通過人為設定通道移位比例(1/2,1/4,1/8),通過多組對比實驗的結果確定最終的通道移位比例;并且利用殘差結構,將移位前的特征與移位后的特征進行融合以保持對空間特征的學習能力。但是,TSM每次按照不同比例所選擇的通道都是局部低層次的通道,且僅比較了局部連續的通道整體上對時序移位的影響,只獲取到局部時序信息。此外,TSM通過殘差結構也僅僅保證了空間特征的學習能力,忽略了時間特征結構的改變對整個特征學習的影響。GSN則利用門控單元改善了TSM中人為設定通道移動比例的局限性。但是,GSN所考慮的是短期時空信息,并未分析不同層次通道上的時序信息,仍然存在著一定的局限性,且采用的殘差結構依舊只能保證空間特征的學習。
2 文中方法
對于進行時序移位的通道的選擇,該文設計一個動態時序移位(DTS)模塊,利用雙層全連接學習多個時間維度的特征間的相關性,獲得不同層次通道的注意力分布,并固定雙層全連接的網絡參數用于保存時空特征信息。此外,為消除時間維度上特征的移位對整個特征結構的影響,利用雙層全連接的網絡參數進一步學習全局時空特征。
2.1 整體網絡結構
基于全連接神經網絡的動態時序移位和全局時空特征學習的網絡結構如圖1所示,主要由特征提取器(ResNet-50)、FFN(FC+Activation+FC)和動態時序移位模塊(DTS)構成。首先,從采樣到的視頻圖像中提取出基礎特征X。然后,利用FFN+Softmax實現通道注意力分布的學習;動態時序移位模塊(DTS)依據通道注意力分布有選擇地對通道特征進行時序移位操作;對FFN進行拆分并對網絡參數進行維度轉換,學習全局時空特征;對全局時空特征和動態時序移位后的特征進行融合,獲得視頻動作特征表示Y。最后,將特征表示Y輸入分類器獲得最終的分類結果。
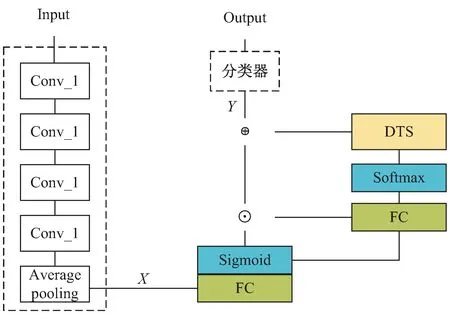
圖1 整體網絡結構
2.2 動態時序移位模塊(DTS)
動態時序移位(DTS)模塊如圖2所示。該模塊依據由FFN學習到的不同層次通道上的注意力分布,對注意力值大于設定閾值的通道進行有選擇的時序移位,實現在同一通道維度上不同時間維度間的信息交互,從而增強時序特征的表達。
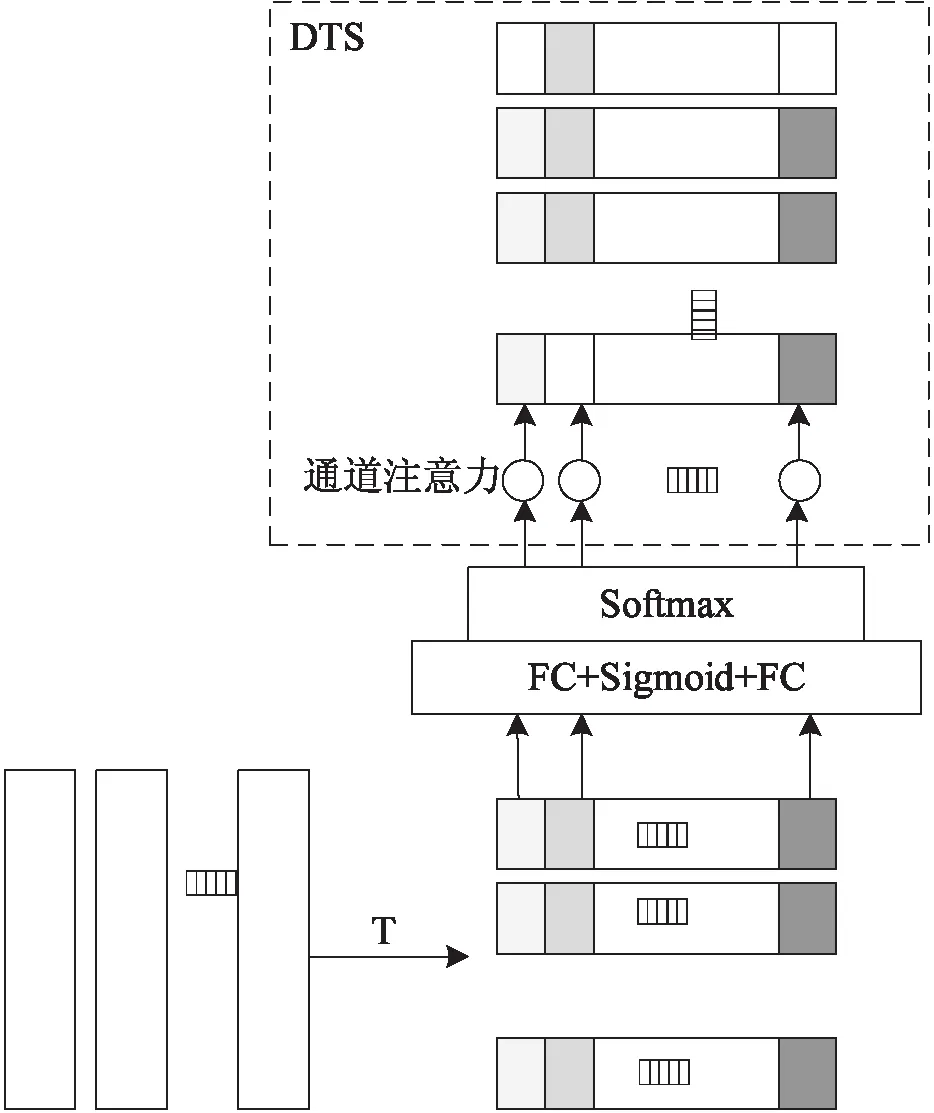
圖2 動態時序移位(DTS)模塊結構
針對上述關于通道選擇的兩個問題,該文從多個時間維度的特征間的相關性角度出發,當特征間的相關性較大時,表明特征所包含的信息更具交互性。在對某通道進行時序移位時,若該通道上多個時間維度特征相關性較大,對時間維度上的特征的改變并不會產生差異性較大或無用的信息。因此,基于注意力機制的思想,利用雙層全連接學習時間維度上特征間的相關性,獲得不同層次通道的注意力分布,并設置閾值,對通道上注意力值大于閾值的通道進行時序移位,這樣不僅確定了對哪些通道進行時序移位,也確定了進行時序移位的通道數。
首先,利用基礎網絡(ResNet-50[4],BNInception[17])進行初步特征提取,定義L個基礎特征集合X∈RC×L,即從同一視頻片段上的L幀圖像中所學習到的基礎特征:
X=(X1,X2,…,XL)
(3)
為學習通道維度上的注意力分布,需對通道維度上的特征間的相關性進行學習,因此先對特征集合X進行維度轉換,再輸入到全連接層:
(4)
然后,利用雙層全連接計算出不同層次通道的注意力分布,并利用Softmax對注意力值進行歸一化。注意力分布a∈R1×L計算如下:
(5)
其中,W1∈RL×H,b1∈RH×1,W2∈RH×1,b1∈R1×C。將基礎特征集合X進行維度轉換后,將每個通道上的一組特征視為一個輸入,進入雙層全連接后,將獲得每個輸入中時序信息間的依賴關系,再利用Softmax將獲得的依賴關系數值化得到整個通道的注意力分布。這樣就可以根據每個通道位置上的注意力大小,決定是否對該通道位置上的特征進行時序移位操作。這樣不僅實現了時間維度上的建模,而且從相鄰時間維度上的特征之間的相關性全面考慮了不同層次通道上的特征,利用網絡學習出的時序特征間的依賴關系對通道進行選擇,實現了對時序信息最大程度的利用。
2.3 全局時空特征學習
考慮到經過動態時序移位后,時間特征的結構信息的改變對整個時空特征學習的影響,該文進一步學習了全局時空特征,并將全局時空特征與時序移位后的特征進行融合,作為最后分類的輸入。
基于全局時空特征的結構特性,利用全連接層可以有效保留完整的特征結構,并且可以獲取長期依賴關系,因此全連接層可以很好實現對全局時空特征的學習。但引入新的全連接層學習全局時空特征會引入大量網絡參數,現有雙層全連接學習不同層次通道注意力分布時,已獲得整個通道上不同時間維度間的依賴關系,而在整個時空特征中,通道域的信息可以看作是原始輸入的層次化特征/層次化信息的層疊,因此可以直接利用現有全連接層學習全局時空特征,即將基礎特征集合進行了維度轉換后作為雙全連接層的輸入,從而學習不同層次通道上多個時間維度特征間的相關性,實現在不增加額外網絡參數的情況下,利用雙全連接層對全局時空特征進行學習。
該文將兩層全連接層進行拆分,并對已經學習到的網絡參數進行維度轉換,對兩個全連接的輸出特征進行融合獲得全局時空特征。這樣可以在不增加額外網絡參數的情況下,不僅保證了對空間特征的學習,而且消除了時序信息移位對整個時空特征的影響,提升了網絡對時空特征的學習能力。
Z=σ(W1X+b1)
(6)
S(Z)=W2Z+b2
(7)
Y=Z·S(Z)
(8)
2.4 損失函數
該文采用了TSN[10]中的分割思想,將視頻分割成L個等長的視頻片段,再對每個視頻片段進行采樣,在使用分類結果計算損失之前,需要將特征的學習分為兩個部分:第一個部分是經過動態時序移位后的特征;第二部分是動態時序移位后的特征與全局時空特征的融合特征。將C個通道的特征經過動態時序移位后的特征定義為F,如式(9)所示:
F=[S(X1;W),S(X2;W),…,S(XC;W)]
(9)
(10)
最后,采用分類任務中經典的Cross Entropy Loss計算網絡的損失:
(11)
3 實驗結果及分析
3.1 數據集
UCF101[20]是收集自YouTube的現實動作的視頻動作識別數據集,包含了101個動作類別的13 320個視頻,101個動作類別大致可分為人與動物互動、人物肢體運動、人與人之間的互動、演奏樂器以及體育運動這5種類型。該數據源自YouTube用戶錄制并上傳的視頻,更貼切現實生活場景。該文將同一類別的視頻分成25組,每組包含4~7個視頻片段,其中訓練集和驗證集的視頻數量分別為9 537和3 783,并采用RGB和Optical Flow兩種特征類型。
Something-something v2[21]數據集由1 133位工作者提供的視頻片段構成,按照同一上傳者的視頻放在一個集合內進行劃分,下面簡稱為Sthv2。相比于其他數據集,Sthv2更加復雜,其視頻數據量龐大,高達220 847,包含174個動作類別,每個視頻片段時長為2~6秒。
3.2 實驗結果分析
在UCF101數據集和Sthv2數據集上,主要進行兩組實驗:與TSM以及現有主流方法(TSN,GSN)進行精度對比;基于消融實驗分析注意力閾值的選擇以及驗證全局時空特征的有效性。實驗基于Pytorch深度學習框架,操作系統為Ubuntu 18.04.1,顯卡型號為GeForce RTX 2080i。
3.2.1 文中方法與主流算法的性能比較
本組實驗研究文中方法與TSM、TSN[10]以及GSN[19]在UCF101和Something-something v2數據集上的識別精度。
實驗采用了TSN的分段采樣策略(Segment based Sampling),將視頻數據分割成8個片段,即num_segments=8,再對每個視頻片段進行密集采樣(Dense Sampling);使用ResNet-50作為特征提取器,初始特征維度為batch_size×64×224×224;使用Softmax函數作為最終的分類器。實驗結果采用Top-1和Top-5性能指標進行評測。
在UCF101數據集上,epoch為25,初始學習率為0.001,且每經過10個epoch進行學習率衰減,即降為原先的0.1倍;在Something-something v2數據集上,考慮到數據量的龐大性,該文將epoch設置為50,初始學習率為0.01,學習率衰減的步數為20,其他參數設置保持不變。考慮到物理設備的限制,batch_size為16;TSM算法中通道移位比例為1∶8,文中方法的注意力閾值為0.5,精度比較結果如表1所示。
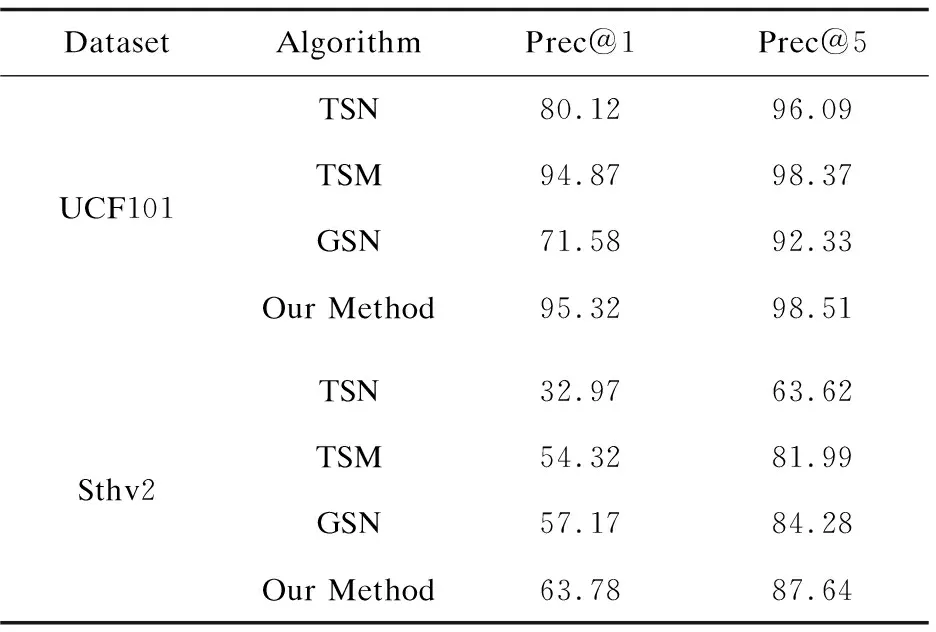
表1 文中方法與其他方法的識別精度比較 %
通過表1可發現,在UCF101和Something-something v2數據集上,文中方法在Top-1和Top-5指標上均取得最好的識別精度,表明文中方法沿著時間維度有選擇地進行通道特征移位,能夠獲取到更有效的時序信息,有利于最終的識別任務。此外,在Something-something v2數據集分類任務上,表1中算法所取得的識別精度均低于UCF101數據集上的結果,原因在于UCF101數據集相對簡單,數據量較小、類別數較少,網絡所需要學習的特征較少從而容易達到相對較好的分類效果。其中,TSN算法在兩個數據集上Top-1精度差最大(ΔPrec@1=47.15%),表明基于時序移位的方法(TSM、GSN、Our Method)所建模的時序信息有利于處理數據更為復雜的分類任務。在UCF101數據集上,文中方法與TSM相比,Top-1精度僅提升0.45%;而在更復雜的Sthv2數據集上,文中方法與GSN相比,Top-1精度提升6.61%,與TSM相比精度提升達9.46%,體現了文中方法具有更好的識別性能。
3.2.2 注意力閾值的選擇
動態時序移位模塊(DTS)基于由FFN獲得的不同層次通道上注意力分布,選擇通道注意力值大于閾值的通道進行時序移位,即選擇出不同時間維度間特征相關性較大的通道。而閾值的大小決定著時序信息的交互程度,如果閾值過大,某些通道上緊密相關的時序信息未被得到有效利用;如果閾值過小,則會對時序信息不緊密的通道進行時序移位,不同時間維度上會產生無關信息。為了進一步分析注意力閾值的選擇,在UF101數據集上進行消融實驗。對基礎網絡(ResNet-50)提取到的特征(32×64×224×224)計算每個通道上32個時間維度特征間的相關性,獲得維度為64的通道注意力分布,并對注意力分布進行歸一化處理,不同層次通道的注意力分布如圖3所示。橫坐標為特征的通道,縱坐標上的注意力值對應著每個特征通道。
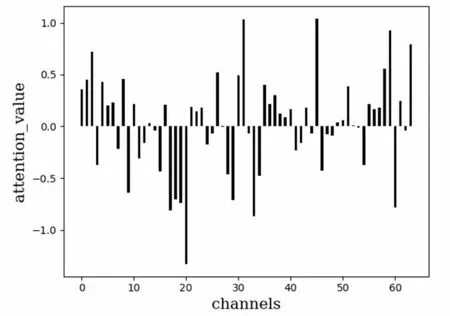
圖3 不同層次通道的注意力分布
從圖3中可以看出,不同層次通道上的注意力分布存在較大的差異,表明不同層次通道上所包含的時序信息是不同的,呈現出正相關和負相關兩種截然不同的結果,因此從多個時間維度間的相關性考慮選擇通道進行時序移位,可以獲取到更全面更有效的時序信息。注意力閾值的選擇采取兩種方式:根據注意力分布的結果人為選擇閾值(0.5);計算所有通道上注意力的均值作為閾值。實驗發現,當對注意力值大于0.5的通道進行時序移位效果更好,因為不同通道上注意力值差異較大,且存在負值,不能很好地反映注意力值的整體分布。
3.2.3 全局時空特征有效性分析
經過動態時序移位后,實現不同時間維度上的信息交互,進一步增強時序特征表達。但時序移位操作對整個時空特征結構產生了一定影響,因此,該文在已有全連接層結構的基礎上,進一步學習全局時空特征。為驗證全局時空特征的有效性,去除所提方法中的全局時空特征學習過程,即取消對雙層全連接(FNN)的拆分,對基礎特征進行動態時序移位后直接用于最終的分類任務,獲得基于全連接神經網絡的動態時序移位方法(Our Method-),其整體網絡結構如圖4所示。在具體實現過程中,不固定雙層全連接的參數,且沒有特征融合過程。
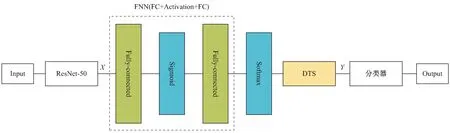
圖4 基于全連接神經網絡的動態時序移位方法
為探究全局時空特征的有效性,在UCF101數據集上對5組視頻動作識別方法進行了對比實驗,所有參數設置均與3.2.1節實驗設置一致,并繪制了測試精度隨迭代變化曲線,如圖5所示。其中橫坐標為迭代次數,縱坐標為識別精度。
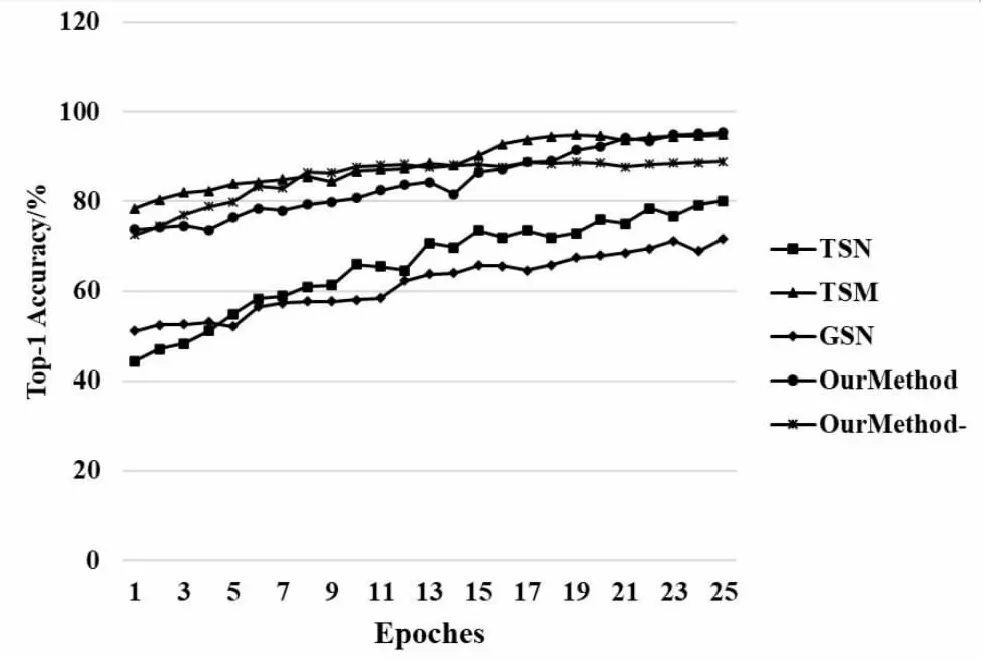
圖5 UCF101數據集上的測試精度比較
由圖可知,5組算法的識別精度均隨著迭代次數增加,整體呈上升趨勢,其中Our Method取得最高識別精度;與TSM和Our Method-相比,Our Method在迭代前期未取得較好的識別效果,這可能是因為Our Method的特征規模較大,需要不斷學習全局時空特征,而隨著迭代步數的增加,學習到的全局時空特征更加穩定,為最終分類任務提供更有效的特征信息,Our Method取得了更好的分類結果;缺失全局時空特征學習的方法(Our Method-)識別精度明顯低于Our Method,進一步驗證了全局時空特征的有效性。
4 結束語
針對處理視頻時序信息中存在的模型復雜度高、時序信息不全面的問題,提出基于時序動作移位和時空特征學習的視頻動作識別方法。首先,利用卷積網絡學習初始特征,通過雙層全連接學習多個時間維度上特征間的相關性,充分挖掘不同層次通道上所包含的時序信息。然后,固定部分網絡參數幫助學習全局時空特征,消除了時序移位對整個特征結構的影響。實驗表明,與現有主流方法以及基于時序移位的方法相比較,該方法的學習效果得到了明顯提升。
視頻動作識別是計算機視覺領域中的研究熱點之一,在智能家居、游戲交互以及安防等多個方面得到廣泛的應用。隨著人工智能技術的不斷發展,不斷創新視頻動作識別的方法,比如Vision Transformer[22],為加強圖像特征學習、減少訓練時計算量等問題提供了新的研究思路,對于改進視頻動作識別方法有著很大的研究價值。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
